数字化电网设备监测与故障诊断
2024-03-08中国能源建设集团广东省电力设计研究院有限公司谭卓敏何智文廖德芳关秋楠
中国能源建设集团广东省电力设计研究院有限公司 谭卓敏 姚 池 何智文 廖德芳 关秋楠
近年来,我国社会经济出现跨越式发展,据专业人员统计发现,在2020年全国GDP总量超过100万亿,和1980年相比,增长幅度为4000%。在这种经济奇迹增长背后,和我国电力工业提供的基础保障能源有直接联系,随着电网规模不断拓展,无形中提高了电网供电能力,但也增加了电网运行的安全风险。
目前,我国辽宁省有很多变电站均受到恶劣天气影响,出现安全故障,导致很多区域发生停电事故,损失负荷为255.2MW,说明自然灾害严重影响到电网运行。除了外在因素影响外,和电网结构、设备故障等因素有关联,电网设备作为电力网络的重要环节,一旦该环节出现安全事故,必然诱发严重的电网振荡,甚至导致电网系统崩溃,严重影响到工农业生产效率[1]。
1 电网设备诊断评估方法
1.1 电网设备状态量选择
电网设备状态量是指能直观反映电网设备实际运行情况的信息。由于电网设备结构过于复杂,单个信息不能反映出设备实际健康状况,但值得注意的是,要合理控制状态量选择数量。在故障诊断过程中,状态量过多很容易影响到判断的准确性,导致有用信息被无效数据埋没,不利于工作人员判断电网设备实际情况。因此,在选择状态量时,要严格遵循科学性、典型性等原则。其中典型性原则决定着设备健康评价质量,能准确反映出设备特征,状态量选择中并非依靠数量,如果其数量过多,不仅会提高数据收集难度系数,还会掺杂各种不相关状态量,避免其对状态评价造成负面影响。可见,典型性状态量筛选是一个减法过程,要解决掉关联性较低的状态,加强模型搭建效率;科学性表示在选择状态量中要具有较强科学依据,通常利用仪器进行检测,能充分体现出设备实际情况[2]。
1.2 数据采集和预处理
为了避免受到上述因素影响,给建模流程打下坚实的基础,工作人员要预处理数据资源:首先,数据清洗。第一,先识别数据中异常信息,主要包括重复信息、不完整信息、不正确信息等,再科学处理异常数据,形成完整的样本集;第二,数据集成。其主要目的是整合各种数据信息,这里的整合不是直接集合过程,由于数据结构、名称、定义等方面存在严重差异性,很容易影响到数据处理的准确性。工作人员要统一数据格式,将这些数据整合,删除重复数据,保证数据使用质量;第三,数据转换。将数据从一种格式转变成其他格式的过程,对数据管理有重要作用,通常应用归一化、规范化两种方法。规范化是指统一数据单位、格式、顺序等要素;归一化是将状态量数据由原本的绝对值向相对值方向转变,是目前最常见的无量纲处理方法。但因为不同电网设备状态数据单位差异性较强,这种处理方法能有效解决不同性质数据差异性,避免量纲给数据信息准确性造成严重影响;最后,数据归约。在确保数据原始特征基础上,合理控制数据集规模,加强算法效率的重要方法,其是由数据规约和数据降维两种处理方式。其中数据降维是通过控制数据集中的属性优化数据集,最常用线性判别分析、特征提取分析、主成分分析等;数值归约控制数据集中数据,改善数据集内容[3]。
2 电网设备故障诊断步骤
2.1 划分样本数据集
将收集到的1039组油中溶解气体数据,严格按照8:2比例,分解到训练集1378组,测试集345组,且进行建模作业。本文实验仿真平台采用Anaconda,编程语言Python 3.7(见表1)。
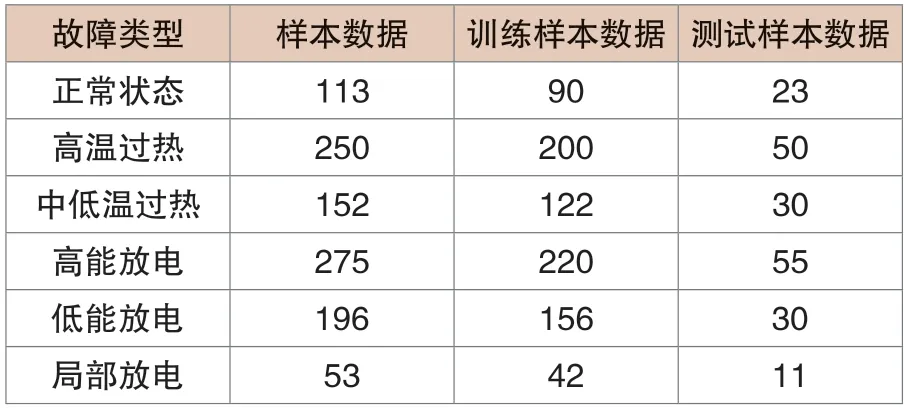
表1 故障样本数据分布
2.2 参数的调整选择
调整参数主要目的是找到模型的最佳参数比,发现误差和模型复杂度间的必然关联。在挖掘数据过程中,工作人员通常采用衡量算法应用到泛化误差方面,其泛化误差值越低,说明模型泛化能力越强(如图1所示)。

图1 泛化误差和模型复杂度关系图
通过分析上述图片内容,发现当模型复杂程度较低时,会影响到算法模型应用效果,产生较高的泛化误差,即模型欠拟合;而如果模型复杂程度较高,算法模型易将噪声数据特征应用到模型,增加泛化误差,统称模型过拟合;如果模型复杂程度适中,能合理控制泛化误差,检测精度最好。而调整参数主要目的是提高模型检测精度,增加模型使用分数。基于此,本文采用Sklearn库,调参对象为决策树最高深度和数量,直到两个参数数值能达到预期标准。结合自身多年工作经验和数据内容,将参数决策树数量设置为n_estimators= [5,10,15,20,25,30,35,40,45,50,55,60,65,70],最高深度值为max_depth_list =[5,6,7,8,9,10,11,12,13,14,15],准确检测测试集准确率变化情况,如图2所示。

图2 RF 测试集的准确率
通过分析上图,发现决策树最高深度和数量经过160次迭代,变压器故障诊断正确率在82次、58次、13次、102次时最高[4]。
2.3 结果分析和性能对比
2.3.1 不同模型性能对比
在故障诊断过程中,最常用支持向量机分类模型、逻辑回归模型、最近领算法模型等方法。因此,工作人员要根据样本集进行划分,以无编码数据为特征参量,应用到不同诊断模型中进行分析(见表2)。

表2 不同诊断模型的结果比较
通过分析上述表格,发现逻辑回归模型诊断模型召回率、分类正确率、F1等分数均小于0.8,诊断效果未达到预期要求;随机森林诊断模型中评价指标均超过0.9,表示其诊断效果较好。从整体角度分析,邻算法模型、支持向量机分类模型正确率较低,随机森林诊断模型能有效提高正确率8%~13%,判断整体性能分数高于其他算法模型,说明本文诊断模型在故障诊断分类方面具有重要作用[5]。
2.3.2 不同故障集结果分析
为了分析各种故障样本集对模型诊断正确率作用,根据不同故障类型,将样本数据分成样本1、样本2、样本3、样本4、样本5、样本6,按照遵循8:2比例,合理规范训练集和测试集,将15对气体比值分别输入到如下表格(见表3)。
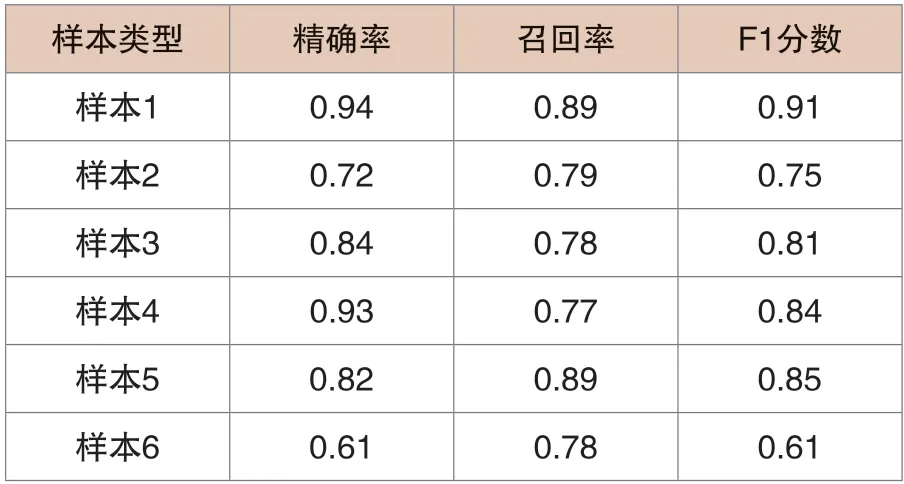
表3 不同故障集诊断结果对比
高温过热、正常数据、高能发电、中低温过热等故障数据诊断精确度较高,F1分数超过0.8,具有良好的诊断性能。而低能发电故障数据精确率仅为0.72,通常是由于低能放电故障出现在电力变压器故障前期,且不同放电类型产生的气体比例存在严重影响,造成低能放电数据过于分散,给诊断效果造成严重影响。同时,各种因素影响局部放电故障数据准确性,工作人员要根据实际情况,合理提升样本数量,全面加强诊断准确率。
2.3.3 不同特征量对结果的影响
本文采用15对气体比值作为分类器的特征属性,为了分析这些特征属性对整体模型的重要程度,注重研究特征数据对模型评分的影响(如图3所示)。可看到C10、C13、C14、C12、C11对整体模型影响程度在首位。但C11、C10、C13三组特征量也是行业标准中常用的三比值法的气体数据,不仅检验了以往数据的正确性,还证明了该模型分类的准确性,对工作人员试验有重要作用。

图3 特征属性对模型评分的影响度
3 总结
综上所述,政府部门要提高对电网设备安全故障的重视程度,分析既有设备工作情况和异常数据,提前预测故障问题,针对问题提出有效解决措施,制订应急预案和运行方案,避免出现大规模停电现象,加强电网运行的稳定性。
