动态平滑系数和参数的动态三次指数平滑法在火电厂发电量预测研究
2024-03-08国家能源集团国源电力有限公司王天晓
国家能源集团国源电力有限公司 王天晓
1 动态指数平滑预测模型
1.1 传统指数平滑模型
式中:AT、BT、CT均为基于过去的观测值和指数平滑法计算得到的系数,其中,AT表示预测时刻t的平滑值;BT表示时间序列在时刻t 的趋势;CT表示时间序列在时刻t 的曲线的二次趋势。进一步分解为:
1.2 改进指数平滑模型
传统三次指数平滑模型的α 被视为常量,这在某些情况下可能导致预测精度的降低[2]。为了克服这一局限性,提出了一种新的方法,即通过动态修正和迭代更新来引入动态平滑系数和参数,以增强模型的预测能力和准确性。
在预测过程中,α 系数的选取受到预测的企业和月份的影响,因此不能单一化。为存储动态平滑系数,引入数组F[m,n],而α 的取值则与时间序列的特性紧密关联:当时间序列呈现水平趋势时,α的推荐范围为0.1~0.3;若存在波动,则范围调整为0.3~0.5;对于明确的上升或下降趋势,α 的取值则位于0.6~0.8。改进三次指数平滑公式为:
式中:am,n表示动态平滑系数,其决定了新的观察值与先前的平滑值之间的权重分配,其中m、n为数组的指标,指示了在特定的情境中(特定时间)中α 的数值。
其中,S(1)=S(2)=S(3)=1/3(XN-3,XN-2,XN-1),XN-3,XN-2,XN-1能够预测实施发电前三个月的发电量,所获得结果呈现动态性,即与每一次的预测值具有关联性,因此,在此条件下的三次指数平滑法中的预测公式则为:
进一步分解为:
首先,在教学中,在“视”“听”的环节花费的时间较长,对“说”的侧重不够。输入和输出两个方面共同构成了语言学习的全过程,如果输出不够,就不能及时巩固所学知识,也不利于学生充分发挥主观能动性。贯通培养项目高中阶段的学生由于英语基础较差,对于口语表达有一定的畏难情绪。教师应创设真实、有趣的语言情境,并对学生提供一定的方法指导,引导学生进行口语输出。
为确保平滑系数α 的准确性,本研究采用均方差和相对误差进行精确地评估和判断:
式中:σ 表示样本的标准偏差;si表示数据序列中的每一个观察值;xi表示数据序列的平均值或某个参考值;t 表示观测值的总数。
在上述的基础上,为进一步提升预测的有效性,需应用相对误差进行处理,根据所计算结果可以反映出预测的准确性,即所得到误差与准确性成反比。δ 的计算公式为:
式中:Δ 表示绝对误差,即测量值与实际值之间的差;L 表示实际值或参考值。
在火电厂的发电量预测中,发电量的走势受多种因素影响,如政策调整、设备检修周期及季节用电高峰期。为增强三次指数平滑法的转折点鉴别能力,本研究引入预测干预法进行数据修正,从而使得模型更为敏感地捕捉到数据的转折点。经过迭代计算,进一步校准预测模型,确保预测结果的准确性。最后,均方差和相对误差被采用作为验证预测效果的关键指标,提供了对模型效能的深入评估。
利用三次指数平滑的时间序列预测模型在火电厂发电量中的应用显得至关重要,特别是选择适宜的平滑系数α 以保证预测的准确性与稳定性,具体的实施过程为:基于前三个月的数据[XN-3,XN-2,XN-1]作为预测起点,并将结果置于数组F[m,n]内;考虑到黄金比例的数学和自然属性,选择了0.618和0.382作为可能的指数平滑系数α。为确保预测的准确性,还须收集与电厂相关的政策、维修检测时间以及季节用电高峰数据进行干预处理;通过综合考虑这些因素,设定了动态的指数平滑系数α,与确定的预测时间长度T 共同作用,经过特定的计算式得到预测数值。
当预测数据与实际情况存在偏差时,可根据干预数据进行相应的调整;通过特定的计算方式对其进行验证后,继续开展迭代计算。每次迭代后都会计算均方差和相对误差。如果这两个指标不满足研究要求,特别是当相对误差超出了0.1的标准,平滑系数α 则需要进行相应调整。在经过多次迭代和验证后,最终选取能使相对误差满足0.1以下标准的平滑系数进行预测。
2 动态三次指数平滑法在火电厂发电量预测的应用
2.1 数据来源与处理
采纳了2020年至2022年某地5家火电厂的发电量数据,其中2020年9月至11月的数据被选作主要参数,后续年份的发电量数据用于预测的验证,确保模型的准确性与可靠性。
2.2 预测模型建立与实现
2.2.1 加权移动平均法预测应用
数据分析。在对5家企业的发电量数据进行深入分析时,平稳性检验表明(见表1)实际数据存在不平稳性,进一步的自相关系数与偏相关系数也验证了这一点,并揭示了其内在的强相关性。由于这种不平稳性和相关性,简单的预测方法可能无法准确地捕捉到发电量的波动,因此考虑到这种复杂性,建议采用动态权值系数对企业发电量进行预测,确保预测的准确性和可靠性。
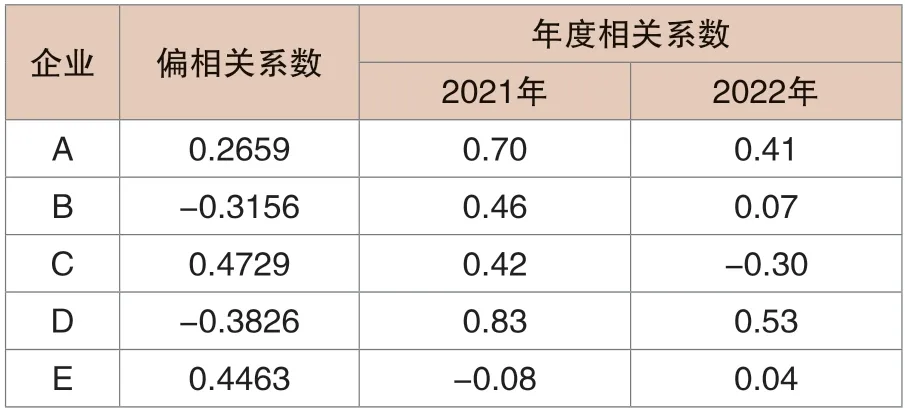
表1 发电量的自相关和偏相关系数
确定权重比例。在加权移动平均法预测中,MA 模型的核心是根据前3个月的发电量权值进行权重赋值。对于这三个参数,即[XN-3,XN-2,XN-1],其权重比例的确定是至关重要的。考虑到自相关系数的影响,当其大于0.2时,按照黄金比例0.618,权值分配为(0.618,0.3,0.082);而当自相关系数小于0.2时,权值则为(0.382,0.6,0.018)。
调整预测时间长度。为精确预测2021年至2022年的发电量,设定预测的时间长度为1,确保每次预测结果的更新能为后续预测提供更贴近数据发展趋势的参考点,从而实现连续迭代预测。
预测及误差值和均方差计算。从2020年9月至11月的数据出发,采用迭代方式预测2021年至2022年的发电量。对比实际和预测数据,计算相对误差值和均方差以评估预测效果,为后续研究提供更有针对性的参考依据。
2.2.2 改进指数平滑模式预测应用
数据分析。基于前3个月的预测数据,设定初始的指数平滑系数并对其进行细化。针对数据的单调与波动特性,分别为两个阶段分配了0.618和0.382的指数平滑系数。此外,还考虑了电厂的假期政策、设备维修时长及季节用电高峰等外部因素,以保证预测的准确性和实际应用的广泛性。
设置平滑系数α。基于数据分析中F[m,n]数组中的系数,通过循环遍历的方式为平滑系数α 进行动态取值。当发电量趋势上升或下降时,α 确定为0.618;而在发电量表现平稳时,α 被调整为0.382,确保预测准确性与应对实际变化的灵活性。
调整预测时间长度。基于维修时间报告与外界干预信息,确定预测干预的月份,对应时间长度设定为1;此长度值随后被代入式(5),确保预测在接下来的研究中具有实证基础和高度准确性。
预测及误差值和均方差计算。采用式(4)~式(6)对2021年至2022年电厂发电量进行预测,得到初始预测值。结合预先设定的干预月份,对这些预测数据执行干预处理,从而准确揭示其变化中的拐点特征。通过式(7)和式(8)评估预测值与真实值之间的相对误差和均方差,若误差值不在设定范围,需要重新调整α 值。为确保相对误差在0.1以下,采用遍历查找方法,每次调整α 的间距为0.01,直至找到满足条件的比例系数,从而保障预测的准确性与稳定性。
2.3 预测结果与分析
在对五家发电企业,分别标记为A 至E 后,运用两种模型预测其2021至2022年的月发电量。将实际与预测数据分别绘制于同一曲线图上,使对比更为直观。对比结果显示(见表2),预测数据与实际数据在大多数时间点上存在较高一致性,通过对发电量数据的预测比对,明显观察到加权移动平均法的预测结果较为偏离实际曲线,尤其在某些关键拐点上,表明其不适合应用于此领域的预测。
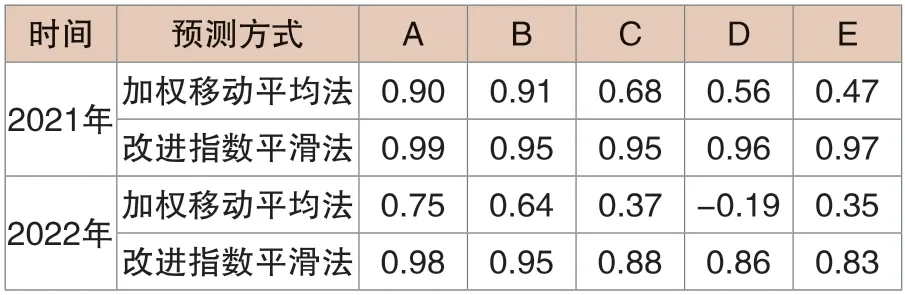
表2 不同预测方式的相关性系数对结果
根据表3,动态三次指数平滑模型在2021年和2022年的发电量预测方差均较加权移动平均法(MA)小。此外,平均相对误差也更低。
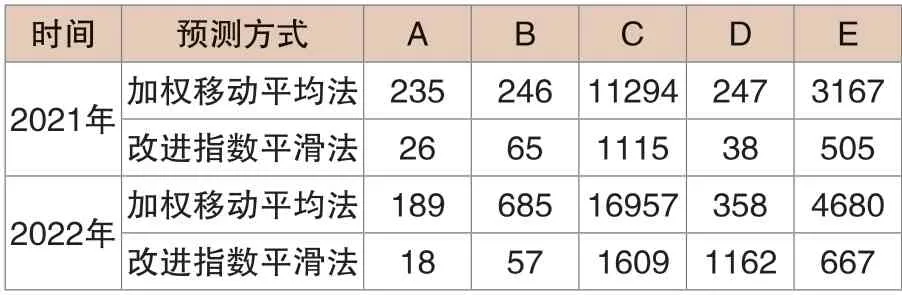
表3 不同预测方法算法方差结果
根据表3的数据,加权移动平均法在预测火电厂发电量时表现出相对较大的方差,而动态三次指数平滑的方差显著地低于前者。图1进一步呈现了两种预测模型的平均相对误差,虽然两者误差均不大,但动态三次指数平滑的整体误差不仅低于加权移动平均法,其相对误差还呈现出稳定性,均低于0.1。相反,加权移动平均法的误差展现出不稳定性,其平均误差达到0.2,甚至在某些时刻高达0.52。因此,对于火电厂发电量的预测,不建议使用加权移动平均法。

图1 2021年、2022年相对误差对比图
