基于个人知识库的大数据房价分析系统
2024-03-05姚开元
常 艳,曹 明,姚开元
(山西农业大学 软件学院,山西 太谷 030801)
0 引言
如何高效利用信息自古以来便是一个非常重要的话题。传统的古老法、跨平台法、类苹果法等在信息加工效率、使用便捷性、安全性等多个方面存在不同程度的局限性。而在大数据时代背景下,结合大数据技术的软件法不仅能够对个人数据实现有效管理,满足用户个性化需要,还能一定程度上保持相关企业的竞争优势[1]。本文借助大数据技术构建个人知识库,达成个性化主题分析,有效提高信息输出的效率。
1 个人知识库的构建
与面向特定领域的通用知识库相比,个人知识库侧重面向用户兴趣,保障知识库中所存储的信息与个人息息相关,能够快速满足用户的个性化需求[2-3]。本文个人知识库的构建重点关注知识数据的实时性与连续性,以便为用户提供持续跟进的知识参考价值。整体划分为采集、处理、存储、监控四个模块进行设计实现[4]。具体架构设计如图1所示。

图1 个人知识库架构设计图
1.1 数据采集
个人知识库的数据来源为Web网页,依托Python爬虫程序,自定义URL入口与爬虫频率,定时触发模拟人为浏览模式实现初始非结构化数据采集,按照个人主题需求对数据进行解析,筛选出主题相关内容并按照一定格式规则存入指定的服务器本地磁盘文件夹内,完成数据采集。
1.2 数据处理
Flume作为一种分布式管道架构,在数据源与目的地之间通过Agent网络实现数据路由[5]。个人知识库利用Flume监听指定文件夹,借助Flume多级架构特性完成Event基本传输单元复用分流至Kafka及HDFS,利用Kafka Cache队列补偿两个数据之间的速率差异,以解决由于发送和接收数据之间的速率不一致而造成的数据丢包问题,最后借助Spark与Hive达成实时处理与离线处理两条数据处理流水线,同步满足用户的实时分析需求与离线统计目标。
1.3 数据存储
数据实时处理场景中,当Flume监控的文件发生变化时,将变化的数据交由Kafka暂存,Spark轮询Kafka获取数据进行计算并将处理结果传递至MangoDB及MySQL进行持久化。同时Flume通过文件配置可同步将数据传输至HDFS,利用多层Hive处理获取用于可视化分析的维度表,并通过Sqoop工具将数据表迁移至MySQL。
1.4 数据监控
个人知识库可采用Azkaban、Zabbix进行全流程调度和集群监控,保障系统能够安全稳定地执行,并对可能出现的一系列故障提供预警方案,输出基于邮件的告警,及时反馈服务器相关问题。
2 系统设计
个人知识库搭建完成后,依赖ParseServer工具提供的API服务,可实现实时信息的查询,完成信息检索,同时也可在FineBI上对数据进行分析,获取隐藏在数据冰山下的知识,为后续的决策提供一定的辅助参考,具体如图2所示。

图2 房价分析系统架构设计图
ParseServer能够协助快速搭建后端,使得用户可以通过App、网站、小程序等各类终端,调用ParseServer提供的API服务,便捷实现用户的精细化查询需求,拓宽用户的数据查询途径。MangoDB作为经典的NoSQL数据库,能够与ParseServer无缝配合进行信息的实时检索。
FineBI可以利用花生壳进行内网穿透实现外网访问,与MySQL建连,让用户能够对海量数据迅速进行多维度可视化分析。
3 系统实现
在CentOS平台首先完成NodeJS及MangoDB的环境搭建,然后进行ParseServer安装,该服务器搭建完成后,即可配置Hadoop集群。集群中所有物理主机安装CentOS7 64位,为了操作方便,修改每台主机的名称和端口号并配置免密登录,同时指定节点信息,具体配置如表1所示。
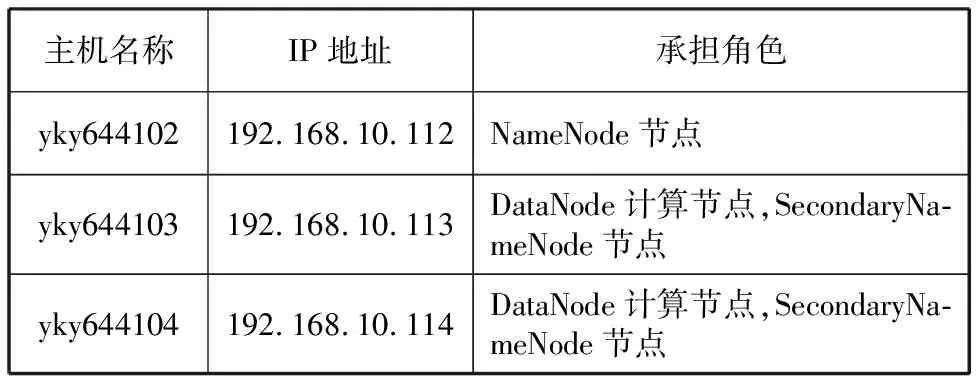
表1 Hadoop集群配置表
Hadoop环境搭建完成即可进行Hive数仓的安装,分别配置hive-env.sh、hive-config.sh、hive-site.xml文件来设置连接MySQL的相关参数与其他参数。
完成基础配置后再进行Flume、Kafka、Spark 、Sqoop、Azkaban和Zabbix等的搭建。Zabbix可以对集群中三个节点的启动状态进行有效监控,能够实现本地资源及数据收集的监测,进行告警,同时用户可以通过zabbix-web页面实时观察相应的监控信息。
整体环境搭建完成后顺利进入数据处理。经统计脏数据等数据量低于1%,这些记录的主要特征是缺少数据值。本系统在设计实现的过程中,数据仓库划分为三层,极大地减少重复计算、方便定位和理解,根据每层的功能,采取不同的数据处理方式,主题维度和各层级中表的命名,字段命名也有不同,表中数据元素的数据类型根据字段名和操作过程确定。
ODS层是数仓的第一层,直接将HDFS中的原始数据进行存储,完成数据备份。数据采用LZO压缩,上传到HDFS并检查Hive中的数据映射包括建表,创建时间分区等。DWD层是数仓的第二层,主要是对ODS层中的数据进行清洗和降维。以分析房价系统为例,去除空值、脏数据,用正则表达式对房价等有单位的数据做一致化处理,将数据值进行拆分,并根据实际情况,“总房价”“每平米房价”“每月租金”相关数据不保留小数位,“租房面积”“每平米租金”“面积”保留两位小数。保存DWD层数据时按照行政区划分对各城区的数据分别存储。ADS层作为数仓的最后一层,主要是对上一层的数据进行汇总与整理。利用函数以及排序、分组和多表联查等操作将DWD层生成的数据按具体需求进行分析后,编写相应的Sqoop语句把数据存储到HDFS中,为后续可视化中的各种统计报表提供数据。
4 系统应用
知识服务是指通过信息技术手段,以用户实际知识需求为中心,对相关知识信息进行采集、处理、存储、分析,辅助提供智力决策,来协同解决用户实际问题,实现知识增值[3]。本文以北京房价数据为例,通过分析6000多个小区的房价数据,为北京的租客提供持续跟进的参考信息服务。
4.1 各城区月租房价比较
将所有房价数据格式化、一致化后按城区分组并通过降序升序和limit函数输出各城区月租房价的最大值和最小值。如图3,各城区每月租金最大为上方第一条折线,每月租金最小为第二条折线。通过数据节点的大小和折线趋势能够直观地横向和纵向比较各城区最大月租金和最小月租金,如“密云”的最小月租金最小,“顺义”最大月租金最大。

图3 各城区月租房价比较图
4.2 房价地图
在可视化工具中根据需要呈现的行政区划形式来选择,将待分析区域地理维度下的字段“城区”转化为地理角色。构建的地图如图4所示,以这些行政区划为单位进行数据呈现。北京市各城区每平米平均房价地图根据区域颜色深浅程度反映房价数值的大小,数值越大颜色越深。移动鼠标指针到区域可交互显示相关参数信息,而点击区域可下钻目录,通过气泡图(如图5)比较同一行政区划下各板块的每平米平均房价。

图4 北京市每平米平均房价地图
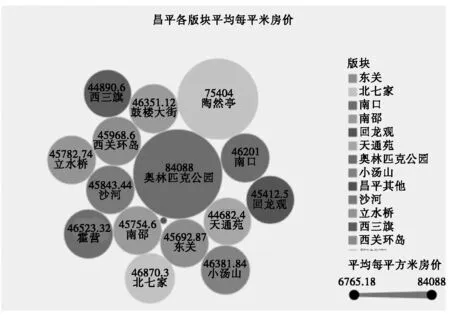
图5 昌平各版块平均每平米房价气泡图
5 总结与展望
经测试,系统稳定灵活,能在较短时间内准确输出检索内容,同时具备跨平台特征。本文结合大数据技术在个人知识库领域进行初步尝试,将传统的个人知识库赋能大数据特征,并通过北京房价数据分析进行应用实践,期望为后续的研究提供一定的参考价值。
