基于深度学习的图像识别系统研究
2024-03-05杨米娜
杨米娜
(山西工程科技职业大学,山西 晋中 030619)
0 引言
随着计算机算力的提高,图像识别技术也逐渐在各个领域得到了广泛应用。所谓图像识别,简单来讲就是对图像的属性特征进行划分和提取,并通过特征分析实现对图像的智能分类[1]。其中传统的图像特征提取方式会消耗大量的算力资源,并要依据一定的先验知识才能达到较好的处理效果,这大大限制了图像识别技术的发展和应用。为了改善这一现状,利用深度学习卷积神经网络对图像特征的提取、分类进行模型训练,以实现图像自动识别是目前最佳的一种解决方案。
1 关键技术
1.1 深度学习
深度学习是在机器学习的基础上通过多层神经网络对数据特征进行分类的一种算法模型。深度学习可以分为有监督学习与无监督学习两种[2]。有监督学习是指在先验信息的指导下,对已知数据特征标识的数据集进行分类模型的学习与训练,并依据该模型实现对未知数据的分类预测,常用的学习方法包括:深度前馈网络、卷积神经网络等;无监督学习是指在没有先验知识的监督下,对未知数据依据其潜在规律或特征的挖掘与分析结果对数据实现自动分类,也就是基于数据的潜在相似性进行分类,以使同一类簇内的数据相似性尽可能大,不同类簇的数据差异性也尽可能大,常用的学习方法有深度信念网等。
1.2 卷积神经网络
卷积神经网络是一种基于深度学习的多层神经网络,由输入层、卷积层、池化层和输出层构成[3]。输入层用于采集二维图像的原始数据;卷积层通过卷积核对图像特征进行卷积,每个卷积核可以得到一种图像特征,使用多个卷积核可以得到图像的多种特征图;池化层对卷积层输出的特征图进行网格划分与特征映射处理后,可以有效减少特征参数的复杂度,提高学习模型的泛化能力。在卷积神经网络中,卷积层与池化层交替部署,并可依据图像的特征维度设置卷积层数,共同构成隐含层,图像信息原样输入后,经过隐含层的多层卷积,再由输出层输出一个最终的预测结果。
1.3 图像识别
图像识别是人工智能领域的一个主要研究方向,它集合了计算机、数据挖掘、电子信息等多门专业学科技术,目的是利用计算机对大量图像中的指定特征或属性进行提取、分析,并从中找到待识别的目标、对象。图像识别的应用主要设计三类场景:图像分类、目标检测和语义分割。
◆图像分类,是通过对图像特征的提取和分析,将图像基于一定的特征规则进行自动分类的过程。图像分类仅需要解决图像中提取的特征目标属于哪一个类别,而不需要考虑其位置信息。
◆目标检测,是在图像分类的基础上,还需要标识出图像中目标特征的位置信息,以便于场景理解、对象跟踪、活动识别等更加复杂的场景应用。
◆语义分割,是为图像的每一个像素点定义了对应的语义类别标识,以实现像素级别的特征分类,并能够对图像信息进行完整解释。
2 系统架构设计
图像识别系统的架构设计主要包括三个功能模块:深度学习图像识别模块、图形化操作模块、网络服务模块。如图1所示。
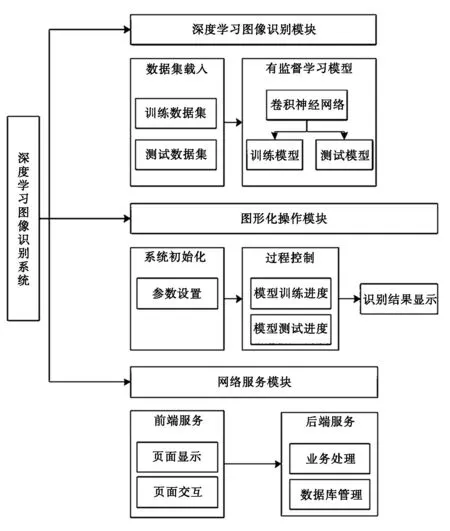
图1 深度学习图像识别系统架构设计
◆深度学习图像识别模块是系统的核心模块,采用有监督学习模式,以卷积神经网络为核心构建了图像识别算法模型。并通过训练数据集与测试数据集对模型分别进行学习训练和可靠性评估。
◆图形化操作模块,是将系统操作由控制台模式转换为了图形化模式,该模块主要设计了系统初始化、过程控制、结果显示三类内容的图形化操作程序。系统初始化用于实现深度学习模型的参数配置,过程控制用于反映学习模型的训练过程与测试过程,结果显示用于输出最终的图像分类结果。
◆网络服务模块,是通过网站搭建,将上述功能模块以网络服务的形式提供给用户。该模块提供的网络服务包括前端服务与后端服务,前端服务提供网站页面的动态显示、交互等功能;后端服务用于实现业务的逻辑处理、数据库访问等。
3 深度学习图像识别模块的功能实现
深度学习图像识别模块主要用于实现图像分类功能,通过对图像中指定目标特征的提取、识别,达到对图像分类的目的。其实现过程主要包括三个步骤:
步骤一:数据集的划分,按照一定的规则将数据集随机划分为训练集与测试集。
步骤二:进行图像识别的深度学习模型训练,采用有监督学习方式,对带有标识的数据集进行前向学习和反向优化,以达到最佳的分类效果。
步骤三:对训练好的模型进行测试,以评估模型的可靠性。
数据集的划分,训练集与测试集的划分应遵循两个原则,一是尽可能位于同一分布区内,二是数据量的比例应设置恰当,通常情况下训练集所需数据量相对较大。数据集划分核心代码示例如下:
random.shuffle(x)
set_split(src_folder,target_folder,
train_box=0.7,test_box=0.3,x)
random.shuffle方法用于打散数据集x的区域分布,使得数据集的区域分布更加均匀,set_split方法用于实现数据集的划分,src_folder参数指向源数据的存放路径;target_folder参数指向数据存储的目的路径;train_box为训练集的划分比例,设置为70%;test_box为测试集的划分比例,设置为30%。
图像识别模型训练,模型训练流程如图2所示。
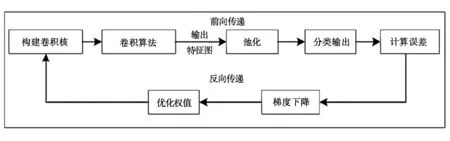
图2 图像识别深度学习模型训练
前向传递,是指将带有标识的数据集通过前向传递,输入卷积神经网络模型进行图像分类结果的预测,具体的实现过程包括:
构建卷积核,利用卷积算法对图像特征进行卷积并输出特征图,卷积公式如下所示:
(1)
Wout、Hout分别表示输出特征图的宽度与高度,Wput、Hput表示输入原图的宽度与高度,Wfil、Hfil表示卷积核的宽度与高度,P表示卷积核的填充圈数,S是卷积核每次滑动的步长。
池化,采用了最大值池化法,将卷积核区域内最大的特征值做为局部池化的输出结果,通过该方法可以快速剔除小权值的特征参数,仅保留主要特征,运行效率较高。
分类输出,采用了Softmax分类器对图像特征进行分类预测,Softmax函数的每个输出结果都映射在[0,1]的区间内,所有输出总和为1,该方法以概率的方式反映图像特征的分类结果,更加直观。
误差计算,是通过损失函数来评价模型的预测结果与实际结果的误差,误差越大,结果的准确性就越差。
反向传播,是针对损失函数逐层反向计算偏导数的一个过程,其目的是通过偏导数的计算逐层优化特征权重,以尽可能减小模型的计算误差,从而使其达到最佳。
梯度下降、优化权值,梯度下降算法主要用于计算凸函数的偏导数,而损失函数就是一个凸函数。计算出偏导数后,利用偏导数更新权值的公式如下所示:
W’=w-r*dw.
(2)
W’表示最新的权值,w为上一次更新后的权值,d为偏导数,r表示学习率。其中r的值越大,梯度下降的跨度也就越大,容易出现过拟合现象。
测试模型,进行可靠性评估,模型训练好之后,就需要借助测试集对模型进行检测了。测试过程与训练过程类似,最后仍需通过损失函数进行结果的评估,损失函数值越大,则模型的可靠性也越差。
4 结语
本研究针对深度学习、卷积神经网络、图像识别等技术进行了深入研究,提出了深度学习在图像识别系统中应用的解决方案,以实现图像分类的智能化处理为主要目的,利用卷积神经网络构建了分类模型,并通过训练集的前向学习与反向传导对模型进行了权值优化,通过测试集对模型的可靠性进行评估,为相关领域研究提供了实践参考经验。
