基于联合损失函数的语音质量特征增强分析
2024-03-05杨玲玲
杨玲玲
(河南工业贸易职业学院 信息工程学院,河南 郑州 450064)
0 引言
DNN用作一种具备优异非线性映射性能的高效算法,目前已被大量应用于语音增强信号处理领域,但该方法在实际应用过程中依然还有部分缺陷未被克服。例如,深度神经网络是以全连接的方式在不同层网络间建立联系,要求后层神经网络中各神经元节点与上层神经元之间都保持相互连接[1-2]。同时,深度神经网络通常选择拓展语音上下帧模式进行语音时序特征学习,导致模型运算量以及训练时间都明显增加。考虑到卷积神经网络(CNN)可以实现局部连接结构并完成权值共享功能,只需网络模型进行小规模数据计算,从而快速完成训练过程[3]。此外,还可以利用卷积神经网络直接分析二维平面数据,包含噪声信号的时频图也属于一种二维平面结构,可根据时间、频率参数来提取获得特征指标,由此实现语音信息的综合分析[4]。在优化神经网络模型的时候,大部分学者都是以均方误差损失函数(MSE)建立代价函数,而MSE算法较简单,只通过含噪语音与纯净语音误差开展计算,并未加入人耳听觉特征[5-8]。
根据上述研究结果,本文优化了以语音增强实现的网络模型与损失函数。为确保代价函数能够根据人耳感知特点开展分析过程,在上述基础上设计了一种联合损失函数。针对损失函数计算过程加入关于人耳听觉的数据。
1 联合损失函数
采用频域加权分段的信噪分析方法可以对语音可懂度进行预测。以下为频域加权分段信噪比表达式:

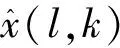
当前大部分均方误差函数只对增强语音与纯净语音幅度谱进行简单处理,未加入人类听觉感知的因素。因此本文为MSE计算过程设置了能够对人耳听觉感知效果进行评价的权重系数,设计了一种根据感知相关代价函数(MSE),得到下述计算式:
式中,M为模型训练Mini-batch;L表示帧数;W(l,k)感知权重因子选择包含语音相位差自适应软掩模。
2 基于联合损失函数的语音增强算法
以联合损失函数建立语音增强算法经多次重复训练后,能够从含噪语音幅度谱内获得估计增强语音幅度谱。图1给出了系统框图的示意结构。
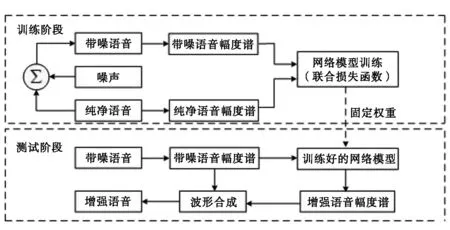
图1 语音增强算法系统框图
以联合损失函数建立的语音增强算法在训练过程中,先对含噪语音与纯净语音开展逐帧短时傅里叶转换,依次获得各自幅度谱(Amplitude)数据。以含噪语音幅度谱作为输入,再以纯净语音幅度谱作为学习对象。本文选择联合损失函数对两者差异进行评价,记录最优性能的网络模型参数。
3 实验结果分析
3.1 实验数据的选取
为验证本文设计的改进算法具备可行性,本次分别测试了200条单纯语音信号与三类噪声信号。以上语音数据都是由IEEE语音数据库提供,之后从NOISEX-92噪声库内提取Pink、Factory与White三种噪声信号,这些信号保持一致频率。总共选择150条单纯语音并将噪声前半段按照设定信噪比进行混合后再对模型开展训练,依次设定信噪比为-5 dB、0 dB、5 dB。
本文设定语音频率为16kHz,并以语音幅度谱作为输入语音特征。各项网络参数见表1。
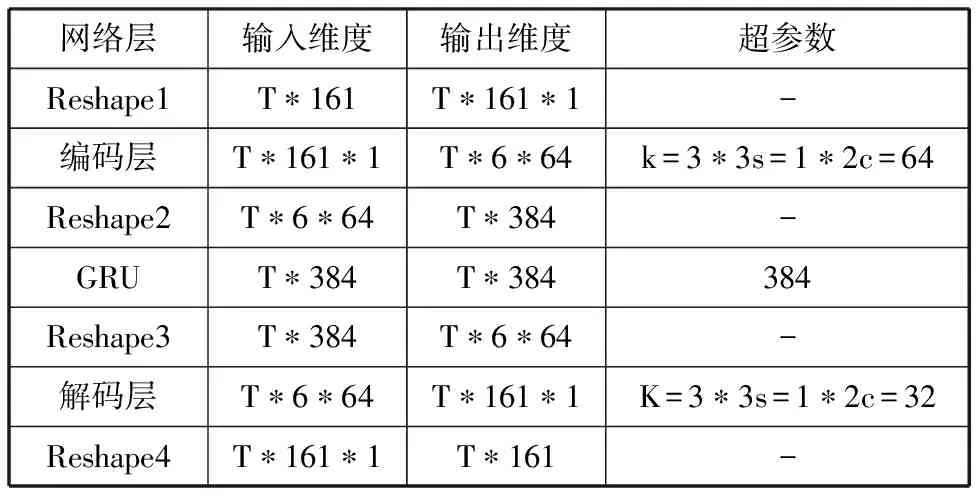
表1 网络模型参数
3.2 对比实验分析
为了对本文建立的联合损失函数与自注意力机制进行有效性验证,构建得到表2的对比算法。

表2 对比算法内容及其编号
图2给出了各个信噪比下以不同算法处理获得的增强语音PESQ值。其中,具体处理过程为先通过联合损失函数开展神经网络训练,再通过自注意力机制对语音特征PESQ值进行优化。对比算法1、2、3发现,综合运用联合损失函数并融合注意力机制后,可以使神经网络获得更优质量增强语音。
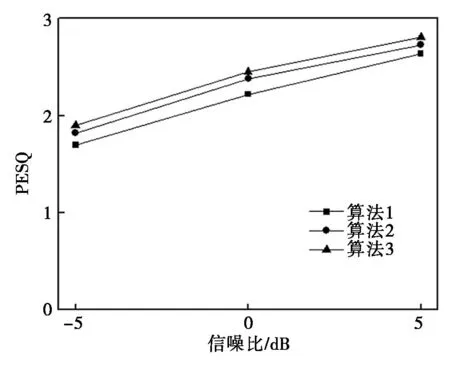
图2 不同信噪比下增强语音的PESQ平均值
以单特征构建的增强语音语谱图存在失真的情况,以混合特征进行处理时,则可以对高低频频谱性能起到优化效果。选择融合相位自适应软掩模方式时,能够最大程度去除背景噪声,并且当语音噪声被去除之后还能够保持明确谐波结构,表明本文算法满足有效性要求。
图3是三种算法针对每种信噪比进行处理获得的增强语音STOI值。对图3进行分析可知,算法3与2都比算法1获得了更高STOI值。同时可以看到,算法2在所有信噪比下都获得了比算法1更高的STOI值,因此可以推断联合损失函数相对MSE更适合神经网络的训练需求,产生该结果的原因在于联合损失函数包含了关于人耳感知方面的权重系数,有助于获得更优增强语音性能。对比算法2与3可以发现,设置自注意力机制能够进一步提升增强语音STOI,表明自注意力机制有助于更高效提取出重要语音特征,利用注意力机制提取特征参数以及结合联合损失函数进行神经网络优化能够促进增强语音质量的提升并达到更高可懂度。
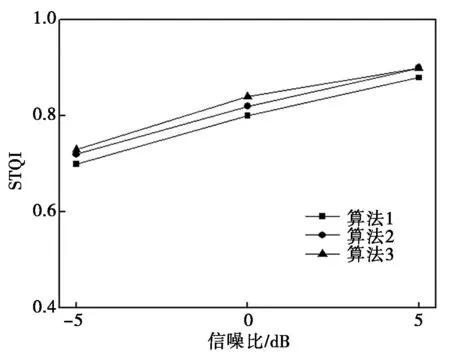
图3 不同信噪比下增强语音的STOI平均值
为深入探讨联合损失函数与自注意力机制,按照图4方法确定信噪比0 dB并以Factory作为背景噪声时建立的语谱图,以此判断两者有效性。

图4 0 dB、Factory噪声下增强语音语谱图对比
图4是在以上语音条件下建立的语谱图,可以看到,以常规损失函数MES进行处理时,增强语音发生了明显失真,这是由于MSE未加入人耳听觉信息的特征。以联合损失函数进行处理时,可以明显降低增强语音失真程度,获得更优的语音质量。同时运用将联合损失函数与自注意力机制的条件下建立神经网络模型时,形成了更清晰的语音频谱,也有助于完整保留语音信号成分,此外也减弱了语音失真的情况。
4 结语
1) 本文设计的混合损失函数实现增强语音质量的明显优化。加入注意力机制后能够促进背景噪音的进一步减弱,从而获得更高可懂度。
2) 以常规损失函数MES进行处理时,增强语音发生了明显失真;以联合损失函数进行处理时,可以明显降低增强语音失真程度,获得更优的语音质量。
