联合循环发电站电力输出预测
2024-03-05陈代俊陈里里李阳涛
陈代俊,陈里里,李阳涛
(重庆交通大学机电与车辆工程学院,重庆市 南岸区 400074)
0 引言
联合循环发电是一种将燃气轮机、蒸汽涡轮机和热回收蒸汽发生器组合起来的发电方式,其具有热效率高、污染低、自动化程度高等特点,联合循环发电站已在我国多个地区建成并投入使用[1-4]。为了提高发电效率,保证电力系统能够安全可靠地运行,研究如何有效利用相关影响因素来预测发电站满负荷电力输出具有十分重要的意义。
目前,有大量的学者采用机器学习的方法对发电站的电力输出进行建模预测,但存在未充分挖掘特征信息或模型简单导致的精度不高等问题。文献[5]采用主成分分析(principle component analysis,KPCA)方法降低气象因素维度,提取互不相关的综合性评价指标,通过主成分分析法提取的特征建立多元线性回归模型。文献[6]采用线性回归算法分析了各特征之间的相关性以及特征与发电量之间的相关性。文献[7]采用模糊C均值聚类算法生成新的样本,并构建支持向量机模型对发电量进行预测。文献[8]利用与日发电量具有高相似度的历史数据构建支持向量机模型对发电量进行预测。文献[9]提出了基于深度信念网络的短期发电量预测方法,并对真实的相关特征及历史发电量进行了预测算例分析。文献[10]基于改进神经网络和能量守恒法的计算方法,利用遗传算法优化相关参数,构建了发电量预测模型。文献[11]采用K均值聚类算法对历史数据进行聚类,并以逆向传播(back propagation,BP)神经网络为基础,引入小波分析构建小波神经网络,同时利用遗传算法对网络参数进行寻优,并以此构建了光伏电站发电量预测模型。文献[12]采用多个神经网络提取特征并进行特征融合以实现超短期风电功率预测。
本文针对上述方法未充分挖掘环境温度、环境压力和环境相对湿度等对电力输出的影响以及电力输出预测误差大等问题,采用核主成分分析算法(kernel principle component analysis,KPCA)与极端梯度提升(extreme gradient boosting,XGBoost)算法特征重要性评分,充分分析各相关特征对电力输出的单一和交叉影响,以XGBoost算法作为回归模型对电力输出进行预测。通过某联合循环发电站收集的实际数据进行实验,并与其他方法进行对比,验证了本文所提方法的有效性。
1 核主成分分析
1.1 核主成分分析原理
KPCA算法主要是在主成分分析算法的基础上加入核函数,能够从数据集中挖掘出隐含的非线性特征间的非线性信息[13]。KPCA算法是采用核函数的方法将数据映射到高维特征空间中[14-15],从而有效地提取到低维空间中几乎无法表达的非线性特征。
设n个m维数据样本,建立数据样本矩阵X’n×m,归一化后得到样本矩阵Xn×m。使用函数φ将样本映射至高维特征空间RF,映射值为ϕ(x1),ϕ(x2),…,ϕ(xn),并使用PCA算法得到协方差矩阵为
其特征方程为
式中:λ为协方差矩阵的特征值;v为特征向量。
由式(1)、(2)可得
式中αi=通常映射φ并不是显式的,对于v的计算比较困难,因此引入核函数:
对于式(2),任意的k=1,2,…,n,则有
分别将式(1)、(3)与式(4)代入式(5)可得
式中:K为k对应的核矩阵,K=k(xi,xj);α=(α1,α2,…,αn)。通过式(6)求得特征值λ1≥λ2≥…λn及其对应特征向量α1,α2,…,αn。新样本φ(xj)映射后得第j(j=1,2,…,p)维坐标为
式中αi已经规范化,αji是αi的第j个分量,规范化满足:
1.2 核函数选择
具有核函数的KPCA算法能够充分挖掘出原始数据中的交叉信息[16-17]。由于线性核函数只能解决线性可分问题,多项式核不适用于大数量级的情况且有较多的参数需要选择,而径向基函数核(radial basis function,RBF)能有效解决这些问题[18-19],因此本文选择RBF作为KPCA的核函数。
RBF在计算过程中涉及到2个向量的欧式距离计算[17],本文采用的高斯核函数公式为
式中σ为可调参数,其作用是控制函数的作用范围。
通过将不同个数的特征输入KPCA,从而挖掘出多个组合特征。这些组合特征中,包含了绝大多数原始特征的有用信息,且去除了一部分噪声信息。从这些组合特征中选取出对预测标签具有较大影响因子的特征,能有效提高模型预测效果。
2 XGBoost算法原理
XGBoost算法是梯度提升树(gradient boosting decision tree,GBDT)的一种改进模型,其基学习器可以选择线性分类以及非线性的树模型。XGBoost在GBDT的目标函数上加上正则项,减少了过拟合的可能性且加快了收敛速度[20]。目标函数如下:
式中:yi表示真实值;表示预测值;L(yi,)表示损失函数;Ω(f)表示正则项;γ代表树进行分割的困难系数,用于控制树的生成;T表示每一个叶子节点的个数;l表示L2正则化项的系数。
XGBoost的损失函数可以根据泰勒公式二阶导数来对其进行展开,这样其目标函数就会拥有一个更快的收敛速度和更高的准确性[21]。此时目标函数为
式中:Ij∊{q(Xi)=j};hi表示损失函数的二阶导数;gi表示损失函数的一阶导数。XGBoost算法可以通过以下3种方式判断所有特征的重要性[22]:
1)基于权重的特征重要性,即在所有树中每一个特征被用来分裂数据的次数。
2)基于覆盖的特征重要性,即在所有树中每一个特征被用来分裂数据的次数,且统计有多少样本点通过这个分裂点。
3)基于增益的特征重要性,即计算每一个特征分裂时平均损失的减少量。
本文基于增益的XGBoost特征重要性与前向选择法提出了XGB-FS特征选择算法。该算法基于XGBoost特征选择重要性评分对所有特征进行排序,采用前向选择法依次将特征输入模型,采用训练集的平均绝对误差(mean absolute erro,MAE)作为评价指标,找到MAE值最小的最优特征子集。
3 基于KPCA-XGB-FS的电力输出预测
本文提出的基于KPCA-XGB-FS的联合发电站电力输出预测方法流程如下:首先,对原始样本的4个特征遍历2个、3个和4个依次组合,通过KPCA算法对各组合的特征进行非线性信息提取,共生成了11个特征;其次,对所有的特征进行对数变换,使其更加满足高斯分布;然后,基于XGB-FS特征选择算法从原始的4个特征和生成的11个特征中选择最优特征子集;最后,直接将最优特征子集输入XGBoost模型进行训练,构建联合循环发电站电力输出预测模型。在实际的应用场景中,输入模型的环境相关特征可通过当地气象局提前获取,从而对未来的电力输出进行预测。
本文实现电力输出预测的方法是基于机器学习中的回归算法。使用对燃气轮机和蒸汽涡轮机负载造成影响的相关特征进行一系列的特征信息提取,然后通过提取的新特征建立电力输出预测模型。具体方法的流程如图1所示。

图1 方法流程图Fig.1 Flow chart of method
4 实验与分析
4.1 实验数据
本文使用来自公开数据集网站UCI中的联合循环发电站数据集来验证所提方法的有效性。该循环发电站由2个燃气轮机、1个蒸汽涡轮机和2个双压热回收蒸汽发生器组成。燃气轮机能够产生电力并用它的废气余热产生蒸汽,再通过蒸汽涡轮机产生额外的电力。实验数据集由某联合循环发电站在674 d满载工作状态下采集的9 568个数据样本,输入特征是每小时从传感器接收的数据平均值,包括每小时平均环境温度(ambient temperature,AT)、平均大气压强(atmospheric pressure,AP)、平均相对湿度(relative humidity,RH)和平均废气气压(V),预测目标为燃气轮机和蒸汽涡轮机每小时净电力输出(electrical energy output,EP)。燃气轮机负载对AT、AP和RH敏感,蒸汽涡轮机负载对V敏感。各特征和EP的平均值、方差、最小值和最大值如表1所示,AT、V、AP、RH均为连续型数值变量。随机选取原始样本数量的70%(6 697例)作为训练集用以训练KPCAXGB-FS模型,剩余的30%(2 871例)样本作为测试集用以评价模型预测效果。
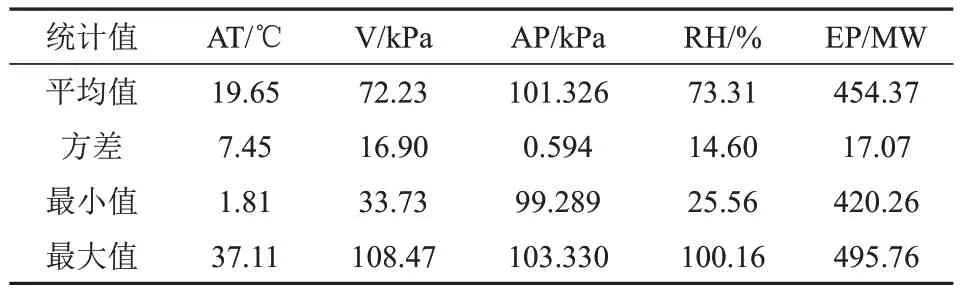
表1 各特征统计值Tab.1 Statistical values of each characteristic
4.2 评价指标
为了衡量所建立模型对测试集的预测效果,本文使用平均绝对误差(mean absolute error,MAE)、平均相对误差(mean relative error,MRE)、均方根误差(root mean squared error,RMSE)和平均绝对百分比误差(mean absolute percentage error,MAPE) 4个评价指标计算模型预测值与真实值的误差,从而对模型预测效果进行评估。4个评价指标分别表示如下:
式中:ŷi为模型预测值;yi为实际值;m为样本数。
4.3 基于KPCA的特征提取
对原始数据中的AT、V、AP、RH特征进行不同的组合,然后采用KPCA对各组合的特征进行非线性降维,每一个组合生成一列新的特征。如图2所示,从原始数据中使用11个不同特征的组合并基于KPCA提取11个融合了各特征信息的新特征。新特征融合了原有特征中重要的信息并且舍弃了原特征中的噪声影响。
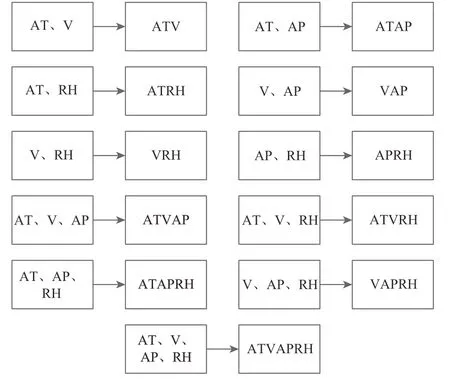
图2 KPCA特征提取结果Fig.2 KPCA feature extraction results
4.4 核心影响特征选择
将基于KPCA提取的11个新特征与原数据的4个特征通过XGBoost特征重要性评分得到每一个特征的重要性。如图3所示,ATVAP、ATVRH、ATV 3个特征都表现出比原始特征更高的特征重要性评分。因此,本文提出的特征提取方法能有效提取出比原数据更为有效的特征。基于FS算法按照特征重要性评分的排序,从一个特征开始依次增加特征个数,分别计算训练集不同特征个数下10倍交叉验证的MAE平均值。如图4所示,当特征个数为8时,训练集10倍交叉验证下的MAE值为2.422 4。MAE值越小,代表预测值与真实值之间的误差越小,因此,ATVAP、ATVRH、ATV、ATAP、VAP、AT、V、AP共8个特征为挑选的最优特征子集。

图3 特征重要性评分结果Fig.3 Feature importance score results

图4 XGB-FS特征选择结果Fig.4 XGB-FS feature selection results
4.5 不同方法效果比较
为了阐明本文所提出的特征提取方法以及特征选择方法的有效性,将本文的特征提取方法与未进行特征提取的方法及文献[23]进行比较。未进行特征提取的方法使用原始4个特征作为XGBoost的输入进行电力输出预测。文献[23]采用机器学习的Bagging方法并以MAE和RMSE作为评价指标获得了较优的预测效果。
本文提出的方法与其余方法均采用MAE、RMSE、MAPE、ME 作为评价指标,各方法性能对比如表2所示,其中本文方法具有最低的误差,MAE值为2.021,RMSE值为2.846,MAPE值为0.446%,ME值为-0.02。从表2各方法误差结果来看,本文提出的基于KPCA算法的特征提取方法能够有效提升模型预测效果,并且本文所提出的KPCA-XGB-FS方法较已有研究方法的MAE值和RMSE值分别降低了0.797和0.941。图5为模型前100个样本的预测值和真实值对比,通过图5中真实值与模型预测值的对比及表2中的ME值得出本文所提出模型预测值整体性小于真实值。
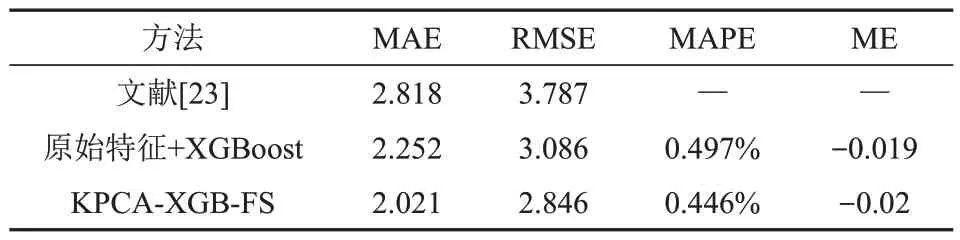
表2 各方法性能Tab.2 Performance of each method

图5 真实值与预测值对比Fig.5 Comparison of actual and predicted values
5 结论
采用KPCA算法对电力预测相关数据进行了非线性特征组合与提取,得到了更多的组合特征;采用XGB-FS特征选择方法筛选最佳特征子集并建立XGBoost联合循环发电站电力输出预测模型。所提方法能够充分挖掘发电相关数据中的线性与非线性信息,去除数据噪声,获得较好的预测效果。为这项研究提供数据集的联合循环发电站已经开始使用这种预测模型来预测第2天每小时的电力输出,预测计算时该联合循环发电站使用的是该州气象研究所给出的第2天的温度预报作为模型输入。所提出的方法也可以使用发电站当地第2天的温度预报作为模型输入进行电力输出预测。
在今后的工作中,将进一步研究如何更加精确地获取未来时间的环境变量以完善预测模型的输入,并对不同发电站更多的数据进一步研究。
