设备端基于深度学习的智能家居服务推荐框架
2024-03-05陈佳雯黄志明蔡泽卓陈星
陈佳雯 黄志明 蔡泽卓 陈星
收稿日期:2023-06-19;修回日期:2023-08-16 基金項目:国家自然科学基金资助项目(62072108);福建省自然科学基金杰青资助项目(2020J06014);福建省财政厅科研专项经费资助项目(83021094)
作者简介:陈佳雯(1998—),女,福建厦门人,硕士研究生,CCF会员,主要研究方向为软件自适应、知识图谱;黄志明(1994—),男,福建莆田人,硕士,主要研究方向为软件自适应、知识图谱;蔡泽卓(2002—),男,福建福州人,主要研究方向为计算机视觉;陈星(1985—),男(通信作者),福建福州人,教授,博导,博士,CCF杰出会员,主要研究方向为软件工程、服务计算、软件自适应(chenxing@fzu.edu.cn).
摘 要:随着智能家居的普及,用户期望通过自然语言指令实现智能设备的控制,并希望获得个性化的智能家居服务。然而,现有的挑战包括智能设备的互操作性和对用户环境的全面理解。针对上述问题,提出一个支持设备端用户智能家居服务推荐个性化的框架。首先,构建智能家居的运行时知识图谱,用于反映特定智能家居中的上下文信息,并生成用例场景语句;其次,利用预先收集的通用场景下,用户的自然语言指令和对应的用例场景语句训练出通用推荐模型;最后,用户在设备端以自然语言管理智能家居设备和服务,并通过反馈微调通用模型的权重得到个人模型。在基本指令集、复述集、场景指令集三个数据集上的实验表明,用户的个人模型相比于词嵌入方法的准确率提升了6.5%~30%,与Sentence-BERT模型相比准确率提升了2.4%~25%,验证了设备端基于深度学习的智能家居服务框架具有较高的服务推荐准确率,能够有效地管理智能家居设备和服务。
关键词:物联网; 知识图谱; 智能家居; 自然语言处理; 相似度计算
中图分类号:TP391.1 文献标志码:A
文章编号:1001-3695(2024)02-032-0533-07
doi:10.19734/j.issn.1001-3695.2023.06.0262
On-device deep learning for smart home service recommendation framework
Chen Jiawen1,2,3, Huang Zhiming1,2,3, Cai Zezhuo4, Chen Xing1,2,3
(1.College of Computer & Data Science, Fuzhou University, Fuzhou 350116, China; 2. Key Laboratory of Spatial Data Mining & Information Sharing, Ministry of Education, Fuzhou 350002, China; 3. Fujian Key Laboratory of Network Computing & Intelligent Information Processing (Fuzhou University), Fuzhou 350116, China; 4. School of Computer Science, Beijing Institute of Technology, Beijing 100081, China)
Abstract:As smart homes become more prevalent, users expect to control smart devices through natural language commands and desire personalized smart home services. However, existing challenges include the interoperability of smart devices and a comprehensive understanding of the user environment. To address these issues,this paper proposed a framework supporting personalized smart home service recommendations for device-end users. Firstly, it constructed a runtime knowledge graph to reflect contextual information in specific smart homes and generated scenario-based sentences. Secondly,it trained a general recommendation model using pre-collected natural language instructions and corresponding scenario-based sentence representations from users in common scenarios. Finally, users interacted with smart home devices and services through natural language on the device end while fine-tuning the weights of the general model through feedback to obtain a personal model. Experimental results on three datasets-basic instruction set, paraphrase set, and scenario instruction set show that the personal model achieves an accuracy improvement of 6.5% to 30% compared to word embedding methods and 2.4% to 25% compared to the Sentence-BERT model, which validates that the device-end deep learning-based smart home service framework has a high ser-vice recommendation accuracy and effectively manages smart home devices and services.
Key words:Internet of Things; knowledge graph; smart home; natural language processing; similarity calculation
0 引言
随着智能家居设备的不断普及,人类生活已经逐步进入到了以智能设备为主导的新时期。智能家居服务通过将房屋设施与物联网(IoT)技术相结合[1]来提高人们的生活质量。例如,方便老年人开关灯、方便年轻人做家务等。目前,一些大型智能设备制造商如苹果、华为、三星等,都致力于构建覆盖家庭生活各个方面的设备生态系统。它们推出了相应的平台,用于统一接入和管理该生态系中的设备。例如,苹果的Homekit[2]、华为的HiLink[3]和三星的Smart Home[4]等平台,为用户提供了集成和控制智能家居设备的解决方案。用户通过在智能手机上安装特定于平台的应用程序来获得对设备的控制权。这些应用程序通常提供单个设备的控制功能,并为协调多个设备的场景定义规则[5]。在被智能设备包围的生活空间中,用户通常需要个性化的智能家居服务[6]。他们可能需要获取设备的具体状态信息或直接对其进行控制,比如确认窗户是否已关闭。此外,他们还可以指定设备之间的协作规则,使智能设备能够在特定环境条件下执行相应操作[7]。例如,当楼道里的传感器探测到夜间有人经过时,自动打开浴室灯。个性化的智能家居场景可能会非常复杂,因此需要使用程序级的服务实现来支持设备的管理和协作[8]。此外,为了提供良好的用户体验,还需要提供简单易懂的交互方式。其中,自然语言指令是一种合理的解决方案,可用于管理智能家居设备和服务,使用户能够通过直接語言输入来控制和操作智能家居系统。
然而,智能家居服务的个性化支持仍面临着一些挑战,如智能设备的互操作性和对用户环境的全面理解。首先,不同品牌的设备需要通过各自的应用程序进行接入,其数据格式、通信协议和函数调用方法也存在差异。因此,在涉及跨品牌设备的场景中,设备之间的交互和协作变得相当困难。其次,个性化智能家居服务需要结合情境知识,以提供实时、灵活和有价值的服务。然而,现有的智能家居系统在抽象层面上缺乏全面的知识表示能力[9]。
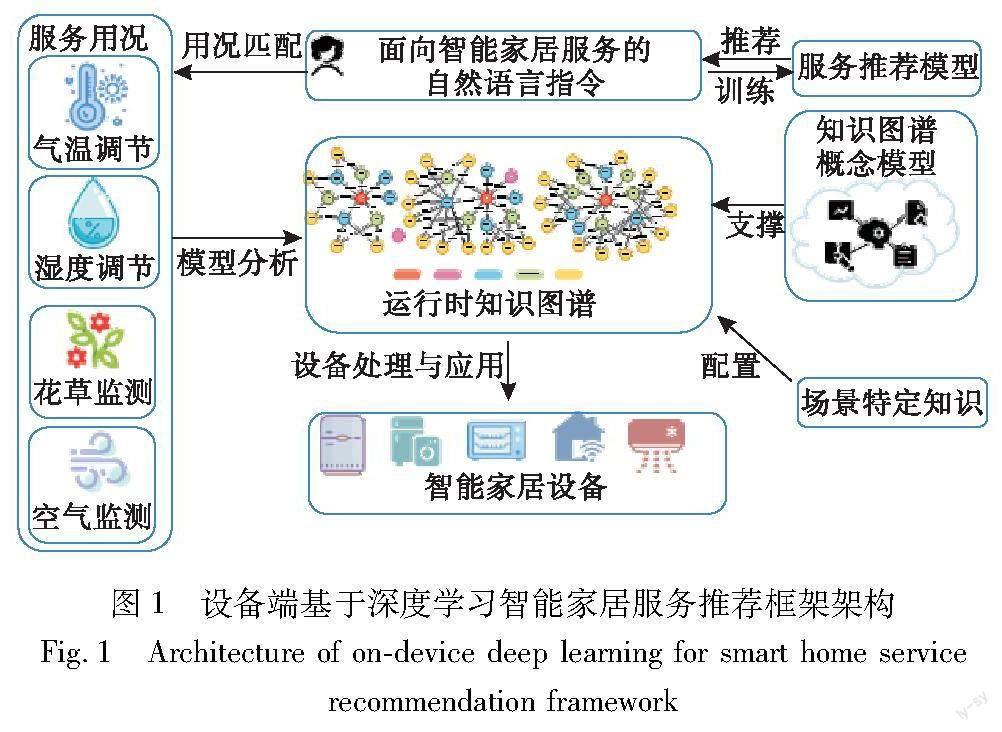
为了解决上述问题,本文提出了设备端基于深度学习的智能家居服务推荐框架。该框架首先支持终端用户的个性化智能家居服务,能够理解用户的自然语言指令,并将其转换为相应的智能家居服务,同时,它还能够实现跨品牌和多功能设备之间的协作。为此,引入了一个运行时知识图谱,作为指令与智能设备操作之间的桥梁。该知识图谱基于概念模型,反映了特定智能家居环境中的实时情景知识,包括设备状态、用户或植物位置等。它能够感知实时场景信息,并相应地更新到知识图谱中。框架还能够将语言指令映射到由知识图谱生成的场景用例,并最终由相应设备执行相应的服务。实验结果显示,本文框架在三个指令数据集上的测试结果超越了对比方法。
1 相关工作
1.1 Siamese LSTM模型
Siamese LSTM模型是一种基于孪生网络架构的文本相似度模型,它结合了长短期记忆(LSTM)神经网络和孪生网络的优势。Siamese LSTM(简称SLSTM)模型通过将两个输入句子分别输入到两个共享参数的LSTM网络中,从而获得两个句子的向量表示,这些向量表示可以用于计算句子之间的相似度或进行其他文本相关的任务。Mueller等人[10]提出了一种基于SLSTM模型的方法,用于学习句子之间的相似度,模型使用两个LSTM网络来编码输入句子,然后通过计算句子表示之间的距离来度量相似度。Neculoiu等人[11]提出了一种基于SLSTM模型的文本相似度学习方法,模型通过将句子映射为低维空间的向量表示,并使用余弦相似度度量句子之间的相似度,该方法在多个文本相似度任务上展现出了优越的性能。
SLSTM模型在文本相似度任务中被广泛应用。它们通过共享参数的LSTM网络来学习句子的向量表示,并利用这些表示来度量句子之间的相似度。这些方法的成功表明SLSTM模型在处理文本相似度问题上具有较强的表现力。
1.2 物联网服务推荐
智能家居是物联网的典型场景。目前已经有几项研究和解决方案来实现智能家居的互操作性。文献[12]提出一种通用数据服务中间件,实现了异构设备和协议在运行时的无缝集成,让用户可以灵活添加、管理和访问各种设备和协议。文献[13]提出了一个允许智能家居中异构设备协作通信的框架,通过集中式数据库服务器验证设备的真实性,并支持设备之间的互操作性,服务器提供远程访问控制和监视功能,通过加密规则协调和监控异构智能设备。虽然引入集成架构可以管理异构设备,但在特定场景下(如个性化的智能家居服务),仍然可能需要手动自定义IoT应用程序的管理逻辑。这是因为,每个智能家居系统都具有独特的需求和功能,无法完全依赖通用的集成架构来满足所有情况。
为了支持物联网应用的服务管理与逻辑开发,已经进行了一些专注于语义表示的研究。文献[14]提出了一种声明式方法,用于构建基于事件驱动的物联网服务系统,该方法明确将物理设备和系统建模为服务架构的核心组成部分。文献[15]提出了一种名为WITSCare的基于Web的智能家居系统,该系统通过整合基础环境服务,为用户提供直观的可视化界面,用户可以采用所见即所得的方式定义规则,并使用拖放操作来指定和管理复杂的规则。使用WITSCare进行个性化服务推荐需要用户付出很大的学习成本,因为用户需要理解如何使用系统的界面和功能来定义和管理规则,这可能对某些用户来说具有挑战性。
目前,智能家居系统普遍支持通过移动终端(如手机)进行操作,这已经成为一种趋势。移动终端的加入使得智能家居体验更加简单和快捷。在文献[16]中,Almond是唯一一个允许用户使用自然语言来指定触发动作命令的虚拟助手。Almond不仅可以控制智能设备,还可以创建自动化任务。它提出了一个开放式虚拟助手架构,并提供了一种获取训练数据的方法。后续工作中的Genie工具包[17]用于为新的虚拟助手训练语义解析器。Genie工具包可以减少人工工作量,处理新的复合命令。它要求开发人员定义适合其领域的技能和结构,并且无须机器学习专业知识即可获得自然语言界面。然而,在语料库有限的情况下,这些虚拟助手对用户的自然语言指令理解通常不够准确。
2 本文框架
图1为本文所提设备端基于深度学习的智能家居服务推荐框架总体架构。首先,根据真实的智能家居场景构建运行时的知识图谱,用于反映特定智能家居中的上下文信息,并根据用例场景指令生成规则得到用例场景指令。其次,利用预先收集的通用场景下用户的自然语言指令和对应的用例场景表示语句,训练一个基于SLSTM的智能家居服务推荐模型,即通用模型,在云端上为通用场景提供服务推荐,并将通用模型推送给单个设备。用户设备从云端获取通用模型,对通用模型权重进行增量训练微调,得到个人模型,其中每个用户在自己的设备上收集其自然语言指令和对通用模型推荐结果的反馈。最后,根据用户在不同场景下的指令,个人模型获得在当前场景下需执行的自然语言指令与用例场景表示语句的相似度,执行相似度最高的用例场景指令,在运行时,知识图谱中匹配与其相应的设备进行操作。 需要注意的是,个人训练阶段的微调意味着将通用模型根据用户对服务推荐结果的反馈进行多组增量训练,以适应用户在不同智能家居场景下的服务推荐。模型增量训练的好处是用户的隐私不会被泄露,即每个用户得到的个人模型是依据用户习惯得到的,并且是独有的。
2.1 运行时知识图谱
智能家居情境感知运行时知识图谱是先前的工作[18],本节对运行时知识图谱的核心概念进行介绍。图2中展示了运行时知识图谱的概念模型,用于智能家居个性化方案。该模型定义了涉及的概念以及它们之间的相互关系。核心概念包括 位置(location)、上下文(context)、设备(device)、服务(service)和用户(user),在图中以方框表示,定義如下:
a)location是指智能家居中的某块区域,定义为元组〈LName〉。
b)context是指可以在智能家居中感知到的特定环境类型,如亮度、温度等。它被定义为一个三元组〈CType,LName,CValue〉,其中CType表示环境的类型,LName表示感知的地点,CValue表示当前的环境值。
c)device是指智能家居系统中的设备,每个设备由一个元组〈DName,LName,State,{Key1,Key2,…,Keyn}〉表示。其中,DName表示设备的名称,LName表示设备所部署的区域,State表示设备的当前状态,{Key1,Key2,…,Keyn}是一个数组,表示设备可以改变或监控的环境类型。
d)service是指设备提供的操作或功能,通过这些服务可以操纵设备并改变环境。服务被定义为一个元组〈DName,LName,CType,Effect,State,SValue〉。其中:DName表示提供该服务的设备名称;LName表示服务生效的区域;CType表示服务影响的环境类型;Effect表示应用服务时环境的影响类型,包括监控、升高和设值;State表示服务的启用状态;SValue记录了由服务监视的值。
e)user是指智能家居系统的使用者,包括真人用户和家庭盆栽等。本文使用元组〈UName,LName〉来表示用户的名称和当前所处位置。
概念模型定义了概念之间的关系,这些关系在图2中显示为带有文本标签的有向虚线。
a)located in(Xlocated inL)为位于关系,其中X可以是设备、服务、用户以及环境,分别代表设备部署地点、服务作用地点、用户所在地点以及当前环境。
b)sence(UsenseC)为用户到环境的关系,它表示用户所敏感的环境信息。
c)provide(DprovideS)为设备到服务的关系,表示智能设备可以提供的智能家居服务。
d)monitor(SmonitorC),increase(SincreaseC),reduce(SreduceC)和assign(SassignC)为服务到环境的关系,它们表示服务对环境的不同影响类型。其中,monitor表示监控环境的状态值;increase和reduce表示增加或减少的环境值;assign是指为当前环境设置某个特定值。
为了实现运行时知识图谱与真实智能家居场景之间的双向同步,本文采用了运行时软件架构模型[18,19]来构建知识图的运行时模型。该模型在模型级别操作设备,并通过映射操作在运行时获取与情境知识相关的属性值,而非提前分配。因此,由于情境上下文的变化,运行时知识图谱可能会发展演进。个性化智能家居服务可以通过在运行时知识图谱上执行模型操作来实现。
2.2 用例场景指令生成
根据用例场景,本文定义了服务推荐模型指令,并将其分为两类基于功能的自然语言指令:
a)环境控制指令:这类指令旨在通过更改知识图谱中设备或服务的属性值来控制当前场景的环境状态。例如,“Open the air conditioner in the sitting room.”和“Increase the brightness of sitting room.”是属于此类的用例场景指令。
b)定量查询指令:属于该类别的指令旨在通过在运行时知识图谱中检索设备或环境实例的相应属性来获取设备或环境的状态。例如指令“What is the brightness of the smart light?”用于获取智能灯设定的亮度值,指令“What is the PM 2.5 of the living room?”则通过调用能够监测客厅PM2.5值的设备的监测功能来查询客厅的PM2.5数值。
因此,可以预先从运行时知识图谱中生成所有可能的场景指令作为用例场景指令用于模型的推荐执行指令。表1提供了用例场景指令生成规则的示例。每一行表示一个生成方案,该方案利用知识图谱中的抽象对象转换为具体的用例场景指令。例如,当将设备“air conditioner”设置为“开”,并且用例场景是“sitting room”时,可以生成指令“Turn on the air conditioner in the sitting room.”。该示例说明了如何根据知识图谱中的信息将抽象概念转换为具体的用例场景指令。
2.3 服务推荐模型
本文模型如图3所示,服务推荐模型分为两个部分。第一部分为embedding层和输入层,输入层读取embedding层处理的自然语言指令作为输入,以产生学习的语义表示向量。第二部分为SLSTM和全连接层,分为LSTMa和LSTMb两个神经网络,由于Siamese神经网络的特性,LSTMa和LSTMb的权重是共享的。
对于用户的自然语言指令和用例场景的自然语言指令中的每个单词,获取其词向量。本文使用预训练din维(本文中din=300)的GloVe[20]来表示词向量,因为GloVe綜合了语料库的全局统计特征和局部的上下文特征,局统计特征帮助捕捉单词的整体语义信息,而局部上下文特征揭示了单词与其周围环境的关系,从而有助于准确识别相似的单词。
在SLSTM层中,LSTM学习从din维向量的可变长度序列的空间到Rdrep(本文中drep=50)的映射。具体来说,用户自然语言指令(表示为句向量序列)x1,x2,…,xn 被传递到LSTM。对于每个t∈{1,…,T},LSTM执行对隐藏状态向量ht的更新的计算公式为
ht=sigmoid(Wxt+Uht-1)(1)
LSTM顺序地更新隐藏状态表示,但是这些步骤也依赖于包含四个分量的存储器单元,即存储器状态ct,确定存储器状态如何影响其他单元的输出门ot,以及基于每个新输入和当前状态控制存储在存储器中(和从存储器中省略)的内容的输入和遗忘门it、ft。下面是在由权重矩阵Wi、Wf、Wc、Wo、Ui、Uf、Uc、Uo和偏置向量Bi、Bf、Bc、Bo参数化的LSTM中的每个t∈{1,…,T}处执行的更新,通过式(2)~(7)在每个序列索引处更新其隐藏状态。
it=sigmoid(Wixt+Uiht-1+bi)(2)
ft=sigmoid(Wfxt+Ufht-1+bf)(3)
t=tanh(Wcxt+Ucht-1+bc)(4)
ct=it⊙t+ft⊙ct-1(5)
ot=sigmoid(Woxt+Uoht-1+bo)(6)
ht=ot⊙tanh(ct)(7)
句子的最终表示由hT∈Rdrep(模型的最后隐藏状态)编码。对于给定的句子对,将预定义的相似度函数g:Rdrep×Rdrep→R应用于LSTM的表示。随后使用表示空间中的相似性来推断句子的潜在语义相似性。需要注意的是,在训练期间,反向传播的唯一误差信号源于语句长度为n、m的用户自然语言指令din子表示x(a)n和用例场景自然语言指令句子表示x(b)m之间的相似性,以及该预测的相似性如何偏离人类注释的基本事实相关性。本文使用的相似性函数为余弦函数,其计算公式为
cos(x(a)n,x(b)m)=∑ni=1∑mj=1x(a)i×x(b)j∑ni=1(x(a)i)2×∑mi=1(x(b)i)2(8)
2.4 用例场景指令的匹配
在用户指令匹配方面,可以将其分为原始指令匹配和复合指令匹配两种情况。对于原始指令匹配,也就是指令的操作仅包括环境控制、定量查询的场景用例指令,例如:“turn on the air conditioner in the sitting room.”,这类指令可以直接进行指令匹配。而对于复合指令匹配,这类指令通常包含if子句的自然语言表达,例如:“if the temperature in the sitting room is above 20, open the air conditioner in the sitting room.”,在处理复合指令时,需要将复合指令分解为两个简单指令句,即“if the temperature in the sitting room is above 20”和“open the air conditio-ner in the sitting room”,针对每个分句进行独立匹配,计算其与用例场景指令的相似度得分。然后,基于两个分句的相似度分数来计算总体相似度,以确定与用户指令最匹配的执行指令。另外,本文认为用户自然语言指令对位置非常敏感。当用户的指令中没有明确包含位置信息时,他们通常期望系统调用所在区域内设备的相关服务。因此在这种情况下,需要在用户的指令中附加获取到的用户位置信息,以确保系统能够正确理解和执行用户的意图。
以一个例子来说明用户指令的匹配过程。假设用户自然语言指令是“turn up the brightness.”。为了提高匹配相似度,首先需要改进指令,附加位置信息。例如,如果用户当前位于客厅(sitting room),则该句子可以被修改为“turn up the brightness in the sitting room.”。然后将用户指令和2.2节生成的用例场景指令的句子对输入个人模型,根据个人模型返回的推荐结果,列出了前5个相似度最高的指令,如表2所示。
第一个结果以0.986 32的相似性值对其他结果进行优先排序。基本的模型指令是“Increase the Servicei.CType of Servicei.LName.”,其中Servicei.CType是“brightness”,Servicei.LName是“sitting room”。根据运行时知识图谱,推导出智能灯来支持指令。然后,基于运行时知识图谱执行针对设备的模型指令,以实现智能家居服务的个性化。
3 实验与结果分析
3.1 场景设置
为了验证实验结果,本文使用的智能家居场景如图4所示。该场景包括客厅、卧室和阳台三个区域,每个区域都布置了智能设备用于调控环境。场景包括温度、湿度、亮度和PM 2.5四种类型的上下文。智能设备针对不同场景提供monitor、increase、reduce和assign等服务。每个区域中的各种智能设备主要是针对当前环境的亮度、温度、湿度以及空气质量进行检测和改变。例如,空调可以监控、增加、减少或分配温度;空气净化器可以提供降低PM2.5的服务。
基于上述智能家居场景实例,本文创建了3个location实例(Ll)、12个context实例(Cl_m,其中l是位置的序列号)、11个device实例(Dd)和29个service实例(Sd_n,其中d是设备的序列号)。还创建了两个用户实例Alice和Ken(U1和U2)。基于智能设备部署的基本知识,该运行时知识图谱建立了54个located in、29个provide、9个monitor、8个increase、5个reduce和7个assign关系。sense关系由用户的实际位置决定,如图5所示。
3.2 实验设置
本文使用SLSTM模型来实现服务推荐,即通用模型和个人模型。在通用模型的训练中设置一个监督学习,其中每个训练示例由用户自然语言指令x(a)n和用例场景指令x(b)m组成的句子对及该句子对的相似度大小y组成,且用户自然语言指令和用例场景指令的句子长度可以是不同的。通过计算句子的平均词向量获得句向量,对句向量求余弦距离获得其在向量空间中的语义距离,即标签y。
服务推荐模型由输入层、embedding层、SLSTM层、全连接层、隐藏层、输出层六部分组成。embedding层的输入为自然语言指令,并根据Wiki百科预训练得出的300维GloVe词向量将自然语言指令表示为句向量。SLSTM层参数的优化使用Adam方法以及梯度裁剪(重标范数超过阈值的梯度)来避免梯度爆炸问题。将数据集随机均匀划分成训练集和测试集,其中训练集占数据集75%,测试集占25%。在训练过程中,使用了批量大小为32的小批量随机梯度下降。为了防止过度拟合,本文采用了提前停止策略和耐心值为5的设置。具体来说,其监测模型在验证集上的性能,并在连续5个epoch中没有改善时,提前停止训练。整个训练过程最多进行50个epoch。为了评估服务推荐模型的性能,并选择最佳模型,本文使用了均方根误差(root mean square error,RMSE)和平均绝对误差(mean absolute error,MAE)作为指标。这些指标对模型的预测结果与实际值之间的误差进行衡量。通过比较不同模型的误差指标,可以选择表现最佳的模型作为最终的服务推荐模型。
在设备端对通用模型进行微调的过程中,首先用户通过向通用模型发送指令,得到服务推荐结果。如果相似度最高的推荐指令与用户指令不匹配,用户可以从推荐结果中选择正确的用例场景指令。然后,将用户指令和用例场景指令作为句子对输入。接下来,在监督学习阶段,将正确匹配的用例场景指令的监督学习量y设置为1,表示为正样本。其他未匹配的用例场景指令的监督学习量y降低5%,表示为负样本,以减少它们对增量训练的影响。随后,使用这些句子对和相应的监督学习量y对通用模型进行增量训练,以获得个人模型,该模型适应用户的个性化需求。为了评估增量训练效果和模型稳定性,可以进行隨机实验检测。在每组实验中,使用相同的通用模型进行10次增量训练。通过这个过程,用户可以不断优化通用模型,获得更符合个人需求的个人模型。
3.3 实验数据
由于用户隐私等问题,真实的实验数据集较难获取,所以,本文中用户自然语言指令使用基本指令集、复述指令集和场景指令集三个数据集。这些数据集由志愿者参与并提供指令语句而形成,总共收集了2 104个指令语句,其中1 424个是原始指令语句,680个是复合指令语句。
基本指令集提供了智能家居服务的基本功能,这些提供基本功能的指令可以帮助用户完成各种设备的基本控制。基本指令集中总共生成了200条指令,其中包括121条原始指令语句和79条复合指令语句。
复述集主要是用于增加智能家居服务指令的多样性,以便在现实情况下尽可能模拟用户对智能家居设备的使用情况。因此,邀请了几位熟悉智能家居设备和智能家居服务的同学在指定的智能家居场景下,根据对应的智能家居设备及服务提出自己认为合适的指令语句。最终,共收集了1 057条指令,其中有714条是原始指令,343条是复合指令。
场景指令集是由对智能家居场景中各种智能设备和智能家居服务不熟悉的同学提供的。这些同学仅根据对智能家居场景的简要介绍,给出了他们认为合适的指令语句。在这个数据集中,共有1 047条指令,其中包括710条原始指令和337条复合指令。尽管缺乏具体设备和服务的知识,但这些同学的贡献提供了一种多样化的用户自然语言指令视角。他们从自己的角度出发,根据对场景的理解和想象力,提供了独特而有价值的指令语句。
3.4 实验评价标准
本文根据指令推荐结果采用了top-k准确率作为评价指标,其中k的取值为1、3和5,用来衡量推荐结果的准确性。此外,还通过比较通用模型增量训练后得到的个人模型与原始通用模型在均方根误差和平均绝对误差上的大小,来验证个人模型的性能。RMSE和MAE的计算如式(9)(10)所示。通过这些评价标准,可以对不同方法的服务推荐效果进行客观的比较和分析。top-k准确率能够反映推荐结果的精确程度,而RMSE和MAE则用于衡量个人模型相对于通用模型的预测误差大小。
MAE=1n∑na=1pia-ria(9)
RMSE=1n∑pia-ria2(10)
其中:n为用户i进行评分的对象个数;pia和ria分别为推荐模型预测分值和实际分值。平均绝对误差和均方根误差的数值越小,说明推荐模型的性能越好。
3.5 实验结果分析
3.5.1 基线方法
为了验证本文方法的指令匹配的性能,将本文方法与基于词嵌入的方法[18]和Sentence-BERT[21]这两个基线方法进行比较。
基于词嵌入的方法利用词向量技术将句子转换为数值化表示。该方法使用预训练的word2vec模型,在大规模训练语料上对每个词汇生成分布式表示的词向量。对于每个句子,可以将其表示为所有词向量的和的平均值。通过这种方式,每个用户指令和用例场景指令都能够被转换为具有相同维度的词向量表示。通过比较用户指令的词向量表示与不同执行指令的词向量表示的余弦相似度,可以找到与用户指令语义最接近的执行指令。
Sentence-BERT(SBERT)是一种基于BERT(bidirectional encoder representations from transformers)模型的句子级别的嵌入模型。SBERT使用预训练的BERT模型进行句子级别的特征提取。与传统的BERT模型只关注下一句预测任务不同,SBERT通过修改损失函数,在训练过程中强制要求具有相同语义的句子在嵌入空间中更加接近。具体而言,SBERT采用了Siamese网络结构,其中两个共享参数的BERT模型分别编码两个句子。然后,通过计算两个句子的嵌入向量之间的余弦相似度,可以衡量它们之间的语义相似性。
3.5.2 对比实验
个人模型是通过对相同的通用模型进行增量训练和微调权重得到的。增量训练的实验步骤如下:从用户输入中选取了五组不同的指令集作为样本,使用了五组指令集作为增量训练数据对同一个通用模型进行了增量训练。通过这种方式,能够对模型在不同情景下的性能表现进行准确且全面的评估。因此,五组实验得到的个人模型的RMSE和MAE值是不同的,这是正常的。在图6和7中,总共有五条线代表着五组实验得到的模型性能。可以观察到,随着对通用模型进行增量训练的次数增加,个人模型的RMSE和MAE呈现出逐渐下降的趋势。这意味着随着用户对个人模型的使用,预测准确性也越来越高。这说明通过增量训练,通用模型转换为个人模型可以更好地满足用户的需求。因此,采用五组实验得到的个人模型对复述集和场景指令集做完匹配后,最终需要对top1/top3/top5的准确率进行统计,然后求出平均值,得到个人模型的最终性能。
在实验中对比本文方法、基于词嵌入的方法和Sentence-BERT三种方法的top-k准确率结果。
首先,对比本文方法与词嵌入方法。SLSTM与词嵌入方法不同之处在于SLSTM能够将整个句子作为输入,可以捕捉到句子中的上下文信息并学习到句子的表示。相比之下,word2vec模型主要关注词汇级别的语义表示,因此传统的词嵌入方法在求取句子向量时通常采用平均操作,这种简单的处理方式可能忽略了一些关键词对于整个句子语义的重要影响,从而导致句子表示的准确性有所降低。
其次,本文方法与SBERT模型的主要区别在于,SLSTM模型能够考虑句子中的上下文信息并捕捉长期依赖关系,通过LSTM结构实现这一目标。此外,SLSTM模型采用带有标签的句子对数据进行监督学习,通过比较相似和不相似的句子对来训练模型。这使得模型训练更高效准确。另外,SLSTM模型专门优化了智能家居场景,可以根据该领域的特定需求和上下文提供更精准的推荐和指令匹配。与之相反,SBERT模型通过预训练,在大规模语料上学习通用的句子表示。然而,由于其通用性,SBERT模型無法针对智能家居场景进行优化,并且无法根据用户反馈微调模型以提高准确率。
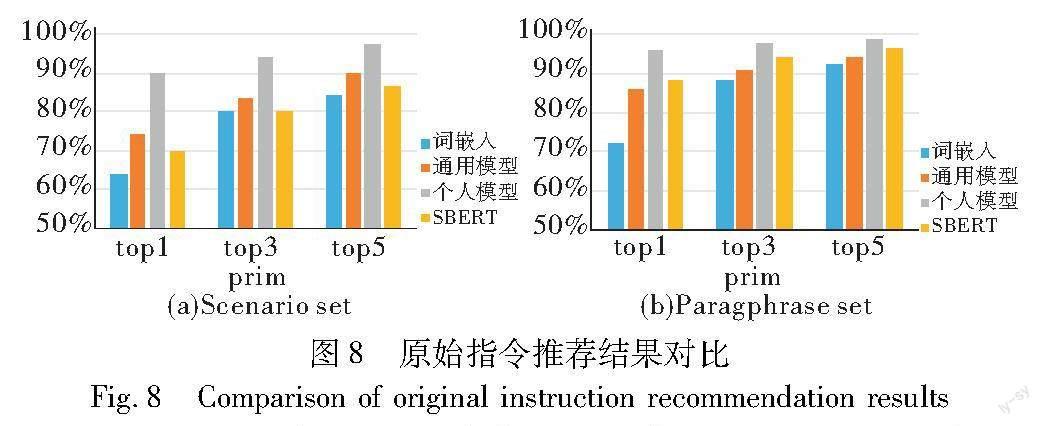
由于三种方法在基本集中的指令匹配方面都表现出100%的准确性,所以在图中未显示具体结果。这种完全匹配的原因在于基本集的指令词汇量是有限的。因此,无论哪种方法,都能够准确识别指令中的单词,并将其正确映射到相应的用例场景指令中。
图8为三种方法对原始指令推荐结果的对比。相比之下,通用模型的准确率比词嵌入的方法提升了3.3%~14%,个人模型的准确率比通用模型提升了4%~16%。通用模型比词嵌入方法准确率更高的原因是通用模型对于指令句向量的表示中含有词语位置的信息,在对于指令中的单词位置变更并替换成同义词时能较好地识别。在场景指令集上,通用模型的准确率比SBERT的方法提升了3%~4%,而个人模型在场景指令集、复述集两个数据集的准确率比SBERT模型提升了2.4%~20%。个人模型比SBERT模型准确率更高的原因是通过增量训练微调了模型权重。个人模型对用户指令的语言风格更加熟悉,即使指令中的词语位置有所变化,也能够准确识别。这种对用户特定语言模式的熟悉以及对词语排列变化的处理能力,使得个人模型相比于SBERT模型在准确性上有所提升。
相比于复述集,场景指令集准确性较低的原因是同学们根据个人生活经验和所提供的智能家居描述,提供了多种口语化的表达方式和特殊单词。这些因素导致了在匹配和映射过程中一定程度的不准确性。例如,当志愿者试图设置房间亮度时,他们可能会使用非常抽象的条件,比如“if the sitting room is well lighted”(如果客厅光线充足)。在这种情况下,三种方法都可能无法准确理解语义,导致最终错误地识别了指令。
图9为三种方法对复合指令推荐结果的对比。相比之下,通用模型的准确率比词嵌入方法提升了2%~8%,个人模型的准确率比通用模型提升了6%~16%。与SBERT相比,个人模型的准确率提升了13%~25%。复合指令比原始指令的准确率降低了5%~20%。准确率更低的原因是复合指令一般由两个原始指令组成,只有在正确识别出两个分开的原始指令时,才能正确识别复合指令。
参考文献:
[1]Civitarese G, Sztyler T, Riboni D, et al. Polaris: probabilistic and ontological activity recognition in smart-homes[J]. IEEE Trans on Knowledge and Data Engineering, 2019,33(1):209-223.
[2]Chaki D, Bouguettaya A, Mistry S. A conflict detection framework for IoT services in multi-resident smart homes[C]//Proc of IEEE International Conference on Web Services. Piscataway, NJ: IEEE Press, 2020: 224-231.
[3]Chen Xing, Li Aipeng, Zeng Xuee, et al. Runtime model based approach to IoT application development[J]. Frontiers of Computer Science, 2015,9: 540-553.
[4]Trimananda R, Aqajari S A H, Chuang J, et al. Understanding and automatically detecting conflicting interactions between smart home IoT applications[C]//Proc of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York:ACM Press, 2020: 1215-1227.
[5]Stojkoska B L R, Trivodaliev K V. A review of Internet of Things for smart home: challenges and solutions[J]. Journal of Cleaner Production, 2017,140: 1454-1464.
[6]Zhang Tiehua, Shen Zhishu, Jin Jiong, et al. Achieving democracy in edge intelligence: a fog-based collaborative learning scheme[J]. IEEE Internet of Things Journal, 2021,8(4): 2751-2761.
[7]邊寒, 陈小红, 金芝, 等. 基于环境建模的物联网系统TAP规则生成方法[J]. 软件学报, 2021,32(4): 934-952. (Bian Han, Chen Xiaohong, Jin Zhi, et al. Approach to generating TAP rules in IoT systems based on environment modeling[J]. Journal of Software, 2021,32(4):934-952.)
[8]Gill S S, Garraghan P, Buyya R. ROUTER: fog enabled cloud based intelligent resource management approach for smart home IoT devices[J]. Journal of Systems and Software, 2019,154:125-138.
[9]Mavromatis A, Colman-Meixner C, Silva A P, et al. A software-defined IoT device management framework for edge and cloud computing[J]. IEEE Internet of Things Journal, 2020,7(3): 1718-1735.
[10]Mueller J, Thyagarajan A. Siamese recurrent architectures for lear-ning sentence similarity[C]//Proc of the 30th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press,2016: 2786-2792.
[11]Neculoiu P, Versteegh M, Rotaru M. Learning text similarity with Siamese recurrent networks[C]//Proc of the 1st Workshop on Representation Learning for NLP. Stroudsburg, PA: Association for Computational Linguistics, 2016: 148-157.
[12]吴宇. 物联网数据服务中间件的设计与实现[J]. 计算机应用与软件, 2022, 39(1):10-18. (Wu Yu. Design and implementation of IoT data service middleware[J]. Computer Applications and Software, 2022,39(1): 10-18.)
[13]Krishna M B, Verma A. A framework of smart homes connected devices using Internet of Things[C]//Proc of the 2nd International Conference on Contemporary Computing and Informatics. Piscataway, NJ: IEEE Press, 2016: 810-815.
[14]Zhang Yang, Chen Junliang. Declarative construction of distributed event-driven IoT services based on IoT resource models[J]. IEEE Trans on Services Computing, 2017,14(1):125-140.
[15]Yao Lina, Benatallah B, Wang Xianzhi, et al. Context as a service: realizing Internet of Things-aware processes for the independent living of the elderly[C]//Proc of International Conference on Service-Oriented Computing. Cham: Springer, 2016: 763-779.
[16]Campagna G, Ramesh R, Xu Silei, et al. Almond: the architecture of an open, crowdsourced, privacy-preserving, programmable virtual assistant[C]//Proc of the 26th International Conference on World Wide Web. Republic and Canton of Geneva, Switzerland : International World Wide Web Conferences Steering Committee ,2017: 341-350.
[17]Campagna G, Xu Silei, Moradshahi M, et al. Genie: a generator of natural language semantic parsers for virtual assistant commands[C]//Proc of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation. New York:ACM Press, 2019: 394-410.
[18]Chen Yiyan, Liu Zhanghui, Huang Zhiming, et al. A services deve-lopment approach for smart home based on natural language instructions[C]//Proc of the 31st International Conference on Software Engineering and Knowledge Engineering. 2019: 367-478.
[19]Song Hui, Huang Guang, Chauvel F, et al. Supporting runtime software architecture: a bidirectional-transformation-based approach[J]. Journal of Systems and Software, 2011,84(5): 711-723.
[20]Pennington J, Socher R, Manning C D. GloVe: global vectors for word representation[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1532-1543.
[21]Reimers N, Gurevych I. Sentence-BERT: sentence embeddings using Siamese BERT-Networks[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2019.
