基于Prompt的两阶段澄清问题生成方法
2024-03-05王培冰张宁张春
王培冰 张宁 张春

收稿日期:2023-07-02;修回日期:2023-08-23 基金项目:国家重点研发计划资助项目(2019YFB1405202)
作者簡介:王培冰(1997—),男,河南许昌人,硕士研究生,主要研究方向为自然语言处理(21120463@bjtu.edu.cn);张宁(1958—),男,北京人,研究员,博导,博士,主要研究方向为铁路信息、智能信息处理、嵌入式系统;张春(1966—),女(满族),北京人,研究员,博导,硕士,主要研究方向为铁路信息、智能信息处理.
摘 要:在自然语言相关系统中,当用户输入存在歧义时,生成澄清问题询问用户有助于系统理解用户需求;基于Prompt的方法可以更好地挖掘预训练语言模型的潜在知识,但往往需要手动设计模板,限制其生成澄清问题的多样性。为解决这一问题,提出了TSCQG(two-stage clarification question generation)方法。首先,在动态Prompt模板生成阶段,利用歧义上下文和预训练语言模型生成动态的Prompt模板;然后在缺失信息生成阶段,将Prompt模板与外部知识相结合,充分利用预训练语言模型的生成能力生成相应的缺失信息。实验结果表明,在CLAQUA数据集的多轮对话情况中,BLEU值和ROUGE-L值分别达到了58.31和84.33,在ClariQ-FKw数据集上,BLEU值和ROUGE-L值分别达到了31.18和58.86。实验结果证明了TSCQG方法在澄清问题生成任务上的有效性。
关键词:预训练语言模型;Prompt;澄清问题生成;自然语言系统
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)02-015-0421-05
doi:10.19734/j.issn.1001-3695.2023.07.0271
Two-stage clarification question generation method based on Prompt
Wang Peibing,Zhang Ning,Zhang Chun
(School of Computer & Information Technology,Beijing Jiaotong University,Beijing 100044,China)
Abstract:In natural language-oriented systems,generating clarification questions to ask users when their input is ambiguous can help the system better understand the users requirements.Although Prompt-based approaches can better exploit the latent knowledge of pre-trained language models,they often require hand-designed templates,constraining their diversity in generating clarification questions.To address this limitation,this paper proposed the two-stage clarification question generation(TSCQG) method.Firstly,in the dynamic Prompt template generation stage,the TSCQG method used the ambiguous context and the pre-trained language models to generate Prompt templates.Then,in the missing information generation stage,it combined the Prompt templates and relevant external knowledge and capitalized on the generative potential of the pre-trained model to gene-rate relevant missing information.Experimental results demonstrate that the BLEU value and ROUGE-L value of the multi-round dialogue situation on the CLAQUA dataset reach 58.31 and 84.33,and the BLEU value and ROUGE-L value on the ClariQ-FKw dataset reach 31.18 and 58.86,respectively.The experimental results validate the effectiveness of the TSCQG method in clarification question generation tasks.
Key words:pre-trained language model;Prompt;clarification question generation;natural language system
0 引言
在一些需要与人进行交互的自然语言系统中,比如对话系统、搜索系统等,用户的输入难免会因为词汇的多义性、上下文信息缺失等原因导致系统难以理解用户的意图,最终导致系统返回给用户不准确的答案,降低用户的体验度。在对话系统中,对话出现歧义是很常见的现象,如何处理自然语言的歧义性将是模型优化中的一个关键挑战。Liu等人[1]发现即使是大型自然语言处理模型如GPT-4[2],也面临着语言歧义导致模型难以准确理解句子真正含义的问题。Shao等人[3]指出澄清问题生成(clarification question generation,CQG)是指当用户的输入存在歧义时,系统可以向用户生成自然语言问题来对缺失信息提问以满足信息需求。Zou等人[4]通过调查发现,对于用户的歧义输入,提供针对性的澄清问题可以大幅度减少用户与系统的交互,提高搜索结果的准确性,从而提高用户满意度。
目前对于CQG的研究还相对较少,主要可以分为自动生成的方法和基于模板的方法。对于自动生成的方法,主要是通过歧义上下文和外部信息直接生成澄清问题,如Rao等人[5]基于生成对抗网络使用强化学习算法来生成澄清问题,之后使用基于相关答案的判别器对生成的澄清问题进行评估,从而优化生成器模型。而基于模板的方法则是预定义一些澄清问题模板来引导生成澄清问题,如Xu等人[6]采用分阶段生成澄清问题的思想,首先将歧义上下文输入到模板生成模块中来生成相关澄清问题模板,再通过实体渲染模块来生成槽位词,最终生成澄清问题;Wang等人[7]基于模板引导澄清问题生成,通过交叉注意力机制来训练模型学习用户的输入、外部知识以及模板信息之间的关系,以此找到最合适的模板和槽位词。然而对于自动生成的方法,其效果高度依赖于训练数据的数量和质量,在训练数据量较小或质量较差的情况下,生成的澄清问题质量会受到较大影响,可能会出现语法错误、生成的澄清问题过于一般化等问题,同时整个过程解释性较差。对于基于模板的方法,虽然可以保证最终澄清问题的质量不会出现语法错误,但是需要人工对数据集进行统计分析并从中观察,手动设计对于该数据集较为通用的模板。该方法可扩展性较差,其生成的结果缺乏多样性,同时耗费大量人力。
近几年,随着数据量和计算能力的增加,各大研究机构开始利用大规模的数据集和计算资源预训练语言模型,如谷歌的BERT[8]、OpenAI提出的GPT[9]系列模型等。这些预训练模型使用海量的数据和大量的计算资源进行训练,能够捕捉更多的语言结构、语义信息和常识,从而提高了模型的泛化能力。为了让预训练模型更好地适应具体任务,研究人员逐渐采用预训练-微调策略,在此策略下,模型在大规模数据集上进行预训练,然后下游任务训练微调某些层或参数以适应具体任务。如Majumder等人[10]为生成高质量的澄清问题,首先通过全局和局部的知识对比找到缺失信息,然后再通过BART[11]和PPLM[12]生成有效的澄清问题。
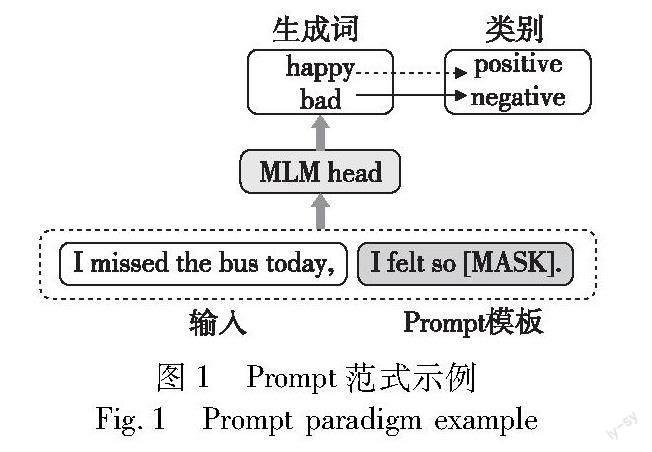
将预训练语言模型应用在澄清问题生成任务中将会极大提升模型理解用户歧义和生成澄清问题的能力,然而如果预训练语言模型和下游任务训练目标不同,会产生两者之间的差异。基于Prompt范式的方法可以更好地激发预训练模型所蕴涵的知识,Prompt范式的思想是通过某个模板将要解决的问题转换成语言模型预训练任务类似的形式来进行处理。如图1所示,对于用户的初始输入,通过结合相关模板的方式将其转换成预训练模型训练时的输入形式。例如,为了预测文本“I missed the bus today.”的情感類型,可以使用Prompt模板构建“I missed the bus today.I felt so[MASK]”并使用遮盖语言模型 MLM(masked language model) 来预测[MASK]的输出,而[MASK]的输出就是文本的情感类型。但是Prompt性能的好坏非常依赖于模板以及表意与任务的匹配程度,大部分工作依然采用手工方式构建模板和表意,即使是经验丰富的设计者也难以人工发现最优的Prompt模板。为了能够动态地生成Prompt模板来激发大规模预训练语言模型蕴涵的知识,最终生成流利顺畅且多样性较高的澄清问题,本文提出了基于Prompt的两阶段澄清问题生成方法TSCQG。在动态Prompt模板生成阶段,通过用户输入的歧义上下文,先动态生成合适的Prompt模板;在缺失信息生成阶段,通过上一阶段生成的Prompt模板和相关的外部知识生成对应的澄清问题所需要的缺失信息;最后将缺失信息插入到Prompt模板中生成最终的澄清问题。通过实验,TSCQGY方法在CLAQUA[6]和ClariQ-FKw[13]两个公开的英文澄清问题数据集上的性能相比于现有的基线均有所提升,实验结果说明了TSCQG方法的有效性。
1 基于Prompt的两阶段澄清问题生成研究
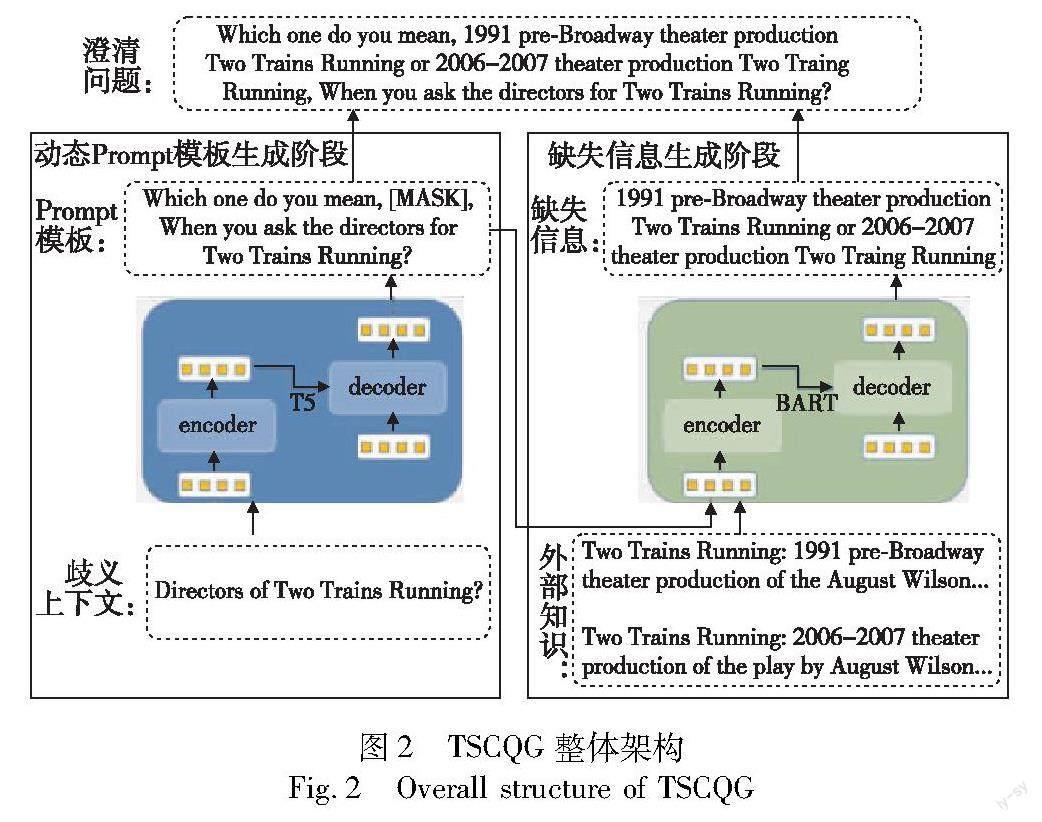
TSCQG方法如图2所示,它主要由动态Prompt模板生成模块和缺失信息生成模块两部分组成。在动态Prompt模板生成阶段,先利用T5(text-to-text transfer transformer)[14]模型,通过用户输入的歧义上下文信息自适应地生成合适的Prompt模板,该模板不仅为下一阶段生成澄清问题缺失信息提供先验知识,同时也为最终生成的澄清问题提供框架。在缺失信息生成阶段,主要是利用上一阶段生成的模板和相关的外部知识,基于Prompt范式使用BART(bidirectional and auto-regressive transformer)[11]模型,让模型识别出对于该澄清问题模板,相关外部知识的哪些重要信息能够补全澄清问题的缺失信息,最后将缺失信息插入到Prompt模板中,生成完整的澄清问题。
1.1 问题定义与解决方案
本文中,澄清问题生成任务的定义为:给定有歧义的上下文C=[c1,c2,…,clenc],lenc表示歧义上下文的长度,ci表示歧义上下文第i个token;歧义上下文相关的外部知识K=[k1,k2,…,klenk],lenk表示外部知识的长度,ki表示第i个外部知识的token。模型可以输出一个澄清问题Q=[q1,q2,…,qlenq]来询问用户关于歧义上下文C的缺失信息,以此满足信息需求,其中lenq表示输出澄清问题的长度,qi表示澄清问题的第i个token。歧义上下文是指在历史上下文对话语句中,用户的输入未能明确表达自己的意图,其常见的特征包括词语的多义性、语义角色的模糊性等;外部知识为歧义上下文中相关实体的外部信息。以CLAQUA数据集为例,输入的歧义上下文C为“What is Aldaras ingredient?”,其中相关的外部知识K为关于Aldara的实体类型和描述,由外部知识可知,关于Aldara,一种是“brand Aldara”,另一种是“non brand Aldara”,因此模型生成澄清问题Q为“Which one do you mean,brand Aldara or non brand Aldara,when you say the active constituent?”来询问用户想问的是哪类Aldara。受文献[6]的启发,本文并不是直接将歧义上下文C和外部知识K一起作为输入,而是将此任务视为两阶段的任务来处理。在动态Prompt模板生成阶段,使用歧义上下文C生成Prompt模板T:“Which one do you mean,[MASK],when you say the active constituent?”;在缺失信息生成任务,使用Prompt模板T和外部知识K生成缺失信息M:“brand Aldara or non brand Aldara”。最终将T和M结合生成澄清问题Q。
1.2 动态Prompt模板生成模块
在动态Prompt模板生成任务中,可以将任务描述为
T=f(C,Θ1)(1)
其中:Θ1是模型的参数。Prompt模板T是将澄清问题的缺失信息用[MASK]替换之后的序列。如Aldara的例子中,歧义上下文C为“What is Aldaras ingredient?”,Prompt模板T为“Which one do you mean,[MASK],when you say the active constituent?”为该任务的输出。由于Prompt模板中不包含相关的缺失信息,所以也就无须结合相关的外部知识,只需将歧义上下文作为输入,再利用大规模预训练语言模型的优势就可以很好地生成。需要注意的是,因为生成的模板中需要包含[MASK],所以在训练时需要先将[MASK]当作一个token加入到模型的分词器中。该任务选取的预训练语言模型为T5模型,T5模型采用了Transformer[15]网络结构,通过自监督的方式进行多任务学习,然后对这些转换后的文本进行无监督训练,从而获得一种通用的表示能力。T5模型的架构包括编码器和解码器,分别用于对输入文本进行编码和解码。编码器和解码器由多个Transformer块组成,每个块由多头自注意力机制、前馈网络以及层归一化组成。在本文中,模型输入的是用户的歧义上下文,输出为动态的Prompt模板。
为了捕捉歧义上下文中不同位置的相关性,进而对输入序列编码,在T5的编码阶段使用了多头注意力机制对嵌入向量进行计算。首先将歧义上下文C变为嵌入向量X=[x1,x2,…,xn],xi∈Euclid Math TwoRApdembedding,其中每个xi是输入序列中对应的嵌入词向量,dembddding为嵌入向量的维度。对于T5的位置编码,采用的是相对位置编码,即每个位置编码都是一个标量,并添加到每一个嵌入词向量中。然后通过X和三个参数矩阵WQ、WK、WV的计算来获得每个注意力头的查询向量Q、键向量K和值向量V,其中Q=XWQ、K=XWK、V=XWV,WQ,WK,WV∈Euclid Math TwoRApdmodel×dk是模型可学习的参数,dk表示预定义的单头维度。自注意力计算公式为
Att(Q,K,V)=softmax(QKTdk)V(2)
第i个头的注意力得分为headi=Attention(Qi,Ki,Vi),那么最终的多头注意力机制得分为
mulAtte(Q,K,V)=concat(head1,head2,…,headh)·Wo(3)
其中:concat表示将每个头的注意力张量拼接起来;h表示头的数量;Wo为可学习的参数矩阵。
为防止模型梯度爆炸或梯度消失,采用残差网络和层归一化对输出向量Z进行处理。T5采用了一种简化版的layer normalization,去除了layer norm的bias,并且将layer norm放在残差连接外面。T5模型的解码层用于将歧义上下文的编码进行解码,输出所需的Prompt模板。解码模块与编码模块非常相似,由多层堆叠的子模块组成,每一层主要包括遮掩多头自注意力机制、交叉注意力机制和全连接前馈网络。解码器的输入是编码器的输出向量以及目标Prompt模板中已经生成的部分,用来生成下一个目标词语的概率分布,并根据该分布生成目标词汇,一直循环进行直到输出整个序列,其中的每个词汇都是根据其前面已经生成的词汇而生成的。模型的损失函数为交叉熵损失函数和正则化项的加权和。交叉熵损失函数可用于度量生成序列与目标序列的相似程度,正则化项在损失函数中被广泛使用以避免模型过拟合,相关公式如下:
lossce(x,y)=-1L∑Lt=1yt log (st)(4)
其中:L表示序列的长度;yt表示目标序列中第t个token的one-hot表示;st表示模型在第t个时间步的输出。
lossreg(θ)=12‖θ‖22(5)
其中:θ表示模型的参数;‖θ‖22表示θ各个元素的平方和,即模长的平方。
loss=α lossce(x,y)+β lossreg(θ)(6)
其中:α和β分别表示交叉熵损失函数和正则化项的权重。
1.3 缺失信息生成模塊
对于缺失信息生成任务可以表述为
M=f(T,K,Θ2)(7)
其中:Θ2为模型的参数。在该任务中,通过第一阶段生成的模板T和相关的外部知识K,利用Prompt的思想,使用大规模预训练语言模型生成缺失信息M,再将T和M结合生成澄清问题Q。如Aldara的例子中,模型需要上个任务生成的Prompt模板和相关的外部知识来生成缺失信息“brand Aldara or non brand Aldara”。
BART模型是一种用于生成式自然语言处理任务的预训练语言模型,其预训练任务主要有text infilling和sentence permutation,主要是将带有噪声的文本输入到模型中去,模型的任务是将其还原为正常的序列。通过这种方式,BART可以利用部分信息重新构建整个文本。而在缺失信息生成模块,该阶段的任务同样是对上一阶段生成的模板中[MASK]信息的预测,这与BART的text Infilling预训练任务是非常接近的。因此,上一阶段动态生成的Prompt模板可以很好地利用到BART学习到的知识来生成相关缺失信息。
BART模型采用的是标准Transformer模型,其包含的编码器和解码器都与Transformer模型基本一致,不过做了一些改变,比如将ReLU激活函数改为GeLU激活函数,还有将解码器的各层对编码器最终隐藏层额外执行cross-attention等。
在该模块,输入的是Prompt模板T和外部知识K,两者通过〈SEP〉特殊符号连接起来,其输入记为U={t1,t2,…,[MASK],…,tlent,〈SEP〉,k1,…,klenk},其中ti为Prompt模板序列,ki为外部知识序列。首先将U输入到编码器中:
Z=Encoder(U)(8)
编码器将输入序列U转换为一个捕捉了输入序列语义信息的上下文编码信息Z,之后将Z输入到解码器中;解码器通过自回归的方式逐步生成每一个token,直到生成完整的缺失信息M。
M1:i=Decoder(Z,M1:i-1)(9)
自回归过程中,解码器根据上下文编码信息Z和已生成的部分序列M1:i-1 来生成下一个标记M1:i。模型最终得到的是Prompt模板中的缺失信息,也就是对[MASK]位置的相关预测。
模型的损失函数为交叉熵损失函数,用于度量生成的序列与目标序列之间的差异。损失函数的计算如下:
loss=-∑mi=1log P(Mi|Z,M1:i-1)(10)
其中:P(Mi|Z,M1:i-1)表示在给定上下文表示Z和已生成的部分序列M1:i-1的条件下,生成下一个标记Mi的概率。
2 实验及分析
2.1 数据集
本文实验采用CLAQUA和ClariQ-FKw数据集来评估TSCQG方法的性能。这两个数据集的统计信息如表1所示。
CLAQUA数据集于2019年公开发布,涵盖多个领域的对话和相应的澄清问题,并支持三种与澄清相关的任务,包括澄清识别、澄清问题生成和基于澄清的问题回答。本实验主要关注澄清问题生成任务,该数据集包含单回合对话情况和多回合对话情况。在本实验中对这两种情况都进行了测试。ClariQ-FKw为对话搜索相关的数据集,包含(query,fact,quesiton)三元组,query是用户的初始查询,fact是相关的类型信息,question是人工生成的澄清问题。数据集包含1 756个训练示例和425个验证示例。由于没有测试集,将训练集的20%作为测试集。
2.2 基线模型
本文选取了三个文本生成模型Transformer、Coarse-to-fine[6]、SHiP[3]作为基线模型。其中Transformer采用传统的编码器-解码器框架,该框架首先将歧义上下文通过注意力机制进行编码,然后依次解码为目标澄清问题;Coarse-to-fine由模板生成模块和实体渲染模块组成,分别生成模板和槽位词组成最终的澄清问题;SHiP是端到端的自监督模型,该框架结合了分层Transformer机制和指针生成器机制来生成澄清问题。
2.3 实验细节
对于数据集CLAQUA,在动态Prompt模板生成阶段,需要先将输入的上下文和相关的外部知识分离出来,只需要用上下文来生成模板。在缺失信息生成阶段,需要将模板和外部知识通过〈SEP〉符号连接起来并输入到BART模型中去。而对于ClariQ-FKw数据集,由于目标澄清问题没有预定义的模板,通过观察数据发现,绝大部分澄清问题的形式都是类似的,可以先进行数据预处理,将目标澄清问题分离出澄清问题模板和缺失信息两部分以供模型训练。
本文中T5和BART的模型参数均使用预训练模型的参数进行初始化。两阶段的训练超参数基本一致,优化器采用的是Transformers库提供的AdamW[16]动态优化算法。学习率设为2E-5,在训练时,对学习率进行调整以优化模型的性能,学习率调整器的类型设为Linear,预热步数设为50。在两个模型上微调的epoch均为20。实验中对比的基线模型,超参数均参考原始论文及其代码设置。
2.4 实验结果及分析
为验证TSCQG方法的有效性,在两个澄清问题生成数据集上与基线模型进行对比,同时在这两个数据集上进行消融实验,对两阶段澄清问题生成方法的有效性和Prompt范式的有效性进行了验证,并测试了模型参数规模对实验结果的影响。
2.4.1 性能对比分析
表2给出了各个模型在各个数据集上的实验结果,以及消融实验和模型參数对比实验的结果。从实验结果可以看出,标准的Transformer模型在生成澄清问题方面已经具备了一定的能力,证明了Transformer的编码器-解码器框架对于澄清问题生成任务的有效性。Coarse-to-fine模型的性能高于Transfomer模型,说明在编码器-解码器框架的基础上分别生成模板和缺失信息对于生成澄清问题是有意义的。SHiP模型的效果更进一步说明使用自监督的方式对模型进行预训练以及分层Transformer机制和指针生成机制对生成任务的有效性。而TSCQG方法性能均优于基线模型,首先这得益于大规模预训练模型的潜在知识,同时基于Prompt范式的两阶段方式可以更好地激发大规模语言模型蕴涵的知识,使其生成的澄清问题更加流利通顺且多样性高。
2.4.2 消融实验
为验证两阶段生成方法的有效性,设计了消融实验no-BART,直接将上下文信息和外部知识结合起来,然后输入到T5模型中去生成澄清问题。为验证Prompt范式的有效性,设计了消融实验no-T5,不使用Prompt模板,单单利用外部知识来生成缺失信息。从no-BART消融实验可以看出,得益于大规模预训练语言模型的潜在知识,直接将上下文和外部知识结合起来,虽然生成的澄清问题效果不错,但是性能依然略低于TSCQG,证明了两阶段生成方式的有效性。no-T5实验性能低于TSCQG的性能,证明了通过Prompt模板,能够更好地激发BART模型的预训练知识,生成更为准确的缺失信息。
2.4.3 對比实验
为验证T5和BART模型在本任务中相较于其他模型更有优势,使用BERT和UniLM[17]模型分别替换T5和BART模型,设计了对比实验BERT-BART、T5-BERT、UniLM-BART、T5-UniLM。由表2结果可知,虽然BERT和UniLM也属于大规模预训练语言模型,但是无论是替换T5还是替换BART,其结果都不如T5和BART相结合的性能,说明在动态生成Prompt模板方面,T5模型可以根据上下文信息生成质量更高的Prompt模板;在缺失信息生成方面,Prompt模板可以更好地激发BART模型的潜在知识,生成更准确的缺失信息。
2.4.4 模型参数对模型性能的影响
为评估参数对模型性能的影响,设计了实验R-T5-small,即使用T5-small模型来替代T5模型;设计了实验R-BART-small,即使用BART-small模型来替代BART模型。
T5-small模型的参数规模约为原模型的1/3,BART-small模型的参数规模约为原模型的1/8,然而两者与TSCQG的模型性能相差不多,甚至在CLAQUA的multi-turn数据集上,R-BART-small要优于TSCQG,其原因是BART模型的参数更多,需要更多的训练数据来准确地估计这些参数。而CLAQUA数据集的规模不足,与BART模型的参数规模不匹配,模型可能无法充分学习到参数之间的关系,导致性能下降。同时过多的参数也可能使得模型更容易过度拟合训练数据,导致在测试数据上的性能下降。
2.5 样例分析
如表3所示,本文挑选了CLAQUA中multi-turn数据集的两条数据作为样例,将TSCQG生成结果与其他两种模型的生成结果进行对比。通过观察可以发现,TSCQG生成的澄清问题相较于Coarse-to-fine和SHiP包含更多必要的关键词或短语,能够准确地针对原问题中的模糊之处进行澄清,并且能够引导回答者提供具体的信息或解释。
3 结束语
生成澄清问题对提高自然语言系统理解用户准确语义有着重大意义,目前基于大规模预训练语言模型微调的方法还较少,而Prompt范式的方法可以更好地激发大规模语言模型蕴涵的知识。为将基于Prompt范式的方法应用到澄清问题生成任务中,同时可以动态地生成Prompt模板,本文提出了基于Prompt的两阶段澄清问题生成方法TSCQG。在动态Prompt模板生成阶段,通过将歧义上下文输入到T5模型中生成Prompt模板;在缺失信息生成阶段,通过Prompt模板和相关外部知识来生成缺失信息,最终将两者组合成完整的澄清问题。从实验结果可以看到,TSCQG优于其他基线模型。 澄清问题生成可以帮助对话系统更好地与用户进行交互,进一步提升用户体验。随着对话系统的发展,澄清问题生成会更加智能化和灵活,未来的澄清问题生成可以通过自适应学习和个性化技术,根据用户的偏好和历史对话数据生成更适合用户的澄清问题,这将提升对话系统的个性化服务和用户满意度。同时,未来的澄清问题生成可以更加充分利用知识图谱和上下文信息,通过结合知识图谱中实体和关系信息以及对话的上下文,澄清问题生成可以更准确地理解用户的意图,生成更具针对性的澄清问题。目前关于澄清问题生成的数据集还相对较少,而大部分的方法也都是有监督的学习,未来的研究将进一步探索如何在小样本或者零样本的基础上生成通顺且特异的澄清问题。
参考文献:
[1]Liu A,Wu Zhaofeng,Michael J,et al.Were afraid language models arent modeling ambiguity[EB/OL].(2023-04-27).https://arxiv.org/pdf/2304.14399.pdf.
[2]OpenAI.GPT-4 technical report[EB/OL].(2023-03-27).https://arxiv.org/pdf/2303.08774.pdf.
[3]Shao Taihua,Cai Fei,Chen Wanyu,et al.Self-supervised clarification question generation for ambiguous multi-turn conversation[J].Information Sciences,2022,587(3):626-641.
[4]Zou Jie,Aliannejadi M,Kanoulas E,et al.Users meet clarifying questions:toward a better understanding of user interactions for search clarification[J].ACM Trans on Information Systems,2023,41(1):article No.16.
[5]Rao S,Daumé III H.Answer-based adversarial training for generating clarification questions[C]//Pro of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2019:143-155.
[6]Xu Jingjing,Wang Yuechen,Tang Duyu,et al.Asking clarification questions in knowledge-based question answering[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2019:1618-1629.
[7]Wang Jian,Li Wenjie.Template-guided clarifying question generation for Web search clarification[C]//Proc of the 30th ACM International Conference on Information & Knowledge Management.New York:ACM Press,2021:3468-3472.
[8]Devlin J,Chang Mingwei,Lee K,et al.BERT:pre-training of deep bidirectional transformers for language understanding[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2019:4171-4186.
[9]Brown T,Mann B,Ryder N,et al.Language models are few-shot lear-ners[C]//Proc of the 34th International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2020:1877-1901.
[10]Majumder B P,Rao S,Galley M,et al.Ask whats missing and whats useful:improving clarification question generation using global know-ledge[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2021:4300-4312.
[11]Lewis M,Liu Yinhan,Goyal N,et al.BART:denoising sequence-to-sequence pre-training for natural language generation,translation,and comprehension[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2020:7871-7880.
[12]Dathathri S,Madotto A,Lan J,et al.Plug and play language models:a simple approach to controlled text generation[EB/OL].(2020-03-03).https://arxiv.org/pdf/1912.02164.pdf.
[13]Sekulic′ I,Aliannejadi M,Crestani F.Towards facet-driven generation of clarifying questions for conversational search[C]//Proc of ACM SIGIR International Conference on Theory of Information Retrieval.New York:ACM Press,2021:167-175.
[14]Raffel C,Shazeer N,Roberts A,et al.Exploring the limits of transfer learning with a unified text-to-text transformer[J].Journal of Machine Learning Research,2020,21(1):5485-5551.
[15]Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2017:6000-6010.
[16]Loshchilov I,Hutter F.Decoupled weight decay regularization[EB/OL].(2019-01-04).https://arxiv.org/pdf/1711.05101.pdf.
[17]Dong Li,Yang Nan,Wang Wenhui,et al.Unified language model pre-training for natural language understanding and generation[C]//Proc of the 33rd International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2019:13063-13075.
[18]Rao S,Daumé III H.Learning to ask good questions:ranking clarification questions using neural expected value of perfect information[C]//Proc of the 56th Annual Meeting of the Association for Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2018:2737-2746.
[19]Zhang Zhiling,Zhu K.Diverse and specific clarification question generation with keywords[C]//Proc of the Web Conference.New York:ACM Press,2021:3501-3511.
[20]Wang Zhenduo,Tu Yuancheng,Rosset C,et al.Zero-shot clarifying question generation for conversational search[C]//Proc of the ACM Web Conference.New York:ACM Press,2023:3288-3298.
[21]Imran M M,Damevski K.Using clarification questions to improve software developers Web search[J].Information and Software Technology,2022,151(11):107021.
[22]Zhao Ziliang,Dou Zhicheng,Mao Jiaxin,et al.Generating clarifying questions with Web search results[C]//Proc of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM Press,2022:234-244.
