基于IG-NRS与ICK双向压缩的KMS自学习案例知识匹配
2024-03-05张建华贺龙飞张淑唯曹子傲温丹丹
张建华 贺龙飞 张淑唯 曹子傲 温丹丹


收稿日期:2023-06-03;修回日期:2023-08-01 基金项目:国家社会科学基金资助项目(19BTQ035)
作者简介:张建华(1975—),男,河北承德人,教授,博导,主要研究方向为知识创新与知识服务;贺龙飞(2000—),男(通信作者),河南南阳人,硕士研究生,主要研究方向为知识匹配与知识推荐(19137787970@163.com);张淑唯(1999—),女,河南商丘人,硕士研究生,主要研究方向为知识进化与知识匹配;曹子傲(1992—),男,河南商丘人,博士研究生,主要研究方向为知识匹配与知识传播;温丹丹(1986—),女,河南商丘人,博士研究生,主要研究方向为知识匹配与知识服务.
摘 要:案例知识匹配可有效缓解知识过载问题,确保知识应用水平。针对知识管理系统自学习案例知识匹配的冗余性问题,提出了一种基于IG-NRS与ICK的双向压缩方法。该方法首先设计NRS的改进模型IG-NRS,据此约简案例知识属性集,实现邻域决策系统的纵向压缩;在此基础上,通过引入谱聚类判别并剔除不一致案例知识实现其横向压缩;再藉由知识视图相似度锁定目标案例知识簇与最相似案例知识,从而确定知识匹配结果。在多个UCI数据集上的实验结果表明,该方法能有效减少知识管理系统自学习案例知识的冗余,取得更高的知识匹配效率和有效性。
关键词:知识匹配;知识管理系统;案例知识;双向压缩
中图分类号:TP393 文献标志码:A
文章编号:1001-3695(2024)02-011-0393-08
doi:10.19734/j.issn.1001-3695.2023.06.0259
KMS self-learning case knowledge matching based on
IG-NRS and ICK bidirectional compression
Zhang Jianhua,He Longfei,Zhang Shuwei,Cao Ziao,Wen Dandan
(School of Management,Zhengzhou University,Zhengzhou 450001,China)
Abstract:Case knowledge matching can effectively alleviate the knowledge overload problem and ensure the level of know-ledge application.Aiming at the redundancy problem of self-learning case knowledge matching in knowledge management systems,this paper proposed a bidirectional compression method based on IG-NRS and ICK.The method firstly designed an improved model of NRS,called IG-NRS.Accordingly,it approximated the set of case knowledge attributes to achieve the vertical compression of the neighborhood decision system.On this basis,
it realized horizontal compression by introducing spectral clustering discrimination and eliminating the inconsistent case knowledge.And then it determined the knowledge matching results by locking the target case knowledge clusters and the most similar case knowledge through the similarity of knowledge views.Experimental results on several UCI datasets show that this method can effectively reduce the redundancy of self-learning case knowledge in knowledge management systems and achieve higher knowledge matching efficiency and effectiveness.
Key words:knowledge matching;knowledge management system;case knowledge;bidirectional compression
0 引言
在知識经济时代,知识已取代传统资源(如土地、劳动力、资本等)上升为新的主导资源,对其进行有效的组织与管理成为企业价值创造的源泉。越来越多的企业认识到知识在社会生产中的决定性地位,正谋求以知识管理打造自身的核心竞争力,进而提升生产效率与组织绩效,以期在日趋激烈的竞争中立于不败[1]。知识管理系统(knowledge management system,KMS)作为将知识管理由理念导向实践的支撑性平台,其自身所具备自组织、自学习能力,为企业藉由知识管理创造价值提供了强大辅助[2,3]。
知识只有通过应用过程才能实现其自身价值。不过,随着信息技术的不断发展,知识结构的日趋复杂与知识体量的不断扩大使知识应用过程愈发困难,知识主体难以获得能够满足其需求的知识。KMS案例知识匹配作为知识管理的关键环节,它将知识主体需求及既有各类知识转换为案例形式,通过匹配计算出与该需求相吻合的知识供给。可见,知识匹配进一步深化了知识的应用进程,增强了知识主体的决策辅助意义,能够有效缓解上述问题;同时也促进了知识获取、知识传播等知识链各活动间的协同联动,提升了KMS的运维水平。
传统案例匹配的实现以基于案例推理(case-based reaso-ning,CBR)系统为依托[4,5]。CBR方法利用历史案例对当前问题推理求解:首先,将历史案例保存于案例库;在用户提交待解问题后,通过在整个案例库中寻找与该待解问题匹配程度最高的案例并提交用户,用户可据此对待解问题进行求解[6]。该方法企图规避对案例库复杂构成规则的获取分析,确实能在一定程度上快速得到待解问题的解。不过,随着CBR系统自组织过程的延续,案例与案例属性数量的不断丰富,导致案例库规模迅猛扩大,遍历巨大案例库会束缚求解效率,而冗余案例与冗余属性还会影响匹配精度,此时须对案例库进行压缩处理(包括横向压缩与纵向压缩)。
为避免对案例集全域的穷举计算,相关学者采用启发检索与归纳检索建立案例集收缩机制。Lundberg[7]将启发检索应用于专家系统和基于知识的系统,发现两者具有相同的实效水平。吴华瑞等人[8]提出基于启发式AO*算法的农作物病虫害诊断方法,在保证高准确度的前提下,显著地提高了搜索的效率。谢燕等人[9]以匹配程度作为启发信息,优先获得匹配程度高的初始解集,再基于此搜寻最优匹配解,有效减少了搜索空间。Ralph等人[10]论证了流畅性启发式检索可能是人类大脑推理决策的工具,可利用环境结构和少量有价值的信息来逃避费力的搜索,能准确地反映实际统计规律的封装频率信息。Cheng等人[11]设计了一系列实验,验证了“变化匹配启发式”有助于消费者快速作出购买决策,提高了其加工的流畅性。该类启发检索受西蒙“有限理性”理论影响,基于启发规则能够快速定位待解问题的相似案例,但该方法亦会受到启发规则的约束,在提升效率的同时使有效性下降。此外,皇甫中民等人[12]采用人工鱼群聚类算法将模型库空间聚类划分为若干子空间,再利用隶属度函数将匹配范畴收缩至相应子空间,其检索质量和效率均有明显提高。张杰等人[13]结合矩阵运算方法及核方法,设计出一种视频关键帧相似度核聚类检索算法,能更好地提高视频检索的效率。雷以良等人[14]利用改进K-means算法生成案例故障类别,按照待解问题对各类别质心的距离实现匹配,提升了故障推理系统的效能。Jiang等人[15]将特征匹配问题转换为空间聚类问题,基于DBSCAN聚类算法将样本数据划分为不同类别,再以此为基础进行检索。李雅欣等人[16]利用近邻成分分析算法训练得到度量矩阵,并结合K近邻分类器映射变换使同类型样本间的距离减小,因此系统效率得到提升。李晓明等人[17]采用三级推理策略进行案例推理,根据故障特征参数实现故障类别的划分,减小案例匹配目标集的规模。该类归纳检索需建立适当的索引结构,基于索引位置划分案例子库,并分别生成少数代表性案例,以此作为目标集实施匹配,极大程度上压缩了匹配空间,使其效率得到有效提升;不过,通过归纳方法直接划分案例子库是以完善案例库为前提,即默认案例库各案例索引距离较近案例的决策结果完全一致,但由于案例构成规则复杂、案例属性有限、存在冗余属性等缘故,导致此前提的可置信程度不高。实践中,某些案例虽距离较近,其决策结果却并不相同。以此作为目标集,匹配模糊程度高,其结果易发生错误;另外,各案例子库的规模参差不齐、代表性案例的标准与结果无法统一、代表性案例过少等因素极易导致索引目标集并非待解问题的最优初始解集,进而降低案例匹配的有效性。
对冗余属性问题,其主流观点是利用粗糙集的理论和方法压缩案例属性集。该方法通过计算属性重要性,逐步迭代以获取最简属性集。常春光等人[18]采用粗糙集理论约简案例冗余属性,并基于最小分辨矩阵的约简算法与逼近精度敏感性离散化算法,纵向缩减匹配空间,从而提升匹配效率。Salamo等人[19]基于粗糙集理论实现了特征选择和案例属性压缩。然而,传统的粗糙集理论需要对数据离散化处理,这可能损失原始信息,从而影响约简效果。基于此,Hu等人[20]引入邻域粗糙集(neighborhood rough set,NRS),并提出了前向贪心算法,以实现对连续属性值的高效属性约简。刘潇等人[21]运用K-means聚类与NRS属性约简,并结合SMOTE方法消除数据不平衡性,进而利用网格搜索组合分类器评估检验客户分类效果,有效提升了其分类的效率和准确率。该类方法通过剔除冗余属性约简案例属性集,案例库与匹配空间的规模得到了有效收缩,从而提升了案例匹配的效率。然而,传统粗糙集理论或NRS理论在距离计算时缺乏对各属性赋权,将重要程度不同的属性同等看待,且仅在案例库规模较小时才具有良好的约简效果,随着案例集与案例属性集的扩大,其计算复杂度迅速上升,时间和空间成本增加,约简效率愈发下降。其中,NRS理论需人为设定邻域大小,若邻域半径设置不合理,其约简效果并不理想。
CBR领域的现有研究成果为KMS自学习案例知识匹配机制的研究、设计奠定了基础。KMS同样是一个具备知识丰富多样、结构复杂、自组织能力强大等特点的复杂巨系统。随着系统的不断运行,案例知识库体量将会迅猛提升,其自学习案例匹配效率严重下降。因其与前述CBR系统的窘境十分类似,亟需谋划更为有效的双向压缩策略,以确保KMS自学习案例知识匹配机制的运维水平。
在约简冗余属性方面,信息增益(information gain,IG)與粗糙集的思路相近,都以案例的条件属性对决策结果的支持程度划分重要属性,但前者处理高维数据的效率远高于后者。启发检索不以其他索引结构区分案例库,保留了案例集更多的信息,有效弥补了归纳检索的前述不足。鉴于此,本文以IG对NRS实施约简改进;将启发检索与归纳检索结合,引入谱聚类(spectral clustering,SC)以判别KMS案例知识库中的不一致案例知识(inconsistent case knowledge,ICK),并将其有效剔除,得到精简的案例知识目标集;在实现双向压缩的基础上,再基于聚类后的案例知识集实施案例知识匹配,以提升其效率和有效性。本文方法的贡献可概括为:a)将IG融入邻域决策系统,收缩NRS的初始约简范畴,在邻域计算时增设对条件属性的赋权,并减少因邻域半径设置失当导致的局部最优情形;b)引入SC构建了案例知识库的双索引结构,定义了ICK,识别出距离索引与规则索引不一致的案例知识并予以约简,为决策表约简增设新的维度;c)用所得SC结果进一步收缩知识匹配目标集,以视图相似度计算最终匹配结果,并在多个真实UCI数据集上验证了其可行性与进步性。
1 理论基础
1.1 信息增益
IG源自信息论,是衡量案例各属性对其决策结果影响程度的统计量。IG值越大,表明采用该属性越容易判别和得到更准确的决策结果,因此应赋予其较大权重;而冗余属性因对导出决策结果作用微弱则被赋予较小的权重。若冗余属性参与知识匹配计算,易提升该机制的混乱程度,因此需有效识别此类冗余属性并予约简。在信息论中,信息熵用来反映随机变量取值的不确定性程度。设X为样本量为n的任意随机变量,第i类样本为xi,p(xi)为其频率,则熵的计算如式(1)所示。熵越高,X的不确定性程度越大。
H(X)=-∑ni=1p(xi)log2(p(xi))(1)
条件熵表示在某条件下随机变量的不确定性程度,X在给定随机变量Y的条件下的条件熵计算如式(2)所示。
H(Y|X)=∑ni=1p(xi)H(Y|X=xi)(2)
IG是信息熵的差值,表示增加条件使不确定性降低的程度,其计算如式(3)所示。可见,IG值越大,采用Y划分X类别使不确定性降低,准确性提高。
IG(X,Y)=H(X)-H(X|Y)(3)
1.2 邻域粗糙集
标记决策系统DES=〈U,C,D,f〉,其中U={x1,x2,x3,…,xn}为论域,C为条件属性,D为决策属性,f:U×C→D为映射关系。NRS在粗糙集理论中增加了邻域,能处理连续型数据。若C生成论域U上的一族邻域关系,则称NDES=〈U,C,D,f〉为邻域决策系统。对于xi∈U,定义xi的邻域为δB(xi)={xj|xj∈U,ΔB(xi,xj)≤r},其中Δ为距离,用p范数表示如式(4)所示,其中f(xi,ai)为样本xi在属性ai上的取值,p为常数。
Δp(x1,x2)=(∑Ni=1|f(x1,ai)-f(x2,ai)|p)1p(4)
在NDES=〈U,C,D,f〉中, D将U划分为n个等价类:X1,X2,X3,X4,…,Xn,其中BC,生成U上的邻域关系NB,则D关于条件属性B的上、下近似分别如式(5)(6)所示,其中,NBXi={x|δ(x)Xi},NBXi={x|δ(x)∩Xi≠},i=1,2,…,n。
NBD={NBX1,NBX2,…,NBXn}(5)
NBD={NBX1,NBX2,…,NBXn}(6)
由此得D关于B的正域、边界域分别为PosB(D)、BN(D),分别如式(7)(8)所示。其中PosB(D)越大,表明越能依据B对决策属性精确划分。
PosB(D)=NBD(7)
BN(D)=NBD-NBD(8)
1.3 知识视图相似度
知识相似度抽象描述知识间的相近程度,按知识相似层次的不同将其划分为知识方面相似度(knowledge aspect similarity,KAS)和知识视图相似度(knowledge view similarity,KVS),两者分别为局部与全局关系。KAS表示不同知识间在同一知识属性下的相近程度,是计算KVS的基础,知识k1、k2在属性am下的欧氏距离计算如式(9)所示。
Simai(k1,k2)=1-(kai1-kai2)2(9)
知识主体因其需求视角不同,对同一知识对象产生的视图也有所不同。该视图包含两层含义:a)知识主体选择知识特征属性构成属性集合,较方面相似度更具全局意义;b)它通过权重向量表征视图中各方面之于知识主体的重要程度。KVS表示不同知识间在同一视图下的相近程度。用V表示视图,ω为权重向量,ωi为其分量,n为视图中属性个数,则视图相似度的计算如式(10)所示。
Simai∈V(k1,k2,ω)=∑ni=1ωiSimai(k1,k2)(10)
2 基于双向压缩与视图相似度的案例知识匹配
一般而言,KMS自學习案例知识虽然属性众多,但其数目却远不及案例知识的体量,由此冗余属性的数量相对较少;另外,属性是对案例知识的表征,案例知识的重要性无疑高于其自身属性。可见,约简冗余属性的纵向压缩对原案例知识库的扰动更小,能更多地保留原始重要信息,故其所引起的偏差更低。若先实施横向压缩,则由于其压缩幅度较大容易使案例信息严重丢失,从而降低对案例知识库进一步压缩的可能,案例知识匹配的效能也随之下降。且相关学者也优先进行特征属性选择[13,21]。有鉴于此,本文采取先纵后横的压缩顺序。
2.1 基于IG-NRS的纵向压缩
依据NRS前向贪心算法[20]可对案例知识实施属性约简。该方法首先对最简属性集合赋空集,即red←,并从全体属性集出发计算属性重要度,再将判断出的重要属性加入red,经过逐步迭代得约简结果。该过程通过衡量加入某条件属性后对约简集合的影响,保证了约简后条件属性内部的独立性与完备性。不过,它也存在如下缺陷:a)从空集出发迭代至最简属性集的迭代次数较多,每次迭代获取属性重要度的计算过程也较为烦琐,当案例知识属性较多时,获取约简结果的效率偏低;b)当案例知识的重要度相差不大或邻域半径设置失当时,属性约简容易陷入局部最优,可能遗漏某些重要属性,进而使所得约简属性集合对原属性集的代表性程度下降;c)距离计算缺乏对各条件属性赋权,精确性不高。
与NRS的重要度类似,IG理论依据案例知识的条件属性对决策结果的决定程度赋权。某条件属性的IG值越大,表明其与决策结果的相关性越强,增加该属性表述案例知识越容易判别得到更准确的决策结果。由于该过程无须迭代,计算复杂度低,所以依据其能快速识别出重要的条件属性,从而得约简结果。但IG仅考虑了各条件属性与决策属性间的相关性,忽视了各条件属性内部的独立性,故容易将多个相关性较强的条件属性纳入约简属性集合。鉴于此,考虑采用IG改进NRS,得到新的约简方法IG-NRS,使两者优势互补,以缓解上述问题。
首先基于既定KMS自学习案例知识库,构建知识表达系统S=〈U,A,V,f〉如表1所示,将各类知识(包括显性知识与隐性知識)转换为案例知识形式。
其中,U={c1,c2,c3,…,ci,…,cs}为论域,表示由案例知识c1,c2,c3,…,ci,…,cs构成的非空有限集合,A=C∪D为案例知识属性集合,C={a1,a2,a3,…,am,…,an}表示由属性a1,a2,a3,…,am,…,an构成的条件属性集,D表示决策属性集(案例决策结果),V表示属性值,f为案例知识属性到属性值的映射,则有f:U×A→V。利用向量ci=(vi1,vi2,vi3,…,vim,…,vin)表示第i个案例知识(1≤i≤s),其中vim表示第i个案例知识的第m个属性值(1≤m≤n)。为消除案例知识属性值量纲与数量级的影响,对其归一化,如式(11)所示。其中,f(vim)为归一化的结果,vim表示第i个知识案例的第m个属性值,vm表示各案例的第m个属性对应的属性值,n为其属性总数。
f(vim)=vim-min(vm)max(vm)-min(vm)(11)
针对该决策表,设决策结果有|D|类,将其划分为不同的案例集Cd,有1≤d≤|D|,则决策属性D的信息熵为式(12)。
I(D)=-∑|D|d=1pdlog2(pd)(12)
其中:pd为D属性值为第d类的概率,用|Cd||D|估计。
对于任一连续属性am,确定其最佳分裂点:首先将am的属性值升序排列,每两个相邻值之间皆有可能产生划分,划分的不同区域视为不同分类,如此对于am的s个属性值应有s-1种可能划分,进而计算各中可能划分的条件信息熵如式(13)所示。其中Dj为am属性的第j分类,v为其总分类数(v=2)。I(D|am)越小表明am属性对决策结果的决定程度更强,故I(D|am)最小时取得最佳分裂点。由此可计算属性am的IG如式(14)所示。
I(D|am)=∑vj=1|Dj||D|×I(Dj)(13)
Gain(am)=I(D)-I(D|am)(14)
依此类推,得到其他属性的IG值,则用式(15)计算am属性权重,其中Gain(am)为am属性的IG。
wam=Gain(am)∑nm=1Gain(am)(15)
而后将各属性按照权重降序排列,排列结果为order,依次对提取的属性权重求和,如式(16)所示。
Sw=∑am∈orderwam(16)
分别设定重要性阈值ε1、ε2(ε1<ε2)。若加入属性使得Sw≥ε1恰好成立,则保留相应属性为重要属性集IGcore;若加入属性使得Sw≥ε2恰好成立,则保留相应属性为预约简属性集IGred;其他视为冗余属性,予以约简。其中ε1、ε2越大,则IGcore与IGred的规模越大,该属性约简过程保存原始属性信息越多;当ε1、ε2为0时,不保存任何案例知识属性;当ε1、ε2为1时, IGcore与IGred不约简任何属性;故有0<ε1<ε2≤1。
之后,从原始案例知识库S中取IGred所包含的属性作为条件属性,将原案例知识相应决策属性合并为预约简案例知识库S1。此时设置邻域半径r,将S1=〈U,A,V,f〉视为邻域决策系统。对于ci∈U,定义ci的邻域为δB(ci)={cj|cj∈U,ΔB(ci,cj)≤r},其中ΔB表示距离,距离用IG加权的2范数(欧氏距离)如式(17)所示。
ΔB(c1,c2)=∑nm=1{[f(c1,am)-f(c2,am)]wam}2(17)
分别依据式(5)~(7)得到PosB(D),再计算决策属性D对条件属性B的依赖度,如式(18)所示。其中,CARD为集合中元素个数,0≤γB(D)≤1表示根据B描述可完全归为某等价类(由决策属性D划分)的比率。γB(D)越大,决策结果对属性B的依赖性越强。
γB(D)=CARD(PosB(D))/CARD(U)(18)
对于该邻域决策系统,BC,am∈B。若同时满足条件:a) γB(D)=γC(D);b)γ(B-am)(D)<γB(D),am∈B,即由C得到规模较小的B,同时不改变决策结果,则称B为C的一个属性约简。属性am相对于属性B的重要度如式(19)所示。当am加入到约简属性集中时,不改变D对其的依赖度,则予以约简。NRS结果记为NRSred,取IGcore∪NRSred=IGNRSred为IG-NRS的约简结果。
SIG(am,B,D)=γB∪am(D)-γB(D)(19)
本文采用由IG改进的NRS前向贪心算法对案例知识库进行属性约简,如算法1所示。
算法1 IG-NRS属性约简
输入:S1。
输出:约简结果IGNRSred。
a)约简属性集合NRSred←。
b)在S1中,对am∈A,以wam对距离赋权,计算邻域关系Nam。
c)利用式(5)~(7)(17)~(19)计算amNRSred相对于NRSred的重要度。
d)选择满足使重要度最大的属性af。
e)若SIG(af,NRSred,D)>0,则NRSred←NRSred∪af;否则返回步骤c),直至SIG(af,NRSred,D)=0。
f)为防止NRS剔除重要属性,取IGcore∪NRSred=IGNRSred输出为约简属性集,运算结束。
综上,IG-NRS方法弥补了单一方法约简属性的缺陷,既用IG方法通过NRS考虑各条件属性内部的独立性,又能高效地获得重要属性集合与预约简属性集合,使NRS可快速得出约简结果。如此,提升了案例知识库纵向压缩的效率与有效性,为进一步的横向压缩与知识匹配过程奠定基础。
2.2 基于ICK的横向压缩
KMS自学习案例具有完备、复杂的决策机制,能够根据不同的条件屬性形成决策;案例知识匹配谋求绕过对此复杂决策规则的解析过程,而侧重以案例知识间相似度预测待解问题的解,从而提高求解效率。据前文所述,对案例知识的聚类在其决策结果之外重塑索引结构。显然,该方法侧重以索引位置决定案例知识的匹配结果,忽略了其本身固有的决策属性,降低了知识匹配的决策辅助水平。启发检索不要求重塑案例结构,能有效兼顾案例知识的位置与决策结果。因此本文拟将两者结合,定义归纳结果与决策结果类型不同的案例知识为ICK,识别并予以剔除。利用ICK方法作为启发条件,以实现横向压缩。
本文采用SC方法对案例知识实施归纳。SC基于距离划分样本,其具体步骤[22]如下:
a)将案例知识样本转换为图顶点,根据式(20)计算案例知识间的距离,之后选取距离最小的K个案例知识作为最近邻。再根据式(21)的相似度对边赋权,并利用该值生成邻接矩阵W,构建无向加权图。
dis(ci,cj)=∑nm=1(cim-cjm)2(20)
wij=wji=0ciKNN(cj) and cjKNN(ci)
e-|ci-cj|22σ2ci∈KNN(cj) or cj∈KNN(ci)(21)
b)使用式(22)(23)计算拉普拉斯矩阵,其中DM为对角阵。
DM=∑nj=1wij(22)
L=DM-W(23)
c)为了分解L,引入指标矩阵H,其值计算如式(24)所示。
hiJ=0ciAJ
1∑ci∈AJdcici∈AJ (24)
d)通过对式(25)的变换,可以得到使Ncut最小的特征矩阵F,使用K-means算法对F的各行聚类得到最终结果。
Ncut(A1,A2,…,Ak)=∑kJ=1hTJLhJ=∑kJ=1(HTLH)JJ
HT(DM)H=I
H=(DM)-12F(25)
可见,SC借鉴图论中的最优划分问题,在K-means聚类的基础上实现压缩功能,改变了传统的直接计算样本间距离的聚类方式[23],故能准确、高效地处理复杂高维的KMS自学习案例知识。而且,SC的簇数K可人为规定,当K=1时,索引结构失效;K越大,聚类过程越能实现对原案例知识的精细划分。但当K>>|D|时,则易使聚类与决策结果类型数的差距增大,这与客观实际相背离,故宜设定K接近|D|,且K∈Euclid Math TwoZAp。
选择适当的K,对上述纵向约简后的案例知识库实施聚类(设属性约简至q个),基于距离生成新的索引,建立双索引结构的知识表达系统如表2所示。
csvs1vs2vs3…vsm…vsqdsscs 如前文所述,聚类所得同一簇案例知识可能拥有多种决策结果。针对此问题,设定决策结果类别阈值θ,计算各决策结果的占比CDM,如式(26)所示,其中nd为d类决策结果的数量,nC为对应SC簇所包含案例知识的数量。将CDM降序排序后依次求和为SCDM,如式(27)所示,并使相应决策结果包含于决策结果类别集合DC,直至SCDM≥θ。而后,判断各案例知识的决策结果是否存在于DC,若存在,将其保存于案例知识库;否则视其为ICK,予以剔除。如此,利用ICK作为启发条件,能够从原案例知识库筛选出一致性更强的案例知识,有效收缩了目标集,从而实现横向压缩。
CDM=ndnC(26)
SCDM=∑CDM(27)
综合以上两节内容可知,该方法在纵向上为传统CBR领域补充新的属性约简方法,缓解了NRS与IG方法约简冗余属性的低效问题,在横向上化解了归纳检索案例知识位置与决策结果的矛盾,从而有效实现KMS自学习案例的双向压缩。此外,相较于传统CBR压缩方式,该方法还具有如下优势:
a)传统CBR案例压缩均发生在案例匹配过程中,这无疑增加了案例匹配的时间消耗,且压缩局限在单一方向;KMS自学习案例压缩则发生于自组织阶段,时间上独立于案例匹配过程,不会增加后者的时间消耗,且双向压缩使案例知识库比单方向压缩更加合理精简,极大程度确保了KMS待解问题的求解效率与有效性;
b)传统CBR压缩内嵌于案例匹配过程中,系统模块化程度低,运维困难;KMS自学习案例压缩过程独立于案例匹配算法,不仅增强了系统模块化特性,提高了压缩计算的灵活性,也降低了系统运维难度。
2.3 基于视图相似度的案例知识匹配
为了提高匹配效率,本节依据2.2节中ICK方法对案例知识的聚类,计算待解问题与各聚类中心的视图相似度,再以最大相似度的簇为匹配空间,遍历搜寻最相似案例知识。对各案例知识簇,以簇内案例知识条件属性值的平均值得到j簇中心向量j,计算如式(28)所示,vjk为该簇的第k个案例知识属性值。
j=∑kvjkk(28)
以2.1节中IG方法确定约简后案例知识库的属性权重向量ω,ωam为ω的am属性分量。计算待解问题cu与簇中心j的视图相似度,如式(29)所示。
Simam(cu,j)=1-(camu-amj)2
Simam∈V(cu,j,ω)=∑ωamSimam(cu,j) (29)
对于待解问题cu,以最大Simam∈V(cu,j,ω)为最相似簇。待解问题越有可能在其中搜寻到相应决策结果。再对该簇中案例知识依次计算视图相似度,取cu、cl相似度最大为Sim(cu,cl,ω),记为Simul。同时设定相似度阈值λ,若Simul≥λ,则匹配成功,预测待解问题cu的解与案例知识cl保持一致,其结果记为d^u;否则表示该待解问题与各簇的相似度都较低,依据视图相似度求解的模糊程度较高,匹配失败,转入KMS自组织机制中的知识适配或知识修正,此环节在本文不作赘述。
综上,基于双向压缩与视图相似度的案例知识匹配算法如算法2所示。
算法2 基于双向压缩与视图相似度的案例知识匹配
输入:S=〈U,A,V,f〉,ε1,ε2,r,K,θ,t。
输出:ci,d^u or 匹配失败。
a)对S归一化。
b)对am∈A,用IG计算得Sw,将其与ε1、ε2比较,相应属性保留在IGcore、IGred。
c)从S中提取{IGred,D}列,设置r,用NRS计算得NRSred。 /*见算法1*/
d)IGcore∪NRSred=IGNRSred。
e)从S中提取{IGNRSred,D}列,用SC方法将案例知识聚类为K类,得双索引结果。
f)对聚类簇中各ci依次计算得SCDM,若SCDM≥θ,得DC,转到步骤g),否则继续。
g)若Dci存在于DC,将ci保存于S1,否则为ICK,予以剔除。
h)用KVS计算得Simam∈V(cu,j,ω),取最大簇计算得Simul。
i)若Simul≥t,匹配成功,输出cl与d^u,否则匹配失败。
如图1所示,本文方法基于双向压缩案例知识库实施聚类匹配,避免遍历完整案例知识库,在确保知识匹配有效性的前提下,显著提升了匹配效率。其中,纵向约简能有效剔除冗余属性,弥补了IG与NRS单一方法的缺陷;横向约简利用案例知识库构建新的索引结构,改善了归纳检索的前述不足;经双向压缩后再实施聚类,如此知识匹配能够进一步收缩匹配空间,从而有效降低KMS知识获取成本,缓解KMS知识存储压力。此外,传统CBR案例匹配直接将匹配结果提交用户,用户需对此相似案例作进一步的分析研究,方能得到最终的决策结果。而本文方法能直接预测待解问题的解,对知识主体的决策辅助程度更高。
3 实验分析
3.1 数据集
本文选取真实数据库UCI中两个不同规模的数据集作实验分析。该数据集各案例均由多个条件属性(连续型)与一个决策属性(离散型)构成,各含有5和6类决策结果。将每个数据集样本的90%作为训练集(案例知识库),10%作为测试集(待解问题),具体信息如表3所示。
3.2 实验评价指标
本文通过指标MR、MAR、MI来评估知识匹配方法,如式(30)所示。其中s0为待解问题总数,st为通过知识匹配阈值λ的待解问题总数,sr为st中匹配结果正确的待解问题总数。0≤MR≤1,其值越接近于1,待解问题匹配成功的概率越高;0≤MAR≤1,其值越接近于1,对匹配成功待解问题进行辅助决策的准确性越强。因此,综合构成的MI(0≤α≤1,0≤MI≤1)与前两者成正向关系,并且在实践中能够根据管理目的的不同灵活调整:若注重解决更多的待解问题,可设定较大的α;设定较小的α以体现对待解问题求解准确性的注重。显然,MI越接近于1,表示知识匹配的总体效果越好。
MR=sts0×100%MAR=srst×100%MI=αMR+(1-α)MAR (30)
通过accuracy、precision、recall、F1进一步评估实例在本文匹配系统中的分类效果,计算方式如式(31)所示,混淆矩阵如表4所示。accuracy衡量所有样本的预测正确程度,precision衡量预测为正样本的准确程度,recall衡量实际为正样本的准确程度,F1值反映综合分类效果。各指标值越高,越能体现分类性能,故越能取得合理的决策推理,对应的案例知识价值越高。
accuracy=TP+TNTP+TN+FP+FNprecision=TPTP+FPrecall=TPTP+FN
F1=2×precison×recallprecison+recall(31)
再利用t、Save衡量知识匹配的效率。t为运算时间,经实验统计可得到。Save为简化案例知识库与原案例知识库之比,故有0≤Save≤1,计算方式如式(32)所示。其中nred为压缩后案例库的属性值数量,n0为原案例知识库的属性值数量。t与Save越小,表示知识匹配的效率越高。
Save=nredn0×100%(32)
3.3 纵向压缩
本文分别使用NRS的前向贪心算法[20]与本文提出的IG-NRS方法对两个规模不同的数据集纵向压缩。其中,NRS中设置r以0.005为步长遍历[0.01,0.04],IG-NRS中设置ε1=0.5,ε2=0.85,r以0.000 5为步长遍历[0.001,0.004],约简结果如表5、6所示。
为比较上述属性约简过程的效率,统计得到t。剔除冗余属性后,逐一计算每一待解问题对上述约简案例知识库中各案例知识之间的视图相似度。为保障知识匹配求解的准确性,应设置λ=1,即检出案例与新的待解问题完全一致,但实践中此类情形极少出现,故适当放宽匹配条件,设置λ=0.985,尽量使其接近于1,即对各待解问题,当Simul≥0.985时视为匹配成功,以此计算所有待解问题的MR和MAR。此外,MR受到λ的影响,当匹配条件宽松(λ取较小值)时,匹配成功的待解问题数量骤增,MR容易取较大值,影响综合匹配效果的判断;而MAR仅当MR非常小时才发生明显变化。故设定α=0.2,对两者加权求和得到MI。t与MI结果如图2(a)(b)所示。
结合表5、6与图2分析可知,随着r增大,NRS与IG-NRS的运算时间均逐渐增加,但无论r取何值,IG-NRS的约简效率都明显高于NRS。这是由于前者先使用IG确定了各屬性的重要度,在NRS约简前剔除了部分不重要属性。NRS在r较小时,由于剔除属性过多,匹配效果较差。随着r的增加,对原始信息的保留程度增大,匹配效果显著提升,而IG-NRS表现出较强的稳定性,且匹配效果较优。理论上,NRS通过r划分等价类,能通过对其调整得到最佳约简属性集。不过,其约简属于NP-hard问题,前向贪心算法虽能在一定程度上提升约简的效率,但实践中如需设定恰当的r,需对原数据结构和NRS约简机理有足够的认识或丰富的经验,否则易使等价类划分错误,进而降低约简结果的有效性。IG与NRS类似,都以案例知识的条件属性值对决策结果的决定程度赋予其重要度。因此,IG-NRS通过IG确定重要属性集合并剔除部分不重要属性,能有效缓解NRS由于r设定失当导致的局部最优,同时能显著提升约简的效率。此外,NRS在距离计算时缺乏对属性的赋权,也在一定程度上减损了等价类的有效程度。
3.4 横向压缩
为验证本文依据ICK方法横向压缩的效率与有效性,选择基于SC聚类的匹配方法作对照,其K均1为以步长遍历[1,5]。在各案例知识簇中,为使决策结果类别囊括其主要的决策类型,宜使θ∈[0.5,1]。当θ=1时,不约简任何案例知识;θ越小,约简规模越大,故取θ=0.6。横向约简后,计算得Save;再以此实施知识匹配(参数与上同),最终得MI。其结果如图3所示。
分析图3可知,横向压缩使计算空间约简至原始案例知识库的30%~80%,一定程度上提高了知识匹配的效率。其中,ICK方法由于事先通过判别并剔除不一致的案例知识,其空间压缩的幅度更大。虽然聚类也能实现空间压缩,但对KMS的存储空间要求与运算初始范畴却依然是原始案例库全域[17],不利于系统协同运作。有效性上,ICK方法随K的增加而剔除更多的冗余案例知识,且其匹配效果随K的变化波动较大。当K=1时,由于保留的案例知识库规模较大(Save较大),匹配性能更优;随着K的增加,剔除了更多的案例知识,其MI开始下降,而后当K接近案例知识的决策结果数目时,匹配效果有所提升并逐渐稳定。运用聚类匹配结果也近似呈现相同态势。不过,经过ICK方法所得案例知识集的匹配效果更优。
3.5 双向压缩
綜合上述两种方法,得到基于IG-NRS与ICK的双向压缩方法,再以聚类所得案例知识集为匹配空间[12,21],实施知识匹配,得到参数r与K不同取值下的MI结果,如图4和图5所示。
由图4、5可知,双向压缩方法的MI会受r与K的共同影响。其中一旦实施横向压缩后,双向压缩的MI随K的波动较小,K≤3时结果较好。纵向压缩上,red数据集的r在[0.001,0.02]与[0.035,0.04]上匹配效果较好,white数据集的r在[0.02,0.04]能够获得最佳匹配效果。因此,不同案例知识库应利用恰当的方法搜寻最佳参数,以获取更优匹配结果。不过,总体上看,保留更多案例知识属性信息时,匹配结果往往较好。数值上,red与white原数据集的MI分别平均为0.629与0.669。若对其实施双向压缩,其MI可提升至0.738与0.714,较原数据平均提升11.3%。
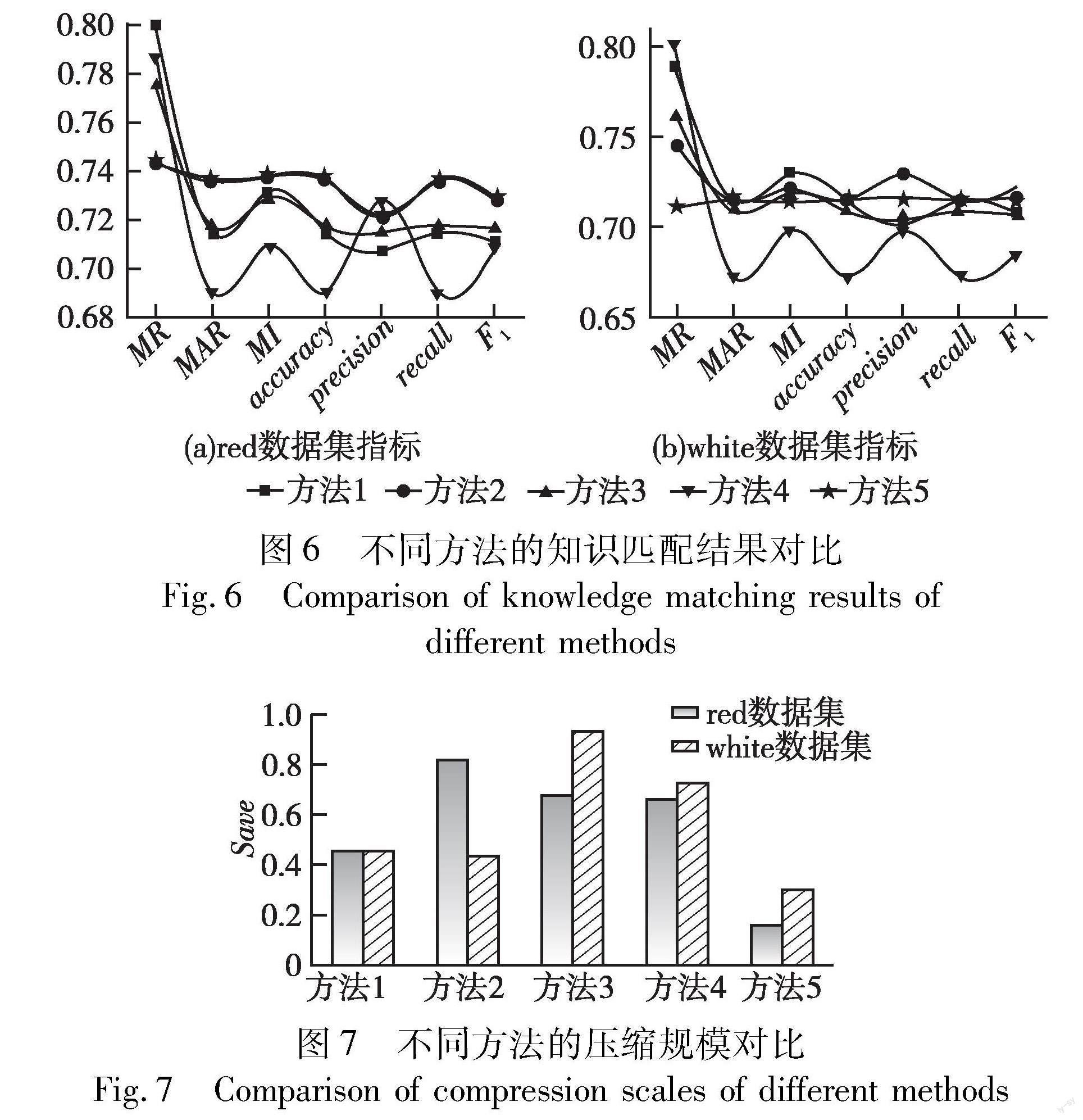
将基于IG-NRS的匹配方法、基于ICK的匹配方法、基于改进K-means与加权KNN的匹配方法[14]、基于K-means与NRS的匹配方法[21]与本文双向压缩匹配方法(分别对应方法1~5)进行对比,各自选择使MI最优的参数,如表7所示。
由此,比较各方法的知识匹配对比结果如图6所示,相应排序的Save结果如图7所示。
综合图6、7可知,各种压缩方法都降低了数据规模,减少了知识匹配的计算量。其中,方法1由于对属性集取并集,往往容易保留更多属性;方法3中PCA降维破坏了原案例知识的数据结构,改进的K-means聚类仅当K较小时,因约简规模较小从而保证匹配结果;方法4也存在该问题,同时NRS约简不如IG-NRS。这三种方法皆由于Save较大,容易获得与待解问题相似的案例,所以所得MR较高,会在一定程度上提升MI,但由于冗余案例知识的存在将导致求解不准确,使MAR与分类性能下降,综合看来其知识匹配效率与有效性不佳。方法2和5则缓解了上述案例知识库双索引结构间的不一致情形,对匹配案例的筛选能力更强,所以获得了更高的MAR;通过ICK方法也会剔除与某些待解问题相近的案例知识,故所得MR较低,MI值虽因MR的减小而有所下降,不过也能维持与其他方法相近的水平,分类效果则明显优于其他方法。方法5更善于以较少的数据量保持或得到较好的匹配效果,兼顾了知识匹配的效率与有效性。由于保存了更加精准的匹配所需有效信息,比单向压缩或其他匹配方法所体现的优越性更显著;同时也会由于剔除数据过多,减损了一定的知识匹配效果。
综上,可得如下结论:a)纵向压缩方面,IG-NRS方法比传统NRS理论的知识匹配结果更好,寻优简便且效率更高,易于处理KMS复杂巨系统;b)横向压缩方面,ICK方法所得的知识匹配效果明显优于传统归纳检索,且能够有效压缩案例知识库、降低KMS的案例知识存储压力;c)将以上两种方法结合所得的双向压缩方法在兼具其各自优势的同时,体现出比单向压缩和其他匹配方法更加卓越的性能。
4 结束语
知识经济时代,知识上升为企业的核心生产资源。为确保和持续提升企业的知识应用效益,本文针对KMS自学习案例知识匹配中属性与案例的冗余问题,提出了双向压缩策略。实验结果验证了该方法的可行性与进步性。本文方法不仅方便了人机交互,提高知识主体的决策水平,更容易实现高质量的知识匹配。此外,本文研究深化了知识匹配方法的研究,丰富了知识管理和KMS的相关理论,同时为KMS系统的开发和实施提供了有价值的参考。在未来的研究中,为进一步提升方法的性能,案例知识间的相关性将被纳入方法的约束中,并在更大范围内进一步验证方法的普适性。
参考文献:
[1]Pillania R K.Knowledge economy leaders,runners-up and laggards:a study of one-hundred-and-forty countries[J].Social Science Electronic Publishing,2008,3(4):471-478.
[2]张建华,刘艺琳,温丹丹,等.融合三支决策与GRA-Orthopair模糊集的知识匹配方法研究[J].计算机应用研究,2021,38(7):1967-1972.(Zhang Jianhua,Liu Yilin,Wen Dandan,et al.Research on knowledge matching method combining three-way decision and GRA-Orthopair fuzzy set[J].Application Research of Computer,2021,38(7):1967-1972.)
[3]彭纪生,赵步同.论知识管理与自组织理论[J].系统辩证学学报,2005(1):37-39,47.(Peng Jisheng,Zhao Butong.On the theory of self-organization and knowledge management[J].Journal of Systemic Dialectics,2005(1):37-39,47.)
[4]封超,郭晓.基于CBR的应急情报智能决策支持系统研究[J].情报杂志,2017,36(10):36-40.(Feng Chao,Guo Xiao.Research on emergency intelligence intelligent decision support system based on case-based reasoning[J].Journal of Information,2017,36(10):36-40.)
[5]谢健民,秦琴,吴文晓.基于本体的突发事件网络舆情案例推理模型[J].情报杂志,2019,38(1):79-86.(Xie Jianmin,Qin qin,Wu Wenxiao.Case Reasoning model of network public opinion based on ontology[J].Journal of Information,2019,38(1):79-86.)
[6]文家富,郭偉,邵宏宇.基于领域本体和CBR的案例知识检索方法[J].计算机集成制造系统,2017,23(7):1377-1385.(Wen Jiafu,Guo Wei,Shao Hongyu.Case retrieval methodology based on domain ontology and case-based reasoning[J].Computer Integrated Manufacturing Systems,2017,23(7):1377-1385.)
[7]Lundberg B G.On the evaluation of heuristic information systems[J].T.H.E.Journal(Technological Horizons in Education),1990,6(3):253-259.
[8]吴华瑞,赵春江,尹宝才.基于启发式搜索的农作物病虫害诊断方法[J].微计算机信息,2010,26(16):18-20.(Wu Huarui,Zhao Chunjiang,Yin Baocai.The diagnosis of crop pests and diseases based on the heuristic search[J].Microcomputer Information,2010,26(16):18-20.)
[9]谢燕,燕辉,陈晓杰,等.基于启发式搜索的带循环模型一致性检测方法[J].计算机集成制造系统,2022,28(10):3081-3089.(Xie Yan,Yan Hui,Chen Xiaojie,et al.Conformance checking for process models with loops based on heuristic search[J].Computer Integrated Manufacturing Systems,2022,28(10):3081-3089.)
[10]Ralph H,Stefan M H,Lael J S,et al.Fluency heuristic:a model of how the mind exploits a by-product of information retrieval[J].Journal of Experimental Psychology.Learning,Memory,and Cognition,2008,34(5):1191-1206.
[11]Cheng Y H,Chuang S C,Yu P I,et al.Change in your wallet,change your choice:the effect of the change-matching heuristic on choice[J].Journal of Retailing and Consumer Services,2019,49(7):67-76.
[12]皇甫中民,张树生,闫雒恒.鱼群启发的三维CAD模型聚类与检索[J].计算机辅助设计与图形学学报,2016,28(8):1373-1382,1392.(Huangfu Zhongmin,Zhang Shusheng,Yan Luoheng.3D CAD model clustering and retrieval inspired by fish swarm[J].Journal of Computer-Aided Design & Computer Graphics,2016,28(8):1373-1382,1392.)
[13]张杰,齐官红,叶蓬,等.基于PCA的关键帧相似度核聚类检索算法[J].控制工程,2017,24(4):728-735.(Zhang Jie,Qi Guanhong,Ye Peng,et al.PKFSKC:PCA based key frame similarity kernel clustering algorithm[J].Scientific Journal of Control Engineering,2017,24(4):728-735.)
[14]雷以良,严承华,陈璐.基于改进K-means算法的网络安全设备故障案例推理研究[J].计算机应用研究,2020,37(S2):110-112.(Lei Yiliang,Yan Chenghua,Chen Lu.Research on fault case-based reasoning of network security equipment based on improved K-means[J].Application Research of Computer,2020,37(S2):110-112.)
[15]Jiang Xingyu,Ma Jiayi,Jiang Junjun,et al.Robust feature matching using spatial clustering with heavy outliers[J].IEEE Trans on Image Processing,2019,29:736-746.
[16]李雅欣,侯慧娟,张立静,等.近邻成分分析和k近邻学习融合的变压器不平衡样本故障诊断[J].高电压技术,2021,47(2):472-479.(Li Yaxin,Hou Huijuan,Zhang Lijing,et al.Transformer fault diagnosis with unbalanced samples based on neighborhood component analysis and k-nearest neighbors[J].High Voltage Engineering,2021,47(2):472-479.)
[17]李晓明,林学东,冯志书,等.基于案例推理的某型航空发动机防喘控制系统故障诊断[J].科学技术与工程,2018,18(21):320-326.(Li Xiaoming,Lin Xuedong,Feng Zhishu,et al.Fault diagnosis case-based reasoning of anti-surge control system of a certain type aero-engine[J].Science Technology and Engineering,2018,18(21):320-326.)
[18]常春光,汪定伟,胡琨元,等.基于粗糙集的案例属性约简技术[J].控制理论与应用,2006,23(6):867-872.(Chang Chunguang,Wang Dingwei,Hu Kunyuan,et al.Rough-set based reduciton techinque for case attirbutes[J].Control Theory and Applications,2006,23(6):867-872.)
[19]Salamo M,Lopez-Sanchez M.Rough set based approaches to feature selection for case-based reasoning classifiers[J].Pattern Recognition Letters,2011,32(2):280-292.
[20]Hu Qinghua,Yu Daren,Liu Jinfu,et al.Neighborhood rough set based heterogeneous feature subset selection[J].Information Sciences:an International Journal,2008,178(18):3577-3594.
[21]劉潇,王效俐.基于K-means和邻域粗糙集的航空客户价值分类研究[J].运筹与管理,2021,30(3):104-111.(Liu Xiao,Wang Xiaoli.Value segmentation of airline customer based on K-means and neighborhood rough sets[J].Operations Research and Management Science,2021,30(3):104-111.)
[22]Zamiri M,Yazdi H S.Image annotation based on multi-view robust spectral clustering[J].Journal of Visual Communication and Image Representation,2020,74:103003.
[23]Husmann S,Shivarova A,Steinert R.Company classification using machine learning[J].Expert Systems with Application,2022,195(6):116958.
