基于层级图标签表示网络的多标签文本分类
2024-03-05徐江玲陈兴荣
徐江玲 陈兴荣

收稿日期:2023-05-05;修回日期:2023-07-31
作者简介:徐江玲(1997—),女,湖北孝感人,硕士研究生,主要研究方向为自然语言处理、多标签文本分类;陈兴荣,女(通信作者),副教授,博士,主要研究方向为数量经济、应用统计(xujiangling2020@163.com).
摘 要:多标签文本分类是一项基础而实用的任务,其目的是为文本分配多个可能的标签。近年来,人们提出了许多基于深度学习的标签关联模型,以结合标签的信息来学习文本的语义表示,取得了良好的分类性能。通过改进标签关联的建模和文本语义表示来推进这一研究方向。一方面,构建的层级图标签表示,除了学习每个标签的局部语义外,还进一步研究多个标签共享的全局语义;另一方面,为了捕捉标签和文本内容间的联系并加以利用,使用标签文本注意机制来引导文本特征的学习过程。在三个多标签基准数据集上的实验表明,该模型与其他方法相比具有更好的分类性能。
关键词:多标签文本分类;标签相关性;层级图表示;标签组嵌入;标签文本注意力
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)02-010-0388-05
doi:10.19734/j.issn.1001-3695.2023.05.0236
Multi-label text classification based on hierarchical graph label representation network
Xu Jiangling,Chen Xingrong
(School of Mathematics & Physics,China University of Geosciences,Wuhan 430000,China)
Abstract:Multi-label text classification is a basic and practical task,and its purpose is to allocate multiple possible labels for text.In recent years,people have proposed a lot of deep -learning label association models,which learn the semantic representation of the text by combining label information,and have achieved good classification performance.This paper promoted this research direction by improving the modeling and text semantics of the label association.On the one hand,the constructed hierarchical graph representation not only learned the local semantics of each label,but also further studied the global semantics shared by multiple labels.On the other hand,in order to capture the connection between labels and text content,it used the label text attention mechanism to guide the learning process of text characteristics.Experiments on the three multi-label benchmark data sets show that the proposed model has better classification performance compared to other methods.
Key words:multi-label text classification(MLTC);correlation of label;graphical representation of the hierarchy;group embedding of label;label-text attention
0 引言
多標签文本分类(MLTC)是为语料库中的每个样本分配一个或多个标签的任务[1]。MLTC目前已在主题识别、问答系统、标签推荐、信息检索[2~5]等领域得到广泛应用。最近的进展主要是利用标签关联模型来学习文本的语义表示。在多标签分类任务中,相关的标签极有可能同时出现,标签的相关性能够为多标签学习提供有用的信息,因此对于标签的相关性建模已经进行了很长时间的研究,并且被证明是非常有效的[6,7]。如何充分挖掘和利用标签的相关性,是目前研究者普遍关注的问题。同时,随着对标签研究的进一步深入,标签不再是没有任何意义的原子符号,而是具有语义信息的实际内容[8,9],标签语义中包含着与文本内容相关的信息,因此利用标签语义引导模型学习文档中的重要单词信息,可以进一步提升分类效果。本文通过改进标签关联的建模和文本语义表示来推进这一研究方向。一方面,不同于现有的只学习每个标签局部语义的方法,本文希望进一步研究多个标签共享的全局语义,以此更加充分地捕捉标签之间的高阶相关性;另一方面,现有方法中利用BiLSTM提取文本特征,通常是直接选取最后一个单词的隐藏状态或者对所有的单词隐藏状态进行等权平均来作为文本的特征表示,但并非所有的单词对标签的贡献都是一样的[10]。为了更加关注文本中与标签相关的成分,引入标签文本注意机制从文本内容中识别出与标签相关的文档表示,可以获得更好的性能。
为了实现上述想法,本文设计了一个层级图标签表示网络(hierarchical graph label representation network,HGLRN),通过标签特定嵌入和标签组嵌入,分别捕获局部语义和全局语义,然后通过注意机制将它们与文本特征结合,学习包含标签语义信息的文本表示。具体过程如下:首先,引入标签组嵌入(label-group embedding,LGE)模块,通过图注意力网络和可微分池化捕获每个标签的局部语义和一组标签共享的语义;然后,标签语义引导注意(semantic guided attention,SGA)模块,通过标签文档注意机制将LGE模块与文本特征模块中BiLSTM的多个隐藏状态结合起来,明确地引导文本特征学习关注对分类重要的单词信息。本文的贡献总结如下:
a)构建了标签之间的层级图结构,除了考虑每个标签之间的局部语义之外,还进一步研究多个标签共享的全局语义,可以有效地捕捉标签语义的高阶相关性,从而更加充分地学习标签的依赖信息。
b)模型中的标签文本注意机制,可以从每个文本中获取与标签相关的成分,最后生成包含标签相关信息的文本表示。
1 相关工作
传统的多标签文本分类方法使用特征工程技术作为文本特征提取器,然后使用分类算法进行分类,例如多标签决策树(multi-label decision tree,ML-DT)[11]、秩支持向量机(ranking support vector machine,Rank-SVM)[12]、多标签K近邻(multi-label K-nearest neighbor,ML-KNN)[13]等。随着深度学习的发展,各种基于神经网络的模型,如卷积神经网络(convolutional neural network,CNN)[14,15]、循环神经网络(recurrent neural network,RNN)[16,17]等在文本分类中得到了广泛的应用,与传统方法相比,它们可以从文本中学到更具分类价值的特征。近年来随着Transformer网络[18]以及基于该网络的预训练模型(bidirectional encoder representation from transformers,BERT)[19]的提出,其在分类性能方面取得了很大的提升。然而,这些方法的分类效果通常依赖于文本特征的学习,可能需要大量的计算资源来获取,因此本文除了利用文本的表示,还寻求利用标签信息来实现更有效的多标签文本分类。
在多标签文本分类中,文档同时被多个标签注释,而标签通常具有相关性。研究表明,利用标签相关性可以显著提高分类的性能[20]。在Kurata等人[21]的研究中,模型隐藏层和输出层之间的权重是利用标签共现矩阵来初始化的,从而考虑标签的相关性;Chen等人[22]利用CNN文档编码器提取局部特征,并利用RNN捕捉标签之间相关性。近年来,有一些方法利用图神经网络(graph neural network,GNN)生成标签语义嵌入。例如Pal等人[23]使用图注意力网络(graph attention networks,GAT)捕捉标签信息,利用双向长短时记忆网络(bi-directional long short-term memory,Bi-LSTM)学习文本特征,以点乘的形式将两者结合起来实现多标签的文本分类;Ozmen等人[24]利用图卷积网络(graph convolutional network,GCN)构建了一种标签信息传递网络,提取标签的拉推关系,以此来考虑标签之间多种类型的双向依赖关系。尽管这些方法在多标签文本分类上取得了不错的性能,但它们是在学习模型顶部的分类器时才融入标签信息,这使得标签信息对学习文本表示的影响是间接的。为了解决这个问题,引入标签文本注意机制,直接从模型底部合并标签信息,以此通过标签信息来引导文本特征的学习,可以关注文本中重要的单词信息。
有些研究进一步利用标签文本之间的依赖关系来学习文本的表示。文献[25]构建了一种标签和文本的显式交互模型,通过单词与标签的匹配得分,针对不同标签学习各自的文档表示;Xiao等人[26]提出了一种标签特定注意网络,利用标簽语义信息来确定标签和文档之间的语义连接,用于构建标签的文档表示;Liu等人[27]利用文本标签协同编码器来获得文本和标签的相互参与表示,使得模型能够专注于文本和标签的相关部分,从而有利于文本分类。但是这些方法过于依赖局部的标签表示,在标签缺失或者含有噪声时,可能导致单词与标签错误匹配的问题,不足以预测正确的标签。因此本文在学习标签语义信息的过程中,通过构建标签的层级结构,同时考虑标签的局部语义和全局语义,可以有效地捕捉标签之间的高阶相关性,从而更加充分地利用标签信息。
2 研究方法
2.1 体系结构
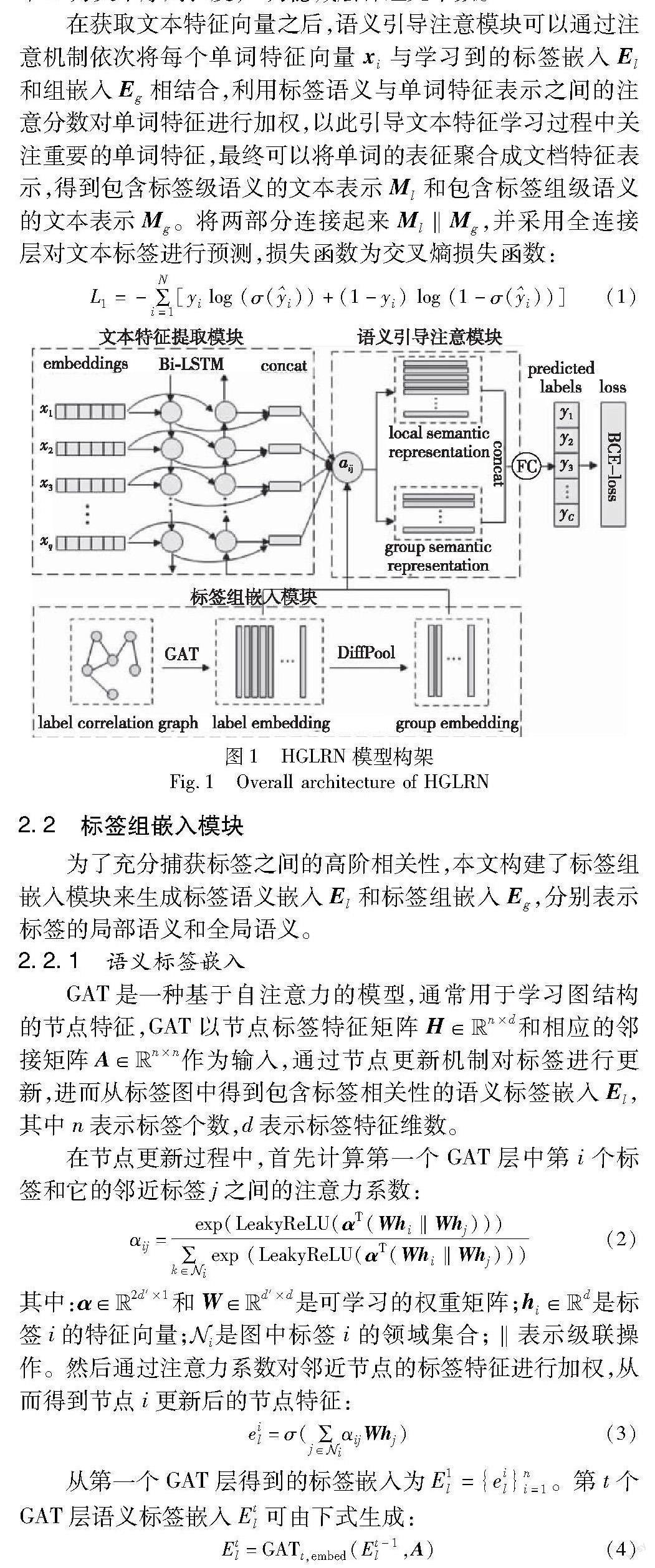
本文的模型结构如图1所示,通过标签组嵌入模块可同时获取标签的局部语义和全局语义,以此来有效地捕获标签的高阶相关性。在标签组嵌入模块中,以标签图结构G={H,A}作为输入来生成标签语义嵌入和标签组嵌入,H={hi}ni=1为标签的特征矩阵,其中hi为标签特征向量,n为标签的个数,A为基于标签共现的邻接矩阵。该模块的输出为标签嵌入El={eil}ni=1∈Euclid Math TwoRApn×d和标签组嵌入Eg={eig}mi=1∈Euclid Math TwoRApm×d,其中m为标签簇数,d为标签特征向量的维数。文本特征提取模块采用双向LSTM网络来获取文档的特征向量,BiLSTM网络从正反两个方向同时对文本单词序列进行更新,即xi、xi,将两者连接起来作为单词的最终特征表示xi=[xi,xi]∈Euclid Math TwoRAp2D,i∈[1,N],其中N为文本序列长度,D为隐藏层神经元个数。
在获取文本特征向量之后,语义引导注意模块可以通过注意机制依次将每个单词特征向量xi与学习到的标签嵌入El和组嵌入Eg相结合,利用标签语义与单词特征表示之间的注意分数对单词特征进行加权,以此引导文本特征学习过程中关注重要的单词特征,最终可以将单词的表征聚合成文档特征表示,得到包含标签级语义的文本表示Ml和包含标签组级语义的文本表示Mg。将两部分连接起来Ml‖Mg,并采用全连接层对文本标签进行预测,损失函数为交叉熵损失函数:
L1=-∑Ni=1[yi log (σ(i))+(1-yi) log (1-σ(i))](1)
2.2 标签组嵌入模块
为了充分捕获标签之间的高阶相关性,本文构建了标签组嵌入模块来生成标签语义嵌入El和标签组嵌入Eg,分别表示标签的局部语义和全局语义。
2.2.1 语义标签嵌入
GAT是一种基于自注意力的模型,通常用于学习图结构的节点特征,GAT以节点标签特征矩阵H∈Euclid Math TwoRApn×d和相应的邻接矩阵A∈Euclid Math TwoRApn×n作为输入,通过节点更新机制对标签进行更新,进而从标签图中得到包含标签相关性的语义标签嵌入El,其中n表示标签个数,d表示标签特征维数。
在节点更新过程中,首先计算第一个GAT层中第i个标签和它的邻近标签j之间的注意力系数:
αij=exp(LeakyReLU(αT(Whi‖Whj)))∑k∈Euclid Math OneNApi exp (LeakyReLU(αT(Whi‖Whj)))(2)
其中:α∈Euclid Math TwoRAp2d′×1和W∈Euclid Math TwoRApd′×d是可学习的权重矩阵;hi∈Euclid Math TwoRApd是标签i的特征向量;Euclid Math OneNApi是图中标签i的领域集合;‖表示级联操作。然后通过注意力系数对邻近节点的标签特征进行加权,从而得到节点i更新后的节点特征:
eil=σ(∑j∈Euclid Math OneNApiαijWhj)(3)
从第一个GAT层得到的标签嵌入为E1l={eil}ni=1。第t个GAT层语义标签嵌入Etl可由下式生成:
Etl=GATt,embed(Et-1l,A)(4)
2.2.2 语义组嵌入
在实际的多标签分类场景中,数据集的标注结果可能包含噪声或缺失标签,仅仅学习特定于标签的语义表示可能不足以作出正确的预测,因此考虑进一步学习多个标签的全局表示,以此更加充分地学习标签的依赖信息。GAT的结构是扁平的,在学习标签的过程中会忽略图中可能出现的层次结构,所以在获得GAT层更新的语义标签嵌入El后,为了有效地捕获多个标签之间的全局语义,继续对El进行可微分池化(DiffPool)[28]。Diffpool是一种将图节点软映射到一组簇的图聚类算法,它可以将相似的标签特征节点进行聚类,得到标签语义组嵌入,这种层级化的方式可以同时捕捉到标签的局部特征信息和多个标签共享的全局特征信息。一旦捕获语义标签嵌入El,就可以應用DiffPool生成语义组嵌入Eg:
Eg=DiffPool(El,A)(5)
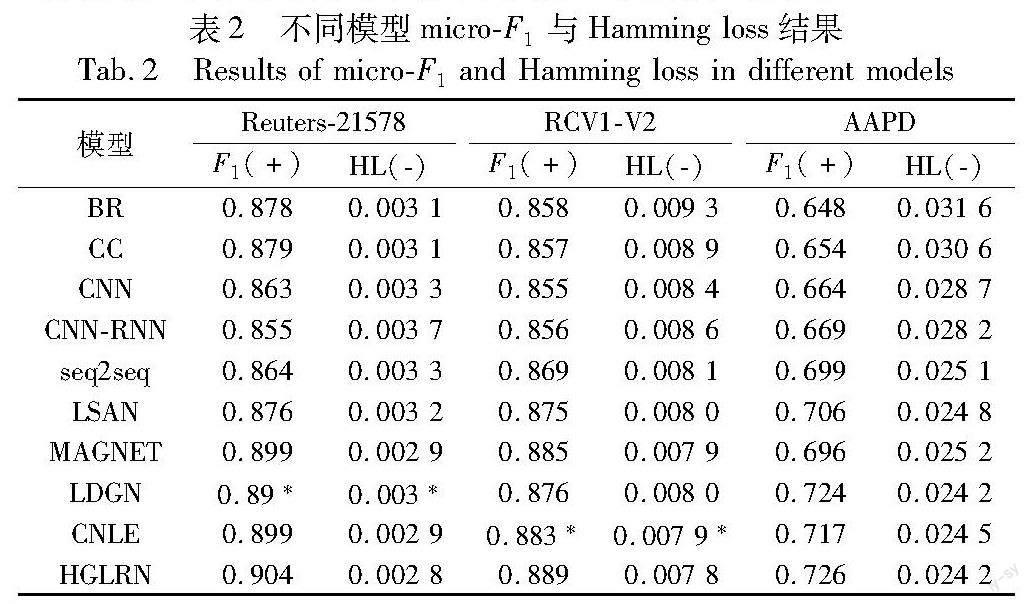
在可微分池化过程中,pooling层利用第t个图注意层的输出节点特征E(t)和邻接矩阵A(t)作为输入信息,经过pooling层后,节点信息将会被聚集到m(m E(t+1),A(t+1)=DiffPool(E(t),A(t))(6) 该过程中利用一个可学习的权值矩阵S(t)将每个节点映射到对应的簇中,通过该权值矩阵可以输出新的特征矩阵和邻接矩阵: E(t+1)=S(t)TE(t)(7) A(t+1)=S(t)TA(t)S(t)(8) 其中:E(t+1)∈Euclid Math TwoRApnt+1×d、A(t+1)∈Euclid Math TwoRApnt+1×nt+1为更新后的标签特征矩阵和邻接矩阵;S(t)同样也是定义在图结构上的矩阵。 S(t)=softmax(GATt,pool(E(t),A(t)))(9) 其中:S(t)∈Euclid Math TwoRApnt×nt+1,利用softmax函数可以得到各个节点划分到下一层各个簇的概率。 此外,为了学习更加紧凑的群嵌入,本文加入正则化项,将组嵌入Eg与标签嵌入El之间的距离最小化,如下所示。 L2=∑mk=1∑Eil∈Ck‖Ekg-Eil‖2(10) 其中:Ck为第k个高度相关的标签簇。 2.3 文本特征提取模块 本文采用双向LSTM网络来获取文档的特征向量。首先需要文本预处理,然后使用BERT来嵌入单词,再输入到BiLSTM网络中,BiLSTM从正反两个方向更新文本序列X,更新后每个单词的隐藏状态为 xi=LSTM(xi-1,xi)(11) xi=LSTM(xi-1,xi)(12) 其中:xi、xi分别表示文本第i个单词正向和反向更新后的隐藏状态输出。然后将这两个方向输出的单词特征向量连接起来,得到第i个单词的最终隐藏表示: xi=[ xi,xi](13) 整个文本特征提取过程可以表示为式(14),X为学习的文本语义特征: X=fBiLSTM(fBERT(s;θBERT);θBiLSTM)∈Euclid Math TwoRApN×2D(14) 其中:s为文档句子;θBiLSTM为网络参数;θBERT为词嵌入的参数;N为文本序列长度;D为BiLSTM的隐藏层神经元个数。 2.4 语义引导注意模块 语义引导注意模块的目的是利用标签语义嵌入El和Eg来引导文本语义表示的学习,以此将提取的标签依赖信息纳入模型当中。首先采用文本单词序列特征分别与标签嵌入、标签组嵌入之间的Hadamard乘积来计算注意权值: sli=X⊙eil(15) sgj=X⊙ejl(16) 然后利用softmax函数对计算得到的注意分数进行归一化处理,得到标准化注意分数al∈Euclid Math TwoRApC×d和ag∈Euclid Math TwoRApm×d,如下所示。 ali=exp(sli)∑iexp(sli)(17) agj=exp(sgj)∑jexp(slj)(18) 得到标准化的注意力分数后,应用第二个Hadamard乘积对文本各单词特征进行加权,以引导在文本特征学习过程中关注对标签语义重要的单词,并且将各单词的表征聚合成文档向量: Ml=∑ial⊙X(19) Mg=∑jag⊙X(20) 通过上式最终得到了包含局部标签信息的文本表示Ml∈Euclid Math TwoRApC×d和包含全局标签信息的文本表示Mg∈Euclid Math TwoRApm×d。 模型的最后为分类模块,首先连接包含标签局部语义信息的文本表示Ml和包含标签共享语义信息的文本表示Mg,再加上一个全连接层,利用sigmoid分类器即可实现分类,通过式(21)来进行标签预测: =σ(fC tanh(Ml‖Mg))(21) 其中:σ(·)和tanh(·)为非线性激活函数;fC为全连接层;L1+λL2为总训练损失,λ为正则化参数。 3 实验 3.1 数据集介绍 表1展示了实验中使用的数据集的详细信息。 Reuters-21578是从路透社收集的新闻文件,该数据集共10 788个文档,其中训练文本7 769份,测试文本3 019份,共90个标签类别。 RCV1-V2数据集由路透社提供的新闻专线文章分类而成。每个新闻专线故事有多个主题,整个数据集共103个主题,包含781 265个用于训练的文档和23 149个用于测试的文档。 AAPD(arxiv academic paper dataset)为论文数据集,共包含55 840篇学术论文,每篇论文有多个主题。AAPD数据集分为44 672个文档进行训练,11 168个文档进行测试,共54个类别。 3.2 参数设置及评价指标 本文在NVIDIA TESLA V100-32G显卡上使用PyTorch进行实验,在训练过程中,使用BERT预训练模型对文档句子和标签进行编码,词嵌入维度大小d为768维,BiLSTM的层数为2,隐藏状态的维度设置为256。语义标签嵌入由两个GAT层组成,第一个GAT层的输出特征维度和第二层的输入特征维度均为768,第二层的输出特征维数和标签组输入维度为512。在GAT层后面加上一个DiffPool层,DiffPool层中有两个超参数,即标签的组数m和正则化参数λ。关于各数据集中超参数的选取,将在3.5节中进行详细分析。对于所有数据集,使用Adam优化器来最小化损失函数,批量大小batch size设置为32,学习率lr初始化为0.001,并且在网络中加入了dropout方法防止过拟合,概率设置为0.5。 本文使用多标签文本分类任务中的两个主要评价指标F1分数(micro-F1)和汉明损失(Hamming loss)来评估模型。F1分数越大,损失越小,分类算法的性能越好。 3.3 结果分析 在三个数据集上评估所提模型,以观察模型在这些数据集上的性能,并且选取基线模型进行对比,包括传统机器学习方法的BR[29]、CC[30]模型,以及基于深度神经网络的CNN[14]、CNN-RNN[22]、seq2seq[31]、LSAN[26]、MAGNET[23]、LDGN[32]、CNLE[27]模型。表2展示了多个模型在各数据集上的micro-F1和Hamming loss。其中HL表示Hamming loss,F1表示micro-F1,标有*的为复现结果,其他为原论文引用结果。 从表2可以看出,HGLRN在两个性能指标方面表现优异,超越其他模型,取得了良好的效果。常用的基线模型BR、CC、CNN、CNN-RNN、seq2seq在这三个数据集上的性能表现相差不是很大。其中BR和CNN没有利用任何标签信息,包括标签之间以及标签文本之间的相关性;CC通过构建二分类问题的贝叶斯条件链建模标签之间的关系,但忽略了标签跟文档的关系;同样CNN-RNN也没有考虑标签和文档之间的相关性,性能与CNN模型相当;而seq2seq模型中同时考虑了这两种依赖关系,因此取得了不错的分类效果。与基线模型相比,本文模型取得了显著的性能提升。 LSAN标签特定注意网络,可以生成特定于标签的文本表示,通过注意力机制将标签和文本信息融合在一起,其在micro-F1上相比前几个基线模型,性能有了明显的提升,而本文模型相较于LSAN,在Reuters-21578、RCV1-V2、AAPD三个数据集上micro-F1分数分别提高了2.8%、1.4%、2%,并相应降低了Hamming loss,进一步证实了本文模型相較于之前的模型有显著的优势。 MAGNET、LDGN、CNLE模型的分类效果大幅超过以往的基线模型,因为这些模型专注于标签依赖信息的学习。本文模型相比这几个模型有着进一步的提升,在这三个数据集上的micro-F1分数分别提高了0.5%、0.4%和0.2%。这是因为本文模型在学习标签的过程中进一步引入了标签组嵌入,可以更好地学习标签的全局语义,同时利用单词与标签的相关性来引导文本特征的学习,从而提升了模型最终的分类效果。 3.4 消融實验 除了与各基准方法整体性能比较之外,本文还进行了消融实验,以评估模型中不同组件的有效性。 为了验证标签组嵌入模块的有效性,将该模块的简化版本进行实验,即对比本文模型框架中不使用LGE模块(No LGE)、仅使用标签嵌入(Label-E)、仅使用标签组嵌入(Label-G)、使用完整LGE模块(HGLRN)四个实验。另外,为了验证标签文本注意机制的有效性,同样简化语义引导注意模块,去掉标签文本之间的注意力,直接将文本特征与标签语义进行点乘交互(No SG_Att)。图2展示了三个数据集上的消融实验结果。 消融实验结果显示,在三个数据集上没有利用任何标签依赖信息的No LGE模型的F1分数均为最低,分类性能与其他模型相比差很多,相较于不使用LGE模块,考虑仅仅加入标签嵌入和仅仅加入标签组嵌入效果均有明显的提升,说明了学习标签的依赖信息能够显著地提升分类效果,而加入整个LGE模块的分类效果最好。因为它同时学习了标签的局部和全局语义,可以更加充分地捕捉到标签之间的依赖信息,结果清楚地展示了整个标签组嵌入模块LGE的有效性。在三个数据集上去掉标签注意机制的模型No SG_Att与HGLRN相比,F1分数会相应降低,表明文本标签注意力机制对提升模型性能是有利的,可以利用文本和标签语义的依赖信息,更好地提取文本特征。 为了更加充分地阐述标签组嵌入模块的重要性,从AAPD数据集中选取了几个典型的示例,如表3所示,展示了这几个示例在加入标签组嵌入模块LGE前后的标签预测结果。从表中可以看出来,对于文本1而言,No LGE的预测结果为cs.CV、stat.ML、cs.CL标签,而加入标签组嵌入模块LGE后,HGLRN能够结合标签的依赖信息进行标签预测,进而移除了不相关的cs.CL标签。文本2中,HGLRN在No LGE模型预测基础上增加了一个正确标签math.IT。对于文本3,HGLRN在No LGE模型预测基础上删除了一个不相关标签cs.IT,且同时预测出了标签cs.SI。从上述示例可以看出,HGLRN模型通过标签组嵌入模块,充分学习标签之间的依赖信息,能够显著地提升文本分类效果。 为了更加直观地观察文本标签注意机制的有效性,对AAPD数据集中一个实例的注意力权重进行可视化。不同标签下不同单词的贡献各异,可视化图中颜色越深,表示该词被分配到越大的注意力权重。由于注意力机制的存在,提出模型可以为标签选择最相关的语义信息,实验结果如图3所示。 图3中示例文本的真实标签为“Physics and Society(phy-sics.soc)”“Computers and Society(cs.cy)”和“Computational Engineering,Finance,and Science(cs.ce)”,模型在分类时侧重于相关度高的单词,如“digitalization”“energy management”“consuming systems”“foundations”“evolutions”等,这表明HGLRN所使用的标签注意机制可有效提取与标签语义相关且最显著的内容,以建立更具分类价值的文本表示。 3.5 参数敏感性 在这一节中主要研究模型中两个超参数设置的敏感性,即标签簇数 m 和正则化参数λ,在三个数据集上分析不同的参数取值对模型性能的影响。首先在Reuters-21578数据集上,对于组数 m ,分别取值10、20、30、40、50、60这几种不同情况进行实验,λ 则固定为10-3。图4(a)中的实验结果表明,当m取值为20时,F1分数最高,分类性能最好。然后固定组数为20,研究不同的λ取值{10-1,10-2,…,10-6}对分类效果的影响,结果如图4(b)所示,从图中结果发现,参数λ的取值对模型性能不是很敏感。根据实验结果,m最终设置为20,λ设置为10-3。 同样在RCV1-V2和AAPD数据集上也进行了消融实验,首先固定λ为10-3,研究F1分数随m的变化情况。可以发现,在RCV1-V2和AAPD数据集上的m分别取30和15时,F1分数最高,因此分别将组数m固定为30和15,研究不同的λ取值对分类效果的影响,结果如图5、6所示。根据图中的实验结果,最终在RCV1-V2数据集上选取组数m为30,正则化参数λ选取10-2。在AAPD数据集上,选择组数m为15,同时将正则化参数λ设置为10-3。 4 结束语 本文提出了一种用于多标签文本分类的层级图标签表示网络,构建的层级图结构同时考虑了标签的局部语义和全局语义,并通过注意机制引导文本语义表示的学习,充分利用了标签的依赖信息。实验结果表明,本文模型性能优于许多方法。 尽管本文模型性能具有竞争优势,但仍然存在一些局限性,在学习标签的相关性时仅仅利用训练数据集中的标签共现度,而忽略了对标签关系的方向和类型的建模,进一步考虑标签间的多种依赖关系可能会取得更好的分类效果。 参考文献: [1]郝超,裘杭萍,孙毅,等.多标签文本分类研究进展[J].计算机工程与应用,2021,57(10):48-56.(Hao Chao,Qiu Hangping,Sun Yi,et al.Research progress in multi-label text classification[J].Computer Engineering and Applications,2021,57(10):48-56.) [2]Tang Duyu,Qin Bing,Liu Ting.Document modeling with gated recurrent neural network for sentiment classification[C]//Proc of Confe-rence on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2015:1422-1432. [3]Chen Jianshu,He Ji,Shen Yelong,et al.End-to-end learning of LDA by mirror-descent back propagation over a deep architecture[C]//Proc of the 28th International Conference on Neural Information Processing Systems.Cambridge,MA :MIT Press,2015:1765-1773. [4]Kumar A,Irsoy O,Ondruska P,et al.Ask me anything:dynamic me-mory networks for natural language processing[C]//Proc of Interna-tional Conference on Machine Learning.New York:ACM Press,2016:1378-1387. [5]Gopal S,Yang Yiming .Multilabel classification with meta-level features[C]//Proc of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM Press,2010:315-322. [6]邓维斌,王智莹,高荣壕,等.融合注意力與CorNet的多标签文本分类[J].西北大学学报:自然科学版,2022,52(5):824-833.(Deng Weibin,Wang Zhiying,Gao Ronghao,et al.Integrating attention and CorNet for multi label text classification[J].Journal of Northwest University:Natural Science Edition,2022,52(5):824-833.) [7]Zhang Qianwen,Zhang Ximing,Yan Zhao,et al.Correlation-guided representation for multi-label text classification[C]//Proc of the 30th International Joint Conference on Artificial Intelligence.2021:3363-3369. [8]肖琳,陈博理,黄鑫,等.基于标签语义注意力的多标签文本分类[J].软件学报,2020,31(4):1079-1089.(Xiao Lin,Chen Boli,Huang Xin,et al.Multi-label text classification based on label semantic attention[J].Journal of Software,2020,31(4):1079-1089.) [9]Wang Tianshi,Liu Li,Liu Naiwen,et al.A multi-label text classification method via dynamic semantic representation model and deep neural network[J].Applied Intelligence,2020,50:2339-2351. [10]吕学强,彭郴,张乐,等.融合BERT与标签语义注意力的文本多标签分类方法[J].计算机应用,2022,42(1):57-63.(Lyu Xueqiang,Peng Chen,Zhang Le,et al.Multi-label text classification based on BERT and label semantic attention[J].Journal of Computer Applications,2022,42(1):57-63.) [11]Clare A,King R D.Knowledge discovery in multi-label phenotype data[C]//Proc of the 5th European Conference on Principles of Data Mi-ning and Knowledge Discovery.Berlin :Springer-Verlag,2001:42-53. [12]Elisseeff A,Weston J.A kernel method for multi-labelled classification[C]//Proc of the 14th International Conference on Neural Information Processing Systems Natural and Synthetic,2001:681-687. [13]Zhang Minling,Zhou Zhihua.ML-KNN:a lazy learning approach to multi-label learning[J].Pattern Recognition,2007,40(7):2038-2048. [14]Kim Y.Convolutional neural networks for sentence classification[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2014:1746-1751. [15]Zhang Xiang,Zhao Junbo,LeCun Y.Character-level convolutional networks for text classification[C]//Proc of the 28th International Conference on Neural Information Processing Systems.Cambridge,MA:MIT Press,2015:649-657. [16]Hu Haojin,Liao Mengfan,Zhang Chao,et al.Text classification based recurrent neural network[C]//Proc of the 5th IEEE Information Technology and Mechatronics Engineering Conference.Piscataway,NJ:IEEE Press,2020:652-655. [17]Wang Ruishuang,Li Zhao,Cao Jian,et al.Convolutional recurrent neural networks for text classification[C]//Proc of International Joint Conference on Neural Networks.Piscataway,NJ:IEEE Press,2019:1-6. [18]Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2017:6000-6010. [19]Devlin J,Chang M W,Lee K,et al.BERT:pre-training of deep bidirectional transformers for language understanding[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2019:4171-4186. [20]Liu Huiting,Chen Geng,Li Peipei,et al.Multi-label text classification via joint learning from label embedding and label correlation[J].Neurocomputing,2021,460:385-398. [21]Kurata G,Xiang Bing,Zhou Bowen.Improved neural network-based multi-label classification with better initialization leveraging label co-occurrence[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Stroudsburg,PA:Association for Computational Linguistics,2016:521-526. [22]Chen Guibin,Ye Deheng,Xing Zhenchang,et al.Ensemble application of convolutional and recurrent neural networks for multi-label text categorization[C]//Proc of International Joint Conference on Neural Networks.Piscataway,NJ:IEEE Press,2017:2377-2383. [23]Pal A,Selvakumar M,Sankarasubbu M.MAGNET:multi-label text classification using attention-based graph neural network[C]//Proc of the 12th International Conference on Agents and Artificial Intel-ligence.2020:494-505. [24]Ozmen M,Zhang Hao,Wang Pengyun,et al.Multi-relation message passing for multi-label text classification[C]//Proc of ICASSP-IEEE International Conference on Acoustics,Speech and Signal Processing.Piscataway,NJ:IEEE Press,2022:3583-3587. [25]Du Cunxiao,Chen Zhaozheng,Feng Fuli.Explicit interaction model towards text classification[C]//Proc of the 33rd AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2019:6359-6366. [26]Xiao Lin,Huang Xin,Chen Boli,et al.Label-specific document representation for multi-label text classification[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2019:466-475. [27]Liu Minqian,Liu Lizhao,Cao Junyi,et al.Co-attention network with label embedding for text classification[J].Neurocomputing,2022,471:61-69. [28]Ying Z,You Jiaxuan,Morris C,et al.Hierarchical graph representation learning with differentiable pooling[C]//Proc of the 32nd International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2018:4805-4815. [29]Boutell M R,Luo Jiebo,Shen Xipeng,et al.Learning multi-label scene classification[J].Pattern Recognition,2004,37(9):1757-1771. [30]Read J,Pfahringer B,Holmes G,et al.Classifier chains for multi-label classification[C]//Proc of the 20th European Conference on Machine Learning.Berlin:Springer,2009:254-269. [31]Yang Pengcheng,Sun Xu,Li Wei,et al.SGM:sequence generation model for multi-label classification[C]//Proc of the 27th International Conference on Computational Linguistics.Stroudsburg,PA:Association for Computational Linguistics,2018:3915-3926. [32]Ma Qianwen,Yuan Chunyuan,Zhou Wei,et al.Label-specific dual graph neural network for multi-label text classification[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2021:3855-3864.
