基于视频的轨道车辆自主定位方法研究
2024-03-04谢远翔谢兰欣安雪晖曾小清
沈 拓, 谢远翔, 盛 峰, 谢兰欣, 张 颖, 安雪晖, 曾小清
(1. 同济大学 上海市轨道交通结构耐久与系统安全重点实验室,上海 201804;2. 清华大学 土木水利学院,北京 100084;3. 中电建路桥集团有限公司,北京 100070;4. 上海泽高电子工程技术股份有限公司,上海 201900)
车辆定位技术作为列车运行控制系统中的一项关键技术,为高速铁路列车运行控制系统实时提供可靠的速度和位置信息,其定位精度将影响列车运行效率、安全性和服务质量。将车辆定位技术用于高速铁路施工车辆定位,现有轨道车辆定位方式,主要是以“车载+轨旁”测量方式来实现“误差累积+复位”。该定位模式强依赖于轨旁设备和信号系统,不仅存在轨道交通线路建设难度大,维修成本高等问题,而且列车长期运行会出现因轨旁设备或信号系统故障,导致传输过程中列车定位失效,从而影响轨道交通的运营秩序。此外,地铁的运行环境多为地下长隧道,因此全球导航卫星系统(global navigation satellite system,GNSS)等精准定位方法不具有适用性。现行轨道车辆定位方法主要有轨道电路定位方法、查询应答器/信标定位方法、无线扩频定位方法、全球卫星导航定位和地图匹配方法,但这些方案依赖信号系统传输数据,易受干扰和控制,且无法避免特殊环境如大量长隧道运行环境下卫星信号较差的局限性。随着下一代高速铁路列控系统中的列车测速定位系统精确性、实时性,可靠性等应用需求越来越高,“车载中心化”的列车自主定位方式已成为新的研究发展方向。
基于视觉的前方目标定位测速测距方法因具有远量程、非接触和高精度等特点,很多学者致力于使用单幅图像来实现车辆路径的保持和跟踪,车辆导航和定位等。轨道交通的视觉定位研究主要有基于人工标志的定位[1-3]、实时定位与建图[4-5](simultaneous localization and mapping,SLAM)和基于局部运动估计的定位[6-7]三种类型,具有远量程、非接触等优点,但是易受光照影响。随着图像处理技术的不断发展,视觉传感器等硬件成本的不断降低,其环境适应性和感知准确性都得到较大幅度提升,将为车辆定位研究提供更加精确可靠的基础性能保障。
为适应全自动运行列车技术的发展和推广,并能够满足负责调车作业和抢险救援等的轨道工程车的自主定位需求,本研究提出一种基于列车前视相机拍摄百米标视频的轨道车辆自主定位方法。百米标是设置在轨道线路旁的一类标识,表示正线每百米距离该线路起点的长度。因此,利用视频识别到轨旁百米标数字编号即可确定百米标的位置信息,从而实现对线路运行列车定位。该方法分别构建了百米标目标检测模型和百米标数字文本识别模型。首先针对轨道交通环境复杂、轨旁标识多样、百米标成像小和定位性能要求,使用单阶段类型的YOLOX 目标检测算法并进行改进,实现复杂环境下的百米标检测;其次,在检测到百米标之后,为解决百米标文本倾斜模糊、光线不均等问题,提出一种结合图像预处理的改进卷积循环神经网络(convolutional recurrent neural network,CRNN)百米标文本识别算法,实现对百米标的线路位置信息提取,从而完成对轨道车辆的定位。最后通过实验验证了算法的有效性和环境适应性。
1 基于改进YOLOX的百米标目标检测
YOLO 算法是由旷视科技于2021 年提出的新一代YOLO系列目标检测算法。YOLOX网络在提升检测速度的同时兼具相当的检测精度,正被广泛应用于各个领域对的目标检测任务中。YOLOX 网络主要由4 个模块构成,分别是输入模块Inputs、网络主干模块Backbone、特征增强模块Neck以及预测模块Prediction。
1.1 YOLOX算法改进
针对前文所述的百米标检测存在的问题,本研究选取综合性能最好的YOLOX-s 网络进行改进并构建百米标目标检测模型,来完成百米标检测的任务。在进一步提高识别准确率的同时,保持原模型的轻量化和检测速度。首先在Mixup和Mosaic图像增强的基础上继续增加随机改变亮度、对比度、旋转以及加入高斯噪声等方式完成数据增强,以适应轨道交通光线变化范围广的复杂环境。然后,改进原YOLOX-s网络结构以提升检测速率和精度,具体方法为:基于原YOLOX-s 框架,在主干网络CSPDarknet 的CSPLayer 结构中引入注意力机制(efficient channel attention,ECA),增强重要特征;引入自适应空间特征融合(adaptive spatial feature fusion,ASFF),使得提取后的三个特征层自适应地学习各尺度特征,增强特征融合效果;最后对损失函数进行优化,以提高模型精度和加快收敛速度。
1.1.1 CSPLayer引入ECA注意力机制
注意力机制的原理可简单地描述成通过某些网络来学习特征权重,得出各特征图重要程度,以及基于上述计算的重要程度,给各特征图赋予权重值。以便于让神经网络把注意力集中在重要的特征图上,通过增强重要特征向量且削弱不重要特征向量来优化模型[8]。本研究将ECA 注意机制引入到YOLOX 的主干网络的CSPLayer 结构中,网络将更加关注重要特征的提取。具体步骤如下:
(1)首先输入特征图x,维度是H*W*C;
(2)对输入特征图进行空间特征压缩,使用全局平均池化(global average pooling,GAP)方法,得到1*1*C的特征图;
(3)对压缩后的特征图进行通道特征学习;采用自适应内核尺寸(设卷积核大小为k)的一维卷积方式实现局部跨通道的信息交互,通过Sigmoid激活函数,此时输出的维度还是1*1*C;
卷积和自适应函数定义如下:
式中: |t|odd表示距离t最近的奇数;γ和b是线性参数,分别取值为2和1。
(4)完成通道注意力结合,将通道注意力的特征图1*1*C、原始输入特征图H*W*C进行逐通道乘,最终输出具有通道注意力的特征图,维度是H*W*C。

图1 两种IoU交并比计算情况Fig. 1 Calculation of two IoU cross-combination ratios
1.1.2 Neck网络引入ASFF机制
特征金字塔网络(feature pyramid network,FPN) 结构会导致检测结果受不同层的特征影响,如果目标在某一层中被判断为正类后,其他层会将其判断为负类。然而当特征融合时,判别为负类的无用信息可能也会被融合,从而产生大量冗余信息。因此本研究在路径聚合特征金字塔网络(path aggregation feature pyramid network,PAFPN)尾部添加自适应空间特征融合ASFF机制[9],能够自适应地学习不同尺寸特征的融合权重,而不是基于元素和抑或级联方式的特征融合。该方法可以缓解特征金字塔中不同尺度特征的不一致性缺点,达到最优融合效果。
将PAFPN 中的三个不同尺度的特征图通过ASFF机制,学习融合权重,理解不同特征尺度在预测特征图中的贡献程度,最后融合成对应尺度的三个特征图。以ASFF3 为例,经过PAFPN 得到的三个不同尺度的特征层Level 1~3,通过分别与权重参数α、β、γ相乘,然后相加,就得到了ASFF3,上述过程可描述如下:
式中:y(l)ij为通过ASFF 特征融合得到的新特征图;分别为第1、2、3 层到第l层特征层的特征向量分别为三个不同特征层的权重参数。
由于求和公式要求各层特征维度保持一致,因此还需要通过下采样且调整通道数的方式对各层特征进行降维。对于权重参数α、β、γ,经过拼接之后通过softmax 函数使其范围都在[0,1]内,并且和为1,上述过程可由式(3)来描述(λ(l)表示与网络的第l层相关的一个超参数,用于调整softmax函数中指数的尺度):
1.1.3 损失函数优化
YOLOX-s网络会生成大量检测帧,大多数的检测帧都是负样本。损失函数中负样本数量过多会导致正样本权重较小,从而对网络最终训练效果造成影响。对此,本研究对于损失函数的改进方法如下:
(1)对象置信度损失函数改进
对象损失函数利用置信度来判断边界框内的目标是否为正负样本,若超过置信度阈值,则判定为正样本,若小于置信度阈值,则判定为负样本(即背景)。由于百米标检测场景下,被检测目标较小,会存在大量负样本,若使用二元交叉熵损失函数BCEloss对目标置信度进行回归,很难克服YOLOXs因负样本过多而导致权重不平衡的问题。因此,本研究试图对YOLOX-s 算法中的置信度损失函数进行改进,把 BCEloss函数改进为 Focalloss函数,该损失函数能够降低负样本所占权重,以确保网络训练过程更加专注于正样本。Focalloss损失函数公式如下:
式中:αp为平衡参数,用于解决正负样本数量不均的问题,将其设置为0.35;pt为预测目标的置信度;γ是调制因子,将其设置为2。
关于对象类型的确定,仍沿用 BCEloss计算方法。计算公式如下:
(2)边界框回归损失函数改进
YOLOX-s 算法采用 IoUloss函数对检测目标边界框进行回归。IoU是计算框(prediction box, P)和真实框(ground truth box, G)的交并比,用于衡量P和G之间的距离,IoUloss的计算公式为
如图1a 所示,当所述预测框P 和所述真实框G没有重叠时,IoU=0,这时无法反映出两者的真实距离,此时若将IoU作为回归损失对模型进行回归,由于IoU为0,梯度无法回传更新。此外,如图1b所示,IoU 值相等,但这2 种情况下两者的真实距离不等。而IoU不能反映两者的回归效果。
而除 IoUloss函数外,常用的还有 GIoUloss、DIoUloss、CIoUloss等损失函数。
GIoU,首先计算P 与G 的最小封闭区域面积Ac,然后再采用 IoU 减去封闭区域中不含两个框的区域在封闭区域中的占比,GIoUloss损失函数计算公式为
GIoU清楚反映出两框的重合程度。但GIoU也存在问题:当P 完全包含G 时G 在P 内的分布位置不同或者当P完全被包含G时,P在G内的分布位置不同,GIoUloss仍然相同,此时也无法反映出各自回归效果。
DIoU,通过约束这个最小封闭区域面积和预测框、真实框中心点的位置,让网络学习移动P向G靠近。但 DIoUloss还存在一种问题:没有考虑P 与G的长宽比。DIoUloss损失函数公式为:
式中:ρ表示预测框与目标框中心点之间的欧几里得距离;c为能同时包含预测框和真实框的最小矩形对角线长度;(b,bGT)代表了预测框和真实框的中心点。
因此,本研究在DIoU 基础上把长宽比考虑进来,得到CIoU,即同时考虑了覆盖面积、中心点距离和长宽比三种情形。CIoU计算公式为
式中:v为P 与G 长宽比(h为框长,w为框宽)的距离,计算公式为
α是一个权重系数,计算公式为
计算 DCIoUloss损失函数的公式为
理论上说,CIoU 效果最好,因此,本研究将原YOLOX-s 算法边界框回归损失函数使用的 IoUloss函数改为 CIoUloss函数。
1.2 百米标目标检测
1.2.1 数据集制作
轨道交通线路上有设置指示线路状态和位置的线路标识,包括公里标、百米标、曲线标、坡度标等;也有设置指示司机完成相关作业的信号标识,包括警冲标、站界标、驾驶员鸣笛标、停车位置标等,这些线路标志的外形十分相似。因此,为防止百米标误检、漏检,需要把其他标识考虑在目标检测范围内。鉴于已有公开数据集并没有可以有效囊括轨道工况的数据,无法满足轨道环境检测应用需求。为适应本研究的百米标检测需要,采集某线路上列车前视相机拍摄的各类天气全天候运行视频,截取视频中高架、隧道、阴天、夜间等场景的视频帧制成图像数据集。
(1)图像数据增强
由于人工采集数据工作量大,并且数量仍然不充分。对此首先增加了大量基于实测轨道为背景的正、负样本数据;并且通过图像增强方法对数据集进行扩充,包括图像翻转、旋转、裁剪、缩放、颜色变换等,使用扩充后的数据集训练模型能够增强模型的鲁棒性和泛化能力。
(2)图像数据标注
本研究使用labeLImg 工具标注出被探测目标所属类别和目标区域,标签设为5 类常见标识:hundred、speedlimit、stationname、curve、warning,分别代表百米标、限速标、站牌、曲线标、警冲标。最后按照8:1:1 的比例将数据集划分为训练集、测试集和验证集。
1.2.2 模型训练
本研究将图像尺寸统一为640*640,Epoch 迭代次数设置为1 000,batch_size 设置为118,初始学习率为0.01,选择余弦退火衰减(Cosine annealing scheduler)动态学习策略,最低学习率为0.000 1,IoU 阈值设置为0.5。训练过程中Loss 损失如图2和图3所示。

图2 YOLOX-s训练过程Loss曲线Fig. 2 Loss curves of YOLOX-s training process
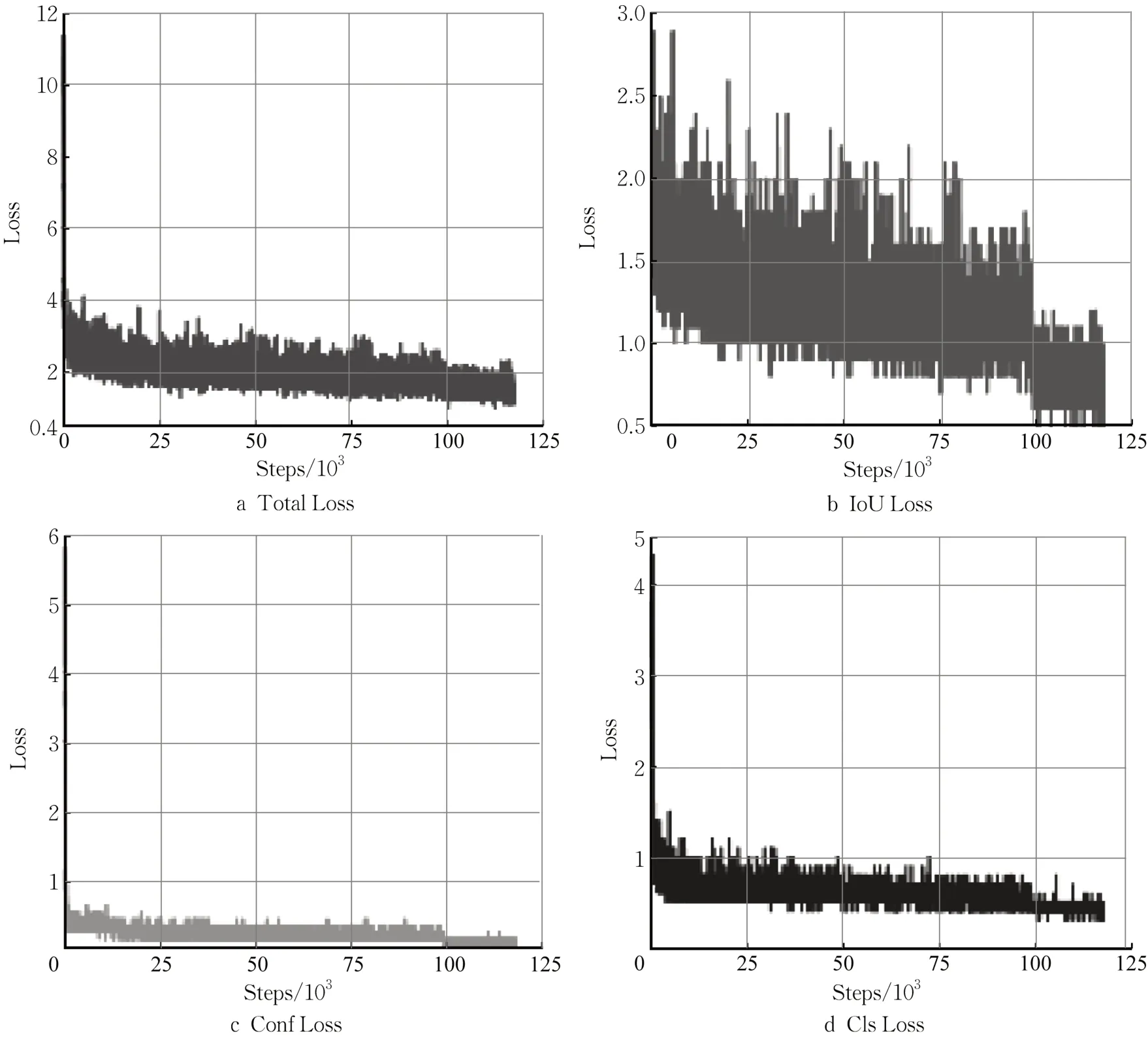
图3 改进YOLOX-s训练过程Loss曲线Fig. 3 Loss curves of improvement of YOLOX-s training process
2 基于改进CRNN 的百米表文本识别
检测到图像中含有百米标后,继续对百米标进行文本识别,以提取百米标的线路位置信息。文本识别的算法主要分为传统光学字符识别(optical character recognition,OCR)方法和基于深度学习OCR 算法两种。传统OCR 处理流程包括图像预处理、基于连通域的文本行检测、字符分割并提取特征、基于分类器的单字符识别和后处理输出5 个步骤。在背景简单的前提下能够精准识别文本序列,但在复杂环境下文本识别效果较差。
本研究需要识别的百米标数字序列存在运动模糊、噪声点多、目标小和文本倾斜等问题,因此本研究选择实际应用中效果更好的基于深度学习的OCR 算法。 其中,CRNN+CTC(connectionist temporal classification,连接主义时序分类)识别算法具有可以识别任意长度的文本,识别速度快,准确率高的优点,广泛应用于各个领域的识别任务中。因此本研究针对轨道交通特殊环境,使用图像预处理+改进CRNN+CTC 方法,来完成百米标的文本识别任务,提取百米标的位置信息。首先针对百米标进行图像预处理,便于提高后续CRNN 网络识别速率和准确率;然后使用CRNN+CTC 文本识别方法对百米标文本进行识别,提取出百米标的线路位置信息。
2.1 图像预处理
由于图像检测到的百米标文本序列存在运动模糊、目标小和文本倾斜等问题。因此,在使用CRNN网络进行文本识别之前,先对带有噪声的百米标图像进行处理。文本预处理流程如图4 所示,主要包括:图像裁剪、灰度化、二值化、倾斜检测与校正、图像平滑与图像规范化。
2.2 CRNN算法与改进
本研究选择的文本识别CRNN网络依次使用了CNN 结构和RNN 结构。图5 是CRNN 网络结构,前两部分卷积层(CNN)和循环层(RNN)都采用了基于结构相似性的特征提取方法,后者转录层(CTC)采用的是基于概率统计特性的特征抽取算法。

图5 CRNN网络结构Fig. 5 Structure of CRNN network
原CRNN 算法的特征提取的主干网络为VGG16网络,会存在梯度消失以及多层卷积之后信息丢失严重的问题,因此,本研究在VGG16 网络的第3 层和第4 层加入如图6b 所示的残差结构,选择残差卷积网络作为特征提取的主干网络。该网络以跨层连接(shortcut connection)的方式连接各层网络,能够提高网络计算效率和性能。
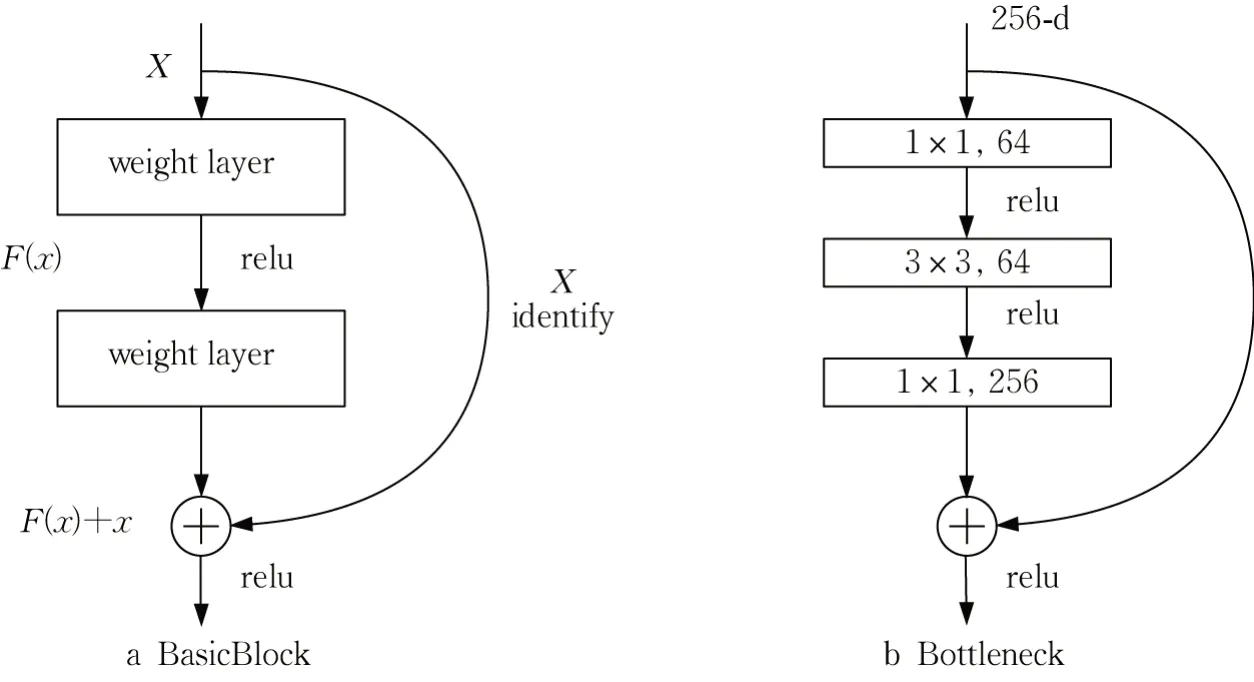
图6 残差单元结构Fig. 6 Structure of residual cell
残差学习模块有两种形式:两层结构称为BasicBlock(图6a),一般适用于Resnet18 和Resnet34。weight layer 卷积层为用于学习输入特征的权重,relu 为激活函数;三层结构称为Bottleneck(图6b),是对BasicBlock的优化,旨在缩小特征图的大小,由此减少参数量。
此种残差单元结构将F(x)学习的内容由x变为x的残差,由于残差的值是接近0 的,故模型学习比VGG每层堆叠更加高效,并且能解决训练集随着网络深度的增加误差反而增大的退化问题。
ResNet中任意一层的计算公式为
式中:xL为L层的特征信息;xl为比L层浅一层的特征信息;F(xi,wi)为残差函数。
2.3 百米标文本识别
2.3.1 文本图像预处理
百米标文本图像的预处理流程及对应的效果如图7所示。
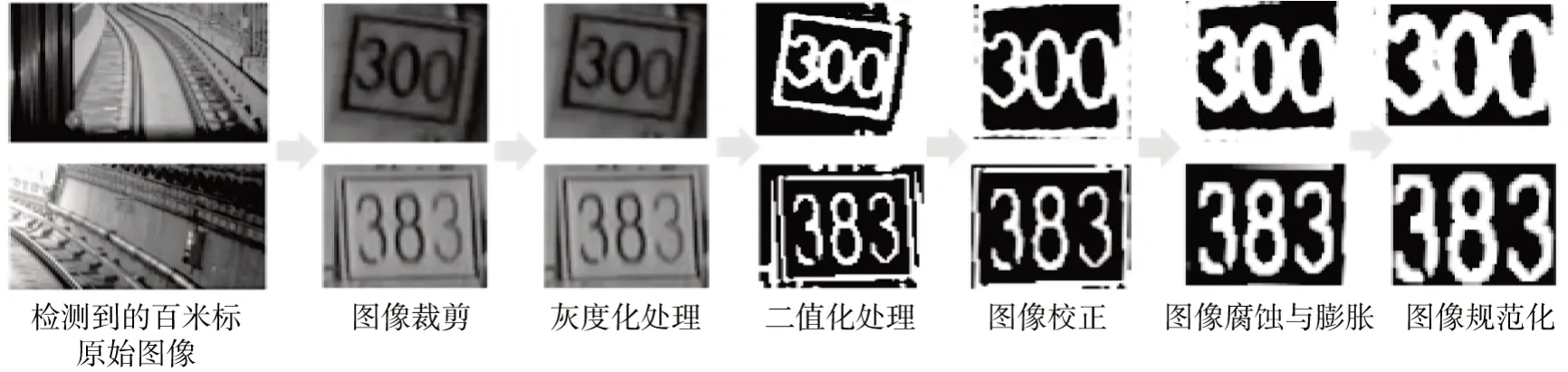
图7 百米标文本图像预处理流程Fig. 7 Preprocessing process of 100-metre sign text image
可以看到,此时的百米标不再倾斜,文本更加清晰,极大地降低了后续文本识别算法的计算量。在依次进行了图像裁剪、灰度化、二值化、倾斜检测与校正、图像平滑与图像规范化之后,生成的标准百米标图像作为后续CRNN网络的输入。
2.3.2 数据集制作
本研究参照ICDAR2015文本识别数据集格式,制作百米标文本识别数据集。标注文件如图8 所示。其标注格式为
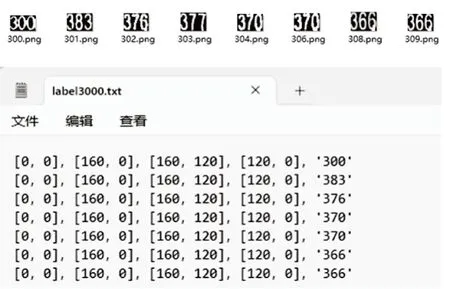
图8 图像文本标注示例Fig. 8 Annotation example of image text
其中,[x1,y1],[x2,y2],[x3,y3],[x4,y4]表示的是按顺时针方向标注文本位置的4 个顶点坐标,“XXX”代表文本内容。
2.3.3 模型训练
由于数字文本数量较少,可适当降低模型训练迭代次数,节省训练时间和消耗。本研究将模型参数batch_size设置为32,学习率设置为0.001,权重衰减系数为0.001,epoch 设置为300。CRNN 网络训练的Loss损失过程如图9所示。
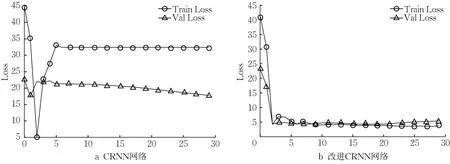
图9 文本识别网络训练过程的Loss曲线Fig. 9 Loss curves of text recognition network training process
3 实验结果与分析
3.1 实验环境
在PC机中基于Pytorch完成百米标线路位置信息提取所需的模型训练和测试,该框架可通过GPU加速优化,结构清晰,并且可移植性强,可以在嵌入式设备上使用。PC机具体配置见表1。

表1 实验环境配置Tab.1 Configuration of experimental environment
3.2 百米表目标检测实验结果与分析
本研究在相同的实验环境下以同样的方式进行训练,对改进YOLOX-s 算法和原始YOLOX-s 算法的百米标检测效果进行对比。结果如表2 所示,改进YOLOX-s 算法的mAP(mean average precision,平均精度均值)值为96.60 %,FPS(frames per second)为52 帧·s-1;原始YOLOX-s 算法的mAP 值为94.24 %,FPS 为51帧·s-1;平均精确率提升了约2 %,百米标精确率提升0.91 %,并且检测速度也有所提高。因此,改进YOLOX-s算法的百米标检测的准确率能够满足系统功能要求。

表2 改进YOLOX-s算法检测效果对比Tab. 2 Comparison of detection performance of improved YOLOX-s algorithm
图10a 为改进YOLOX 算法在高架上检测百米标效果,图10b为改进YOLOX算法在隧道里检测百米标效果。可以看出,当百米标距车辆较近时能被有效检测出,当小目标百米标距车辆较远且在高架环境里仍能被有效检测出。

图10 改进YOLOX-s算法百米标检测效果Fig. 10 Improvement of YOLOX-s algorithm for detecting 100-metre markers
本研究设置检测百米标是否有效的AP 判断阈值为80 %,当被检测百米标AP 值大于等于80 %,则判断该目标为有效目标,送入文本识别模型中。
3.3 百米表文本识别实验结果与分析
本研究在相同的实验环境下以相同的训练方式进行训练,对CRNN算法和改进CRNN算法的百米标文本识别效果进行对比。结果如表3 所示,在相同环境下,改进CRNN模型的准确率(PR)和召回率(RR)比CRNN 模型分别提高了3.52 %和3.48 %,并且检测速度也有所提高。可以看出,改进后的网络模型可以很好地满足系统在实际应用中的功能需求。

表3 改进CRNN文本识别算法检测效果对比Tab. 3 Comparison of detection performance of improved CRNN text recognition algorithm
CRNN 文本识别网络的输出结果由6种元素组成, 其输出格式为:
其中,前4 个元素为文本框的顶点坐标信息,′XXX′为分类结果,score为文本框置信度分数。
图11a为改进CRNN算法的百米标文本识别结果,图11b 为目标检测后的有效百米标通过图像预处理和改进CRNN算法的文本识别结果的可视化展示。以图11b 为例,该有效百米标的文本检测结果为321,则提取出百米标的线路位置信息为M321。

图11 改进CRNN文本识别结果Fig. 11 Text recognition results of improved CRNN
4 结语
本研究提出了一种适用于轨道交通复杂环境的基于百米标视频的轨道施工车辆自主定位方法。介绍以下流程:首先分析轨道交通复杂的轨旁环境特点和百米标成像特点;然后,针对轨道复杂环境、小目标检测和定位性能要求,选择YOLOX-s网络做改进并构建百米标目标检测算法,完成百米标的目标检测;若检测出图像含有百米标,则针对百米标文本倾斜模糊、光线不均等特点,结合图像预处理方法和改进CRNN 算法构建百米标数字文本识别模型,实现对百米标的文本识别,输出百米标的线路位置信息,从而实现对轨道车辆的定位。实验结果表明该方法能够快速准确定位轨道施工车辆的位置信息。
作者贡献声明:
沈 拓:建模,初稿撰写。
谢远翔:数据分析,修订论文。
盛 峰:方法思路,需求分析。
谢兰欣:数据搜集。
张 颖:算法测试。
安雪晖:框架建议。
曾小清:技术应用分析。
