基于计算叙事模型的虚假健康信息特征研究*
2024-03-01孔杉杉冯立超
孔杉杉 张 军 冯立超
(山东理工大学管理学院 淄博 255000)
0 引 言
数字技术的发展使微信、微博等为代表的开放式互动平台成为大众获取和分享健康信息的重要渠道,然而健康信息类型多样、内容丰富、信息质量却参差不齐[1],不同于网络上真实的健康信息,虚假健康信息往往以“故事”的形式,既借助诱导性、欺骗性文本汇集伪科学、哲学、民俗等复杂深刻的人文概念,又采用独特的数据叙事策略迎合了大众健康需求和情感需求,说服那些专业医学知识缺乏的在线用户[2],误导其健康决策和行为。
为准确识别和阻断虚假健康信息传播,学者们从信息源、主题标签、文本内容等多个角度开展虚假健康信息的特征提取和建模,发现根据信息来源和信息生成意图来进行信息可信度分析并不可靠[3-4],通过文本主题也很难辨别信息真伪[5]。关于文本内容的研究发现语言特征、语义特征和叙事方式等在辨别虚假信息时作用显著[6]。但是如何将这些特征抽取出来成为研究过程中的一个难点。计算叙事的研究范式可以通过标识事物、概念和组织等要素,抽取、泛化和构建语义三元组来刻画文本中的叙事特征,对于甄别虚假健康信息将非常有效。然而,以往的计算叙事研究对虚假信息特征的建模和语义分析方法时依赖于工作者的经验或知识,而虚假健康信息的甄别包含了大量的生活健康常识、观念和行为,涉及了专业的医学知识和技术[4],人工识别存在诸多困难。因此现有的计算叙事方法应用于虚假健康信息特征分析时效果较差,不能深入解释虚假健康信息特征之间的关联。
鉴于此,本文基于计算叙事的基本分析框架,提出虚假健康信息的计算叙事模型,通过文本挖掘技术提取叙事内容、叙事逻辑和叙事链接模式,实现虚假健康信息叙事特征的量化研究,并对比分析不同类型的虚假健康信息叙事特征。一方面创新了虚假健康信息特征识别研究视角,另一方面可以为政府和互联网平台阻断虚假健康信息传播提供决策支持。
1 文献综述
1.1 虚假健康信息特征研究
社交媒体上各类信息正处于爆炸式的增长阶段,从海量信息中准确识别虚假健康信息并采取措施阻断其传播,需要以厘清虚假健康信息特征为基础。目前相关研究可以分为特征提取和特征建模两条主线。
虚假健康信息特征提取多围绕信息来源、信息内容、信息传播者等传播要素特征开展。Winker等的研究发现虚假健康信息来源的可信度不高[3],因此构建了一套基于信息源的可信标注标准,包括作者信息完整性、单位来源权威性、利益冲突声明规范性等具体指标。后续研究关注到信息来源的内容生成意图,是无意散布错误信息,还是有意制造虚假健康信息并欺骗工作[4,8-9]。随着社交媒体应用的深入,结合文本挖掘技术提取虚假健康信息特征研究成为热点。Ghenai等以Twitter上的zika相关虚假健康信息和权威机构发布信息为研究对象,利用LDA技术对比了二者在主题数量、主题词等方面的差异,研究发现虚假健康信息主题数量多,且会频繁使用疫苗、发烧等词汇,而健康信息中不仅主题数量少,且上述词汇的使用频率也比较低[10]。Kabir通过Bert方法研究了新冠肺炎疫情发生后的虚假健康信息,结果显示宗教信仰主题和社会文化主题在识别算法中的作用比较显著[11]。Sicilia和Safarnejad的研究结果显示虚假健康信息文本的主题具有高度多样性,只用文本主题很难区分信息的真假[6,12]。
虚假健康信息特征建模研究大多是在社会影响、行为认知等多学科理论基础上开展。Metzger基于MAIN可信度模型构建了网络健康新闻可信度语料库,在此基础上通过SVM方法发现虚假健康信息不同主题可信度的关联十分微弱[13]。 Kumar 等基于“持续影响效应”理论[14],解释了虚假健康信息文本中存在大量负面情绪,且恐惧和愤怒等能在公众心里留下深刻印象,并且这种效应的持续时间比真实信息要长。Zhao等提出了基于精细化似然模型的虚假健康信息特征模型,其中文本主题特征是中心级特征,外围级特征包括语言特征、情感特征和用户行为特征等,且语言特征在甄别虚假信息过程中作用显著[2]。张帅等通过程序化编码的方法构建了虚假健康信息的关键特征清单,发现了夸张等语义特征是说服公众接受的一个主要原因[15]。此外,由于政府和机构辟谣策略,虚假健康信息语言表达更隐晦,学者们开始广泛的采用知识图谱等文本挖掘技术尝试对虚假健康信息中的错误观点和事实进行挖掘和建模。
1.2 计算叙事研究
19世纪80年代早期,社会学领域和心理学领域开启了叙事学研究,逐渐认识到“故事化”是形成社会认同和集体行动决策的有效引擎。在此基础上著名学者沃尔特·费希尔提出了叙事传播理论,他认为所有的人类交流活动都是叙事活动,是通过讲故事的形式反映社会经济中的不同实体之间的关联[16]。由于叙事传播的内容描述了某些特殊经历,它比逻辑严谨的科学论证更符合公众的认知水平[17],因此更容易激发大众的兴趣,并具有较高的说服力[18]。鉴于此,医学健康领域较早地引入这一理论来解释健康信息的作用机制。医学知识科普中会设计叙事内容对错误信息“增强纠正”[19],影响人们对疫苗的信念[20],激励和支持健康行为的改变[21]。在社交媒体上不同叙事逻辑对健康信息的采纳产生了差异化影响[22]。
人工智能和机器学习与NLP的深度融合,推动了诸如传播学、社会学等学科转向数据驱动的研究范式。在此背景下,Shiller等研究者提出可以利用互联网上的数字化痕迹,通过文本挖掘、数据分析等可计算性方法,对人类交流活动中的叙事特征开展描述、解释,并发现其背后的驱动机制,并将此领域命名为计算叙事学(Computational Narrative)[23]。研究者发现通过计算叙事研究范式,可以识别经济学、传统文化、医学等特定领域的社会思维和行为模式,而这些模式往往无法通过日常互动或阅读个人故事或想法来观察[24]。相关研究多通过标识事物、概念和组织等要素,抽取、泛化和构建<实体-关系-实体>三元组来刻画文本中的叙事特征[25]。例如, Ash等人利用语义中的行为三元组
此外,常用的计算叙事技术实现可以分成两类:一是基于规则模板的图谱技术,二是基于语义角色标注的浅层语言分析方法。基于规则模板构建实体和关系的过程中,需要人工编写因果关系、条件关系、顺承关系等规则模板,其优势是可以精准的发现实体关系。但是它依赖工作者的经验和知识,可能遗漏实体关联方式,泛化能力较差[29]。基于语言角色标注的方法是通过识别句子中的谓词和句法成分,自动抽取语义三元组并以<施动者-动词-受动者>的形式记录,其优势是不依赖人工标注就能产生结果。这种方法适用于处理文本内容中概念明确且逻辑关系简单的语料集,如新闻语料、政策语料等。但是在处理语义逻辑比较复杂的文本时,会以冗余的方式保留施动者和受动者,实体和关系的对齐效果差。而虚假健康信息文本中的实体关系类型多,多数句子的逻辑结构复杂。由此,准确识别和分析虚假健康信息的计算叙事特征,需要重新改进语义角色标注算法,既要尽量保留文本中的语义信息,还要适当对实体和关系进行降维。
综合上述文献可以发现,现有研究已经从多方面刻画了虚假健康信息的文本特征,且从计算叙事角度开展医疗健康研究是一种有效的途径。但是研究结果不能深入解释虚假健康信息特征之间的关联,对虚假健康信息特征的建模和语义分析方法研究还有待深入。借助计算叙事研究范式可以揭示虚假健康信息中有哪些错误健康知识和健康行为规范[30],解释其如何影响公众健康认知构建的方式[31]。因此,本文构建虚假健康信息的叙事模型,解决以下3个方面的问题:①虚假健康信息的计算叙事模型是什么?②如何提取虚假健康信息叙事特征?③不同类型虚假健康信息的叙事特征有哪些差异?
2 虚假健康信息计算叙事模型研究
2.1 虚假健康信息计算叙事模型
社交媒体上虚假健康信息的叙事过程基于社交媒介支持,通过复杂文本结构实现了健康知识、行为和态度等相关事件的组织逻辑,导致公众对自身健康状态和风险感知错位、形成健康知识的错误意义建构,产生认知偏差。本文基于计算叙事视角,对虚假健康信息的潜在逻辑和隐含语义进行建模,将虚假健康信息文本解构为叙事内容、叙事逻辑和二者特定链接方式共同组成的符号体系,用叙事网络G(V,L,E)抽象和表达其中的语义网络。
V={v1,v2,…vn}是网络中的节点集合,表示叙事内容。一般而言,叙事内容可以表示人、事、物、地点等故事化概念。本文将虚假健康信息的叙事内容扩展到医疗组织、疾病、症状、身体部位等术语和概念。
L={l1,l2,…lm}是网络中边的标识集合,表示叙事过程中采用的因果、顺承、夸张等叙事逻辑。本文根据Harris等提出的CARS分类结果[32],将叙事逻辑分为6类:包括夸张、行为诱导、心理认同、假借权威、消极、因果。每类叙事逻辑的代表性逻辑词和示例如表 1 所示。
E={e1,e2,…eq}是网络中的边集合,∀es∈E记为es
2.2 虚假健康信息计算叙事模型构建方法
2.2.1研究设计
本文按照数据获取、叙事内容抽取、叙事逻辑发现、叙事特征计算的顺序开展研究,具体过程如图1所示。首先进行文本数据收集。根据辟谣平台上标识的虚假健康信息标题,收集微信、微博、新闻网站上的虚假健康信息文本,形成False_text={ft1,ft2,…ftp}。然后构建虚假健康信息对应的叙事网络。本文借助语义角色标注算法对虚假健康信息文本中的叙事内容和叙事逻辑进行发现和泛化,经过命名实体识别、语义角色标注、词向量嵌入聚类等计算方法,实现从纯文本语料到低维叙述性语义的直观映射。最后,借助复杂网络理论构建进行计算叙事特征分析,解释不同类型虚假健康信息叙事内容、叙事逻辑和叙事链接模式的差异。
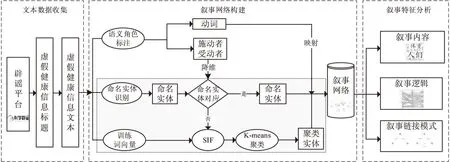
图1 研究框架

表1 叙事逻辑及示例
2.2.2基于语义角色标注的叙事网络构建方法
本文针对虚假健康信息文本中冗余信息多、语法逻辑复杂的特点,提出了DR-SRL(Dimensionality Reduction based on Semantic Role Labeling)方法构建叙事网络,目的是对文本中语义进行识别和结构化表示。具体步骤如下:
第一步,基于SRL的语义结构分析。
输入False_text={ft1,ft2,…ftp}集合,基于Allennlp框架对文本中的单个句子进行语义角色标注(SRL)[33],处理逻辑如图2所示。汇集处理结果,得到语义角色标注集Sinit={Srl1,Srl2,…Srlt},其中Srli=<施动者A0i,谓语Vmodi,受动者A1i>。

图2 文本处理逻辑
如图2所示,Sinit语义角色标注集是对虚假健康信息文本的浅层语义分析结果,其主要作用是高维语义特征刻画句子中单词之间的对应关系。
第二步,基于语义降维的叙事内容抽取。
Sinit比虚假健康信息叙事网络蕴含了更多的冗余信息,对此本文通过加权词向量聚类进行降维,合并施动者A0i和受动者A1i,删除多余谓语Vmodi。
下一步,石家庄市教育局将把小学生免费托管工作与校外培训机构专项治理行动结合起来,创造条件、加大投入、完善政策,不断强化中小学校在课后服务中的主渠道作用,进一步完善课后托管各项制度,帮助学生培养兴趣、发展特长、开拓视野、增强实践,不断提高课后托管服务水平。
Step1:基于spaCy框架对False_text进行命名实体识别[34],得到命名实体集合NES={en1,en2,…enr}。
Step2:其次遍历Sinit,取出Srli中的施动者A0i和受动者A1i,若A0i或A1i∈NES,将其添加到叙事内容集合V中;否则,生成词向量Vec_A0i或Vec_A1i。
Step3:用SIF方法确定每个施动者A0i和受动者A1i的加权平均词向量,计算方式如公式(1)。用K-means对加权平均词向量进行聚类,取类心关键词添加到叙事内容集合V中。
(1)

第三步,叙事链接构建。
根据叙事内容集合V,再次遍历Sinit={Srl1,Srl2,…Srlt},若Srli的施动者A0i和受动者A1i为NES中的元素,或者其词向量与类心词向量相似度>0.5,则将谓语Vmodi添加到叙事逻辑集合L中,则生成es
3 实证分析及结果
3.1 数据集介绍
本文虚假健康信息文本采集依据是“科普中国-科学辟谣”辟谣平台,于2019年8月由中央网信办指导上线。该平台不仅标注了美容健身、食品安全、疾病防治、营养健康等4类虚假健康信息,并对每条虚假信息发布了辟谣信息。由于辟谣信息本身包含虚假信息本体,因此可以借助这些内容反向提取虚假信息,进而达到不依赖大量专业知识标注来获取虚假健康信息的目的[35],反向提取示例如图3所示。

图3 依据辟谣信息反向提取虚假健康信息示例
本文采集平台上2019年8月15日至2022年12月1日期间发布的辟谣信息,在社交平台反向提取对应虚假健康信息,最终得到683条虚假健康信息语料,其中美容健身91条,食品安全178条,疾病防治204条,营养健康210条。
3.2 叙事网络构建及特征
依据上文DR-SRL方法对4类虚假健康信息分别构建叙事网络,并用Gephi软件的进行统计网络结构统计和可视化分析。叙事网络结构统计结果如表2所示,除了节点和连边数量之外,聚集系数、平均路径长度、网络直径和模块度取值都相近。网络的基本特征是平均路径长度短、模块度高,说明任意两个叙事内容(节点)可以通过少量的叙事逻辑(连边)连接起来,并形成了局部的“团块”。
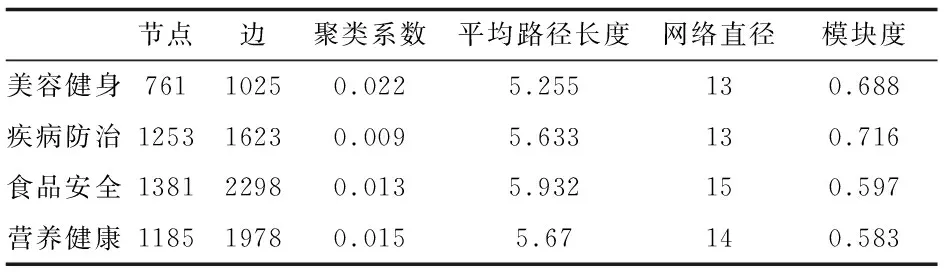
表2 不同类型虚假健康信息叙事网络指标
结合图4(a-d)的可视化结果可以看出,虚假健康信息的叙事网络主要由关于人、事、物、医学术语等概念为核心形成明显的语义团块。观察这些团块的结构可以发现,它们多数是由一个或多个中心节点为核心,沿着不同叙事逻辑发散,并通过hub节点将不同团块链接起来。这些中心节点多为“人们”“身体”“孩子”“减肥”“维生素”等一些常见易懂的概念,发散链接起来的节点包括了“锻炼”“癌症”“胆固醇”等健康知识术语。叙事网络上中心节点的作用是塑造普通民众都能嵌入的叙事情景,叙事逻辑的功能是引导公众形成概念间关联的认知图谱,增加虚假健康信息内容的多样性。

(a)美容健身 (b)疾病防治
3.2.1叙事内容特点
社交媒体上的虚假健康信息以讲述事实的方式呈现在用户面前,通过词汇构建健康概念和情景,吸引互联网用户注意力。本文通过叙事网络节点度分布和词云可视化两个方法,展示虚假健康信息中的重要叙事内容。
图5(a)展示了双对数坐标系下4种虚假健康信息叙事网络的分布,横轴是节点度k,纵轴是度为k的节点在网络种的出现频率P(k)。图像展示节点度分布特征是长尾分布,即极少的叙事内容被经常使用,大部分叙事内容使用频率较低,说明叙事内容即存在一定的集中特性,也具备多样性特征。结合图5(b)中的叙事内容词云,可以发现那些经常被使用的叙事内容有两类。第一类是“人们”“老人”“孩子”“女士”“专家”等故事化文本中的人物,即虚假健康叙事是通过讲述与这些特殊人群相关的内容,明晰身份认同并形成有效互动。第二类叙事内容是“身体”“癌症”“血液循环”“维生素”等事、物概念,立足人们的日常生活提供健康知识,进一步增加虚假健康信息的可用性。

(a) 叙事内容节点度分布 (b)虚假健康信息叙事内容词云图
此外,4种虚假健康信息的词云可视化结果还具体展示了不同类型虚假健康信息的叙事内容的差异。在美容健身类型中以“体重”“皮肤”“减肥”等为主要叙事内容;在疾病防治类型多围绕“药物”“效果”“感冒”等疾病、治疗手段和药物展开叙述;食品安全类则主要涉及“水”“西瓜”“小龙虾”等食品使用的叙事内容;营养健康类叙事内容更多样,其关注的叙事内容为与其他3种类型信息的叙事内容重叠较多。每个类型虚假健康信息叙事中经常出现的叙事内容往往是这些领域中最为关注的问题,这些叙事内容对人们的生活产生了直接的影响,用户对于这些叙事内容更为敏感和关注,因此虚假信息往往会通过宣传产品或服务能够解决人们最为关注的问题来吸引消费者的注意力和购买欲望。
3.2.2叙事逻辑分布
亚里士多德的说服力理论中提到人类决策过程中逻辑的作用超出了信任。类似的,社交媒体用户很难确定信息的来源是否可信,因此信息中的叙事逻辑对其是否接受和转发行为起到了重要的作用。
图6(a)展示了4种虚假健康信息的六类叙事逻辑占比情况,表明虽然虚假健康信息的类型不同,但是大都主要采用行为诱导和夸张的叙事逻辑,加之心理认同和因果来强化表达,再辅以假供权威和消极骗取网民信任。不同叙事逻辑中常见的逻辑词在各类虚假健康信息分布情况如图6(b)所示。具体而言,“吃”“喝”“使用”“购买”等行为诱导型逻辑词在四类主题中使用最多,通过这些逻辑词构建了诸如“感冒的人吃水果真的有助于恢复”等叙事链接,给网民提供了一个可以参照的健康知识或者健康行为选项,促使他们接受信息。占比较多的另一类叙事逻辑夸张在美容健身类虚假健康信息中高达36%,这是由于此类信息的生成目的是宣传“胶原蛋白”“面膜”等产品,通过“增加”“缓解”“提升”“促进”等的逻辑修辞可以加深公众对产品的印象,吸引人们的注意力和兴趣,使产品或方法看起来更加有效,从而增加用户的信任或引起消费者的购买欲望,导致他们接受了其中隐含的归类描述。排名第三的是心理认同叙事逻辑。认同是个体对自我和周围环境有用性或价值的判断和评估,若个体对某个人和事产生认同感,就容易失去自己的客观判断能力。因此,虚假健康信息中使用“知道”“认为”等词语唤起公众的共鸣,也是欺骗公众的一种常用手段。因果型逻辑词的占比也比较显著。尤其是在疾病治理类虚假健康信息中,通过“导致”“引起”“影响”“依赖于”等词汇展示特定结论,用貌似严谨的逻辑放大了疾病的风险,促使公众相信并传播虚假信息。消极型逻辑的作用是从情感上唤起恐惧感,戴维·迈尔斯[36]的研究表明面对网络上纷繁复杂的信息时个体的恐惧程度越高,信息的说服效果越好。通过“遭受”“损害”“感染”等逻辑词的使用,能令公众产生焦虑、恐惧的情绪,从而增加虚假信息的关注度及说服效果。假借权威型逻辑词包括“发现”“发布”“证明”“研究”等,它们以官方口吻编造所谓权威信息,采用诉诸可信的方式来增加信息的可信度,获得公众的信任。

(a)叙事逻辑分布
3.2.3叙事链接模式
叙事网络的形成是通过若干的es
三阶模体可以分为结构洞和集聚型两大类[37],如图7所示,其中v表示叙事内容,type(l)表示边标识所属叙事逻辑类型。对这两类三阶模体分析可以帮助我们发现叙事网络中的语义结构及链接模式,即叙事内容之间的逻辑组合模式。

(a)结构洞三阶模体 (b)集聚型三阶模体
利用Batagelj提出的三元组普查(Triad Census)算法[38]统计不同类型虚假信息的叙事网络中三阶模体的出现的次数,结果如图8所示。结构洞链接类型数量明显多于集聚型,这说明叙事内容之间存在某些隐含的逻辑关系。在线用户遇到结构洞链接时,会关注作为中介的叙事内容,忽略错误的逻辑漏洞,从而接受和传播虚假健康信息。在结构洞类型中,021D数量最多,这说明虚假健康信息叙事网络中往往以某个叙事内容为中心,通过不同类型的叙事逻辑指向其他叙事内容。在集聚型模体中,030T数量最多,表明叙事内容通过逻辑链接呈现集聚、发散和传递倾向。
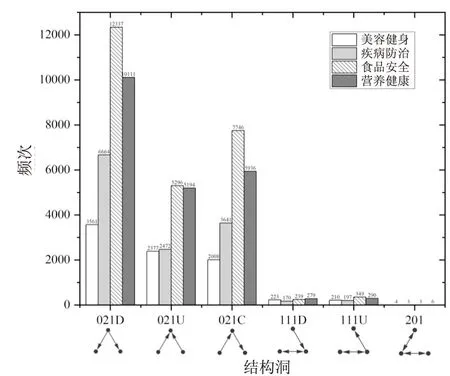
(a)结构洞频次分布
在结构洞的链接模式中,通过叙事链接共形成21种叙事逻辑组合模式,主要的逻辑组合模式如表3所示,按照逻辑组合在每种数据类型中占比总和进行从高到低排序,其中“心理认同-行为诱导”“夸张-行为诱导”“夸张-心理认同”“行为诱导-行为诱导”的逻辑组合形式在不同类型虚假信息中使用频率均较高,说明这些虚假健康信息往往通过行为诱导与其他类型逻辑词进行结合实现目的。此外,“因果”型逻辑词与“夸张”型逻辑词组合频率高于与其他类型逻辑词组合频率,“消极”“假借权威”型逻辑词与“行为诱导”型逻辑词组合频率高于与其他类型逻辑词组合频率。
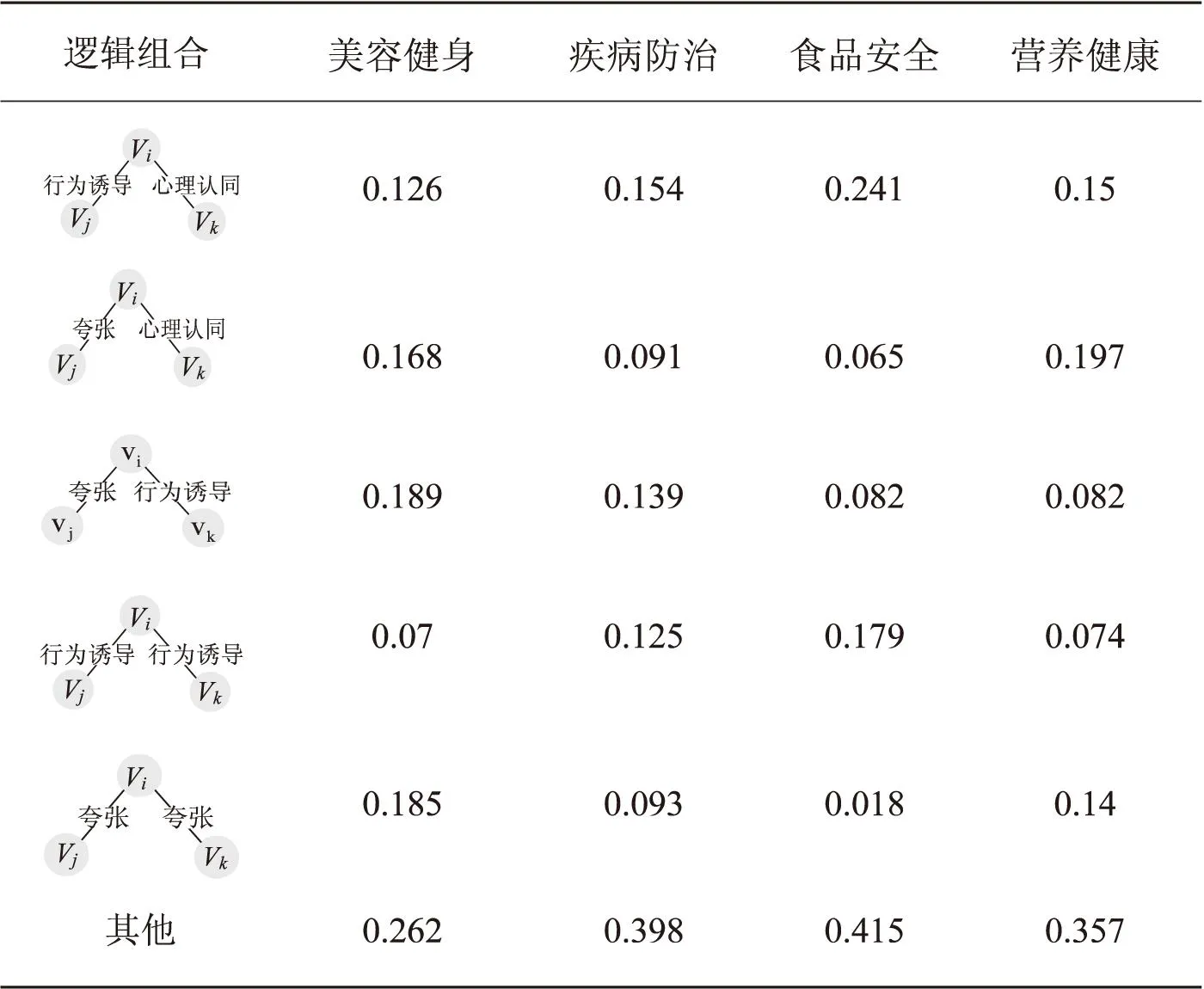
表3 结构洞类型链接模式的主要逻辑组合
从虚假健康信息类型来看,美容健身类虚假信息的逻辑组合中“夸张-夸张”占比较高,说明此类虚假信息对叙事内容的描述偏向于夸大其词;疾病防治类虚假信息中“因果-夸张”逻辑组合使用高于其他类型虚假信息,表明此类信息通过因果逻辑词结合夸张手法实现说服效果。
在集聚型的链接模式中,叙事逻辑类型组合模式较为多样,可以划分为三大类,如图9(a)所示,发现A+A+B型逻辑组合模式在每类虚假健康信息中占比均最高,虚假健康信息多利用“2+1”组合模式,这表明虚假健康信息叙事时采用两个相同的逻辑增强信息的说服力,同时添加一个不同的逻辑则可以实现目的。图9(b)表示三种类型主要逻辑组合示例,其中“夸张-行为诱导-心理认同”的逻辑组合在不同类型虚假健康信息中使用频率均较高,这个叙事逻辑组合模式能够产生一种针对性策略,通过夸大虚假健康信息的可信度、认同感,借助行为诱导的方式实现目的。在美容健身及营养健康类虚假信息逻辑组合模式使用频率最高的均为“夸张-夸张-心理认同”,通过双重夸张,利用用户的需求和认同感,以实现夸大作用、推销产品的目的。

(a)三种类型逻辑组合占比图 (b)三种类型逻辑组合示例
4 结论和展望
针对目前虚假健康信息特征提取和建模问题,本文提出了计算叙事视角下的虚假健康信息特征模型和实现方法。研究结果显示,虚假健康计算叙事模型不仅能解决和适用于“叙事”——人类交流活动的抽象和表示问题,而且还能准确的量化叙事内容、叙事逻辑和叙事链接的程度和模式。它比经典的主题建模和扎根分析等质性研究具备两个方面的优势:可计算性和适应性。可计算性是指能对文本中人类交流活动意图和策略进行表示和量化。主题建模等方法是从关键词的角度刻画文本内容的重点,无法说明这些重点内容之间的逻辑勾连程度。本研究构建虚假健康信息的计算叙事模型,能对叙事内容概率统计、叙事逻辑分类统计和叙事链接模式分析等进行计算,统计结果为传播学与叙事学等相关研究提供了更广阔的探索思路。适应性是指可以适用于不同类型虚假健康信息的特征建模需求。尽管不同类型虚假健康信息的文本数量有差异,但计算叙事模型构建不会因为文本规模差异就失效,并能通过量化结果识别出不同类型之间的特征差异。而质性研究与建模者的知识理论和经验有关,研究过程不能快速复制和迭代。
从实证分析结果来看,虚假健康信息叙事特征主要有三点:a.虚假健康信息的叙事网络中以人、物等特定概念为核心形成明显语义团块,且叙事内容多样化程度高,给不同区域、不同年龄段甚至不同健康状态网民提供了丰富的内容。b.虚假健康信息类型不同,所采用的叙事逻辑不同。使用频率比较高的叙事逻辑类型是行为诱导、夸张和心理认同,是导致普通网民难以分辨信息真假的重要原因。c.由叙事链接构成的三阶模体可以分为结构洞和集聚两大类。统计每一类模体连边上的叙事逻辑标记,可以发现虚假健康信息采用的内容生成策略是相对集中的,通过夸大提升虚假健康知识的有效性,再获取用户心理认同。因此,在进行虚假健康信息的辟谣内容设计时,应该注重每个领域中最为关注的问题,并且针对不同人群,应该提供不同的内容,针对老人群体关注的健康问题,如心血管疾病、骨质疏松等,并提供相应的预防和治疗建议。针对女士群体,在美容健身领域关注的健康问题,如减肥、美白等,并提供相应的科学指导和建议;针对虚假健康信息中经常使用的行为诱导、夸张、心理认同等叙事逻辑,可以从多个角度进行解释和说明,同时在设计健康信息或辟谣信息时,应该注重逻辑的使用方法,以提高信息的说服性;针对虚假健康信息中存在的叙事链接,可以从不同链路进行打破和反驳,澄清叙事内容之间的真实逻辑关系,突破虚假健康信息中的结构洞,建立科学的叙事链接,提供准确可靠的健康知识。
尽管本文在计算叙事学理论和实践方面做出了一定探索,但研究结果仍然存在一些局限。首先,本研究是基于科学辟谣平台的辟谣信息提取的虚假健康信息,其结论是否具有普适性,还需结合其他平台进一步研究。其次,尚未将时间、空间因素纳入研究范畴,笔者在未来研究中将进行进一步的优化。
