输入受限及干扰下固定翼无人机强化学习控制
2024-02-26赵振根梁惠勇
孔 飞, 赵振根, 程 磊, 梁惠勇
(南京航空航天大学自动化学院,南京 210000)
0 引言
随着强化学习算法和算力的不断发展,智能体通过强化学习可以完成飞行控制、任务规划、机动决策等复杂任务。对于非线性系统的最优控制问题,其核心思想主要围绕求解Hamilton-Jacobi-Bellman(HJB)方程[1-2],而求解这个方程是一个非常具有挑战性的任务。近年来,研究者利用神经网络的函数逼近特性在此方面做了许多工作,如自适应动态规划(Adaptive Dynamic Programming,ADP)作为一种有效的最优控制框架,其独特的Actor-Critic设计可以控制许多结构复杂的MIMO(Multiple-Input Multiple-Output)系统。对于六自由度(6-DoF)无人机的MIMO复杂模型,需要进行建模和参数设计,理论复杂、计算量大,很难适用于传统控制方法。 因此,飞行控制系统既要有能够处理无人机复杂动力学模型的能力,又要有对环境的高适应性[3-4]和抗干扰性[5-6]。
文献[7]采用改进的Fuzzy-PID 控制理论进行飞行控制器的设计,使用模糊规则下的切换开关来完成PID控制和Fuzzy控制输出量的加权,调整模糊隶属度函数参数来得到系统的最佳控制方案;文献[8]针对固定翼无人机定高路径跟踪控制问题,基于动态面自适应控制设计了期望路径与时间无关的参数化路径跟踪双环控制器;文献[9]针对理想情况下固定翼无人机的姿态动力学模型,在原有无人机姿态控制器的基础上结合模糊神经网络来补偿无人机运行过程中存在的模型不确定及干扰;文献[10]针对无人机飞行参数及气动参数的不确定性问题,根据H∞理论提出基于回路成形的无人机鲁棒控制器设计方法。
以上文献对无人机的控制问题进行了分析,但是没有考虑无人机的控制输入受限问题,各状态量存在峰值较大的风险,而在实际无人机飞行过程中如果某个状态量超出飞行包线容易造成飞行器内部结构损伤,给无人机的飞行安全带来巨大的隐患。为此,本文基于强化学习的Actor-Critic算法设计了无人机飞行控制器,考虑无人机实际的输入约束和外部干扰,通过Actor网络和Critic网络在线求解HJB方程进行最优控制律计算,并且在神经网络中添加动量系数保证系统能够在有限时间内快速收敛到平衡点。最后,通过仿真对比实验验证了该控制方法的有效性和合理性。
1 无人机模型构建
对连续状态下固定翼无人机非线性动力方程离散化得到其离散状态下的纵向非线性模型,对状态加上干扰项进行建模研究与控制相关项分离。无人机纵向状态主要有4个变量,分别为速度v、航迹角γ、迎角α和俯仰角速度q。根据文献[11]对固定翼无人机进行建模,可以得到其连续纵向动力学方程(变量均为标量)为
(1)
式中:Iyy为转动惯量;m为飞行器质量;g为重力加速度。其中,升力L、推力T、阻力D和俯仰力矩M都可表示为飞行器参数、状态和控制输入的函数,其算式为
(2)
式中:S为机翼面积;ρ为空气密度;Sprop为螺旋桨旋转面积;c为机翼平均气动弦长;Cprop为螺旋桨弦长;Kmotor为发动机常数;δT为节流阀输入(0≤δT≤1)。气动参数为
(3)
式中:e为奥斯瓦尔德效率因子,表示不同机翼形状对应产生的不同升力系数;RAR为翼宽高比;δe为升降舵输入(-1≤δe≤1)。对无人机纵向模型离散化可得离散纵向动力学方程为

(4)
式中,h为采样间隔。
2 干扰下存在输入约束的无人机飞行最优控制问题描述
本章主要描述干扰下存在输入约束的无人机飞行最优控制问题并分析该问题的求解方法。干扰下无人机状态可以近似写成如下非线性仿射离散系统
(5)
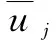
2.1 约束下性能函数与效用函数定义
根据固定翼无人机纵向动力学定义如下性能函数来衡量k时刻无人机性能指标[12]
(6)
式中:λ为性能函数折扣因子,0<λ<1;γd为干扰衰减因子;效用函数U(k)用来衡量系统状态对无人机的消耗,U(k)∈R;Q和W(u(i))都为正定的。

(7)

注意到通过定义该非二次型效用函数W(u(i)),最小化性能函数求解出来的控制输入为有界的。
2.2 无人机最优控制问题的贝尔曼与HJB方程
根据之前定义的性能函数,给出干扰下无人机的贝尔曼和HJB方程。
通过式(6)和式(7)可得(本文d(k)不作为矩阵研究)
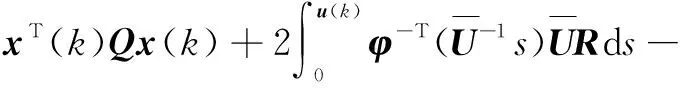
(8)
由以上可以得到贝尔曼方程的迭代形式为
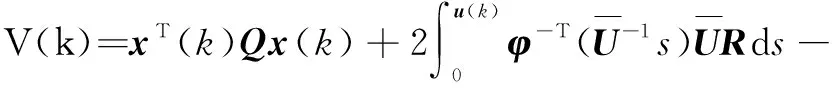
(9)
由式(9)定义哈密顿方程为
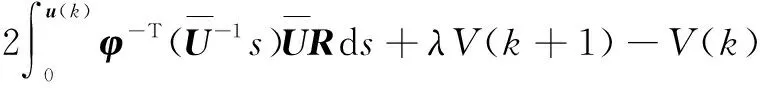
(10)
由贝尔曼最优定理可得HJB方程
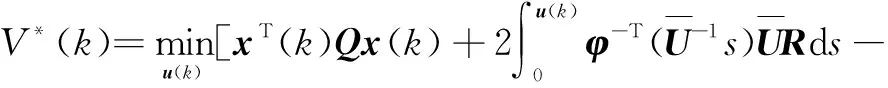
(11)
然而考虑到性能函数中还存在干扰变量的影响,因此约束下最优控制问题可以转换为性能函数在两个变量中求解动态平衡,即
(12)
最优性的必要条件为稳定静止条件,贝尔曼方程的两边对控制律u求偏导,寻找性能函数对应u的极值点使得性能函数最小,即系统的性能消耗最小的最优控制点
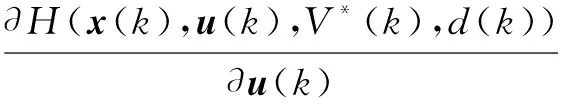
(13)
由式(13)可得
(14)
类似地,最优方程两边再对干扰d(k)求导,寻找性能函数中使得无人机外部干扰最大的极值点来检测该强化学习控制器的抗干扰能力,即
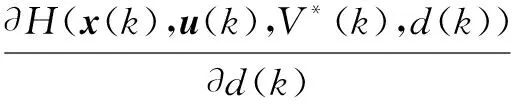
(15)
由式(15)可以求得
(16)
求出的干扰即为无人机所承受的极值干扰。
为了求解最优控制问题,首先定义性能函数V,然后通过求解性能函数得到最优控制律式(14)。然而,这个最优控制中HJB方程由于存在非线性与未知参数并不能够解析求解。因此,本文设计了一种基于Actor-Critic的强化学习算法实时在线求解HJB方程,控制无人机在干扰下稳定飞行。
注1:通过约束下效用函数求解出来的最优控制律永远不会超过其允许界限,因为这是通过最小化非线性性能函数式(6)求解出的最优控制律,在约束情况下运用非二次型性能函数,其中的单调有界奇函数φ(·)能够确保控制律保持在设定的界限以内。
3 Actor-Critic抗干扰无人机强化学习算法
由于HJB方程存在非线性和未知项无法解析求解,可使用策略迭代算法来在线求解HJB方程的最优解,但是此算法需要无人机的全部动力学信息,因此计算繁杂;为了提高运算效率与运算精度以保证无人机能够快速地调节稳定,提出一种Actor-Critic算法来在线求解非线性HJB方程。
3.1 Actor-Critic结构
此部分使用的Actor-Critic结构并不需要无人机系统的控制无关项动力学,并且与策略迭代算法不同的是性能函数与策略同时更新。性能函数和策略使用双层神经网络进行逼近。Critic神经网络用来逼近由状态、误差和控制律构成的性能函数,其作用为最小化贝尔曼方程逼近误差;Actor神经网络产生控制策略,其作用为计算出最小化无人机性能函数的控制律。
3.1.1 Actor神经网络
采用单隐藏层的双层神经网络作为Actor神经网络以逼近求解无人机最优控制问题的控制输入。Actor神经网络结构如图1所示。

图1 Actor神经网络Fig.1 Actor neural network
Actor神经网络的输出为
(17)
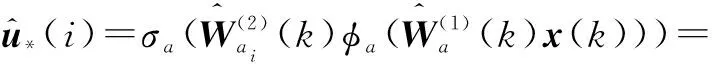
(18)
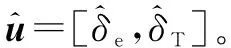
输入层和隐藏层之间的权值矩阵定义为
(19)
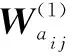
定义由隐藏层到输出层的权值为
(20)

3.1.2 Critic神经网络
采用单隐藏层的双层神经网络来逼近Critic神经网络,Critic神经网络如图2所示。
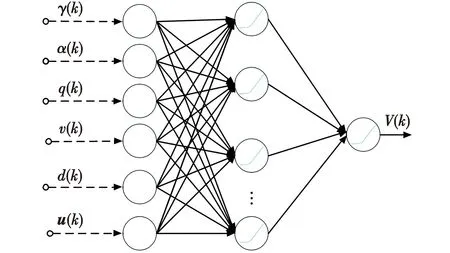
图2 Critic神经网络Fig.2 Critic neural network
Critic神经网络的输入xc(k)包括状态x(k)、干扰d(k)和控制律u(k),Critic神经网络的输出为
(21)
式中:φc(k)=[φc1(k),…,φcNc(k)]T∈RNc×1,为Critic的隐藏层激活函数,设置为φc(·)=ReLU(·);σc(·)为Critic的输出层激活函数,σc(·)=ReLU(·)。输入层到隐藏层的权值定义为
(22)

(23)
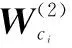
3.2 Actor权值更新与梯度下降算法
主要介绍用于Actor与Critic神经网络的近似梯度下降算法。Critic通过权值更新能够最小化贝尔曼方程误差,Actor通过权值更新能够求出最小化性能函数的控制律。为了避免需要求出Vk+1,算法中使用系统状态xk之前的状态xk-1以及性能函数Vk-1来进行Actor和Critic的权值更新。梯度下降算法的收敛性已在文献[13]中严格证明。
3.2.1 Critic网络更新
最优贝尔曼方程的预测误差定义为
(24)
式中,效用函数
(25)
设置为时间差分信号。选取贝尔曼方程误差的平方作为权值更新的误差信号
(26)
Critic神经网络的更新方式选用近似梯度下降算法
(27)
(28)
其中,ηc>0,为学习率。
通过链式求导法则可以求得
(29)
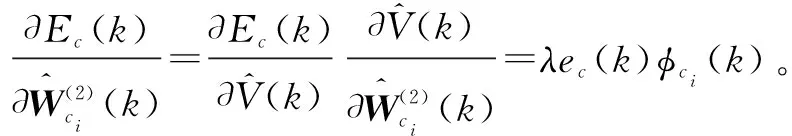
(30)
3.2.2 Actor网络更新

(31)
但是,如果要获取k+1时刻性能函数的值,就需要一个model网络来预估未来的状态。因此,为了避免出现此情况,将上一时刻系统的状态与性能函数存储起来,并且根据当前Actor和Critic的权值来最小化实际控制律和目标控制律之间的误差
(32)

(33)
Actor网络的权值更新方式采用近似梯度下降算法
(34)
(35)
其中,ηa为Actor神经网络学习率。通过链式求导法则可以求得输入层和隐藏层之间的权值更新为
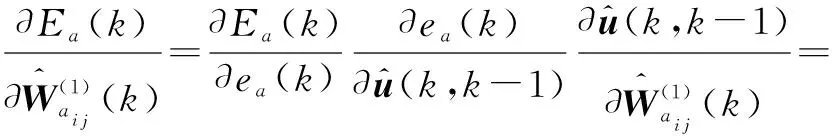
(36)
隐藏层和输出层之间的权值更新为
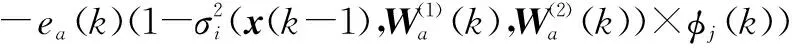
(37)
3.3 Disturbance神经网络
3.3.1 Disturbance神经网络模型
Disturbance神经网络的作用主要为对无人机施加极值干扰,便于模拟无人机在极值干扰下Actor-Critic的控制效果;采用单隐藏层的双层神经网络来构建输出极值干扰的Disturbance神经网络。
Disturbance神经网络的输出为
(38)
为保证Disturbance神经网络干扰输出存在实际阈值,Disturbance神经网络的隐藏层与输出层激活函数选取双曲正切函数:φd(·)=tanh(·),σd(·)=tanh (·)。
输入层和隐藏层之间的权值定义为
(39)

(40)
3.3.2 Disturbance神经网络更新
Disturbance网络的主要目的在于输出无人机当前状态的极值干扰来模拟无人机在外部干扰下Actor-Critic控制器的控制效果,通过式(16)计算出目标干扰和神经网络的输出干扰之差来进行权值更新。设定Disturbance网络的误差为输出和目标之差的平方
(41)
(42)
Disturbance网络权值更新方式采用近似梯度下降算法
(43)
(44)
其中,ηd>0,为学习率。由链式求导法则可得
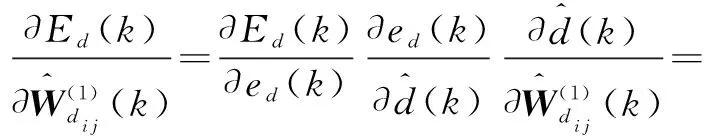
(45)
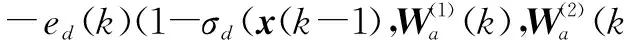
(46)
干扰下无人机Actor-Critic强化学习控制流程如图3所示。
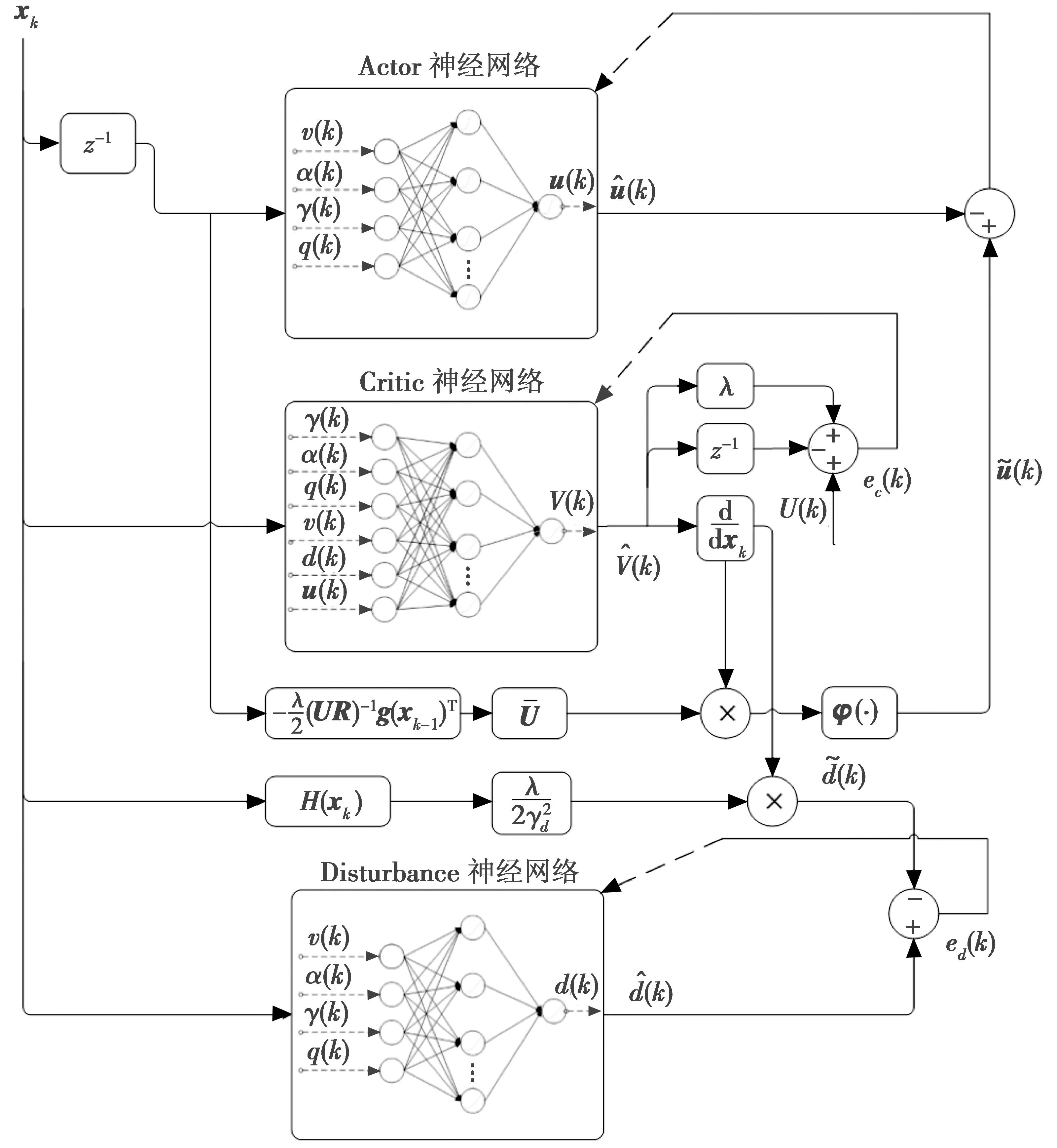
图3 干扰下无人机Actor-Critic强化学习控制流程图Fig.3 Flow chart of Actor-Critic reinforcement learning control for UAV under disturbance
3.4 动量式系数
考虑到实际运行过程中固定翼无人机在飞行状态下对干扰非常敏感,如若无人机受到干扰时控制器没有及时调节使其恢复到稳定状态,极有可能出现失速或者抖动等现象。为加强无人机的控制效果,减少无人机受到干扰时产生的运行偏差,考虑使用带有动量系数的神经网络作为Actor和Critic的框架构建。如果连续两次迭代后其梯度迭代方向仍相同,表示其梯度下降速度过慢,那么动量系数可使神经网络学习速率加倍;相反,如果连续两次梯度迭代方向相反,表示梯度下降过度,那么动量系数可以使得学习速度减慢[14-16]。将其运用到神经网络中可得其一般形式迭代更新方程为
(47)
将上述形式分别运用到Actor-Critic控制器的神经网络中可得
(48)
将带有动量系数ζ的神经网络运用到无人机系统控制以后可以极大增强神经网络的学习速度,减少无人机受到干扰时由控制器的调节时间所造成的运行偏差。
4 抗扰控制对比仿真
本章通过两组模拟仿真实验来验证设计的抗干扰强化学习控制器在无人机中的控制效果。第1组为Disturbance网络干扰下无人机的飞行模拟,第2组为外部常值干扰下无人机的飞行模拟。小型固定翼无人机的物理参数和气动数据如表1和表2所示。

表1 小型固定翼无人机物理参数Table 1 Physical parameters of small fixed-wing UAV
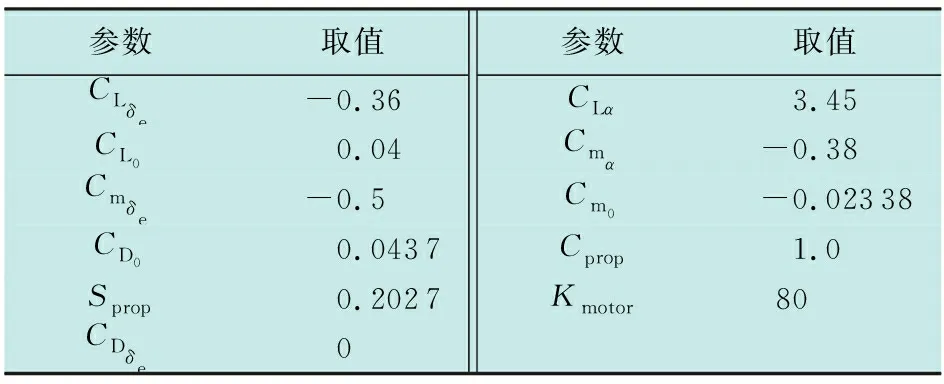
表2 气动参数常数Table 2 Aerodynamic constant parameters
4.1 Disturbance网络下仿真
4.1.1 Actor神经网络
本文Actor神经网络选取单隐藏层双层网络,权值包括输入层权值和输出层权值,其中输入层节点数为4,隐藏层节点数为10,输出层节点数为2。激活函数σa,φa选用tanh函数,无人机控制输入约束设置为|δe|<1 rad(即57.3°),|δT|<100%。Actor网络的控制输出结果如图4所示。
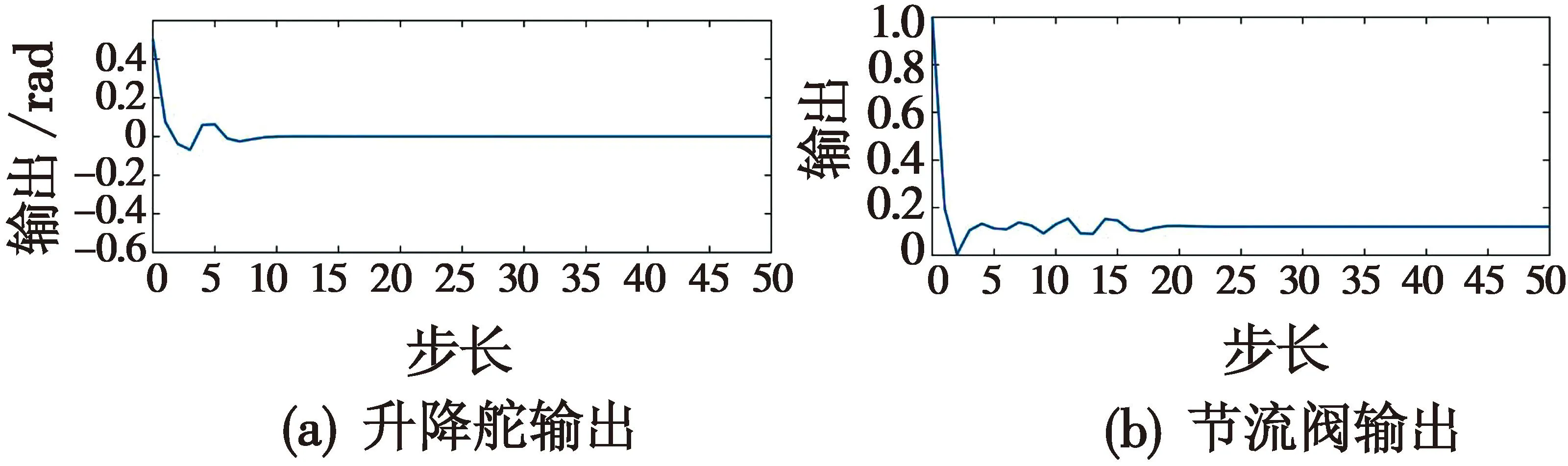
图4 Actor网络控制输出Fig.4 Actor network control output
从图4中可以看出,Actor神经网络具有很强的收敛性,在干扰影响下可以快速收敛到平衡态。Actor网络收敛的快速性保证飞行器在飞行过程中遭受干扰时能快速调节到稳定状态,其权值变化如图5所示(为方便数值显示,选取每一层权值的第一个节点数据进行绘制)。
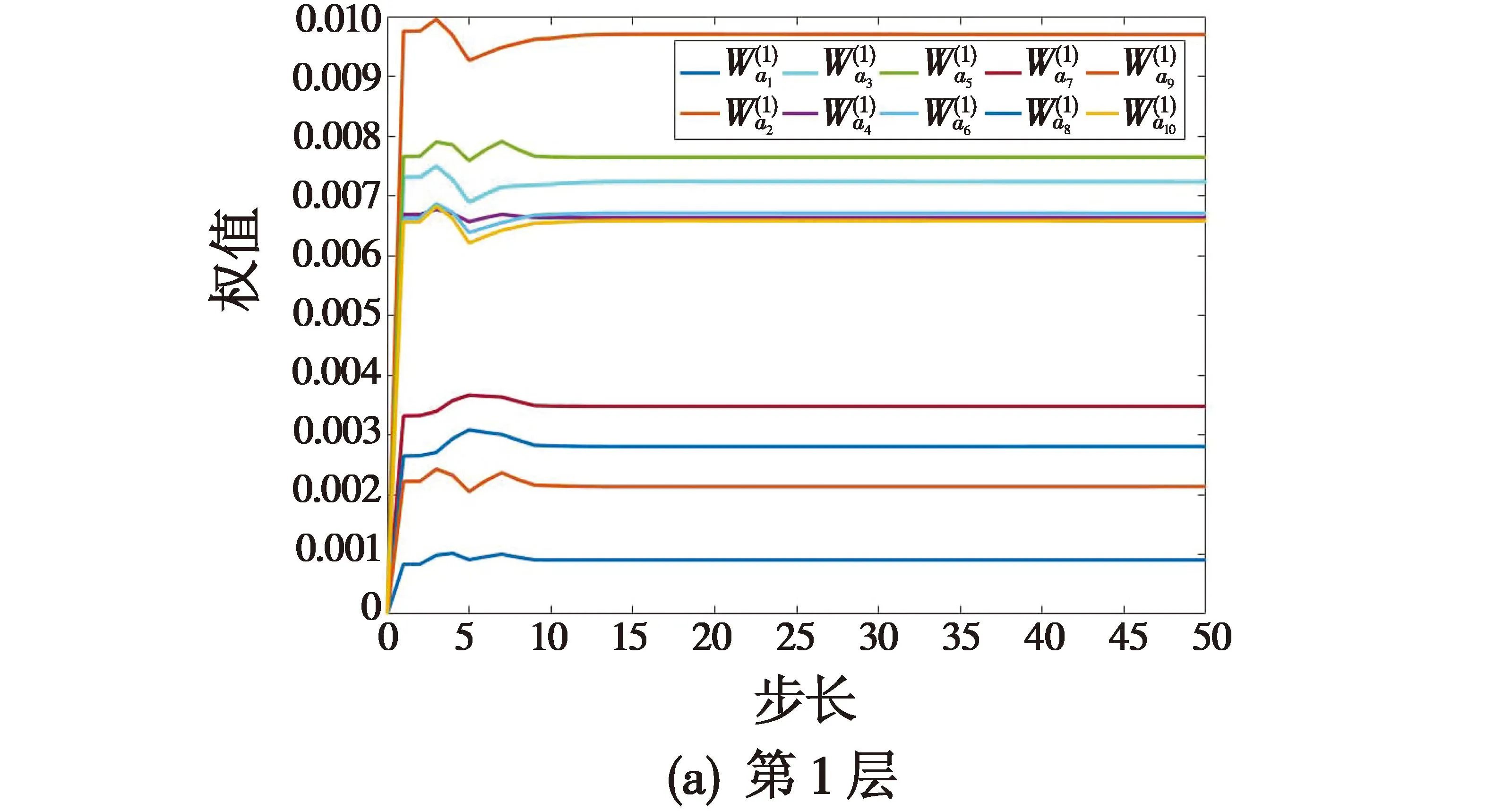
图5 Actor神经网络权值变化Fig.5 Weight change of Actor neural network
4.1.2 Critic神经网络
Critic神经网络选用含有单隐藏层的双层神经网络,输入层节点数为7,隐藏层节点数为10,输出层节点数为1。激活函数σc,φc都选用ReLU函数。Critic网络逼近输出结果如图6所示。
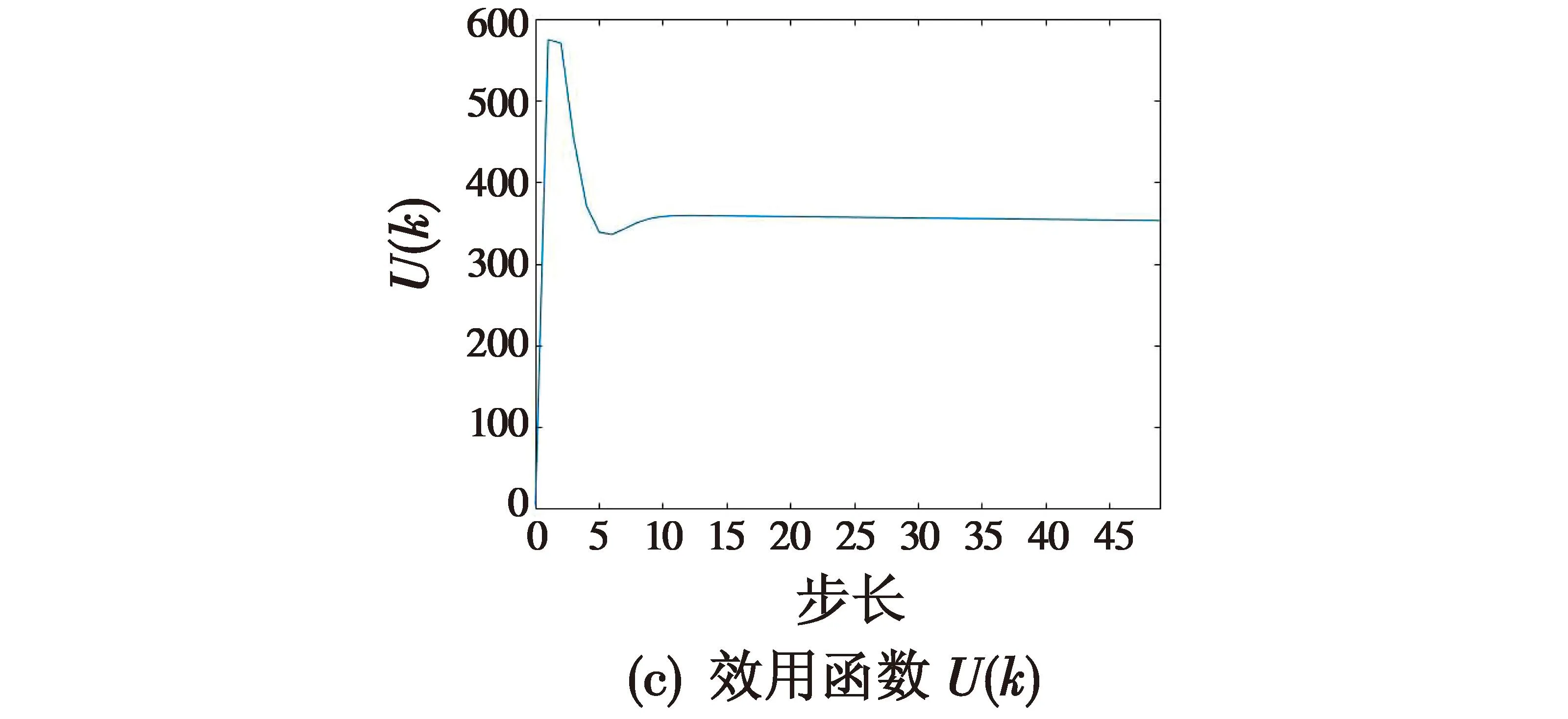
图6 Critic网络逼近输出Fig.6 Critic network approximation output
4.1.3 Disturbance神经网络
Disturbance神经网络选用单隐藏层双层网络,输入层节点数为4,隐藏层节点数为10,输出层节点数为1。激活函数σd,φd为ReLU函数。Disturbance网络数据如图7所示。
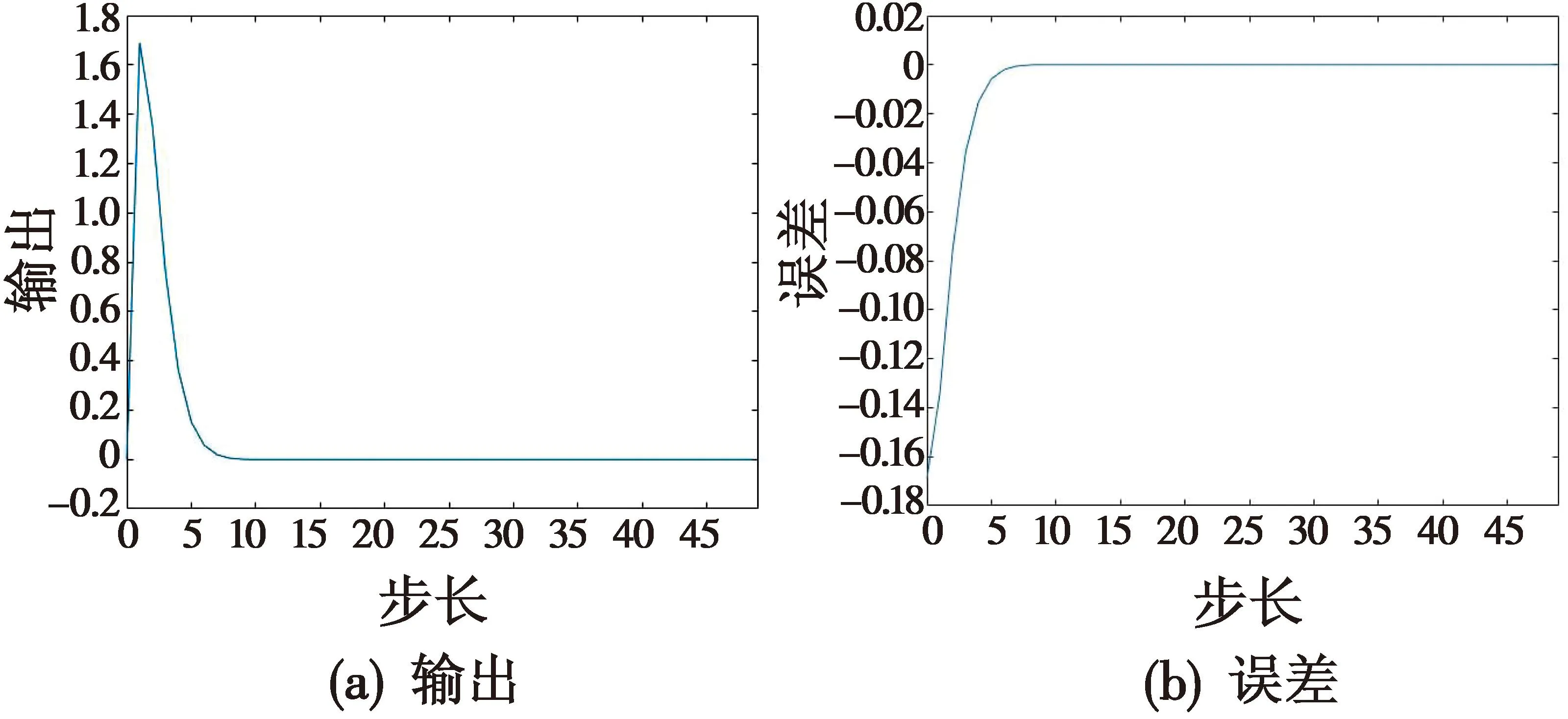
图7 Disturbance网络数据Fig.7 Disturbance network data
4.2 抗干扰对比仿真
本组算例对无人机模拟加入了正弦干扰d(k)=0.5 sin(k)e-0.1k,将PID与强化学习(RL)控制器、非线性动态逆(NDI)方法进行对比,仿真对比结果如图8所示。
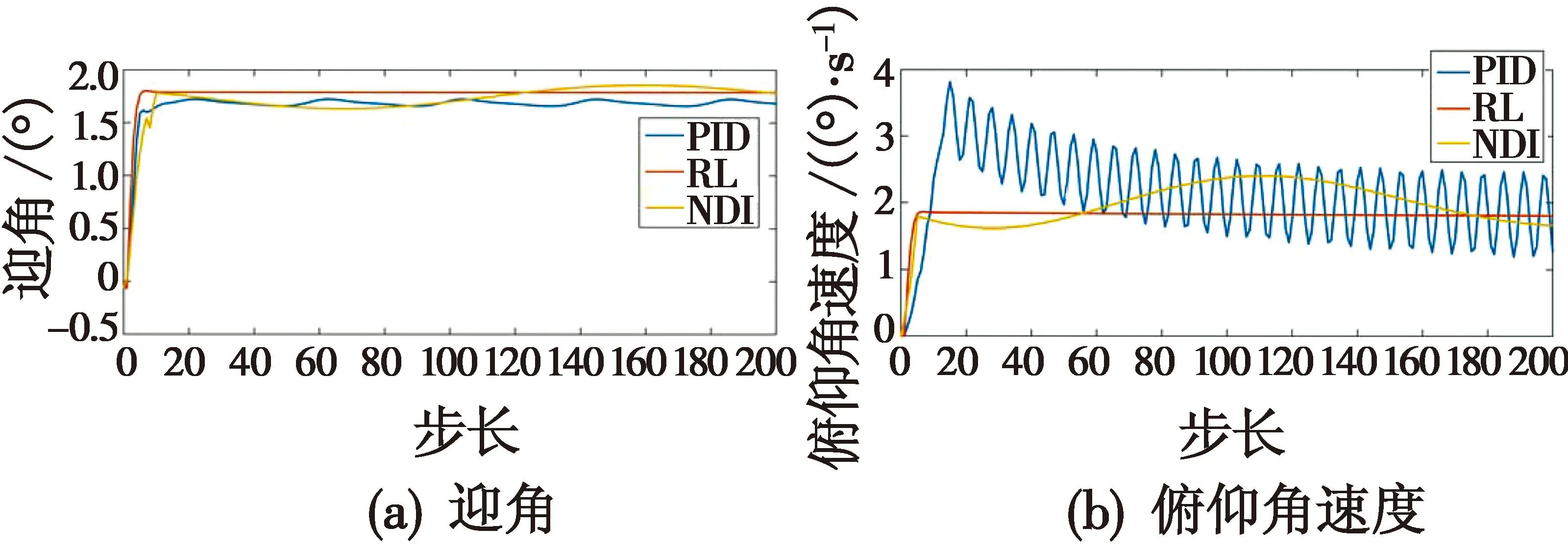
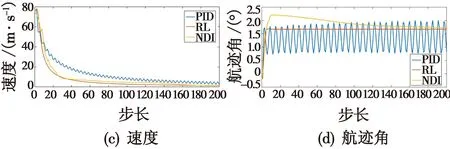
图8 控制仿真对比Fig.8 Control simulation comparison
由图8可以看出:PID控制在外部干扰的影响下,无人机出现大幅度抖动并且未有随时间稳定收敛的现象;非线性动态逆在干扰的影响下,相较于PID控制虽然能够相对稳定地控制无人机,但是收敛后依然存在微小干扰,且超调量相对较高,对无人机的控制存在一定安全隐患;相较于前两种非线性控制器,强化学习控制器在干扰的影响下能够快速平稳地控制无人机保持在稳定状态,该结果说明了本文基于Actor-Critic的控制器的有效性。
5 结论
本文研究了固定翼无人机在输入约束和干扰下的控制问题,基于强化学习的Actor-Critic算法设计了一种强化学习控制器,能够在短时间内快速控制无人机平稳飞行;采用带有动量系数的神经网络进行控制器构建,增强神经网络的稳定性和收敛速度,并且增强了控制器的性能。仿真实验表明,相比于传统的控制器,所设计的强化学习控制器在保证系统全局收敛的同时,能够在外部干扰的情况下保证快速平稳地飞行,表现出了优良的控制性能。
