建筑基本周期多因素机器学习预测模型
2024-02-25宋颖豪王泽涛
陈 隽,宋颖豪,王泽涛
(1.同济大学土木工程学院,上海 200092;2.土木工程防灾国家重点实验室,同济大学,上海 200092)
建筑物的基本周期是建筑结构最重要的动力特性,综合反映了结构的刚度、质量及其分布情况,在设计阶段的荷载估计、参数化建模,以及使用阶段的结构健康监测、实际性能评估等方面,都有十分重要的用途。例如,结构基本周期决定了地震下频谱加速度/地震影响系数[1-2],影响基底剪力设计值;已建结构健康监测系统设计时基本周期的预估,周期的变化也往往预示着结构中系统性损伤的发生与演变[3];城市区域抗震分析中,建筑物周期是参数化建模的核心变量[4]。
面向设计阶段对建筑周期快速预测的需要,以及无实测条件时已建建筑物特性评估的需求,学者们提出了大量的结构基本自振周期经验预测模型[5-7]。然而,受传统的指定函数后拟合回归建模手段的限制,目前大多数预测模型仅含有单因素(如建筑高度或层数等),再通过对结构形式或材料进行分类的方式反映其他因素的影响,回归模型形式大多如:
式中:T为基本周期;H为高度。但是,大量实测数据表明:除高度、材料以外,建筑物结构形式和功能、基础类型、地域等因素对于周期的影响也不能忽视。
近年来,机器学习方法因其强大的数据特征提取能力和处理大规模数据的优势,作为一种新型建模手段备受关注。例如,基于生成对抗网络的方法研究主余震下结构的破坏机制[8]、基于决策树和人工神经网络等方法建立砌体填充混凝土框架的基本周期预测模型[9]、基于BP 神经网络的RC 框架结构地震易损性曲面分析[10]。上述工作基于机器学习方法得到了有价值的成果,也展示了用于建筑基本周期预测的可行性,但还存在如下需要解决的问题:① 由于实测数据获取困难,现有机器学习模型大多基于数值模拟的数据进行训练,如果要包含多因素影响,特别是语义型因素,必须基于既有建筑的实测数据来建立新模型;② 预测模型的输入参数在结构初步设计阶段难以获取,因此,新模型应使用容易确定的结构参数,并应允许部分输入参数缺失;③ 模型的超参数调节和模型选择过程需要人工参与,难以随着数据量的增加实现模型的高效、动态更新,因此,新模型应具有对新增数据的自学习能力,以及对新型机器学习算法的自适应能力。
针对以上关键问题,本文收集了公开文献中大量的建筑周期的实测数据,并建立了数据库。在此基础上,以新兴的AutoML(Auto Machine Learning,自动机器学习)技术建立基本周期预测模型,可利用结构初步设计阶段全部或部分已知信息作为输入参数,预测建筑结构的周期。最后,分别采用本文模型、现有规范模型和文献建议公式对未参与训练过程的500 多栋实际建筑进行了周期预测,并对结果进行了对比分析。
1 实测结构周期数据库
1.1 数据来源
建筑物基本周期的数据来源分为实测数据和模拟数据。由于数值模型与实际结构显然存在差异,难以反映真实的建筑物周期,本研究只选用实测数据进行分析。作者在文献[5]中报告了实测周期数据收集的详细过程和结果,为全文完整性,本节做简要说明。
研究采用从大量公开发表的文献和书籍中检索建筑物基本周期(及其相关信息)的方式,截至本文撰写时,已经完成了上万篇论文的检索,并建立了原始数据库。进一步,采用查重、离群点检验等手段进行数据清洗,形成用于建模分析的可靠数据库。其中,由于不同文献中可能存在相同的建筑,通过比较位置、结构信息和名称等可识别重复的建筑。此外,由于研究角度的差异,不同文献中对同一建筑的描述信息不同,综合多篇文献的内容可实现信息补全。
本文分析的主要数据来源于文献[7, 11 - 29],其他仅包含单条数据的文献,由于数量众多,不一一列举。主要数据来源和建筑数量情况见表1。

表1 主要建筑周期信息数据库来源及相关信息Table 1 Main buildings period information database sources and related information
1.2 数据特征说明
经数据收集与数据清洗后,目前数据库包含2561 条记录。虽然在收集数据时已尽可能全面地收集建筑信息,但不同数据来源所包含的信息完整性会有差别,因此在选择用于机器学习的建筑特征(如材料、抗侧力体系、功能等)时,既要关注它们与基本周期的相关性,也需考虑数据库中包含对应特征的有效记录数量。
结合已有研究的成果,本研究初步从数据库中筛选出了16 个能够影响到建筑物周期的特征,并将其归为分类型(即语义型)和数值型两大类,具体见表2。表2 和图1 同时给出了在2561 条数据中,16 个特征各自的有效数据量比例。可见,包含“抗侧力体系”“材料”“高度”及“所在国”四个特征的数据均超过了70%。此外,“基础深度”的有效数据量最小,为8.9%,但也有228 条。以往研究中,文献[12 - 13]的预测模型分别用到287 条和574 条,文献[15]用到244 条。因此,认为初筛的建筑特征的最低有效数量满足建模要求。

图1 不同特征的有效信息占比Fig.1 Percentage of valid information of different factors
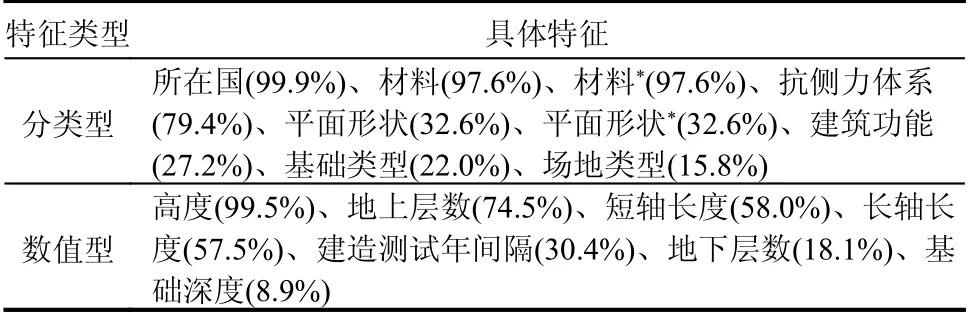
表2 特征类型及具体特征Table 2 Feature type and specific features
收集数据过程中,分类型数据的“值”(文本)尽量遵照原文描述,如抗侧力体系中的“框架”“框架剪力墙”等,这可能导致某些分类值所对应的数据偏少。若将此类数据直接用于训练,机器学习模型容易对这些分类值的特征产生过拟合。为此,需要对语义型特征的分类值进行聚合操作,即合并某一种特征中相近的分类值。由于“材料”和“平面形状”两特征在聚合前,其分类值所对应的数据量就比较多,因此将聚合前的数据作为其补充信息用于模型训练,其余的分类型特征则仅保留聚合后的特征数据。对于目前数据量很小且难以与其他分类值聚合的情况,如图2抗侧力体系的“核心筒”“框架-核心筒”“框架-砌体承重墙”分类以及图3 材料中的“木材”“砌体+木材”分类,统一聚合为对应特征的“未知类型”。一方面,解决数据量小不利于模型训练的问题;另一方面,提升模型包容未来新增其他类型的能力。表3 为聚合完成后,模型具体的分类型输入特征。
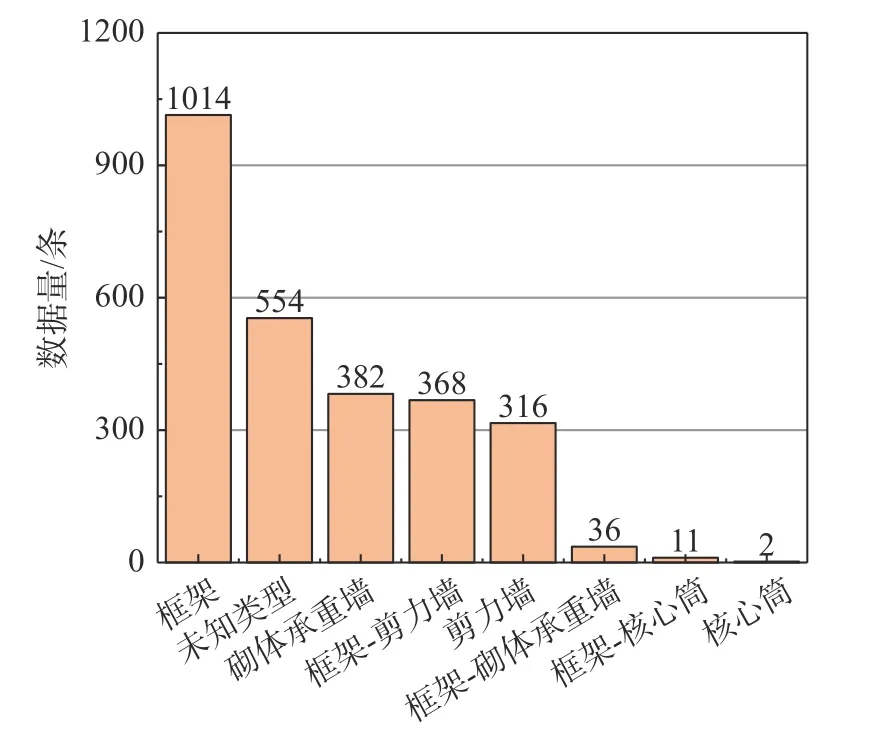
图2 抗侧力体系数据分布情况Fig.2 Data distribution of lateral force resisting system

图3 材料数据分布情况Fig.3 Data distribution of material

表3 分类型特征输入Table 3 Input of classified features
2 基本周期自动机器学习预测模型
2.1 数据填充
不完整性是大数据的重要特点,本文问题中体现为并非每条数据都包含全部上述16 个特征信息,用于模型训练前还必须进行填充处理。本研究针对分类型和数值型两类记录,采用了不同的填充方式,具体为:
1) 分类型特征填充。采用缺失值处理为对应分类型特征中的“未知类型”的方式进行填充[32]。表4 展示了分类型数据的缺失示例(表4 中的“[未知类型]”表示缺失值及其填充处理)。

表4 分类型数据填充示例Table 4 Classification data filling example
2) 数值型特征填充。表5 为数值型数据填充示例,对于缺失值分别尝试了常用的中位数、平均数和众数填充,对比表明最终模型的预测效果相差不大。因此,后续分析中均采用了中位数填充。

表5 数值型数据填充示例Table 5 Numerical data filling example
填充好的2561 条数据再分为训练集(1844 条)、验证集(205 条)和测试集(512 条)3 部分,分别用于后续模型训练和测试。
2.2 基于AutoML 的预测模型
选择合适的模型并进行训练调参,是传统机器学习任务中不可避免、十分繁琐但非常重要的一个环节,需要尝试多次并且依赖一定的经验才能得到性能相对优秀的模型。当数据量增加后,往往还需要重新进行模型的调参优化,使用不便。
考虑建筑物类型会不断变化及实测数据会不断增加的需求,本研究采用了AutoGluon[32]策略来实现自动学习,此方法的基本思想类似于采用基函数的线性组合来逼近复杂函数,通过融合多个未进行调参的简单模型来提高最终模型的性能,称为stacking(堆叠)方法。
本研究采用目前常用的三类机器学习模型:BP 神经网络、XGBoost[33]和LightGBM[34]作为“基模型”,并预先设置每类模型的超参数选择空间。以BP 模型为例,隐藏层有3 层(可取50×40×30、100×80×60、300×200×100 三种,数字为每层神经元数)、二层(200×100)或一层(100、1000)三种选择;3 种激活函数(Relu、Tanh、Softrelu)、学习率在10-5与10-2之间、5 种计算轮次(100、200、300、400、500)、神经元丢失(dropout)概率在0 与0.5 之间。随后,对每类基模型在其对应的参数空间内随机选取N组超参数,可得到3×N个模型,构成底层学习器,本研究将N取为20。此外,为了节约资源AutoGluon 会提前终止预测精度不再随训练而显著提升的底层学习器,以便为其他底层学习器释放计算资源。
利用训练集和验证集数据对底层学习器中的每个模型进行训练,训练好的模型在训练集和验证集上的周期预测结果连同对应的真实值,组成新的训练集和验证集,分别是[1844, 61]和[205, 61]的数组(其中61 列=3 类×20 列预测值+1 列真实值)。最后,利用新的训练集和验证集对一个线性回归模型进行训练,获得最终的模型。该线性回归模型的输入是前3×N个模型的预测值,输出是这些值加权平均后的结果。
图4 是AutoGluon 融合建模的全过程。整个建模过程中,超参数的选择、单个模型的训练都无须人工介入、无须先验经验。由于底层学习器中的每个“基模型”自身比较简单,其训练成本不高且可并行完成,模型的计算效率很高。当有新的数据加入或者有更好的“子模型”出现,重复上述建模步骤重新训练即可完成模型的更新和功能提升,实现数据驱动的模型自动学习。
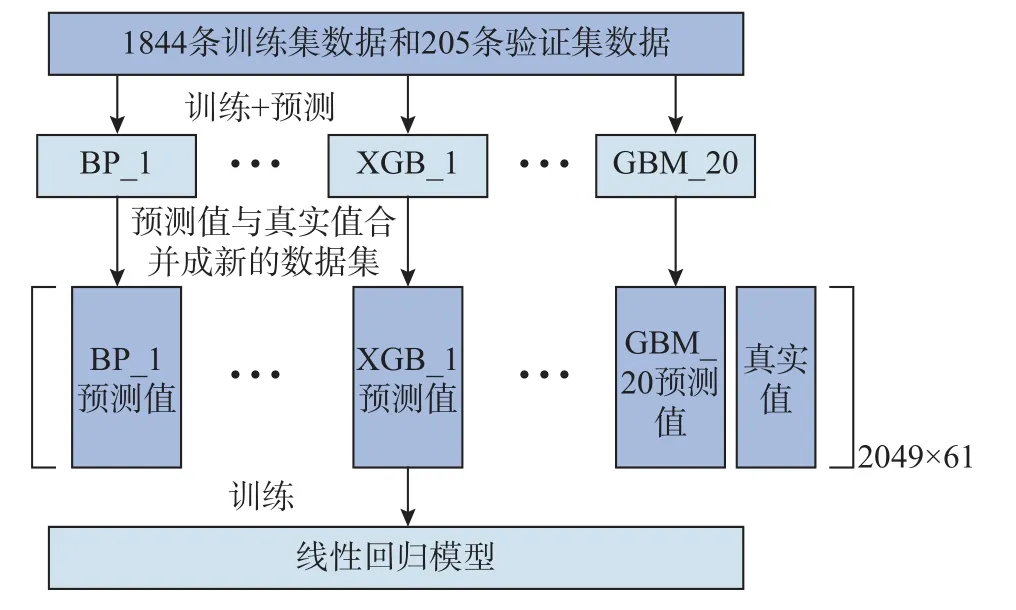
图4 模型建立流程Fig.4 Model establishment process
2.3 AutoML 预测模型性能对比
为了证明AutoGluon 算法的有效性,将融合模型结果与仅使用底层学习器的结果作了对比。表6 为模型的预测性能的排序,按照512 条测试集数据上的RMSE 从小到大排列,受篇幅限制只比较了融合模型和4 个最优的底层学习器的预测精度性能和预测时间成本。结果显示,融合模型的预测精度(RMSE)最好,特别是在模型训练中未接触过的测试集上。同时,相较于底层学习器,融合模型的预测时间也非常小。

表6 不同机器学习模型性能对比Table 6 Performance comparison of different machine learning models
此外,AutoGluon 预测模型中包含2.1 节中的数据填充功能,模型使用时就可将结构在初步设计阶段尚未明确的参数(如平面形状、基础类型、基础深度等)作为“未知类型”输入,从而显著提高模型的适应性。因融合模型的预测是底层学习器加权平均后的结果,其预测需在底层学习器预测之后才能计算,所以预测时间高于底层学习器,平均下来每次预测在0.01 s 以内,是可以接受的。
训练数据时除了将数据划分为训练集和验证集这种简单交叉验证方式外,还可采用k折交叉验证。k折交叉验证的步骤如下:
1) 将样本分为k个大小相等的样本子集;
2) 依次遍历这k个子集,每次把当前子集作为验证集,其余所有样本作为训练集,进行模型的训练和评估;
3) 最后把k次评估指标的平均值作为最终的评估指标。
本研究分别尝试了5 折交叉验证以及10 折交叉验证,结果发现采用交叉验证后训练时间增加了数十倍,且在测试集上的预测精度也没有明显提升,RMSE 分别为0.3585、0.3598。因此本研究采用简单交叉验证的方法进行训练。
3 特征指标重要性的量化分析
1.2 节中初步选择了16 个影响周期的特征,传统上可进一步采用方差分析、卡方检验、最大信息系数等方式,分析其中是否存在冗余特征或不相关特征。利用已经建立的融合模型,也可以通过置换重要性[35]的方式来量化分析各特征参数的重要性,具体方法如下:
1) 将顺序正确的验证集数据输入已经训练好的预测模型,得到预测结果。
2) 将验证集数据中某一特征对应的某列数据随机打乱后输入预测模型,得到预测结果。重复M次。
3) 比较每次数据打乱前后模型的预测结果,如均方误差RMSE 的差异。
4) 对其他特征参数重复上述步骤。
以“高度”特征为例,将205 条验证集记录的高度值随机打乱后输入预测模型,由于高度信息是错误的,预测误差应增大,误差增大的程度可用来量化“高度”特征的重要性。若误差不变或减小,说明该特征对于预测模型无效或有害。为了减小计算偶然性,对205 条验证集数据的每列数据都进行了100 次顺序打乱,最终计算结果如表7 所示,其中P值表征特征无效的概率。例如,P值为0.01 表示有1%可能性,该特征对建立模型是无用的或有害的。
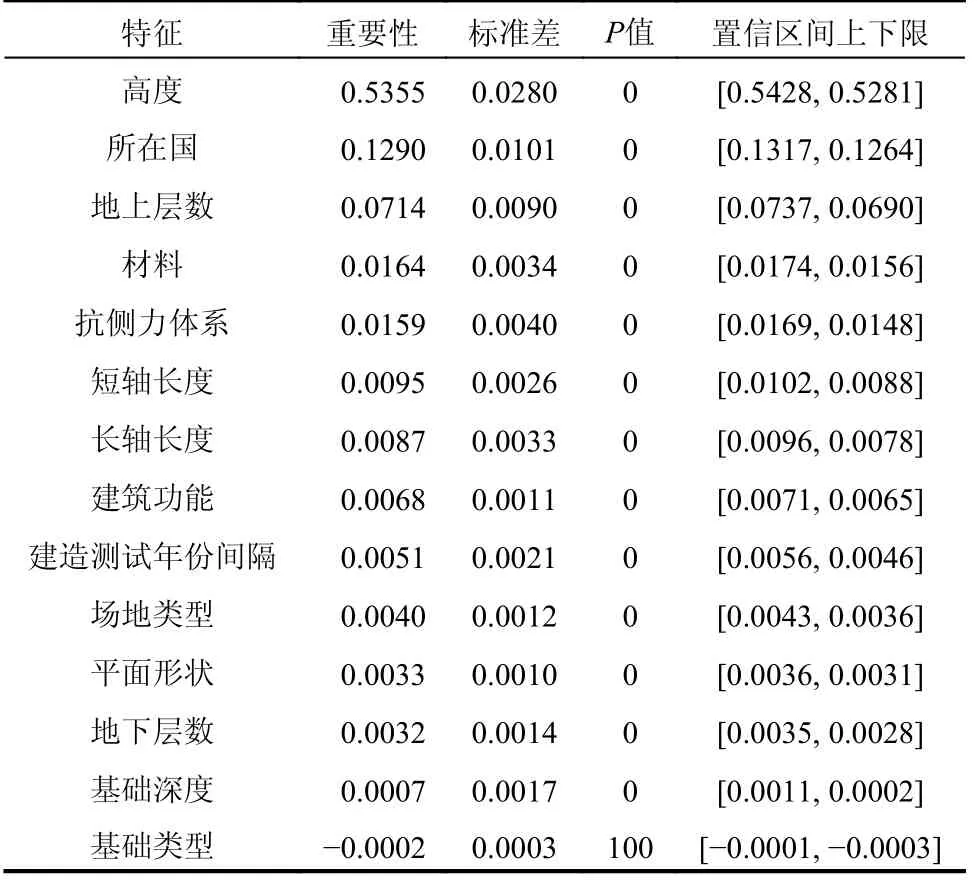
表7 特征重要性及相关参数Table 7 Feature importance and related parameters
表7 显示:高度、所在国、地上层数、材料和抗侧力体系五个特征重要性程度高,除去“所在国”,其余特征与以往研究认识相同。对于“所在国”特征,由于过往研究的数据大多集中于某一地区,地域因素的影响未受到重视。由于“所在国”特征暗含了设计规范、经济水平等因素,值得随着数据的增加进一步关注,文献[36]也提出,中国规范《高层建筑混凝土结构技术规程》(JGJ 3-2010)中对于高层建筑的划分显著地影响到了建筑的基本周期。重要性排在最后四位的特征为:平面形状、地下层数、基础深度和基础类型,可以认定为冗余特征。在预测模型中删除这些冗余特征后,发现训练时间未有明显减少,从模型的发展及完备性角度考虑,目前研究中保留了所有特征作为模型输入。
4 预测模型性能分析
4.1 预测性能
图5、图6 为最终模型在训练集和测试集数据上的预测结果,其中横轴为真实值,竖轴为预测值,预测结果越靠近图中斜线越好,左上角为平均绝对误差MAE、平均百分比误差MAPE 和均方根误差RMSE,训练集和测试集的这三项指标都较小。可见,模型的预测效果良好。

图5 训练集基本周期预测结果Fig.5 Training set natural period prediction results
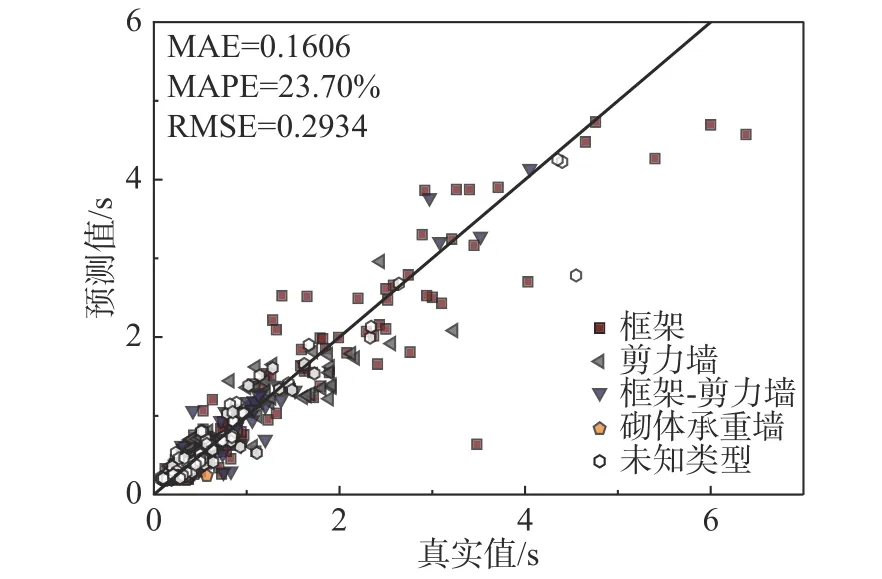
图6 测试集基本周期预测结果Fig.6 Testing set natural period prediction result
4.2 对比分析
与以往预测模型以及相比,本研究预测模型基于多源实测数据,可以预测多种类型的建筑。与之前研究[4]采用传统统计回归的建模思路不同的是,本研究采用机器学习的方法建模,模型的参数更加复杂多样,同时进一步应用新兴的AutoML技术,大大简化了模型建立流程。
表8 中给出了当前规范和文献中的一些结构周期预测模型,本文将它们的预测结果与自动机器学习模型结果进行对比。

表8 规范及文献中基本周期预测模型Table 8 Natural period prediction model in specification and literature
本研究训练模型时采用的训练集包含1844 栋建筑,验证集包含205 栋建筑,测试集包含512 栋建筑未参与任何工作,为了保证验证结果的可靠性,将测试集的建筑用于预测模型的对比。由于传统的预测模型大多针对某类建筑进行预测,在进行预测之前需要进一步筛选出不同预测模型所适用的建筑。
以GOEL 和CHOPRA[19]的模型为例,其模型主要针对框架结构,测试集中相应建筑一共有205 栋,图7 为GOEL 和CHOPRA[19]的模型与本文模型预测结果对比。可见,机器学习模型的预测结果在真实值附近,而GOEL 模型的预测结果总体上较真实值偏低。
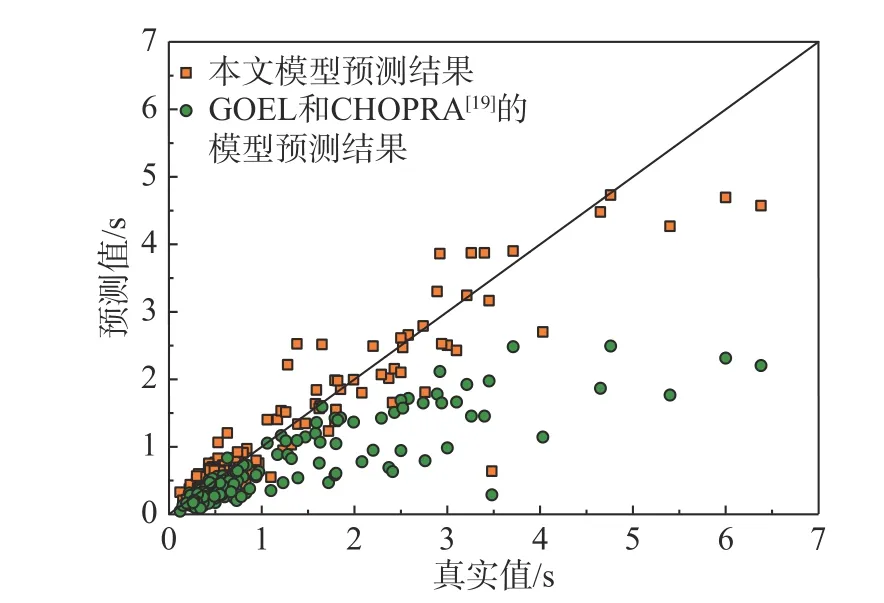
图7 GOEL 和CHOPRA[19]模型与本文模型在框架结构预测结果对比Fig.7 Comparison of prediction results between GOEL and CHOPRA[19] model and this model in frame structure
图8、图9 为表8 中的四个预测模型与本研究预测模型在MSE 和R2两个指标上的对比。MSE是指真实值与预测值之差平方的期望值,MSE 越小说明预测精度越好;R2用以衡量整体的拟合度,R2越大表示拟合效果越好。此外,表9 给出了MAE、MAPE、RMSE 的对比结果。可以发现,本文预测模型在整体上保证预测范围广泛的情况下,整体上预测结果的准确性也是最好的。

图8 不同模型预测结果MSE 对比Fig.8 Comparison of MSE of prediction results of different models
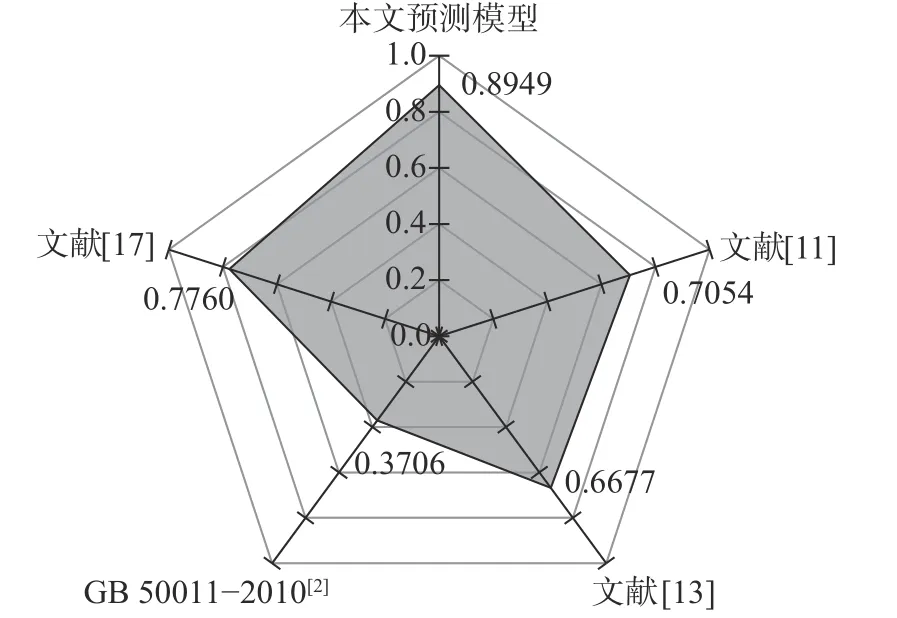
图9 不同模型预测结果R2 对比Fig.9 Comparison of R2 of prediction results of different models
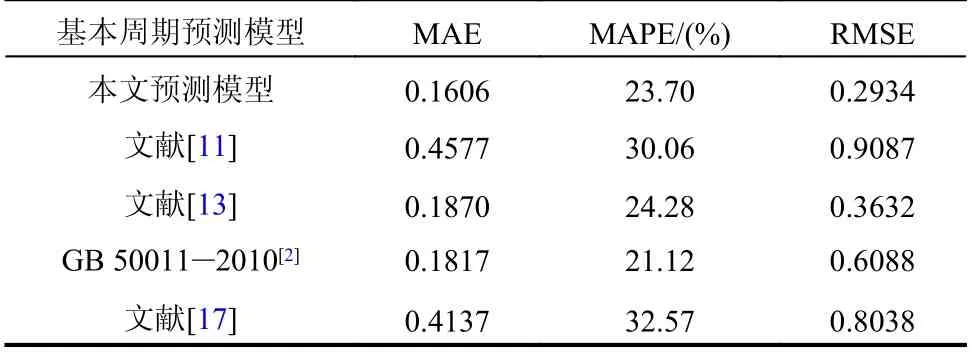
表9 模型其他准确性指标对比Table 9 Comparison of other accuracy indexes of model
5 结论
本文基于多源实测数据,利用机器学习方法建立了建筑结构基本周期的多因素自动机器学习预测模型。所提出的机器学习模型较以往模型可以考虑多因素影响,并适用于多类型建筑,从而显著提高了周期预测的准确性。所建立的自动机器学习模型具有三方面特点:
(1) 无须调参,显著提升了建模效率。
(2) 当有新型、性能更好的“子模型”出现时,仅需对底层学习器进行更换。
(3) 当有新的实测数据加入,也可自动实现模型的更新和功能提升。
将此模型与云端动态更新的建筑周期数据库相结合,可形成一种全新的、网页开放的、在线自学习的建筑周期预测功能。本文模型的源代码将连同文章一起公开,服务于科学研究与工程实践。
