基于数据驱动的干旱等级预测研究
2024-02-21郭财秀杨开斌李显鸿崔松云胡俊波
郭财秀,杨开斌,李显鸿,崔松云,胡俊波
(1.云南省水文水资源局昆明分局,云南 昆明 650106;2.中国电建集团昆明勘测设计研究院有限公司,云南 昆明 650051)
0 引言
干旱对农业生产、城市供水、生态环保产生巨大危害,影响范围广、涉及时间长。随着全球气候变化,干旱灾害的频次日趋增加、程度日趋加深,对干旱进行有效预测是干旱减灾管理的重要手段[1-2]。
基于干旱指数在时间序列上的自相关性,部分学者开展了干旱指数预测研究。彭世彰[3]等采用加权马尔可夫链模型对南京市干旱指数等级预测研究,预测精度较为满意。白致威[4]等采用ARIMA模型对云南省5个区域的SPEI指数进行了预测,总体合格率较为满意。Moreira E E[5]等基于SPI指数采用三维列联表对数线性模型预测了葡萄牙阿伦特约和阿尔加维地区干旱等级,论证了方法的可用性。
此外,基于干旱指数的影响因素分析,近年来不少学者采用多元回归、机器学习方法开展干旱预测研究。林果果[6]基于粒子群算法改进极限学习机模型(PSO-ELM)构建了重庆干旱预测模型,精度较高。杨辉[7]、梅传贵[8]、董亮[9]等基于标准化降水指数SPI以及前人通过西南致旱机理分析,挑选了大气环流资料,对大气环流因子作不同线型的非线性处理,基于多元线性回归建立了西南地区秋季干旱预测模型,论证了模型具有较为稳定的预测特性。刘振男[10]等通过研究挑选了多种海温指数作为预报因子,采用耦合遗传算法和极限学习机预测云贵高原SPEI指数,论证预测精度高于自适应神经模糊推理系统。M Jamei[11]等将水文气象、卫星反演得到的11项数据作为输入,采用浮雕算法挑选因子-人工神经网络建模-鲸鱼算法优化的研究方式预测了恒河流域综合陆地蒸散指数,对比分析表明预测精度较Elbeltagi等研究有显著提高。殷浩[12]等基于随机森林、ANN等机器学习方法结合ECMWFSEAS5输出大气变量构建了动力统计模型对华北、华东、华南地区进行季度干旱预测,预见期和精度上均有改善。
从目前的研究与实践进展来看,基于气候因子的干旱预测方法预测精度要高于基于干旱指数自相关关系分析的时间序列方法,而基于数值气候模式的干旱预测有较好的发展情景,目前仍处于研究阶段。基于气候因子的干旱预测方法,以往研究多基于机理研究进行气候因子挑选,方法具有较强的物理成因意义,但同时也具有较高的研究及学习成本,不利于干旱预测方法的推广实践应用。因此,本研究拟通过数据驱动的方法自动挑选气候因子作为预报因子,结合建模方法研究,尝试在降低研究、学习成本的基础上尽可能提高干旱预测精度。
1 研究区域概况及数据资料
1.1 研究区域概况
昆明市位于中国西南云贵高原中部,是中国面向东南亚、南亚开放的门户城市,属亚热带高原季风气候,年平均气温15℃,年均日照2200h左右。20世纪以来,昆明市分别于1906年、1943年、1960年、1982年、1987—1988年、1992—1993年、2003年、2009—2013年、2019年遭受了严重旱灾,且总体呈现干旱灾害频次增加、影响程度加深加重的趋势。
1.2 研究数据资料
研究数据资料包括昆明气象站1953—2021年逐月降水、气温资料以及包含大气环流、海温、其他因子的130项气候因子1952—2021年指数资料,数据来源国家气候中心网站(http://cmdp.ncc-cma.net/download/Monitoring/Index)。
2 研究方法
2.1 SPEI指数及干旱等级划分
干旱指数可以反映干旱强度及持续时间,是干旱监测预警工作的基础。为给出昆明市干旱的强度等级,本研究采用标准化降水蒸散指数SPEI[13]进行昆明市年度干旱等级划分。
SPEI指数计算公式为:
(1)
当P≤0.5时,W=[-2ln(P)]0.5;若P>0.5,则替换为1-P计算,SPEI结果取反。
式中,W—概率变量;P—超过某一确定的降水蒸散差值的概率,P=1-F(x);C0、C1、C2、d1、d2、d3—常系数,C0=2.515517,C1=0.802853,C2=0.010328;d1=1.432788,d2=0.189269,d3=0.001308。
概率分布函数F(x)基于下式计算:
(2)
其中:
(3)
(4)
(5)
式中,Γ—伽马函数;w—L-矩参数;α—尺度参数;β—形状参数;γ—位置参数。
Di序列的概率加权矩wl(l=0,1,2…)计算公式为:
(6)
式中,xi—Di(降雨量减去蒸发量)从小到大排序的系列。
为进一步划分干旱等级,本研究基于昆明市长系列SPEI指数的均值、标准差统计值,沿用以往研究多采用的干旱分级方法[3],方法见表1。
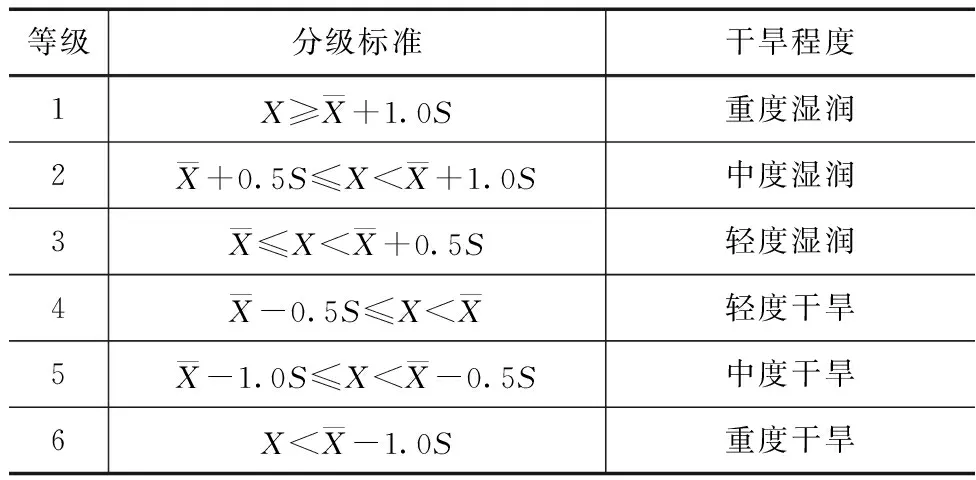
表1 干旱等级划分方法
2.2 随机森林简介
随机森林是最早由美国学者Leo Breiman和Adele Cutler发展推论出的一种基于组合树型分类器的机器学习算法[14],通过训练多个树(决策树预测模型),每个树基于随机机制尽可能拟合,最终成果综合多个树的预测结果,实现目标分类及数值回归,并具有成果精度高且稳定,较少受缺失值及不重要特征影响,可以生成预报因子重要性排序等优良特性[15-16]。随机森林算法原理详见Leo Breiman的《Random Forests》一文。
2.3 干旱等级预测方法
考虑到气候因子数据的发布有一定滞后性,但滞后时间不超过1个月,因此预测下一年干旱指数/干旱类别所采用的气候因子为去年12月至当年11月的月值数据。由于随机森林能反映因子与预报对象间的复杂非线性映射关系,本研究采用能在一定程度上反映非线性关系的Spearman相关系数,挑选与预报对象间相关系数的绝对值超过相应阈值的因子,并计算因子间相关系数,剔除因子间相关系数绝对值超过一定阈值而与预报对象相关系数绝对值较低的因子。
本文昆明市干旱等级预报按直接分类和回归归类分为两种预报方法。
2.3.1直接分类
(1)预报因子选择
昆明市年度干旱等级系列为1953—2022年共计69年,以2012—2022年为检验期。为模拟利用实际预测时可获得的信息,训练期为1953年至所预测年份的前一年,其时期随预测年份的不同而变化,大数在60年左右。通过查表,在置信度0.05条件下,样本数60的相关关系显著性阈值约为0.25,因此以预报因子与昆明市干旱指数间Spearman相关系数绝对值不低于0.25为条件进行因子初选。再设定因子间相关系数绝对值阈值为0.85,保障挑选的因子两两间相关系数绝对值不超过0.85,进一步筛选预报因子。最终采用随机森林算法内部的因子重要性识别方法,根据预报因子的重要性权重排序,取累积重要性权重不低于0.85的前n个因子作为预报因子。
(2)预报模型构建
采用随机森林分类算法进行昆明市干旱等级分类预测研究。以训练期的年度干旱等级为目标变量,以最终筛选的预报因子系列为解释变量,通过样本训练构建预报模型,并对检验期的干旱等级结果进行精度检验。其中,随机森林分类算法参数采用网格搜索进行率定,相关参数集合见表2。
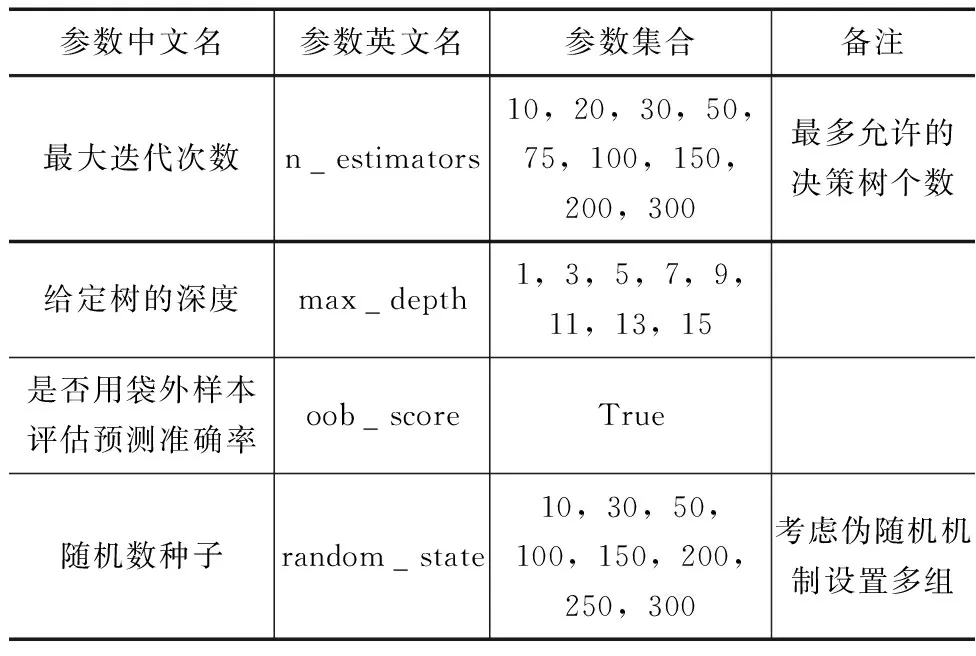
表2 网格搜索率定参数集合表
2.3.2回归归类
(1)预报因子选择
考虑到昆明市连续干旱事件时有发生,即年干旱指数系列具有一定的年代际变化特征,该特征会对回归建模造成一定的不利影响[17]。因此,本研究对预报对象系列、预报因子系列进行增量计算处理(当年增量为当年数值减去去年数值),即将原始预报对象系列、预报因子系列替换为预报对象增量系列、预报因子增量系列。在此基础上,采用与直接分类一致的方法进行预报因子选择(本研究昆明市干旱等级系列最早年份为1953年,由于进行了增量计算处理,训练期起始年份为1954年)。
(2)预报模型构建
采用随机森林回归算法进行昆明市干旱等级回归归类预测研究。以训练期的年度干旱指数增量为目标变量,以最终筛选的预报因子增量为解释变量,通过样本训练构建预报模型,预测的下一年年度干旱指数增量再叠加当年的年度干旱指数,得到下一年年度干旱指数,结合表2进行归类,从而预测干旱等级。同样也对检验期的干旱等级预测结果进行精度检验,网格搜索率定参数集合同表2。
此外,本研究还构建了加权马尔可夫模型进行对比研究。
3 研究成果
3.1 干旱指数及干旱等级划分
本研究基于昆明气象站1953—2022年逐月降水、气温资料,计算了12月尺度的SPEI指数,进一步统计出1953—2022年逐年SPEI指数,其中2001—2022年数值见表3。从表3可以看出,SPEI指数反映了2009—2013年连续干旱事件,可以较好表征干旱状态。
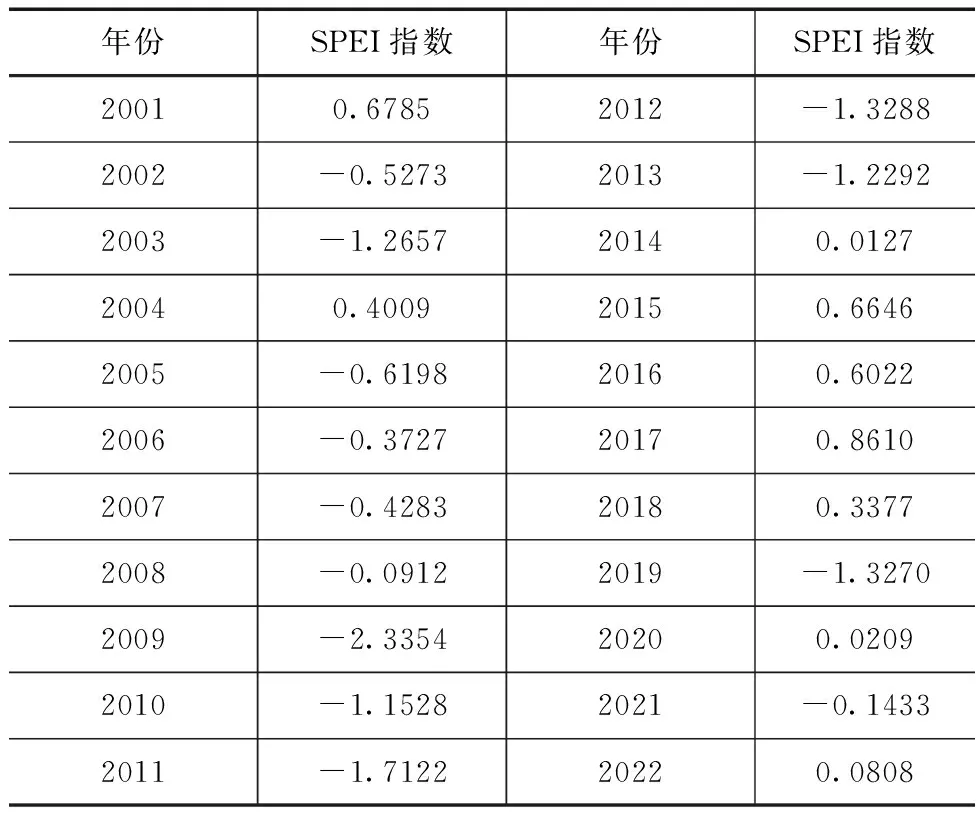
表3 昆明市SPEI指数(2001—2022年)
依据昆明市1953—2022年逐年SPEI指数及前述干旱等级划分方法,划分干旱等级,见表4。
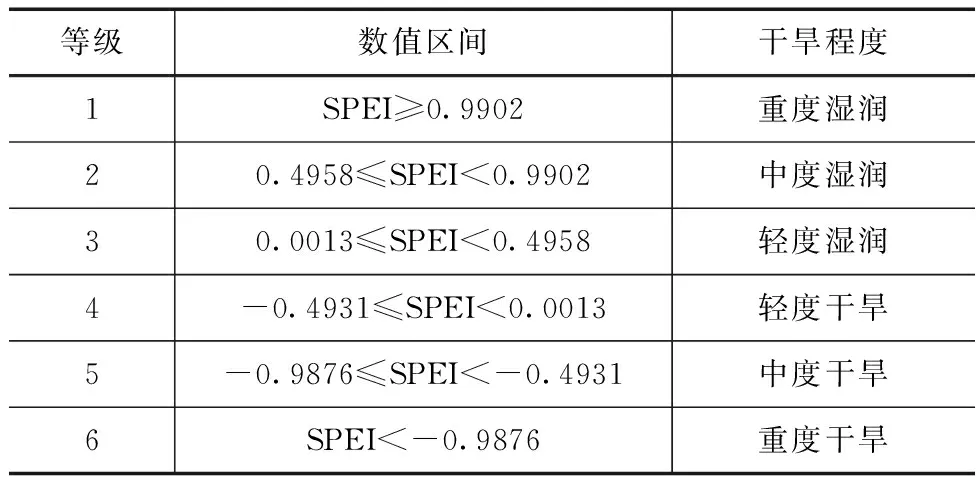
表4 昆明市干旱等级划分方法
3.2 干旱等级预测成果
基于随机森林的直接分类模型(以下简称“RF直接分类模型”)、基于随机森林的回归归类模型(以下简称“RF回归归类模型”)及加权马尔可夫模型逐年预测的2012—2022年昆明市干旱等级见表5。
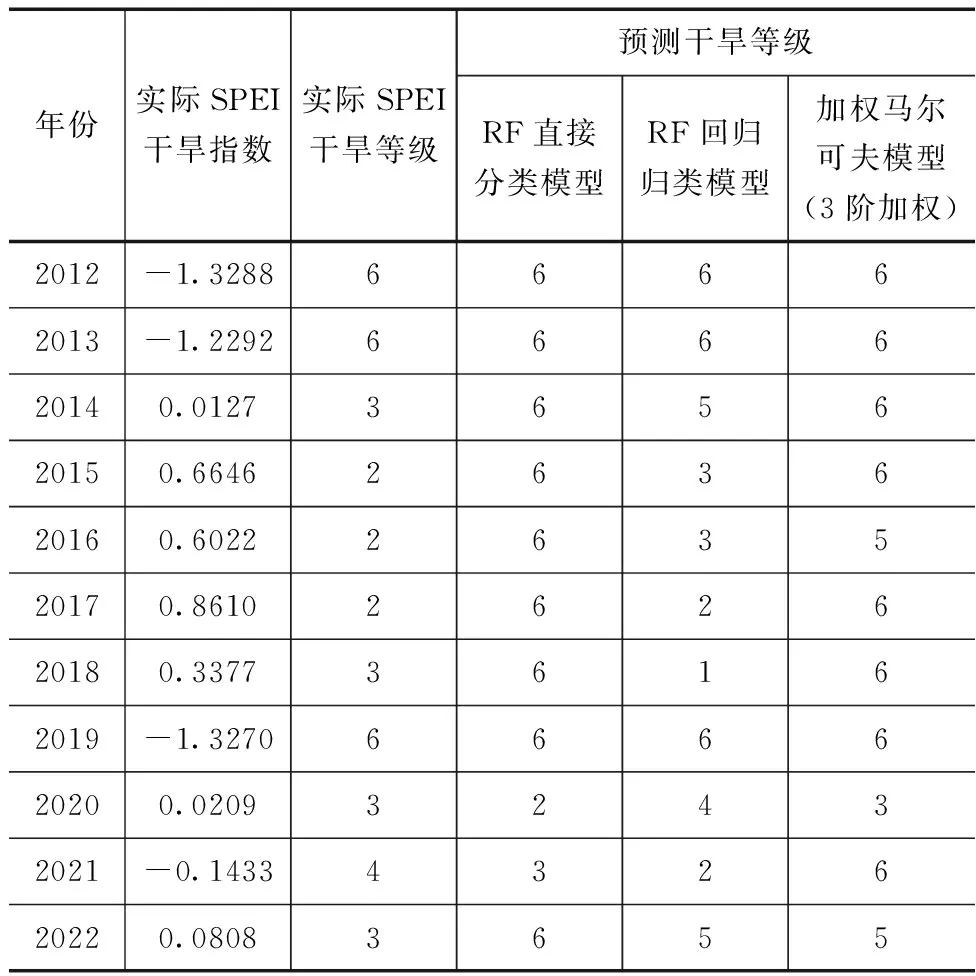
表5 三种方法预测的昆明市干旱等级成果
从表5可以看出,RF直接分类模型和加权马尔可夫模型更倾向把干旱等级预测为6,而RF回归归类模型预测成果与实际干旱等级在趋势上较为一致。11年预测中,RF直接分类模型在2012年、2013年、2019年预测准确,在2020年、2021年预测与实际接近,其余6年预测与实际相差较大,总体预测效果不佳;加权马尔可夫模型在2012年、2013年、2019年、2020年预测准确,在2022年预测成果与实际有一定偏差,其余6年预测与实际相差较大,总体来看预测效果最差;RF回归归类模型在2012年、2013年、2019年、2017年预测准确,在2015年、2016年、2020年预测与实际接近(相差1个等级),在其余4年预测成果与实际有一定偏差(相差2个等级),总体来看有一定预测精度,3种方法中表现最优。
除干旱等级预测成果外,RF回归归类模型还可输出选择因子个数、模型最优参数等中间成果,件表6。绘制RF回归归类模型预测的SPEI干旱指数与实际的拟合图,如图1所示,可以看出,预测的干旱指数值变化过程与实际较为相符,这也保障了RF回归归类模型干旱等级预测精度相对较高。
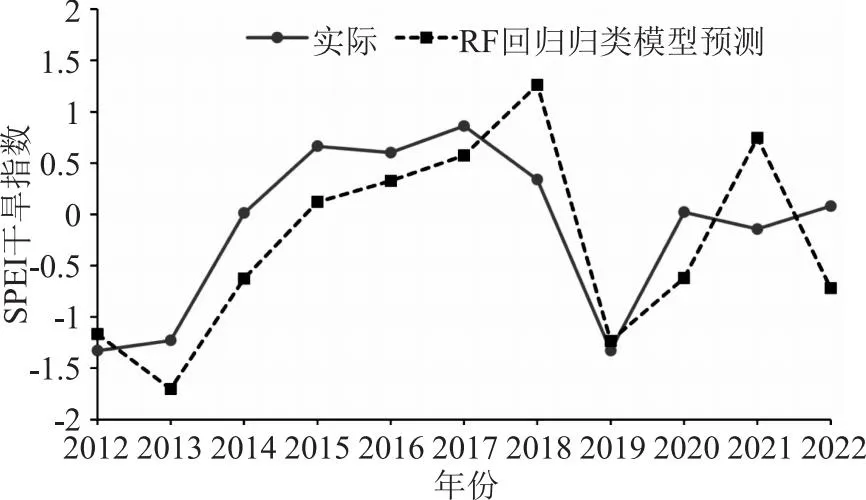
图1 RF回归归类模型预测与实际SPEI干旱指数拟合
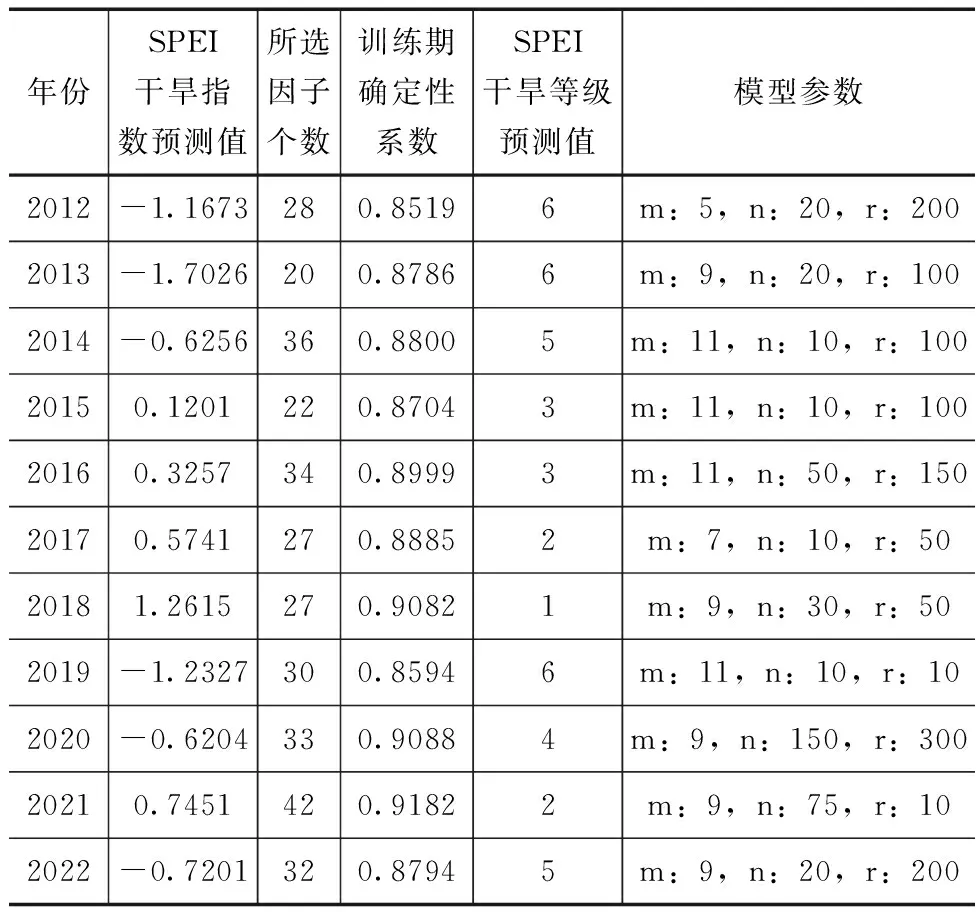
表6 RF回归归类模型干旱预测成果
依据历史SPEI指数及气候因子数据,采用RF回归归类模型预测昆明市2023年SPEI指数为0.0251,干旱等级为3,为轻度湿润水平。
4 结语
干旱预测是水资源管理领域的重点及难点问题,本研究针对干旱灾害情势严峻的昆明市开展基于数据驱动的干旱等级预测方法尝试性研究。研究构建的RF回归归类模型,可以利用到前期气候因子信息,较好构建前期气候因子与干旱等级之间的复杂非线性关系,相比基于时间序列方法的加权马尔可夫模型,干旱等级预测精度更高。而由于气候因子与干旱等级之间的关系较为复杂,直接分类一定程度上损失了信息量,也更难把握气候因子数值与干旱等级类别之间的关系,反映的结果为预测精度不如回归归类模型。本研究可为干旱预测研究提供一定的方法参考。
