基于改进Centerfusion的自动驾驶3D目标检测模型
2024-02-21刘家森
黄 俊,刘家森
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引言
随着自动驾驶技术的不断发展和普及,3D目标检测作为自动驾驶中关键的环境感知模块,正日益成为引领自动驾驶技术发展的重要领域[1]。3D目标检测是感知模块的核心,可为自动驾驶的路径规划、运动预测、决策控制等提供精确、丰富的空间信息[2]。
现有的3D目标检测可以分为3种,分别是基于图像、点云和多传感器融合的方法[3]。在基于图像的方法中,文献[4]首先使用卷积神经网络预测出初步的3D预测框,再将其投影到2D图像上提取目标的可视表面,利用可视表面的特征对初步的3D预测框进行调整得到最终结果。文献[5]使用被测车辆一些特征点的位置信息来表示整个车辆的3D预测框信息。根据车辆本身具有的形状,从自建数据集中进行车辆模型匹配,得到最终3D预测框信息。上述基于图像的3D目标检测算法虽然步骤简单,但是图片缺少目标深度信息,不能准确还原目标3D信息。
在基于点云的方法中,文献[6]将空间划分为逐个的体素,体素中对雷达点云进行抽样,然后对每个体素进行编码,得到输入特征集合,然后进行3D卷积,得到结果。文献[7]将雷达点云数据自身进行柱状扩张,再将其转换为虚拟特征图像,然后从3D卷积换为2D卷积来得到结果。上述基于点云目标检测方法中,都缺少目标的纹理特征信息,并且由于大部分点云是3D卷积,运算量过大、实时性很差。
在基于融合的方法中,文献[8]将图像信息做语义分割,分割出需要检测的目标;然后将生成的语义信息和点云相融合后传入检测网络;最后得到检测结果。这样的缺点在于融合方式过于简单,容易把干扰雷达的信息融合从而导致准确率下降。文献[9]提出了一种多摄像头鸟瞰视角下的三维物体检测算法。该算法使用卷积神经网络将不同摄像头收集的车辆图像映射到一个共同的鸟瞰图平面上,然后进行物体检测和分类。但是,该算法对于不同车型和不同尺寸的车辆在检测方面可能存在一定的局限性。其次,该算法在计算鸟瞰图时需要对图像进行投影变换,会引入一定的误差。文献[10]对RGB图像先提取出准确的2D边框信息以及初步预测的3D边框信息,再对毫米波雷达点云进行柱状扩张,然后通过视锥关联网络的方式选取一个雷达点云作为特征信息补充,并且把2D信息和补充的雷达点云进行信息融合后再通过特征网络得到最终预测的3D信息,最终解码器通过初步预测的3D信息和最终预测的3D信息得到准确的3D边框信息。
综上所述,本文针对自动驾驶中相机信息特征不充分而导致目标漏检的问题,设计了多通道特征数据输入方式,通过雷达特征弥补相机特征以增强目标检测网络在远距离情况下的鲁棒性来解决漏检问题,并改进了损失函数来提高目标检测网络的准确率。此外,为了得到更加准确的3D目标检测结果,设计了改进注意力机制对毫米波雷达和视觉信息进行特征融合,解决复杂环境下的目标误检问题。本文在大型公开数据集Nuscenes上进行算法验证,实验结果表明,本文所提出的改进Centerfsuion模型在远距离以及复杂环境下,相较于传统Centerfusion模型具有更好的准确率。
1 Centerfusion
摄像头和雷达特征进行融合时,很难将雷达和视觉特征相关联,Centerfusion是一种利用视锥来关联摄像头和雷达特征的检测网络,其网络架构如图1所示。
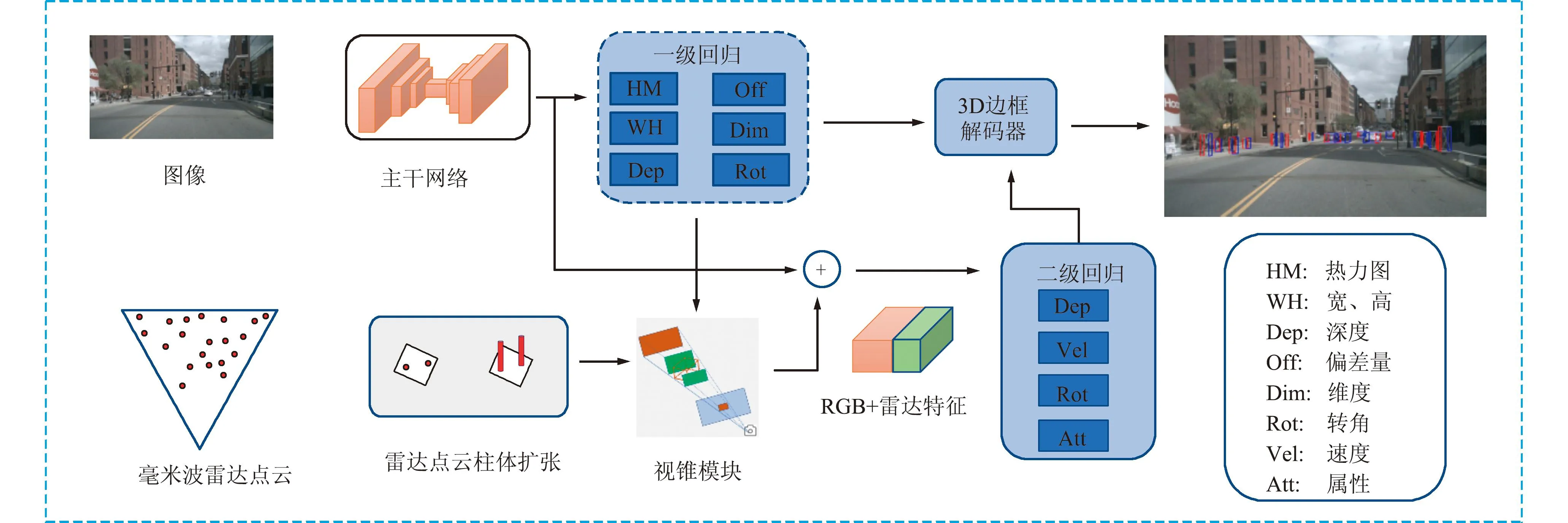
图1 Centerfusion网络架构Fig.1 Centerfusion network architecture
该网络结构分为3个主要部分,分别为目标检测网络、视锥关联网络和二级回归特征融合网络。目标检测网络的输入为单一的RGB图像,采用Centernet[11]作为目标检测网络结构,并将深度层聚合(Deep Layer Aggregation, DLA)作为检测网络的骨干网络。其输出结果为准确的2D边框信息和初步预测的3D边框信息。
视锥关联网络通过对毫米波雷达点云进行柱状扩充,并根据准确的2D边框的4个顶点进行投影,形成视锥。视锥关联网络将初步预测的3D边框与投影曲线相切,从而确定视锥的形状。对于落在3D边框内部的雷达点云柱体,视锥关联网络认为其与视锥相关联。
二级回归特征融合网络在视锥关联模块中选择与目标检测网络输出的中心点最近的雷达点云,并将其作为补充的雷达特征信息。该雷达点云与目标检测网络中的特征信息按通道拼接构成新的输入特征,用于预测目标准确的3D边框信息。通过3D边框解码器将目标检测网络输出的初步3D边框信息与二级回归特征融合网络得到的3D边框信息相结合,得到更准确的3D边框结果。
2 本文模型
2.1 多通道特征
在Centerfusion的初步检测阶段,仅使用相机信息作为输入特征。然而,在远距离和复杂环境下,由于目标像素特征占比过低,仅依靠相机信息进行初步检测可能导致鲁棒性不足的问题。与相机相比,雷达在极端环境条件下能够提供更多丰富而有用的目标信息。因此,为了解决这一问题,在Centerfusion的初步检测阶段,可以同时利用相机和毫米波雷达的特征进行初步检测。这种融合相机和毫米波雷达特征的方法能够充分利用二者之间的信息互补能力。
基于文献[12],本文加入了多通道特征输入,其中包括毫米波雷达的深度d、速度v、反射截面r和相机信息。首先,将毫米波雷达点云投影到垂直平面,并将投影在平面方向上进行拉伸以弥补高度信息。为了解决雷达数据稀疏问题,参考了文献[12]中的将13个毫米波雷达扫描帧进行聚合。垂直投影线的高度为参考的3 m,像素宽度为1。垂直投影线从3D空间中的地面开始,雷达点云离摄像机原点越近,线的高度越大。图2显示了点云投影到图像上拉伸的效果。

图2 雷达点云高度拉伸图Fig.2 Stretching diagram of radar point cloud height
将雷达回波特征作为像素值存储在特征图像中。对于没有雷达回波的图像像素位置,将对应的雷达投影通道值设置为0。这些雷达通道特征与RGB输入图像连接,共同构成多通道特征输入,作为Centerfusion目标检测网络的输入特征。图3展示了多通道特征输入的信息示意,其中包括摄像机图像通道特征和额外的雷达特征通道信息。

图3 多通道特征输入Fig.3 Multi-channel feature input
2.2 注意力特征融合
在视锥关联模块中选择距离中心点最近的雷达点云作为融合的雷达特征信息,视锥关联模块如图4所示。
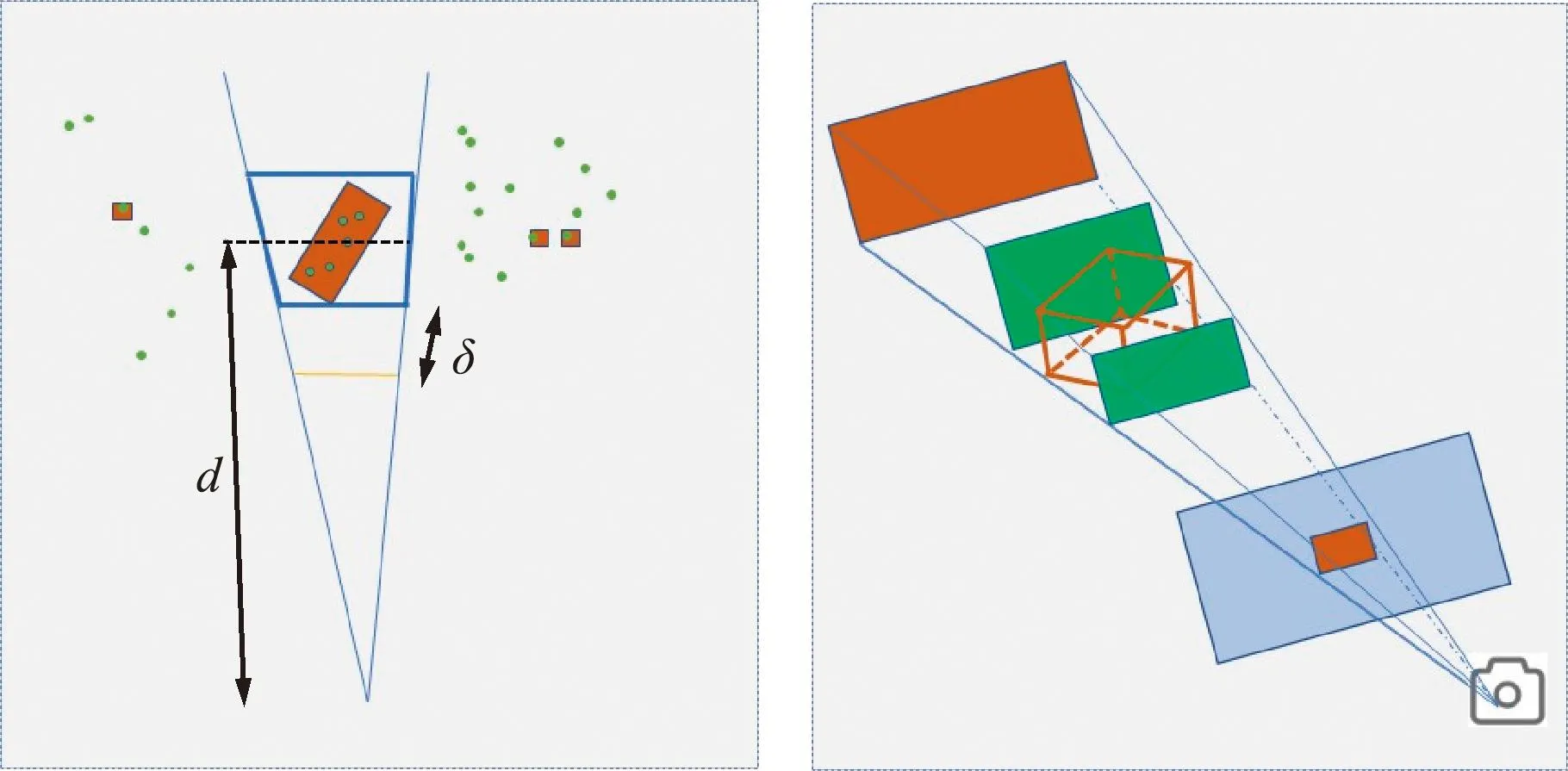
图4 视锥关联模块Fig.4 Visual cone correlation module
图4(左)为鸟瞰图视角下的视锥关联图,其中红色矩形为真实框,绿色点为毫米波雷达点云,d为训练阶段的真实深度值,δ为调节视锥大小的参数。图4(右)为基于3D边框生成视锥感兴趣区域,绿色形成的框架为初步预测的3D框,中间棕色的3D框为判断雷达是否关联的矩形区域,如果雷达存在该区域则视为关联,否则视为不关联。
通过视锥关联模块得到的补充雷达特征信息为包含深度d和2个方向速度vx、vy的3通道特征信息。该特征信息作为融合网络的一部分输入。
同时,目标检测网络通过输入多通道特征获得的特征热图也作为融合网络的另一部分输入,特征热图如图5所示。

图5 目标检测网络特征热图Fig.5 Feature heatmap of target detection network
为了更好地将2种特征热图信息进行融合。并考虑到CBAM[13]中为了避免特征维度缩减和增加通道间信息交互,在降低复杂度的同时保持性能。本文在文献[14]的基础上,设计了改进的高效卷积注意力模块(Efficient Convolutional Block AttentionModule,ECBAM)来促进2种特征信息更好地融合。把该补充雷达特征热图和目标检测网络得到的特征热图先分别经过改进的ECBAM,然后按通道拼接融合构成新的融合特征 。
改进的ECBAM构架如图6所示。在注意力通道模块中,输入特征F先经过去全局平均池化(Global Average Pooling,GAP)后得到F1,然后通过一个自适应卷积核大小为K的1D卷积且通过Sigmoid激活层得到的F2,F2和输入特征F相乘得到输出结果M1。M1同时作为空间注意力模块的输入特征信息,在通道方向上进行最大池化和平均池化,并将二者按通道堆叠得到M2,然后M2再通过一个7×7 大小卷积核的卷积层得到M3,M3通过 Sigmoid 激活层得到M4,最后将输入特征M1与该权重参数M4进行相乘,得到最终输出特征M。

图6 ECBAM架构Fig.6 ECBAM architecture
自适应卷积核尺寸K的计算如式(1)所示,其中,C表示输入层的通道数或特征图的通道数,γ=2,b=1,odd表示K只能能取奇数。
(1)
综上所述,在加入了多通道特征输入以及ECBAM融合方式之后,最终本文模型的整体网络架构如图7所示。
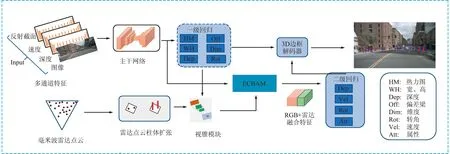
图7 整体网络架构Fig.7 Overall network architecture
2.3 损失函数改进
Centerfusion目标检测网络采用Centernet,Centernet的损失函数计算如式(2)所示,由热力图损失Lk,目标大小损失Lsize和中心偏移量损失Loff组成。
Ldet=LkλsizeLsize+λoffLoff,
(2)
式中:调节因子λsize=0.1,λoff=1。
(3)
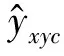
(4)

(5)
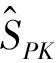
为了解决边界框不重合以及边界框宽高比导致的回归精度不高的问题,本文对损失函数进行改进,计算如式(6)所示:
(6)
式中:IoU[15]表示预测框和真实框的交并比,p表示为预测框和真实框中心点的距离,c表示预测框和真实框的最小box的对角线长,α表示权重系数,v表示衡量2个矩形框相对比例的一致性,其原理如图8所示。

图8 CIoU原理Fig.8 CIoU schematic
IoU计算如下:
(7)
式中:A表示真实框,B表示预测框。
α和v计算如下:
式中:wgt和hgt表示真实框的宽和高,w和h表示预测框的宽和高。
因此改进后的总损失函数如下:
Lloss=LK+LCIoU。
(10)
改进后的损失函数可以缓解Centernet预测时只有一个中心点而导致的准确度不高的问题,提升了目标检测网络的检测精度。
3 实验与分析
3.1 实验环境
本文使用的实验平台为 Ubuntu 20.04,开发语言为Python 3.7,深度学习框架为PyTorch 1.7,CUDA 版本为 11.1,CPU为至强Platinum 8350, 主频 2.60 GHz,内存43 GB,硬盘600 GB,显卡为RTX3090,24 GB显存。
3.2 数据集介绍
目前3D目标检测主流数据集包括Nuscenes[16]、Kitti[17]和Waymo[18]。本文采用Nuscenes数据集进行算法验证。它是目前主流的3D目标检测数据集之一,拥有6个摄像头、5个毫米波雷达、1个激光雷达进行数据采集。该数据集包括1 000个不同城市场景,每个场景时长20 s,包含40个关键帧。拥有140万张图片、130万个毫米波雷达扫描帧、39万个激光雷达扫描帧、140万个对象边界框、23个类别注释。在本文中舍弃了激光雷达数据,且数据分为10种类别:Car、Truck、Bus、Trailer、Const、Pedest、Motor、Bicycle、Traff、Barrier。
3.3 评估指标
Nuscenes数据集的检测任务评价主要指标包括:平均精度均值(mean Average Precision, mAP),Nuscenes检测分数(Nucenes Detection Scores,NDS)。其中计算mAP需要计算精确度P和召回率R,其计算公式如下:
式中:TP为真实样本而预测为真实样本,FP为错误样本而预测为真实样本,FN为真实样本而预测为错误样本。某一种类别的平均精度(AP)计算如下:
(13)
mAP是所有类别的AP之和,计算如下:
(14)
式中:n为10种类别。
NDS根据mAP以及平均度量mTP[19]计算得到,其中mTP指标包括5小类,分别是:平均平移误差(Average Translation Error,ATE)、平均尺度误差(Average Scale Error,ASE)、平均角度误差(Average Orientation Error,AOE)、平均速度误差(Average Velocity Error,AVE)和平均属性误差(Average Attribute Error,AAE)。NDS计算如下:
3.4 实验结果
本文对远距离小目标以及复杂背景环境下2组情况进行测试,检测结果如图9所示。

图9 对比检测结果Fig.9 Comparison test results
在图9中,从左至右分别为原图、基于Centerfusion的基模型检测结果以及本文模型的检测结果。其中,从最上方的3张图片可以看出,对于远距离小目标情况,公路上2个白色小车之间的黑车,以及公路右侧远处的一个行人没有被基模型Centerfusion检测出来,而本文模型能够在较远距离下正确地将目标识别出来。
第二组实验针对复杂背景下存在许多背景物体的情况进行了测试。从图9可以看出,基模型未能检测出远处草丛中的人和右方黑暗门口中的另一个人。此外,尽管基模型检测到了大树下的白色汽车,但是可以看出其3D边框存在较大的偏移误差,相比之下,本文模型因为引入了雷达特征信息,所以在相机模糊区域依然可以有效识别目标。此外,本文模型还采用了基于改进注意力机制的融合网络,使得大树下的白色汽车3D信息更加准确,因此相较于基模型,本文模型取得了更好的检测效果。
为了进一步验证本文所提出模型的有效性,在相同环境情况下,分别先后测试了Centernet、Centerfusion。算法性能对比如表1所示。

表1 算法性能对比Tab.1 Comparison of algorithm performance
从表1可以看出,本文模型相比于基模型Centerfusion在NDS指标上提升了1.2%,同时也在mAP指标上提升了 1.3%。此外,在mTP的各项误差指标中也获得了显著下降。综合各项指标来看,本文模型在目标检测性能上优于其他2种模型。此外,本文模型和其他2种模型各类检测目标的精度对比如表2所示。

表2 算法精度对比Tab.2 Comparison of algorithm accuracy
从表2可以看出,本文模型在各个目标类别的检测精度上都有显著提升,特别是针对小目标如Pedest、Motor和Bicycle等,相较于基模型Centerfusion分别提升了7.4%、9.3%和5.9%。而针对较大目标类别如Car、Truck、Bus和Trailer分别提高了1.8%、1.6%、2.6%和1.7%。这是因为本文模型针对小目标在相机信息中像素特征占比不足的问题进行了改进,引入了多通道特征进行补充,从而增强了目标检测的鲁棒性。此外,通过引入基于改进注意力机制的特征融合方案,结合毫米波雷达和相机特征,进一步提高了目标检测的准确性。
3.5 消融实验
为进一步验证本文各个模块的有效性,分别对多通道特征、融合方式以及损失函数进行消融实验,结果如表3所示。

表3 融合实验对比Tab.3 Comparison of fusion experiment
从表3第2组实验结果可以看出,仅仅加入了多通道特征之后,模型的mAP得到了显著提升,这是因为多通道特征可以解决相机特征不足的问题,改善了漏检现象。但是,在mATE上有所增加,这是因为多通道特征虽然可以补充额外信息,但也可能引入了一些错误信息,导致中心点定位不准确。
为了缓解该误差并更加准确地确定目标的中心点位置,第3组实验加入了改进的损失函数,从而提高了中心点的准确性,进而改善了mATE。
第4组实验相较于第1组实验,加入了基于改进注意力机制的融合方式,在NDS、mAP指标上相对于基模型和第1组实验都得到了提高,此外,在mASE、mAOE、mAVE和mAAE方面的改善较为明显,这是因为新的融合方式能够更好地匹配相机信息和雷达信息,从而更准确地还原物体的3D信息。
在第5组实验中,相较于第4组实验,引入了改进的损失函数,模型各方面参数均得到提升和改善。综合来看,通过这5组实验结果可以得出结论,本文模型在改进的方向上具有有效性,通过引入多通道特征、改进的损失函数和基于注意力机制的融合方式,显著提升了目标检测的性能。这些结果表明本文模型在多模态目标检测任务中的潜力和优越性。
4 结束语
针对当前3D目标检测中远距离小目标漏检以及复杂环境下对目标3D信息误检的问题,本文提出了一种基于毫米波雷达和视觉信息融合的3D目标检测方法,并在Nuscenes数据集上进行了模型验证与对比实验。实验结果表明,本文提出的多通道特征输入方式和新的融合方式相较于传统的单一相机通道特征以及简单融合方式具有更好的抗干扰能力和检测精度。由于条件限制,本文算法在速度上仍然存在缺陷,且没有在实车上进行测试。因此,未来将针对时效性和实用性进行验证并改善。
