信息量法耦合机器学习模型的西山煤田滑坡易发性评价
2024-02-21李凯新苏巧梅张潇远范锦龙白东升
李凯新,苏巧梅*,张潇远,范锦龙,白东升
(1.太原理工大学 矿业工程学院,山西 太原 030024;2.国家卫星气象中心,北京 100081;3.山西地质集团有限公司,山西 太原 030006)
0 引言
滑坡是一种地质灾害类型,它分布范围广、突发性强且破坏性大,严重影响地区社会经济发展[1-2]。区域地质环境是滑坡孕育的基础条件,人类工程活动、降雨等是滑坡的诱发因子,精准的滑坡易发性评价一直是滑坡风险评估管理的研究热点[3]。滑坡易发性是指在考虑各类滑坡致灾因子的综合作用下,区域发生滑坡的可能性或空间概率,对区域防灾减灾、科学规划管理和决策具有重要意义[4]。
滑坡易发性评价方法分为定性和定量2种类型[5]。定量统计分析方法主要有证据权、信息量、频率比、概率法和熵指数等[4]。随着遥感和地理信息技术的快速发展,各种机器学习模型在滑坡易发性评价中广泛应用。常用的机器学习模型有随机森林(Random Forest,RF)、逻辑回归(Logistic Regression,LR)、神经网络和支持向量机(Support Vector Machine,SVM)等[6],每种模型都有自己的优缺点。不同区域的地理位置、地质条件和气候环境等自然环境条件不同,滑坡致灾因子也不同,影响到滑坡易发性评价结果,因此,不同区域有不同的滑坡易发性评价模型。
统计分析方法无法解释各类致灾因子的非线性关系,机器学习模型学习能力强,但容易过拟合[5],一些学者尝试使用统计分析耦合机器学习模型来评价滑坡易发性,结果证明可以有效提高滑坡易发性评价的精度[7-9]。栗泽桐等[10]在研究青海沙塘川流域的滑坡易发性时,对比了单一信息量、逻辑回归模型以及二者耦合模型的结果,发现耦合模型的准确率较单一模型有了很大提高。郭子正等[11]以三峡库区某区为研究区,利用证据权法和优化后BP神经网络模型对研究区进行滑坡易发性区划,结果显示耦合模型预测精度高。徐胜华等[12]使用熵指数耦合LR和SVM模型研究滑坡易发性,预测结果精度较高。
山西省是我国重点采煤区,区内采空区面积所占比例较大,采煤过程破坏地表环境,引发一系列地质灾害。西山煤田是典型的煤矿开采区,煤矿开采活动使得区内滑坡灾害比较严重。以西山煤田为例,选择可以解决多源数据差异性的信息量(Information Value,IV)法,耦合不受主观因素影响的LR模型、具有高泛化能力的RF模型和计算效率高的SVM模型3种机器学习模型进行建模,为研究区防灾减灾提供可靠依据。
1 研究区概况
西山煤田是山西省六大煤田之一,地理坐标为(37°24′N~38°02′N,111°52′E~112°31′E),地处山西省中部,太原市区西部,东南部为太原市区和清徐县,中部大部分为古交市,西部主要是文水和交城县。研究区内地势西南高、东北低,地貌类型复杂,盆地、山地和丘陵都有分布,地貌分区有吕梁山区、晋中盆地、黄土丘陵以及山间谷地,属于构造剥蚀成因的低、中高山地貌。气候为北温带季风气候,春冬干旱少雨、夏季湿热多雨,寒暑、昼夜温差大,干湿季分明,年平均气温为7~9 ℃,年平均降雨量为410~500 mm。区域内矿区主要包括古交、西山和清交矿区,地下采空区分布广泛,在突发性地质灾害诱发因子作用下,极易造成地质灾害。西山煤田地理位置及区内地质灾害点位置空间分布如图1所示。

图1 西山煤田地理位置及区内地质灾害点位置空间分布Fig.1 Geographical location of Xishan Coalfield and spatial distribution of geological hazard locations in the area
2 滑坡数据及环境影响因子
2.1 数据源
根据山西省地质灾害调查编目数据,研究区内地质灾害点有崩塌205处、滑坡109处、泥石流33处、地裂缝25处、地面塌陷98处和不稳定斜坡44处。以广义滑坡定义下的崩塌、滑坡和泥石流灾害点作为滑坡样本数据,收集研究区其他遥感、基础数据和文献数据,数据源、精度及用途如表1所示。

表1 数据信息
2.2 环境影响因子
滑坡的发生和发展受地质条件和外界环境因素共同影响,地质条件包括地貌、构造和岩性等,外界环境因素包括水文环境因子、人类工程活动等[13]。在区域滑坡易发性评价过程中,合理地选取环境评价因子是非常关键的一步[14]。对西山煤田区域进行了充分的野外调查,尽可能收集完善的环境因子数据,结合前人已有研究成果,选取了高程、坡度、坡向、平面曲率、剖面曲率、地形起伏度、地表粗糙度、地形湿度指数(TWI)[15]、径流强度指数(SPI)[16]、岩土体、距断层距离、地震峰值加速度[17]、距河流距离、归一化植被指数(NDVI)、归一化建筑指数(NDBI)、改进的归一化差异水体指数(MNDWI)[18]、转换型植被指数(TVI)、土地利用类型、距道路距离和距采空区距离共20个环境影响因子进行滑坡易发性评价,西山煤田的20个环境影响因子如图2所示。
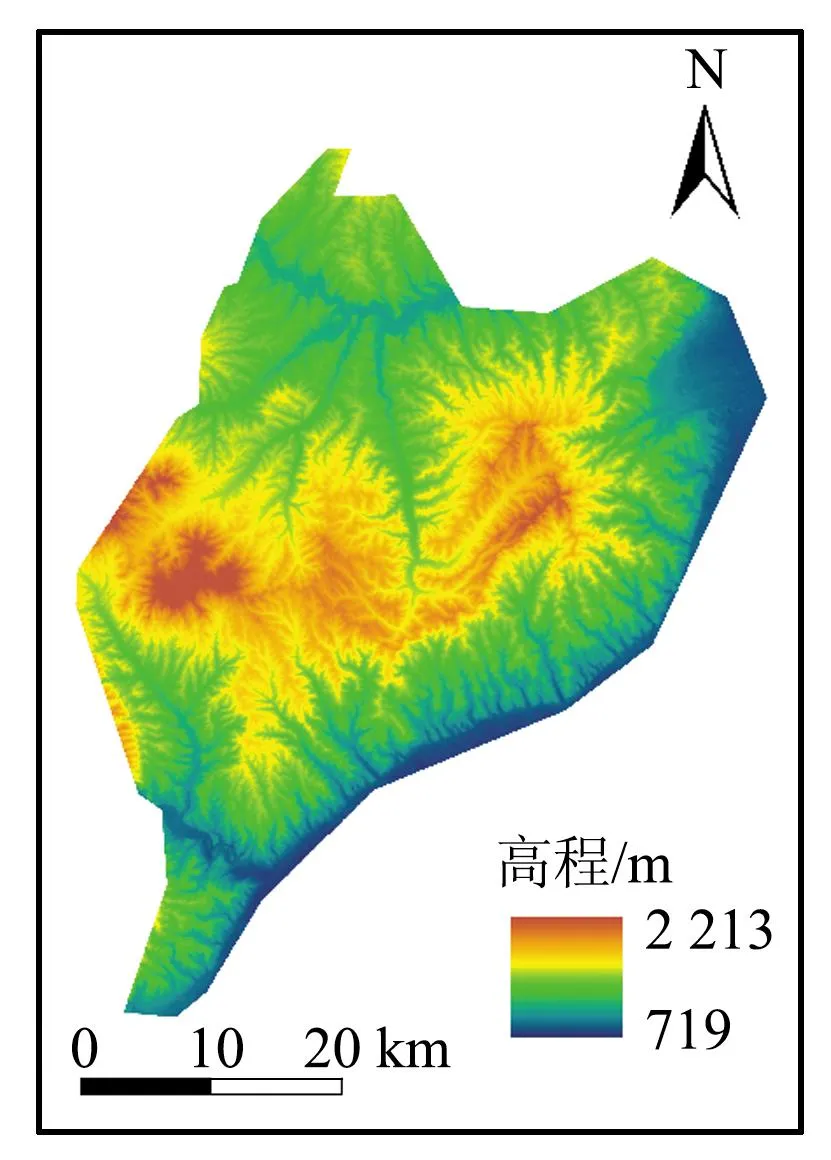
(a)高程
3 滑坡灾害易发性评价模型
3.1 IV法
IV法是一种基于信息论进行区域滑坡易发性评价的有效方法,适用于中小比例尺的滑坡易发性评价[19-20]。滑坡受多种影响因素的影响,各个因素的作用机理和影响程度不尽相同[10],IV法利用滑坡发生的概率或密度来反映不同评价因子的影响程度,计算各个影响因子不同区间对滑坡贡献的IV值[21]。一般情况下,IV的计算可以用滑坡发生的频率来代替条件概率,IV值计算方法[22]如下:
(1)
式中:IV(i,j)表示第i个环境影响因子在第j个分级区间的IV值,A(i,j)表示第i个环境影响因子在第j个分级区间内的滑坡数量,A表示研究区内的滑坡总数,B(i,j)表示第i个环境影响因子在第j个分级区间内的栅格单元数量,B表示研究区栅格总数。
3.2 机器学习模型
3.2.1 LR模型
LR模型属于线性回归方法,模型基于二项分类,能够对定性变量的准确性进行有效的分析[22]。利用逻辑回归模型进行滑坡易发性评价时,将单个环境影响因子的数据作为自变量,因变量为是否发生滑坡灾害[10,23]。其中,滑坡发生值为1,滑坡未发生值为0[24]。一般情况下,LR模型的方程如下:
(2)
式中:p和1-p分别为滑坡发生和不发生的概率,L(P)为滑坡发生概率的目标函数,C0为一个常数,指在无任何因素影响时,p与1-p比值的对数;[x1,x2,…,xn]为自变量影响因素集,[C1,C2,…,Cn]为逻辑回归系数,即[x1,x2,…,xn]的估计参数。
3.2.2 RF模型
RF模型是基于多个决策树的模型,基本原理是对不同的因子数据集,创建多个决策树,使用多个决策树对样本进行训练和测试,然后对多个决策树得到的结果进行投票,得到RF模型的最终结果[25]。RF模型在训练集随机选择以及分裂属性随机选取,能够防止模型过拟合,提高稳定性[26]。RF模型的运行流程如图3所示。
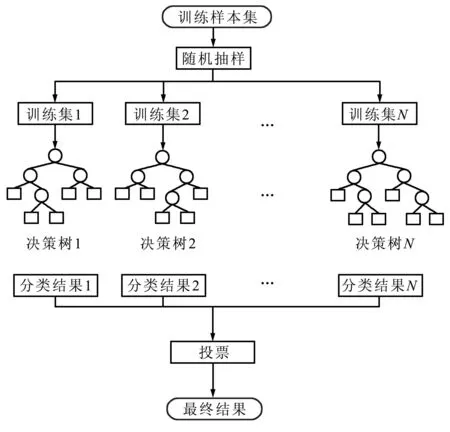
图3 RF模型运行流程Fig.3 Running flowchart of RF model
3.2.3 SVM模型
SVM模型是统计分析方法下,源于风险最小化的新一代算法[27]。SVM的基本原理是通过核函数(非线性映射),将输入向量数据(非线性可分)映射到更高维度的特征空间中,然后在这个空间中寻找能将二类数据高效分开的分类最优超平面[28]。SVM是一种集成了核函数、最大区间超平面技术的二分类监督分类,适用于小样本、非线性和高维度的数据分类[29]。SVM在处理二类分类问题时,训练样本集Xi(i=1,2,…,n)分为2类,表示为Yi=±1。SVM要寻找一个以最大间隔区分二类数据的n维超平面(平面或曲面),且要求分开的数据点到超平面的距离最大[30]。超平面H的数学表达式及约束条件分别见式(3)和式(4):
(3)
Yi((H·Xi)+a)≥1,
(4)

(5)
假设L对于H和a的偏导数均为0,得到式(6)和式(7):
(6)
(7)
将式(6)和式(7)带入式(5),得到式(8):
(8)
式中:λi大于0。
3.3 IV耦合机器学习模型
IV耦合机器学习模型是利用已知的滑坡点和随机选取相同数量的非滑坡点来提取不同因子各区间的IV值,这样,不仅考虑了不同因子对滑坡发生的贡献权重,而且兼顾了不同因子各区间致灾效应的大小,进而对滑坡易发性进行评价[31]。在滑坡灾害易发性评价中,IV法耦合机器学习模型的基本思想是利用IV模型计算各个环境影响因子的IV值,以此作为LR、RF和SVM模型的输入变量,建立用于滑坡易发性评价的耦合模型。将IV法与LR、RF和SVM这3种基于Python的机器学习模型耦合,构建西山煤田滑坡易发性评价模型,分别记作IV-LR、IV-RF和IV-SVM模型。
4 西山煤田滑坡易发性评价
4.1 IV计算
在计算IV值之前,用自然间断点分级法对各环境影响因子进行重分类,各个影响因子的分级标准、IV值和IV值排序计算结果,各影响因子的IV值如表2所示。

表2 各影响因子的IV值
由表2可以看出,IV值最小的因子为地形起伏度因子为0~150 m区域,IV值最大的因子为土地利用类型中的人造地表类型。各环境影响因子的权重可通过利用单个因子各区间的IV值和区间内滑坡灾害的数量来计算并标准化,单一因子权重数值及标准化计算如下:
(9)
(10)
式中:Wi为第i个环境因子的权重值,j为因子分级区间,ni为第i环境因子的分级数量,IV(i,j)、A(i,j)分别为第i个环境影响因子在第j分级区间的IV值、滑坡数量,Wmax、Wmin分别为所有环境因子权重值中的最大、最小值,Si为标准化后的因子权重值。各评价因子标准化权重指数值计算结果如表3所示。
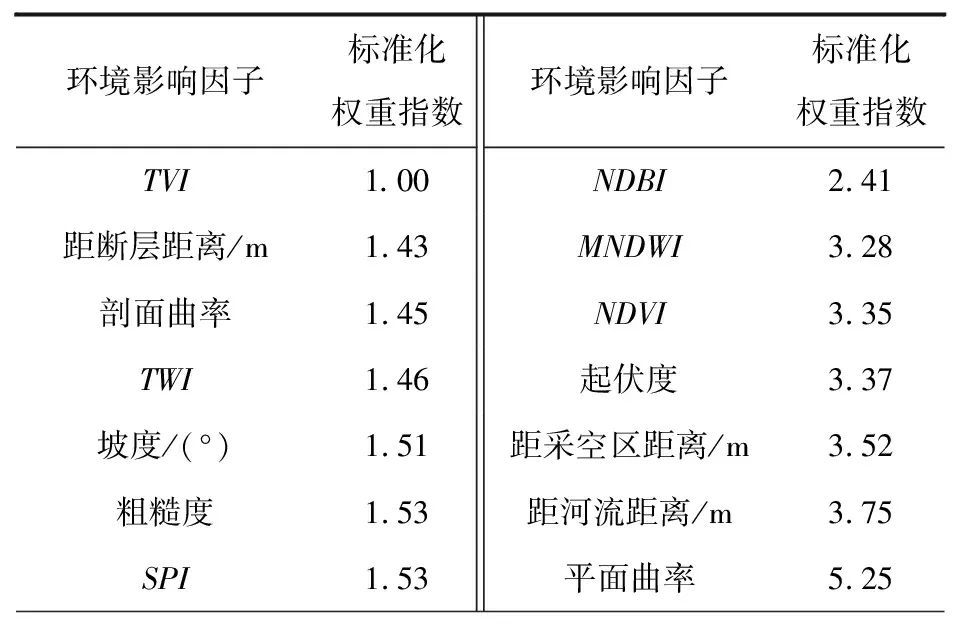
表3 各评价因子标准化权重指数值计算结果
由表3可知,TVI权重指数最小,距道路距离权重指数最大。
4.2 数据准备与处理
对西山煤田滑坡易发性进行评价,首先要获得研究区滑坡灾害数据和各类环境影响因子数据。滑坡预测单元的空间分辨率为30 m,整个西山煤田全区共有栅格单元226.114 6万个。针对滑坡易发性评价建模中非滑坡点的构建,依据滑坡点与非滑坡点比例为1∶1、非滑坡点与滑坡点的距离大于400 m以及任意2个非滑坡点之间的距离大于200 m这3项条件[32],在ArcGIS平台上生成滑坡负样本点。滑坡正、负样本点分别赋值0、1,以此为模型的输出变量,将环境因子原始值重新赋值为IV值,作为模型的输入变量。将滑坡样本点数据按7∶3的比例随机划分为训练集和测试集,把整个研究区内20个影响因子的IV值输入模型中,预测结果根据自然间断点法划分为易发性极低、低、中、高和极高5个区间。
4.3 滑坡易发性评价结果
构建了3种信息量法耦合机器学习模型,分别为IV-LR模型、IV-RF模型和IV-SVM模型。针对不同的模型,滑坡易发性划分有不同的分级标准,西山煤田滑坡易发性分级标准如表4所示。
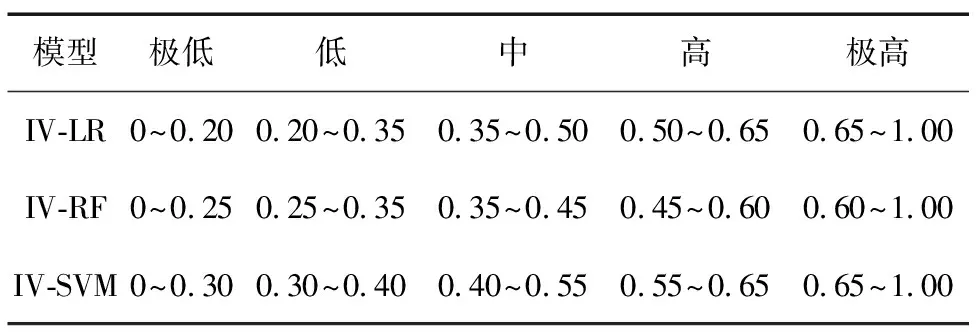
表4 西山煤田滑坡易发性分级标准
将3种信息量法耦合的机器学习模型计算得到滑坡易发性指数结果导入ArcGIS软件中,得到西山煤田滑坡易发性分区结果,不同模型滑坡易发性预测结果如图4所示。
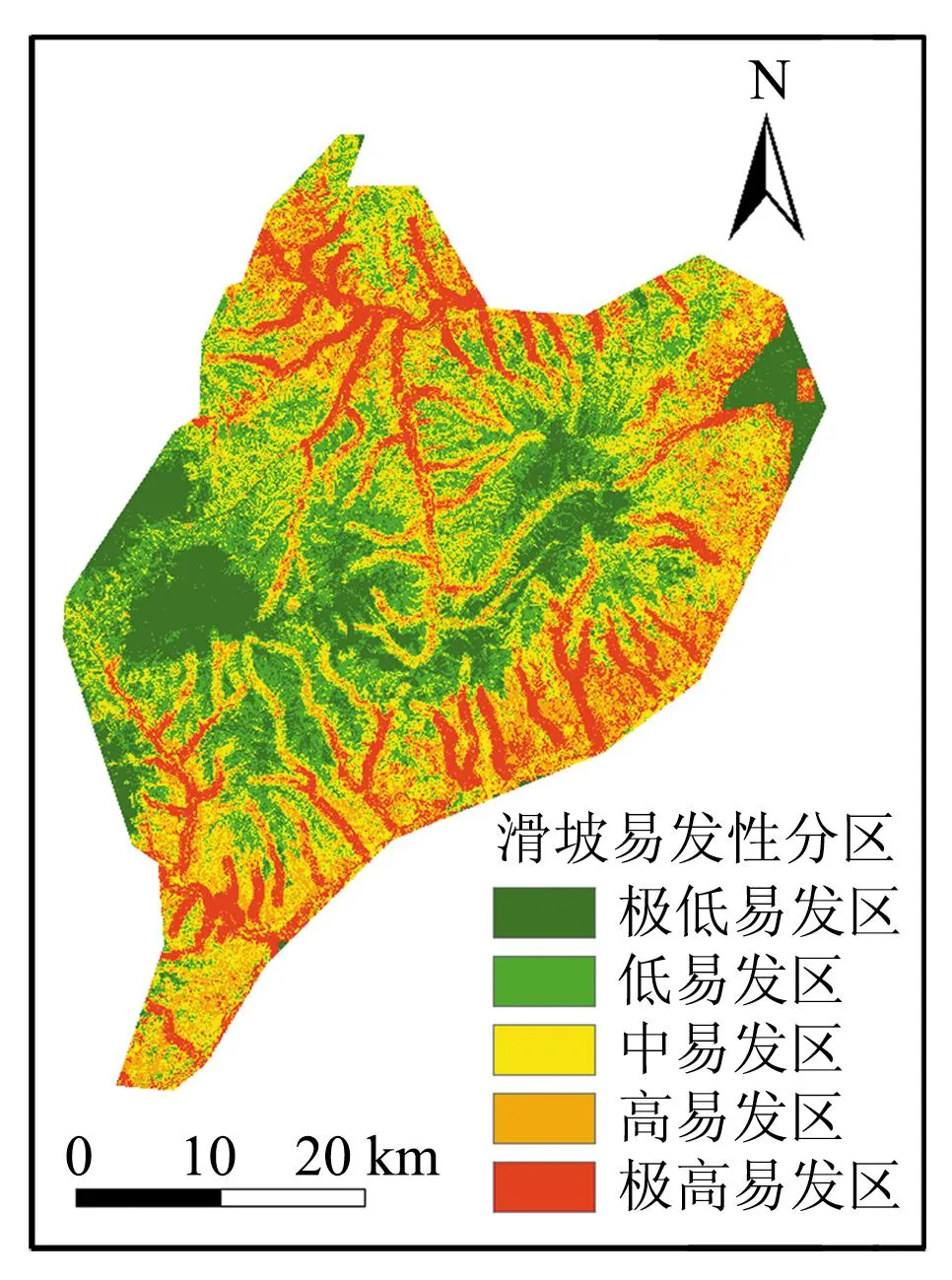
(a)IV-LR模型滑坡易发性分区
由图4可以看出,不同耦合模型的预测结果具有一定的相似性,滑坡易发性分区图具有以下特点:
① 高、极高滑坡易发区主要分布在距离水系300 m左右的区域内,水系对河岸坡体的软化和冲刷作用会降低岩体强度,有利于滑坡灾害的发育形成。
② 极低和低滑坡易发区主要分布在研究区的中西部地区,但不同模型预测面积不同,IV-SVM模型预测下极低、低易发区面积最大,IV-LR模型次之,IV-RF模型预测面积最小。
③ 各信息量模型结果中,西山煤田大部分区域为中、高和极高等级易发区,低和极低易发区面积较小,研究区内采空区分布广泛,有利于滑坡灾害的发育。
④ IV-LR模型、IV-RF模型和IV-SVM模型预测结果在研究区东北部的一块区域有明显不同,该区域地处太原市万柏林区和晋源区。IV-LR模型预测该区域滑坡易发性等级大部分极低,有一小块地区分级为高或极高等级,而在IV-RF模型下这一区域分级为中、高等级,在IV-SVM模型下分级为低、中等级易发区。
根据不同IV法耦合模型的预测结果,统计滑坡易发性等级区间的栅格数目及所占比例、落入各区间内的训练集滑坡数及所占比例,不同模型各等级易发区比例统计结果如表5所示。

表5 不同模型各等级易发区比例统计
由表5可以看出,IV-LR模型和IV-RF模型随着滑坡易发性等级的升高,分级区间内滑坡点的数目逐渐增加,而IV-SVM模型结果不同于前2种模型,其中等滑坡易发区内的滑坡数大于高滑坡易发区。IV-LR、IV-RF和IV-SVM模型落入模型高—极高易发区的滑坡灾害点比例分别为67.72%、76.08%和57.06%,超过半数以上的滑坡灾害点都发育在高—极高易发区内,而低—极低易发区内滑坡点数量显著减少,与西山煤田实际滑坡灾害发育情况相吻合,3种信息量耦合模型都可以有效评价西山煤田滑坡灾害易发性。IV-SVM模型预测结果与IV-LR、IV-RF模型区别明显,极低易发区面积占比最大,高易发区面积最小。
4.4 建模结果不确定性分析
4.4.1 精度评价
计算各IV法耦合机器学习模型在测试集上的预测准确率,模型的准确率是指评价模型分类结果中分类正确的样本个数占测试集样本总数的比例,计算如下:
(11)
式中:TP表示正样本被评价模型分类正确的个数,即真正例;TN表示负样本被评价模型分类错误的个数,即真反例;FP表示正样本被评价模型分类错误的个数,即假正例;FN表示负样本被评价模型分类错误的个数,即假反例。经计算,IV-LR、IV-RF和IV-SVM模型在测试集上的预测准确率分别为76.67%、74.62%和78.57%,模型的预测准确率差别不明显,但都大于70%,都可以有效评价西山煤田滑坡易发性。
利用广泛使用于滑坡易发性模型精度评价中的受试者工作特征(Receiver Operating Characteristic,ROC)曲线和曲线下面积(Area Under Curve,AUC)值对评价模型的精度进行对比分析,AUC值越大,模型的分类正确率越高、精度越好[30]。IV法耦合机器学习模型的ROC曲线如图5所示。
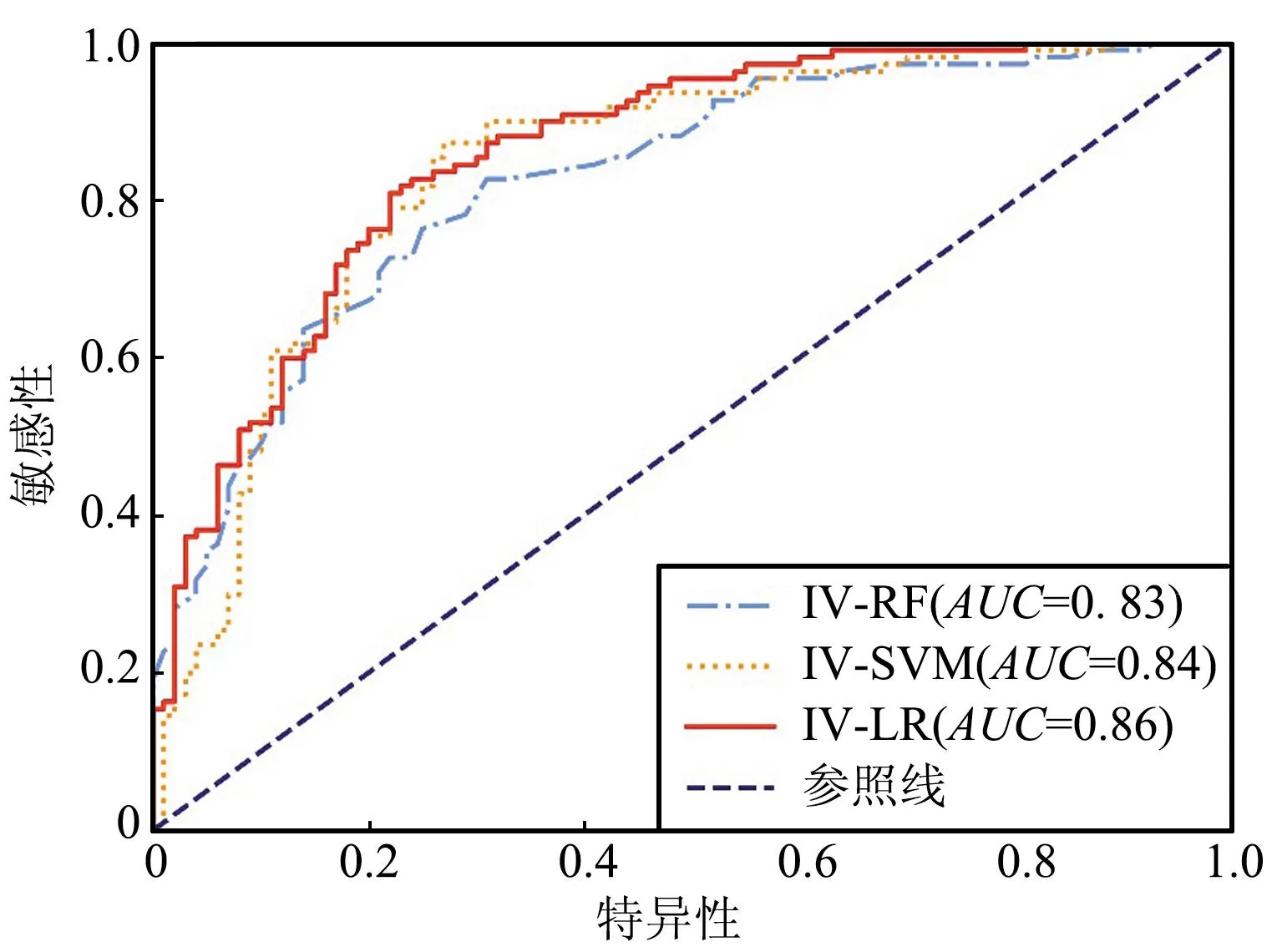
图5 信息量法耦合机器学习模型的ROC曲线Fig.5 ROC curves of information value method coupled machine learning model
由图5可以看出,IV-LR、IV-RF和IV-SVM模型的AUC值分别为0.86、0.83和0.84。将3种耦合模型的ROC曲线进行对比,AUC值表明,3种模型的建模精度相差不大,均在0.8以上,模型预测结果良好,其中IV-LR模型预测结果最好,IV-SVM模型次之,IV-RF模型AUC精度最差。
4.4.2 滑坡易发性指数分布规律
计算各耦合模型预测下滑坡易发性指数的平均值(Mean)和标准差(Standard)来分析模型预测的不确定性。IV-LR模型、IV-RF模型和IV-SVM模型预测下,滑坡易发性指数分布结果不相同,不同模型的滑坡易发性分布如图6所示。
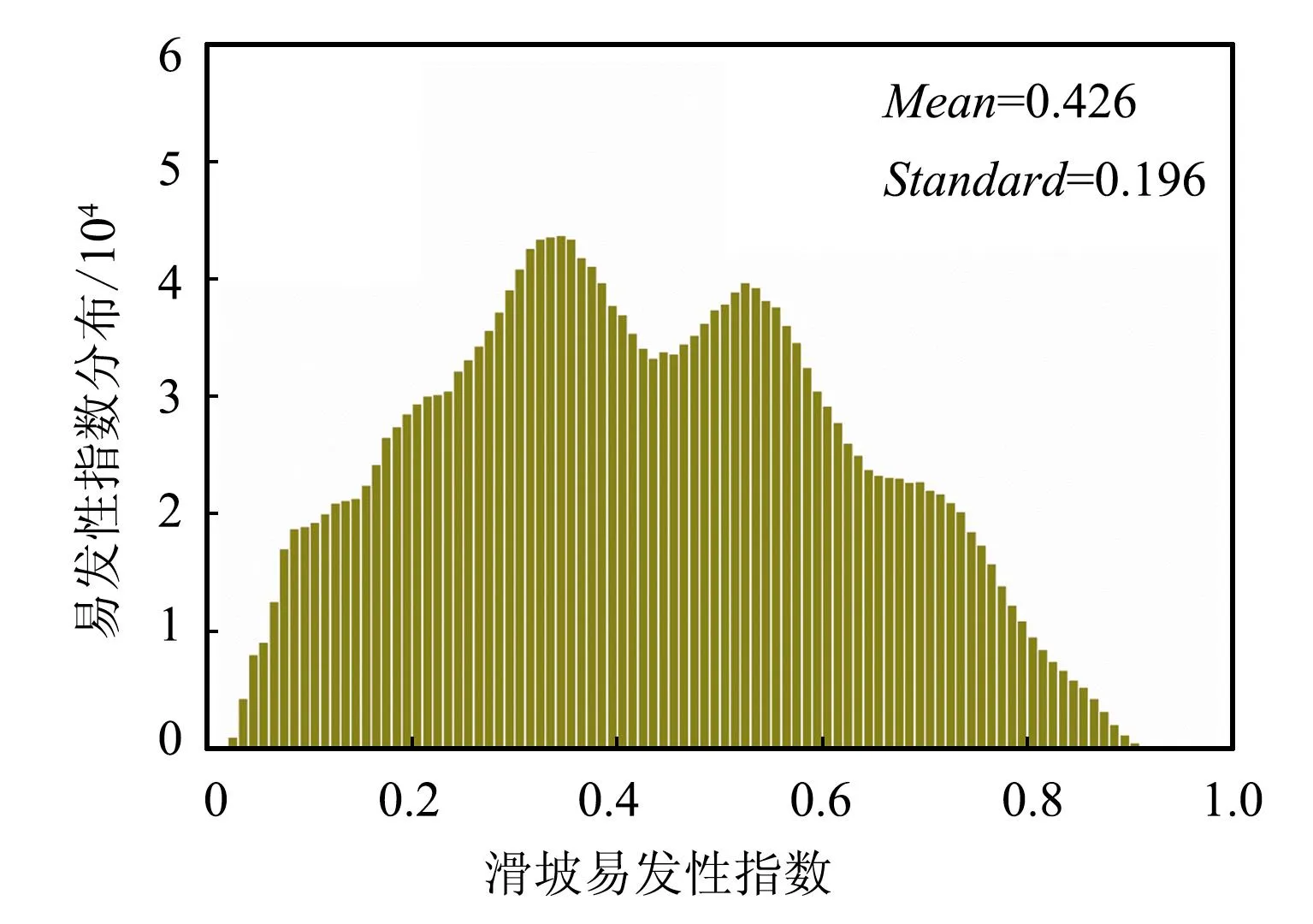
(a)IV-LR模型
由图6可以看出,IV-LR、IV-RF和IV-SVM模型下易发性指数Mean分别为0.426、0.425和0.440。从易发性指数分布离散情况来看,IV-LR模型离散程度最高,然后是IV-SVM模型,IV-RF模型离散程度最低。IV-LR模型预测的Standard最大,Mean和最小的0.425相差无几,模型AUC值最高,所以IV-LR模型对西山煤田的滑坡易发性区分度较好,能够很好地反映不同栅格单元的滑坡易发性指数差异性。IV-RF模型预测易发性指数Mean和Standard都是3个模型中最小的,结合其验证精度和AUC值也是最小,表明该模型对研究区滑坡易发性的区分度较IV-LR和IV-SVM模型差一些。IV-SVM模型预测的易发性指数数值普遍偏大,在极低易发区分布较少,离散度居中。
5 结论
通过3种信息量法耦合机器学习模型对西山煤田的滑坡易发性进行评价,结论如下:
① 西山煤田高、极高滑坡易发区主要分布在距离水系300 m左右的区域内,极低和低滑坡易发区主要分布在研究区的中西部地区,区内大部分区域为中、高和极高等级易发区,低和极低易发区面积较小。研究区内不同耦合模型的预测结果具有一定的相似性,但在区内东北部部分区域滑坡易发性分布有明显不同。
② IV-LR模型和IV-RF模型结果显示,随着滑坡易发性等级升高,区间内滑坡点的数目逐渐增加。各信息量耦合模型中半数以上的滑坡点都在高—极高易发区,低—极低易发区内滑坡点很少,与实际滑坡灾害情况相吻合,说明各模型均可有效评价西山煤田滑坡灾害易发性。
③ IV-LR、IV-RF和IV-SVM模型的验证精度分别为76.67%、74.62%和78.57%,AUC值分别为0.86、0.83和0.84,再结合不同模型的滑坡易发性指数Mean及分布情况表明,IV-LR模型对西山煤田的滑坡易发性分区效果最好,模型分类精度最高,能很好地反映不同栅格的滑坡易发性差异。
