双注意力机制的复杂场景文字识别网络
2024-02-21宋问玉杜文爽王丽园
宋问玉,杜文爽,封 宇,王丽园
(1. 华中电力国际经贸有限责任公司,湖北 武汉 430066;2. 中国电力技术装备有限公司,北京 100052;3.武汉大学 电子信息学院,湖北 武汉 430072;4.中交第二公路勘察设计研究院有限公司,湖北 武汉 430040)
0 引言
光学字符识别(Optical Character Recognition, OCR )[1]具有丰富的应用场景,最重要的应用之一是自然场景下的文本识别。随着人工智能技术的兴起和万物互联(Internet of Everything,IoE)的发展,使用OCR技术代替传统算法识别,既能降低信息识别错误率,也能提高应用系统的安全性和便利性。
近年来,研究者们在目标检测、语义分割等领域使用深度学习方法替换传统计算机视觉方法,取得了显著的成果。Liao等[2]对于竖直、倾斜的文本检测提出改进的Textbox++网络,在预选框宽高比中增加了小数,并将卷积核改为3×5,来更好地适应竖直和倾斜文本的检测。文献[3]提出一种角度优化的印章文字检测与识别算法,先通过极坐标变换将印章拉伸,再进行检测。Tang等[4]对文本弯曲和密集问题,提出一种模块,用来表示文本块之间吸引和排斥,并设计instance-aware损失函数使Seglink++网络可以端到端地训练。Wang等[5]设计了轻量级特征增强模块(FPEM)和特征融合模块(FFM),提高文本检测性能,后处理采用更加快速的像素聚类方法,提高了文本检测速度。陈静娴等[6]设计实现了联合注意力特征增强模块 (Joint Attention Feature Enhancement Module, JAM), 利用卷积对级联后的特征在不同通道之间、 空间位置间的联系建模。Liao等[7]发现基于分割的算法在阈值二值化处理耗时较多,提出了可以自学习分割阈值的网络——DBNet,并巧妙设计了一种二值化函数,检测精度得到提升、检测速度大大提高。Zhu等[8]创新地将弯曲文本轮廓线用傅里叶变换参数表示,而数学上傅里叶系数可以拟合任何曲线,结合设计的FCENet网络,提高了文本检测的精度。文献[9]提出了一种将残差神经网络与自注意力机制相结合的主干网络,在提升准确度的基础上,减少了注意力机制的偏差和RNN的耗时。陈瑛等[10]提出了一种基于层次自注意力的场景文本识别网络。通过融合卷积和自注意力增强文本序列与视觉感知之间的联系。虽然许多文字识别算法已经获得了比较精确的检测结果,但是仍然有许多问题需要解决。例如:路标的文本行存在文本分布位置、字符间隙差异,造成文本检测框粘连的问题,字体字迹多变,路标字符包括英文、中文和标点符号等6 000类字符,加上各类印刷字体的差异,给文本检测带来了困难。
针对以上问题,本文主要创新点在于:① 提出了一种双注意力和内容感知上采样的文本检测网络,双注意力机制用于提高网络的特征提取选择能力;内容感知上采样模块可以增大原上采样的感受野,提高内容感知能力;② 将卷积递归神经网络(Convolutional Recurrent Neural Network,CRNN)[11]与连续时序分类(CTC)结合,通过将序列特征接入CTC进行解码计算文本识别损失,解决CRNN在设定时间长度与真实文本长度不一致的问题,同时增加中心损失增大字符之间的特征间距,避免“误检”问题。
1 算法模块设计
1.1 算法概述
OCR算法框架如图1所示,主要包括三部分:预处理、文本检测和文本识别。预处理部分采用带颜色恢复的Retinex图像亮度增强和基于自适应对比度增强(ACE)的图像色彩增强;文本检测部分提出了基于双注意力和内容感知上采样的DBNet的文本检测算法,精确地截取图片中的文本行区域,保留文本行检测坐标;文本识别部分提出了融入中心损失的CRNN+CTC文本识别网络,识别出文本行图像的内容。

图1 OCR算法框架Fig.1 Framework of OCR algorithm
1.2 文本检测模块
文本检测模块采用基于双注意力和内容感知上采样的DBNet文本检测网络。与传统使用设定好的阈值图对概率图进行二值化的分割网络不同,DBNet网络可以生成阈值图(Threshold Map),实现自适应分割,生成近似二值化图(Approximate Binary Map),文本检测结果更加准确。可变形卷积 (Deformable Convolution Network,DCN)[12]的使用,给原有卷积核加入偏移量,使得卷积网络能够自适应地调整感受野,有效提升了DBNet网络对文本行的检测能力。设输入特征图为X,则对p0中心点进行标准卷积:
(1)
式中:R={(-1,-1),(-1,0),…,(0,1),(1,1)}。可变形卷积单元中增加了偏移量Δpn,如下:
(2)
可变形卷积示意如图2所示,输入特征图在C常卷积之前,先通过一个标准卷积单元计算得到尺度不变、通道数为2N的偏移域,其分别代表卷积视野每层像素点在x轴和y轴的偏移量。标准卷积核加上该偏移量之后,卷积核的大小和位置可根据输入特征图的内容进行自适应调整,从而更好地适应形状不规则、形变的文本区域。
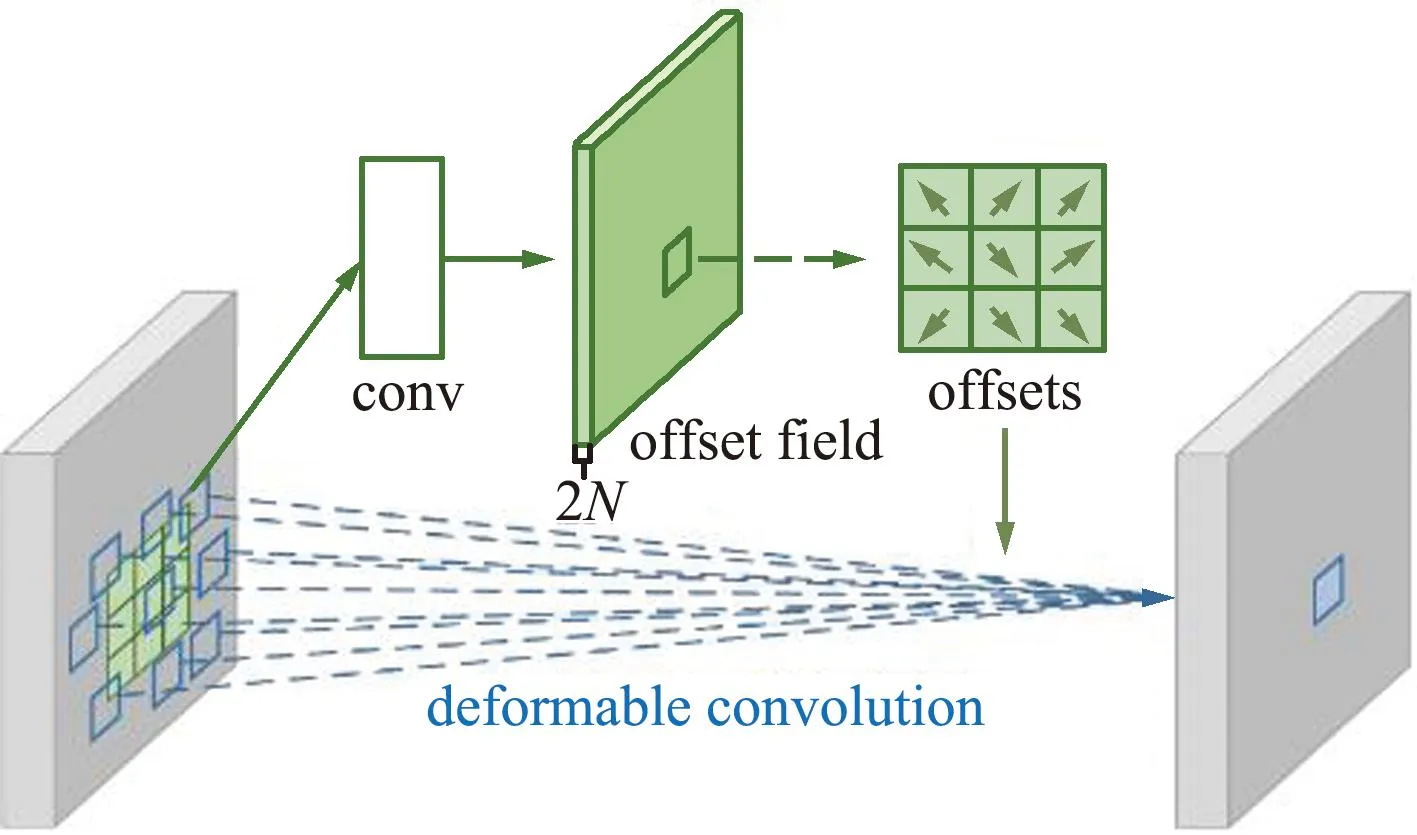
图2 可变形卷积示意Fig.2 Schematic diagram of deformable convolution
DBNet网络的特征提取采用ResNet残差网络,在ResNet的每个残差块中加入了双注意力模块 (Convolutional Block Attention Module, CBAM)[13]。该模块由通道注意力和空间注意力两部分组成,融合双注意力残差模块如图3所示。通道注意力自适应调整特征图不同通道的权重,提高了对重要特征的选择能力,滤出或减弱干扰的特征;空间注意力自适应调整特征图不同位置的权重,提高对场景中文本区域的辨识度,抑制场景文本的背景区域。

图3 融和双注意力的残差块Fig.3 Residual blocks incorporated with a dual attention
其中,通道注意力考虑了特征图中不同通道的重要性,所以通过生成大小为1×1×C的Mc向量,作为特征图F的不同通道的系数。而空间注意力考虑了特征图不同位置的重要性,通过生成大小H×W×1的矩阵,给特征图F′不同空间位置赋予不同的系数。下面分别介绍通道注意力和空间注意力模块的设计,如图4和图5所示。
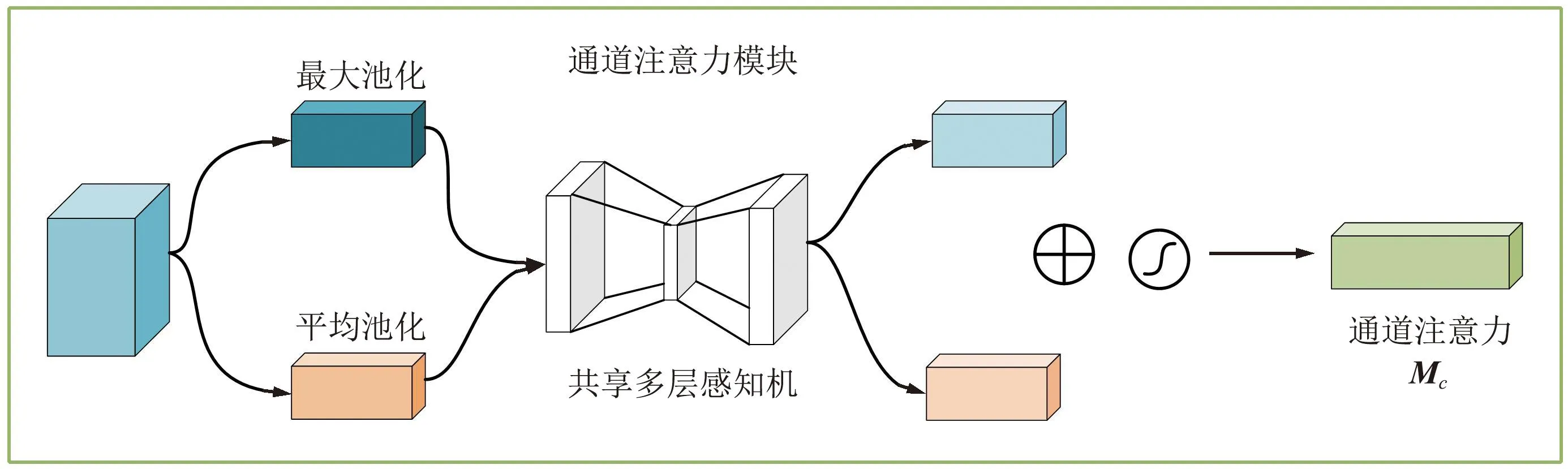
图4 通道注意力模块示意Fig.4 Diagram of channel attention module

图5 空间注意力模块示意Fig.5 Diagram of spatial attention module
输入特征图记为F,其大小为H×W×1,对其分别进行空间维度上的最大池化和平均池化得到2个大小为1×1×C的向量,其中最大池化提取的是细节特征,而平均池化提取的是背景特征。2个向量特征共享一个多层感知机(Multilayer Perceptron,MLP),将二者输出结果逐像素相加并经过sigmoid激活层,得到大小为1×1×C的通道注意力Mc。最后将Mc作为通道系数和特征图F相乘,得到通道提纯特征图F′。
将通道提纯特征图F′作为输入,与通道注意力模块不同,空间注意力模块是在通道维度上分别进行最大池化和平均池化,输出结果大小为H×W×1,将池化结果拼接在一起,然后通过卷积层和sigmoid激活层,得到大小为H×W×1空间注意力Ms,并作为系数,与通道提纯特征图F′逐像素相乘,得到最终的提纯特征图F″。同时将残差网络ResNet部分的标准卷积替换成图2所示的可变形卷积,以适应形状不规则和字体多变文本的特征提取。除此之外,在特征金字塔(Feature Pyramid Network,FPN)网络将ResNet生成的不同尺度的特征图进行融合时,使用具有内容感知的上采样算子(Content-Aware Re Assembly of Features, CARFE)[14], 进行不同尺度特征图的融合,其算子结构如图6所示。
CARFE主要包含两部分:上采样核预测模块(Kernal Predication Module)和内容感知重组模块(Content-Aware Reassembly Module),前者根据样本内容特征信息预测出上采样核,后者根据预测的上采样核进行内容重组。设输入特征图为χ,尺寸为H×W×C,假设上采样倍率记为σ,则输出上采样结果为χ′,尺寸大小记为σH×σW×C。
上采样核预测模块:先通过1×1卷积组成的通道压缩 (Channel Compressor) 模块,将输入特征图通道压缩至Cm,以减少后续计算量。假设上采样核尺寸为kup×kup,则对于输出结果中任意一个元素l′∈χ′,都有与之对应的上采样核,所以预测的上采样核尺寸应该为σH×σW×kup×kup。因此采用了σ2kup2个尺寸为kencoder×kencoder的卷积核进行内容编码(Content Encoder),输出尺寸为H×W×σ2kup2,并在通道维度上展开,这样得到尺寸为σH×σW×kup×kup上采样卷积核,最后经过核归一化处理(Kernel Normalizer),使得上采样核的元素之和等于1。
内容感知重组模块:对于输入特征图中任意元素χl,取出以其为中心的kup×kup感受野范围的像素N(χl,kup),从上采样核取出对应位置的元素l′,并在通道维度上展开,得到该点处的kup×kup大小上采样核Wl′,经过点积得到该位置的上采样值。
由此可知,输入特征图不同位置的像素对应的上采样核是不一样的,其上采样核是由输入特征图内容所决定的,做到了“内容感知”。除此之外,上采样感受野尺寸为kup×kup,相比较最近邻上采样或双线性插值上采样,做到了较大的感受野,有效地弥补了原上采样的缺陷。
1.3 融入中心损失的CRNN+CTC
文本识别网络主要分为Seq2Seq+Attention[15]和CRNN+CTC。前者是循环神经网络的变种,包括编码器和解码器两部分,CNN网络提取到特征序列后并行输入到编码器,用于计算编码器当前时刻的隐藏状态,所有隐藏状态编码得到统一语义特征向量C,后面再对语义向量进行解码,由于Seq2Seq将所有输入特征汇聚成统一语义向量C,导致解码过程全部依赖C,因此进行长文本检测时,文本偏后的字符获取信息较少,识别效果不够理想,且Attention机制给网络带来巨大的额外参数量。 CRNN+CTC结构分为CNN、RNN和CTC三部分,CNN网络用于提取特征序列,RNN网络将提取到的字符特征序列并行输入到序列长度为T的双向LSTM中,一般来说长度T取待识别文本的最大字符数,考虑到在本文所述场景下的极端情况,设置T=25,并构建了6 623个字符的中英文词典,和T配合成后验概率矩阵,得到字符后验概率矩阵后,CTC在原有中英文词典集的基础上引入空白特殊字符,用以表示该位置没有字符。可以消除在文本字符数小于25时直接通过softmax层得到的长度为25的字符串难以计算其文本识别损失的情况,该方法在长短文本识别效果都较为理想,且得益于CTC向前-向后递推,既能保持较低的计算复杂度,也不会给网络带来额外的参数。但CRNN+CTC只适用于一维形状规则的文本行,对于形变、不规则文本识别效果较差,考虑到路标中的文本行都是规则文本行,本文采用了CRNN+CTC。在CRNN+CTC基础上,尝试加入中心损失,进一步提高字符识别准确率。
由前文可知,CRNN+CTC文本识别网络中CTC损失是先通过softmax求出序列中每个预测字符的概率,再通过CTC转录解决文本序列对齐问题,本质上文本识别是字符图像的分类问题,而字符分类错误是由字符特征决定的。本文加入了用于增大样本特征分布间距的中心损失函数(Center Loss)[16],原理如下。
对于一个全连接分类网络来说,假设输入特征向量xi∈d,网络矩阵参数为W∈d,预测类别为yi,共有m类,softmax分类损失如下:
(3)
Center Loss函数定义如下:
(4)
式中:Cyi表示yi类别特征分布的中心,xi表示输入进全连接分类层的特征,m表示训练中每个batch的样本数量。由上式可知,Center Loss是计算样本特征和特征中心的距离,希望一个batch中输入样本的特征与该类的特征中心之间的距离越小越好。中心损失Lc和特征中心Cyi更新如下:

(5)
(6)
式中:δ(yi=j)表示当分类类别为j时,等于1;否则等于0。由此可知,只有当预测的类别yi与真实标签j相等时,才会更新该类的特征中心Cj。将Center Loss以一定的权重λ加入到分类损失函数中,如下:
Ltotal=Ls+λLc。
(7)
文献[14]以手写数字识别分类为例,给出了不同λ情况下,手写数字特征分布的变化,如图7所示。

图7 手写数字识别特征分布Fig.7 Distribution of handwritten digital recognition features
由图7可知,随着λ不断增大,类与类之间的间隙越来越大,各类特征分布界限越来越清晰,从而可以减少分类错误。
对于复杂场景文本识别,文本混杂着汉字、英文和数字等各类字符,共6 000多个类别,汉字中存在的大量形似字,所以相比纯英文文本识别,本文字符分类难度大幅度提高。印刷字体的特性和路标图像存在少量噪声,导致更容易出现字符相近的情况,如字母“l”和数字“1”,汉字“治”和“冶”。本文尝试将中心损失加入到CTC损失函数中,并将λ设置为0.1。希望通过增大字符特征分布之间的间隙,减少字符误识别的情况,从而提高文本识别的准确率。
2 实验结果分析
2.1 实验数据集
为了验证本文设计的OCR算法框架的实用性和正确性,本文收集了多种复杂场景下图片数据。主要数据集如图8所示,包含了各种生活工作场景下、复杂光照环境下、各种拍摄视角下、不同使用状态、不同图像分辨率和不同印刷字体等各类情形的图像。对图像进行带色彩恢复Retinex图像亮度增强和基于ACE图像色彩增强处理之后对数据集标注。

图8 SynthText和ICDAR2015场景文本检测数据样例Fig.8 Text detection datasets of SynthText and ICDAR2015 sample scenes
由于算法框架中采用了“基于双注意力和内容感知上采样的DBNet文本检测网络”和“融入中心损失的CRNN+CTC文本识别网络”,所以需要大量的场景文本检测数据集和场景文本识别数据集去训练网络。本文检测数据集结合了目前OCR领域常用的公开场景文本检测数据集SynthText[17]和ICDAR2015[18]。
实验环境为基于Linux系统下的Ubuntu 18.04操作系统,基于Python(版本3.7)语言实现,实验所用电脑配置为Intel Core i7-7700K,GPU采用NVIDIA GeForce RTX 3090。

表1 文本检测试验结果
本文首先对原DBNet网络和改进后的DBNet进行试验,同时为了对优化措施对比分析,加入CBAM和具有内容感知的CARFE,对融入双注意力机制的DBNet和基于内容感知上采样的DBNet分别训练。由表1可知,本文改进的DBNet的文本检测精度提高了5.09%,召回率提高了2.12%,F评分提高了3.46%。对比融入双注意力机制DBNet可知,双注意力机制对检测精度有一定的提升;对比基于内容感知上采样DBNet可知,基于内容感知上采样对检测精度和召回率都有一定的提升。改进的DBNet相比原DBNet,结果如图9所示。

(a)道路场景DBNet效果
由图9可以看出,本文改进后DBNet对较小文本区域也能很好地检测出来,“漏检”(红色框)情况明显减少,从而提高文本检测的召回率。对比图9(c)和图9(d)可知,原DBNet将标识牌(蓝色框)误检测为文本区域,改进后的DBNet这种“误检”情况也到一定改善,从而提高了文本检测的准确率。
2.2 文本识别实验结果
本文实验采用的文本识别数据集是由200 000张Chinese OCR文档文本行图像和ICDAR2013文本识别数据集共同组成,其中80%用于训练集,20%用于测试集。对CRNN+CTC文本识别网络进行训练,主干网络都采取ResNet34,RNN序列长度T均设为25,输入的文本图片尺寸为320 pixel×320 pixel,优化器采用Adam,beta1设为0.9,beta2设为0.999。学习率采用余弦退火算法,初始值学习率设为0.001,采用了L2正则化,权重设为0.001。作为对比,本实验又采用纯英文文本数据集ICDAR2013进行训练和测试。文本识别结果如表2所示。
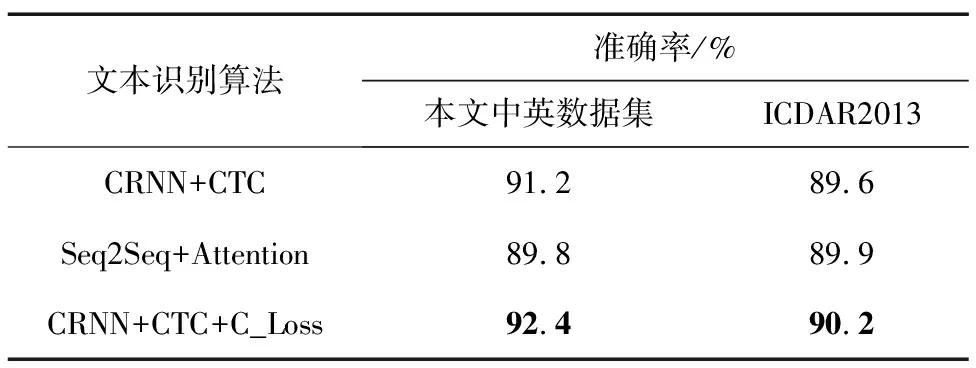
表2 场景文本识别实验结果
由实验结果可知,本文分别采用了CRNN+CTC和Seq2Seq+Attention两种识别网络训练,对于文本长度较短的数据集ICDAR2013,Seq2Seq+Attention识别效果稍好,但对于文本长度较长的本文数据集,CRNN+CTC更有优势,验证了Seq2Seq +Attention对长文本识别不理想的解释。同时本文在原有CTC损失基础上,加入了Center Loss对字符种类多的中英文数据集识别准确率提升了1.2%,而对ICDAR2013英文识别数据集也有0.6%的提升。测试用例如表3所示。

表3 文本识别结果样例
对于CRNN+CTC,偶尔会出现字符识别错误的情况,如将较模糊的“B”识别成了“8”,将“冶”识别成了“治”,这是因为中文、英文和数字字符共6 000多个,有些字符过于相似,加上图像出现模糊、噪声等因素,很容易出现误识别。Center Loss可以增大字符特征分布之间的距离,减少由于字符特征相似而导致分类错误的情况,从而提高字符识别准确率;又由于中文字符种类远比英文字符多,形似字情况比英文字符更为常见,所以Center Loss在本文数据集识别率的提升好于在纯英文数据集,可见Center Loss对于提高中文字符识别的准确率效果更为明显。
3 结束语
本文对场景文本检测算法进行研究,采用了性能和速度兼具的DBNet文本检测网络,并对其进行改进。在DBNet的FPN网络模块加入了CBAM,提高网络对场景中文本区域重要特征的选择能力,抑制其他背景区域带来的干扰。采用具有内容感知的CARAFE,克服传统上采样的感受野小、不具有内容感知等缺点,并将其应用在不同尺度特征图融合中,进一步提高网络的文本检测性能;对场景文本识别算法CRNN+CTC进行改进,加入了增大字符特征间距的Center Loss,减少中英文字符形似而导致的误识别;收集了大量复杂场景下的路标图像,制作成场景文本数据集和场景文本识别数据集;结合公开数据集对改进后的DBNet网络和改进后的CRNN+CTC网络进行训练测试,实验结果显示网络的检测和识别性能均有理想的提升。
