蜣螂优化算法下“互联网+营销服务”虚拟机器人应用模型
2024-02-20周雨湉康雨萌钱旭盛
何 玮,周雨湉,俞 阳,康雨萌,朱 萌,钱旭盛
(1.国网江苏营销服务中心,江苏 南京 210000;2.伦敦大学 国王学院,伦敦 WC2R 2LS)
0 引 言
伴随着互联网时代的蓬勃发展,各行各业都与互联网进行了深度的捆绑。近年来,随着国家电网网格化服务的深入推进,各种不同形式的电力营销服务得到了长足的发展。但当前营销业务仍然面临信息化支撑不足,无法实现全过程闭环管控,亟需通过技术和管理的手段予以规范,更好地推动服务质量和服务效率双提升[1-2]。然而,当前电力营销部门人机交互水平存在局限性,造成客户的实际需求难以实时得到响应,因此有必要对人机交互技术开展深入研究,保障电力客户的用电需求[3-4]。
以虚拟机器人为代表的人机交互技术由于其对社会经济的重要推动而颇受关注,其中主要的研究方向在于通过人工智能技术实现虚拟机器人的人机交互功能。文献[5]研发可识别人体视觉手势的人机交互平台,主要通过Leap Motion传感器设备抓取客户手势信息并完成特征提取,然后将特征量输入到长短期记忆网络中完成检测识别。文献[6]针对咽拭子机器人采集时可能出现的图片瑕疵,提出一种高效自修复网络,基于多尺度注意力机制抓取客户表情,进而通过线性聚合的方法完成检测。文献[7]针对当前机器人知识图谱库的局限性,以知识图谱波纹网络为核心,引入实体嵌入方法,同时考虑情感和内容友好度,从而设计得到一种高效的人机情感交互模型。文献[8]针对智能制造领域人与机器人的交互融合问题,自主研发了一种基于增强现实技术的互认知人机安全交互系统,以可穿戴增强现实设备充当基础交互设备,完成机器人的虚实注册与实际映射,全面采集三维信息,完成人机互认知辅助,该系统设计了可视化、运动检测以及基于深度强化学习的机器人避障功能,从而实现了人机的安全融合。文献[9]针对人机语音识别问题,利用改进的谱减法完成噪声语音的高度降噪,并通过混合高斯-通用背景模型结合梅尔频率倒谱系数特征完成对象鉴定,然后采用深度神经网络设计相应的语音识别单元,有效实现服务机器人在人机交互过程中的快速响应。但是以上方法主要针对交互信号进行优化处理,以实现人机交互功能的进一步发展,忽略了机器人内部运转性能的应用优化,在面对需要处理海量数据的电力营销业务领域时,往往存在一定的局限性。
考虑到电网营销部门在对接客户时需要面临各种各样的需求(即海量的数据),故而数据驱动应当作为“互联网+营销”相结合的核心要点。深度强化学习由于自身具有较好的自主学习能力,能够高效完成数据的快速学习,因此本文基于DBO算法改进的DQN设计得到面向电力客户的虚拟机器人应用模型,根据客户要求实时做出精准响应。
1 人机交互分析与关系框架设计
在研发电力营销虚拟机器人时需要重点考虑与电力用户的衔接和内部机器逻辑的自洽,因此首先要对其人机交互情况开展分析,并针对性地开展关系框架设计。
1.1 人机交互分析
当电力用户连接互联网与虚拟机器人产生交互时,用户开始利用虚拟机器人应用程序编程接口完成指令派发,虚拟机器人在收到解码后的指令后会对应用软件进行操作或者调用,然后将软件反馈的信息反馈至用户,而之后用户可以根据反馈结果选择继续向虚拟机器人派发指令或是改变指令。整个过程可以视为一种用户-机器人-软件的运作模型,其运作的流程如图1所示。
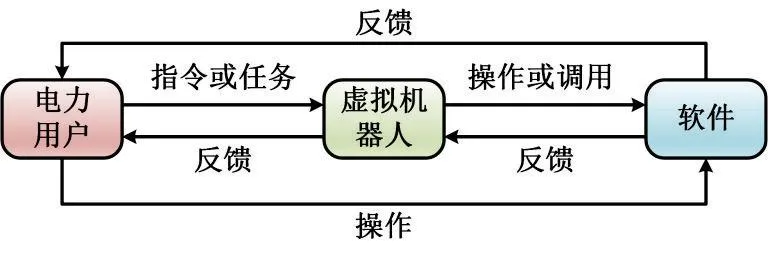
图 1 用户-机器人-软件运转流程Fig.1 User-robot-software operation process
1.2 关系框架设计
虚拟机器人在实现与电力用户的人机交互时其实现过程的整体关系框架自上而下依次是表征层、业务层、数据访问层以及数据层共计4层,如图2所示。
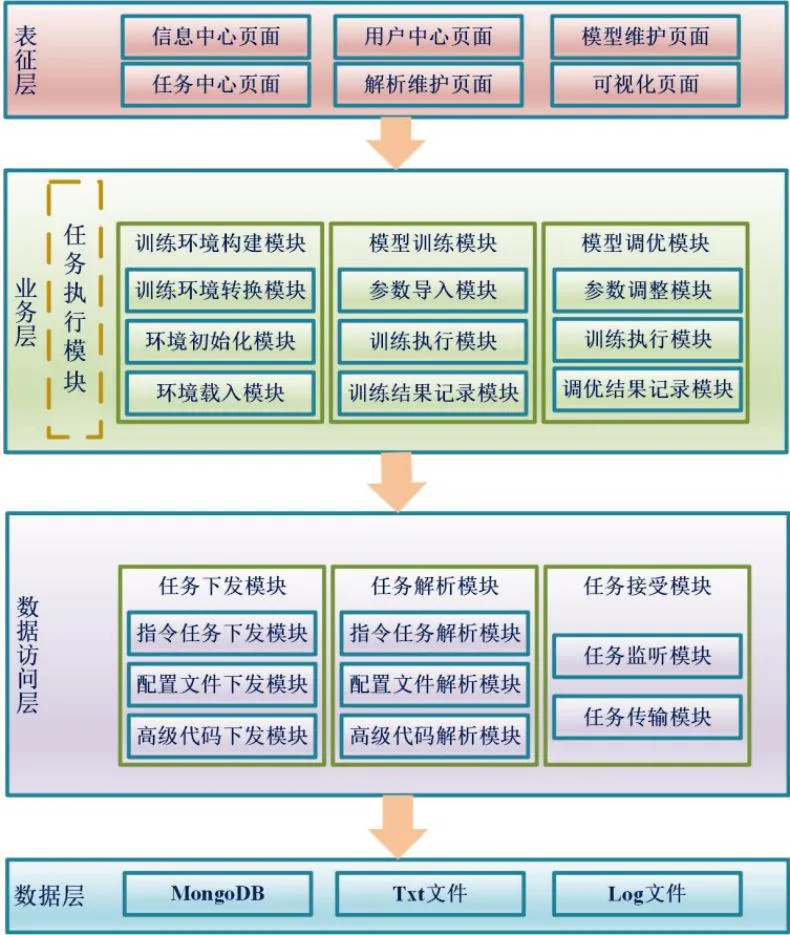
图 2 人机交互关系框架Fig.2 Human-computer interaction framework
图2中,表征层主要是面向电网营销部门提供功能呈现,当虚拟机器人从该接口与电力用户进行对接后,其保留的记录可以供电力营销部门进行查阅;业务层主要包括虚拟机器人的训练、优化和任务执行,在虚拟机器人收到下达指令后,由该层对任务指令进行解析并开始执行训练,最终完成整个任务,主要作用是提供算法支撑;数据访问层的主要作用是实现数据的有效交换,在指令派发后,该层将指令所需的配置文件及代码也一同派发,并在之后对以上文件进行解析,同时还负责任务的监测和传输;数据层的主要作用是对数据进行存储,主要存储对象包括json、txt和log等格式文件。
本文设计的虚拟机器人模型需要运行在以上关系框架下,在电力用户派发指令后可以快速完成执行并实现整个流程的自主学习,然后在执行完任务后对用户进行反馈。
2 基于DBO-DQN的虚拟机器人应
用优化模型
由于虚拟机器人在应用时往往需要在交互环境下实现智能计算,而智能计算往往需要强大的运算模型用于支撑。为了提升虚拟机器人的应用效果,需要引入更为智能的计算方法,实现虚拟机器人在人机交互过程中的响应效率,增强虚拟机器人的性能。考虑到作为典型深度强化学习模型的DQN具有较好的计算性能,能够兼顾运算的效率与精度,因此本文选取DQN优化虚拟机器人的应用性能,并针对DQN的不足开展改进,获得DBO-DQN模型,用于虚拟机器人的智能计算,提升其运算效率,从而获得性能优良的虚拟机器人应用优化模型。
2.1 DQN基本原理
DQN的本质是将强化学习与神经网络糅合在一起的深度网络[10]。在DQN中开展自主学习的主要个体是代理方[11],本文选择虚拟机器人作为代理方。虚拟机器人在交互环境下开展操作,使得交互环境发生改变,然后将状态与奖励信息反馈至虚拟机器人。
定义S表征虚拟机器人收到的信息,主要是训练环境状态;动作A表征虚拟机器人在环境中的操作;虚拟机器人操作的奖励信息定义为R。以上三者的关系为:如果虚拟机器人的操作达标,则训练环境反馈奖励为10,如若未达标则返回奖励为0,如果发生虚拟机器人操作错误则施加惩罚信息为-10。
虚拟机器人在初始状态S1下基于策略Ω获取的奖励加权和即为该状态的表征函数ξΩ(S),也即反馈的预期总报酬,其计算公式可表示为[12]
(1)
式中:ω=[ω1,ω2,…,ωn]表征的是奖励权重,主要用于调节当前和以后奖励的重要性,总体加权期望为E[R|Ω,S]。
虚拟机器人处于St状态时采取操作At与策略Ω获取的期望总报酬可以定义为操作函数ϑ(S,A),其计算公式可表示为[13]
(2)
DQN的实际运行情况主要决定于贪心因子ε、学习率α和折扣因子γ。其中ε主要决定DQN学习效果,α决定虚拟机器人学习的数值更新速度,γ决定未来虚拟机器人奖励的折扣。
2.2 应用模型的构建
虚拟机器人在t时刻对学习环境进行观测,进而按照策略Ω执行操作At,这时环境状态由St变更为St+1,并反馈新的奖励Rt+1至虚拟机器人。虚拟机器人按照奖励Rt+1与状态St+1执行操作,由此按照这一循环机制,虚拟机器人应用模型实现了自主学习,其自主学习流程如图3所示。
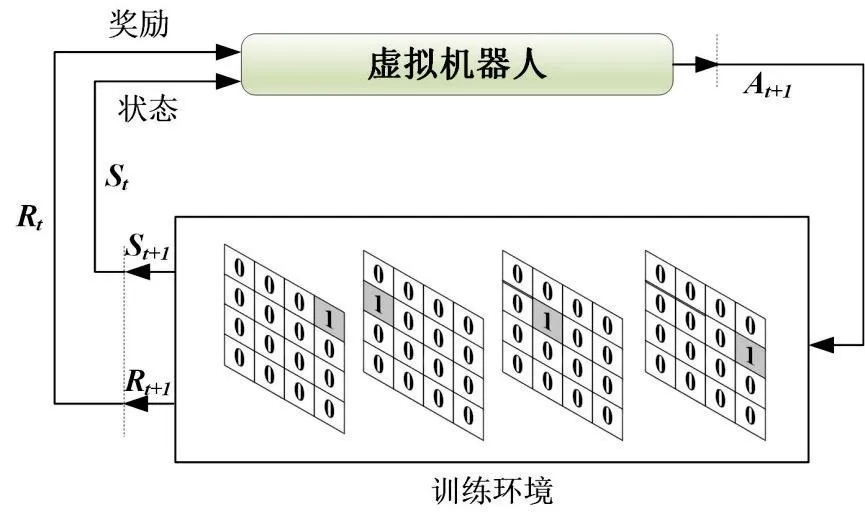
图 3 虚拟机器人应用模型自主学习流程Fig.3 Autonomous learning process of virtual robot application model
DQN中的Q函数可以求解任意状态下执行操作的值,故而虚拟机器人可以按照最大预测值执行操作。而鉴于分开计算Q值会造成计算资源的浪费,因此利用向量值函数求解特定状态时操作的Q值并反馈其向量[14-15]。在DQN中的输出层产生Q值的输出变量,任意操作均有相应Q值对应,考虑到虚拟机器人的回应类型有4个,因此设定输出节点为4,其训练总体架构如图4所示。
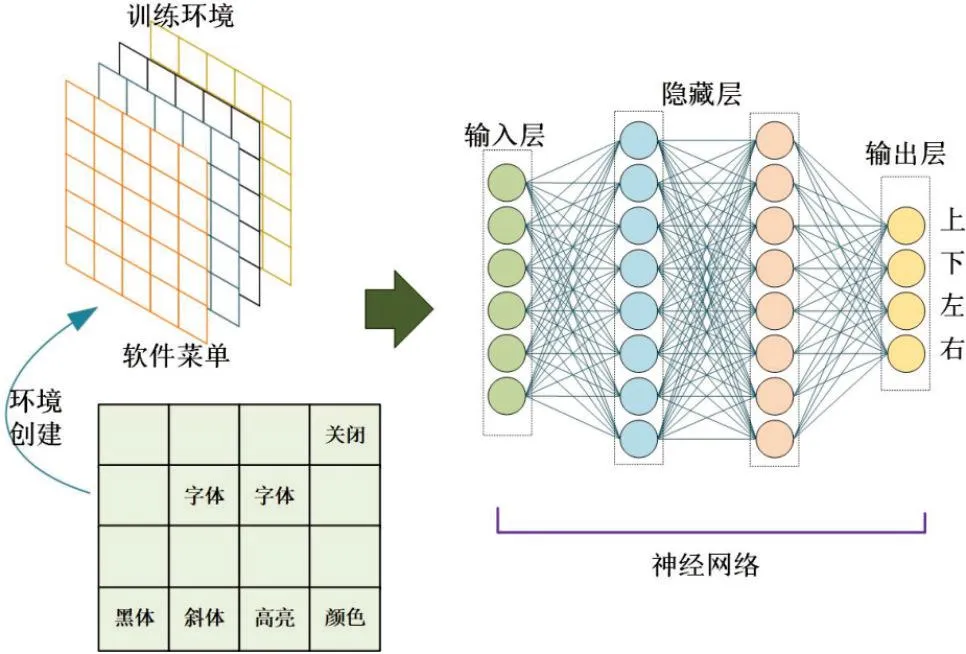
图 4 DQN训练整体架构Fig.4 Overall architecture of DQN training
图4的环境创建中,设定DQN的运行环境,进行数据预处理,完成数据样本划分和输入;训练环境设定DQN的初始结构及相应参数,同时设定DQN的初始训练参数;训练过程中,数据从DQN输入层进入后,在隐藏层中迭代计算,最终根据目标函数限制条件输出预测值。
2.3 DQN模型的训练
本文DQN采用ε-greedy策略[16]完成操作选定,并在虚拟机器人在构建好的训练环境开展DQN的训练后输出相应操作的预测Q值,由此整个应用模型运转结束,整体流程如图5所示。

图 5 DQN模型训练流程Fig.5 Training process of DQN model
图5中,初始化DQN模型参数,设定训练各参数值;判断训练是否到达上限,若是则直接结束,反之则继续训练;模型前向传播,采用ε-greedy策略随机筛选并执行操作A,然后观察新状态St+1并据此获得奖励Rt+1,然后使用St+1令DQN存储最大Q值;判断操作A结束后训练环境是否关闭,若是则终止训练,反之则继续训练;判断St+1的合法性,若合法则计算目标值并输入Q方程中进行计算更新,继续迭代,反之则将目标值更改为Rt+1,训练结束。
2.4 基于DBO的虚拟机器人应用模型优化
由于DQN的实际运行情况主要决定于超参数:贪心因子ε、学习率α和折扣因子γ,因此这3个超参数的最终值将会对DQN的学习结果造成影响。为了确保DQN具有较好的搜索性能,避免陷入局部最优,需要引入优化算法实现超参数的寻优。
DBO算法主要由蜣螂生活习性引申而来,其寻优能力强、收敛效率高[17],因此本文采用DBO算法优化DQN超参数。
蜣螂在滚动时利用触角导航来确保粪球在滚动过程中保持直线前行,这一行为在模拟中需要让蜣螂在搜索空间中按照设定的方向前进,且假设光强会影响蜣螂的前进路径选择[18],则在前进过程中蜣螂位置可以表示为
xi(t+1)=xi(t)+λkxi(t-1)+μΔx
(3)
Δx=|xi(t-1)-xworst|
(4)
式中:t表征目前的迭代次数;xi(t)表征第i只蜣螂在第t次迭代的位置;k∈(0,0.2)表征挠度因子,通常设为定值;λ为-1或1的常数;μ为(0,1)范围内的定值;xworst表征局部最差位置;Δx主要用于光强的调节。
当蜣螂遇障难以继续前进时,就需要重新滚动重新定位以制定新的路线[19]。为了模拟滚动定向行为,利用切线函数求解新方向:
xi(t+1)=xi(t)+tanθ|xi(t)-xi(t+1)|
(5)
式中:θ∈[0,π]表征的是挠度角度;xi(t)-xi(t+1)表征第i只蜣螂在不同迭代周期的前后位置差。
为了确保安全,雌蜣螂产卵位置极为重要,其边界上下限应为
(6)
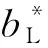
确定雌蜣螂产卵区后规定一次仅产生一个卵,式(6)表明边界会动态变化,主要由ρ决定。而因此卵球位置也是动态变换的:
(7)
式中:Bi(t)表征第t次迭代时第i个卵球的位置,其中β1和β2均为1×N的2个独立向量,N为优化问题的维数。
种群中小蜣螂的位置为
(8)
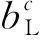
此外,种群中会存在偷窃者。假设xbf为食物最优抢夺点,则种群中偷窃者位置为
Di(t+1)=xbf+ζ·υ·(|Di(t)-xbest|+
|Di(t)-xbf|)
(9)
式中:Di(t)表征种群中第t次迭代时第i只偷窃者的位置;υ为1×N维的随机向量且服从正态分布;ζ为恒定值。
则DBO-DQN的整体优化流程如下所示。
1) DQN网络参数、DBO种群和算法参数初始化;
2) DQN中Q前向传播,DBO根据目标函数求解全部个体适应度值;
3) 更新蜣螂位置并判断是否越界;
4) 更新蜣螂最优位置及适应度值;
5) 重复以上步骤直到达到迭代上限,输出全局最优解及适应度值至DQN中;
6) DQN采用ε-greedy策略执行操作;
7) 操作执行后检测环境新状态并获取奖励信息,基于新状态持续前向传播并保存最大Q值;
8) 选取操作行为,如果操作后环境未关闭则将目标值导入Q方程中持续运算更新;如果操作后环境关闭则表明无有效新状态,目标改为Rt+1;
9)重复训练流程直至迭代上限,若未到达则跳转至步骤2),反之则输出运算结果。
3 实验分析
在获得了相应的虚拟机器人优化模型以后,在特定的实验环境下,从功能性、非功能性和安全性3个角度综合检测模型的实际应用情况,用以检验模型性能。
3.1 模型实验环境
本文所设计的虚拟机器人应用模型的实验主要是对用户端和服务端开展实验分析,所有实验均在计算机上进行,主要基于电力营销数据进行分析,实验环境如表1所示。
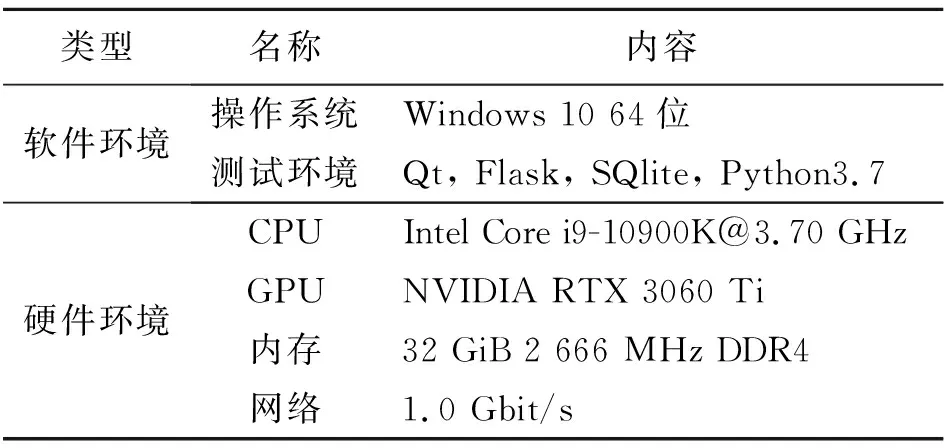
表 1 实验环境配置
3.2 模型功能性实验
本文针对应用模型的已经实现的功能开展测试,主要节选DBO-DQN算法关联部分的关键功能测试,采用电力营销数据进行测试,其结果如表2所示。

表 2 应用模型关键功能测试结果
从表2可以看出,针对应用模型开展功能性测试,所选取的示例均实现了预先设计的功能,测试均通过,表明模型功能良好,可以用于实际应用。
3.3 模型非功能性实验
模型的非功能性测试重点是检测模型执行功能时的内存占用、运行时间、读写速度以及运转情况,以上指标均可反映出用户与模型开展人机交互时的模型的性能。由于指令、配置文件和高级代码派发以及奖励记录占全部功能执行时内存占用的95%以上,因此重点针对以上4个功能进行非功能性测试,结果如表3所示。
从表3可以看出,当应用模型在执行功能时,其内存的占用相对较小,运行时间较短,磁盘读写速度较快,模型整体运转良好,模型的非功能性测试结果为合格。

表 3 系统非功能性测试
3.4 模型安全性实验
本文为了保证模型运转时其内部数据对于不同使用群体具备可知性的同时兼顾数据安全,且不会对模型及其所嵌入的系统平台造成破坏,所以需要测试模型的安全性,其结果如表4所示。
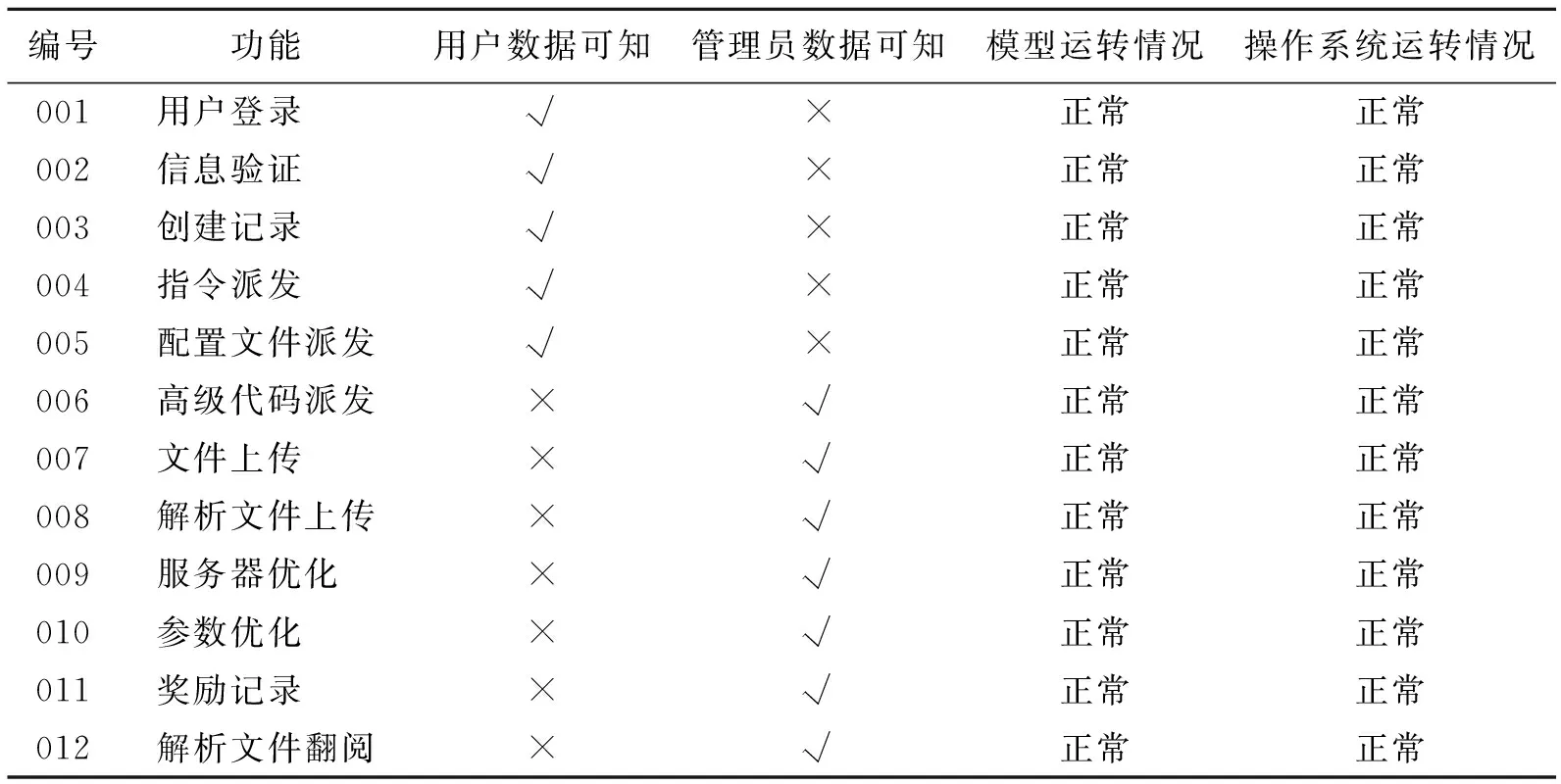
表 4 模型安全性测试结果
从表4可以看出,当不同的使用群体对虚拟机器人应用模型进行人机交互时,相互之间数据不可知,从而使得数据存在隔离,可以有力保障电力营销数据的安全和电力用户的隐私,并且未在使用时造成模型及其所嵌入的系统平台的破坏,应用模型及其所嵌入的系统平台运行正常,安全性良好。
4 结 语
本文针对当前电力营销智能化水平的不足,设计了一种基于蜣螂优化算法的“互联网+营销服务”虚拟机器人应用模型。针对电网营销部门可能发生的用户与机器人的人机交互情景开展了交互分析,并对人际关系框架进行了设计。考虑到人机交互海量数据处理难的问题,基于DQN建立虚拟机器人自主学习模型,同时引入蜣螂优化算法完成DQN超参数的高效寻优,并将电力营销数据输入到模型中进行实验测试。实验结果表明本文设计的虚拟机器人应用模型通过了功能性、非功能性和安全性测试,能够较好地实现人机交互功能,具有良好的实际应用能力,有力提升了电力营销的服务质效。
