骨架引导的多模态视频异常行为检测方法
2024-02-17付荣华刘成明刘合星高宇飞
付荣华, 刘成明, 刘合星, 高宇飞, 石 磊
(1.郑州大学 网络空间安全学院 河南 郑州 450002; 2.郑州市公安局 科技通信管理处 河南 郑州 450000)
0 引言
视频异常行为检测是智能视频监控系统的一项重要、具有挑战性的任务。在智慧城市时代,视频监控用于监控基础设施财产和公共安全已变得非常重要。大量的摄像头安装在地铁口、购物中心、校园环境等公共场所,并不断产生大量的视频数据。对于观察者来说,人工监控长时间的实时视频流并检测是否存在异常事件是一件非常困难和耗时的任务。从监控视频流中自动检测出异常事件可以显著减少人工的监查工作。
近年来,随着深度学习和计算机视觉等领域的蓬勃发展,视频特征提取借鉴了图像特征提取的先进研究成果,提出多种视频特征提取网络并取得了良好的成果。可以利用多种特征如外观、深度、光流和人体骨架等对视频中的人类行为进行识别。在这些特征中,动态的人体骨架通常能传达与其他特征互补的重要信息。监控视频中的人类异常行为通常具有较低的类间方差,部分日常行为活动表现出相似的运动模式,如步行和慢速骑车的人,慢速骑车的人因为与步行有相似的速度和姿势而被误判为步行模式,这种情况下须要进行细粒度的理解。
早期对视频异常行为检测的研究主要基于RGB视频模态,其包含了丰富的细节信息,但其面对背景复杂和可变性的干扰,以及身体尺度、光照、视角等因素的变化时容易受到影响。在人类异常行为检测领域,有利用骨架特征且基于图卷积的方法关注人体关节的空间配置。时空图卷积网络(spatial temporal graph convolutional networks, ST-GCN)[1]在学习非欧几里得数据的空间和时间依赖性方面表现了其有效性,ST-GCN的局限性在于只捕捉空间和时间维度的局部特征,缺乏全局特征。与RGB视频模态相比,骨架模态能够提供更丰富的人体骨架行为关键点信息,并且对光线和尺度的变化具有较强的鲁棒性,是对人体的高层级语义表示,但缺乏外观信息,特别是人与对象交互的行为信息[2-3],这是检测细粒度异常行为的关键。骨架模态总体信息量也不如RGB模态的高,比如对于某些和物体交互的动作,光用骨架信息就很难完全描述。
为了利用骨架姿态和RGB视频模态的优点,可将多模态信息融合成一组综合的鉴别特征。由于这些模态是异构的,必须通过不同类型的网络进行处理以显示其有效性,这限制了它们在简单的多模态融合策略[4-5]中的性能,因此,许多姿态驱动的注意力机制被提出来指导基于RGB的动作识别。文献[6-7]通过LSTM实现姿态驱动注意力网络,专注于显著的图像特征和关键帧。随着三维卷积的成功发展,一些工作尝试利用三维姿态来加权RGB特征图的鉴别部分[6-9]。Das等[8]提出了一种在三维卷积网络上的空间注意力机制来加权与动作相关的人体部位。为了提升检测性能并提取更具鉴别性的特征,陈朋等[10]提出的弱监督视频行为检测结合了RGB数据和骨架数据。
以上方法提高了动作的识别性能,但它们存在以下缺点:在计算注意力权值的过程中,三维姿态与RGB线索之间没有准确的对应关系;在计算注意力权值时忽略了人体的拓扑结构。
由于目前基于骨架单一模态的自注意力增强图卷积网络[11]克服了ST-GCN空间局部特征的局限性,空间自注意力增强图卷积网络可以捕获空间维度的局部和全局特征,但无法捕捉动作中微妙的视觉模式,与骨架动作姿态相似的行为动作容易出现误判。为了充分利用RGB模态与骨架模态之间的优势并克服时间卷积的局限性,本文提出了一种骨架引导的多模态异常行为检测方法,使用新的空间嵌入来加强RGB和骨架姿态之间的对应关系,并使用时间自注意力提取相同节点的帧间关系。
如图1所示,本文提出的方法将原始监控视频的RGB视频帧及其提取的对应骨架姿态作为输入。通过视觉网络处理视频帧,并生成时空特征图f。所提出的引导模块(RGB pose networks, RPN) 以特征图f和骨架时空图P作为输入,通过骨架姿态和视频外观内容的空间嵌入(RGB-Pose spatial embedding, RGB-Pose)加强视频RGB帧和骨架姿态之间的对应关系,并在时间维度上使用时间自注意力模块(temporal self-attention module, TSA)研究同一关节沿时间的帧间相关性,从而获取更好的判别性特征。RPN由改进的时空自注意力增强图卷积和空间嵌入(RGB-Pose)两部分组成。改进的时空自注意力增强图卷积进一步由空间自注意力增强图卷积[11]和时间自注意力(TSA)组成,融合RGB视频和骨架两种模态进行异常行为检测。RPN计算特征映射f′。然后使用特征图f′进行深度嵌入聚类,并进行异常行为检测,异常分数用于确定动作是否正常。
本文提出了一种新的时空自注意力增强图卷积算子,由空间自注意力增强图卷积模块以及时间自注意力模块(TSA)构成。使用时间自注意力(TSA)提取相同骨骼节点的帧间关系,捕获时间全局信息。

图1 骨架引导的多模态视频异常行为检测方法框架图Figure 1 The framework of skeleton-guided multimodal video anomalous behavior detection method
使用新的空间嵌入(RGB-Pose)来加强RGB和骨架姿态之间的对应关系,充分利用各个模态的优势。所提出的方法在ShanghaiTech Campus异常检测数据集和CUHK Avenue数据集上进行实验评估,实现了优秀的性能指标,证明了所提方法的有效性。
1 骨架引导的多模态异常行为检测方法
1.1 特征提取
监控视频中人体骨架数据从预训练的视频姿势估计算法或运动捕捉设备中获得。通过改进的时空自注意力增强图卷积块[11]构建时空自注意力增强图卷积自编码器(spatioteporal self-attention augmented graph convolutional autoencoder,SAA-STGCAE)来提取骨架特征,使用编码器将提取的骨架姿态嵌入到时空图中。人的行为被表示为时空图。时空图的骨架时空连接配置如图2所示,配置描述遵循ST-GCN。将N定义为人体骨架的关节数,F定义为视频的总帧数。对于监控视频流中的每一个人,构建时空图G=(V,E),其中:V={vtn|t=1,2,…,T,n=1,2,…,N}是所有关节节点作为图的顶点的集合;E表示时空图的边,描述人体结构中自然联系的所有边和时间的集合。此外,E由两个子集Es和Et组成,其中:Es={(vtn,vtm)|t=1,2,…,T,n,m=1,2,…,V}表示每一帧t中任意关节对(n,m)的连接;Et={(vtn,v(t+1)n)|t=1,2,…,T,n=1,2,…,N}表示沿连续时间的每一帧之间的连接。图2中的节点表示人体骨架关节,实线为人体骨架关节的自然连接,表示空间维度边,虚线为相同骨架关节相邻帧之间对应的时间维度连接,表示时间边。
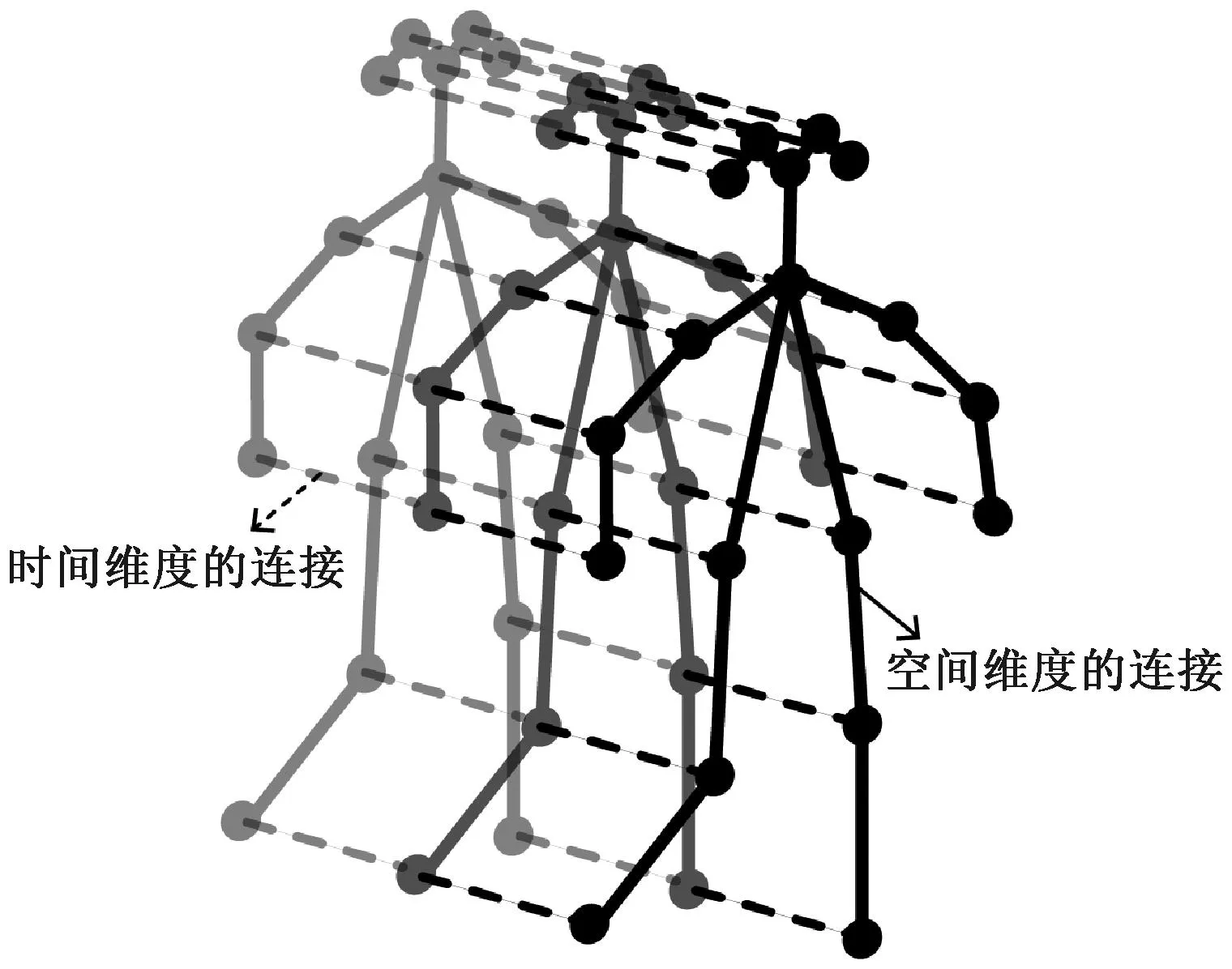
图2 骨架时空图Figure 2 Spatiotemporal graph
对于RGB视频,从视频剪辑中提取人类裁剪图像作为输入,通过三维卷积网络提取视频的时空特征表示。然后,在两种模态特征的基础上,利用引导模块的空间嵌入融合骨架和RGB特征,增强两种模态特征的对应关系。
1.2 时间自注意力模块
时间自注意力模块(TSA)的每个独立关节沿所有帧分别研究每个关节的动力学。通过沿着时间维度的相同身体关节的变化来计算各帧之间的相关性,如图3所示。当计算源节点加权结果时,所有帧的该节点参与计算,此为捕捉时间全局特征的体现。
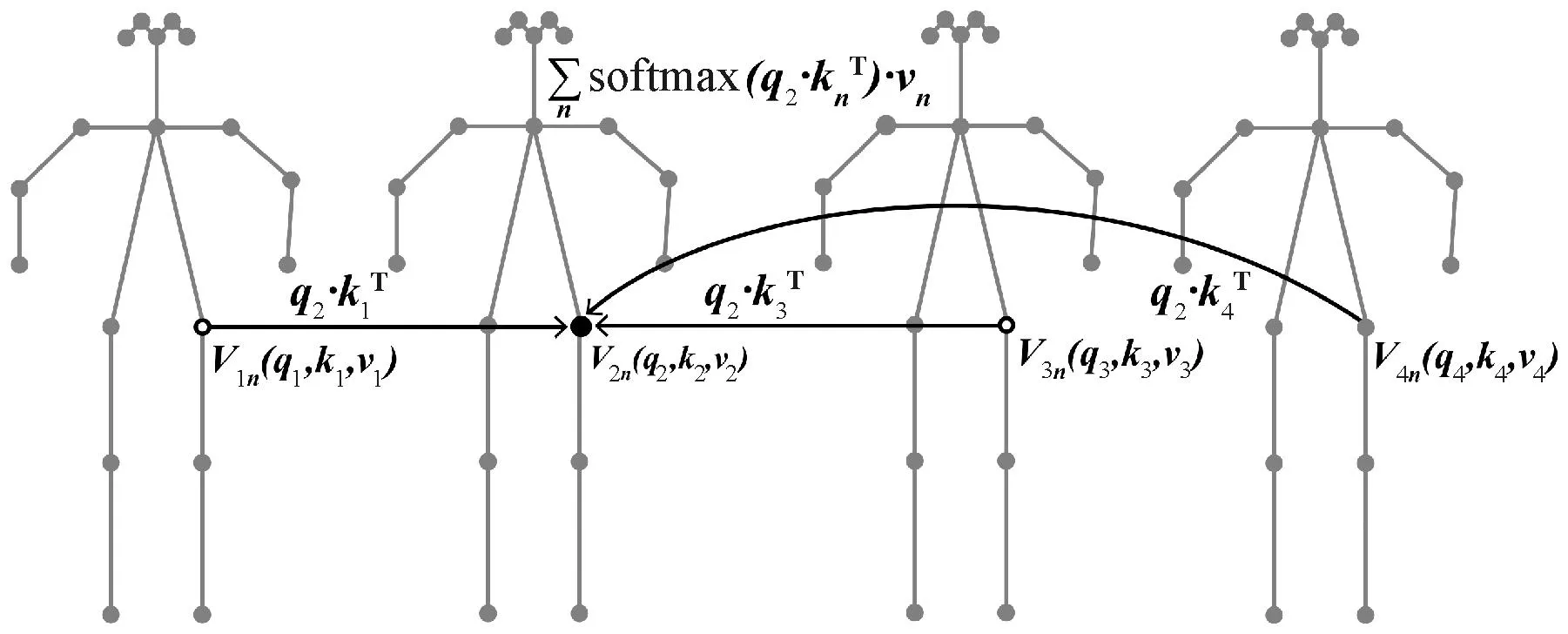
图3 时间自注意力模块示例图Figure 3 Example of temporal self-attention module
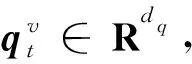
(1)
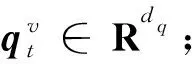
(2)
TSA使用下标表示时间,上标表示关节。TSA采用多头注意力机制,所用公式为
(3)
SAT=concat(head1,head2,…,headNh)·Wo。
(4)
为了便于处理,输入矩阵变维为XT∈RV×Cin×T,可沿时间维度在每个关节上单独操作。Wo是一个可学习的线性变换,结合了所有头的输出。
TSA模块通过提取相同骨骼节点的帧间关系,学习同一关节不同帧间的关系,例如首帧中的关节与末帧中的关节。TSA是沿着同一关节(如所有左脚或所有右手)的时间维度上进行,从而在时间维度得到判别特征,并捕获时间全局特征,这是通过标准ST-GCN中TCN无法达到的。
1.3 时空自注意力增强图卷积
本文提出了一种新的时空自注意力增强图卷积算子,如图4所示。由空间自注意力增强图卷积模块[11](如图5所示)、时间自注意力模块(TSA)构成(如图6所示)。其中空间自注意力增强图卷积是核心部分。

图4 时空自注意力增强图卷积算子Figure 4 Modified spatiotemporal self-attention augmented graph convolution
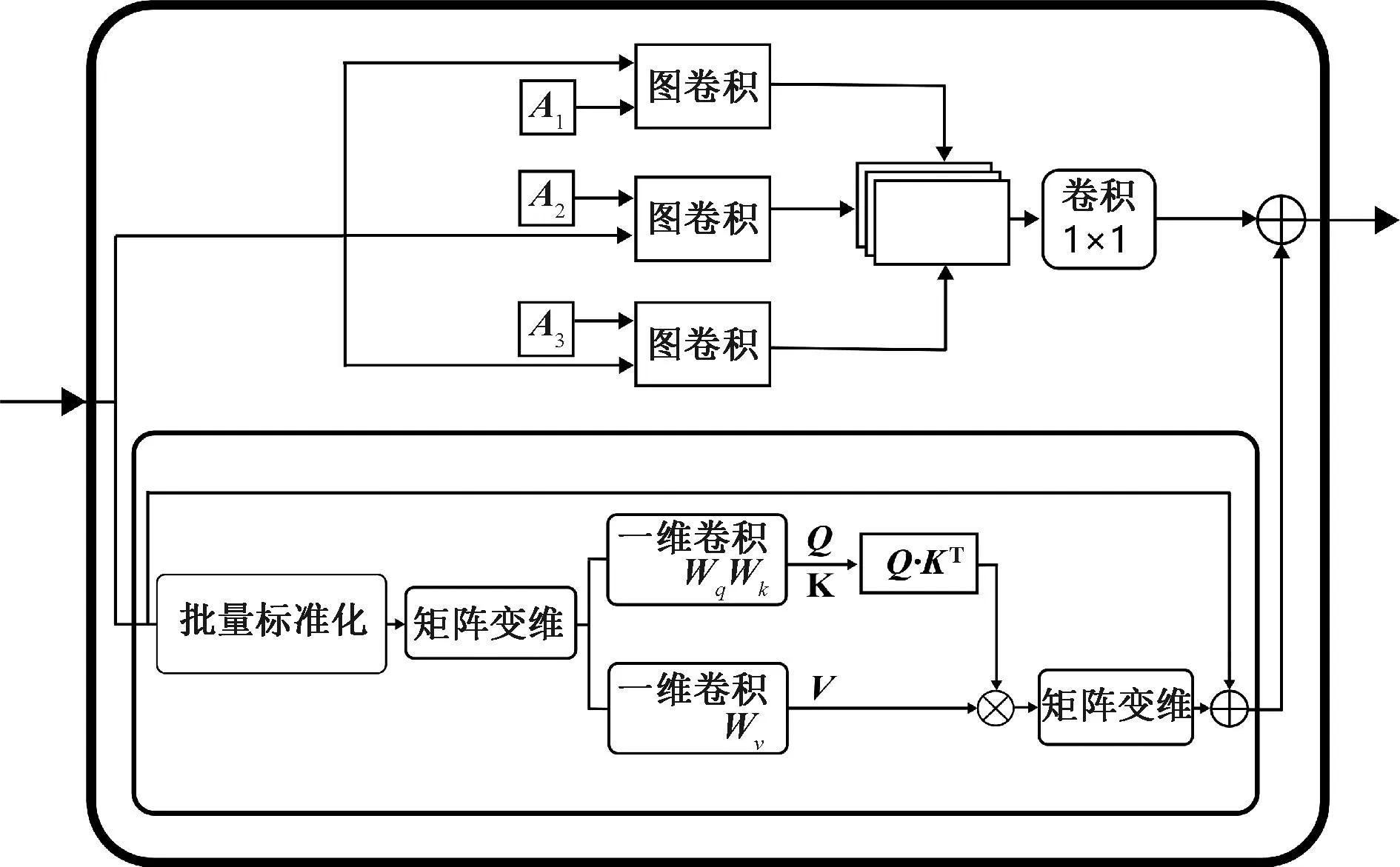
图5 空间自注意力增强图卷积模块Figure 5 Spatial self-attention augmented graph convolution module
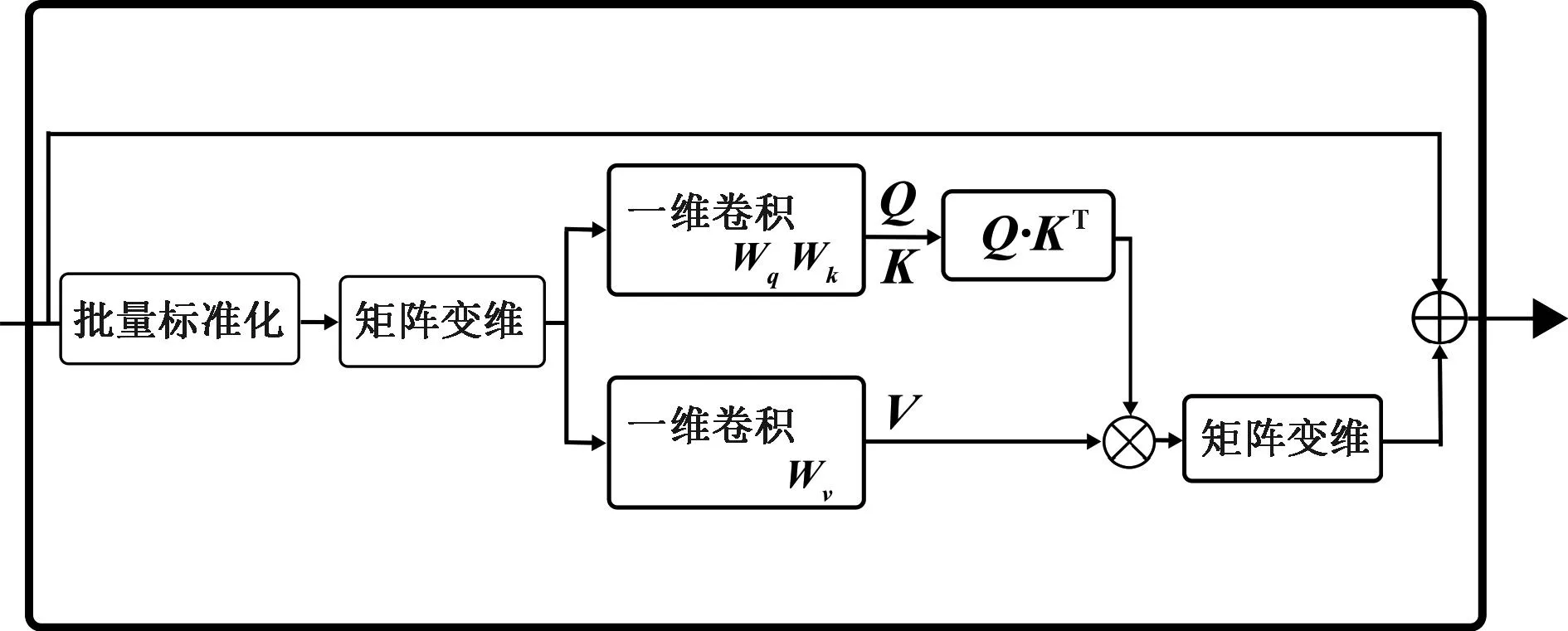
图6 时间自注意力模块Figure 6 Temporal self-attention module
空间自注意力增强模块基于空间图卷积提出,空间维度使用三种类型的邻接矩阵:静态邻接矩阵(A1);全局学习邻接矩阵(A2)和自适应邻接矩阵(A3)。空间自注意力模块应用修改后的自注意力算子,捕捉同一帧中不同关节的空间特征,并动态构建关节内和关节之间的空间关系,以加强非直接连接的人类骨架关节的相关性。
空间自注意力增强图卷积主要关注关节之间的空间关系,其输出被传递到时间自注意力模块,以提取帧间的时间关系,可描述为
ST-SAAGCN(x)=TSA(GCN(x)),
(5)
时空自注意力增强图卷积算子既可以捕获空间局部和全局特征信息,又可以捕获时间全局信息。
1.4 骨架引导的RGB视频和姿态的空间嵌入
骨架自注意力增强图卷积网络[11]被认为是主干网络,可以检测出行为动作中显著的异常行为信息。对于引导网络,在骨架姿态和RGB数据之间有一个准确的对应关系是很重要的。空间嵌入的目的是使用骨架姿态和RGB模态之间紧密的对应关系,向RGB视频帧提供骨架姿态反馈。如图7所示。
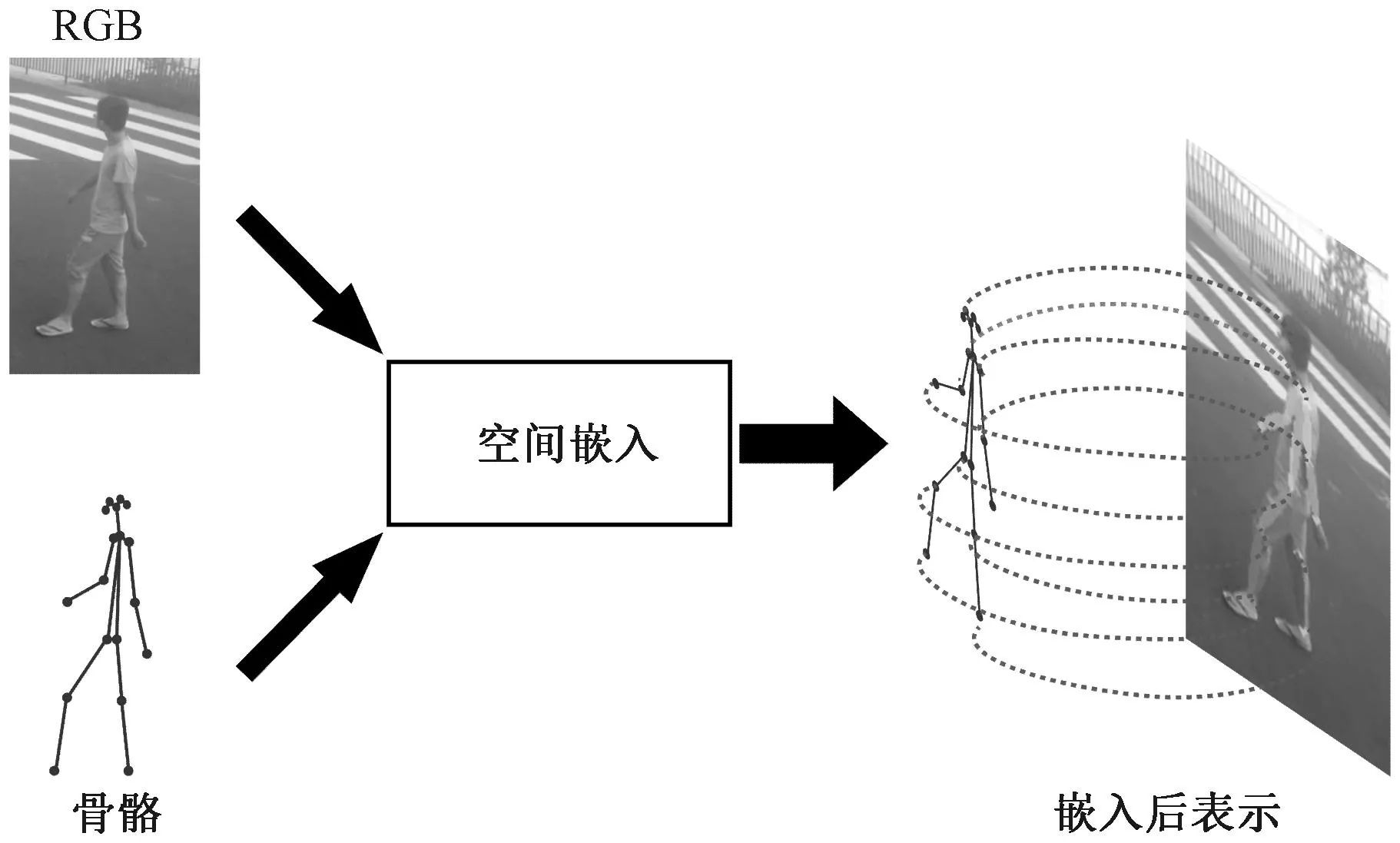
图7 空间嵌入对应关系Figure 7 Spatial embedding correspondence
文献[8-9]使用姿态信息在RGB特征图上提供注意力权重,而不是将它们投影到相同的参考中。因为没有像素到像素的对应,通过骨架数据计算出的空间注意力并不与图像部分对应,但这对于检测相似的动作行为至关重要。为了将这两种模态关联起来,本文使用了一种来自图像字幕任务[12-13]的嵌入技术来构建一个精确的RGB-Pose嵌入,使姿态能够表示动作的视觉内容,空间嵌入说明如图8所示。
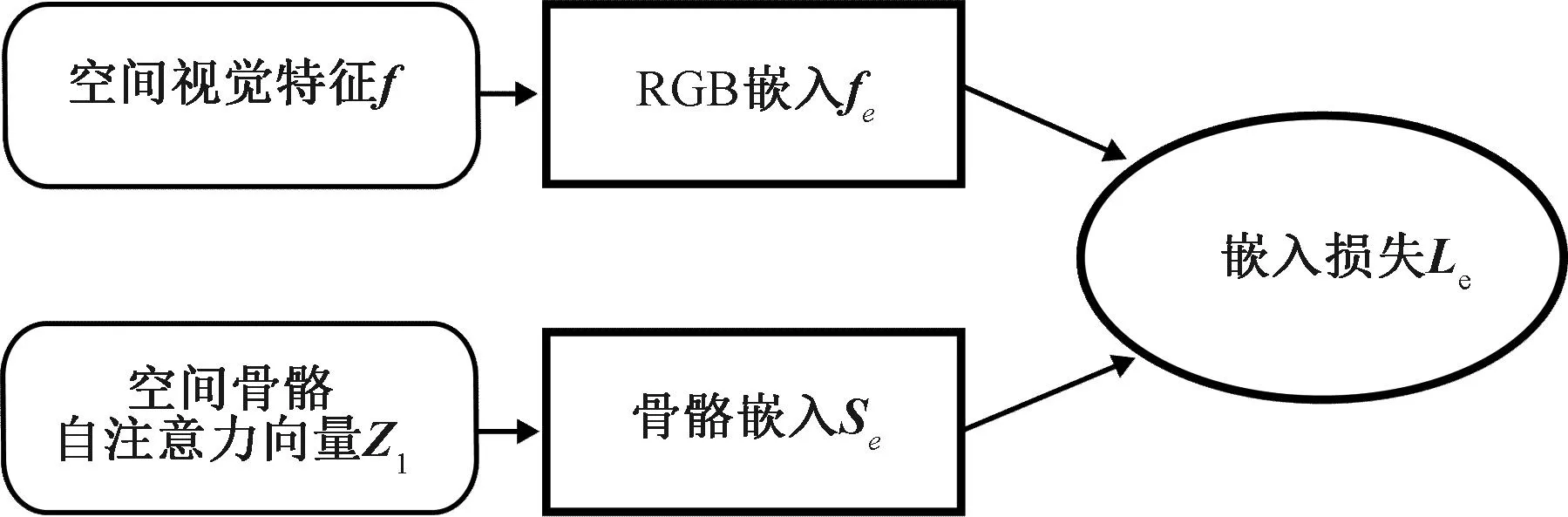
图8 空间嵌入说明图Figure 8 Spatial embedding illustration
从视频剪辑中提取的人类裁剪图像作为输入,通过三维卷积网络计算时空表示f,其中f是维度为tc×m×n×c的特征图。然后,利用本文提出的网络对特征图f和相应的骨骼姿态P进行处理。
空间嵌入输入的是一个RGB图像及其相应的骨架姿态。强制嵌入人体关节中代表图像的相关区域。假设视频特征图f(一个Dv维向量)及其对应的基于姿态的潜在空间注意力向量Z1(一个Dp维向量)的全局空间表示存在低维嵌入。映射函数推导公式为
(6)
其中:Tv∈RDe×Dv和Tp∈RDe×Dp是将视频内容和骨架姿态投影到相同的De维嵌入空间的变换矩阵;fe、Se分别为RGB嵌入和骨骼嵌入。将该映射函数应用于视觉空间特征和基于姿态的特征上,以实现上述空间嵌入的目标。
为了衡量视频内容和骨架姿态之间的相关性,计算它们在嵌入空间中映射之间的距离。将嵌入损失定义为
(7)
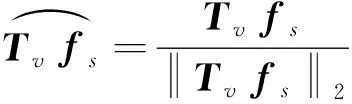
这种嵌入损失和全局分类损失在RGB特征映射上提供了一个线性变换,保留了动作表示的低秩结构,并为不同的动作引入了最大分离特征。因此,通过最小化相关性嵌入损失来加强视频和姿态之间的对应关系。这种嵌入确保了用于计算空间注意力权值的姿态信息与视频的内容保持一致,能更好地体现视频的语义。
1.5 深度嵌入式聚类
聚类层的开始是SAA-STGCAE的嵌入。该方法调整了深度嵌入式聚类[14],并使用提出的SAA-STGCAE架构对时空图进行软聚类。该聚类模型由编码器、解码器和软聚类层三部分组成。基于初始重构对嵌入进行微调以获得最终的聚类优化嵌入,然后每个样本由分配给每个集群的概率Pnk表示,所用公式为
(8)
其中:Zn是SAA-STGCAE的编码器部分生成的潜在嵌入;yn是软聚类分配;Θ是聚类层数为k的聚类层参数。
按照聚类目标[14]执行算法优化,最小化当前模型概率聚类预测P和目标分布Q之间的Kullback-Leibler(KL)散度,所用公式为
(9)
(10)
在期望的过程中,固定模型并更新目标分布Q,在最大化步骤中,模型被优化用以最小化聚类损失Lcluster。
1.6 异常检测模块
异常分数计算由狄利克雷过程混合模型进行评估。狄利克雷过程混合模型是评估比例数据分布的有用度量,理论上是处理大型未标记数据集的理想选择。它在估计阶段评估一组分布参数,并使用拟合模型为推理阶段的每个嵌入样本提供分数。在测试阶段,使用拟合模型以对数概率对每个样本进行评分。模型提供的正态性分数用于确定动作是否正常。
2 实验与结果分析
2.1 数据集
在ShanghaiTech Campus和CUHK Avenue两个公共数据集上评估了所提视频异常检测方法的性能,这两个数据集可以轻松识别行人并提取人体骨架数据,HR-ShanghaiTech为第一个数据集中异常的且仅与人类有关的子集。图9显示了实验所使用数据集中的一些正常和异常事件。本节将提出的网络与基于外观[15-17]和基于骨架的[11,18-20]方法进行比较。所有实验都在帧级AUC度量上进行评估。

图9 数据集正常和异常事件示例Figure 9 Examples of normal and abnormal events in the dataset
CUHK Avenue与ShanghaiTech数据集的帧数(训练帧、测试帧)、异常事件和场景数等相关信息如表1所示。

表1 数据集比较表Table 1 Comparison of datasets
2.2 实验设置
本文方法由Pytorch框架实现,在Nvidia GeForce RTX 2080Ti (×4)Ubuntu 18.04操作系统,CUDA 10.0支持下进行实验。
本文实验中,所选择的视觉网络是在数据集ImageNet和Kinetics-400上预训练的I3D(Two-Stream Inflated 3D ConvNet)网络。视觉主干以64帧视频作为输入。从I3D的Mixed_5c层中提取的特征图和相应的骨架姿态组成RPN的输入。
使用Alpha-Pose算法来提取视频中每一帧人的骨架姿态估计。对于自注意力时空图卷积的配置,遵循ST-GCN中的设置,其中包含9个时空自注意力图卷积层。前3层、中3层和后3层分别有64、128和256个通道用于输出。Resnet机制应用于每个自注意力时空图卷积。
2.3 消融实验
模型包括两个新的组件,空间嵌入和时空自注意力。这两者对相似行为下的异常行为检测识别性能都是至关重要的。
2.3.1自注意力网络消融实验 本文进行了空间自注意力、时间自注意力以及时空自注意力的消融实验,结果如表2所示。
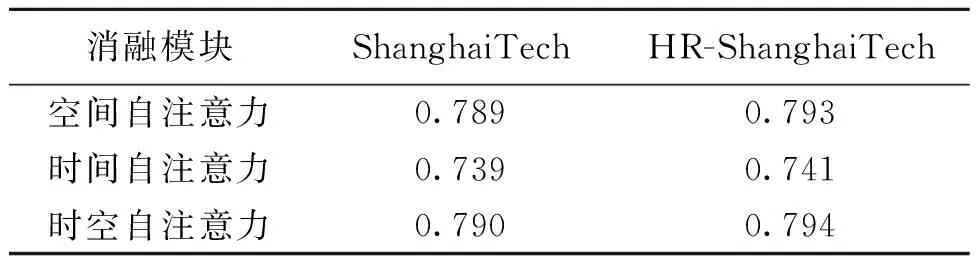
表2 自注意力网络消融实验结果表Table 2 Self-attention network ablation experimental results
结果表明,仅采用空间自注意力,可以捕获空间局部和全局特征但缺乏时间全局特征。仅采用时间自注意力,考虑了时间全局特征,但缺乏空间全局特征。时空自注意力增强图卷积计算注意力权重时,不仅在空间维度上考虑了骨架特征的局部和全局信息,而且在时间维度上考虑同一关节的时间全局关系,这进一步提高了异常行为检测的性能,使模型能减少误判。
2.3.2时空自注意力与空间嵌入消融实验 进行了时空自注意力网络和RPN的空间嵌入模块的消融实验。时空自注意力网络在数据集ShanghaiTech上结果为0.790,在数据集HR-ShanghaiTech上结果为0.793;空间嵌入在数据集ShanghaiTech上结果为0.795,在数据集HR-ShanghaiTech上结果为0.798。结果表明,空间嵌入提供了RGB模态和骨架姿态模态的精确对齐,与没有嵌入的动作相比,细粒度动作的检测性能有所提高。时空自注意力增强图卷积操作和空间嵌入使识别模型能够更好地消除外观相似的动作歧义。
2.3.3时空自注意力增强图卷积数量的选择 本文还对时空自注意力增强图卷积数量进行消融研究,以探索其有效性。实验逐渐增加时空自注意力增强图卷积的数量。如图10所示。

图10 改变时空自注意力增强图卷积数量在 ShanghaiTech Campus数据集上的性能Figure 10 Performance of changing the number of spatiotemporal self-attention augmented graph convolutions on the ShanghaiTech Campus dataset
由图10可知随着增加时空自注意力增强图卷积数量,在ShanghaiTech Campus数据集上的AUC性能逐渐增加。当时空自注意力增强图卷积数量选择为9时,模型在ShanghaiTech Campus数据集上的性能最好。消融实验表明更深层次可能会导致模型优化困难。
2.4 实验结果的可视化
为了直观地评价模型,将CUHK Avenue数据集和ShanghaiTech数据集的部分实验结果可视化。异常分数可视化图以视频帧为x轴,以异常分数为y轴,图中阴影区域表示异常行为发生的时段。
图11为CUHK Avenue数据集的摄像头采集的第11视频片段的异常得分。异常分数归一化为[0, 1],图中阴影区域代表异常,此视频片段异常事件为扔掷东西和逆向行走。
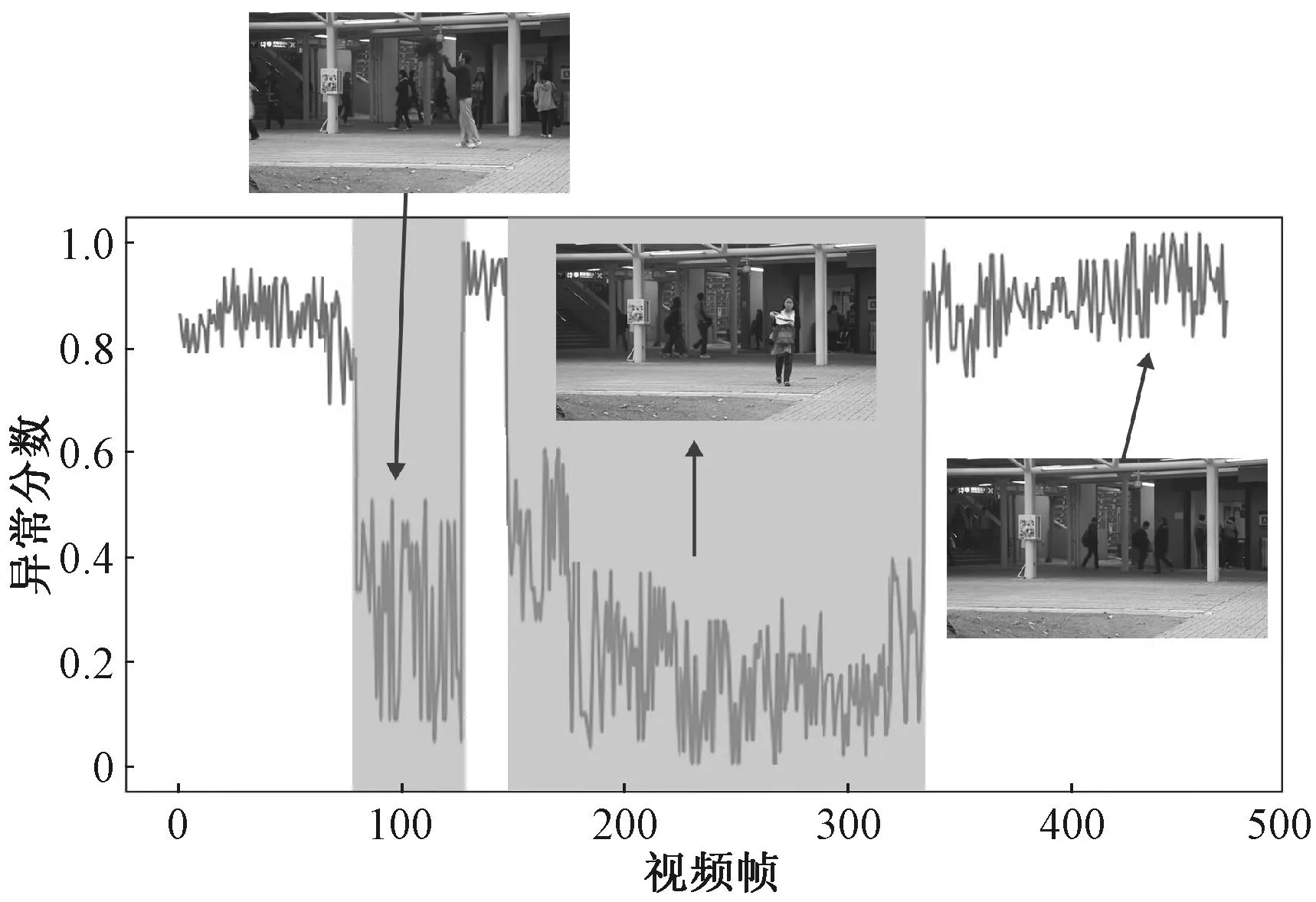
图11 数据集CUHK Avenue#11异常分数可视化图Figure 11 The visualization of anomaly scores for CUHK
图12为数据集CUHK Avenue#11的典型异常帧,图12(a)93帧表示人准备开始向上扔掷动作,图12(b)150帧表示人捡起扔掷物品,图12(c)300帧表示逆向行走的人,行人的运动方向与他人不一致,即运动轨迹异常。

图12 数据集CUHK Avenue#11的典型异常帧Figure 12 Typical anomalous frame for dataset Avenue#11
图13为ShanghaiTech数据集的07号摄像头视角的第009视频片段的异常得分,图中阴影区域代表异常,此视频片段异常事件为突然跳跃。从图13中可以看出,异常行为从115帧到198帧,视频片段中的人进行了多次跳跃动作。
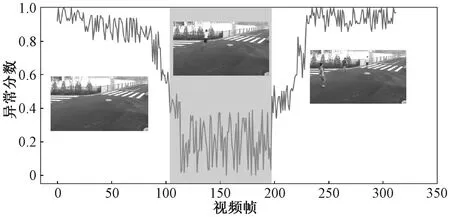
图13 数据集ShanghaiTech#07_009异常分数可视化图Figure 13 The visualization of anomaly scores for ShanghaiTech#07_009
如图14所示,图(a)118帧表示人准备跳跃的下蹲起势动作,图(b)132帧表示人向前跳跃的动作,图(c)145帧表示跳跃的落地动作,图(d)155帧表示人再次起跳动作,图(e)167帧表示再次落地,图(f)180帧表示3次起跳动作。

图14 数据集ShanghaiTech#07_009的典型异常帧Figure 14 Typical anomalous frame for dataset ShanghaiTech#07_009
图15为ShanghaiTech数据集的06号摄像头视角的第150视频片段的异常得分,图中阴影区域代表异常,此视频片段异常事件为骑自行车的人。慢速骑自行车的人与行走的人具有相似的运动模式,在只使用骨架模态进行异常检测时极易产生误判,本文方法可以对其进行异常检测,降低误判率。
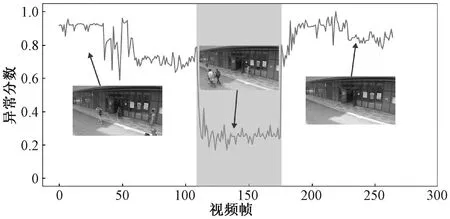
图15 数据集ShanghaiTech#06_150的异常分数可视化图Figure 15 The visualization of anomaly scores for ShanghaiTech#06_150
2.5 实验结果与分析
对比本文所提方法与其他单模态的方法在ShanghaiTech Campus数据集、与人类活动相关的HR-ShanghaiTech Campus数据集和CUHK Avenue数据集上的性能,显示帧级的AUC分数,如表3所示。
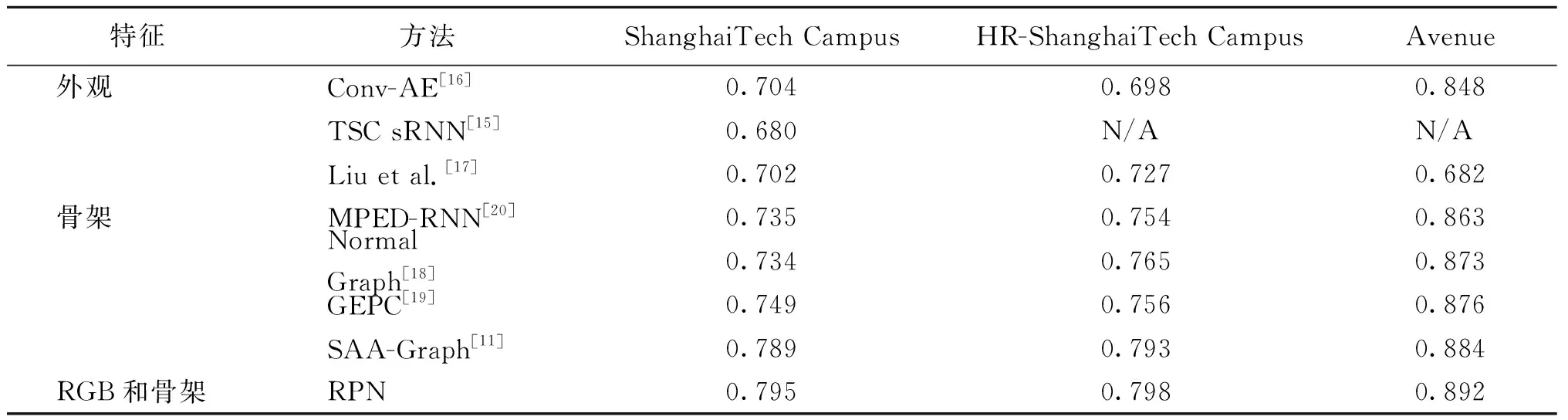
表3 异常检测结果表Table 3 Table of anomaly detection results
将本文所提出的方法与基于外观的方法[15-17]和基于骨架的方法[18-20]进行比较。一般来说,基于骨架的方法比基于外观的方法表现更好,尤其是在ShanghaiTech Campus数据集中,异常仅存在与人类有关的子集HR-ShanghaiTech Campus上。原因是这些算法只关注人体姿势而不是不相关的特征,例如复杂的背景、光照变化、动态摄像机视图等。对于基于骨架的方法,基于GCN的方法[18-19]表现更好,与基于RNN的方法[20]相比,因为骨架可以自然地定义为图结构,并且图卷积网络在处理非欧几里得结构数据方面优于RNN网络。对于只使用单模态的异常行为检测,由于外观信息的缺乏,MPED-RNN[20]、Normal Graph[18]、GEPC[19]、SAA-Graph[11]无法消除具有相似视觉外观动作的歧义。骨架模态和RGB模态结合可以提升检测的性能,使用新的空间嵌入来加强RGB视频和骨架姿态之间的对应关系,以及使用时间自注意力提取相同节点之间的帧间关系,可以提高部分相似行为下的异常行为检测性能。
3 总结
本文主要研究相似运动模式下的异常行为检测。提出了一种新的视频姿态网络RPN,提供了一种精确的视频姿态嵌入方法,通过显式嵌入来结合RGB模态和骨架模态并采用时间自注意力捕获时间全局信息。结果表明,RGB-Pose嵌入与骨架时空自注意力产生了一个更具区别的特征图,提升了相似异常行为的检测性能。本文异常行为检测模型在两个公共数据集上的性能都取得了优异的结果。本文针对不同监控场景下的人类异常行为检测进行了相关研究,但仍然存在一些可以进一步改进的问题。未来与人类行为相关的监控视频异常行为检测工作:1) 在有噪声的骨架姿态情况下,可利用本文提出的嵌入方法提高网络的异常行为检测。2) 引入更多视觉特征或拓展模态并研究轻量级模型,在考虑保证特征的全面性和有效性的同时提高计算速度。
