集成学习和动态融合算法在福建省短时强降水预报中的应用*
2024-02-06陈锦鹏黄奕丹程晶晶1杨德南2
陈锦鹏 黄奕丹 朱 婧 林 辉 程晶晶1, 杨德南2,
1 厦门市海峡气象开放重点实验室,厦门 361012 2 福建省灾害天气重点实验室,福州 350001 3 福建省漳州市气象局,漳州 363005 4 集美区气象局,厦门 361021
提 要:为了提高短时强降水预报准确性,在2019—2020年4—9月福建省逐时降水实况观测资料与中国气象局广东快速更新同化数值预报系统(CMA-GD)模式预报产品的基础上,应用LightGBM集成学习算法框架,建立以30 mm·h-1为阈值的逐时降水预报模型。通过特征处理、自助聚合及超参数搜索等技术对模型进行优化,结合AUC、AUPR与传统分类指标,设计了包括业务模拟测试在内的多项试验,通过对比各建模方案验证了模型对于较长时效的短时强降水预报的适用性。结果表明:模式预报本身的命中率和空报率均较高,各建模方案具有不同程度的改善作用。自助聚合可以增强模型预测稳定性,轻微不平衡子训练集能降低模型预测空报率而取得更高的综合评分,在验证集中最佳TS评分可达17.5%;对分类信息增益贡献最大的特征变量为K指数,其次为500 hPa露点温度和时间参数特征;试验指标从优到劣依次为:随机交叉验证、小时划分的随机交叉验证、业务模拟测试,可见模型有效性主要来自相同或相邻时刻的样本信息;设计基于逻辑回归的异质模型动态融合方案以改善静态同质模型表现,各项指标均有小幅提升,在命中率接近50%时削减空报样本超过52万个。
引 言
短时强降水是福建汛期内较常发生的强对流天气之一,这种极端降水天气主要由超级单体和中尺度对流系统(MCS)造成(章丽娜等,2014)。随着高分辨率中尺度数值模式在短时临近预报预警业务中的广泛应用,对于短时强降水预报的客观订正技术需求也日益迫切。结合福建省业务标准,将小时雨强超过30 mm·h-1的降水事件定为短时强降水。从全年的逐时数据来看,短时强降水的样本比例极低。尽管过去大多数研究是基于逐日降水资料开展的,但是逐时降水数据能反映出更加精细的特征(李德帅,2016)。另外,在降水事件时间尺度为 1 h 的情况下其非线性和随机性特点将进一步放大,加大了预报订正的难度。
与降水客观预报订正技术相关的研究工作逐年增多。唐健等(2018)实现了主客观融合定量降水预报(QPF)平台,其中包括多模式QPF集成技术与QPF预报场调整和订正技术等,对预报业务起到了良好的支撑作用;唐冶等(2021)采用消空订正方案对新疆区域数值天气预报系统DOGRAFS的降水预报产品进行订正,小幅提高了晴雨准确率和TS评分;张华龙等(2021)基于因子分析法构建分期、分区短时强降水逐6 h格点概率预报模型,在汛期业务试验中相对于模式预报提升较大,尤其对于容易漏报的暖区短时强降水具有明显优势;张武龙等(2021)通过时间滞后集合预报方法构建多个不同权重系数的集合成员进行逐小时降水预报,发现晴雨TS评分提升了10%左右,且有效减小了模式空报率;洪伟和郑玉兰(2018)在分析福建前汛期短时强降水发生背景下模式预报物理量分布特征的基础上,建立基于阈值判定方法的短时强降水预报模型,对福建西部关键区的TS评分白天可达0.5、夜间约为0.3;危国飞等(2020)设计了全球模式与区域模式相结合的降水分级最优化权重集成预报算法,24 h 累计降水预报TS评分比主观预报高出0.9%~2.3%;赵渊明和漆梁波(2021)基于上游降水实况与模式预报的匹配程度,设计动态权重多模式短时临近定量降水概率预报方法,有效提高定量降水概率预报的准确性;潘留杰等(2022)基于卡尔曼滤波方法动态匹配预报和观测降水频率进行降水预报订正,发现能够改善模式对小量级降水预报偏大、大量级降水预报偏小的现象。但总体上,精细到逐小时降水的客观预报方法研究仍相对较少。
近年来,以神经网络为代表的机器学习方法逐渐展现出在强对流预测方面的潜力。金子琪等(2021)采用卷积神经网络算法构建飑线识别模型,揭示了该算法能够学习并识别飑线和非飑线回波的图像特征;黄骄文等(2021)构建基于深度学习网络的降水相态判识模型,针对两年数据以及一次大范围雨雪天气过程进行检验,判识准确率为98.2%,雨、雪的TS评分分别为97.4%和94.4%,较传统指标阈值法的判识准确率有较大提高;张烨方等(2021)以卷积神经网络模型为基础,结合多个时间序列的雷达产品与闪电数据研发雷电临近预报方法,与常规采用雷达、闪电阈值控制的雷电预警算法相比准确率有所提高;韩丰等(2021)以大气层结和对流参数作为特征参数,基于XGBoost集成学习方法建立短时强降水预报模型,同时使用分段权重损失函数进行模型调优,命中率为0.65、空报率为0.37、TS评分为0.47,表明模型对短时强降水天气具有一定预报能力。
集成学习(ensemble learning)是机器学习领域最热门的研究方向之一,基本思想是通过提升(boosting)、自助聚合(Bagging)和推叠(stacking)等方式将多个弱学习器进行组合以获得比单一模型更好的表现和更小的误差(余东昌等,2021),其中梯度提升决策树(gradient boosting decision tree,GBDT)算法在分类、回归、排序等问题上取得了优异的性能,在学术界和工业界中被广泛使用(江佳伟等,2019)。轻量梯度提升机(light gradient boosting machine,LightGBM)则是在GBDT的基础上引入多项优化技术进行改进和提升的一种算法框架,主要目的在于解决高维度大样本数据运行耗时及可拓展性差的问题(刘新伟等,2021),具备内存占用少、并行化学习和准确率较高的优点。在几乎相同的精度上,LightGBM可以使传统GBDT的训练过程加速20倍以上(Ke et al,2017),自2016年开源以来逐渐成为Kaggle等数据挖掘竞赛中的夺冠热门算法。
本研究应用LightGBM集成学习算法框架建立逐小时的短时强降水预报模型,在特征处理、自助聚合以及超参数搜索等模型优化技术的基础上,通过多项对比试验对不同方案下的模型预测能力进行评估,并针对业务实践中的应用难点设计了基于逻辑回归的异质模型动态融合方案,在一定程度上提高了长时效、精细化的短时强降水预报能力,为集成学习与模型融合方法在数值预报订正中的应用提供了有益参考。
1 资 料
1.1 实况资料
选取2019—2020年4—9月福建地区的逐小时自动站观测数据作为实况资料,全省自动站数量约为2200个。2019年和2020年收集到的有效样本数分别为4 491 604个和4 368 497个。其中,2019年作为建模所用的已知的训练集和验证集,而2020年作为未知的测试集,旨在最大限度模拟实际业务情况下模型的表现。以30 mm·h-1为阈值将实况资料划分为正负类样本,其中≥30 mm·h-1为正样本,具体分布如表1。从样本比例来看,实况资料具有极端不平衡的特点,短时强降水属于极小概率事件,后续试验将会对此问题进行探讨。

表1 2019年和2020年的正负类样本数量
1.2 预报资料
在中国气象局广东快速更新同化数值预报系统(CMA-GD)模式预报的基础上开展订正试验。该模式预报产品的空间分辨率约为0.03°×0.03°,预报间隔为1 h,每日起报时次为08时和20时(北京时,下同)。以当日白天的短时强降水潜势预报为例,由于计算耗时、传输延迟等因素,一般只能参考前日20时起报的CMA-GD模式产品。因此选择2019年和2020年4—9月、预报时效为18~23 h(预报时段只涵盖了下午至傍晚及后半夜)的预报产品,其预报变量主要有各等压面层的温度、位势高度、相对湿度、露点温度、水平风场、垂直速度、沙氏指数和K指数等。以观测站点为中心,应用最邻近16点平均插值计算对应于该站点的特征变量。如此得到的“点”特征称为结构化特征,便于集成学习模型训练。另外,由于数值模式升级或气候背景变化,2019年和2020年的数据分布规律可能会存在差异,称为数据漂移,因此订正模型需要具备一定的泛化能力以适应新的数据。
2 方 法
2.1 LightGBM集成学习算法框架与建模思路
集成学习是指通过训练与集成多个弱分类器来提高最终学习效果的一种技术(李勇等,2014),本研究具体采用LightGBM算法框架进行建模。LightGBM作为集成学习代表性算法之一,其基本原理是通过梯度下降法不断拟合残差(真实值与预测值的偏差)来迭代学习的决策树,再将所有决策树的单独预测进行相加即得最终结果,因此可以由如下公式表示:
(1)
式中:X代表输入特征变量,T代表决策树,Θn为决策树的超参数(如最大深度、叶子节点数等),N为决策树的个数。LightGBM应用了两种创新性采样技术:基于梯度的单侧采样(gradient-based one-side sampling)和互斥特征捆绑(exclusive feature bundling)。前者可以缩减用于计算信息增益的样本数量,后者则能减少用于参与分裂点筛选计算的特征数量(任师攀和彭一宁,2020)。
在具体算法应用中,对于t时刻至t+1时刻的多个站点累计雨量P,依托LightGBM建模工具包来挖掘与t时刻模式预报的结构化特征变量X之间的隐含关系,即假设存在P=f(X)+ε,其中ε代表预测误差。这样的建模思路不仅可以大幅增加样本数据量,而且不会受到外推时效的制约,能够在数值模式的基础上进行较长时效的预报。
2.2 特征处理
对2019年特征变量进行标准化处理,再利用其均值和标准差对2020年特征变量做相同变换。由于短时强降水在不同的季节具有不同的日变化规律(付超等,2019),为了让模型尽可能地捕捉到这种规律以增强待挖掘的映射关系,在原始特征的基础上添加时间参数特征,具体包括距离当年1月1日的天数(日期参数)和降水所在的时刻(时刻参数)。
最后根据皮尔逊相关系数大小进行特征过滤。分析特征变量两两之间的相关系数,以0.95为判断阈值,选择两个强线性相关特征变量中的一个进行剔除,从而减少建模过程中的冗余数据与过拟合现象对模型的不利影响。
2.3 分层K折交叉验证与自助聚合
数据采样和模型训练过程中均不可避免地存在随机性。为了增加试验结果的可信度以及提高样本数据利用率,有关2019年数据的试验中采用随机分层4折交叉验证:将数据集进行随机采样而划分为4份,且保持每份子集中的正负样本比例与全集基本一致,每次试验取其中3份作为训练集,剩余1份作为验证集以跟踪模型性能变化,最后取4次试验结果的平均值进行分析。
针对逐小时降水样本极端不平衡的问题,可以采用自助聚合(bootstrap aggregating,简称Bagging)方法缓解其不利影响。在训练集中,对大数量负样本随机采样N次,每次采样数与正样本数的比例为P,然后与同一份正样本组成子训练集,且通过调节N和P可在一定程度上提高样本利用率与削弱样本不平衡程度。相比于单纯的平衡欠采样,经过Bagging处理后的数据利用率至少增加了(N-1)/2倍。基于N份子训练集可训练出N个超参数不同的同质基模型,再对每个基模型的预测结果进行平均。
2.4 模型跟踪指标
利用模型输出的概率预测结果对逐时降水进行分类预报,会涉及到分类阈值的问题,传统的检验指标(如TS评分、命中率POD和空报率FAR等)会随分类阈值变化而变化。当阈值较低时,命中率提高,空报率也随之增加,反之则都会降低,因此传统的检验指标不利于实时跟踪和评估模型性能随训练代数的变化。引入受试者工作特征曲线(receiver operating characteristic curve,ROC)曲线下面积(area under ROC curve,AUC)、精准率和召回率曲线(precision-recall curve,PR)曲线下面积(area under PR curve,AUPR)来解决该问题。ROC曲线和PR曲线均是指遍历所有分类概率阈值后由相应坐标系中的散点所连成的曲线。其中,ROC曲线以伪阳性率(false positive rate,FPR)为横坐标,以真阳性率(true positive rate,TPR)为纵坐标;而PR曲线是以召回率Recall为横坐标,以精准率Precision为纵坐标(黄苏琦,2020)。其中,TPR与召回率是一致的,等同于气象业务检验中常用的命中率POD,而精准率与空报率之和为1。当AUC为0.5 时说明预测完全是随机的;AUC在0.5以上才能说明模型具有正向预测价值;AUC和AUPR越接近1,则模型整体的预测效果越趋于完美。在正负样本不平衡的分类问题中,PR曲线与ROC曲线的评价结果并不一致,PR曲线更能突出不同算法之间的性能差异(Davis and Goadrich,2006),其纵轴也更加贴近气象业务检验习惯。
3 分 析
3.1 模式预报检验
分别对2019年和2020年CMA-GD模式预报进行以30 mm·h-1为阈值的二分类检验。2020年的AUC为0.7577,高于2019年的0.7022;但从更具参考意义的AUPR来看,2019年的0.2354略高于2020年的0.2178。
传统的分类检验指标与分类阈值密切相关,从命中率、空报率、TS评分和FPR随分类阈值变化(图1)的角度来对比两者表现。可以发现,2019年和2020年模式预报的命中率变化曲线基本重合,但在分类阈值接近30 mm·h-1时后者仍保持在47%以上,略高于2019年;对于空报率和TS评分而言,2020年模式预报均显著优于2019年,侧面反映了在极端不平衡数据中空报情况对TS评分影响很大;2019年模式预报的FPR略优于2020年。整体来看模式对逐小时强降水预报仍不够理想,业务应用存在困难。
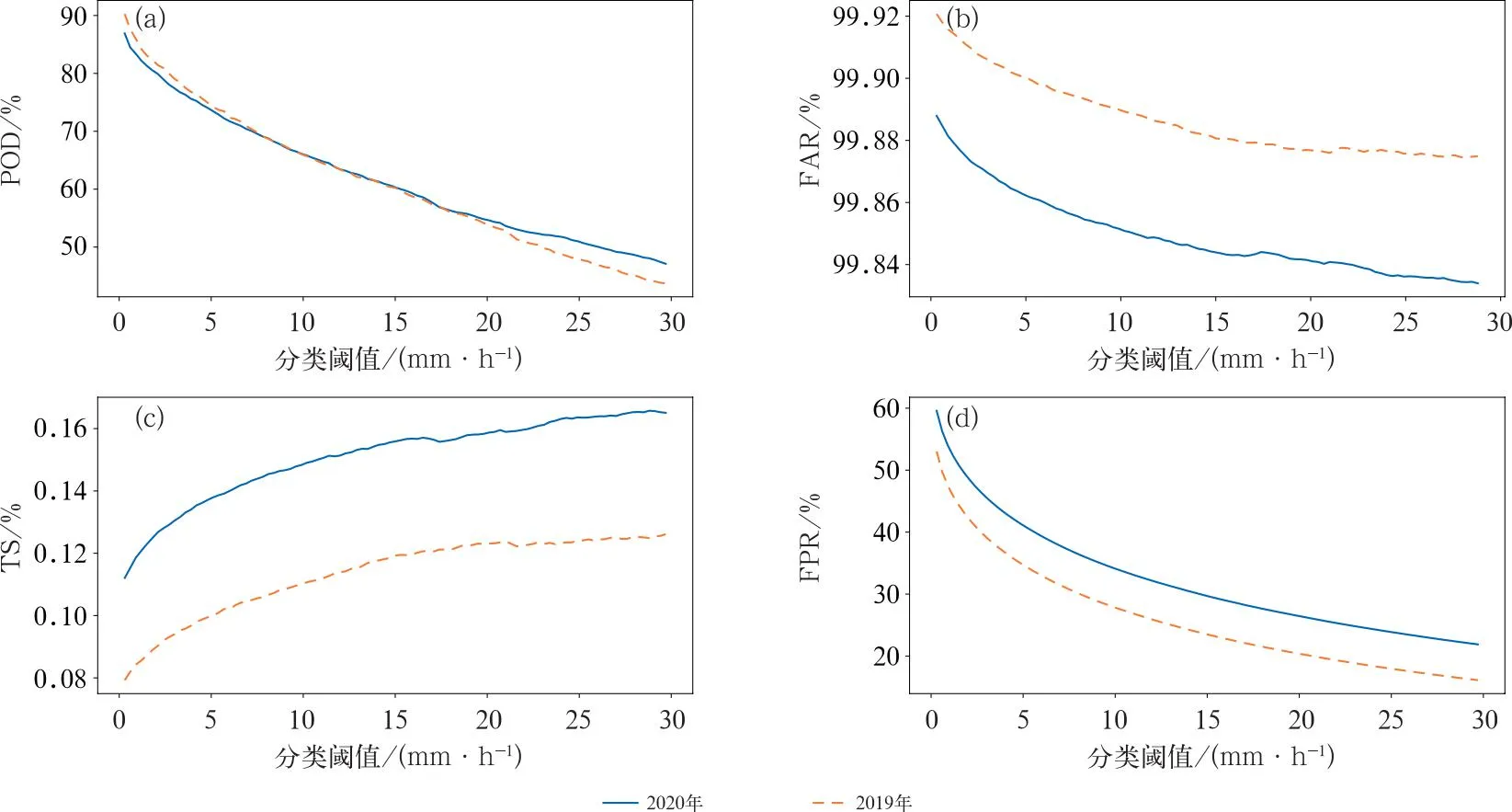
图1 2019年和2020年CMA-GD模式预报检验指标随分类阈值的变化
3.2 基于LightGBM的建模方案与超参数优化
在2019年数据集上训练模型和调整超参数。通过随机4折交叉验证将2019年数据集划分为75%的训练集和25%的验证集。验证集作为模型未曾学习过的陌生数据,跟踪其指标变化能够在一定程度上反映模型的过拟合程度,还可以为模型的超参数调优提供必不可少的参考依据。
在训练集的全部样本数据直接用于建模的情况下,由于过度拟合极端不平衡数据,模型性能变得极不稳定,验证集变化曲线大幅波动,即模型失效(图略)。因此需应用Bagging方法进行处理,设定子模型数量为3个,采样的正负样本比例为1。不同的超参数组合对模型表现影响极大,最大深度和叶子节点数从小到大意味着模型拟合能力越来越强,但泛化能力可能下降。如图2所示,Bagging采样融合方法带来的最大改变是模型在验证集上的稳定性大大增加,AUC与AUPR均随着训练次数增加而大致趋于收敛。同时注意到AUC和AUPR变化曲线均呈“V”形。当超参数较小时(图2a,2b),前5代以内的模型反而取得了较高的AUC和AUPR,这主要是因为此时模型拟合能力偏弱、泛化能力偏强而具有高命中率的特点导致的。随着训练代数的增加,模型拟合能力逐渐增强,AUC和AUPR也有所回调,隐含了模型拟合能力与泛化能力相互制约的关系。

图2 不同超参数的模型在验证集上的AUC与AUPR
相比于模式预报在验证集上的AUC为0.706,不同超参数组合的订正模型在该项指标上均有显著提升,且表现出随着模型超参数增大而小幅增加的趋势。另外,模式预报的AUPR为0.114,当最大深度和叶子节点数较大时模型的该项指标有所下滑,逐渐劣于数值模式。
为了进一步改善模型表现,尝试对Bagging采样的样本比例进行调节。以最大深度为8、叶子节点数为22的订正模型为研究对象,当负类样本数与正类样本数之比P逐渐增大时,AUC与AUPR均有不同程度提高,AUPR尤其显著(图3)。当P=6时AUC最大值超过0.97,P=10时AUPR最大值超过0.2,且注意到此时模型还存在继续训练的潜力,表明了模型能够从轻微不平衡训练集中学习到比平衡训练集更多的数据信息。
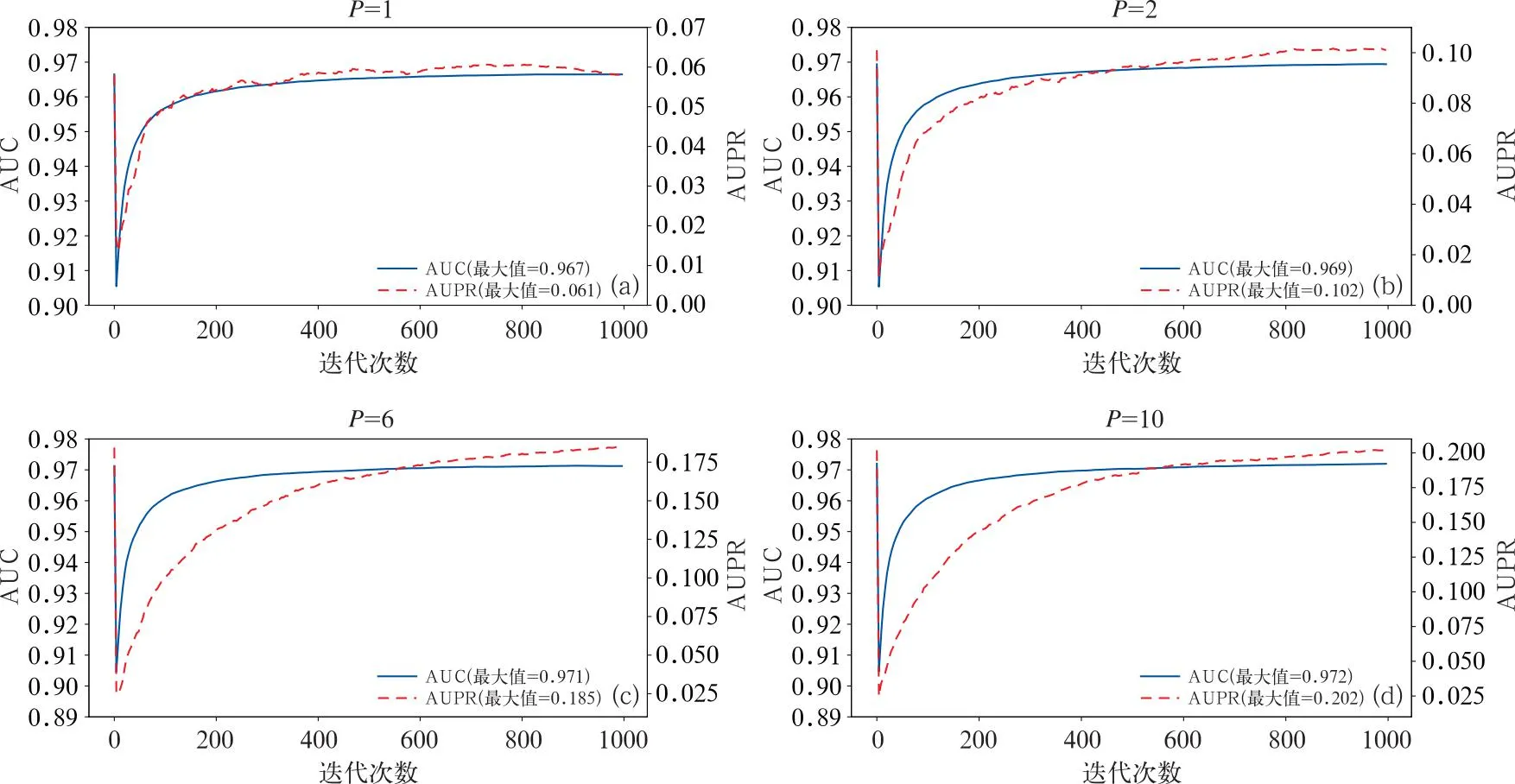
图3 不同P值下轻微不平衡采样的模型在验证集上的AUC与AUPR
分析基于轻微不平衡与平衡采样训练集的建模方案在传统分类指标上的差异。从图4可以看到,平衡方案的优势在于高命中率,除此之外的其他指标在全部概率分类阈值上均劣于轻微不平衡方案。以P=10为例,当分类阈值达到0.8以上时,命中率快速下滑至30%左右,同时空报率也降低至约70%,TS评分则快速上升至超过17.5%,FPR则变化不大,整体保持在10%以下。由此可见,面对极端不平衡的数据集,提高预测TS评分的关键和难点在于降低空报率。
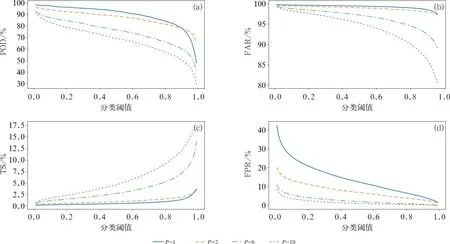
图4 不同Bagging采样比例的LightGBM模型预报检验指标对比
基于LightGBM的订正模型在训练完成后可从累计信息增益的角度统计特征重要性。信息增益g的公式如下:
g(D,A)=H(D)-H(D|A)
(2)
其中
(3)
式中:D和A分别表示待分类数据和分类条件,H表示信息熵,n为类别数(二分类中为2),p(xi)为该类别事件发生概率。对轻微不平衡模型而言,排序前十的特征变量如表2所示,最重要的特征变量为K指数,且重要性远远大于之后的特征变量,可见K指数对于模型预测的指示意义最佳。其次为500 hPa露点温度,第三和第四分别为自定义添加的时间特征——时刻参数和日期参数,表明了日变化和年变化规律的挖掘对于模型预测具有较大的帮助。另外,700 hPa以上经向风、中高层位势高度与850 hPa相对湿度也占据一定的重要性。
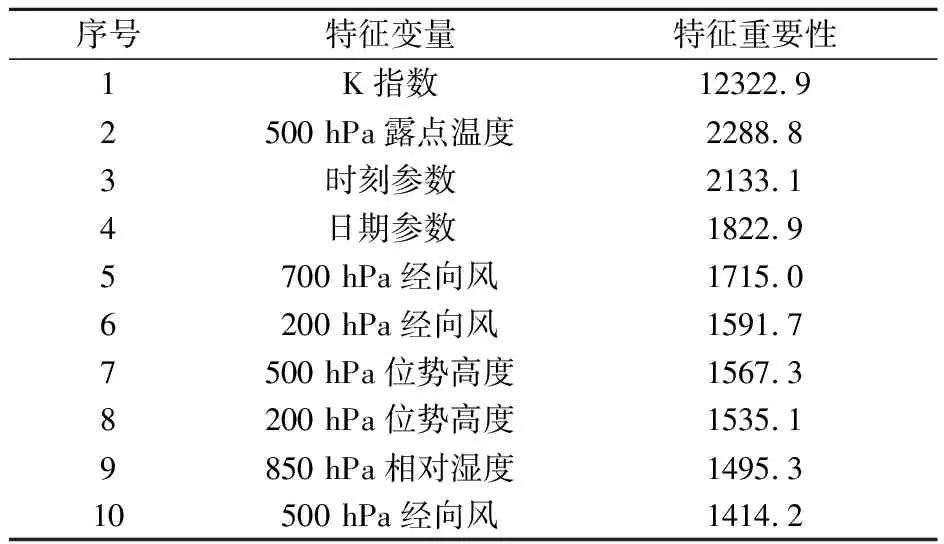
表2 模型特征重要性前十排序
3.3 订正模型的有效性分析
上述建模与调参试验中均无视数据集中存在的时间关系而进行随机交叉验证,为了进一步分析轻微不平衡模型的有效性来源以及在具有时间关系的业务模拟中的表现,分别设计2019年小时划分的交叉验证试验以及2020年测试集试验,模型超参数设为:最大深度为8、叶子节点数为22、子模型数为3、负类与正类样本之比为10。
同样基于2019年数据集,小时随机交叉验证与3.2节中随机交叉验证的最大不同在于,模型无法从训练集中学习到与验证集中所属同一小时的样本数据,从而避免了时间上的信息泄露。在这种情况下,模型预测能力明显下降,尤其是AUPR最高仅为0.024,几乎缩减了一个数量级(图5a),此时最高TS评分只有3.671%,命中率下降至10.959%,空报率也升高至94.768%。不难发现,同一小时内的样本信息对模型能力提升的贡献极大,即便是相邻时刻的样本也难以弥补其作用。换言之,该试验验证了基于数值模式的逐时降水数据集具有时间敏感的特点,这会给模式后处理技术带来很大的困难。
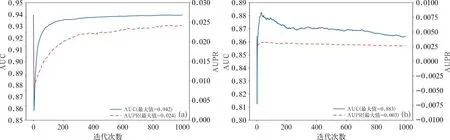
图5 轻微不平衡采样的模型在(a)2019年小时划分的交叉验证和(b)2020年测试集的AUC与AUPR
2020年测试集的条件更为苛刻,与训练集之间基本不存在时间相关性,模型甚至无法获取邻近时刻的样本信息。因此,模型的最高AUC和AUPR再度下降,分别仅有0.883和0.003,表明了模型从2019年数据集中学习到的映射关系只有很小一部分适用于2020年,再次验证了模型有效性主要来自于相同或相邻时刻的样本信息。
3.4 异质模型动态融合方案
从模拟实际业务的角度来讲,尽管无法得到超出当前时刻的样本信息,但可以将已发生的最新样本信息用来更新模型,使模型逐渐适应新的数据分布。上述LightGBM模型在本质上是基于决策树的加性模型,导致很难将最新样本信息引入其中。因此,选择逻辑回归(logistic regression,LR)算法作为次级模型以达到对初级静态模型“再订正”的目的。LR是一种相对简单的分类算法,在具备非线性拟合能力的同时又可以避免在小样本的情况下发生严重的过拟合。此外,仅把LightGBM模型的输出概率作为次级模型的输入特征,会存在变量过少、信息过于单调的问题。深度神经网络(deep neural net,DNN)模型作为目前受到广泛应用的机器学习模型,可以提供不同的统计视角来作为信息补充(陈锦鹏等,2021)。
具体的异质模型动态融合方案为:分别用2019年训练集提前训练好LightGBM模型和DNN模型,其中LightGBM模型超参数与3.3节中一致,DNN模型则采用3层全连接层结构来匹配点特征的输入,网络层的连接顺序为输入层、64个神经元的全连接层、32个神经元的全连接层、16个神经元的全连接层、失活比例为0.1的随机失活层(用来减轻模型过拟合)以及实现概率归一化的Softmax函数输出层。在对2020年测试集的预测过程中,发现由于过拟合问题的存在,训练代数越多反而会削弱泛化能力,故分别取第50代LightGBM模型和第10代DNN模型进行预测。另外在进行动态融合前,需要先判断过去5 d的最新数据中正样本数量是否充足,当正样本数≥10时采用LR进行融合建模,正样本数<10时只对输出概率求平均。具体的流程示意图如图6所示。
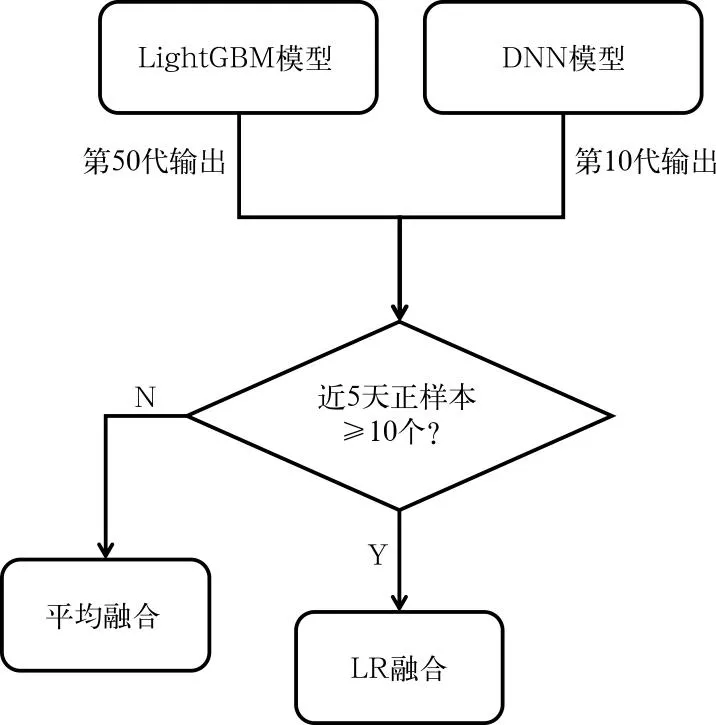
图6 异质模型动态融合流程示意图
对比试验中包含了数值模式、LightGBM模型、DNN模型与LR融合模型共四种预测。在命中率方面(图7a),模式预报表现较稳定,区间大致为42%~90%;LightGBM模型和DNN模型均有随阈值升高而快速下降的特点,实际应用中阈值设定不宜过高;LR融合模型的下降速率则表现出“先高后低”趋势,分类阈值<0.4时命中率维持在90%以上,在0.4~0.6时则为快速下滑阶段,之后与单模型趋于一致。在空报率方面(图7b),三种订正模型均低于模式预报,其中LightGBM模型和LR融合模型在高阈值情况下会出现反弹。TS评分来看(图7c),LR融合模型在LightGBM模型和DNN模型的基础上能够小幅提升,分类阈值达0.78时可得最高TS评分为0.568%。三种订正模型的FPR在分类阈值≥0.5时均优于模式预报,其中LR融合模型的FPR变化趋势与命中率相似。

图7 不同模型预报检验指标随分类阈值的变化
在逐小时强降水预报检验中,命中率尤为重要,为此需要分析在较高命中率的情况下各类方案的表现。通过调节分类阈值将四种预测的命中率控制在实际业务能够接受的50%左右,便于对比其他指标。如表3所示,此时三种订正模型对于模式的空报情况均有所改善,从而在不同程度上提高了TS评分。在空报数方面,LightGBM模型减少了约49.7万个样本,而LR融合模型在命中率提高了1.665% 的前提下减少了约52.4万个样本。在极端不平衡数据中空报数对TS评分影响极大,由于LR融合模型能够有效降低空报数,故TS评分为最优,对比模式预报提高了将近3倍,同时分类阈值也比较合理。
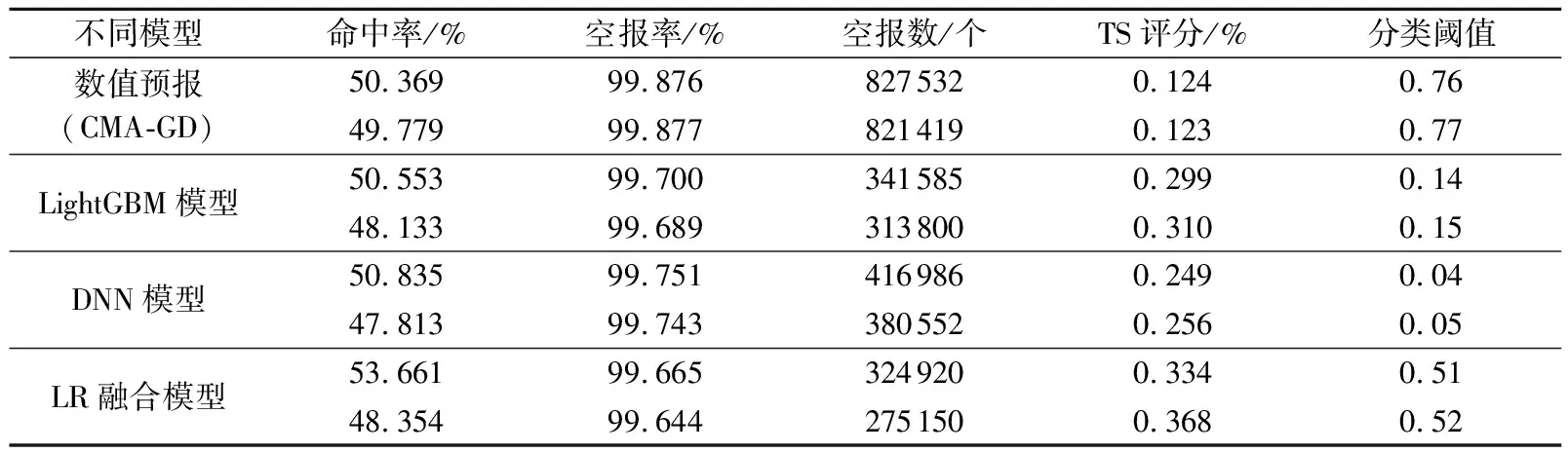
表3 不同模型在命中率约为50%时的对比
4 结 论
本文在逐时降水观测资料与数值模式预报产品的基础上开展短时强降水预报订正试验,应用LightGBM集成学习算法框架与多项模型优化技术进行建模和训练,通过对比不同建模方案在验证集和测试集上的表现,得到如下结论。
(1)CMA-GD模式在短时强降水预报方面具有较低AUC和较高AUPR的特点,从传统指标来看命中率和空报率均较高,各类建模方案的订正模型对此具有不同程度的改善作用。其中Bagging处理能够增强模型预测稳定性,而基于轻微不平衡子训练集的模型在验证集上表现最佳,主要优势在于显著降低了预测空报率而取得更高的综合评分,在验证集中最佳TS评分可达17.5%。
(2)LightGBM模型具有良好的可解释性,通过合理的特征处理可以进一步增强变量间的映射关系,对分类信息增益贡献最大的特征变量为K指数,其次是500 hPa露点温度和自定义添加的时间参数特征。
(3)从随机交叉验证、根据小时划分的随机交叉验证、业务模拟测试等三类时间相关性依次减弱的试验来看,随机交叉验证的指标评分最高,而业务模拟测试为最低,验证了LightGBM模型在短时强降水分类数据集上的有效性主要来自相同或相邻时刻的样本信息。
(4)在业务模拟测试中LightGBM模型略优于3层全连接层架构的DNN模型。针对实际预报业务中客观存在的时间敏感性及数据漂移等问题,基于逻辑回归的异质模型动态融合方案能够实时学习来自不同统计视角的最新样本信息而改善静态同质模型的表现,融合模型在命中率、空报率和TS评分等指标上均有小幅提升,在命中率接近50%时削减空报样本超过52万个。
