考虑行为克隆的深度强化学习股票交易策略
2024-02-05杨兴雨陈亮威郑萧腾
杨兴雨,陈亮威,郑萧腾,张 永
(广东工业大学 管理学院,广州 510520)
如何设计股票交易策略是金融领域中被广泛关注的重要问题。传统的交易策略利用股票的历史价格数据进行技术分析,寻找合适的投资机会,例如双推力策略[1]。然而,这类交易策略有一定的局限性。一方面,面对复杂的金融市场,策略的泛化能力较弱,不能很好地适应未来的价格变化;另一方面,策略依赖人类专家对市场规律的准确分析与把握,而人类专家可处理的信息量有限且存在认知偏差。
近年来,随着人工智能的迅速发展,深度强化学习越来越多地被用于设计股票交易策略。强化学习与人类学习类似,通过与环境的不断交互试错来积累经验,从而实现对环境的感知,并做出与环境相适应的决策[2],可应用于研究资产定价[3]等问题。深度学习通过多层网络和非线性变换对输入的信息进行特征提取,实现高维特征的表达,被广泛应用于研究资产定价[4]、股价预测[5]与信用风险管理[6]等问题。深度强化学习将两者结合,通过不断地感知环境,实现从状态空间到动作空间的映射转换,使决策者同时具有深度感知能力和决策能力,并实现自适应的优化控制[7]。目前,深度强化学习广泛应用于金融投资决策[8]、商品定价[9]、游戏博弈[10]等领域,展现了其在解决序列决策问题方面的优势。
利用深度强化学习,可以直接从大量金融数据中学习得到股票交易策略,即根据决策时的价格等信息,对股票头寸进行适应性调整。与传统的交易策略相比,基于深度强化学习的股票交易策略具有较强的泛化能力。该策略设计方法可以方便地调整网络层数与数据类型,具有良好的扩展性。对于利用深度强化学习设计的股票交易策略,智能体通过不断地探索金融市场环境,利用市场反馈的收益奖励,适应性地调整股票头寸。然而,在探索过程中智能体缺少探索方向的指引,学习效率低,需要大量的探索才可能得到有效的股票交易策略。因此,本文借鉴模仿学习的思想,使智能体在保持自主探索能力的同时,将专家的投资决策作为探索的指引,即模仿专家的行为,从而提高智能体的决策质量与学习效率,使交易策略具有良好的盈利能力和抗风险能力。
基于上述分析,本文研究考虑行为克隆的深度强化学习股票交易策略。首先,选取股票的价格数据与技术因子作为强化学习中环境的状态,用于模拟股票市场环境;其次,通过设计专家策略为智能体提供每个状态的投资建议;再次,令智能体不断探索股票市场环境,使用对决DQN(Dueling Deep Qlearning Network,DDQN)算法优化智能体的决策,利用行为克隆的方法,使智能体在环境中探索的同时模仿专家的决策,从而构造出考虑行为克隆的对决DQN 股票交易策略;最后,对交易策略进行数值分析,并检验策略的性能。
本文的主要贡献如下:
(1) 将模仿学习中的行为克隆引入深度强化学习,让智能体在探索的同时克隆专家的决策,提高智能体的决策水平。
(2) 结合深度强化学习与模仿学习,设计同时具有探索能力和模仿能力的股票交易策略,使交易策略具有良好的盈利与抗风险能力。
(3) 利用多只股票对所设计的策略进行测试,实验结果表明,所设计的策略可以适应金融市场的变化,具有良好的泛化能力。
1 文献综述
利用深度强化学习算法设计股票交易策略已成为量化投资领域的新趋势,受到众多学者的广泛关注,取得了丰富的研究成果。
许多学者提出了以Q 学习算法为框架的交易策略。Chakole等[11]利用K-Means聚类算法对股票状态进行离散化,并确定每个状态类别离散的交易动作集合,借助Q 学习算法设计了一个单只股票交易策略。由于深度学习的发展,可以利用神经网络实现非离散的股票状态到投资动作的映射,使强化学习也适用于状态连续的决策问题。Li等[12]利用深度Q 学习(Deep Q-learning Network,DQN)算法分别在股票上实现了交易策略,通过数值实验验证了将深度强化学习用于设计股票交易策略的优势。许杰等[13]利用长短期记忆网络(LSTM)和卷积神经网络(CNN),提出了一个可在复杂的金融市场中实现自动交易的DQN 股票交易算法。考虑到股票数据的噪声与非线性往往是影响交易策略性能的重要因素,Wu等[14]利用门控循环单元(GRU)提取股票在时间维度上的特征,结合DQN 算法构造了GDQN 模型,实现了单只股票的自适应交易。Lucarelli等[15]设计了一个由单个全局智能体和多个局部智能体构成的深度Q 学习投资组合管理框架,其中,每个局部智能体负责单个资产的交易,全局智能体管理每个局部智能体的奖励,且在加密货币市场对所设计策略进行了测试。Lee等[16]基于多智能体DQN 强化学习框架设计了一个分散化的投资组合策略。为了在动态的金融市场中实现稳定的决策,Jeong等[17]利用深度神经网络提取股票价格数据的时序特征和挖掘交易信号,并结合DQN算法设计了具有良好鲁棒性的深度强化学习交易策略。
在基于深度强化学习设计交易策略的过程中,上述研究只关注股票自身的信息,而在现实的投资决策过程中,往往还需要参考专家的决策建议。因此,本文考虑将模仿学习引入深度强化学习股票交易策略,使智能体在学习过程中模仿专家的决策,从而提高智能体的学习效率与决策质量。模仿学习使智能体通过模仿专家的决策过程学习策略。类似于强化学习,模仿学习也适用于决策问题,其广泛应用于机器人控制[18]、自动驾驶[19]、游戏[20]等领域,例如AlphaGo即通过克隆人类围棋选手的行为进行决策。然而,将模仿学习应用于金融领域的研究较少。Liu等[21]通过模仿学习使智能体在学习中尽可能地参考专家的投资决策,设计了一个高频的期货交易算法。
随着深度强化学习算法的不断发展,不少更稳定的DQN 改进算法被提出,例如对决DQN[22]。为了进一步丰富深度强化学习应用于股票交易的研究,本文将对决DQN 作为基础模型,设计股票交易策略。同时,结合模仿学习的行为克隆方法,通过引入专家的决策信息,让智能体在探索环境的同时克隆专家的决策,使其同时具有自主探索能力和模仿能力。将模仿学习引入强化学习,一方面可以利用专家信息作为智能体探索环境的指引,提高探索环境的效率与决策质量;另一方面保持智能体的自主探索能力,避免只依赖于行为克隆方法导致策略泛化能力弱的问题。
2 相关概念与原理
2.1 对决DQN 算法
强化学习是通过与环境的不断交互试错,根据环境反馈的奖励,不断优化策略。智能体观测到环境的状态s t,并根据策略π做出动作a t,然后从环境中得到奖励r t,同时观测到环境的下一个状态s t+1。框架如图1所示。
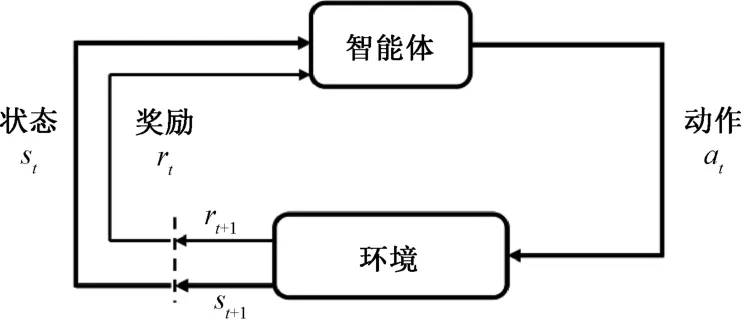
图1 强化学习框架Fig.1 The framework of the reinforcement learning
智能体在状态s t下执行动作a t,从环境中获得的折扣奖励记为u t,其期望称为动作价值函数或Q函数,记为Q(s t,a t),即
式中,γ为折扣率,且γ∈(0,1)。动作价值函数可用于判断动作a t的好坏。
Q 学习的目的是学习最优动作价值函数,使智能体做出最优决策,其更新公式为
2015年,Mnih等[7]基于深度神经网络和Q 学习算法,使用Q 网络代替Q 表,实现连续状态到离散动作的映射,即(其 中θQ为Q 网络的参数),提出了DQN 算法。同时,为充分利用智能体的探索经验,DQN 引入经验回放机制[23]。在智能体每次与环境交互之后,将经验四元组(s t,a t,r t,s t+1)存放在经验回放池P中。在训练过程中,DQN 每次从P中随机抽取N个四元组,并将当前Q值与目标Q值之间的均方误差作为损失函数,即
然而,DQN 算法存在高估Q值的问题[24],对决DQN 算法是解决这一问题的方法之一。该算法通过改进DQN 中Q 网络的结构,更准确地估计Q值。对于某个状态,动作价值与状态价值之差称为动作优势值,对决DQN 设计了状态价值网络和动作优势网络,分别计算智能体的状态价值V(s)以及各动作的优势值D(s,a),从而得到Q(s,a)。对决DQN 还包括一个共享网络,其网络结构如图2所示。

图2 对决DQN 框架Fig.2 The framework of the dueling DQN
2.2 行为克隆
模仿学习是一种针对专家决策进行模仿的方法,其中最直接的模仿学习方法是行为克隆(Behavior Cloning,BC),即对专家的决策行为进行克隆[26]。它以专家的决策动作为标签,使智能体在克隆专家决策的过程中得到一个接近专家决策水平的策略。
行为克隆的决策流程如下:
(1) 构建一个专家训练集D,由M个“(状态,动作)”二元组组成,即
(2) 在监督学习的范式下,将智能体在N个状态下的决策与专家决策的差距,定义为行为克隆的损失,即
(3) 计算损失值Loss(θμ),并利用梯度下降法优化策略网络参数θμ,从而使智能体具有接近专家决策水平的能力。
3 考虑行为克隆的对决DQN 股票交易策略
在强化学习中,智能体不断地在环境中进行探索,并根据环境反馈的奖励,优化自身的策略。然而,智能体通过探索的方式学习策略,存在学习效率低、策略收敛速度慢的问题[27]。若智能体在学习过程中将有关决策的先验知识作为指引,则有望提高其探索与学习的效率。因此,本文考虑利用机器学习中模仿学习的思想,赋予智能体模仿专家决策的能力,提高智能体的决策水平。具体地,本节结合对决DQN 与行为克隆,设计一个克隆专家决策的深度强化学习股票交易策略。
3.1 专家策略的构造
理想的专家行为应与市场行情一致,即专家在每期决策时已知当期股票价格的涨跌,并进行相应的买入或卖出操作。由于专家在每期期初调整资产头寸时已知当期股票价格的涨跌,故专家只持有现金或股票。
专家决策规则如下:
(1) 若当期股票的收盘价高于开盘价,则专家买入股票。具体地,若专家当前持有现金,则全部买入股票;若专家当前持有股票,则继续持有。记对应的交易动作为1。
(2) 若当期股票的收盘价低于开盘价,则专家卖出股票。具体地,若专家当前持有股票,则卖出全部股票,转为持有现金;若专家当前持有现金,则继续持有。记对应的交易动作为-1。
(3) 若当期股票行情持平,即收盘价等于开盘价,则专家不进行任何交易操作,记对应的交易动作为0。
综上可知,第t期的专家动作可表示为
投资者难以预知未来股票的涨跌,而且该类型的专家策略只有在事后才能确定,因此,这类专家策略不能用于现实的股票交易。本文将该类型专家引入股票交易策略的训练过程中,为智能体提供一个模仿对象,使智能体进行自主探索的同时根据专家的决策进行模仿学习。
3.2 股票策略的设计
为实现基于深度强化学习框架的股票交易策略,下面首先介绍环境的状态、智能体的交易规则与动作以及环境中的奖励函数,然后利用深度强化学习对决DQN 算法和行为克隆方法设计完整的股票交易策略。
3.2.1环境的状态 状态是对环境的一种描述,代表智能体从环境中所能获取的信息。利用股票价格数据与技术因子等指标模拟真实的金融环境,包括每日股票的开盘价(Open)、最高价(High)、最低价(Low)、收盘价(Close)、相对强弱指数(RSI)、变动率指标(ROC)、顺势指标(CCI)、收盘价平滑异同移动平均线(MACD)、指数平均数指标(EMA)和成交量平滑异同移动平均线(VMACD)10个指标。智能体每次从环境中观察到的状态是股票在过去一个历史时间窗口内(本文的历史时间窗口大小是15个交易日)的各指标数据。状态s的样例如表1所示。

表1 环境的状态s 的样例Tab.1 The example of the environment state s
3.2.2智能体动作与奖励函数 在投资过程中,投资者只持有股票或现金,不会同时持有两者,在每期期初对资产头寸进行调整,因此,投资者的决策包含将持有的资金全部买入股票、将持有的股票全部卖出和不进行任何交易3 种,分别记为1、-1 与0。智能体的动作记为a t,代表投资者的投资决策,其取值范围为{1,-1,0},与专家动作一致。值得注意的是,相比于专家策略,智能体并不知道当期股票的涨跌,只能基于过去历史时间窗口内的数据进行投资决策。
在强化学习中,通常选取Q值最大的动作作为智能体的动作,即然而,对于本文研究的股票交易问题,Q值最大的动作不一定能够被执行。具体地,若当前不持有现金,则买入动作不能被执行;若当前不持有股票,则卖出动作不能被执行。因此,下面分3 种情形讨论智能体的动作。为方便叙述,记第t期末股票的持有数量为m t,第t期末的现金数额为b t,交易费用率为c。
将第t+1期对数收益率作为环境对智能体的奖励,即
3.2.3股票交易策略 股票投资是一个序列决策问题,可利用深度强化学习方法实现交易决策。相比于DQN 算法,对决DQN 算法能更准确地估计各投资动作带来的未来期望收益。因此,本文基于对决DQN 算法设计股票交易策略。
令智能体在金融环境中探索。具体地,在第t期智能体观察状态st,通过ε贪心策略选择投资动作a t,从环境中获得相应的即期奖励r t,随后环境返回下一个状态s t+1,得到一个经验四元组(s t,a t,r t,s t+1)。为了打破经验间相关性和重复利用经验,采用经验回放技巧,将智能体每次探索得到的经验放入经验回放池。当经验数量大于阈值L时,开始对Q 网络进行训练。随机抽取经验回放池的N条经验计算这批经验四元组的实际Q值与目标Q值间的均方误差,即
对决DQN 通过不断地与环境交互以优化策略,这种基于探索的学习方式存在效率不高、策略收敛速度慢的问题。为此,本文将对决DQN 与行为克隆方法相结合,将专家的决策作为智能体模仿的对象,通过模仿专家来提高智能体的学习效率与决策质量。令智能体对被抽取的历史状态s i再次决策,对应的动作为,并与专家动作进行对比,然后计算智能体的模仿损失,即此处不应采用状态si下的历史动作a i与专家动作对比,是因为过去的决策不能及时反映智能体模仿的效果。
为使智能体同时具备探索环境和克隆专家决策的能力,本文将智能体的强化学习损失和模仿损失进行加权求和,作为智能体的最终损失。考虑到智能体的强化学习损失与模仿损失存在量纲不一致的问题,若直接联结智能体强化学习损失和模仿损失,则调节效果不明显。因此,本文利用两个损失的极差解决该问题。具体地,智能体强化学习损失和模仿学习损失的极差的定义为:
利用极差分别对这两部分的损失进行归一化,再利用参数λ1、λ2加权处理后的损失,最终构造模型的损失函数。具体定义为
式中:θ为Q 网络的参数;λ1和λ2分别为探索损失与模仿损失的权重,用于调节智能体探索能力和模仿专家的程度,λ1+λ2=1,λ1∈[0,1]。当λ1=0,λ2=1时,智能体仅具有克隆专家决策的能力。随着λ1的不断增大和λ2的不断减小,智能体的探索能力逐渐增强,模仿能力逐渐减弱。当λ1=1,λ2=0时,智能体仅具有自主探索的能力。
利用梯度下降法对Q 网络参数θ进行更新,更新公式为
式中,α为学习率。
综上所述,本文设计了考虑行为克隆的对决DQN 股票交易策略,称为BCDDQN(Behavior Cloning Dueling Deep Q-learning Network)。该策略的整体算法框架如图3所示。

图3 股票交易策略BCDDQN 的算法框架Fig.3 The algorithm framework of the stock trading strategy BCDDQN
伪代码如算法1所示:
4 实验设计与结果分析
为检验上节所设计的BCDDQN 策略的性能,将在多只股票上对其进行训练与测试,同时与多个基准策略进行对比,并分析相关的实验结果。
4.1 实验数据
从银行、房地产、制造业与高新科技行业选取4只股票作为测试对象,分别是中国A 股市场的平安银行、万科A、格力电器和紫光股份。为了更充分地说明策略的性能,额外选取银行业指数、家电行业指数与沪深300指数作为测试对象。
描述环境状态的资产数据从东方财富网中获得,时间段是2011年3月1日至2023年3 月1日。其中,将2011-03-01~2020-02-07 的交易数据作为训练集,将2020-02-10~2023-03-01的交易数据作为测试集。由于策略在决策时需要使用过去15个交易日的数据,故测试数据中初始决策日实际为2020年3月1日。对于数据残缺值,采取过去历史时间窗口内的平均值进行代替。
4.2 网络结构与参数
在实验中,选取3 个全连接神经网络作为BCDDQN 策略的共享网络、状态价值网络与动作优势值网络。选取股票的10个指标在过去15个交易日的每日数据作为状态s,将其转换为一个150维的向量作为Q 网络的输入,亦即共享网络的输入。设置共享网络输出层的节点数为50,即状态价值网络与动作优势值网络输入层的节点数为50。后两者的输出层节点数分别为3和1。Q 网络最终输出一个维度为3的向量,各分量分别为买入、持有和卖出3个动作的价值。
设置智能体与环境交互的回合E=100,学习率α=0.001,经验回放池中经验数量阈值L=1 500,每次抽取经验四元组的个数N=512,探索损失权重λ1与模仿损失权重λ2均为0.5。在训练过程中,Q网络参数每更新10次,目标Q网络参数更新一次。另外,除了交易成本灵敏度分析,取交易费用率为0.3%。
4.3 对比策略
本文将与买入并持有策略、基于DQN 的交易算法、基于对决DQN 的交易算法、基于行为克隆的交易算法以及A 股市场指数在测试集内的表现进行对比。各对比策略介绍如下:
(1) 买入并持有策略(B&H)。该策略在第1期使用全部现金买入股票,此后不进行任何买卖操作,其最终累计收益完全由市场决定。因此,通过观察B&H 策略的走势,可以判断该股票在各阶段内是否发生了较大的价格变化。
(2) 基于DQN 的交易策略。该算法适用于解决状态连续的序列决策问题,其决策动作是离散的。DQN 算法可用于实现股票交易,在每一期选择对股票进行买入、持有或卖出的决策。
(3) 基于对决DQN 的交易策略。与DQN 算法类似,该算法同样适合于解决连续状态的序列决策问题,其决策动作是离散的。相对于DQN 算法,对决DQN 对动作价值的估计更准确。
(4) 基于行为克隆的交易策略。该策略仅利用行为克隆的模仿学习方法。该算法中的智能体不与环境进行交互,而是在监督学习的范式下,以专家决策为标签,通过克隆专家的决策学习股票交易策略。
(5) 市场策略。利用A 股指数在测试时间段内的表现与BCDDQN 进行对比,从而判断BCDDQN盈利表现是否能够高于市场整体水平。
在各策略训练完成后,将它们分别在不同股票上进行测试,记录每期的累计收益率,并选取年化收益率、夏普比率与卡玛比率作为评价策略性能的指标,计算公式分别为:
式中:y为投资年限;n为投资期数;S n为累计至n期的收益率;最大回撤
rf为无风险年化收益率;σ为日收益率的年化标准差。本文取rf=0.03。
4.4 实验结果与分析
本节对比各策略在累计收益率、夏普比率和卡玛比率等指标上的表现,以此分析损失函数中权重λ1、λ2和 交易成本对本文策略BCDDQN 的影响,并对BCDDQN 策略进行超额收益检验。
4.4.1策略的收益表现 为检验本文策略的盈利能力,分别使用上述所选标的资产对其进行测试,计算策略在各标的资产上的逐日累计收益率,并与其他策略进行对比,如图4所示。

图4 各策略在不同标的资产上的逐日累计收益率对比Fig.4 The comparison of daily cumulative returns of the strategies on different underlying assets
由图4可以发现:对比基于行为克隆的交易算法,BCDDQN 策略的逐日累计收益率更高。基于行为克隆的交易算法缺少自主探索能力,其每期的投资动作只是针对当期情况做出,而强化学习方法会考虑对未来期望收益的影响。通过观察BCDDQN 策略在7 只标的资产上的表现,可以发现:当市场上涨时,智能体往往能够持有股票赚取收益;反之,当市场下跌时,智能体往往能够卖出股票减少损失。这体现了BCDDQN 策略具有充分应对股票价格变化的能力和较好的泛化能力。DQN 与DDQN 交易算法缺少模仿专家投资决策的能力,仅通过自主探索能力所学策略不能很好地适应未来复杂且变化的金融市场,导致策略的收益表现不足。对比DQN 和DDQN 只有自主探索能力的交易算法,BCDDQN 策略的逐日累计收益率也是最高的。BCDDQN 策略通过行为克隆的方法模仿专家决策,充分利用专家的投资建议,从而智能体在各状态下能更准确地执行投资动作。因此,同时结合强化学习和模仿学习的股票交易策略有更好的收益表现,其逐日累计收益率明显高于其他对比策略。
4.4.2策略风险调整的收益表现 衡量股票交易策略的性能既要考虑收益也要考虑风险,因此关注策略风险调整的收益表现。测试各策略并计算夏普比率和卡玛比率,结果如表2、3所示。

表2 各策略的夏普比率Tab.2 The Sharpe ratios of the strategies
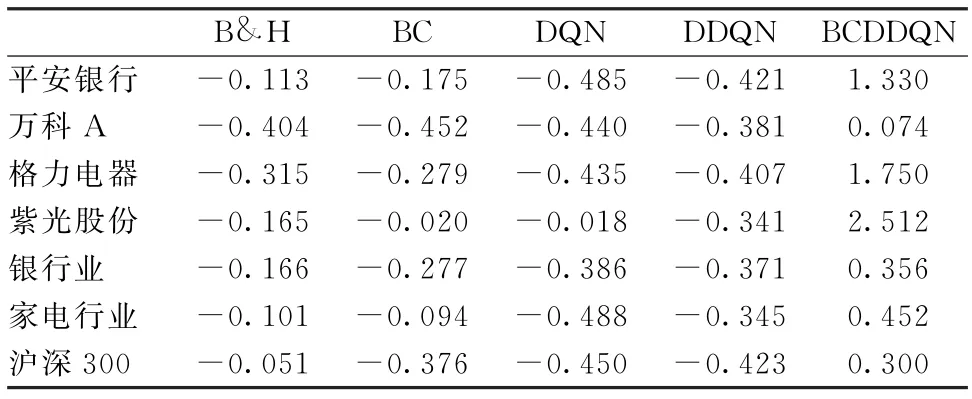
表3 各策略的卡玛比率Tab.3 The Calmar ratios of the strategies
由表2、3可知,BCDDQN 策略的风险调整后的收益均优于其他策略。基于行为克隆的策略仅模仿专家的决策,在学习过程中缺少收益等信息的指示,即智能体不知道决策可带来的奖励与动作价值,最终策略的收益表现不足。BCDDQN 策略在模仿的同时保持了自主探索能力,不仅模仿专家的投资决策,而且还利用环境反馈的奖励信息调整策略,从而提高策略在风险调整后的收益。
DQN 和DDQN 交易策略只是根据每期的对数收益率来调整投资策略,则智能体可能会执行冒险的投资动作来赚取收益而忽略风险。BCDDQN 策略通过引入专家决策进行模仿,使智能体在探索时考虑决策可实现收益的同时减少决策带来的风险,最终策略具有良好的风险调整后的收益表现。同时,策略的抗风险表现也是股票交易策略的重要性能,相关结果如表4所示。由表4可知,BCDDQN 策略抗风险的表现也是最优的。综上所述,BCDDQN 策略在所选股票上展现了良好的适用性和抗风险能力。

表4 各策略的最大回撤Tab.4 The maximum drawdowns of the strategies
4.4.3行为克隆与对决Q 网络的作用 为了进一步验证智能体在探索环境时克隆专家决策的有效性以及不同类型Q 网络对策略的影响,本文设计了考虑行为克隆的DQN 算法,记为BCDQN(Behavior Cloning Deep Q-learning Network)策略。BCDQN策略分别与DQN 交易算法和BCDDQN 策略对比年化收益率,从而验证使用行为克隆和对决Q 网络的作用。BCDDQN 策略与DDQN 交易算法对比年化收益率,用于验证克隆专家决策的作用;DDQN 交易算法与DQN 交易算法对比年化收益率,用于验证使用对决Q 网络的作用。实验结果如表5所示。

表5 各策略的年化收益率Tab.5 The annualized percentage yields of the strategies
由表5可知:在多数股票上考虑行为克隆的深度强化学习交易策略对比未考虑行为克隆的深度强化学习股票交易策略实现了更高的收益,即BCDQN 策略好于DQN策略,且BCDDQN 策略好于DDQN策略;使用对决Q 网络的策略对比使用传统Q 网络的策略,在多数股票上实现了更高的年化收益率,即DDQN 策略好于DQN策略,且BCDDQN策略好于BCDQN策略。BCDDQN 策略结合强化学习和模仿学习两种方法,不仅保持了在环境中自主探索的能力,而且还具有克隆专家决策的能力,使智能体在学习时同时利用自主探索的学习经验和专家的投资建议优化投资策略,从而智能体执行更为恰当的投资动作,带来更高的收益。
4.4.4损失函数中权重对策略的影响 本文策略通过探索损失权重λ1与模仿损失权重λ2控制智能体自主探索和克隆专家决策的程度。为了分析损失函数中权重对策略的影响,分别计算BCDDQN 策略在不同权重取值下的年化收益率,如表6所示。

表6 参数λ1 与λ2 对各策略年化收益率的影响Tab.6 The impact of parametersλ1 and λ2 on the annualized percentage yields of the strategies
由表6可知:当λ1取值较小、λ2取值较大时,智能体主要依赖于专家过去的决策经验进行模仿学习,并利用所学投资策略做出关于未来市场的决策,策略在缺少足够的探索时未能实现良好的收益;当λ1取值较大、λ2取值较小时,智能体主要依赖于自主探索能力进行学习,智能体在探索过程中模仿专家的投资建议不充分,所学策略不能充分体现专家的决策规则,使得策略可带来的收益降低;当λ1、λ2取值恰当时,智能体在环境中探索时具有充分的自主探索能力和克隆专家决策能力,策略在各股均实现良好的收益。因此,应同时保持智能体的自主探索能力和模仿能力,使智能体在学习过程中充分利用环境反馈的信息和专家的投资建议不断地优化投资策略。
4.4.5交易成本对策略收益的影响 交易成本是影响策略实现收益的重要因素之一,智能体每次买卖标的资产时均会产生交易费用。为了分析交易成本对策略收益的影响,对各策略在交易费用率分别为0.00%、0.15%、0.30%、0.45%和0.60%时进行测试,计算它们在不同交易成本下最终实现的年化收益率。具体结果如图5所示。

图5 交易成本对策略收益的影响Fig.5 The impact of transaction costs on the returns of the strategies
由实验结果可知,当交易费用率不断提高时,各股票交易策略可实现的收益均呈现下降趋势。本文提出的BCDDQN 股票交易策略,在不同的交易费用率下,其收益变化曲线均高于其他策略的收益变化曲线,且在各股中实现了最高的年化收益率。即使在高交易费用率下,BCDDQN 股票交易策略仍然表现出良好的盈利能力,相比于其他策略具备更高的收益性和稳定性。因此,同时保持智能体的自主探索能力和模仿能力,能有效提高智能体的投资决策水平,使股票交易策略有良好的收益表现。
4.4.6基于Fama-French三因子模型与五因子模型的策略超额收益检验 实现超额收益是交易策略的核心目标之一,一个交易策略如果能持续地获得超额收益,则意味着该策略具有一定的市场优势,并能够抓住市场中存在的收益机会。为了检验BCDDQN 策略是否具有市场优势,利用Fama-French 三因子模型[28]与Fama-French 五因子模型[29]对BCDDQN 策略进行超额收益检验,检验结果如表7、8所示。实验结果表明,BCDDQN 策略在测试集中均实现超额收益且通过显著性检验。本文策略为投资者实现了比市场平均水平更高的收益,从而增加投资者的回报。

表7 基于Fama-French三因子模型的BCDDQN超额收益检验Tab.7 The excess return test of the strategy BCDDQN based on Fama-French three-factor model

表8 基于Fama-French五因子模型的BCDDQN超额收益检验Tab.8 The excess return test of the strategy BCDDQN based on Fama-French five-factor model
5 结语
本文将专家的决策信息引入深度强化学习对决DQN 算法中,设计了同时具有探索能力和模仿能力的股票交易策略。利用不同标的资产数据对本文策略进行测试,实验发现:本文策略在收益和风险指标上均表现良好,具有较强的抗风险能力与适用性。这说明,模仿专家决策的同时保持自主学习能力能够有效提高交易策略的表现。
本文存在一些不足。设计的交易策略只适用单只股票的投资决策,在决策过程中仅使用历史价格数据与技术指标。因此,未来研究将利用多源异构的股票数据,包括基本面数据和财经文本数据,设计交易多只股票的策略。
