小样本条件下的公路建设项目场景识别与安全预警
2024-02-03周志宇王天一左治江任明龙
周志宇,王天一,左治江,冀 虹,杨 刚,任明龙,高 智*
(1.武汉大学 遥感信息工程学院,湖北 武汉 430079;2.江汉大学 智能制造学院,湖北 武汉 430056;3.中交路桥建设有限公司,北京 101107;4.广州市高速公路有限公司,广东 广州 510030)
0 引言
当前人工智能快速发展,基于深度学习的遥感影像场景分类在诸多领域取得了丰富成果。此类工作主要依靠高质量且数量充足的已标注数据来训练强大的深度网络模型[1-3]。然而现阶段由于场景的特殊性与数据的稀缺性,满足训练条件的优质数据集在实际场景中难以获取,或者构建该类数据集需要投入大量的人力物力,代价高昂且周期很长。因此,关于小样本学习的研究越来越多,其核心任务在于通过有限的训练样本快速掌握对全新数据的理解[4-11]。
当前的小样本学习方法大致遵循将知识从基础类别迁移到全新类别的技术路线,可以分为基于迁移 学习 的方法[4]、基于 元学 习的方法[5,7,11]和基于转导学习的方 法[6,9-10]。经典的迁移 学习[4](又称为基线模型)的核心思想是先在拥有足量训练样本的基础类别上进行学习和知识的积累,然后以聚类和匹配的方式将新的测试样本划分到最相近的基础类别上。元学习方法的思路是“掌握如何学习”,即以偶发式策略(episodic manner)模拟真实世界中的小样本场景[5,11-12]。但是,极少数的训练样本仍然无法概括完整数据集的分布规律,数据的稀缺性又会造成严重的过拟合[13]。为了解决数据稀缺的问题,转导学习引入了额外的未标注数据来改善模型的性能和表现。不论上述方法如何复杂,一个有效的表达对于小样本学习都是至关重要的[6]。
在遥感影像场景分类任务中,小样本学习方法取得了不错的效果,小样本的优势也使得越来越多的科研工作者将其应用到遥感影像场景分类中。Li 等[14]提出了一种名为自适应匹配网络的判别学习方法(DLA-MatchNet),使用新的注意力模型,可以自动发现区分性区域以提取更具区分性的特征。在使用度量学习进行分类时,DLA-MatchNet 使用非线性网络来衡量查询图像和支持集之间的相似度。Li 等[15]提出了一个名为RS-MetaNet 的框架和一个称为平衡损失的新型损失函数,旨在解决现有方法在样本级别上执行并容易过度拟合于个别样本的问题。Zhai 等[16]设计了一个终身Few-shot 学习模型,利用有限的注释数据处理来自不同机构的数据集之间的差异。然而,上述方法都忽略了一个重要点,即虽然样本来自同一类别,但不同样本具有不同大小的分类目标,这导致特征表示效果较差,并且大部分现有策略普遍仅利用元学习框架来学习相似性度量[14-15,17-18],忽略了稳健特征学习的重要性,并忽视了未标注数据中蕴含的潜在信息。
针对当前遥感影像场景分类中小样本研究存在的问题,本文提出一种双阶段场景识别框架,以公路场景识别为例,为解决该问题提供思路。
1 双阶段场景识别框架
本文提出的双阶段场景识别框架如图1 所示。图1(a)表示学习3 个任务的共享主干网络,即:①语义预测识别图像类别;②旋转预测识别二维旋转;③对比预测对匹配的图像进行聚类,找出不匹配图像。图1(b)表示转导学习,通过LP 结果的修正原型进行分类。
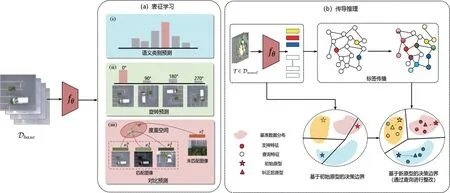
图1 双阶段场景识别框架Fig.1 Two-stage scene recognition framework
多任务学习模型的完整目标函数可以表示为
式中,Lfull表示网络训练的总体损失:Lb、Lr和Lc分别表示语义预测、旋转预测和对比预测的损失;α和β分别表示两个辅助预测损失的权重。在网络收敛后,使用特征提取器fθ将一个新任务T中的所有数据点映射成特征向量,然后使用标签传播修正类别原型,最后使用修正后的类别原型来完成最邻近分类。
1.1 符号说明
Dbase表示已标注的具有大量样本的数据集,该数据集中包含的类别记为Cbase。Dnovle表示未标注的数据集,它包含的类别记为Cnovel,Cnovel与Cbase中没有相同类别。在小样本学习中,用T表示一个任务,任务中包含的类别数记为K。该任务中的支持集记为S={(xi,yi)}NKi=1(即每个类别包含N个样本),查询集记为Q={(xi,yi)}MKi=1,其中xi和yi∈{1,2,…,K}分别表示输入数据以及对应的类别标签。值得注意的是,在表示学习阶段所采用的样本都是(xi,yi)这样的数据点(而不是元学习中的任务)。在推理阶段,一个任务的集合会通过从Dnovle中采样得到。在每个任务中,都会给出支持集S作为训练数据,最终的评估则通过对查询集Q的测试完成。符号说明汇总见表1。

表1 符号说明Tab.1 Symbol description
1.2 基线模型
在训练阶段,基线模型会通过最小化标准交叉熵损失来训练出一个特征提取器fθ(θ代表特征提取网络的参数)和一个线性分类器E(·|Wb)(由权重矩阵Wb∈Rd×|Cbase|进行参数表示)。分类器E(·|Wb)由线性层W_bTfθ(xi)和Softmax 操作(xi∈Dbase)构成。在推理阶段,使用最近邻法则来对每个新任务T={S,Q}进行分类。假设表示第k个类别的支持集数据,计算出这些数据的平均特征作为该类别的原型,即。对于一个查询样本x∈Q,其概率分布通过对它与每一个类别原型的距离进行Softmax 操作后给出,即
1.3 旋转预测任务
旋转预测任务的目标是学习哪一种二维旋转变换被应用于输入图像。将一组旋转操作定义为G=,其中xr=gr(x)表示被旋转某个角度后的图像,共有R种旋转变换。给定旋转分类器的参数Wg=[w1,w2,…,wR],那么输入图像xi上被使用的旋转变换为r的概率可以表示为
在B个随机采样的图像上的损失函数是一个标准交叉熵损失,即
由于这些监督信息与类别无关,所以旋转预测可以促进不同类别之间的信息共享。此外,旋转监督信息背后所蕴含的真正启发在于:网络在有效地执行旋转识别任务之前,应该已经具备了识别该类物体的能力,同时也已经能够认识到图中目标所在的部分。此外,在训练过程中,一张影像通过旋转生成的所有副本都会被同时送入网络,这会迫使这些副本共享某些与旋转无关的特征。其语义分类损失被定义为
给定分类器参数Wb=[w1,w2,…,wc],xi属于第c类的概率可以通过式(6)计算,
1.4 对比预测任务
对比学习的目的是学习一个能够区分出一致(正)样本对和不一致(负)样本对的特征表示。从数学上来讲,首先fθ将输入x映射到一个特征向量r∈Rd,再通过一个映射网络将其映射到一个低维的向量z∈Rd,即z=C(r|ø)。通过一个128 维的全连接层实例化映射网络,将这个网络的输出归一化后用内积来计算它们的余弦相似度。对于一个有B个输入的图像批次,将生成B对随机增强的样本对用于训练。为了识别出与每个样本zi相对应的正样本zp(p∈A(i)),A(i)是当前训练批次中样本zi的所有正样本的索引集),设计了如式(7)的对比损失,即
很明显,训练Lc是为了让正样本对拥有高相似度,同时使得负样本对的相似度更低。为了加强类内一致性和类间差异性,用同一类别的图像来构建正样本对,而用不同类别的图像来构建负样本对。
1.5 转导学习
如图1 所示,经过查询数据的修正,各类别原型更接近于每一类数据的中心点。具体来说,首先利用标签传播策略来为查询样本分配合适的标签。与单独预测每个查询样本的线性分类器不同,标签传播的目的是找到一个足够平滑的标签分配方式,这一方式利用了已知数据(支持集)以及未知数据(查询集)二者的固有内在结构[19]。简而言之,标签传播通过考虑所有数据点之间的关系进行联合预测。
更详细地说,给定一个任务T,小样本特征被表示为R={r1,r2,…,rl,rl+1,…,rl+u} ∈Rd,标签集则记为L={1,K};前l个特征被标记为,其他u个查询特征未被标记(l=N*K,u=M*K)。初始标签由一个(l+u)*K的矩阵Y指定,如果ri(xi的对应特征)被标记为yi=j,则yij=1,否则yij=0。具体可参考文献[19],这里使用欧氏距离来构建无向图。完成标签的传播后,如式(8)所示,通过那些被新归入各个类别的查询样本,i∈I}来扩展各个类别的支持集,
式中,I是被归入k类的查询样本的索引集。完成上述步骤后,即可计算出修正的原型,即=。最终,如式(1)所示,通过寻找查询样本的最邻近类别原型来完成对查询样本的分类。
2 实验和分析
本文设计两组实验来验证公路场景识别的可行性与准确性。第一组实验在遥感数据上训练主干网络并进行测试。第二组实验在第一组实验基础上,首先在遥感数据上训练主干网络模型,再利用训练好的主干网络在构建的小样本公路数据集上进行测试,实现对工程车辆行驶安全的场景识别与智能预警。
2.1 数据和网络结构
第一组实验在3 个有代表性的数据集上进行,即西北工业大学发布的有45 个类的遥感图像场景分类数据集(NWPU-RESISC45)[20]、航空图像数据集(AID)[21]以及武汉大学发布的有19 个类的遥感图像场景分类数据集(WHU-RS-19)[22]。本文遵循文献[14]的标准划分规则(见表2)来划分训练集和测试集(见表3)。

表2 数据集划分规则Tab.2 Partitioning rules of the dataset

表3 各个数据集组成Tab.3 Composition of each dataset
第二组实验在构建的小样本公路数据集上进行测试,包括一个工程车辆数据集、公路数据集以及工程车辆行驶数据集。将常见工程车辆按照尺寸分为两类(大型、中型),将公路按照道路表面建设质量分为3 类(沥青、已铺设、未铺设),将不同类型车辆在不同道路上行驶的情况所构成的风险等级分为3 类(安全、存在隐患、危险)[23],依据文献[24]对于车辆及其行驶公路的分类标准,将数据集划分为3 类,具体按照表4 施行。每一类搜集20 张图片组成3 个小样本测试数据集。3 个数据集的结构划分见表5。
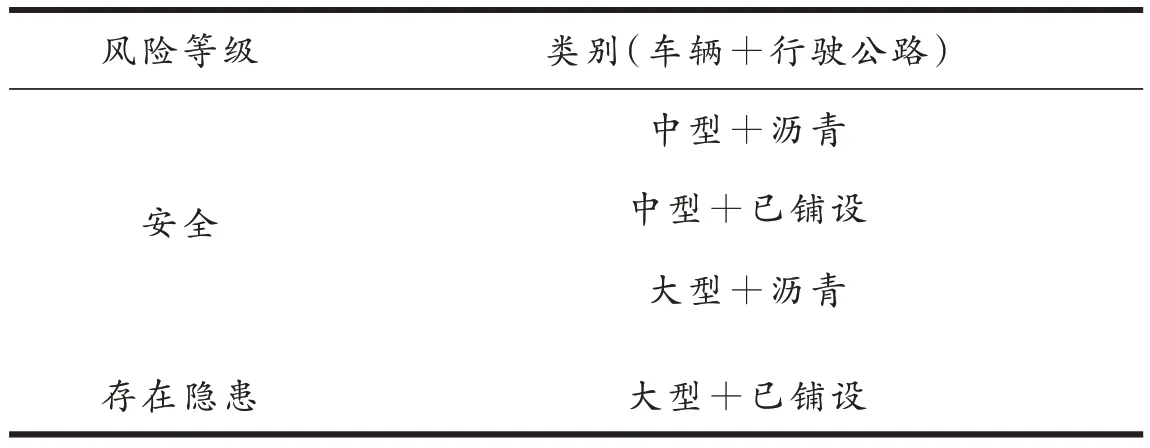
表4 风险等级评定标准Tab.4 Risk rating criteria
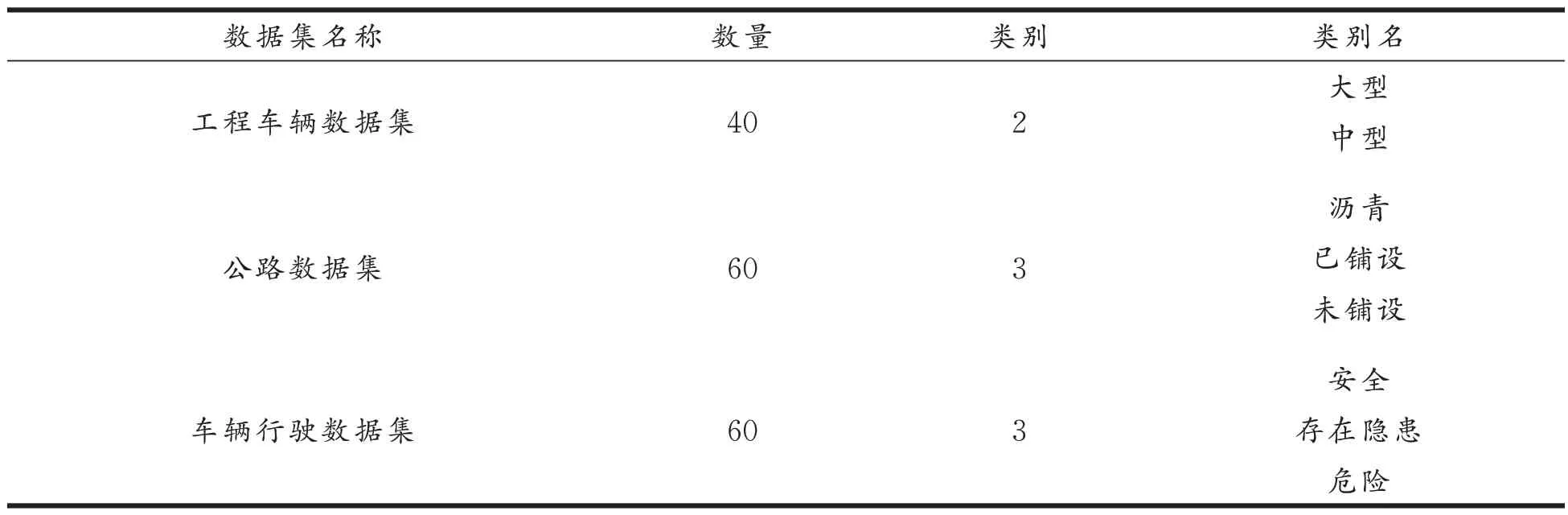
表5 测试数据集组成Tab.5 Composition of the test dataset
关于网络结构,采用层数较深的ResNet12[25]和层数较浅的Conv-256 用于特征提取,然后是3 个平行的单全连接层用于学习3 个任务。3 个分支的对应输出维度Wb、Wg和φ,分别设置为Cbase、4(包含4 个旋转{0、90、180、270})和128。此外,使用视觉表征对比学习框架SimCLR[26]来获得对比学习中的匹配样本。因此,在每个迭代中,网络能够从比批次数量(batch size=32)多8 倍的图像中进行对比学习。
2.2 训练策略
本文设计两组实验来验证模型的可靠性与公路场景识别的可行性与准确性。第一组实验只在遥感数据上训练模型并测试,第二组实验利用第一组实验训练好的模型,在构建的公路场景小样本数据集上进行测试。所有的模型均使用随机梯度下降(SGD)优化器来训练,参数如表6 设置,动量为0.9,初始学习率为0.01,权重衰减为5exp(-4),总训练轮数设定为120 个。学习率在第80 和第100 个训练轮数衰减为原来的1/10。式(2)中的损失权重α和β设为1。为了评估网络性能,随机抽取了2 000 个任务进行五类别分类,每个任务包含15 个查询样本。使用具有95%以上置信度的平均准确率作为网络性能评价标准。

表6 SGD 参数设置Tab.6 Parameter setting of SGD
2.3 与现有工作的比较
将本文方法与现有的7 个代表方法进行了比较,结果见表7。可以得出,使用深度网络架构(即ResNet12)的模型比基于Conv-256 的模型表现更好,这表明深度骨干网络具有强大的学习能力。从特征学习的角度来看,与使用单一旋转预测任务S2M2 相比,本文方法具有巨大优势,取得了73.50%的精度,相较于S2M2 提升了10.26%,其性能明显优于其他算法。在基于元学习的方法中,本文方法同样取得了很好的效果,证明了迁移学习的巨大潜力。而用于光学遥感图像的方法、自适应匹配网络(DLA MatchNet)的判别性学习性能在不同的数据集上表现波动很大,而本文方法在这两个数据集上一直表现良好。这验证了本文所提出的网络结构特征的良好泛化能力。此外,由表7 可知,尽管SIB 和CAN+T 能够实现转导学习,但本文完整模型(使用ResNet12)最终取得了80.58% 的分类精度,相较于SIB 和CAN+T 分别提升了13.24% 和10.69%,其性能明显优于其他方法,证明了本文转导推理算法的有效性。
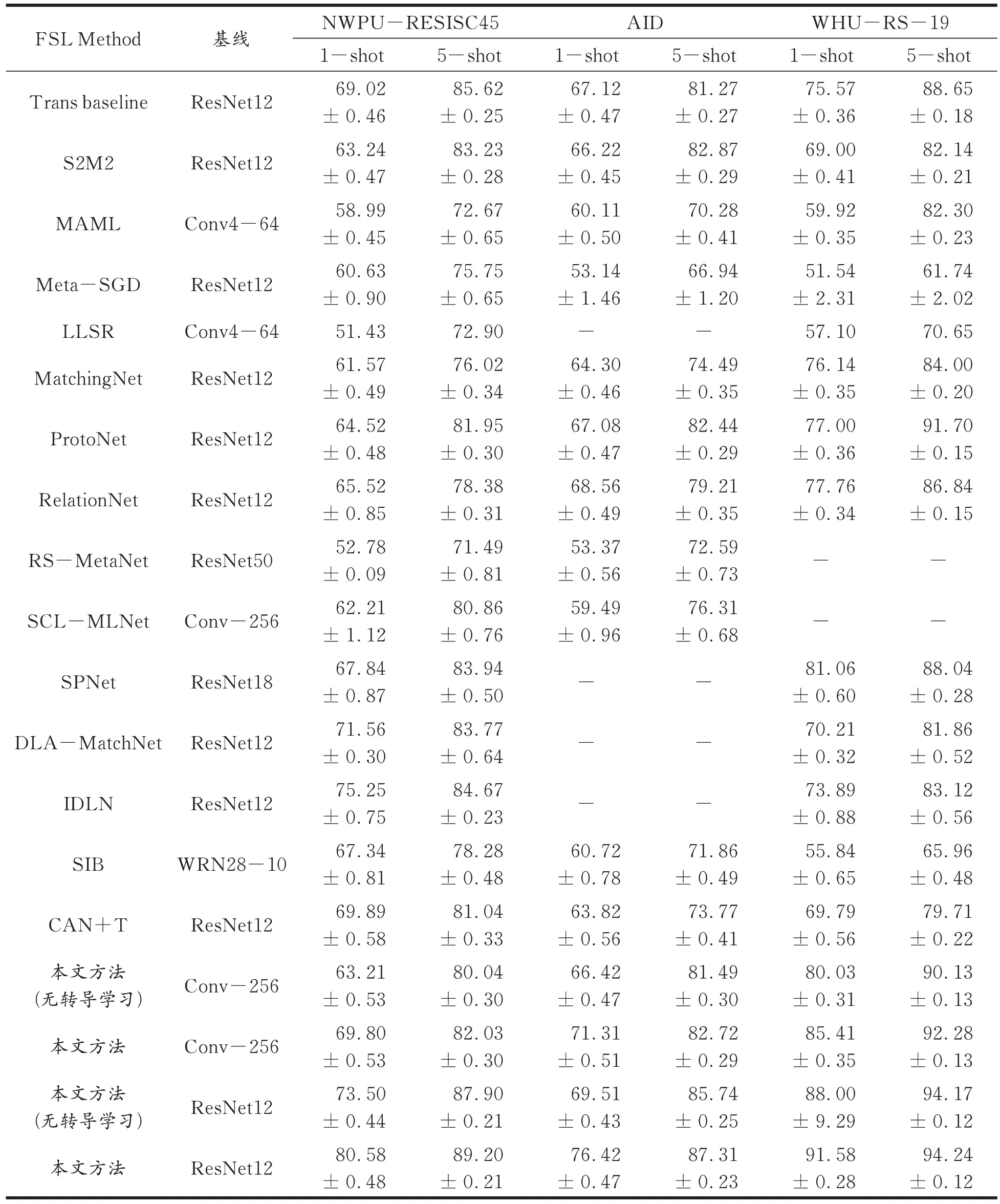
表7 第一组实验结果Tab.7 Results of the first set of experiments
第二组实验结果见表8,对于工程车辆数据集取得了69.37%的精度,对于公路表面质量数据集取得了69.54%的精度,对于车辆行驶数据集取得了48.45%的精度,这验证了模型的可靠性与公路场景识别的可行性与准确性,且证明了本文方法在小样本条件下不同类型的测试数据上仍然能够达到很高的精度。该方法可用于各类实际公路建设项目中车辆行驶安全的场景识别与智能预警任务,具有较强的泛化性。

表8 第二组实验结果Tab.8 Results of the second set of experiments
2.4 消融实验
为了验证每种网络结构的贡献,进行了一系列的消融研究,结果见表9。其中,第一部分①代表仅使用基线模型得到的结果,②则代表在基线模型基础上增加了数据增强技术得到的结果,以此类推。

表9 消融实验结果Tab.9 Results of ablation experiments
1)借口任务。表9 第二部分(②~⑤)显示了两个借口任务(不含归纳推理)的影响。总的来说,引入借口任务学习的3 个模型获得了更好的结果,分别是70.72%和71.58%,都高于不使用任何模型的69.02%。此外,④使用单一借口任务的结果不如⑤使用两种借口任务组合的结果,分别是71.58%和73.50%。这证实了借口任务学习的必要性和它们的协同作用。需要注意的是,虽然应用旋转变换作为数据增强可以带来1.8%的提升,但仍然不如④实验引入旋转预测任务学习的提升(71.58%)。这表明旋转预测可以促进跨类的信息共享。
2)标签传播的效果。表9 的第三部分(⑥~⑨)显示了使用标签传播的结果。结果表明,标签传播可以在所有的实验场景中提高分类精度。特别是当数据稀少时,标签传播能获得更明显的提升。例如,在一分类和五分类的任务中,它与多任务模型相比获得了约3.0%和0.3%的提升。此外,网络性能随着更好的特征而增加,由74.48%提升到76.48%,因为更好的特征能够更好地描述数据点之间的关系(在无定向图中)。
3)原型校正的影响。表9 的第四部分(⑩~⑬)显示了仅使用原型校正的结果。以原型校正为基础模型和用借口任务训练的模型都带来了明显的性能提升。这一现象表明,最初的原型确实是有偏差的,经过校正后可以更准确地表示数据分布。最后,第五部分⑭给出了完整模型的结果,得到了80.58%的精度,数据证明了本文提出的网络模块组合的优越性。
2.5 结果可视化与网络效率
通过计算单次五分类任务所需的推理时间来衡量模型的计算效率。平均到2 000 个任务上,使用ResNet12(47.43 M 参数)和Conv-256(0.43 M 参数)作为骨干网络,推理15 次查询样本的结果耗时分别为2.5 和2.4 ms。这样的推理速度可以很好地满足实时性要求。此外,如图2 所示,图像特征的t-SNE[27]可视化显示了校正后的原型确实更准确地代表数据分布。

图2 NWPU-RESISC45 数据集样例与t-SNE 可视化Fig.2 NWPU-RESISC45 dataset and t-SNE visualization
3 结论
本文提出了一个新的双阶段框架来解决小样本场景识别问题。在第一阶段,将两个辅助任务(旋转预测和对比预测)与迁移学习理论进行融合、联合训练,实现对基础训练数据通用特征表达的学习。在第二阶段,基于标签推理对新类别进行联合预测,并在预测基础上实现对模型的精化与校正。在遥感影像数据上的实验表明,该方法具有良好的性能与较强的泛化能力,可以用于有效训练样本较少的公路项目建设场景,实现建筑工地车辆行驶安全的识别与监控。
