基于跨视图对比学习的知识感知推荐系统
2024-02-02鄢凡力胥小波赵容梅孙思雨琚生根
鄢凡力,胥小波,赵容梅,孙思雨,琚生根*
(1.四川大学计算机学院,四川成都 610065;2.中国电子科技集团公司第三十研究所,四川成都 610225)
随着技术飞速发展,海量信息在网络上生成,信息严重过载。推荐模型作为一种有效的信息过滤机制被广泛应用,其能根据用户需求从海量数据中筛选出有用内容,并推荐给用户[1]。提高推荐系统的精度对商家、电商平台和用户具有重要的商业和使用价值[2]。传统的推荐方法,如协同过滤(CF)[3–5],依赖于历史用户交互数据[6]对用户、物品相似性进行分析,从而实现推荐[7]。但是对于新出现的用户和物品,其历史交互数据通常是非常稀缺的,也就是存在冷启动问题[8]。为了解决冷启动问题,一个被广泛采用的方法是引入知识图谱[9]。知识图谱具有丰富的实体和相关关系信息,能够增强模型可解释性。基于知识图谱的推荐系统也被称为知识感知推荐(KGR)[10–12]。早期的KGR研究使用不同的知识图嵌入(KGE)[13–14]模型来预训练实体嵌入以进行物品表示学习。近年来,有学者提出了基于连接的方法,该方法可以进一步分为基于路径的方法[15–17]和基于图神经网络(GNN)[18–21]的方法。基于路径的方法通过捕获知识图谱的长程结构来丰富用户与物品之间的交互,而基于GNN的方法则利用节点邻居上的局部聚合信息来生成节点表示,并将多跳邻居集成到节点表示中。虽然基于GNN的模型有效,但它们存在用户–物品交互稀疏性的固有缺陷[22],这意味着在实际推荐过程中会出现标签不足的问题。
对比学习是一种能很好解决以上问题的方案。作为自监督学习的经典方法,对比学习实现了从无标签样本数据中学习嵌入的目标[23]。具体地,对比学习通过最大化负样本之间的距离、最小化正样本之间的距离来训练模型,从而实现了无显式标签的训练。
尽管基于对比学习的方法对于解决监督信号稀疏问题是有效的,但是现有的方法还存在以下两个问题[24]:
1)现有的方法普遍使用图卷积直接聚合节点的邻居信息,在面对复杂网络中稠密的节点时,无法排除其中不必要邻居节点的干扰信息。
2)现有的方法对用户–物品–实体的全局视图进行处理时忽略了局部特征;同时,在全局视图上使用多跳信息聚合后,堆叠的多个神经网络层可能使得整个图的节点过于平滑。
为了解决以上两个问题,提出了基于跨视图对比学习的知识感知系统(know ledge–aw are recommender system w ith cross–views contrastive learning,KRSCCL),以充分利用知识感知推荐系统中的用户–物品交互,实现推荐。
模型首先基于全局和局部两个视图生成不同的用户、物品节点,全局视图使用关系图注意力网络聚合重要信息,局部视图使用轻量级图卷积网络(Light–GCN)逐层聚合。然后,对两个视图下的节点表示进行对比学习优化,得到最终的节点表示来进行预测和推荐。
主要贡献如下:
1)使用关系图注意力网络有选择地在邻居节点上采集信息,以显式和端到端的方式实现关系建模。
2)从用户–物品–实体图中考虑了两种视图,包括全局视图、局部视图。然后,对这两个视图进行对比学习,实现表示增强。
3)在3个基线数据集上进行了广泛的实验。结果证明了KRSCCL的优势,这表明了跨视图对比学习和关系图注意力网络的有效性。
1 相关工作
1.1 基于GNN的知识感知推荐
基于知识图谱的推荐系统,也称为知识感知推荐,将用户和物品视为知识图谱中的顶点,并根据交互关系相连。因此,基于GNN的方法非常适合、并已广泛应用于知识感知推荐领域;该方法通过GNN的信息聚合机制,将多跳邻居的信息聚合到节点中,建模知识图谱的远程连接。Wang等[19]提出的图卷积网络推荐系统和Wang等[25]提出的标签平滑推荐系统首先利用GCN迭代聚合物品的邻域信息来得到物品嵌入。Wang等[20]提出的注意力网络推荐系统以端到端的方式对知识图谱注意力网络中的连接进行建模,利用GCN递归地传播来自节点邻居的嵌入。Wang等[21]提出的意图推荐系统通过对关系进行建模,提出意图的概念,形成用户–意图–物品–实体的信息传递路径。尽管这些方法在有监督学习方面表现出色,但它们必须依赖于稀疏的交互数据集,这限制了推荐效果的提升。
1.2 基于对比学习的方法
对比学习方法可通过拉近锚样本和正样本间距离、远离锚样本和负样本间距离来学习节点表示方式。谷歌提出的多任务自监督学习大规模项目推荐框架[26]尝试通过数据增强的方法将同一物品变成两种不同的输入,并得到两个嵌入,借助自监督损失函数,提升模型对物品特征的判别能力。在传统的基于协同过滤的推荐方法中,Wu等[27]提出的自监督对比学习模型将用户–物品–实体图扩展(或损坏)为视图,对原始图和损坏图进行用户–物品交互的对比学习。Shuai等[28]提出的评论感知模型利用评论构建了一个具有特征增强边的评论感知的用户–物品图,并从节点和边两个角度建模并进行对比学习。这些方法通过对比学习,挖掘了更加深层次的信息,但缺乏一种结合细粒度方式的方法。
2 模型
提出了KRSCCL模型,如图1所示,模型包含5个模块:1)使用关系图注意力网络聚合用户–物品–实体信息的全局视图模块;2)使用轻量级图卷积网络聚合用户–物品信息的局部视图模块;3)基于全局、局部两个视图的对比学习模块;4)对用户、物品表示进行贝叶斯个性化排序(BPR)的预测推荐模块;5)实现多任务联合训练的优化模块。
2.1 全局视图
全局视图包含所有用户、物品和实体节点以及它们之间的关系,提供了所有可用信息。KRSCCL在全局视图中构建了关系图注意力网络,有选择地聚合节点之间的信息,并引入了意图[21]来增强用户的表示能力。
2.1.1知识图感知
为了充分利用知识图谱信息[29–31],本文提出了一种全局视图下的知识图感知模块,通过1阶邻居节点表示更新节点表示。将不同节点之间的关系视为不同的嵌入表示,通过对每个物品节点和其连接实体节点之间的关系进行建模,该模型可以学习到每个关系的权重,进而实现节点信息的聚合。
图2为关系图注意力的一个实例,展示了不同节点之间的关系具有不同权重。图2中:节点“Cast Away”和“Forrest Gump”通过“U.S.”和“Tom Hanks”联系起来,每一条边表示的关系α代表节点之间具有不同关系,不同α具有不同的权重数值;α6为“Cast Away”的出品国家是“U.S.”,α4为“Forrest Gump”的出品国家是“U.S.”。“U.S.”对连接的两个节点表示的电影具有不同影响力,α4和α6具有不同权重。
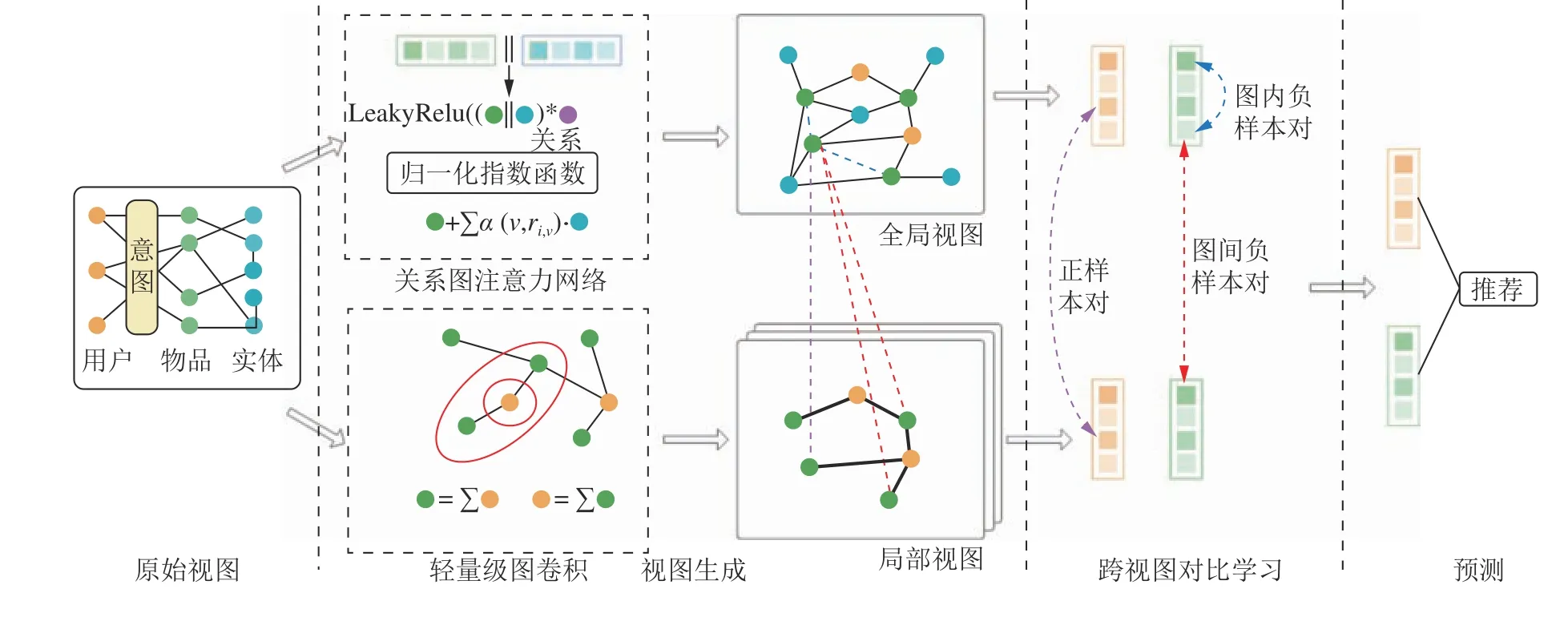
图1 KRSCCL模型视图Fig.1 Illustration of the proposed KRSCCL model

图2 关系图注意力实例Fig.2 Example of relation graph attention
综上,KRSCCL建立了一种在知识图谱上的消息聚合机制,用于连接物品及其连接实体,并通过注意力机制生成物品的嵌入。公式如下:
式(1)~(2)中,e v为实体v的初始嵌入,r i,v为物品i关于实体v不同关系的嵌入,Ni为物品i相邻实体集合,ζ(v,r i,v)为知识聚合过程中实体v和特定关系r i,v相关性,为物品i的初始嵌入,为物品i在全局视图(global view)下的最终表示,LeakyReLU为用以处理非线性变换的激活函数。
2.1.2节点表示生成
在全局视图中,KRSCCL通过两种不同方式分别生成用户和物品表示。
在生成用户表示时,引入意图p的概念,意图反映用户在选择物品时的偏好,被用于衡量用户对于不同的物品维度的关注程度[21]。例如,一个用户可能更关心某个物品的价格和品牌,而不是其他维度,比如物品的颜色和生产日期。意图p可以看作是一种对用户偏好的编码方式,公式如下所示:
式(3)~(4)中,e p为意图p的嵌入,e r为关系r的嵌入,γ(r,p)为一个注意力分数来量化关系r重要性,wrp是关系r和意图p的可训练权重,R为所有种类的关系集合,r'为R中的关系。
要注意的是,意图p并不是单个用户独有的,而是所有用户共同训练的结果。意图p的数量和每个意图下r的数量是人为规定的,多数人会基于相同的意图做出物品的选择,而对于某一个意图只需要考虑占比重最大的几个关系。意图表示彼此之间应该尽可能不同。因此,应该最大化意图距离相关性cor(),距离函数有很多选择,如余弦距离或欧氏距离[32],采用如下表示:
式(5)~(6)中,p'为和意图p不同的其他意图,cov()为两个意图表示的距离协方差,var()为意图表示的距离方差,LIND为增加意图独立性的损失函数。通过如下公式得到用户u的最终表示:
式(7)~(8)中,β(u,p)为用户u关于意图p的注意力分数,P为所有意图,Nu为用户u的所有相邻物品的集合,|Nu|为用户u所有相邻物品的数量。
和文献[21]不同的是,KRSCCL不采用多层聚合的方式,KRSCCL只有1跳。原因是图注意力和图卷积网络的不同,多层聚合会对关系注意力造成干扰,使实验效果下降。
2.2 局部视图
过去的模型仅考虑全局视图下用户–物品–实体节点的信息,无法很好地反映用户和物品之间的局部关系。为了更全面地进行对比学习,受到文献[33–35]的启发,本文提出了细粒度的局部视图。
在局部级别的用户–物品视图中使用Ligh t–GCN[36]来学习用户和物品表示。Light–GCN是一种递归执行k次聚合的模型,可以有效地捕捉用户–物品交互的远程连接信息。不需要特征变换和非线性激活函数,Light–GCN使用简单的消息传递和聚合机制,且计算高效[34]。在第k层中,Light–GCN的聚合过程如下所示:
2.3 跨视图对比学习
得到全局和局部节点后,为了进一步挖掘两个视图的特征信息,KRSCCL对两个视图的节点使用对比学习。以物品节点为例,全局和局部视图分别产生了物品表示和。为了找到正、负和锚样本,两个视图内的节点对可以分成3类:同一视图不同位置节点对、不同视图不同位置节点对和不同视图同一位置节点对,分别对应图1的蓝色、紫色和橙色。例如,不同视图同一位置节点对()表示从两个视角看同一个事物的不同内容。因此,这样的节点对应视为正样本。相反,对于同一视图不同位置节点对(),i≠i'和不同视图不同位置节点对(),i≠i',它们所指向的是不同的事物,因此视为负样本。受文献[37–38]的启发,将这些正、负和锚样本带入对比学习中,物品对比损失 Li的公式如下:
式中,s为余弦相似度计算,τ为温度参数,为全局视图下物品i的嵌入,为在global全局视图下和物品i位置不同的物品i'的嵌入,为在局部视图下物品i的嵌入。
同理,KRSCCL使用类似的方法对用户节点进行跨视图对比学习。在分别得到用户和物品的对比学习损失 Lu和 Li后,最终对比学习损失 LCL如下:
2.4 模型预测
在全局视图下,KRSCCL通过关系图注意力网络得到全局级用户表示和全局级物品表示;在局部视图下,通过轻量级图卷积网络得到局部级用户表示和局部级物品表示。然后,对图内和图间节点对进行对比学习,对节点表示进行优化。
2.5 模型优化
为了将推荐、对比学习等任务结合起来,KRSCCL使用了多任务训练策略来优化整个模型。对于推荐任务,采用BPR损失[39]LBPR来重构历史数据,使用户对历史交互过的物品预测得分高于未交互过的物品。这种方法可以增强模型对用户历史行为的理解,从而更准确地推荐相关物品。
式中:O为观察到的训练数据集,包含交互样本O+和随机挑选的样本O–;σ()为sigmoid函数;i+为O+中的正样本物品;i–为O–中的负样本物品。通过将全局和局部层面的对比损失、BPR损失和意图独立性损失相结合,最小化以下损失 L来学习模型参数:
式中,Θ是模型参数集,δ为平衡对比损失和BPR损失的超参数,β为控制意图独立性权重的超参数, λ为控制正则化项权重的超参数。
3 实 验
为了验证本文模型的效果,进行了广泛的实验,回答以下研究问题:
1)相对于最先进的基线模型,本文模型在推荐任务上表现如何?
2)本文模型不同模块如何影响其性能表现?
3)不同的超参数设置如何影响本文模型的性能表现?
3.1 数据集及评估指标
3.1.1数据集描述
在评估模型有效性方面,使用了3个不同领域的公开数据集:Book–Crossing、MovieLens–1M和Last.FM。这些数据集分别来自书籍、电影和音乐领域,并且具有不同的规模和稀疏性,数据集统计见表1。

表1 数据集内容Tab.1 Statistics of datasets
Book–Crossing收集自书籍交叉社区,该社区由对各种书籍的评级(范围从0到10)组成。
MovieLens–1M为电影推荐的数据集,包含大约100万个显式评分,来自6036个用户和2445个物品。
Last.FM为一个从Last.FM 在线音乐系统中收集的音乐收听数据集,拥有约2000名用户。
作者采用RippleNet[40]方法,对3个数据集进行了统一处理,并将其构建成了用户–关系–物品的3元组形式。为了构建知识图谱子集,按照3元组格式的要求,将每个子知识图视为整个KG的子集,并且仅保留置信度大于0.9的3元组。在给定子知识图的情况下,使用所有有效电影、书籍、音乐的名称与3元组尾部进行匹配,以获取它们的ID。接下来,将物品ID与所有3元组的头部进行匹配,并从子知识图中选择所有匹配良好的3元组。
表1中的稀疏度分别是由交互在用户–物品交互矩阵中的占比和3元组在物品–实体交互矩阵中的占比计算得来。可以看出电影、音乐、书籍3个数据集稀疏度依次下降。
3.1.2评估指标
使用训练过的模型对测试集中的每个交互进行预测,并以点击通过率(CTR)预测作为实验的评估标准。为了评估CTR预测的性能,采用了两个广泛使用的指标,即ROC曲线下方的面积(AUC,记为SAUC)和F1分数。这些指标通常用于评估2分类模型的性能,其中,AUC反映了模型在不同阈值下分类正例和负例的能力,而F1分数则综合考虑了准确率和召回率的表现,能够更全面地评估模型的性能。AUC越接近1、F1分数越高,代表模型的性能越好。
3.2 基线模型
为了证明提出的KRSCCL的有效性,本文将KRSCCL与4种类型的推荐系统模型进行了比较,分别是:基于CF的模型(BPRMF)、基于嵌入的模型(CKE,RippleNet)、基于路径的模型(PER)和基于GNN的模型(KGCN,KGNN–LS,KGAT,KGIN,CG–KGR):
BPRMF是一个典型的基于CF的模型,使用成对矩阵分解隐式反馈优化BPR损失。
CKE是一种基于嵌入的模型,将结构、文本和视觉知识结合在一个框架中。
PER是一种典型的基于路径的模型,它提取基于元路径的特征来表示用户和物品之间的连通性。
KGCN是一种基于GNN的模型,通过迭代集成邻近信息来丰富物品嵌入。
KGNN–LS是一个基于GNN的模型,通过GNN和标签平滑正则化丰富了物品嵌入。
KGAT是一种基于GNN的模型,通过注意机制迭代地集成用户–物品–实体图上的邻居,以获得用户、物品表示。
KGIN是一种基于GNN的模型,它在用户意图的粒度上分离用户–物品交互,并在提出的用户意图–实体图上执行GNN。
CG–KGR是最新的基于GNN的模型,使用GNN将协作信号融合为知识聚合。
3.3 性能比较
表2为上述所有模型的实验结果。把KRSCCL和最优基线模型的实验结果(表2中带*数值)进行比较,有以下观察的现象与结论。
KRSCCL在两个数据集上表现良好,高于所有基线模型,在Book–Crossing上仅次于最优基线模型;在M ovieLens–1M数据集上,其AUC和F1分别高于最优基线模型1.51%和2.00%;在Last.FM数据集上,其AUC和F1分别高于最优基线模型2.35%和5.12%;不过在Book–Crossing数据集上提升不明显,仅在F1上高于最优基线模型,而在AUC上明显弱于CG–KGR。
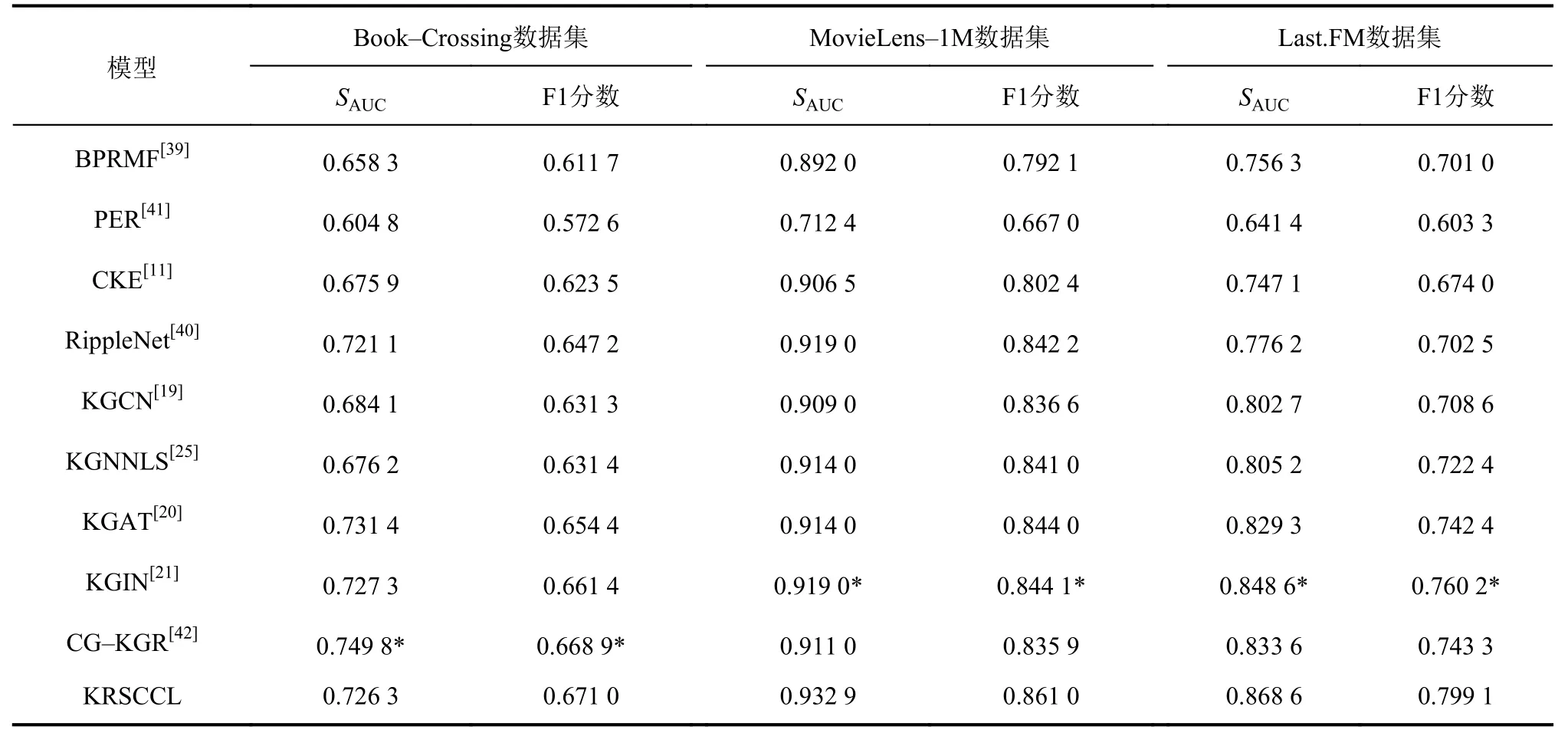
表2 在AUC和F1上的预测结果比较Tab.2 Results of AUC and F1 in CTR prediction
分析认为提出模型性能普遍较好的原因是:1)对于数据更加稠密(电影、音乐)的数据集,KRSCCL的关系注意力网络能有选择地从邻居节点获取信息,减少了不重要信息的噪声干扰;2)通过对全局和局部两个视图的对比学习能更好地挖掘数据信息,兼顾粗粒度和细粒度的信息,生成更强的节点表示。
分析认为KRSCCL在Book–Crossing数据集效果不如最优基线模型的原因主要是KRSCCL的关系注意力网络的多跳聚合能力不如图卷积网络。在数据集特别稀疏的情况下,应该直接将数据集信息全部聚合,而不是有选择性地聚合。这样做不会显著增加计算时间,但是会有效提升性能。由于关系注意力网络在稀疏数据集(Book–Crossing数据集)上的表现不佳,导致KRSCCL的性能效果上的表现不佳。解决这一问题将是后续工作的重点。
3.4 消融实验
图3为KRSCCL、KGIN及KRSCCL的两个变体(WKGA、WACL)在AUC和F1上的表现,展示了模型中主要模块对最终性能的贡献。在WKGA变体中,去除了全局视图中的知识图感知模块KGA,物品–实体通过最简单的方式进行保留;在WACL变体中,去除了跨视图对比学习模块ACL。
由图3可知:
1)WKGA变体显著降低了模型的性能,是效果最差的变体,这证明挖掘图结构信息对于知识感知推荐的重要性。同时,该模块也是整个模型唯一利用知识图谱的模块,说明了引入知识图谱的重要性。
2)在WKGA变体的3个数据集中,MovieLens–1M数据集下降不明显,而其他数据集出现显著下降。这可能是因为MovieLens–1M数据集最稠密,本身就包含丰富的信息。此时,模型仍然保留ACL模块,使用了对比学习,从粗粒度和细粒度角度挖掘数据集本身信息,仍然可以生成效果不错的节点表示。
3)在WACL变体中,可以看出两个指标均有下降,这证明了ACL模块的重要性。相比于Book–Crossing数据集,另外两个数据集下降不明显,这说明在稀疏数据集上ACL模块更加重要。这可能是由于在数据稀疏的情况下,更加需要深度挖掘图信息,而对比学习在这个过程中起到了关键作用,能更加有效利用现有数据生成出更强节点表示。
4)从图3中可以直观地看出,WACL变体仍然在3个数据集的多数指标上高于KGIN模型。这可能是因为KRSCCL在面对知识图谱异构网络中复杂节点和关系时,排除了不必要信息的干扰,只对重要信息进行了聚合。所以在稠密数据集上,取得了非常好的实验结果。

图3 消融实验结果Fig.3 Effect of ablation study
3.5 超参实验
3.5.1局部图聚合深度的影响
为了探究局部图聚合深度对LightGCN模块的影响,在卷积层数范围为{1,2,3,4,5}的模型进行了实验。图4为MovieLens–1M、Last.FM和Book–Crossing数据集上的性能比较结果。在3个数据集上,当层数分别为4、3、3时,KRSCCL呈现出最佳性能。实验发现:1)随着聚合层数的增加,模型效果逐步提升,但达到最优层数后再增加将导致效果急剧下降;2)在较稀疏的数据集Book–Crossing和Last.FM上,选择较小的聚合层数也能取得优秀的效果,而在交互最稀疏的MovieLens–1M数据集中需要更深层次的聚合。
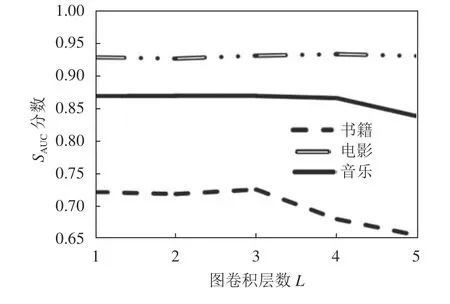
图4 局部视图聚合深度的影响Fig.4 Effect of local view aggregation depth
和全局视图相比,只含有用户–物品交互信息的局部视图中的信息更为重要,因此,对其进行更深层次的聚合能够取得更好的效果。但是,当聚合层数过多时,冗余信息会叠加,抵消有效信息的增益,导致效果下降。但是在稀疏数据集上,则获取更多信息更重要。
3.5.2对比损失权重ϵ的影响
在式(16)定义的总体损失中,权重参数ϵ可以平衡BPR损失和对比损失的影响。为了分析系数ϵ的影响,在0.05~0.15的范围内容改变ϵ,建立不同ϵ下的模型,图5为ϵ是不同值时模型的AUC分数。由图5可知:一个合适的ϵ可以有效地提高对比学习的表现。随着ϵ增大,BPR损失占比越来越大,当ϵ为0.1时,模型表现最佳。但是ϵ继续增大,效果不再能继续提高,甚至有所下降。也就是说,当ϵ为0.1时,BPR损失和对比损失处于最佳的平衡状态。

图5 权重ϵ的影响Fig.5 Effect of the weightϵ
3.6 节点聚类可视化
在全局视图下进行多层图卷积时,节点的区分力下降,节点的表示向量更加趋同,这导致了以GCN为基础的后续学习任务变得困难,即过平滑问题。为解决这一问题,本文采用了图注意力网络有选择地聚合信息,并引入局部视图强调1阶邻居信息。通过使用T–SNE对200个物品节点的嵌入进行降维,并将其映射到2维空间中观察。图6为在KRSCCL及其去除局部视图后的变体中,用户节点在2维空间中的聚类效果。由图6可知:用户节点在图6(a)呈现出较为分散的聚类效果,相较于在去除局部视图后(图6(b))更具差异性,这表明,KRSCCL成功地缓解了过平滑问题。

图6 用户节点聚类可视化Fig.6 User nodes clustering visualisation
4 结 论
本文提出了一个KRSCCL模型,该模型专注于对比学习任务中的关系感知推荐,通过自监督的方式提高用户和物品的表示学习质量。同时,该模型结合关系注意力网络,旨在解决在知识感知推荐中图神经网络模型的邻居节点聚合和细粒度信息发掘的问题。
因此,未来的研究将继续探索推荐中的自监督学习,以揭示数据实例之间的内部关系,并着重处理好冷启动问题。引入因果概念,如因果效应推理和反事实推理到知识感知推荐中,来发现和放大偏差[43]。
