集成显著性话语上下文窗口采样方法的长对话摘要生成模型
2024-01-30吴杰王鹏鸣熊正坤
吴杰 王鹏鸣 熊正坤
北京大学学报(自然科学版) 第60卷 第1期 2024年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 60, No. 1 (Jan. 2024)
10.13209/j.0479-8023.2023.078
国家自然科学基金(62166018, 62266017)和江西省重点研发计划(20203BBE53029)资助
2023–05–18;
2023–08–01
集成显著性话语上下文窗口采样方法的长对话摘要生成模型
吴杰1王鹏鸣2,†熊正坤1
1.华东交通大学信息工程学院, 南昌 330013; 2.温州理工学院数据科学与人工智能学院, 温州 325035; †通信作者, E-mail: zhangwuji115@163.com
针对对话语料的特点, 提出一种集成显著性话语上下文窗口采样方法的长对话摘要生成模型。该模型分为两个模块: 1)显著性话语上下文窗口采样模块将对话话语进行显著性评估, 以显著性话语作为采样锚点, 然后设置采样窗口, 将采样锚点左右相邻的话语一起提取为片段, 提取出来的片段包含更丰富的话语关系; 2)片段间信息融合摘要生成模块利用 Transformer 块, 将相互独立的片段进行信息融合, 加强片段之间的语义关系, 并且为片段在生成摘要期间分配混合权重。利用一致性损失机制, 鼓励显著性话语上下文窗口采样模块确定更佳的采样锚点。在基于查询的长对话摘要公开数据集 QMSum 上的实验结果表明, 该模型在ROUGE 评估指标上的分数高于现有最好的模型。
长对话摘要; 窗口采样; 显著性话语; 信息融合; 生成模型
近年来, 长对话摘要任务成为自然语言处理领域新兴的研究热点。长对话摘要旨在将冗长的对话文本浓缩成能够包含原对话关键信息的简短文本。对话文本产生于会议、客服和闲聊等生活场景中, 对这些文本进行摘要, 可以提取到所需的关键信息。会议记录是记录会议对话内容的重要手段, 然而阅读冗长的会议记录比较费时费力。因此, 会议摘要非常必要, 可以帮助与会人员快速理解会议的关键决定和需要完成的任务。同时, 根据不同类型用户的需求, 需要产生不同的摘要。如图 1 所示, 给定一段会议的对话文本, 可以通过查询“通过上述对话, 学校的主要目的是什么?”来获取所需的关键信息, 即得到符合查询内容的摘要。
基于 Transformer[1]的大规模预训练模型(比如BART[2]和 T5[3])在一些短文本摘要任务中的性能已达到人类水平[4], 但在长对话摘要上的表现不尽人意。与文档摘要相比, 长对话摘要文本内容无结构, 对话角色多, 对话内容冗长, 关键信息较为分散, 导致对话文本的数据结构较为稀疏, 模型难以一次性地输入整个对话内容, 并且对话中的噪声较多。因此, 长对话摘要任务具有一定的挑战性。
为了能利用整个长文本信息, Gidiotis 等[5]提出一种先分割后生成的方法, 先将输入分割成多个片段, 再对每个片段分别进行摘要, 最后将摘要片段组合在一起。Zhang 等[6]提出多阶段生成摘要框架, 利用分割好的片段与标准摘要匹配, 先生成粗粒度的摘要片段, 再生成细粒度的完整摘要。但是分割再生成方法会让片段之间失去联系。为了能让模型感知整个长序列文本, Reformer 模型[7]使用局部敏感哈希注意力, 使输入长度序列扩展到 64k, 并进一步减少内存消耗。然而, 稀疏注意力会牺牲预训练带来的好处。此外, 层次模型重点关注话语结构和角色信息, 试图从不同的角度挖掘信息, 提高生成摘要的效果。HMNet[8]是一个两级层次结构的处理冗长会议记录的摘要生成模型, 包含话语层面信息和对话角色信息的层次结构。上述模型仅关注模型的效果, 没有考虑内存与计算成本。
Sun 等[9]认为生成摘要只需要对话中的关键信息, 不需要利用整个对话文本, 因此提出提取器–生成器混合模型。提取器主要提取对话文本的关键内容, 主要目的是既能提取到所需要的信息, 又能去除对话文本中包含的噪声[10]。然而, 以前的提取器与生成器是单独训练的, 提取不到充分的重要信息, 导致生成摘要时发生级联错误[11][12]–13]。Mao 等[14]提出一个联合训练框架 DYLE 来弥补信息的丢失, DYLE 是一种用于长对话摘要的动态潜在提取方法。DYLE 联合训练一个提取器和一个生成器, 生成器可以在每个时间步骤中动态地为每个提取的对话话语分配权重。动态权值使解码过程可解释, 并通过降低不相关片段的权重来降噪提取。DYLE 还利用一致性损失, 为提取器提供训练信号, 将提取器和生成器桥接起来, 进一步优化提取器。
由于对话中的关键信息往往离散地分布在对话文本中, 因此提取出的关键信息是互相独立的。然而, 在对话中出现的显著性话语与其周围的话语是紧密联系在一起的, 因此, 仅仅依靠这些显著性话语信息生成摘要是不充分的, 显著性话语相邻的话语信息能够为摘要的生成提供更丰富的话语关系。因此, 本文提出一种集成显著性话语上下文窗口采样方法(SDCWS)的长对话摘要生成模型, 包括一个显著性话语上下文窗口采样模块(CWS)和一个融合片段间信息的摘要生成模块(IF)。利用一致性损失机制, 将两个模块联合训练, 鼓励显著性话语上下文窗口采样模块感知更佳的显著性话语采样锚点。最后, 在 QMSum[15]数据集上进行实验, 与现有模型进行对比, 验证本文方法的可靠性。

图1 基于查询的对话摘要案例
1 集成显著性话语上下文窗口采样方法的长对话摘要生成模型(SDCWS)
SDCWS 模型的框架如图 2 所示。首先, 显著性话语上下文窗口采样模块将对话文本的话语进行显著性评估, 以显著性话语为采样锚点, 利用采样窗口将其上下文提取为片段。此外, 提取初始对话中的显著话语作为训练显著性话语上下文窗口采样模块的监督信号。然后, 片段间信息融合摘要生成模块将采样好的相互独立片段联系起来, 并生成片段在摘要生成期间的混合权重, 该权重由动态权重和全局权重组成。最后, 通过一致性损失机制, 将显著性话语上下文窗口采样模块与片段间信息融合摘要生成模块桥接起来。
1.1 问题定义
给定对话文本={1,2, …,u}和一个可选择的查询, 其中对话话语u代表每个角色r及其发言s的串联表示, 即u=r:s。目标是生成长度为的摘要={1,2, …,y},y表示摘要的每个单词。我们将该任务表示为训练一个模型, 给定对话文本和可选的查询及其第个时间步前生成的单词y

其中,表示模型的参数。
1.2 显著性话语上下文窗口采样模块(CWS)
受提取–生成方法启发, 对话中的显著性话语对摘要生成的重要程度更高, 但是其相邻的话语对摘要生成也具有重要作用。本文对话语u进行显著性程度评估, 以显著性话语程度高的前个话语作为采样锚点, 将采样窗口大小设为, 将对话采样提取为包含显著性话语的若干片段。
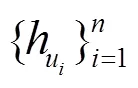
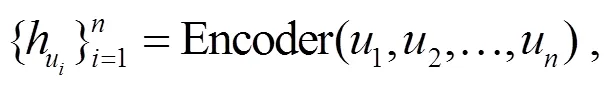
h=Encoder() , (3)
其中,h表示每个对话话语u的隐藏层状态。
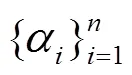

其中,代表多层感知机,表示参数。
接下来, 选择显著性程度高的前个对话话语作为采样锚点S:
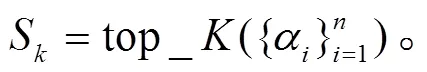
利用采样窗口, 将对话文本采样提取为个文本片段={1,2, …,T}, 每个文本片段的序列长度为。
最后, 将该摘要生成任务表示为
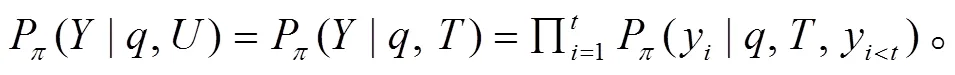
我们提取对话文本的若干重要话语o, 作为训练显著性话语上下文窗口采样模块的监督信号, 以便提取到显著性话语作为采样锚点。本文使用贪心算法提取重要话语o, 设置一个空集合, 迭代地从对话中选择一个对话话语u放入集合中, 使得对话话语u和集合中已存在的对话话语的串联表示与标准摘要的 ROUGE-1, ROUGE-2 和 ROUGE-L 的 F1平均值最大。对于训练显著性话语上下文窗口采样模块, 计算显著性话语采样锚点S与重要话语o的交叉熵损失(重要话语损失):
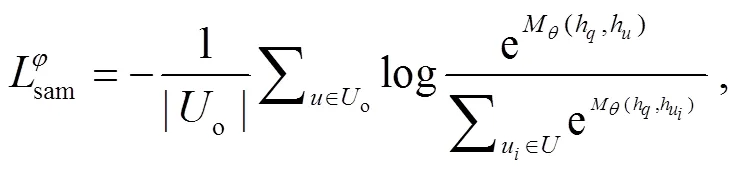
为显著性话语上下文窗口采样模块的参数。
1.3 片段间信息融合摘要生成模块(IF)
经过显著性话语上下文窗口采样模块后, 从对话文本中提取出个文本片段, 但这个文本片段之间的信息被割裂。为了减缓这一不可避免的缺陷, 我们提出一个能够融合各个片段之间信息的摘要生成模块(IF)。该模块在摘要生成模块的编码器与解码器之间增加了个 Transformer 块, 对片段间的信息进行交互, 并且得到生成摘要前片段的全局权重。
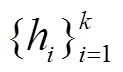
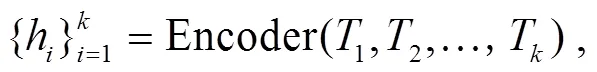
h=Encoder() , (9)
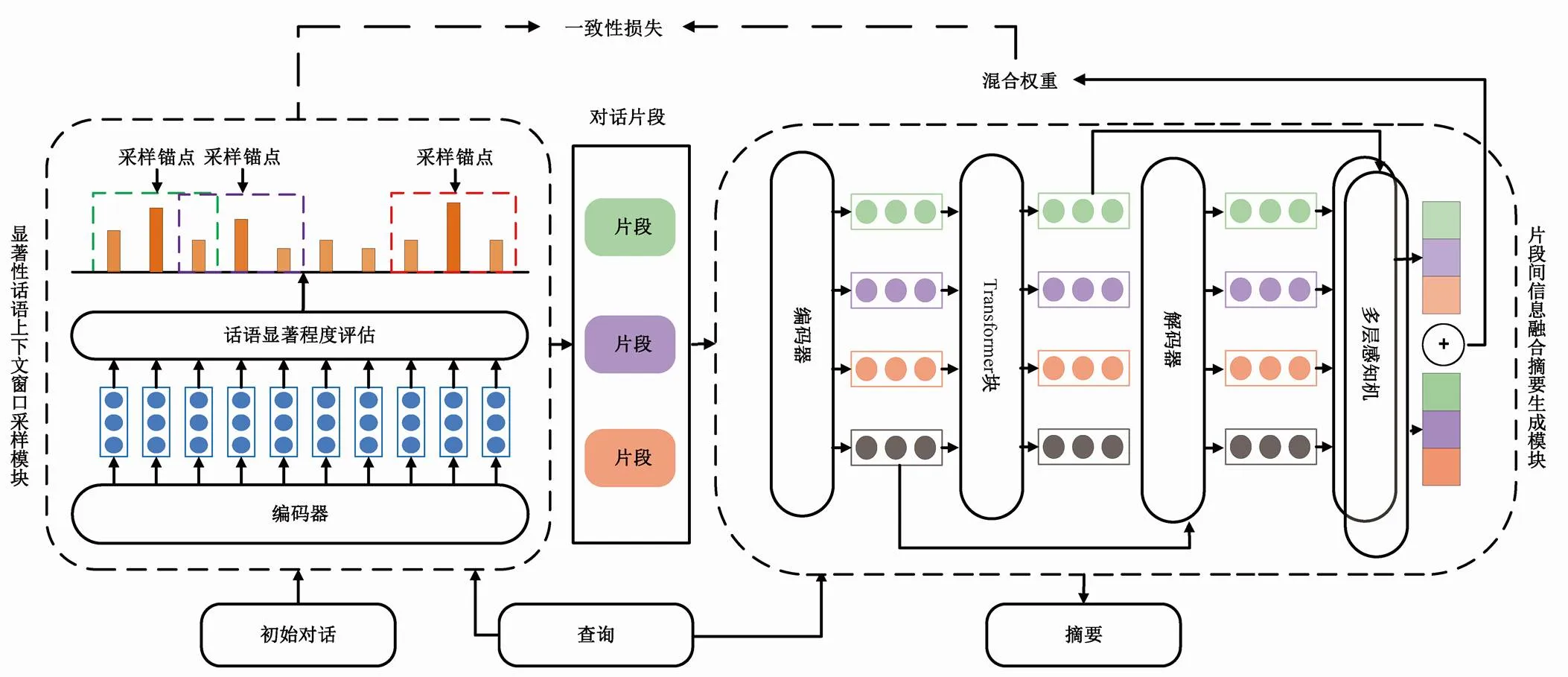
图2 集成显著性话语上下文窗口采样方法的长对话生成摘要模型的整体框架
其中,1,2, …,T表示个片段。
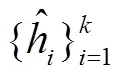
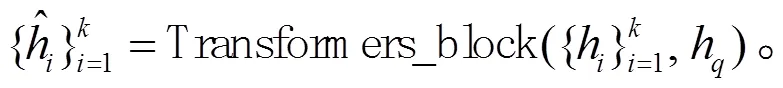
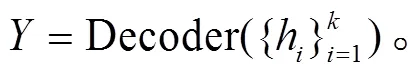
片段间信息融合摘要生成模块的损失函数表示为生成摘要与标准摘要的负对数似然函数:
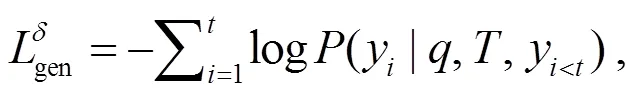
其中,表示摘要生成模块的参数,y表示生成的第个单词。
1.4 一致性损失机制
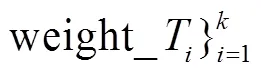
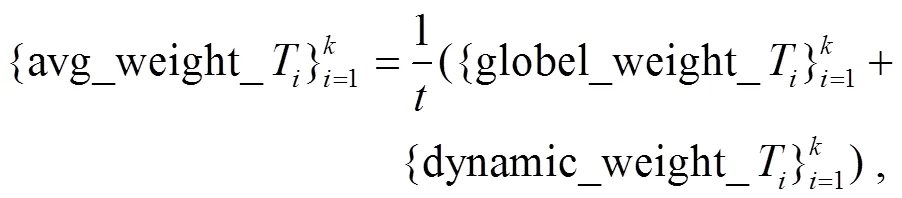
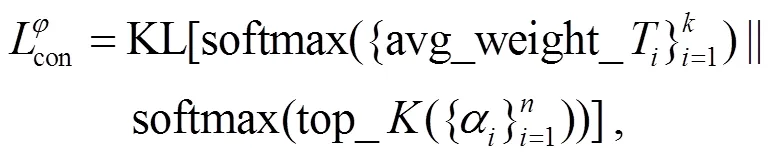

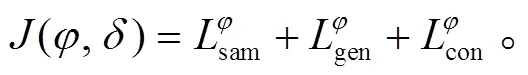
2 实验
2.1 数据集
QMSum[15]是一个基于查询的多域会议总结任务, 包含产品会议(AMI[16])、学术会议(ICSI[17])、威尔士议会和加拿大议会的委员会会议 3 个领域的会议, 对话文本的平均长度为 9069 个单词, 标准摘要的平均长度为 69 个单词。将数据集分为训练集(80%)、评估集(10%)和测试集(10%)。
2.2 基准模型对比
本文采用以下几个基准模型进行对比实验。
1) Pointer-Generator Network (PGNet)[18]: 是一个具有复制机制和覆盖损失的序列到序列模型, 并且在许多生成任务中充当基线模型。
2) BART-large[2]: 是一种用于语言生成、翻译和理解的去噪预训练模型, 在许多生成任务上取得不错的成果, 包括摘要和抽象问题的回答。
3) HMNet[8]: 是最先进的会议总结模型, 通过一个层次结构来处理长时间的会议记录, 通过一个角色向量来描述发言者之间的差异。
4) DYLE[14]: 是一个动态的先提取再生成模型, 将提取器和生成器联合训练, 并将提取的文本片段视为潜在变量不断优化提取器, 在长输入摘要方面取得良好的性能。
5) SUMM[6]: 是一个用于长对话和长文档的多阶段摘要模型, 采用先分割文本后生成摘要的方法, 先生成粗粒度的摘要, 再生成细粒度的摘要。
2.3 评估指标和参数设置
我们采用 ROUGE 指标[19]评估摘要生成的质量, 包括 ROUGE-1, ROUGE-2 和 ROUGE-L, 每个指标都包含精确率、召回率和 F1 值。使用 pyrouge 软件包来计算分数。
对于显著性话语上下文窗口采样模块和片段间信息融合摘要生成模块, 我们分别使用 RoBERTa-base[20]和 BART-large[2]作为骨干模型, 模型初始参数来自 DYLE[14]。
超参数设置: 显著性话语采样锚点S设置为25, 采样窗口大小分别设为 100/300/500。片段间信息融合 Transformer 块设置为 2。
在训练阶段, 随机打乱训练集, 采用批量训练, 批量大小设置为 8。使用 Adam 优化器[21], 显著性话语上下文采样器的学习率为 0.00005, 片段间信息融合生成器的学习率为 0.0000005, 批量大小设置为 8, 训练 4 个 epoch。使用一块 NVIDIA A40, 显存为 48G 的显卡训练。
3 结果和分析
3.1 评估结果
我们使用 ROUGE 评估指标来衡量生成的摘要质量, 采用 F1 值衡量各个模型之间的差别。在数据集 QMSum 上的评估结果如表 1 所示。本文方法在窗口大小为 500 的情况下, ROUGE-1, ROUGE-2和 ROUGE-L 取得的分数分别为 36.10, 11.50 和32.01, 性能表现优于基准模型。值得指出的是, 与提取生成方法 DYLE 相比, 本文模型有很大提升, 在 ROUGE-1, ROUGE-2 和 ROUGE-L 上分别提高1.68, 1.79 和 1.91, 证明显著性话语周围的话语对摘要生成也是重要信息, 通过对这些信息进行多重采样可以增加模型的性能。与分割方法 SUMM相比, 本文模型有显著性的提升, 只分别提升 2.07, 2.22 和2.53, 表明本文模型在一定程度上能够充分利用对话文本的信息, 可以增强片段之间的联系。
3.2 采样窗口大小分析
为了探究采样窗口大小对模型性能影响, 我们通过改变采样窗口的值来评估模型生成摘要的ROUGE-1, ROUGE-2 和 ROUGE-L 的分数。由图 3可知, ROUGE 分数随采样窗口的增大而增加, 这是因为包含的信息越多, 生成摘要的质量越好。另外, 当采样窗口增大, 某些话语会被多次采样到片段中, 表明这些话语对生成摘要质量的提升有重要作用。特别的是, 当采样窗口大小为 300 时, ROUGE-2 和ROUGE-L 的分数提升较明显, 在计算资源开销与DYLE 相当的情况下, 本文模型生成的摘要质量比DYLE 好。
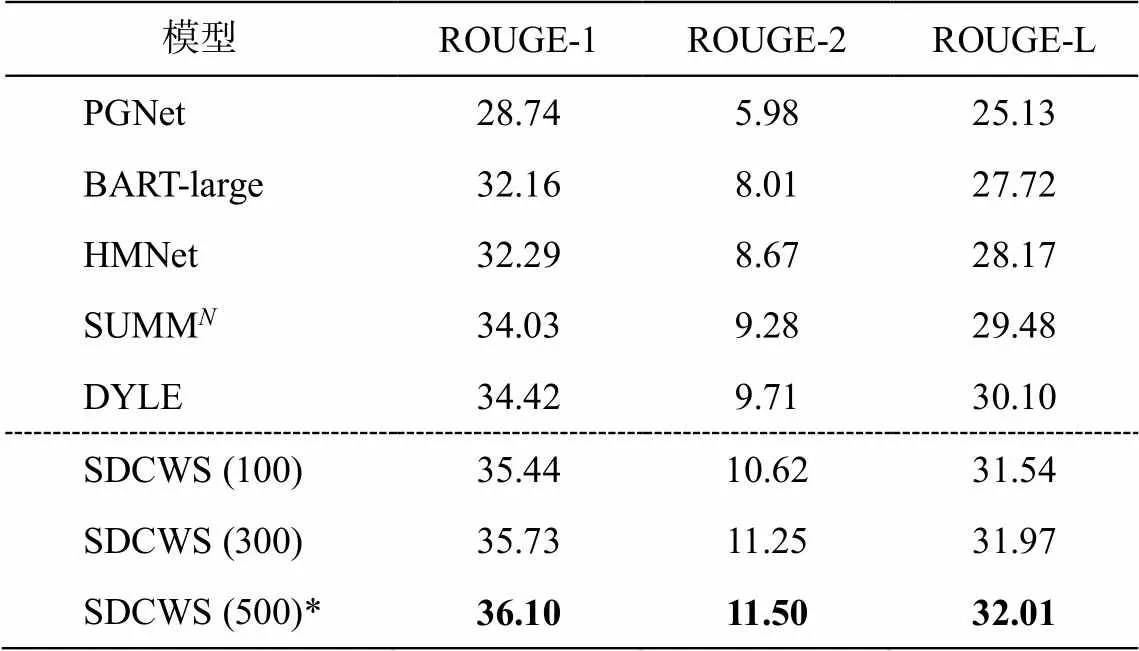
表1 QMSum数据集实验结果
注: *表示 ROUGE 评估结果的提升具有统计显著性(<0.01), 括号内数据表示窗口大小; 粗体数字表示最优结果。
3.3 消融分析
为了验证本文模型的有效性, 在采样窗口大小为 300 的情况下, 分别对显著性话语上下文窗口采样方法(CWS)与片段间信息融合(IF)方法进行消融实验。在数据集 QMSum 上的消融实验结果如表 2所示。
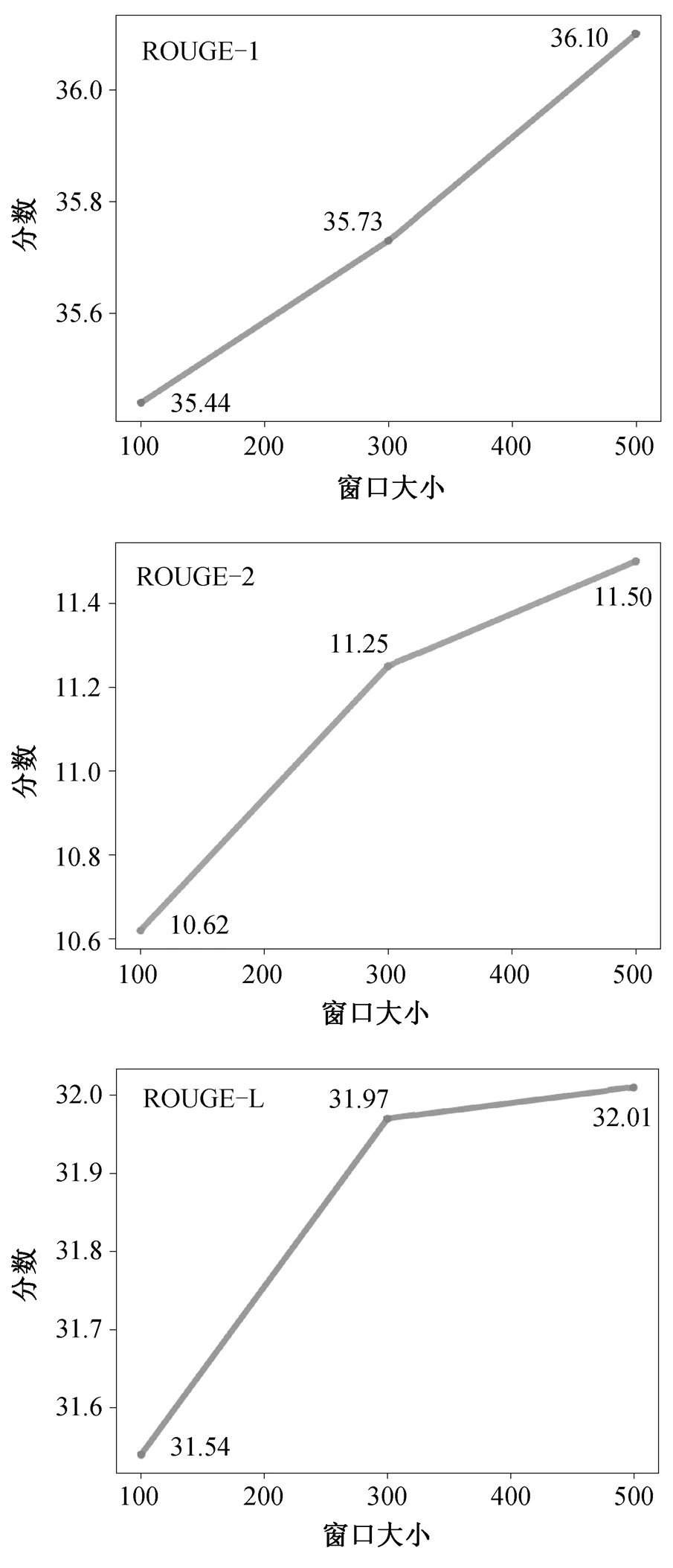
图3采样窗口大小对模型的性能影响
当去除显著性话语上下文窗口采样方法(CWS)后, ROUGE-1, ROUGE-2 和 ROUGE-L 分别下降0.61, 0.89 和 0.76。这表明 CWS 定位了显著性程度高的话语作为采样锚点, 进一步证明显著性话语邻近的话语也包含生成摘要的关键信息。当去除片段间信息融合方法(IF)后, ROUGE-1, ROUGE-2 和ROUGE-L 分别下降 0.66, 0.42 和 0.84, 表明将提取出来的各个对话片段进行上下文语义交互对生成摘要非常重要。如果把两者都去除, 模型就退化为DYLE。从表 1 可以看出, 本文模型采样的显著性话语更丰富, 生成的摘要质量更高。
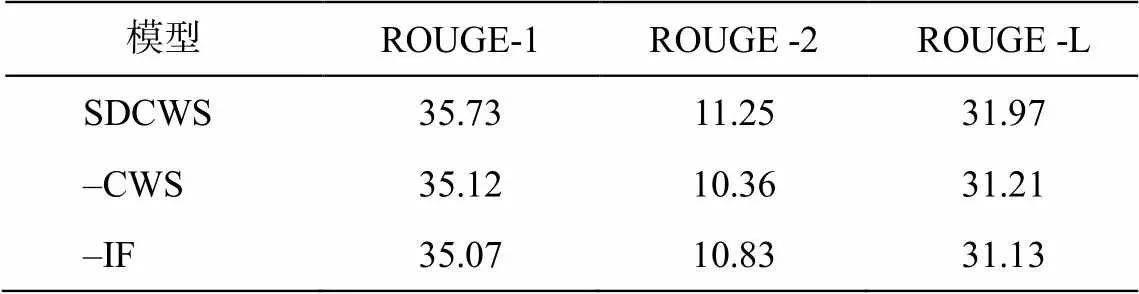
表2 在QMSum数据集的消融实验结果
注: “–”表示在模型中删除该方法。
3.4 案例分析
我们选取 QMSum 数据集中的两个例子, 分别对模型 SDCWS 和 DYLE 进行对比。图 4 为 DYLE生成的摘要在 ROUGE-L 上分数最高的例子与SDCWS 的对比。可以看出, 在 DYLE 生成的最好摘要情况下, 模型 SDCWS 展现出与其相当的性能, 两者之间生成的摘要内容重合度几乎一样。
图 5 为模型 SDCWS 生成的摘要在ROUGE-L分数最高的例子与 DYLE 的对比。可以看出, DYLE几乎没有生成与标准摘要相匹配的摘要, 而模型SDCWS 生成的摘要内容与标准摘要高度匹配, 摘要质量明显好于 DYLE。因此, 显著性上下文窗口采样方法能提取更丰富的话语关系, 生成的摘要质量更好。

灰色文字表示与标准摘要匹配

灰色文字表示与标准摘要匹配
4 结论
本文提出一种集成显著性话语上下文窗口采样方法的长对话摘要生成模型。该模型利用显著性话语上下文窗口采样模块中的话语显著性程度, 评估感知显著性话语采样锚点, 从而将显著性话语邻近的话语信息提取出来, 为摘要生成提供更丰富的话语信息。利用片段间信息融合摘要生成模块, 有效地将提取出来的话语片段之间的语义相联系, 提高了摘要质量。利用一致性损失机制, 将显著性话语上下文采样模块和片段间信息融合摘要生成模块联合训练, 鼓励显著性话语上下文窗口采样模块感知更佳的显著性话语采样锚点。在数据集 QMSum 上的实验结果表明, 本文方法 SDCWS 显著地优于现有的提取生成方法和分割生成方法。
未来的研究中, 将在多个长对话数据集中进行实验, 进一步验证本文方法的可靠性。同时, 将在长文档数据集上验证本文模型对长文本摘要的通用性。
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need // NIPS. Long Beach, 2017: 5998–6008
[2] Lewis M, Liu Yinhan, Goyal N, et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension // Procee-dings of the 58th Annual Meeting of the Association for Computational Linguistics. Online Meeting, 2020: 7871–7880
[3] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 2020, 21(1): 1–67
[4] Tang Tianyi, Li Junyi, Chen Zhipeng, et al. TextBox 2.0: a text generation library with pre-trained language models // Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, 2022: 435–444
[5] Gidiotis A, Tsoumakas G. A divide-and-conquer app-roach to the summarization of long documents. IEEE/ ACM Transactions on Audio, Speech, and Language Processing, 2022, 28: 3029–3040
[6] Zhang Yusen, Ni Ansong, Mao Ziming, et al. SUMM: a multi-stage summarization framework for long input dialogues and documents // Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Dublin, 2022: 1592–1604
[7] Kitaev N, Kaiser L, Levskaya A. Reformer: the effi-cient transformer [EB/OL]. (2020–01–13)[2023–05–30]. https://arxiv.org/abs/2001.04451
[8] Zhu Chenguang, Xu Ruochen, Zeng M, et al. A hie-rarchical network for abstractive meeting summa-rization with cross-domain pretraining // Empirical Methods in Natural Language Processing (EMNLP). Online Meeting, 2020: 194–203
[9] Sun Xiaofei, Sun Zijun, Meng Yuxian, et al. Sum-marize, outline, and elaborate: long-text generation via hierarchical supervision from extractive summaries // Proceedings of the 29th International Conference on Computational Linguistics. Gyeongju, 2022: 6392–6402
[10] Bajaj A, Dangati P, Krishna K, et al. Long document summarization in a low resource setting using pre-trained language models // Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Krishna, 2021: 71–80
[11] Zhang Haoyu, Cai Jingjing, Xu Jianjun, et al. Pre-training-based natural language generation for text summarization // Proceedings of the 23rd Conference on Computational Natural Language Learning. Hong Kong, 2019: 789–797
[12] Logan L, Song Kaiqiang, Dernoncourt F, et al. Sco- ring sentence singletons and pairs for abstractive summarization // Proceedings of the 57th Annual Mee-ting of the Association for Computational Linguistics. Florence, 2019: 2175–2189
[13] Xu Jiacheng, Durrett G. Neural extractive text summa-rization with syntactic compression // Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, 2019: 3292–3303
[14] Mao Ziming, Wu Chen, Ni Ansong, et al. DYLE: dynamic latent extraction for abstractive long-input summarization // Proceedings of the 60th Annual Mee-ting of the Association for Computational Linguistics. Dublin, 2022: 1687–1698
[15] Zhong Ming, Yin Da, Yu Tao, et al. QMSum: a new benchmark for query-based multi-domain meeting summarization // Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Techno-logies. Online Meeting, 2021: 5905–5921
[16] Carletta J, Ashby S, Bourban S, et al. The AMI meeting corpus: a pre-announcement // International Workshop on Machine Learning for Multimodal Interaction. Berlin, 2005: 28–39
[17] Janin A, Baron D, Edwards J, et al. The ICSI mee- ting corpus // 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing. Hong Kong, 2003: 7769054
[18] See A, Liu P J, Manning C D. Get to the point: sum-marization with pointer-generator networks // Procee-dings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver, 2017: 1073– 1083
[19] Lin C Y. ROUGE: a package for automatic evaluation of summaries // ACL. Barcelona, 2004:74–81
[20] Liu Zhuang, Lin Wayne, Shi Ya, et al. A robustly optimized BERT pre-training approach with post-training // Proceedings of the 20th Chinese National Conference on Computational Linguistics. Huhhot, 2021: 1218–1227
[21] Kingma D P, Ba J. Adam: a method for stochastic optimization [EB/OL]. (2015–06–23) [2023–05–30]. https://arxiv.org/abs/1412.6980v6
A Long Dialogue Summary Model Integrating Salience Discourse Context Window Sampling Methods
WU Jie1, WANG Pengming2,†, XIONG Zhengkun1
1. School of Information Engineering, East China Jiaotong University, Nanchang 330013; 2. School of Data Science and Artificial Intelligence, Wenzhou University of Technology, Wenzhou 325035; † Corresponding author, E-mail: zhangwuji115@163.com
A long dialogue summary generation model with integrated salience discourse context window sampling method (SDCWS) is proposed according to the characteristics of dialogue corpus. The model is divided into two modules. 1) The salience discourse context window sampling module (CWS) evaluates the dialogue discourse for salience, uses the salient discourse as the sampling anchor point, and then sets the sampling window to extract the discourse adjacent to the left and right of the sampling anchor point together as fragments, containing richer discourse relations. 2) The inter-fragment information fusion summary generation module (IF) uses the transformer block to fuse information from mutually independent fragments, enhancing the semantic relationships between fragments and assigning blended weights to fragments during summary generation. The loss-of-consistency mechanism is used to encourage the salience discourse context window sampling module to determine better sampling anchors. Experimental results on the publicly available query-based long conversation summary dataset QMSum show that scores of the proposed model are significantly higher than the best existing model on the ROUGE evaluation metric.
long dialogue summary; window sampling; salient discourse; information fusion; generating models
