融合知识的文博领域低资源命名实体识别方法研究
2024-01-30李超侯霞乔秀明
李超 侯霞 乔秀明
北京大学学报(自然科学版) 第60卷 第1期 2024年1月
Acta Scientiarum Naturalium Universitatis Pekinensis, Vol. 60, No. 1 (Jan. 2024)
10.13209/j.0479-8023.2023.070
北京市自然科学基金(4224090)资助
2023–05–12;
2023–08–23
融合知识的文博领域低资源命名实体识别方法研究
李超 侯霞†乔秀明
北京信息科技大学计算机学院, 北京 100192; †通信作者, E-mail: houxia@bistu.edu.cn
文物数据的实体嵌套问题明显, 实体边界不唯一, 且文博领域已标注数据极度缺乏, 导致该领域命名实体识别性能较低。针对这些问题, 构建一个可用于文物命名实体识别的数据集 FewRlicsData, 提出一种融合知识的文博领域低资源命名实体识别方法 RelicsNER。该方法将类别描述信息的语义知识融入文物文本中, 使用基于跨度的方式进行解码, 用于改善实体嵌套问题, 并采用边界平滑的方式缓解跨度识别模型的过度自信问题。与基线模型相比, 该方法在 FewRlicsData 数据集上的 F1 值有所提升, 在文博领域命名实体识别任务中取得较好的性能。在公开数据集 OntoNotes 4.0 上的实验结果证明该方法具有较好的泛化性, 同时在数据集 OntoNotes 4.0 和 MSRA 上进行小规模数据实验, 性能均高于基线模型, 说明所提方法适用于低资源场景。
文博领域; 命名实体识别; 知识融合; 注意力机制
命名实体识别(named entity recognition, NER)[1–3]用于从文本中识别并提取具有特定意义的命名实体(如人名、地名、组织机构名等), 是构建知识图谱和自然语言处理的重要基础。文博领域的命名实体识别是从博物馆藏品中的文献以及文物展览介绍等相关文本中识别出文物名称、类别、年代、作者和出土地等重要信息, 构建文博领域的知识图谱, 有助于文物数字化研究, 也有助于文物保护、研究和展示工作, 对展现和传承传统文化具有重要意义。然而, 面向文博领域的命名实体识别存在领域标注数据极度缺乏以及实体嵌套问题严重两大难点。
首先, 现有的深度学习网络模型训练需要大量标注数据, 但文博领域高质量标注数据极度缺乏。由于文博领域的专业性强, 非专业人士难以标注高质量的数据, 导致数据标注成本巨大。针对数据稀缺的问题, 学者们提出不同的解决方案, 诸如基于半监督的方法和增强句子表示方法等[4–6]。Zhang等[7]使用基于半监督的方法, 在大量无标注数据集中重复选择高置信度高的样本, 通过反复迭代的方式, 逐步扩大训练集的规模。但是, 半监督方法不仅受阈值选择影响, 并且难免有错误样本, 影响模型效果。
其次, 文物名称是文博领域的重要实体, 构成复杂, 可能包含文物的年代、款识或作者(窑口)、地域、纹饰、题材、工艺技法、形态质地、颜色和用途等很多信息, 导致实体嵌套问题严重。例如, 在文物名称“登封窑白釉珍珠地刻花文字枕”中, “登封窑”代表窑口即本文定义的生产机构, “白釉”代表瓷器釉色, “珍珠地”代表表面纹饰, “枕”表示用途。
序列标注和跨度(span)识别是命名实体识别任务中两种常用的方法。序列标注方法将整个文本视为一个序列, 在序列上对每个字进行标注, 标签通常包括实体和非实体两种; 跨度识别方法则将每个实体视为一个跨度, 跨度的起点和终点是该实体在文本中的位置, 目标是预测每个实体的跨度和对应的实体类型, 通过识别每个跨度的起点、终点和实体类型来完成实体识别任务。相比于序列标注的命名实体识别方法, 基于跨度识别方法的优点在于可以准确地定位实体的位置, 从而提高实体识别的准确性, 更有助于解决实体嵌套问题[8–9]。
但是, 常见的基于跨度识别方法中, 训练数据中标注实体的分布是离散的[10], 即实体的分布概率为 1, 非实体的分布概率为 0。这种锐度明显的离散分布不利于模型的训练, 同时在语义层面, 这种明显的边界不适合文博领域的数据。例如, “明嘉靖”和“嘉靖”代表同一个意思, 不应该根据标注规则就断定另一个候选实体的分布概率为 0。另外, 数据稀少导致的数据多样性降低, 会加剧基于跨度识别模型的过度自信问题[11]。
针对上述问题, 本文提出一种融合知识的文博领域低资源命名实体识别方法 RelicsNER, 将类别描述语句知识融入文物文本表示, 辅助模型预测实体, 减少模型对训练数据量的依赖。同时, 该方法在基于跨度实体识别的基础上, 采用边界平滑的方式进行模型训练, 显式地将一小部分分布概率分配给真实实体周围的候选实体, 从而一次性地识别出内嵌于文物名中的多个实体。为了验证 RelicsNER方法面向文博领域数据的有效性及方法的泛化性, 本文构建一个文物数据集 FewRlicsData, 并选取两个公开数据集 OntoNotes 4.0 和MSRA 进行实验。
1 相关工作
有一些研究工作采用序列标注的方法面向文博领域进行命名实体识别, 通常基于现有命名实体识别工具或模型进行改进和优化[12–15], 以便适应文博领域数据的特点。例如, 杨云等[12]基于中文分词工具, 加入文博领域的专有名词词典, 提高文物名称识别的准确率; 巩一璞等[13]使用文博领域的相关知识和特征对模型进行优化, 提升文物类别和年代等信息的识别效果。然而, 基于序列标注的命名实体识别方法很难处理文博领域数据的实体嵌套问题。
很多研究工作使用基于跨度识别的方式进行命名实体识别, 可以在很大程度上缓解实体嵌套的问题。基于跨度识别的方式一般分为两步, 跨度识别和跨度分类。Yu 等[16]通过 BiLSTM 获得单词表示之后, 使用两个独立的前馈神经网络分别表示跨度的开始和结束, 随后使用双仿射模型对句子中的开始、结束位置对进行打分, 最后为此跨度分配类别。Li 等[17]首次将命名实体识别任务定义为问答(QA)任务, 对于嵌套的实体, 只需回答不同的问题, 就能识别不同的实体类型, 但是每次回答一个问题的方式使得模型训练速度缓慢。Shen 等[18]提出并行实例查询网络, 实现并行查询所有的实体, 模型中的多个查询实例在模型训练过程中学习查询语句的语义, 可以避免手动引入外部知识。查询语句提供了相关标签类别的先验知识, 故问答形式的命名实体识别模型在零样本学习场景下有着不错的表现。Yang 等[5]利用注意力机制, 将类别相关的查询语句语义融入文本表示中, 更加充分地利用标签知识。Mengge 等[19]通过维基百科数据训练模型的跨度识别模块, 利用基于词典的远程监督策略训练模型提取跨度的粗粒度类型, 最后通过聚类方法, 挖掘更细粒度的实体类型。Fu 等[20]在识别实体跨度之后, 根据预定义实体类的自然语言描述对提取的跨度进行分类。
2 本文方法 RelicsNER
本文提出一种融合知识的文博领域低资源命名实体识别方法 RelicsNER, 整体结构如图 1 所示。设需要识别的实体类别集合为={1,2, …,|C|}, 为了丰富类别的语义, 本文对中每种标签给定一个类别解释Q, 得到集合={1,2, …,|C|} (||是文物属性类别的数量)。例如, 对于类别“作者”, 其描述信息为“作者是指进行文学、艺术或科学创作的人”。
对文物描述文本和类别解释进行预处理后, 分别输入两个 RoBERTa 编码器网络中。两个编码器在处理各自的输入时共享模型权重, 借此可缓解类别解释数据量不足的问题。然后, 通过注意力机制引导的语义融合模块, 将类别解释的知识融入文本表示中, 得到文本的增强表示。最后, 在基于跨度的解码过程中, 使用增强嵌入来预测每个标记是某个类别的开始索引还是结束索引。同时, 通过优化损失函数, 对人工标注的数据进行边界平滑处理, 用于缓解跨度解码器的过度自信问题。
2.1 融合知识的增强表示
融合知识的增强表示是借助文物实体类别解释中的知识, 对文本的表示进行增强。本文使用RoBERTa[21]预训练语言模型, 分别编码文物文本语句和文物属性描述文本, 得到各自的 token 表示∈R×d和∈R|C|×m×d, 其中和分别是文物文本和文物属性标签描述语句的长度,是编码器的向量维度。由于文物属性标签的文本数量有限, 文物属性描述文本的编码器共享文物文本语句的编码器1, 计算公式如下:
=1() , (1)
=1()。 (2)
得到类别解释的 tokenh后, 计算每个文本表示h与每个文物属性描述语句h的注意力分数, 再把注意力分数作为权重信息, 将类别解释的语义融入文物文本语句的 token 中, 具体做法如式(3)~ (5)所示:
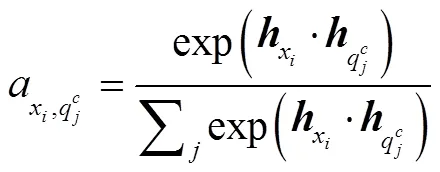
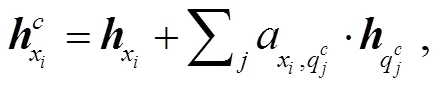
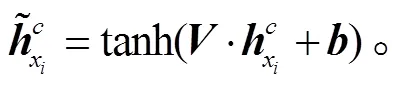


图1 RelicsNER模型结构
2.2 基于跨度的解码模块
RelicsNER 在 token 中融合文物类别解释的语义信息后, 通过计算句子中某个类别开始位置或结束位置的概率, 确定该类别实体在句子中的跨度。目前, 某类别实体开始位置和结束位置的匹配方法有两种。1)就近匹配原则[22–23]: 某类别实体的开始位置与模型预测出的最近的同类别实体的结束位置匹配。2)启发式原则[24]: 在某类别的候选起始位置和结束位置中, 只匹配某类别实体最高概率的起始位置和结束位置。但是, 同一类别中的跨度可能是嵌套的或重叠的, 此时启发式原则不起作用。
本文基于 Li 等[17]的方法, 通过训练, 获得 3 个分类器, 包括起始位置分类器、结尾位置分类器和区间匹配分类器。
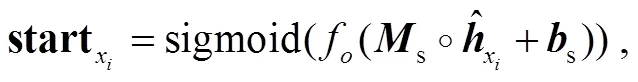

结尾位置分类器 end的原理与起始位置分类器相同:
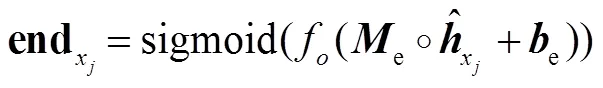
区间匹配分类器用于计算模型预测出的实体跨度是否属于类别的概率:

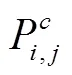
2.3 边界平滑优化的损失函数
在进行实体识别时, 如果实体边界的分布是离散型, 容易导致基于跨度的模型过度自信, 不适用于文物数据。也就是说, 在判断实体边界时, 基于跨度的模型可能只考虑到少数几个具体位置, 忽略了其他可能的边界位置。在这种情况下, 模型很可能只关注最高概率预测实体的位置而忽略其他可能的边界。例如, 在对句子“绛色缎缉米珠彩绣云龙海水江崖纹龙袍清嘉庆长 141 厘米通袖宽 214 厘米形制为圆领, 右衽, 斜襟, 马蹄袖, 四开裾直身长袍式……”进行数据标注时, 将“嘉庆”指定为年号, 则算法就无法识别“清嘉庆”, 或者认为“清嘉庆”没有年号的含义。因此, 本文借鉴 Zhu 等[10]的思想, 在 Yang 等[5]工作的基础上, 增加边界平滑处理之后的损失函数。具体做法是, 将标注实体的分布概率由 1 改为 1–, 其余分布概率分配给标注实体周围的候选实体。设平滑窗口大小为, 所有离标注实体曼哈顿距离为(≤)的候选实体的分布概率总和为/。例如, 句子“药师佛像明景泰元年铜镀金高 85 厘米, 这是一组三世佛像……”经过边界平滑处理后标注实体的分布概率如图 2 所示。
损失函数的定义如下:
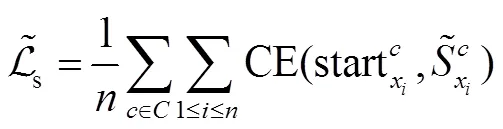
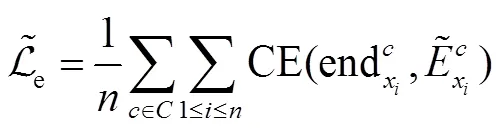

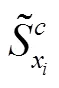
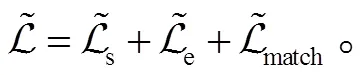
3 实验
3.1 数据集介绍
由于缺乏文博领域可用于文物实体识别的公开标注语料库, 本文从首都博物馆官方网站(https:// www.capitalmuseum.org.cn)爬取 507 条非结构化文物文本, 并进行预处理, 构建一个小型文物数据集FewRlicsData。该数据集的规模为训练集 303 句, 测试集 101 句, 验证集 102 句。参考 CDWA(Cate-gories for the Description of Works of Art)[25]元数据标准, 确定 7 种实体类别, 文物实体类别、中文简称、类别解释以及各类别数量如表 1 所示。其中, 类别解释作为额外的知识融合在文本表示中。基于表 1 中的类别定义, 本文以 json 形式标注文物文本, 形成数据集, 数据标注实例如下。
{
“text”: “釉陶多子盒, 西晋(265-317), 长 25.6 厘米, 宽 17.1 厘米, 高 5.2 厘米, 1962 年北京西郊景王坟西晋墓葬出土首都博物馆藏。泥质红陶。明器。长方形, 共分为十个大小不等的格子。外施褐色釉, 底部有座, 并有弧形装饰, 是魏晋南北朝时期的典型随葬器物之一, 并且可作为中原地区墓葬分期的标准器物之一, 流行于公元 3 世纪中期至 5 世纪末期。”,
“entities”: [{
“label”: “RelicsName”,
“text”: “釉陶多子盒”,
“start_offset”: 0,
“end_offset”: 5
}, {
“label”: “Dynasty”,
“text”: “西晋”,
“start_offset”: 6,
“end_offset”: 8
}, {
“label”: “Collection”,
“text”: “首都博物馆”,
“start_offset”: 112,
“end_offset”: 121
}, {
“label”: “OutOfLand”,
“text”: “北京西郊景王坟西晋墓葬”,
“start_offset”: 59,
“end_offset”: 64
}]
}

表1 FewRlicsData类别名与类别解释
在自建的文物数据集 FewRlicsData 以及公开数据集 OntoNotes 4.0 和 MSRA 上分别进行实验。Onto Notes 4.0 由新闻领域的文本组成, 其中标注了18 种命名实体类别, 本文采用 Meng 等[26]的切分方式。MSRA 来自新闻领域, 标注了 3 种类别的命名实体。OntoNotes 4.0 和 MSRA 这两个数据集常用于评价命名实体识别模型的性能。
3.2 实验设置
基于 RoBERTa-large 模型[21]实现命名实体识别模型, 将 Adam[27]作为优化算法。根据 Zhu 等[10]的实验结果, 将分配出去的分布概率(见 2.3 节)设为0.2, 平滑窗口的大小设为 1。初始化随机数生成器的种子值设为 42, 学习率遵循 Yang 等[5]的设置, 其他参数如表 2 所示。
采用精确度(), 召回率()和 F1 值作为文物实体识别的评价指标。代表模型识别出的实体中与实际情况相符的实体数量,表示测试集中的真实正例有多少被模型正确地识别, F1 值是精确度和召回率的综合指标, 取决于二者的加权平衡。
3.3 实验结果
3.3.1对比模型
为验证 RelicsNER 的有效性, 本文选择 MRC-NER[17]、PIQN[18]、LEAR[5]和 CoFEE-main[19]这 4种基于跨度识别的命名实体识别模型以及序列标注的模型 BERT-Tagger[28]进行对比。MRC-NER 将命名实体识别任务视为机器阅读理解问答任务, 将提取实体类别视为回答某类问题, 可以处理嵌套的NER 任务。PIQN 初始化大量实例查询, 在训练过程中学习不同的查询实例语义, 每个实例查询预测一个实体, 可以并行查询所有实体, 避免人工构造实例查询, 具有更好的泛化性, 模型训练速度比MRC-NER 快。LEAR 分别将句子与问题输入预训练语言模型, 生成句子表示, 随后通过注意力机制, 将问题语句中包含的标签知识集成到文本表示中, 并且模型训练速度比 MRC-NER 快。CoFEE-main是特定于 NER 的预训练框架, 其中的跨度识别模块在大量维基百科数据中学习通用知识, 再通过字典引导学习领域知识, 最后通过聚类, 学习领域内更细粒度的知识。
表2 模型参数设置
3.3.2命名实体识别结果
首先, 在本文构建的文物数据集 FewRlicsData上进行实验, 结果如表 3 所示。本文模型 Relics-NER 的 F1 值高于其他模型, 说明它适用于文物领域的命名实体识别任务。LEAR 模型通过显式的语义融合模块, 学习与类别相关的知识增强表示, 在数据稀缺的文物数据集中表现较好。相较于 LEAR模型, 本文模型 RelicsNER 的 F1 值又提升 0.93%。通过配对 t 检验, 证明本文模型(包含边界平滑模块)显著优于 LEAR 模型(<0.05, 显著性水平= 0.05)。这是因为 RelicsNER 的边界平滑模块缓解了模型进行实体识别时的过度自信问题。跨度解码器提高判定预测实体为正确实体的阈值, 模型的精确度就会提高, 反之, 模型的召回率会提高。本文对模型的边界平滑训练方式隐式地使模型建立一个更高的实体识别阈值, 所以模型预测实体的精确度有很大的提升。
各模型在通用的 OntoNotes 4.0 中文数据集上的实验结果如表 4 所示。可以看到, 本文模型也有较好的表现, 精确度高于其他模型。MRC-NER 模型对提取的实体类型做了非常重要的先验知识编码, 并且其机器阅读理解问答模式不受标注数据稀疏性的影响, 所以表现好于 BERT-Tagger 类的模型。同时, MRC-NER 模型在标注数据稀少的文物数据中有着不错的表现。PIQN 模型的表现较差, 说明其查询实例在 OntoNotes 4.0 中文数据集中没有很好地学习到语义区别。CoFEE-main 模型引入大量的外部知识, 所以在领域数据较少的情况下依然有不错的表现, 但首次训练速度较慢, 并且存在错误传播问题。
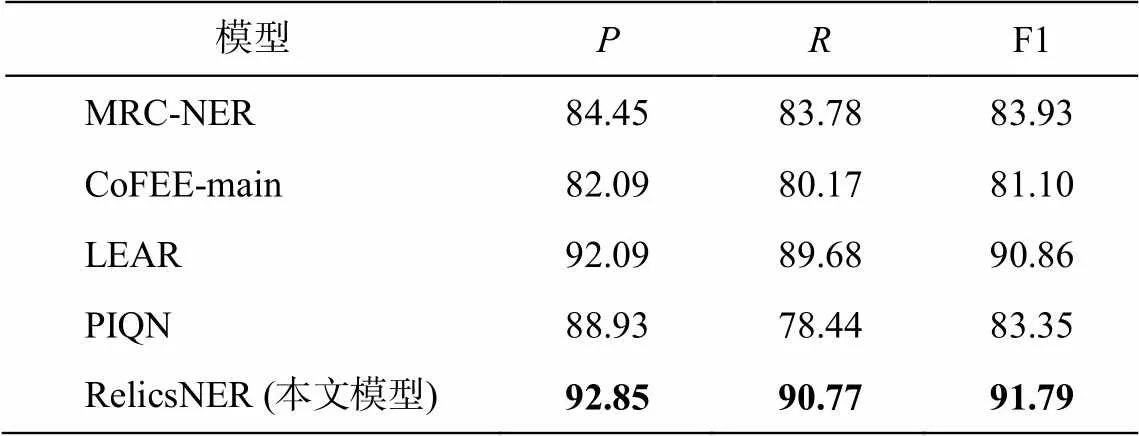
表3 各模型在文物数据集FewRlicsData上的4折交叉验证结果(%)
说明: 粗体数字表示最优结果, 下同。

表4 各模型在中文数据集OntoNotes 4.0上的实验结果(%)
3.3.3低资源场景实验结果
为了进一步验证本文提出的 RelicsNER 模型对低资源情况的适用性, 在公共数据集 OntoNotes 4.0和MSRA 中随机抽取每种类别的实体作为对比模型的训练数据, 分别称为 zhonto4 和 zhmsra。训练数据量的取值范围根据文物实体的各类实体数量(20~ 300)界定。
图 3 显示, 在低资源情境下, 通过注意力机制将标签知识集成到文本表示中的方式效果好于其他模型。在 100 条训练数据的情况下, LEAR 模型的F1 值比全数据训练模型低 2.61%, 而在训练数据达到 300 条时, F1 值只比全数据(15650 条训练数据)训练模型低 1.69%。因此, 本文模型借鉴 LEAR 模型的方式, 将标签知识融入文本表示中, 以便减少模型对训练数据量的依赖。通过与 LEAR 模型对比可以发现, 在只有 20 条训练数据时, 本文模型的 F1值提高 0.98%, 在有 300 条训练数据时提高 0.07%。在训练数据量少的情况下, 本文模型的效果略微好于 LEAR 模型, 说明边界平滑的操作有利于模型对数据特征的学习。由于本文模型与 LEAR 模型在zhonto4 数据集上的差距并不明显(图 3), 故本文进行配对 t 检验, 结果表明本文模型(包含边界平滑模块)显著优于 LEAR 模型(<0.05, 显著性水平= 0.05)。从图 3 可以发现, PIQN 模型比其他模型更依赖训练数据量, 这是因为查询实例也需要较多的数据才能准确地学习查询语句的语义。但是, PIQN 模型并不需要人为地定义查询语句语义, 可以在数据中自动地学习。MRC-MAIN 模型在 zhmsra 数据集上存在过拟合问题, 但是在 zhonto4 数据集上表现正常。
3.3.4训练速度
表 5 显示, 各模型的训练时间与类别数量|| 正相关。LEAR 对所有类别解释进行一次编码, 其训练速度远小于传统的问答 MRC-NER 模型。本文提提出的 RelicsNER 模型对边界做平滑处理, 在训练时增加了模型的计算负荷, 导致训练时间大于LEAR 模型, 但少于其他基线模型。CoFEE-main 模型在预热阶段要从 20 万条维基百科数据中训练模型的通用 span 提取能力, 故其第一阶段的训练十分耗时。本次实验中从预热阶段之后开始计算训练时间, CoFEE-main 模型在聚类挖掘数据特征的过程中耗时较多。PIQN 模型在训练过程中需要选择最佳的查询实例, 故训练时间较长, 并且在类别种类增加时, 训练时长成倍增长。

图3 各模型在数据集zhonto4和zhmsra上的实验结果

表5 不同模型的训练速度对比
说明: 括号内为相较于LEAR模型训练时间的倍数。
3.3.5消融实验
为了验证模型中各个成分的有效性, 我们进行消融实验, 结果如表 6 和 7 所示。
变体 1(w/o BS): 不采用边界平滑方式训练模型。zhonto4 数据集实验结果的 F1 值下降 0.12%, 文物数据集实验结果的 F1 值下降 0.93%, 说明边界平滑操作能够缓解模型自信问题, 在文物数据集中的表现有所提升。
变体 2(w/o fusion): 删除了融合标签知识的模块。zhonto4 数据集实验结果的 F1 值下降 1.48%, 文物数据集实验结果的 F1 值下降 0.75%。这个结果说明融合标签知识的模块可以将标签知识有效地集中到文本表示中, 从而增加 token 作为实体边界位置的概率。
对比表 6 与 7 可以发现, 融合标签知识的模块对 zhonto4 数据集实验结果的影响较大。为了分析数据集和训练数据量对融合标签知识模块的影响程度, 我们在 zhonto4 数据集中随机抽取 20~300 条每种类别的实体作为模型的训练数据, 据此观察在zhonto4 数据集的低资源情况下, 融合标签知识模块对模型的影响, 结果如图 4 所示。可以看出, 在低资源情况下, RelicsNER 模型在 zhonto4 数据集上实验结果的 F1 平均值比变体 2 高 1.18%, 说明训练数据量不会影响融合标签知识模块的作用。

表6 本文模型在文物数据集FewRlicsData上的4折交叉验证结果(%)
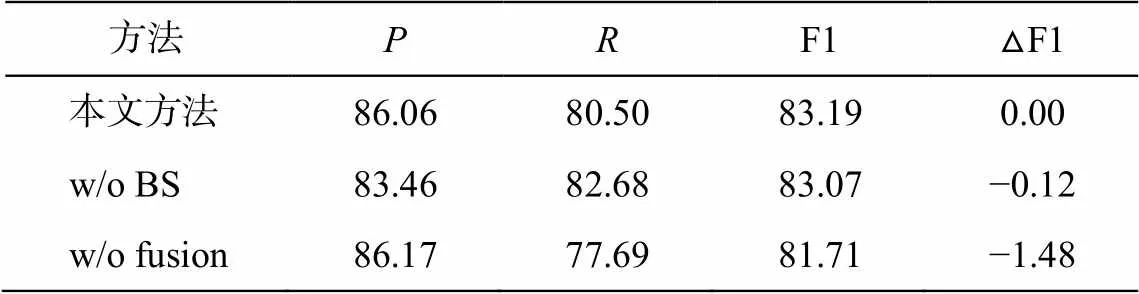
表7 本文模型在zhonto4数据集上的实验结果(%)
3.4 案例分析
针对同一文本, 不同模型的命名实体识别结果如表 8 所示。CoFEE-main 没有正确地识别出文物名, 说明通用知识与文博领域存在一定的差异。此外, 大部分基线模型对出土地(OutOfLand)和生产机构(ProductionAgency)类别的命名实体识别效果欠佳。LEAR 模型将“西晋”错误地识别为“西”和“晋”, 可见存在过度自信的识别边界, 导致出现分词错误。本文提出的 RelicsNER 模型中边界平滑, 学习到实体表示的多样性, 减少了这种过度自信的问题, 提高了分词的准确性。
4 结语
为了解决文博领域的命名实体识别任务中缺乏已标注数据以及因文物名内嵌一些文物的重要属性而导致命名实体嵌套这两类问题, 本文标注 507 条非结构化文物数据, 构建一个小型数据集FewRlics-Data, 并提出 RelicsNER 模型的框架。RelicsNER模型采用基于跨度的方式, 一次性地识别多个实体, 通过注意力机制, 将类别解释语义融入文物文本特征中, 从而可以融入更多的文博领域知识, 降低模型对训练数据量的依赖程度, 并通过边界平滑操作缓解模型过度自信问题。在 FewRlicsData 数据集上的实验结果证明, RelicsNER 模型适合于低资源文博领域的命名实体识别任务。在文物数据集和两个公开数据集的实验中, 本文 RelicsNER 方法的性能都比基线模型有所提升。

图4 本文模型与w/o fusion在不同训练数据量下的实验结果
表8 不同模型的识别结果对比
Table 8 Case study of different models

说明: 红字为未识别出的命名实体。
[1] Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition // Procee-dings of NAACL-HLT. San Diego, 2016: 260–270
[2] Cao P, Chen Y, Liu K, et al. Adversarial transfer lear-ning for Chinese named entity recognition with self-attention mechanism // Proceedings of EMNLP. Brus-sels, 2018: 182–192
[3] Trieu H L, Miwa M, Ananiadou S. Named entity reco-gnition for cancer immunology research using distant supervision // Proceedings of the 21st Workshop on Biomedical Language Processing. Dublin, 2022: 171–177
[4] Ke P, Ji H, Liu S, et al. SentiLARE: sentiment-aware language representation learning with linguistic know-ledge // Proceedings of EMNLP. Online Meeting, 2020: 6975–6988
[5] Yang P, Cong X, Sun Z, et al. Enhanced language representation with label knowledge for span extrac-tion // Proceedings of EMNLP. Punta Cana, 2021: 4623–4635
[6] Zhao X, Yu Z, Wu M, et al. Compressing sentence representation for semantic retrieval via homomorphic projective distillation // Findings of ACL. Dublin, 2022: 774–781
[7] Zhang M, Geng G, Chen J. Semi-supervised bidirec-tional long short-term memory and conditional random fields model for named-entity recognition using em-beddings from language models representations. Entro-py, 2020, 22(2): 252–271
[8] 赵山, 罗睿, 蔡志平. 中文命名实体识别综述. 计算机科学与探索, 2022, 16(2): 296–304
[9] 王颖洁, 张程烨, 白凤波, 等. 中文命名实体识别研究综述. 计算机科学与探索, 2023, 17(2): 324–341
[10] Zhu E, Li J. Boundary smoothing for named entity re-cognition // Proceedings of ACL. Dublin, 2022: 7096–7108
[11] Guo C, Pleiss G, Sun Y, et al. On calibration of mo-dern neural networks // International Conference on Machine Learning. Amsterdam: PMLR, 2017: 1321–1330
[12] 杨云, 宋清漪, 云馨雨, 等. 基于BiLSTM-CRF的玻璃文物知识点抽取研究. 陕西科技大学学报, 2022, 40(3): 179–184
[13] 巩一璞, 王小伟, 王济民, 等. 命名实体识别技术在“数字敦煌”中的应用研究. 敦煌研究, 2022(2): 149–158
[14] 李文亮. 基于深度学习的历史文物知识图谱构建方法研究与应用[D]. 太原: 中北大学, 2022
[15] 冯强. 文物藏品知识图谱构建技术研究[D]. 西安: 西北大学, 2022
[16] Yu J, Bohnet B, Poesio M. Named entity recognition as dependency parsing // Proceedings of ACL. Seattle, 2020: 6470–6476
[17] Li X, Feng J, Meng Y, et al. A unified MRC framework for named entity recognition // Proceedings of ACL. Seattle, 2020: 5849–5859
[18] Shen Y, Wang X, Tan Z, et al. Parallel instance query network for named entity recognition // Proceedings of ACL. Dublin, 2022: 947–961
[19] Mengge X, Yu B, Zhang Z, et al. Coarse-to-fine pre-training for named entity recognition // Proceedings of EMNLP. Online Meeting, 2020: 6345–6354
[20] Fu J, Huang X J, Liu P. SpanNER: named entity re-/ recognition as span prediction // Proceedings of ACL. Bangkok, 2021: 7183–7195
[21] Zhuang L, Wayne L, Ya S, et al. A robustly optimized BERT pre-training approach with post-training // Pro-ceedings of the 20th Chinese National Conference on Computational Linguistics. Huhhot, 2021: 1218–1227
[22] Du X, Cardie C. Event extraction by answering (al-most) natural questions // Proceedings of EMNLP. Online Meeting, 2020: 671–683
[23] Wei Z, Su J, Wang Y, et al. A novel cascade binary tagging framework for relational triple extraction // Proceedings of ACL. Seattle, 2020: 1476–1488
[24] Yang S, Feng D, Qiao L, et al. Exploring pre-trained language models for event extraction and generation // Proceedings of ACL. Florence, 2019: 5284–5294
[25] Baca M, Harpring P. Categories for the description of works of art. New York: Art Association, 2017
[26] Meng Y, Wu W, Wang F, et al. Glyce: glyph-vectors for chinese character representations // Advances in Neu-ral Information Processing Systems. Piscataway, 2019: 2746–2757
[27] Kingma D, Ba J. Adam: a method for stochastic optimi-zation. Computer Science, 2014, doi: 10.48550/arXiv. 1412.6980
[28] Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language under-standing // Proceedings of NAACL. Minneapolis, 2019: 4171–4186
A Low-Resource Named Entity Recognition Method for Cultural Heritage Field Incorporating Knowledge Fusion
LI Chao, HOU Xia†, QIAO Xiuming
Computer School, Beijing Information Science & Technology University, Beijing 100192; † Corresponding author, E-mail: houxia@bistu.edu.cn
In cultural heritage field, entity nesting of cultural relics data is obvious, the entity boundary is not unique, and the marked data in the field of cultural relics is extremely lacking. All the problems above can lead to the low recognition performance of named entities in the field of cultural relics. To address these issues, we construct a dataset called FewRlicsData for NER in the field of cultural heritage and propose a knowledge-enhanced, low-resource NER method RelicsNER. This method integrates the semantic knowledge of category description information into the cultural relics text, employs the span-based method to decode and solve the entity nesting problem, and uses the boundary smoothing method to alleviate the overconfidence problem of span recognition model. Compared with the baseline model, the proposed method achieves higher F1 scores on the FewRlicsData dataset and demonstrates good performance in named entity recognition tasks in the cultural heritage field. Experimental results on the public dataset OntoNotes 4.0 indicate that the proposed method has good generalization ability. Additionally, small-scale data experiments on OntoNotes 4.0 and MSRA datasets show that the performance of the proposed method surpasses that of the baseline model, demonstrating its applicability in low-resource scenarios.
cultural heritage field; named entity recognition; knowledge fusion; attention mechanism
