PCP-tuning:面向小样本学习的个性化连续提示调优*
2024-01-30刘汀蔡少填陈小军章秦
刘汀,蔡少填,陈小军,章秦
(深圳大学计算机科学与技术系,广东 深圳 518071)
0 引言
大量研究表明,基于循环网络和注意力模块的模型对序列型数据可以学习到很好的表达,且在基准测试中能取得优异的结果:艾山和曾蓉等使用LSTM进行专有领域的情感分类任务[1]和交通流预测[2];谭勋和亚力青等在模型语义表达层面进行下游语义相似度分析[3]和文本过滤[4];Raffel等提出超大数据量进行预训练的T5模型[5].然而,现有的基于预训练语言模型的学习方法大多遵循先预训练再微调的范式,其中预训练和微调都需要使用大规模的标注训练数据集,会消耗大量的人力和计算资源.因此,使用有限的训练数据进行学习的少样本学习已经引起了越来越多的关注,如无监督学习、少样本学习和知识图谱[6].
在少样本学习设置下,提示学习将下游任务视为缺失词语重组语言建模问题,通过预训练语言模型(PLMs)完成完形填空任务达到语言模型获得语义知识的目的[7],引起了研究者的强烈兴趣.例如,GPT-3就表现出令人印象深刻的少样本学习能力,仅使用16个标记样本就实现了80%的SOTA结果[8].
“提示学习”的关键问题是如何构建合适的提示语(prompt).早期的工作使用人工设定的提示来提取语言模型中的相关知识[9],然而想要写出一个有效的提示是十分困难的.随后,研究人员提出自动搜索提示的方法以提高提示设计的效率,并获得了广泛关注.一些研究通过将提示搜索问题重新定义为预测任务来搜索离散空间(词汇表中的单词)[10],主要分为梯度信息引导[11]和外部大模型知识融入[12],除此之外,还能进一步将逻辑规则[13]或知识图谱[14]纳入学习过程.最近的研究也有转向学习连续提示嵌入的趋势[15],这是因为与在离散的词库中寻找提示相比,在连续的词表达空间中学习提示更适合神经网络处理.
现有的提示学习方法通常对所有样本应用统一的提示,其中存在一个潜在的粗略一致性假设,即所有样本都偏向使用相同的提示.然而,这种假设是有风险的.如图1所示的例子中,很难找到适用于任务中的所有样本的单一提示.虽然有研究人员提出集成来自多个提示的结果以获得更好的预测结果[16],但在实际任务中如何选取基准提示及如何集成都是需要考虑的复杂问题.
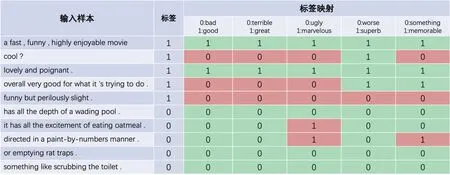
图1 5个离散型提示在SST-2中随机抽样的10个样本上的预测结果
基于上述发现,本文提出了一种用于小样本学习的个性化连续型提示调优方法(PCP-tuning),其目的是根据数据集中每个样本的语义来生成个性化的连续型提示.该方法通过考虑每个样本的语义特征来训练一个叫提示生成器的网络以生成个性化提示,采用分布校准和多样性校准对生成的提示做进一步调整.
本文的主要贡献包括3个方面:1)针对任务中每个特定样本的提示,提出了弱一致性假设,减少了以往统一任务级提示的粗略一致性假设;2)提出了两种校准技术来控制生成的样本提示的分布,多样性校准迫使提示在单个样本上是多样化的,分布校准迫使提示表达近似于高斯分布,以更好地模拟提示的弱一致性,这两种技术都为快速校准提供了一个有趣的研究方向;3)在10个公共benchmark上进行的详细实验表明,新方法几乎在所有任务上都优于现有方法.
1 相关工作
1.1 语言模型提示
最近,GPT-3[8]等大规模PLMs的出现证明了通过任务级提示进行少样本学习的巨大潜力.LM-BFF[12]进一步将GPT-3中的提示学习方法应用于中等大小的语言模型,并在广泛的NLP任务中实现了与大型GPT-3模型相当的性能.
早期的提示学习工作通常使用人工设计提示来提取语言模型中的相关知识[10].为了提高提示设计的效率,自动搜索提示方法得到了广泛的探索.Schick等将提示学习问题重新表述为解决完形填空式问题[9],进一步将潜在的NLP任务重新表述为蕴涵任务[10].Shin等建议将下游任务重新表述为预测任务,这可以通过基于梯度搜索来获得最优解[11].Han等将逻辑规则纳入提示学习[13],而Hu等将知识图谱纳入提示学习[14].Gao等利用T5模型自动生成提示[12].然而,上述方法都是在离散空间(词汇表中的单词)中搜索提示,由于提示表达空间的连续性,这样只能搜索到次优的提示.
为了克服上述限制,最近的研究开始学习连续型提示表达,这更适合神经网络.Liu等使用LSTM学习连续提示嵌入[16].Zhong等将提示调优结合进事实探测任务中[15].Liu等提出P-Tuning来自动搜索连续的提示嵌入,以弥补GPT在NLU任务中的缺陷[16].Li等提出了Prefix-tuning[17],可以应用于NLG任务.Lester等简化了Prefixtuning方法[18],且证明了微调的性能随着模型大小的增长而下降.Gu等在正式进行提示微调前先对提示表达进行预训练以获得更好的初始提示[19].Zhong等提出将下游自然语言处理任务融合进语言模型的预训练任务中,发现集成多个提示的预测结果可以获得更好的性能[15].但是上述方法通常对所有样本应用同一个提示,这样会忽略不同样本之间存在的语义特征差别.虽然可以为一个数据集生成多个提示最终集成来自多个提示的结果以获得更好的性能,但提示挑选和集成方法的选择是一项复杂的工作.本文提出了一种资源节约又简单高效的方法,根据样本的语义特征生成特定于样本的提示.
1.2 少样本学习
少样本学习的主要目标是使用少量的训练样本来达到语言模型到下游任务的迁移.常用的少样本学习方法包括:1)半监督学习,它利用了标记[7]和未标记的示例[20];2)元学习,这是一种通用的学习范式,在训练中不断为模型提供新的任务场景[21]、新的类别[22]或者新的数据分布[23]进行训练.这些方法可以与提示学习结合使用,以获得更好的性能.
2 问题定义
2.1 少样本训练定义
给定一个已经过预训练的语言模型LM,一个有标签且标签空间为Y的数据集Dtrain=,其中Ktotal=K×|Y|(K通常很小),即Dtrain中每个类包含K个训练样本.小样本学习目的是在数量少的训练集Dtrain上学习到能够很好地推广到测试集的模型参数.同时需要一个与训练集大小相同的开发集Ddev来实现模型和超参数的选择,即|Ddev|=|Dtrain|.
2.2 任务级连续型提示学习定义
任务级样本连续型提示学习是目前常用的学习范式.给定一个输入xin={x1,x2,···,xL},其中:xi是输入文本样本的第i个词元(token),L是词元的总数.首先,将xin转换为词元id序列˜x,再使用语言模型LM将˜x映射到词元表达在任务级连续型提示学习中,会有一个统一应用于所有样本的提示T.用于将输入xin转化为xprompt,xprompt是带有[MASK]标记的输入.然后将xprompt输入到语言模型中对[MASK]进行填空.xprompt通常定义为
在输入为句子对的任务中,假设xin=(xi,xj)是输入句子对,那么xprompt通常定义为
提示T 可以表示为T={v1:j,[MASK],vj+1:k},其中:vi是提示的第i个词元,k是提示的长度.因为LM是采用遮蔽词语重组进行语言建模的语言模型(masked language modeling),所以提示中会包含一个[MASK]词元.用V来表示LM的词列表,并以M:Y →V成为从任务标签空间Y到语言模型单词表空间V的映射.然后原任务可以看作语言模型对于输入xprompt在y∈Y标签空间的分类问题,即
其中:wv表示词表v∈V对应的pre-softmax向量,h[MASK]对应的是xprompt输入[MASK]标记处的隐藏向量.最后通过最小化交叉熵损失来对LM进行微调.
2.3 特性化连续型提示学习定义
本文提出了一种新的学习范式,即个性化连续型提示学习,它为每个样本学习个性化的提示.如在单句类型任务中,将原输入样本xin通过加入提示重构为新的输入xprompt
其中T(xin)是给定输入xin得到的个性化提示.
相应的,在句子对类型任务中,将xin=(xi,xj)用以下格式重构为xprompt
接着通过最小化公式(3)中的预测概率p(y|xin)与真实样本之间的交叉熵损失来微调语言模型.
3 个性化连续型提示调优
现有的提示学习方法通常对任务内所有样本应用统一的提示,其中存在潜在的粗略一致性假设:所有样本可以共享相同的提示.然而,由图1可知,这种假设是有风险的.因此,本文尝试根据每个样本的语义信息来学习一个个性化的提示,提出了如图2所示的个性化连续型提示学习框架来训练一个个性化连续型提示生成器.同时,本文进一步提出了两种校准技术来调整提示生成器的输出:1)多样性校准迫使提示在样本之间多样化;2)分布校准强制提示的分布近似于特定分布,以便更好地模拟提示的一致性.接下来,将详细介绍提示生成器和两个校准模块.最后,将给出训练目标的公式定义.
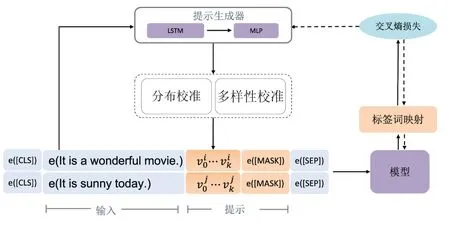
图2 本文提出的PCP-tuning框架
3.1 提示生成器
个性化连续型提示学习的基本步骤在2.3节中已定义.本文设计了一个用θ参数化的个性化提示生成器网络PG(.;θ),其将为每个输入xin生成它对应的个性化提示PG(xin;θ).则xprompt可表示为
对应句子对类型的输入xin=(xi,xj)则为
基于Liu等的研究[16],提示内每个向量不应该相互独立,所以本文选择双向长短期记忆网络(LSTM),结合使用了ReLU激活的两层多层感知器(MLP)来作为提示生成器的架构.
3.2 多样性校准
受到对比学习的启发[24-25],本文将对比学习应用于多样性校准模块中.与以往方法仅对模型输出进行对比损失计算不同[26],本文引入对比损失,旨在使不同样本所对应的提示之间呈现多样性.具体而言,给定一个输入xin,多样性校准的损失Ld(xin)定义为
其中:s(·)是余弦相似度函数,用于计算两个提示表达之间的相似度,τ是对比学习的温度控制系数.是通过往返翻译(英文-中文-英文)xin得到的增强样本.,B是训练中每批的训练样本集合,B+则是B对应的所有增强样本.
3.3 分布校准
为了防止提示分布过于无序,提出了分布校准模块,以强制提示分布近似于特定的分布,从而更好地对提示的一致性进行建模.使用高斯分布作为目标分布,也可以考虑其它分布,如长尾分布.分布校准策略分为两种:1)预校准使用精心选择的离散提示对提示生成器进行预训练;2)后校准对提示发生器输出的提示进行校准.两种策略的详细步骤如下.
预校准.此策略在开始正式训练前,先使用一个优秀的离散提示Tt预训练提示生成器PG(.;θ).给定输入样本xin∈Dtrain,预训练通过最小化以下损失进行θ的优化
其中h(Tt)是离散提示Tt相应的表达张量.预训练后的提示生成器将生成近似服从于高斯分布(h(Tt),σ2)的提示,方差σ2反映了生成提示的多样性.
预校准在整个少样本学习过程正式开始之前进行.因此,也可以将其视为提示生成器的热身步骤.在此策略中,选择合适的目标提示Tt非常重要.本文使用的Tt来自于LM-BFF[17]中生成的提示.
后校准.该策略的做法是引入额外的离散提示来对提示生成器的输出进行后处理,让输出近似于高斯分布.假设有一个优秀的离散提示Tt,便可以通过以下公式获得校准后的提示Tc=h(Tt)+λPG(x;θ),其中λ是控制离散提示表达张量和提示生成器输出的提示之间的混合程度.Tc近似服从于高斯分布N(h(Tt),λσ2),高斯分布的方差项σ2由提示生成器的输出来控制.
与预校准类似,选择合适的离散提示Tt在此策略中也很重要.本文提出了两种简单有效的方法来解决这个问题:1)精心设计好的离散提示;2)由简单词汇随机组合成的离散提示.虽然选择设计好的离散提示是合理的,并且还有性能保证,但对于全新的任务,设计好的离散提示就没那么容易获得.所以本文提出了另一种简单有效的方法,只需在多个常用单词或符号(如“the”“a”“.”等)随机排列组合成的序列中随机位置插入[MASK]词元便可作为离散提示使用,且可以在句子分类任务中获得与精心设计好的离散提示相当的性能.
3.4 训练目标
给定一个输入xin,提示生成器的损失函数为
其中CE为交叉熵损失.
结合了多样性损失函数后,整个xin的损失函数为
其中β是超参数.
最后,对语言模型LM(.;W)和PG(.;θ)进行微调
4 实验
4.1 实验设置
场景任务.本文对GLUE[27]的10个公共基准任务进行了全面评估,包括单句分类任务:SST-2,MR,CR[28],Subj,TREC[29],MPQA[30];句子对类型分类任务:MNLI,SNLI,QNLI,MRPC.这些任务都与对比算法P-Tuning V1[16]保持一致,以便可以对结果进行公平合理的比较.
基线(baselines).分为三种类型:1)无提示,在少样本或者全样本的环境设置下,直接微调更新整个语言模型的所有参数;2)人工提示,使用一个固定的人工提示来协助语言模型微调,与GPT-3中的零样本学习、上下文情景学习一致;3)可学习提示,LM-BFF[12]是一种经典的离散提示学习方法.P-Tuning V1[16]和DART则是连续型提示学习的代表.
评估指标(metrics).本文根据准确性(Acc)和F1指数来评估模型的性能.
实现环境细节.基于Intel(R)Xeon(R)Platinum 8255C CPU和Nvidia V100 GPU.代码在PyTorch[31]上实现.实验的基本设置与LM-BFF[12]和DART相同.模型性能表现评估方面,对于每个任务,使用了5个固定的随机种子Sseed={13,21,42,87,100}分别进行实验,最终表现取5个精度的平均值.并使用RoBERTa-large作为基座语言模型.
4.2 主要结果
表1展示了PCP-tuning的下游任务分类结果以及同任务下相关对比算法的实验结果.PCP-tuning在除MPQA之外的所有任务上都优于其它方法.与排名第二的结果相比,新方法在Subj和TREC任务上获得了2.1%的性能提升,在QNLI任务上提升了6.1%,在MRPC任务上提升了3.1%.这证明了个性化提示学习针对少样本学习问题的有效性.实验发现新方法在MPQA任务上表现不佳,通过分析发现该任务中样本输入的句子非常短(每条输入长度小于5个词汇),这极大程度阻碍了需要从输入中提取语义信息的提示生成器训练.然而,与使用T5模型作为提示生成器的LM-BFF相比,新方法引入的提示生成器是非常轻量级的,极大程度节省了计算成本.

表1 PCP-tuning在10个基准任务上的结果
4.3 消融实验
表2展示本方法的消融实验结果.表中方法缩写对照如下:D为多样性校准(Diversity calibration),WR为预校准(Well-designed prompt for pRe-calibration,高质量离散提示),WO为后校准(Well-designed prompt for pOst-calibration,高质量离散提示),SO为后校准(Simple-words prompt for pOst-calibration,简单词汇随机排列离散提示).可以看到,引入校准模块确实可以提高性能.在CR、QNLI和MRPC任务上使用D+WR的组合为最优解,在SST-2和MR任务上D+WO表现最佳.由此推测,D+WR可能更适合单句类型任务,而D+WO可能更适合句子对类型任务.虽然D+SO没有优于其它策略,但它在大多数任务上都能产生相当的结果.考虑到其简单又节省计算成本的特性,它将是成本敏感型任务的不错选择.

表2 在SST-2、MR、CR、QNLI和MRPC任务上的消融实验结果
4.4 超参数分析与可视化
本文进行了一系列实验来进行超参数的选择和生成提示分布的可视化.
提示长度.设置为pl={1,3,5,10},并在表3中展示不同长度的提示在两个任务上的结果.由表3可知,提示太长会导致性能下降.SST-2任务使用长度为3的提示最佳,MR任务最佳则为1,这表明不同的任务提示长度设置需要额外考虑.

表3 不同提示长度的实验结果
超参数λ和β灵敏度分析.新方法引入了超参数λ控制预校准中离散提示和生成连续提示的混合程度,而超参数β则权衡下游任务的有监督损失和多样性校准模块损失.如图3所示,过大或过小的λ和β都会导致模型性能的下降,最优的超参数设置是λ=1、β=10.

图3 超参数λ和β不同取值时在QNLI任务上对应的精度曲线
类样本个数K.表4展示了使用不同类样本个数K的小样本数据集对模型性能的影响.可知在所有方法上随着K的增大,模型性能会提高,并且新方法在所有K设置下都优于其它方法.

表4 K取值为8、16、32时在Subj、QNLI、MRPC任务上的结果
提示分布可视化.为了展示训练优化不同阶段PCP-tuning方法生成的连续提示分布的演变,本文使用提示生成器结合后校准与多样性校准,在QNLI数据集上进行了提示微调.图4为训练步推进生成的提示降维可视化分布.优化前的提示分布呈U形,通过分析这是由BiLSTM网络的特定结构引起的.随着训练的进行,分布趋近于高斯分布.此外还形成了许多局部密集的簇,这也证明提示分布具有局部相似性.

图4 生成的提示分布随着训练推进的变化
4.5 示例和提示之间的一致性分析
为了研究提示表达和输入表达之间的一致性,本文设计了一致性指标C
其中:SI(xiin,xjin)是两个输入xiin和xjin之间的余弦相似度(xiin是第i个输入标记),而SP(xiin,xjin)是提示生成器为样本xiin和xjin生成的两个提示表达之间的余弦相似度,如图5所示,随着下游任务的有监督训练推进,一致性指标C增加,且损失函数值相应减小,这表明相似的样本使用相似的提示将会获得更好的性能.这将为未来提示学习工作提供重要的参考.

图5 C和损失值变化曲线
5 总结
本文提出了一种新颖的个性化连续型提示学习方法(PCP-tuning),用于少样本学习任务.PCP-tuning通过优化一个轻量级提示生成器来学习生成适应各个样本的提示.为了更好地控制生成的提示分布,提出了两种提示校准策略:多样性校准使针对不同样本的提示表达具有多样化,分布校准则让提示表达近似服从于高斯分布以更好地模拟生成的提示之间的一致性.大量的实验结果验证了新方法的有效性.
本文提出的PCP-tuning方法在分布校准模块需要使用额外的离散提示来协助提示生成器的训练,未来将研究新的提示生成器,在不依赖离散提示的前提下直接生成个性化提示.
