麻雀搜索算法优化的RF-BILSTM短期电力负荷预测
2024-01-29蔡志豪史洪岩
蔡志豪,史洪岩
(沈阳化工大学 信息工程学院,沈阳 110142)
电力负荷预测是基于系统自身属性与天气、季节等外在因素,按照以往负荷数据规律对日后趋势进行预测分析,是电力部门部署筹备的根本。优良的预测模型可以有效维持电网的安全运转,有助于制定科学的电力方案,避免能源虚耗。电力负荷预测按时间分类可以分为短期、中期、长期、超短期预测[1]。其中,短期预测时间一般为一天到一周。
关于电力负荷预测方法众多,通常分为以下两种:经典预测法(如时间序列法[2-3])和人工智能预测法。人工智能预测法的核心是机器学习技术,其对非线性以及多因素影响下的负荷数据拟合能力更好,学习能力更强,因此,被国内外学者广泛应用。文献[4]利用最小二乘支持向量机(LSSVM)对电力负荷进行预测,并采用粒子群算法(PSO)对其进行优化,预测效果得到明显提升。文献[5]采用模糊聚类与随机森林算法(RF)相结合的预测模型,对负荷数据聚类后输入到随机森林中进行训练,再将预测结果进行修正,最终成功提高了预测精度。文献[6]将改进后的果蝇优化算法(FOA)用来搜索BP神经网络的最优初始权重和阈值,在加快收敛速度的同时提高了预测精度。随着互联网与计算机技术的发展,深度学习逐渐被广泛应用在负荷预测领域中。文献[7]提出卷积神经网络(CNN)与长短期记忆神经网络(LSTM)相结合的模型,充分利用CNN提取数据特征能力与LSTM处理时间序列数据能力。文献[8]通过主成分分析(PCA)对原始数据进行压缩,然后利用循环神经网络(RNN)进行预测,使得模型具有较低的复杂度。文献[9]提出使用随机森林算法筛选特征,将排除冗余因素后的其余关联特征输入到门控循环单元(GRU)进行训练,降低了模型计算时间。
根据上述研究,为了进一步提高电力负荷预测的精度,通过RF算法对电力负荷数据与负荷影响因素进行相关性研究,从而筛选出相关性较高的影响特征,缩短模型训练时间。采用双向长短期记忆神经网络(BILSTM)进行预测,考虑正向以及反向的负荷数据信息。同时,BILSTM超参数利用麻雀搜索算法(SSA)进行寻优取值。最后,根据对真实数据的预测结果对比,证明了所提方法是有效可行的。
1 基本原理
1.1 随机森林算法
随机森林是对bagging算法进行改良后的集成算法,顾名思义,“随机”体现在两个方面:一是利用bootstrap思想从数据集中有放回的随机抽取数据[10],即数据随机。二是对所有的样本特征随机抽取部分特征,即特征随机。“森林”意为由多个决策树构成,其中,每棵决策树对应一组由原始数据样本随机抽取出的训练样本。随机森林有着预测准确率较高、模型简单且不易陷入过拟合等优点。
随机森林的实现步骤如下:
1)假设样本数量为M,有放回的抽取m个数据作为一颗决策树的训练样本。
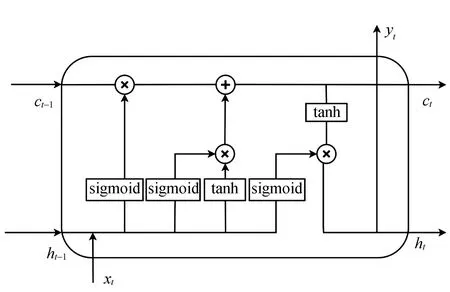
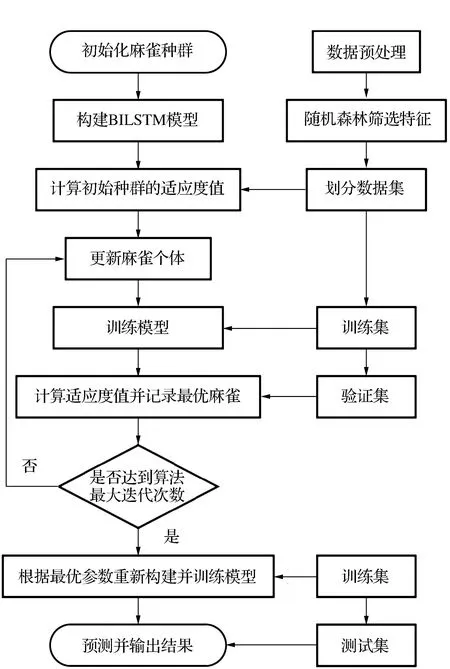
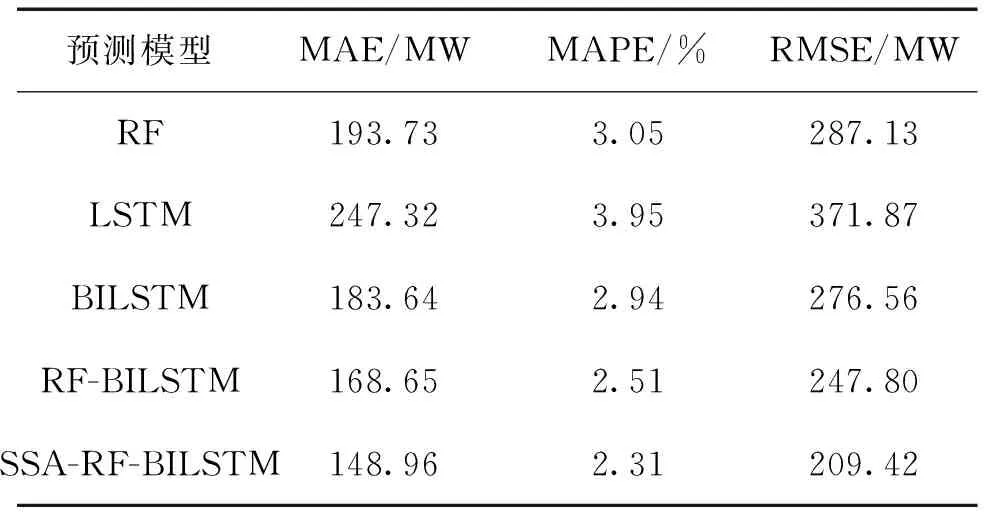
2)对于训练样本的所有特征N,随机选择n(n 3)对于回归问题基于方差最小化准则在n个特征中选出最优特征进行分裂,如式(1)所示。分类问题则采用基尼系数进行分裂。 (1) 式中:A,s分别为分裂特征以及对应的分裂点;R1和R2为划分的样本集;c1,c2为R1,R2的输出均值。 4)决策树的每个节点按照步骤3)进行分裂,直至达到分裂限度时停止分裂。 5)生成多棵决策树,回归问题根据所有决策树的输出平均值作为随机森林的最终输出,分类问题则通过决策树投票确定最终输出类别。 此外,随机森林还有特征选择的功能,其原理是基于不纯度(基尼系数或方差)变化量[11],即分别计算出数据样本中每个特征在决策树节点分裂前后的不纯度减小量,对其进行比较,从而得到特征重要性排序,根据重要性排除相关性较低的特征,有利于降低模型输入维度,提高模型效率。 麻雀搜索算法是近两年提出的新兴群智能优化算法,具备算法原理简单、收敛速度快等优势[12]。该算法基于麻雀种群的社会行为将麻雀个体分为发现者、加入者以及警戒者,发现者能力较强可以找到食物并为同类指明方向,公式为 (2) 式中:t和T分别为算法当前以及最大更新次数;α为随机数,其取值范围为[0,1];Q同样为随机数,但服从正态分布;L为所有元素都是1的行矩阵,其列数由待求解问题维度确定;R2为大于0小于1的预警值;ST为大于0.5小于1的安全值。 加入者则通过观察发现者的食物来源以便取而代之,公式为 (3) 警戒者需要时刻留意当前环境,以便发现危险立即飞往安全环境。位置更新公式为 (4) RNN相较于其他神经网络更擅长处理序列数据[13],原因在于序列数据并不是独立存在的,其前后具有关联性,RNN中的隐藏状态可以保留历史信息,根据当前输入并结合历史输入共同确定输出,但针对长序列数据的处理仍然具有一定的困难,即长期依赖问题[14]。LSTM是RNN基于此类问题进行改进的神经网络,如图1所示,其内部的记忆单元状态与特殊的门结构对输入信息有选择地进行记忆,从而可以长期保留历史输入信息。 图1 LSTM单元结构 LSTM的核心是记忆单元状态Ct,用来记忆与传递信息,通过遗忘门、输入门、输出门控制记忆单元状态更新以及输出。遗忘门通过上一时刻的输出ht-1与此刻的输入xt控制Ct-1中信息的记忆及遗忘,公式为 ft=σ(Wf·[ht-1,xt]+bf). (5) it=σ(Wi·[ht-1,xt]+bi), (6) (7) 根据遗忘门以及输入门的操作对记忆单元状态Ct进行更新,公式为 (8) 最后,输出门基于更新后的Ct决定最终输出,公式为 ot=σ(Wo·[ht-1,xt]+bo), (9) ht=ot*tanh(Ct). (10) 式中:W和b分别为各自对应的权重与偏置。 LSTM按照序列数据先后顺序进行输入,只考虑了数据的正向特征,而双向LSTM在单向LSTM的基础上增添了一个反向的LSTM,序列数据分别以正向和逆向同时输入,基于两个神经网络的输出构成最终输出[15]。相较于单向LSTM,BILSTM通过对数据正反方向的学习,提高了神经网络的学习效率,使得模型具有更好的预测效果[16-17]。 针对电力负荷预测提出麻雀算法优化的RF-BILSTM模型,将经过RF算法过滤后的负荷数据输入到BILSTM中,通过SSA对神经网络的超参数批量大小、学习率、时间窗进行寻优取值,流程如图2所示。 图2 模型流程 麻雀算法优化的RF-BILSTM模型具体步骤如下: 1)将负荷数据以及影响因素预处理,运用RF算法对温度、湿度、季节等外部因素进行特征选择,将选择后的特征与负荷数据结合构成数据集,并划分为训练集、验证集、测试集。 2)选取SSA参数,基于学习率、批量大小、时间窗初始化麻雀种群,将训练集输入到BILSTM中进行训练。 3)构建算法适应度函数 (11) 式中:n为验证集样本总数;yi与y′i分别为验证集数据的真实值、预测值。 4)根据麻雀个体适应度划分种群,并按式(2)~(4)进行位置更新。 5)计算更新后个体的适应度并记录最优值及其对应位置。 6)算法达到最大迭代次数输出最优超参数,重新构建BILSTM进行训练。 7)将测试集输入到训练好的模型中进行预测。 对于预测模型的评估主要是基于真实值和预测值之间的误差,因此,选取均方根误差(RMSE)、平均绝对误差(MAE)、平均绝对百分比误差(MAPE)作为评价指标对模型优劣进行评估,公式为 (12) (13) (14) 式中:n为测试集样本总数;yi与y′i分别为测试集实际值与模型预测值。由公式可知,评价指标越大,模型预测效果越差。 选择某地区的电力负荷数据作为文中实验的数据集,数据集中除了历史数据还包括自2012年到2015-01-10的每日天气及日期等10种影响因素,具体如表1所示,选取2012年至2014-11-30为训练集,2014年12月为验证集,对数据集最后10 d进行预测。 表1 影响因素 为了方便构造模型输入,需要对文字类特征量化处理,将星期类型、节假日中的“是”量化为1,“否”量化为0,对季节因素中的4个类别分别量化为1、2、3、4。此外,数据还需要进行归一化处理,一方面可以使各个特征处于同一数量级内,便于分析。另一方面,将数据缩放到[0,1]区间内,有利于提高模型计算速度。归一化公式为 (15) 式中:x为原始数据;xmax与xmin分别为对应的最大值、最小值。 3.2.1 特征选择 利用RF算法对表1中10个影响因素进行重要性排序,筛选出重要特征,并与历史负荷数据结合作为BILSTM的输入,构建随机森林中决策树的数量为200,10个影响因素重要性排序如图3所示。 图3 特征重要性 根据图3删除重要性较低的因素,保留前6个重要特征,即选择平均温度、最低温度、月份、最高温度、相对湿度、星期作为模型最终的输入特征。 3.2.2 参数选择 负荷数据集的采集间隔为15 min,将每日产生的96个负荷值与RF算法选择的6个特征作为模型输入,预测下一日的96个负荷,即输入为102,输出为96。麻雀算法优化的RF-BILSTM模型参数设置如下:隐藏层数为2,隐藏层神经元数量均为180,为了提高SSA寻优速度先将模型训练次数设置为100。学习率、时间窗、批量大小由SSA寻优得出,SSA中种群规模为15,算法迭代次数为10,对应的参数范围分别为[0.001,0.01]、[1,7]、[64,256],寻优过程如图4所示。 图4 适应度曲线 经SSA寻优后确定学习率为0.001,时间窗为6,批量大小为66。最后将模型训练次数提高到950次。 3.2.3 性能对比与误差分析 利用上述参数完成模型搭建后,为了更好地验证麻雀算法优化的RF-BILSTM模型(SSA-RF-BILSTM)预测精度,采用RF模型、LSTM模型、BILSTM模型、RF-BILSTM模型分别进行负荷预测,5种模型对测试集以及测试集中最后一天的预测曲线如图5所示,误差评价指标如表2所示。 表2 模型评价指标 图5 模型预测曲线 由图5可知,RF模型、LSTM模型以及BILSTM模型能够大体预测出电力负荷的整体趋势,但在负荷峰值处与真实负荷数据相差较大,预测精度较低。RF-BILSTM模型预测效果在负荷峰值处有所提升,SSA-RF-BILSTM模型的预测曲线在所有模型中与实际数据曲线最为接近,能够有效推断出电力负荷的变化规律,具有良好的预测精度。 根据表2可以看出,在5种预测模型中,LSTM模型预测效果最差,BILSTM模型与之相比,MAE、RMSE分别降低了63.68 MW、95.31 MW,MAPE降低了1.01%,证明BILSTM模型预测效果优于LSTM模型。此外,BILSTM模型的3项误差评价指标均优于RF模型,但总体相差较小。而RF-BILSTM模型的3项指标与RF模型、BILSTM模型相比均得到了很大提升,说明通过RF排除负荷相关性较低特征后的BILSTM模型表现更好。在所有预测模型中,SSA-RF-BILSTM模型的MAE为148.96 MW,相较于其余4种模型降低了19.69~98.36 MW;MAPE为2.31%,降低了0.2%~1.64%;RMSE为209.42 MW,降低了38.38~162.45 MW。事实证明,经SSA寻优后的RF-BILSTM模型预测误差最小,预测精度最高,从而验证了文中提出模型的有效性。 为了提高短期电力负荷预测精度,提出了一种基于麻雀算法优化RF-BILSTM预测模型,通过对负荷数据的预测仿真以及多种模型对比,得出以下结论: 1)采用RF算法对电力负荷的众多影响因素进行排序,排除对电力负荷影响较弱的影响因素,保留重要特征作为模型输入,缩小了数据量,在降低模型复杂度的同时提高了模型预测速度。 2)采用BILSTM模型代替传统的LSTM模型,对负荷数据进行双向学习,很好地提取了数据的正反向特征,通过对MAE、MAPE、RMSE 3项误差指标的对比,证明了BILSTM模型相较于LSTM模型,预测误差得到了良好的改善。 3)采用SSA对BILSTM模型的部分超参数进行寻优求解,有效避免了人工选取超参数不确定问题。经过对实际负荷数据的预测证明,文中提出的SSA-RF-BILSTM模型与RF、LSTM、BILSTM以及RF-BILSTM模型相比,具有更好的预测性能。1.2 麻雀搜索算法
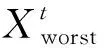
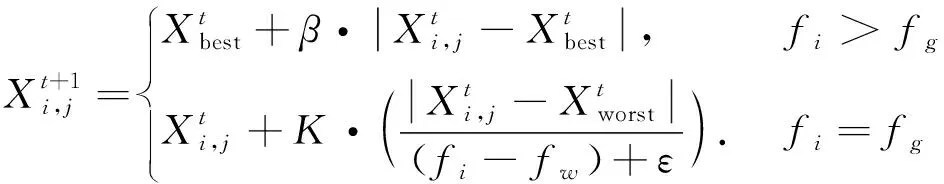

1.3 LSTM神经网络

2 SSA优化的RF-BILSTM模型
2.1 模型流程
2.2 模型评价指标
3 实验与结果
3.1 数据预处理

3.2 模型构建与预测



4 结 论
