基于多头自注意力机制和PANet的优化YOLOv5行人检测算法
2024-01-29宋子昂刘惠临
宋子昂,刘惠临
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
在计算机视觉领域,行人检测一直是一个重要且具有挑战性的问题.近年来,随着人工智能技术的飞速发展,行人检测在视频监控和无人驾驶、人群统计和智能交通等众多领域获得了越来越多的应用.现在行人检测技术日益成熟,但仍然存在进一步改进和发展的空间.例如,在实际场景下行人往往面临小范围多目标以及目标行人尺度小的问题.目前,基于深度学习的行人检测技术分为2大类:第一类是基于候选框的双阶段算法,其中以Faster R-CNN[1]为代表.这种算法模型检测精度较高,但由于其训练过程复杂且检测速度慢,导致双阶段算法难以满足实际应用.第二类是基于单阶段算法,以SSD[2]和YOLO为代表.与双阶段算法相比,这类算法采用端到端的训练方式,使其拥有更快的检测速度.通过这种简化的设计,单阶段算法在实际应用中能够更好地满足实时行人检测的需求.为了解决密集场景下行人检测准确率不高的问题,研究者们提出一系列方法和数据集.在数据集方面,ZHANG等[3]提出CityPersons数据集,ZHANG等[4]提出Wider Person数据集,这些数据集为后续的研究提供了丰富的数据支持.针对密集行人场景下的检测精度,WANG等[5]引入互斥损失函数(repulsion loss),该函数能够减少高度重叠的预测框对检测目标的干扰,提高了Faster R-CNN的检测精度.此外,PANG等[6]提出基于注意力掩码的算法,增强了对于遮挡部分的特征提取,从而达到较好的检测效果.此外,LIU等[7]提出一种采用动态阈值的非极大值抑制算法,通过密度子网预测每个位置的密度,并根据不同密度值为NMS设置适合的交并比(Intersection over Union,IoU)阈值.本文以单阶段检测算法YOLO系列中的YOLOv5作为基础模型进行改进,旨在解决以下问题:首先,针对密集场景下目标行人存在大量遮挡,导致行人部分特征丢失的问题,在其骨干网络末端嵌入融合了多头自注意力层(Multi-Head Self-Attention, MHSA)的BoTC3模块,加强了网络对目标行人的全局信息感知,同时采用更适合密集场景的Varifocal Loss[8]损失函数替换原有的Focal Loss损失.其次,针对目标行人尺度小的问题,改进了PANet结构,获取更细粒度信息的特征图.最后,比较所提算法与常用检测算法对于拥挤场景下行人检测的性能,证明所提算法的有效性.
1 YOLOv5算法概述
YOLOv5是当下主流的目标检测框架,它汲取了YOLOv1、YOLOv2、YOLOv3和YOLOv4 4种模型的优点并进行了整合,因此选择YOLOv5作为实验改进的基线模型.整体网络结构如图1所示.
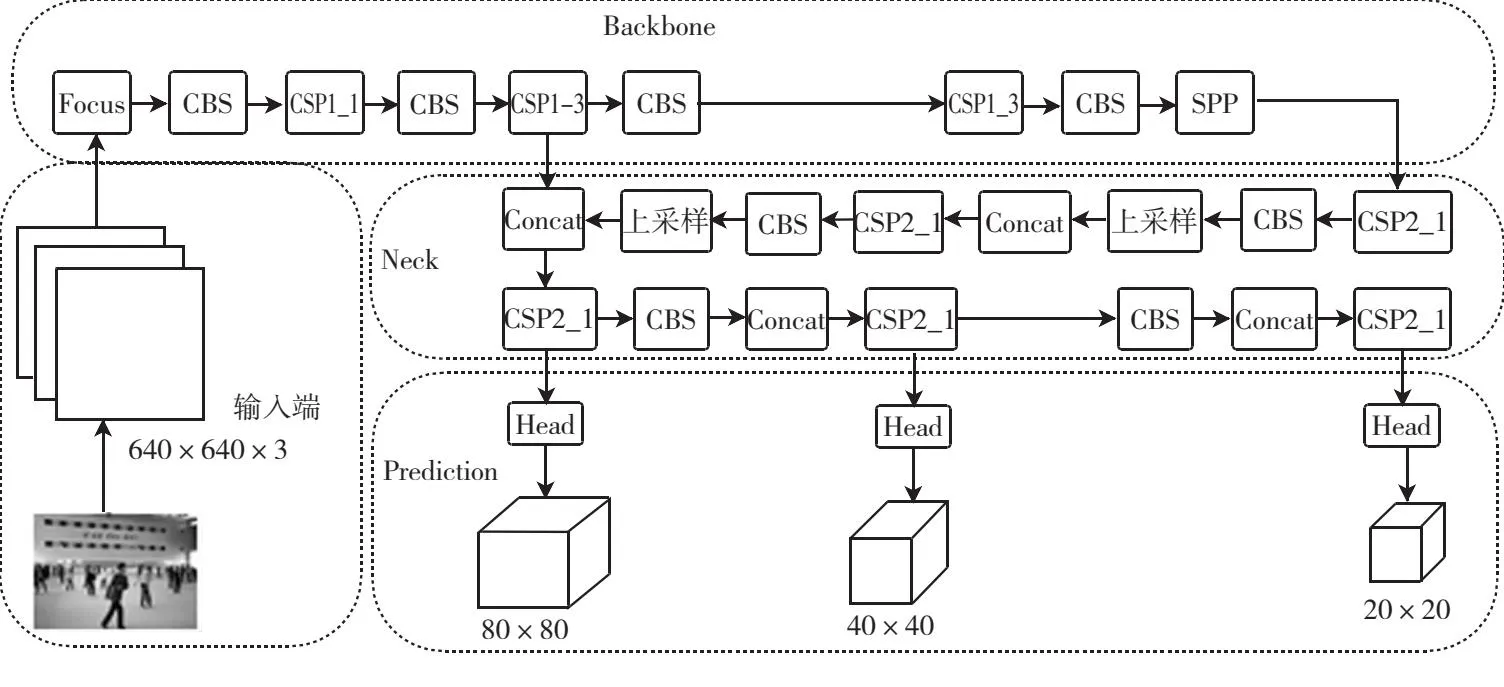
图1 YOLOv5网络结构
YOLOv5由输入端、骨干网络、颈部网络和头部网络组成.输入端采用Mosaic数据增强技术以提升模型的性能和泛化能力.Mosaic数据增强技术通过增加样本的多样性和复杂性,使模型能够更好地适应各种实际场景,增强了模型的鲁棒性.同时,拼接多张图片还有助于提高训练效率,减少数据加载和预处理时间.
YOLOv5的骨干特征网络由CSP-Darknet53组成.在YOLOv5的骨干网络中,主要是C3模块和CBS模块的堆栈.C3模块主要由n个瓶颈模块、多个CBS模块和2个大小为1 × 1的卷积层组成,旨在更好地提取图像的深层特征.C3模块和瓶颈模块分别如图2(a)和(b)所示.CBS模块指普通卷积层、BatchNorm 2d层和SiLU层的顺序连接,用于对输入特征图执行卷积、批量归一化和激活函数操作.CBS模块具体结构如图2(c)所示.

(a)C3 (b)Bottleneck
主干的最后一层是SPP模块.先使用第一CBS模块将输入图像的通道数减半,然后将第一CBS模块输出的特征图通过3个不同大小的最大池层(13×13、9×9和5×5),并将与第一CBS模块的输出一起构建的剩余边缘并行连接.最后通过第二CBS模块将通道数减半,保证不同大小输入的特征图在池化后高度和宽度都能保持一致,结构如图2(d)所示.
Neck部分受PANet[9]模型启发,在FPN[10]架构的基础上引入一种自下而上的增强途径,即FPN+PAN结构,旨在缩减信息传递距离.该途径利用底层特征中蕴含的精确定位信息,强化了特征金字塔结构.具体来源,FPN层自上而下传递高级语义特征,特征金字塔则自下而上传递准确的定位信号,通过在不同的主干层上进行参数汇聚,进一步增强了特征提取的效能.
2 YOLOv5算法改进
本文对YOLOv5的骨干网络、颈部网络和损失函数进行了相应的改进.首先,在骨干网络的最后一层使用基于多头自注意力机制的BoTC3模块替换原本的C3模块,以此提高检测精度.其次,基于目标行人多数为小尺度目标,在颈部网络中修改FPN+PAN结构,获得具有更细粒度信息的特征图.最后,使用Varifocal Loss损失替换Focal Loss损失,以此解决密集场景下检测性能不佳的问题.改进的YOLOv5网络结构如图3所示.

图3 改进后的YOLOv5网络结构
2.1 瓶颈变换器
瓶颈变换器(Bottleneck Transformer)是一种在计算机视觉领域中应用的注意力机制网络模块.它是对传统Transformer模型的改进和优化.传统的Transformer模型在处理图像数据时存在输入特征图的尺寸较大,导致计算和内存消耗较高的问题.为了解决这个问题,Bottleneck Transformer引入瓶颈结构(Bottleneck structure).瓶颈变换器首先通过一个降维卷积层将输入特征图的通道数降低,从而减少计算量.然后在降维后的特征图上采用经典的Transformer模块,包括自注意力机制和前馈神经网络.这些模块能够对特征图中不同位置之间的关系进行建模和学习.最后使用一个升维卷积层将特征图的维度恢复到原始大小.瓶颈变换器的优势在于通过降维和升维操作减少了计算和内存开销,同时保持较高的模型表达能力.这使它成为处理大尺寸图像数据的有效工具,特别适用于图像分类、目标检测和图像分割等计算机视觉任务.
YOLOv5的骨干网使用大量的卷积层捕获图像的局部信息,卷积层的堆叠提高了骨干网提取特征的性能,但也增加了模型参数的数量,降低了模型的推理速度.文献[11]用多头自注意算子代替残差卷积神经网络卷积算子,可以提高模型的识别精度,减少模型参数的数量.借鉴该方法,将YOLOv5骨干网络的C3模块替换为BOTC3模块.改进后的BoTC3如图4所示.由于多头自注意力是一种显式机制,用于对全局依赖项进行建模,因此将该模块嵌入骨干网络末端,使其更有效地处理和整合特征图中密集且微小的缺陷语义信息,并提高缺陷检测的准确率.
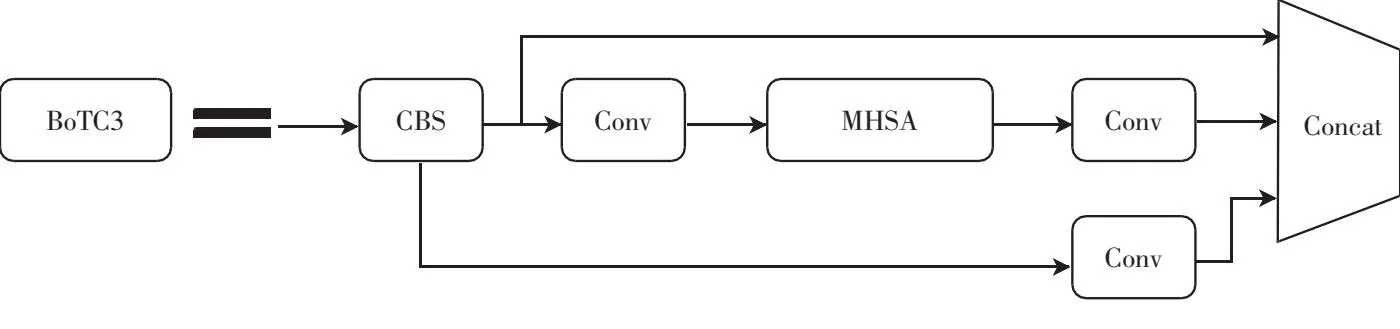
图4 改进后的BoTC3模块
多头自注意(Multi-Head Self- Attention,MSHA)将位置编码视为空间注意,在水平和垂直2个维度上嵌入2个可学习的空间注意向量,然后将空间向量求和融合到q中得到内容位置.对内容-位置和内容-内容进行求和,得到对空间敏感的相似特征,使 MHSA能够聚焦于合适的区域,使模型更容易收敛.图5中Rw和Rh分别对应宽度和高度的相对位置编码,其中q、k 、r和v分别表示查询、键、位置编码和值,qrT和qkT是注意力对数,WQ、Wk和Wv分别是用于查询向量、键向量和值向量的投影矩阵。在瓶颈变压器模块中引入 MHSA 层,利用全容进行求和,得到对空间敏感的相似特征,使 MHSA 能够聚焦于合适的区域,使模型更容易收敛.在瓶颈变压器模块中引入MHSA层,利用全局自注意对卷积捕获的特征映射中包含的信息进行处理和聚合[12],降低模型的参数,避免卷积神经网络参数叠加导致的模型膨胀,并在一定程度上提高了推理的准确性.MHSA结构如图5示.
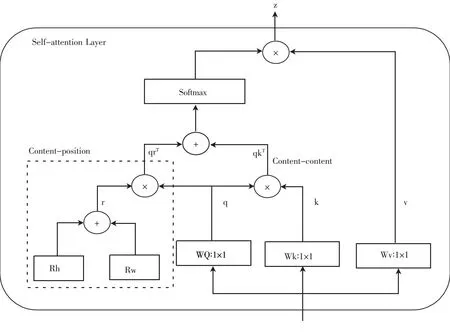
图5 MHSA结构
2.2 PANet网络的改进
在FPN[10]+ PAN结构的输出中,得到了20×20、40×40和80×80 3个不同大小的特征图.这些结构通过融合来自不同尺度的特征图,提供了多尺度的信息,有助于检测不同大小的目标.其中20 × 20和40 × 40的特征图被用于检测较大尺寸的目标,80×80的特征图被用于检测较小尺寸的目标.针对行人检测这一特定任务,较小的目标更为常见.因此,为了更好地适应行人检测任务并提高边界框回归的精度,舍弃20 × 20和40 × 40的特征图.通过丢弃这些特征图和针对大目标的识别帧,能够减少无用的计算操作,并且更集中地关注中小尺寸目标的检测.这种优化策略既提高了模型的效率,又保证了行人检测的准确性.
同时,为了获得更加细粒度的特征图,对PANet网络的连接方式进行改进.通过对骨干网络输出的2次上采样,并将其与相应尺寸的骨干网络特征图进行融合,得到新的160 × 160特征图.由于改进后的骨干网络生成了320 × 320、160 × 160、80 × 80 3层特征映射,所以不需要对FPN进行2次上采样.最终实验选择160 × 160和80 × 80的特征图作为探测头.PANet网络改进后的示意图见图6.

图6 YOLOv5中PANet网络改进结构图
2.3 损失函数的改进
YOLOv5模型在分类任务中采用了Focal Loss作为损失函数,旨在解决类别不平衡的问题.该损失函数通过为少数困难样本分配较大的权重,对多数简单样本的权重进行更多的衰减实现优化.Folcal Loss的计算定义如下:
(1)
其中,p为目标类的预测概率,范围为[-1,1];y为真实正负样本类别,取值1或-1;α是一个用于平衡正负类别权重的因子,其值在0~1;β是一个用于调整难以分类样本权重的因子,其值通常设定为一个正数,用于放大难以分类样本的损失;(1-p)β为前景类调制因子;pβ为背景类调制因子.
为了突出小范围多目标密集检测任务中正样本的贡献,将YOLOv5模型中的损失函数替换为Varifocal Loss.Varifocal Loss基于二元交叉熵损失,并继承了Focal Loss的加权处理策略,同时优化了密集目标训练中前景类和背景类极度不平衡的问题.Varifocal Loss能够更好地预测目标的存在置信度和定位精度,从而提升检测目标的性能.Varifocal Loss的计算定义如下:
(2)
在上述公式中,预测的IoU感知分类评分p用于衡量目标预测的准确性.对于正样本,该评分由预测框和真实框之间的交并比值q确定.而对于负样本,q的取值为0.调节因子α可以对负样本数量进行调节,并对负样本的评分p进行pβ衰减,以便更好地利用正样本的信息.此外,对正样本的加权考虑了交并比值q的影响.当正样本和真实框之间的交并比值较高时,正样本对损失函数的贡献将增加,从而使训练过程集中在高质量的正样本上.
通过以上机制,可以更好地优化分类损失函数,使其在正负样本的处理上更具针对性.这种方法充分利用了正样本的信息,同时通过调节负样本数量和考虑交并比值q的加权,使训练过程更加关注高质量的正样本.
3 实验及结果分析
3.1 数据集
WiderPerson数据集是一个户外行人检测数据集,包括常规行人、骑自行车的人、部分遮挡的人、假人和人群5种类别.根据本实验的需求,假人和人群这2种类别是不需要的,因此只将前3种类别合并为行人类别.合并后的数据集包含训练图片8000张、测试图片1000张.
3.2 实验策略及环境
实验代码基于YOLOv5进行改进.在本次实验中,将图片输入大小设置为640×640像素.通过深入分析,决定将批处理(bath-size)大小设置为16,并将训练轮数(epoch)设定为300.初始学习率为0.01,学习率动量为0.1,采用随机梯度下降方法,其他为默认设置.实验环境如表1所示.

表1 实验环境
3.3 评价指标
在本次实验中,采用一些评价指标作为衡量模型性能的标准.这些指标包括mAP@0.5、mAP@0.5∶0.95、召回率(Recall)和准确率(Precision).其中,mAP@0.5与mAP@0.5∶0.95分别表示在IoU阈值设置为0.5与0.5~0.95时的平均精度值(AP).TP表示真阳性,即检测模型正确预测到的样本正例.TN表示真阴性,即模型正确预测到的样本负例.FP表示假阳性,即模型没有预测到的样本负例.FN表示假阴性,即模型没有正确预测到的样本正例.Precision表示被分类为正例的样本中实际为正例的比例,而召回率(Recall)则度量了模型正确识别出的正例数量占总正例数量的比例.AP是Precision-Recall曲线下的面积.具体的计算公式如下:
(3)
(4)

(5)
(6)
3.4 消融实验
为了更好地展示检测结果和评估性能,进行了模块消融实验.实验结果详见表2.
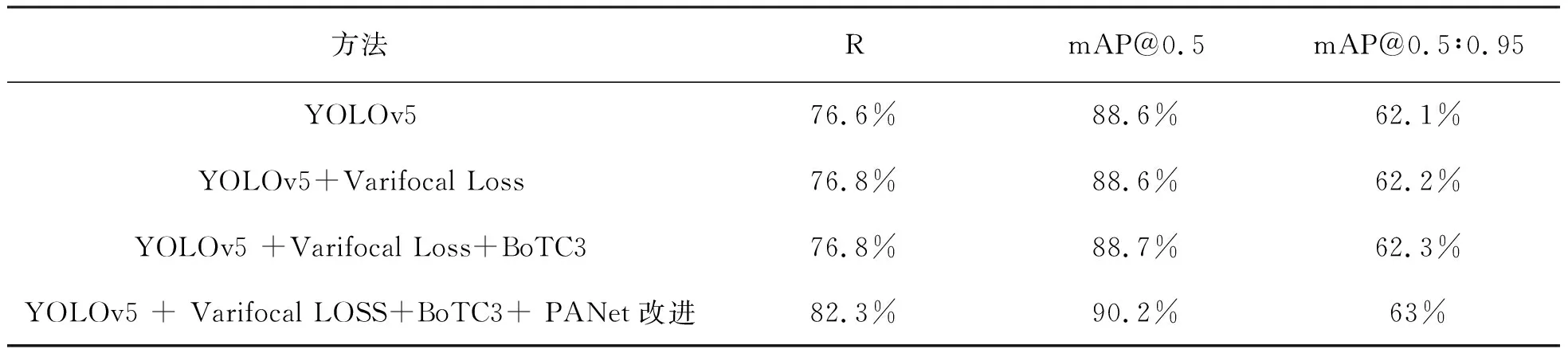
表2 消融实验结果
由表2可知,与原始的YOLOv5模型相比,使用Varifocal Loss损失函数替换原模型中的Focal Loss后召回率与mAP@0.5∶0.95分别提升了0.2%与0.1%.实验结果显示,使用Varifocal Loss损失函数替换Focal Loss损失函数的改进对于密集场景下的行人检测是有效的.在YOLOv5骨干网络的末端增加BoTC3模块后,mAP@0.5与mAP@0.5:0.95分别提升到88.7%与62.3%.实验结果表明融合了多头自注意力机制的BoTC3模块能够有效检测部分特征丢失的目标行人.在原模型中添加改进后的PANet网络后,召回率与mAP@0.5分别提升到82.3%与90.2%,mAP@0.5∶0.95也提升到63%.实验结果充分证明改进后的PANet网络在检测小尺度目标行人方面的适用性.相较于原模型,最终模型的召回率、mAP@0.5与mAP@0.5∶0.95分别提高了5.7%、1.6%和0.9%,证明此方法的可行性.为了更加直观地体现改进后算法的检测性能,对改进前后模型的检测效果进行对比展示,如图7所示.实验结果表明,该算法对于小目标行人以及密集行人的检测相较于原YOLOv5模型都获得了较好的检测效果.

(a)原始图像
3.5 对比实验
为了验证所提算法的有效性,现将所提算法与常见主流算法做比较.为了保持实验对比的公平性,统一将图片输入大小设置为640×640,进行对比实验的训练参数和超参数都设置为默认值.如表3所示,所提算法在准确率上远高于SSD算法和YOLOv4算法,略低于YOLOv7-tiny,但在mAP上优于YOLOv7-tiny.总的来说,所提算法在行人检测任务中的综合性能优于目前的主流算法.
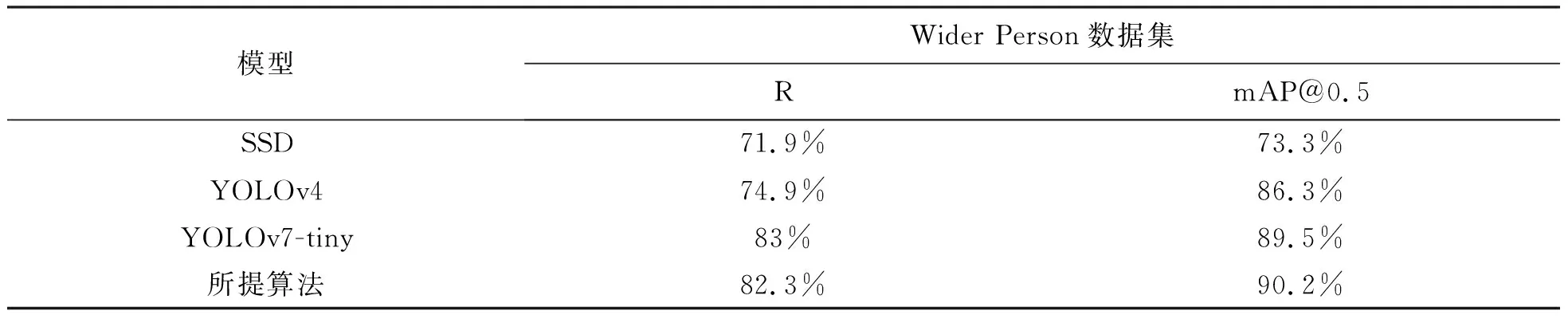
表3 对比实验结果
4 结论
提出了一种适用于密集场景下的改进型YOLOv5行人检测方法.为了提高整体检测效果并增强对遮挡和较小行人目标的提取能力,基于YOLOv5网络模型进行改进.引入融合了多头自注意力机制的模块,解决了由于目标行人之间互相遮挡导致的部分特征丢失问题,提升了整体网络性能.在特征融合阶段,改进了PANet网络,增强了对小尺度目标的检测能力,从而提高小尺度行人的检测精度.此外,使用Varifocal Loss损失函数替换Varifocal Loss损失,使模型更适用于密集场景中的行人检测.
实验结果表明,所提方法在密集场景中的行人检测方面具有更好的效果,可视为一种有效的检测方法.然而所提方法的参数量较大,为了进一步提高模型的推理速度,需要在保证准确率的前提下进行网络轻量化.
