基于双分支多尺度特征融合的道路场景语义分割
2024-01-29肖哲璇
肖哲璇,陈 辉,王 硕
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
图像语义分割作为计算机视觉领域的重要研究内容之一,其主要任务是为输入图像中的每个像素分配与其相对应的类别标签,从而实现一个类似密集预测问题.现阶段基于深度学习的语义分割网络模型已经得到了广泛应用,尤其是在自动驾驶、遥感影像、无人机着陆系统等场景发挥着重要作用.在自动驾驶应用场景中,语义分割成为道路场景信息处理的关键技术之一,而随着卷积神经网络的不断发展,一些基于全卷积神经网络的分割模型[1-3]能够实现较高的分割性能,但在实时应用场景中,由于移动设备数量、空间容量和推理速度等有限,对语义分割算法提出了更高的要求[4-5],因此设计一个轻量且高效的实时语义分割网络模型已成为当前研究的热点.
针对该问题,近年已提出很多实时语义分割网络模型,这些网络使用了轻量级架构以平衡语义分割的准确性和实时性,主要分为编码器-解码器结构[6-7]和双分支结构[8-10].编码器可以由高效的骨干网络组成,也可以是从头训练的高效变体,例如CHEN等[11]提出的Deeplabv3+中使用Xception网络和空洞卷积金字塔模块作为编码器,以聚合不同区域的上下文信息.LEDNet[12]在编码器部分使用了ResNet作为骨干网络,并且在每个残差块中使用了信道分离和混洗,而在解码器部分则通过使用注意金字塔网络以进一步减少网络的参数.在ROMERA等[13]提出的ERFNet中,其编码器使用了深度可分离卷积层,分解后的卷积层将一般的3×3卷积用3×1和1×3卷积进行替换,以减少网络中的参数量,并且该网络在残差分解块中交错使用了空洞卷积,以获取更丰富的特征信息.FANet[14]引入了非局部上下文聚合的快速注意模块,并且在网络的中间特征阶段应用额外的空间降维,从而有效地降低了计算成本,同时增强模型的空间细节,在速度和准确性之间实现较好的平衡.SFNet[15]通过将FAM模块插入特征金字塔,与邻级别的特征图形成一个特征金字塔对齐网络,用于更为快速准确的场景分析.
虽然编码器-解码器结构能够有效降低网络模型的参数量,但在处理分辨率较高的输入特征图时,由于重复下采样过程中有部分信息丢失,且无法通过上采样完全恢复,从而导致语义分割结果的准确性降低.因此,引入双分支网络结构缓解该问题.在双分支网络结构中,为了降低网络的计算成本,通常在深层路径中对低分辨率特征图进行全局上下文捕捉,在浅层路径中对高分辨率特征图提取丰富的空间细节作为补充,然后将2个分支进行压缩合并以获取最终的分割结果.BiseNets[8-9]作为典型的双分支结构模型,提出了一种包含空间路径和上下文路径的双边分割结构,并且使用基于注意力的融合模块对不同分支的输出特征进行融合,以获取丰富的特征信息.Fast-SCNN[10]中的2个分支先共享下采样模块以确保低级特征共享的有效性和高效实施,并通过简单地融合不同分支的特征以确保有效性,同时该网络利用卷积和池化操作作为编码器以提取深度卷积网络特征,然后从低分辨率特征上恢复空间信息.但是双分支结构会增加网络的参数量,并且会在浅层分支结构中引入噪声.针对这一问题,研究表明使用注意力机制[16-17]可以通过对图像像素给予不同权重,从而细化特征信息以提高网络的处理能力,提高目标的分割精度.例如空间通道注意力机制模块CBAM[16],将通道注意力和空间注意力进行混合,并通过卷积操作获取图像中感兴趣区域的信息及其位置信息.
尽管上述方法在测试中取得了不错的结果,但是在分割精度、模型大小和推理速度的平衡上仍有较大的改进空间.因此,本文提出了一种轻量级双分支语义分割算法(Lightweight Dual-branch Network,LDBNet).该算法首先通过残差块进行下采样,然后分成2个不同分辨率的分支,在不同分支中分别加入注意力机制以对空间和语义信息进行提取,且在2个分支之间建立多次连接以实现信息融合,最后在上采样前引入设计的特征融合模块,以增加重要区域空间细节的权重,进一步强化了网络的学习能力.实验结果表明,LDBNet在实时语义分割网络的各项指标上取得了较好的平衡.
1 网络模型
1.1 整体框架
本文提出的网络模型整体结构如图1所示.该网络以ResNet18作为网络模型基础,主要由残差基础块(Basicblock)、切分金字塔瓶颈块(Pyramid Split Attention Bottleneck,PSABottleneck)、残差空洞金字塔模块(Residual Atrous Pyramid Pooling,RAPP)和多尺度特征融合模块 (Multi-scale Future Fusion Module,MFFM)构成.

图1 LDBNet整体结构
LDBNet的整体网络结构为双分支结构,该模型首先将ResNet18中的7×7卷积换成2个步长为2的3×3卷积作为网络的输入,并下采样至原图像分辨率的1/8,然后分成高分辨率分支和低分辨率分支分别对输入特征图进行特征提取.在低分辨率分支中,模型通过残差块连续下采样至原始图像的1/32,然后通过RAPP模块对输入特征图进行上下文语义的信息提取;而在高分辨率分支中,为了尽可能满足推理速度和模型尺寸的要求,模型通过将残差块中的3×3卷积的步长设置为1以保持1/8分辨率,并且在该分支的尾部添加一个将切分金字塔注意力模块和瓶颈块相结合的切分金字塔瓶颈块,在扩展输出维度的同时能够获取更加丰富的通道和空间信息.为了使模型在空间位置信息上能够进行更好的定位,并结合模型对分割实时性的要求,该模型在2个分支输出不同的特征图后,将不同特征图通过特征融合模块进行信息整合,可以在增加较小计算量的同时增强对位置信息的关注,并对通道间的特征信息进行提取,之后再进行1/8上采样,得到原图像大小的分割图.
为了能够增强对不同尺度信息的提取并且充分融合不同尺度特征的空间信息和语义信息,模型的2个分支在不同阶段进行多个双侧特征融合[18],使不同尺度特征更加细化,从而优化了分割效果.不同分支之间的融合过程具体操作可以用公式(1)表示:
(1)
其中,XHi和XLi分别代表第i个高分辨率特征图和低分辨率特征图,R表示ReLU函数,B表示双线性插值法,C1×1表示1×1卷积,C3×3表示3×3卷积.
1.2 残差空洞金字塔模块
在城市道路场景中,不同对象的尺度差异较大,如何获取并整合更有效的上下文信息也是该场景语义分割的关键.针对该问题,本模型通过进行多尺度特征提取的方法,在低分辨率分支上进行语义信息的提取和融合,提升分割结果的准确性.考虑到对模型实时性的要求,残差空洞金字塔模块(RAPP)通过使用多个空洞卷积进行多尺度的特征提取,目的是在不增加参数量的情况下扩大感受野,从而更好地捕获多尺度的特征信息,在低分辨率分支中能够获取更高级别的特征信息,其整体结构如图2所示.
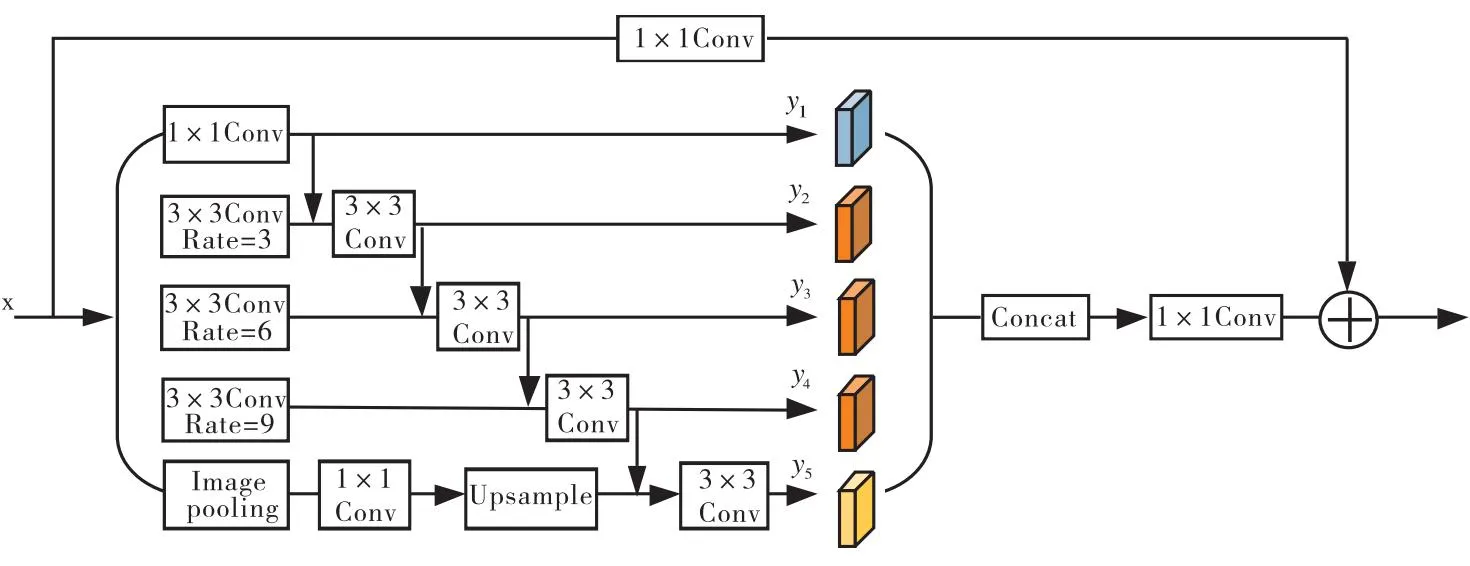
图2 RAPP模块
该模块从上到下使用1×1卷积层和采样率依次为3、6和9的空洞卷积进行相应层次的特征提取,然后与全局平均池化分支进行连接,最后将连接后的输出特征与1×1卷积后的原始特征进行点态求和.但是考虑到只单一地融合所有多尺度上下文信息是不够的,受到Res2Net[19]的启发,使用多个3×3卷积以层次残差的方式,在每次特征连接时将不同尺度的上下文信息进行融合,虽然该模块用较复杂的融合策略进行上下文信息提取,但是由于其输入特征图的分辨率为原图像分辨率的1/32,所以该模块对推理速度的影响较小,其操作可用公式表示为
(2)
其中,x表示输入图像,yi表示第i个尺度的输出,C1×1表示1×1卷积,C3×3表示3×3卷积,AC3×3表示3×3空洞卷积,U表示上采样,Pg表示全局平均池化.
1.3 PSABottleneck模块
PSABottleneck模块在网络结构中位于高分辨率分支的最后一个模块,其主要构成是将瓶颈块中的3×3卷积替换成切分金字塔注意力[20](PSA)模块,以实现通道和空间维度上的特征提取.其结构如图3所示.

图3 PSABottleneck结构
PSA注意力机制首先通过SPC模块,在通道维度上对特征图进行多尺度特征提取,然后通过SE权重模块获取每组通道的权重值,并利用Softmax函数进行归一化和加权操作,最后输出一个具有丰富特征信息的细化特征图,其结构如图4所示.

图4 PSA模块
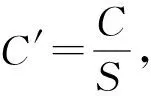
PSA注意力机制能够有效获取跨通道信息,因此通过使用PSA注意力机制可以将多尺度空间信息和跨通道注意力集成到每个特征组中,更好地实现局部和全局通道注意力之间的信息交互.
1.4 多尺度特征融合模块
为了将不同分支得到的特征信息进行整合,本文算法根据文献[8]设计了一个新的特征融合模块,将空间信息和上下文语义信息进行融合,其结构如图5所示.
图5 多尺度特征融合模块
图中空间分支和语义分支分别代表网络结构中高分辨率分支和低分辨率分支所得的特征图,该模块首先将空间分支特征进行连续下采样操作并与语义分支特征进行合并,同时引入协同注意力[21](Coordinate Attention,CA)模块对空间分支特征进行处理,然后将1/32特征图进行上采样操作并与经过注意力模块处理后的特征图合并,最后再与初始空间分支特征图进行逐点相乘操作.该模块通过不同尺度的特征融合实现在较小参数量的情况下,有效地恢复了空间细节信息,其中协同注意力模块的结构如图6所示.
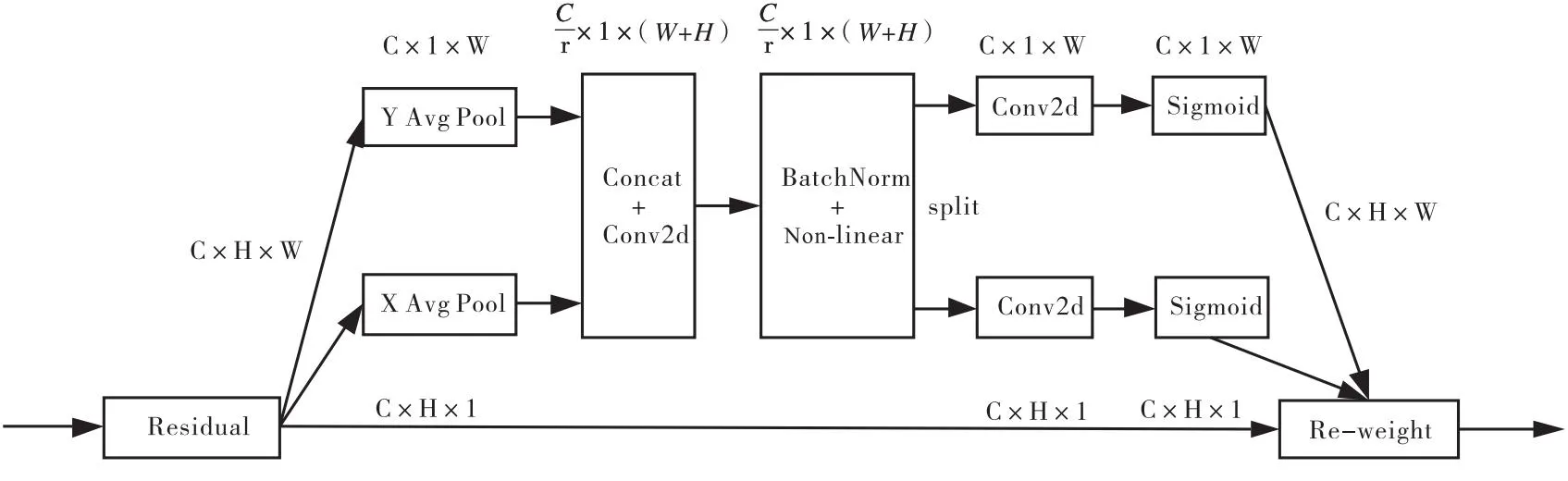
图6 协同注意力模块
CA模块在通道注意力中嵌入了坐标位置信息,主要过程分为2步:坐标信息嵌入和坐标注意力生成.为了获得精确位置信息的远程空间依赖,CA模块先通过2个平均池化操作对全局池化进行分解,然后对这2个包含方向的通道进行编码处理,将输出的特征图进行拼接、卷积和激活函数操作,可以得到同时具有水平和垂直方向空间信息的特征图,之后将输出沿着空间维度分成2个独立的张量,并分别进行卷积和激活函数操作,使其通道数与输入特征图的通道数一致,最后将输出结果作为注意力权重与特征图相乘,得到最终输出.综上所述,该模块能更准确地定位感兴趣区域对象的位置,增强了聚焦特征的能力,从而帮助整个模型对不同区域进行更好的识别.
2 实验分析
2.1 数据集及实验设置
本文用于实验的数据集为Cityscapes[22]数据集和CamVid[23]数据集.Cityscapes数据集是一个较为常用的城市街景语义分割数据集之一,该数据集采自50个不同城市的街道场景,包含5000张精细标记图片,其中包括2975张精细注释图像、500张验证图像和1525张测试图像,除此之外,还包含约20000张粗略标记图片,可以用作模型的预训练,且图像分辨率为1024×2048.数据集中精细标注的图片有34种类别,其中有19种用于语义分割,其他类别被设置为不感兴趣类别.在本文实验中的训练阶段,将图像的分辨率随机裁剪为1024×1024.CamVid数据集是从视频序列中提取的高分辨率图像,由701张精准标注图像组成,其中包括367张训练图像、101张验证图像以及 233张测试图像,且图像分辨率为720×960,使用11种常用类别对分割精度进行评估.与Cityscapes数据集相比,该数据集的图像增加了目标的数量和异质性.本文实验所用的CPU是24核Intel(R) Xeon(R) Gold 5320 CPU @ 2.20 GHz,内存为64 GB,GPU型号为RTX A4000,显存大小为16 GB,选用的是PyTorch框架,并使用Python3.8进行编程.
对于街道场景语义分割网络模型,通常使用评价指标mIoU、模型参数量和推理速度分别体现模型的分割精度、空间复杂度和实时性,其中mIoU表示所有语义分割类别真实值和类别预测值的交集与并集比的平均值,其公式可以表示为
(3)
其中,pii为正确分类的像素数量,pij代表实际类别为i、预测类别为j的像素数,pji代表实际类别为j、预测类别为i的像素数,n为像素分类的类别总数.
2.2 网络模型性能对比
本节基于Cityscapes数据集和CamVid数据集,将LDBNet与现有的轻量级语义分割算法在浮点运算数(GFLOPs)、参数量(Parameters)、分割精度(mIoU)、运行速度(Speed)等方面进行比较,其结果如表1和表2所示.
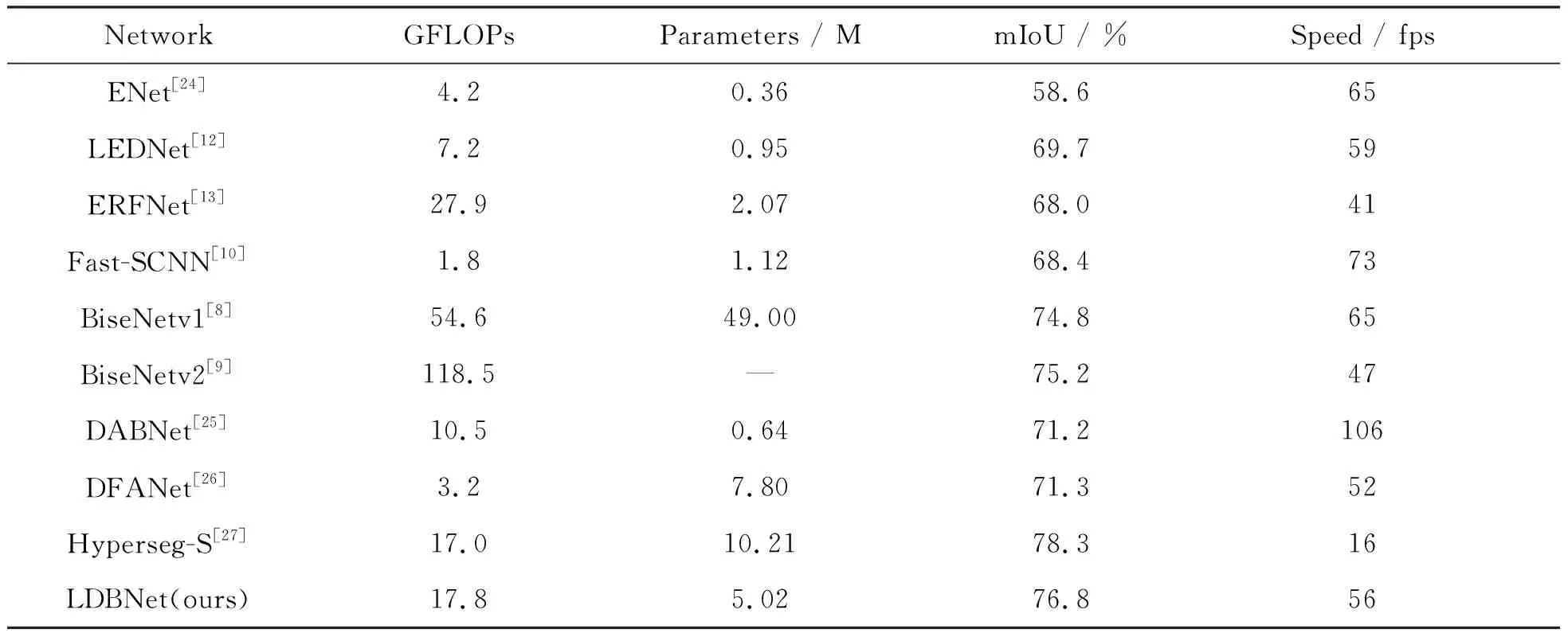
表1 不同语义分割算法在Cityscapes数据集上的结果对比
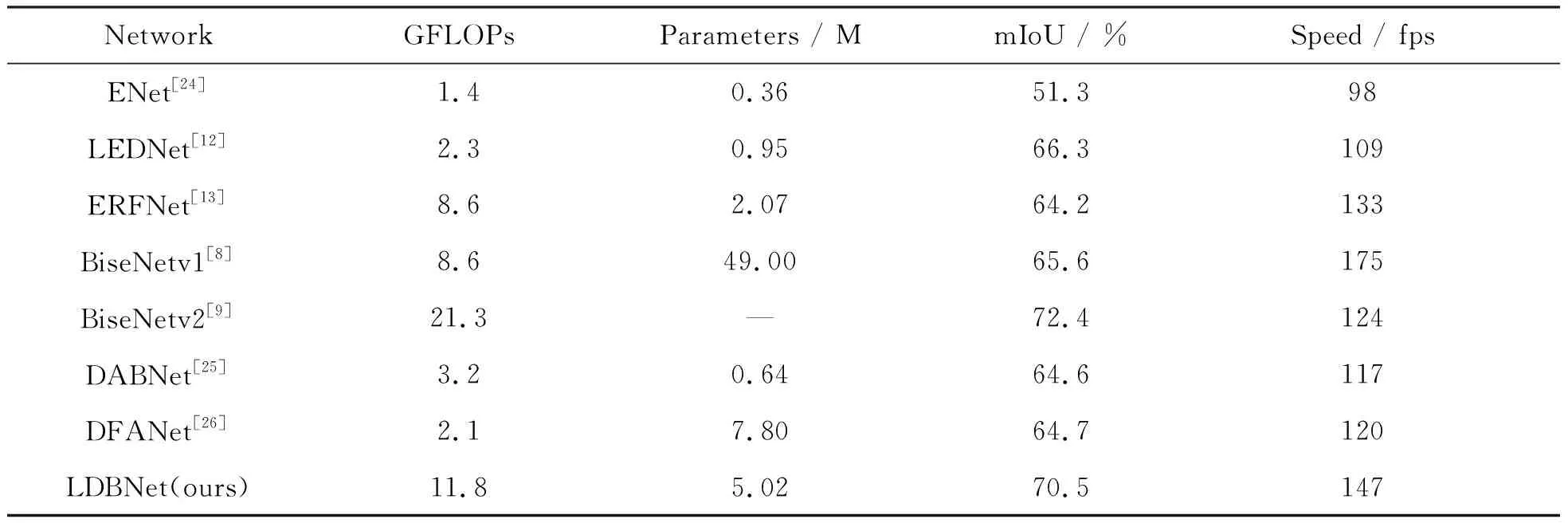
表2 不同语义分割算法在CamVid数据集上的结果对比
从表中分割结果的定量分析可以看出,不同的轻量级模型在性能方面各有优势,当输入图像的分辨率为1024×2048时,LDBNet在Cityscapes测试集上以56 fps的运行速度达到76.8%mIoU.而同样以ResNet18作为主干网络的BiseNetv1[8],其分割精度相较于之前的算法有了较大的提升,但是其模型参数量也达到49 M.而BiseNetv2[9]模型计算所需的浮点操作数更大,计算复杂度更高,推理速度也稍慢,相比较而言,LDBNet能更好地平衡模型复杂度和准确度之间的关系.表中ENet模型参数量最小,仅有36万参数,但是其mIoU值比LDBNet的低了18.2%.而相比表中mIoU值最高的Hyperseg-S模型,虽然LDBNet的mIoU值与其相比低了1.5%,但是在模型参数量和运算速度上有较大的提升.对于DABNet模型,虽然其运行速度达到106 fps,但是其mIoU值相较于LDBNet的低了5.6%,这也说明LDBNet在参数量、运行速度和准确度上实现了较好的平衡.
在CamVid数据集中,由于模型处理图像的分辨率降低至720×960,所以模型的运行速度得到了较大提升,仅次于BiseNetv1.但是LDBNet的mIoU值比BiseNetv1的高了4.9%,并且参数量也比BiseNetv1低.而与BiseNetv2相比,虽然其mIoU值低了1.9%,但是LDBNet的运行速度提升了23 fps,所以相较于表中的大多数网络模型而言,LDBNet能够以较快的运行速度达到更高的分割精度.
为了直观地展示本文所提网络模型的分割效果,本文将与其他模型的分割结果进行可视化对比,并选择部分分割结果,如图7所示.从对比图中可以看出,在第一个场景中,在绿化带被阴影遮挡的情况下,本文所提算法相较于其他算法能够进行更好的分割,能够有效地减少客观环境对分割结果的影响.在第二个场景中,本文所提算法在较远处路口横向马路的识别中具有较好的性能,而其他算法没有明显的效果.在第三个场景中,除了在对阴影遮挡部分的处理优于其他算法外,本文算法对不连续遮挡物的分割效果也较为清晰,如右侧人行道被警示柱遮挡的摩托车.从第四个场景可以看出,本文算法对不同类别的边缘分割较为准确,如左侧的路标和人行道的边缘分割效果较其他几种算法更为明显.从图6的整体结果可以看出,算法对轮廓较为清晰且对没有被遮挡的物体进行分割时,其分割效果都较准确,但是对于复杂场景、有遮挡目标及小目标的分割,本文算法较其他方法,能够进行更加有效地处理,且更加注重对高级特征语义信息的多尺度特征提取,这增强了网络对复杂场景和遮挡目标的有效分割,但由于空间信息是在1/8分辨率下进行提取的,也会对分割结果产生影响,导致部分类别的分割结果较为模糊.

Input image Ground truth DABNet DFANet LDBNet(Ours)
2.3 网络模块性能分析
为了验证本文RAPP模块的有效性,将其与Deeplabv3+[11]中的空洞卷积金字塔(Atrous Spatial Pyramid Pooling,ASPP)模块进行比较,结果如表3所示,其中Type表示消融实验中的不同方案.实验结果表明,加入RAPP模块的mIoU值比加入ASPP模块的mIoU值上升了1.1%,并且只略微增加了模型的参数量.除此之外,对RAPP模块的下采样率进行实验以验证其有效性,使用不同的采样率几乎对模型参数量和运行速度没有影响,但是在整体网络框架中,采样率rate=3、6和9时的mIoU值达到了最高,所以在本文所提算法中,RAPP模块在平衡分割精度、运行速度和模型大小方面优于其他选择.
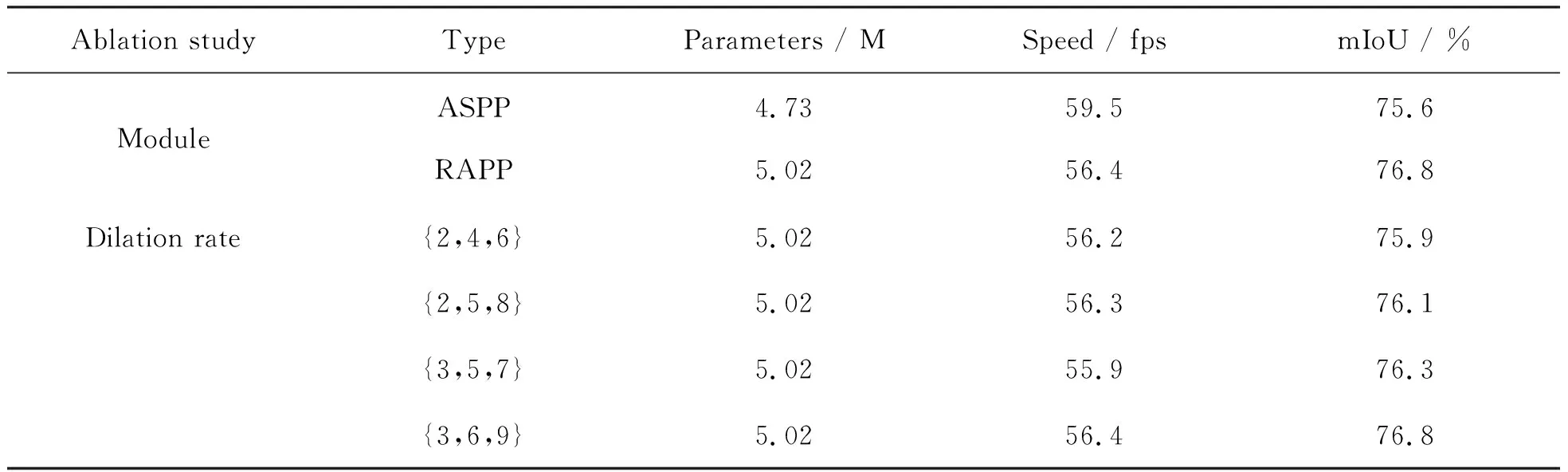
表3 RAPP模块在Cityscapes数据集上的消融实验
为了验证特征融合模块MFFM的有效性,对该模块中的融合方式和所加入的注意力模块进行消融实验,结果如表4所示.
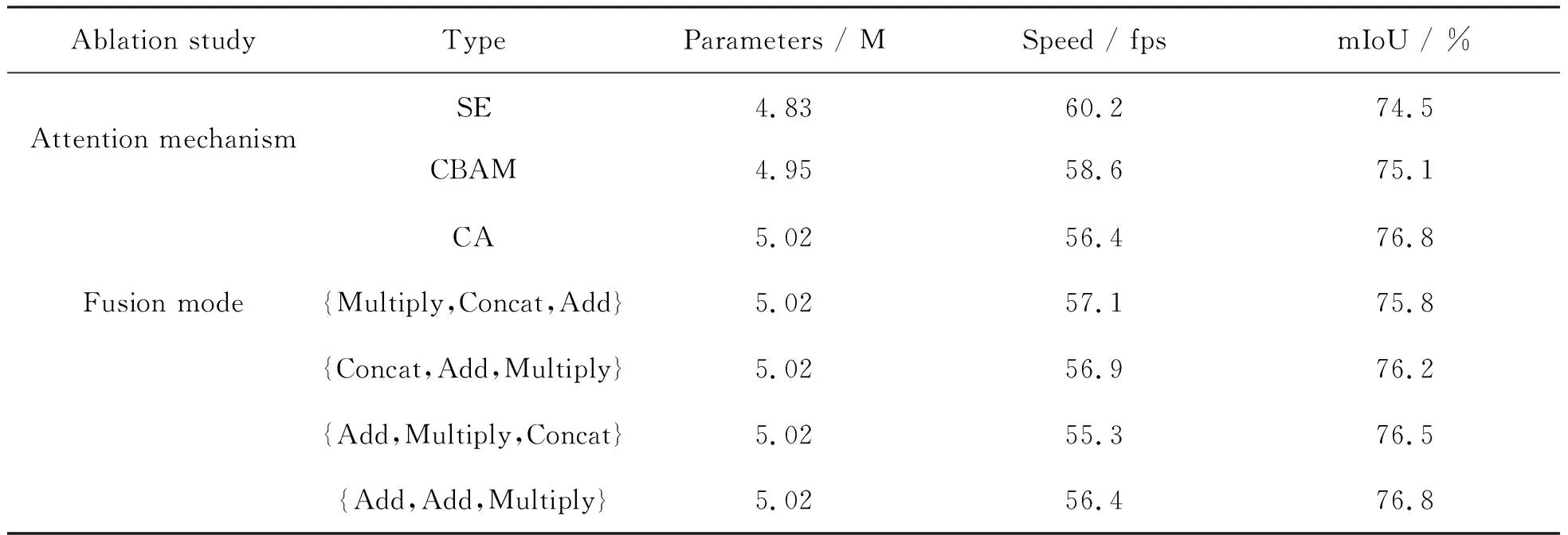
表4 MFFM模块的消融实验结果
从表中可以看出,当把CA注意力模块换成其他注意力模块时,mIoU值都比原模型分割略低一些.而将不同融合方式进行替换,使用原模型中融合方式的mIoU值最大,由此可以看出MFFM中的注意力模块和融合方式在选择上达到了最优效果.
本文在Cityscapes数据集和CamVid数据集上对相对应的模块进行了消融实验,以验证本方法中各个模块在道路场景数据集上的有效性,结果如表5所示.
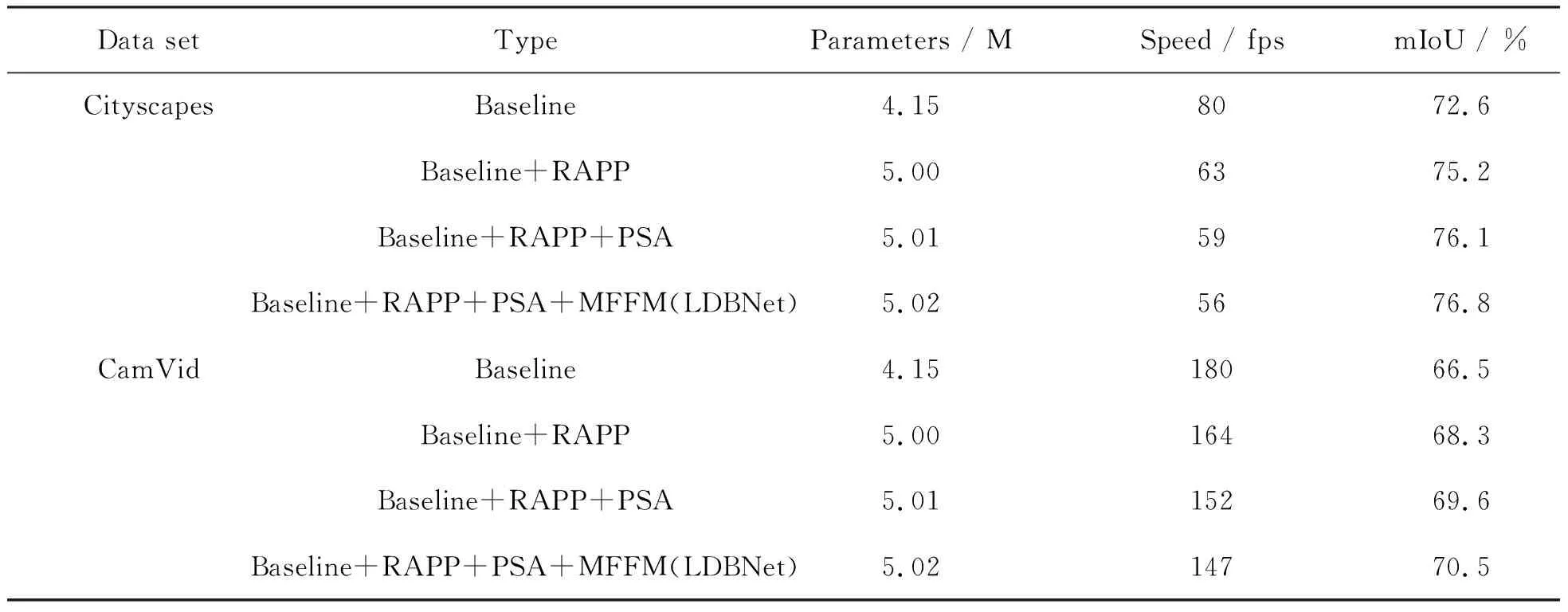
表5 不同模块的消融实验结果
本文以没有加入任何模块的网络模型作为基础网络进行实验,然后分别加入RAPP模块、PSA模块和MFFM模块进行数据对比.从表中可以看出,加入每个模块后,其mIoU值与基础网络相比都有所提升,且在最后达到了最大值.由此可以看出,所提出模型中的各个模块都具有一定的适用性和互补性,能够有效地提高分割性能.
为了更直观地感受各模块对分割效果的影响,本文选取在Cityscapes验证集中的部分可视化分割结果对各模块进行定性分析,其结果如图8所示.

Input image Truth Baseline Baseline+RAPP Baseline+RAPP+PSA LDBNet
在场景一中,加入RAPP模块后的模型优化了基础模型的分割效果,其中对人行道的分割较为明显,增强了对输入图像上下文信息的提取.在场景二中,加入PSA模块后的模型在复杂场景处的分割效果更好,可以看出其能够有效地增加模型的抗干扰能力.从场景三可以看出,加入MFFM模块后的模型对于远距离小目标的分割效果以及不同类型对象的边缘分割有较为明显的提升.根据消融实验的对比结果,网络模型中的各个模块都能够有效地解决场景语义分割问题,增加了模型对于不同场景的分割精度,具有一定的有效性.
3 结论
针对实时场景中对实时语义分割模型的要求,本文提出了一种轻量级的实时语义分割网络模型LDBNet.该算法的整体网络结构为双分支结构,并且在高分辨率分支和低分辨率分支中分别加入PSABottleneck模块和RAPP模块以对通道与空间特征信息进行提取,并在最后加入MFFM模块以优化不同分支之间的特征融合.在Cityscape数据集上的实验结果表明,LDBNet能够以56 fps的运行速度达到76.8%的mIoU,且参数量仅有5.02 M,而在CamVid数据集中,该模型以147 fps的运行速度达到70.5%的mIoU.从消融实验的结果可以看出,各个模块都具有较优的性能,从而能够更好地平衡模型复杂度、准确度和推理速度之间的关系.
