基于机器学习的儿童颅骨畸形分类研究
2024-01-29张顺雨胡骏林勇
张顺雨 胡骏 林勇



关键词:颅骨畸形;集成学习;图像处理;分类预测
0 引言(Introduction)
颅骨畸形[1]并不仅仅是外观问题,更是影响儿童健康发育的重要因素。颅骨畸形会改变婴幼儿面部形态,严重的畸形可能影响大脑发育,造成发育滞后的问题。颅缝早闭[2]是导致颅骨变形的常见原因,全球每10 000名新生儿中就有3.1~6.4人患病。目前,我国对儿童颅骨畸形的诊断和治疗未有统一标准,诊断方法包括手工测量和CT临床检测以及近期出现的光学三维建模技术,手工测量和临床检测存在速度慢、过于依赖医生经验、患儿配合性差且测量精度不高等问题,光学三维建模诊断的精度也较难保证,CT图像具有较高精度,但也需要依赖检验医生读片诊断[3]。因此,设计一套能够自动对获得的CT数据进行自动分类预测的模型,用于对儿童颅骨图像的高精度分类预测,这对通过早发现、早诊断、早手术进而实现挽救患儿生命和改善症状直至彻底治愈具有重要意义。
1 研究现状(Research status)
目前,机器学习在医学图像领域的应用越来越广泛,但将机器学习用于颅骨畸形的研究并不多见,YOU等[4]使用迁移学习方法从CT图像自动分类颅骨畸形,该方法首先从CT图像切片中分割3D颅骨,通过半球投影将3D颅骨投影到二维空间以获得二值图像并进行数据扩充;其次在生成的数据集上对预训练的深度学习模型进行微调,最终在数据集上的预测准确度达到了90%以上。SABETI等[5]将机器学习技术应用于新生儿颅缝早闭识别研究,头部边界采用GrabCut算法进行分割和识别,然后计算人体测量指标,如颅骨指数(CI)、颅顶不对称指数(CVAI)、前中线宽度比(AMWR)、前后宽度比(APWR)、左右高度比(LRHR);分类器采用KNN(K-NearestNeighbors)、支持向量机(SVM)[6]、随机森林和Bagging集成学习,预测准确率为0.85~0.92。此研究提出了5个常见的数值测量特征,为了进一步丰富对头颅畸形进行量化的数值特征,LEI等[7]使用SVM和高斯径向基函数考虑了非线性超平面,采用留一法交叉验证优化软间隔参数和高斯宽度;结合2D和3D形状指数索引对颅骨畸形进行预测,准确率达到了0.958。但是,该研究只进行了单一模型的预测,其精度还有一定的提升空间。
针对上述研究的不足,本文设计了一套基于Stacking方法构建的异构分类器模型,并利用图像处理的方式从CT数据集中提取出包括CI、CVAI、AMWR、WPWR、LRHR等9个量化特征,选用SVM、KNN、随机森林(RandomForest)、XGBoost作为初级分类器,随机森林作为次级分类器进行集成。实验结果表明,本文构建的分类模型和量化特征在精度和分类性能上均优于之前的研究。
2 材料与方法(Materials and methods)
2.1 數据集介绍
本研究使用的数据集来自项目合作医院提供的463例儿童颅骨CT扫描数据集,年龄分布为0~9岁,其中100例为患有颅缝早闭而导致颅骨畸形的头部3D计算机断层扫描(CT)数据,其余363例为正常的头颅CT数据。
2.2CT图像处理
为了从原始的CT图像数据集中提取所需的数值特征,需要进行一系列的数字图像操作,具体步骤如下。
为了完整地提取到头颅模型的颅骨特征,并对所有样本进行标准化处理,需要将原始的CT扫描切片进行面绘制,生成pcd格式的3D模型。由于拍摄环境存在噪声[图1(a)],因此需要对提取到的pcd数据进行过滤。本文将最大联通区域提取算法[8]应用到点云数据中,结果如图1(b)所示。本研究的兴趣区域仅为头颅部分,有别于临床研究中的头颅划分方式,利用开源库PCL(Point Cloud Library)进行点云运算,提取出3D模型中的z 轴中点以上的点云数据并保存[图1(c)]。考虑到原始模型中,异常数据仅为100例,对异常模型的pcd数据进行逐层抽样[图1(d)],用此方案扩充后的颅骨畸形样本量达到323例,与正常颅骨样本363例的数据量基本平衡。
为了方便后续的机器学习和特征提取,需要将三维空间中记录的pcd点云数据投影到2D平面中。在提取图像的数值特征时,为了避免因图像像素不同而造成的误差,将所有图像归一化为512×512的像素大小。采用随机翻转和旋转的方式对原始数据集进行扩充,扩充后的数据集大小为正常头颅图像样本969例、畸形头颅样本1 164例。
2.3 特征提取
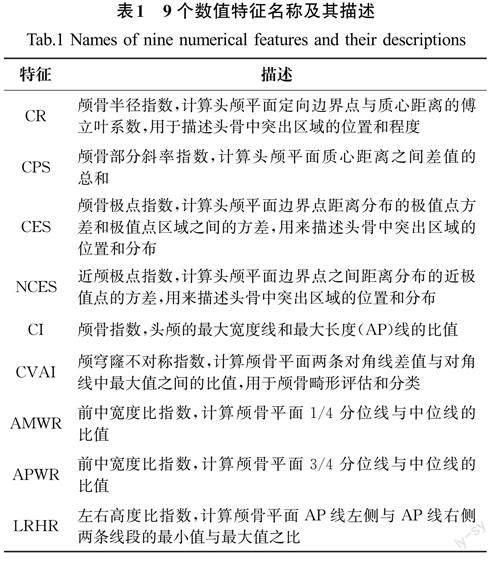
为了区别由颅缝早闭造成的颅骨畸形和正常颅骨,研究人员参考了目前针对颅骨畸形的研究文献,提出了9个数值特征,包括描述正常颅骨和变形颅骨之间突出区域的判别形状特征的4个指数CR、CPS、CES、NCES,以及5个颅骨测量指数CI、CVAI、AMWR、APWR、LRHR;9个数值特征名称及其描述如表1所示。
2.4 特征预处理与分析
提取特征之后,为了保证数据应用于模型的适用性,并减少数据噪声和异常值对模型精度和可靠性的影响,特进行了数据清洗、特征差异分析和正态分布纠正等操作。
本文采用Tukey方法[9]去除异常值,计算数据上下四分位数(Q1,Q3)和四分位距(IQR),根据Tukey的规则将位于1.5倍IQR之外的数据点视为极端值,将其从数据中删除。将去除异常值后的数据绘制成箱线图,来进行正常和异常样本的特征差异分析,数据清洗后样本箱线图如图2所示,从图2中可见,多数特征具有较高的区分度,表明所选特征对于区分正常样本和异常样本是有效的。
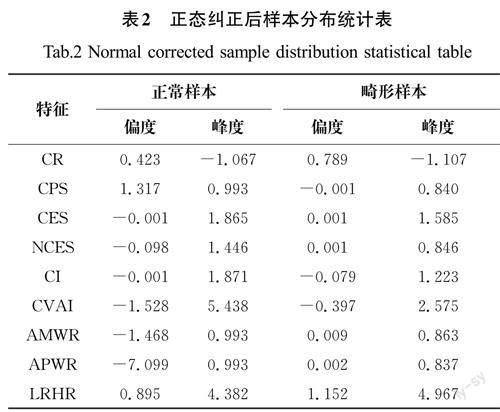
颅骨畸形描述特征属于随机变量,从统计学的角度看,随机变量的分布应该满足正态分布,通常用偏度和峰度作为衡量数据符合正态分布形态的指标。由于样本数据量有限和人为进行的数据增强,造成样本分布很难满足正态分布的要求,导致直接针对原始的数据集进行建模效果不佳,需要对数据进行正态分布纠正,以进一步提高模型的准确性和实用性。
分位数归一化转换法[10]可以将数据转换为具有类似正态分布的形状而不考虑特定的概率分布函数。该方法使用数据经验分布的分位数(数据集中的百分比位置上的数值),具体来说:该转换法首先计算输入数据的经验分布函数,并将其映射到均匀分布。然后应用逆变换函数将均匀分布映射到目标分布。将数据转换为正态分布时,转换的目标分布是正态分布。正态纠正后样本分布统计表如表2所示。其中,偏度越接近0,则越接近正态分布,峰度为正表示数据分布更加陡峭或集中,而峰度为负表示分布更加平坦或散开。由表2可知,大部分特征经过纠正后基本能符合正态分布。
2.5 畸形分类模型构建
集成学习通过合并多个学习器进一步提升预测准确性。本文采用Stacking[11]集成的方式,首先从原始训练集训练出初级学习器,其次将初级学习器的预测结果作为新的数据集训练次级学习器。在新的数据集中,初级学习器的输入作为输入特征,而样本标记与原始数据集中的样本标记一致,本文使用的初级学习器使用不同的学习算法产生,即初级集成是异构的。在训练阶段,次级训练集是用初级学习器生成的,若直接用全部的原始数据集训练次级训练集,就会增大过拟合的风险,本实验采用k折交叉验证的方式生成次级训练集,具体过程如下。
为了使每次划分的训练集足够大,本文将初始训练集D随机划分成k 个大小相同的子集D1,D2,…,Dk。Dj 表示第j折的测试集,DJ 表示第j 折的训练集,其表示如下:
本文给定T 个初级学习算法,初级分类器l(j) t 为在训练集DJ 上使用第t 个分类算法所得。其中,Dj 中的每个样本xi为计算出的9维特征向量。初级分类器的预测结果为pit,表示如下:
由xi 产生的次级训练样本集示例为pi=(pi1,pi2,pi3,…,piT ),标记部分yi 为样本的类别,其中正常样本标记为0,异常样本标记为1。于是,在整个交叉验证过程结束后,从T 个分类器产生的次级训练数据集如下:
将D'用于训练次分类器STi,本实验预选的次级分类算法的集合如表3所示,将选择预测精度最高的预选次级分类算法训练次级分类器,最终得到本文基于Stacking的异构分类器。
2.6 评估指标
为验证不同分类模型的有效性,本文采用准确率(Accuracy)、查准率(Precision)、召回率(Recall)和F1度量对不同的模型进行评估。
对于二分类问题,TP 为真阳性,表示头颅畸形的样本预测结果也是畸形的;TN 为真阴性,表示头颅正常的样本预测结果也是正常的;FP 为假阳性,表示将正常的样本预测为畸形;FN 为假阴性,表示将畸形的样本预测为正常。
3 实验结果与分析(Experimental result andanalysis)
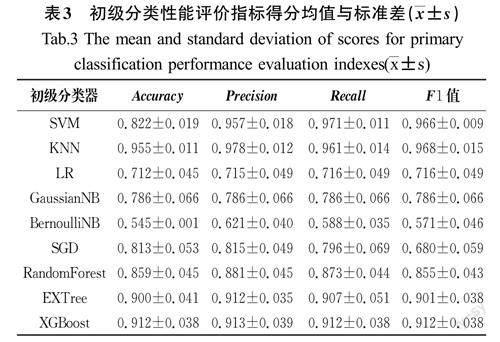
对本文使用的初级分類器进行十折交叉验证,计算准确率、查准率、召回率和F1度量在10次验证过程中的平均得分以及标准差,初级分类性能评价指标得分均值与标准差(x±s)如表3所示。
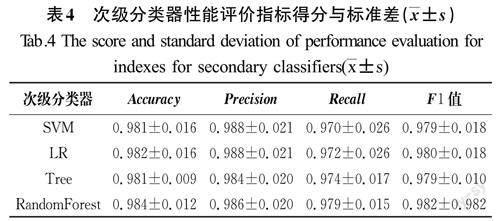
由表3可知,排名前4的初级分类器分别为SVM、KNN、RandomForest、XGBoost,其精度分别约为0.822、0.955、0.859、0.912,性能优于其余的候选分类器。用排名最靠前的4个异构的初级分类器对原始训练集进行预测,将预测的结果作为新的训练集用于训练次级分类器,并选出性能最优的次级分类器。次级分类器性能评价指标得分及标准差如表4所示。由表4中的数据可以看出,当用RandomForest作为次级分类器时,集成学习分类器的准确率约为0.984,相比其他次级分类器SVM(准确率约为0.981)、LR(准确率约为0.982)、Tree(准确率约为0.981),分别提升了0.003、0.002、0.003。
相比仅使用单一分类的模型中准确率最高,本文所提模型的精度则至少提升了0.1左右。综合以上数据,本文提出的将SVM、KNN、RandomForest、XGBoost作为初级分类器,将RandomForest作为次级分类器的Stacking方法所集成的异构分类器的性能最优,精度约为0.984,准确率约为0.986,召回率约为0.979,F1得分约为0.982。为了更清楚地比较上述次级分类器和集成分类器的性能,特绘制出各分类器的ROC(受试者工作特征)曲线以及PR (查准率-查全率)曲线(图3)。ROC 曲线边界越靠近左上角边界,AUC(曲线下面积)值越大,就表示分类器性能越好,PR 曲线直观地展示了学习器在总体样本上的准确率和召回率。由图3可见Stacking异构分类器的PR 曲线完全包住了其余分类器,可以判断Stacking分类器的性能最优。
4 结论(Conclusion)
本研究实现了一种用于自动判断颅骨畸形的集成学习方法,该方法首先对原始的CT图像数据集进行格式转化,然后进行3D模型清洗、兴趣区域提取、类别平衡、2D投影及数据扩充等一系列图像处理工作,利用数字图像处理的方式提取出用于训练畸形判别分类模型的9个数值特征,并构建训练集和测试集,最后对比了9种常见的初级分类器在训练集上进行十折交叉验证的评价得分,选出了SVM、KNN、RandomForest、XGBoost四种性能最优的初级分类器,用于训练次级训练器所需的新的训练集,并在新的训练集上选出最佳的次级分类器,至此构建了初级分类器为SVM、KNN、RandomForest、XGBoost,次级分类器为RandomForest的Stacking异构集成学习分类模型。实验结果表明,本文实现的基于Stacking的异构集成学习分类模型能够很好地区别头颅畸形样本和正常样本,并且与单一分类模型相比精度更高、性能更好。
受限于项目初期样本量,本文仅尝试了基于机器学习的分类方法,在后期样本量得到扩充后,将进一步研究深度学习的应用场景,以期进一步提高分类模型的泛化能力。对于建立的分类模型,将结合摄影测量技术,对采集到的摄影图像进行分类判别,实现对儿童颅骨畸形的早筛。
