融合CNN 与Transformer 的跨年龄人脸识别
2024-01-26刘二毛
刘二毛,智 敏
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
人脸识别技术目前成为现代社会中广泛应用的一种身份验证和安全保障手段。然而,年龄因素仍然是人脸识别领域的主要瓶颈。人的外貌特征在成长过程中会发生非线性变化,导致类内差异和类间相似性极高,为人脸识别技术的准确性和稳定性带来了挑战。目前,深度学习是跨年龄人脸识别的主流方法之一。Transformer 作为一种新兴的深度学习模型,具有快速推理能力和强大的特征抽取能力,能够很好捕捉不同身份之间的关键特征,被应用于跨人脸识别领域。但是,基于Transformer 的跨年龄人脸识别模型仍存在对局部底层特征表达不足,以及特征分解不彻底的问题。
针对Transformer 缺少局部底层特征信息的缺陷,在提取人脸特征时,本文将深度可分离卷积(depthwise separable convolution,DSC)嵌入到Transformer 架构的T2T-ViT[1]模型,构建了一个高效而简单的深度可分离T2T-ViT 网络(depthwise separable T2T-ViT,DST2T-ViT),其结合了卷积神经网络(convolutional neural networks,CNN)在提取底层特征、加强局部性,以及Transformer 在建立远程依赖关系的优势,以增加较小的额外计算成本,获取丰富的底层特征。
针对身份、年龄特征分解不彻底的问题,受注意力机制能够自适应地关注与目标任务相关的特征,而抑制无关信息的启发,本文拟通过串联改进的通道和空间注意力,构造多尺度注意力分解模块(multi-scale attention decomposition module,MSADM)。该模块分别在通道和空间两个维度上采用多尺度注意力,使网络选择性地关注与年龄相关的特征,促进高效的特征分解,采用互信息(mutual information,MI)定量地度量两者之间解耦程度,通过最小化身份和年龄特征之间的MI 对分解后的特征进行相关性约束,捕获完整的身份信息。
1 相关研究
本文中跨年龄人脸识别通过DST2T-ViT 网络高效捕获丰富的初始人脸面部特征,采用MSADM 和MI 最小化的正则化算法结合获取鲁棒性强的身份特性。因此,将从人脸特征提取和人脸特征解耦2 个方面讨论相关工作。
1.1 人脸特征提取
近些年,基于CNN 模型在跨年龄人脸识别任务取得较多研究成果。文献[2]将ResNet 网络作为编码器和解码器,提出既能学习稳定身份特征、又能实现逼真人脸合成的混合网络。文献[3]在ResNet 网络中,添加金字塔特征融合模块,从多个尺度学习有效的特征,以实现鲁棒的特征提取。基于CNN 的方法通常模型的参数和MACs 较高,且CNN 专注于对相邻像素间的关系进行建模,对面部全局信息的掌握有漏洞。Alexey 等[4]将Transformer 引入计算机视觉任务中,提出视觉Transformer(vision transformer,ViT)网络模型。文献[5]将T2T-ViT 模型引入跨年龄人脸识别任务,克服CNN 复杂度高和计算耗时等问题,该方法虽然在全局信息建模中具备良好的性能,但对局部信息提取时效果还待提高。所以,本文将CNN 嵌入到T2T-ViT 模型,利用DSC 获得局部信息,T2T-ViT 捕获人脸全局信息,进而提取丰富的人脸信息。
1.2 人脸特征解耦
为学习判别性强的身份特征,文献[6]介绍了一种隐性因子分析算法,将初始人脸特征表示为年龄分量、身份分量和噪声的线性组合,缓解年龄因素对识别影响。文献[7]用2 个并行全连接层从深度特征中学习身份特征和年龄特征,引入直和模块消除年龄、身份子空间中的冗余特征。文献[8]利用线性规范映射模块获得年龄特征,引入去相关对抗性学习算法降低两者之间的相关性。考虑到特征向量间存在非线性关系,文献[9]利用通道注意力块在高级语义特征空间中非线性分解人脸特征,以学习健壮的身份特征。文献[10-11]将空间注意力机制引入特征分解模块,从空间和通道层次上分配不同的注意权重,提高对年龄特征的表示。空间注意力图通过压缩通道计算,每个通道上的空间注意力权重易分布一致,导致提取的身份特征中包含年龄特征。本文使用多尺度深度条纹卷积来构建空间注意力,单独计算每个通道的空间注意力图,促进注意力权重在空间维度上的动态分布,进而学习鲁棒性强的身份特征。
2 整体框架
跨年龄人脸识别过程中主要的任务是提取不受年龄因素干扰且完整的身份特征。本文提出的整体框架如图1 所示,该模型主要由3 部分组成:DST2T-ViT 网络,MSADM,以及MI 估计器、身份和年龄判别器构成的多任务训练模块。经过不断训练、优化参数来彻底解耦身份、年龄特征。最后使用优化后的模型提取身份特征,将其与数据库中的特征向量计算余弦距离,实现跨年龄人脸识别。

图1 整体框架图Fig.1 Overall framework diagram
2.1 DST2T-ViT 特征提取网络
本文将DSC 与T2T-ViT 相融,设计了DST2T-ViT 的特征提取网络,如图2 所示,主要包含patches嵌入模块(Patch embedding)、Transformer 层和深度可分离卷积模块(DSC Block)。
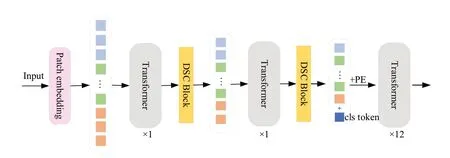
图2 DST2T-ViT 网络结构图Fig.2 Diagram of the DST2T-ViT network architecture
patches 嵌入模块是由卷积层和池化层构成的模块,充分利用了CNN 提取底层特征方面的优势,从特征图中提取patches,克服Transformer 对局部信息建模能力差的问题。具体来说,利用内核大小为7、步长为2 的卷积层提取人脸浅层局部特征,生成32 个通道的特征图,再经过BatchNorm 层稳定模型训练,利用内核大小为3、步长为2 的最大池化层压缩特征图,生成比输入图像小4 倍的特征图以便模型学习更多细节特征。
Transformer 层是ViT 模型基本单元,由多头注意力(multi-head attention,MHA)和多层感知机(multilayer perceptron,MLP)两个子层构成,在每个子层周围采用残差连接,Transformer 层被用于对脸部上下文信息进行建模。多头注意力子层使用多组注意力权重,学习不同的语义信息。对于头数为h的注意力子层,输入特征使用线性变化得到Query、Key、Value 向量,计算公式为
其中,l∈{1,…,L}代表Transformer 层数,i∈{1,…,h}代表头数,LN为线性变化,不同的l有不同的权重参数,Dh=D/h表示每个注意力头的维度。然后不同头q(l,i),k(l,i),v(l,i)并行计算放缩点积注意力,最后将放缩点积注意力结果拼接再次投影作为最终的输出。计算过程为
其中,σ为激活函数,增强特征间非线性关系。MLP 层通过两个全连接和GeLU 激活函数将数据映射到不同维度空间,学习面部更加抽象的特征。两个子层周围使用残差连接防止信息丢失。
深度可分离卷积模块是一种高效的卷积操作,它在通道和空间两个维度上分解传统卷积操作,包含深度卷积和逐点卷积两部分。两个DSC Block 中均使用卷积核为3,步长为2 的深度卷积聚合通道上的局部空间信息,将特征图大小缩放原来的一半,再使用多个1×1 卷积对每个通道的特征图进行逐点线性组合,融合通道之间的信息。该模块在扩展通道容量的情况下,能够有效地减少token 序列的长度。
2.2 多尺度注意力分解模块
为降低特征分解过程中对身份特征造成的损失,构建了MSADM 在高级语义空间中非线性分解混合人脸特征。MSADM 主要分为改进的通道注意力(improved channel attention,ICA)和多尺度空间注意力(multi-scale spatial attention,MSSA)模块,利用ICA 使网络选择性地关注与年龄相关的对象,MSSA 关注重要的空间区域,通过两个维度上动态分布注意力权重学习年龄特征,促进高效的特征分解,结构如图3所示。
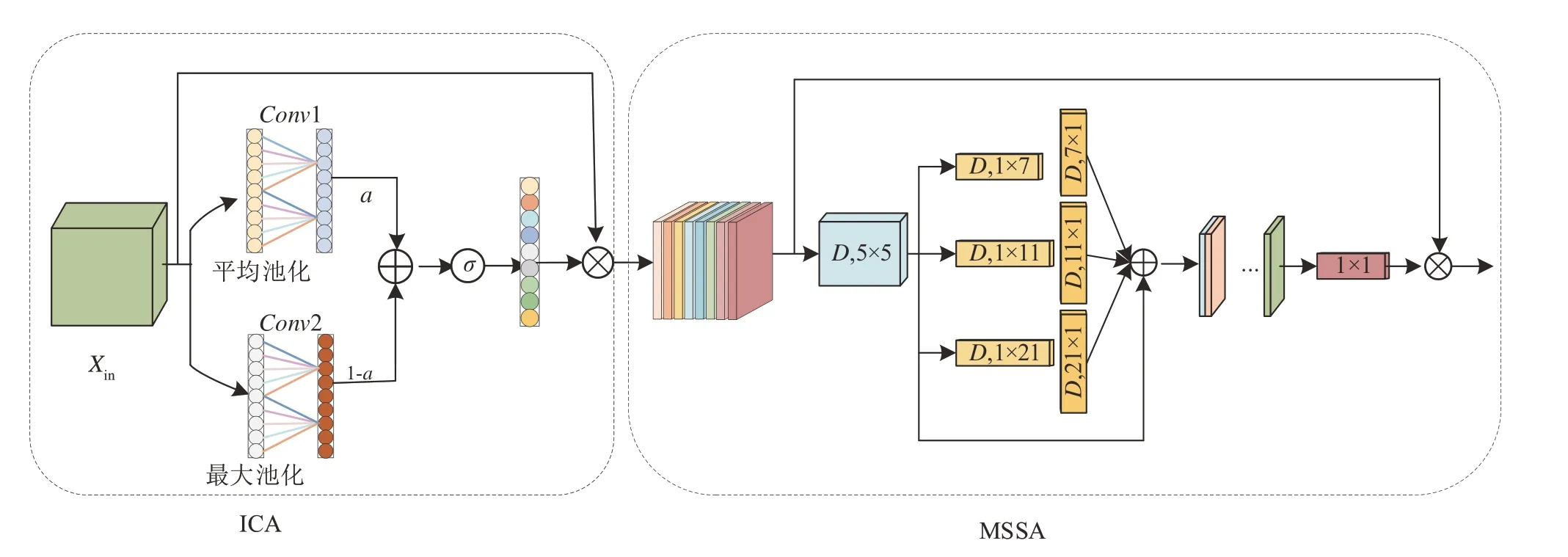
图3 MSADM 结构图Fig.3 Diagram of MSADM structure
2.2.1 改进的通道注意力 ICA 模块将全局平均池化和最大池化并联,利用平均池化保持全局信息的不变性,而最大池化突出对关键通道的关注度,引入可学习参数α对两种池化通道上的特征加权,增强通道上有效特征的选择。ICA 为了克服通道交互过程中部分信息丢失问题,引入一维快速卷积实现跨通道局部信息交互,强化特征图的表示能力。特征图Xin经过ICA 模块的输出表达式为
其中,Xage表示年龄特征,Xin表示初始人脸特征,FGMP,FGAP分别表示最大池化和全局平均池化,Conv1 和Conv2 分别表示两个卷积核为5 的一维卷积,α表示可学习参数,⊗表示张量对应元素相乘。
2.2.2 多尺度空间注意力 MSSA 模块根据不同空间区域对年龄分类结果的贡献,为每个空间位置分配不同的权重,突出特征图中关键年龄结构特征,作为通道注意力的补充。为了在每个通道维度上动态调整空间注意力的权重,本文利用深度卷积来捕捉特征之间的空间关系,确保通道间关系的保留,同时降低计算复杂性。采用多尺度结构来增强卷积运算捕获空间关系的能力。通道混合由1×1 卷积执行,从而生成更精细的注意力图。MSSA 模块的输出表达式为
其中,X′age表示MSSA 模块输出的年龄特征,Xage表示ICA 模块输出的年龄特征,DConv表示深度卷积,Branchi表示第i个分支,在每个分支中,使用两个深度方向的条纹卷积来近似具有大内核的标准深度卷积。每个通道的卷积核大小不同,以捕获多尺度信息。本文将该模块与ICA 模块级联在一起,组成多尺度注意力分解模块,促进年龄特征在高级语义空间中有效的选择。
2.3 多任务训练
本文采用多任务训练约束特征学习,主要有三个基本的约束模块:身份判别器、年龄判别器和MI 估计器。身份特征判别时,使用ArcFace 函数[12]来监督身份特征Xid学习。ArcFace 函数定义为
其中,n表示个体数量,s表示缩放因子,m表示控制角度上的常数间隔项,yi表示第i个样本的身份标签,cosθj表示第i个特征和标签yj的权重向量之间的余弦值。
对于年龄判别器,由于年龄标签存在一定的噪声,遵循文献[5]年龄标签划分为8 个无重复的年龄组,将其作为年龄的类别,使用交叉熵函数评估预测的年龄组与真实年龄组之间的差异。交叉熵函数定义为
其中,N表示年龄组数,zi表示样本i对应的年龄组标签。
MI 估计器用于降低年龄特征Xage和身份特征Xid之间相关性。对于给定的Xage和Xid向量之间的互信息I(Xage;Xid)[13]定 义为
通过最小化I(Xage;Xid)使网络生成对年龄不敏感的身份特征。在人脸特征分解的情况下,条件分布p(Xage;Xid) 无法获取,使用qψ(Xage|Xid) 来近似p(Xage;Xid)。对于给定样本(Xage,Xid),MI 最小化目标函数[14]定义为
其中,N表示训练样本的数量。为了使上界值更加接近真实值,通过最大化相应的对数似然函数进行约束,其定义为
综合式(7)及式(8)-(10),整个网络的多任务训练总函数定义为
其中,λ1和λ2表示平衡三个损失函数的比例系数。
3 实验
3.1 实验设置
3.1.1 数据预处理 使用多任务级联卷积网络(multi-task cascaded convolutional networks,MTCNN)[15]检测人脸图像中的面部区域和关键点,相似性变换对5 个面部关键点进行处理,输入人脸图像被裁剪为112×112 的RGB 图像。最后,通过减去127.5 并除以128对裁剪后的人脸图像像素值进行归一化,如图4所示。

图4 人脸对齐效果Fig.4 Face alignment effect
3.1.2 网络结构 本文的主干使用与T2T-ViT-14类似的网络结构,采用隐藏维度较少但层次较多的深窄结构,利用卷积操作在空间维度上对特征图进行三次放缩,分别放缩为原来的1/4、1/8 和1/16,减少tokens 序列长度的同时,对结构信息进行建模。前两个Transformer 层仅使用一层Transformer,捕获浅层特征中全局信息,Transformer 层中隐藏尺寸和MLP 尺寸均为64,最后一个Transformer 层的深度设计为14,隐藏尺寸和MLP 尺寸分别为384 和1 152,深窄结构设计能够降低模型复杂度,并提升特征表达能力。
3.1.3 训练细节 选用大型的人脸数据集faces emore[16]预训练网络模型,在跨年龄人脸数据集CACD 上微调,实现整个网络的高效训练。采用预训练的年龄估计模型[17]估计训练数据集中人脸年龄信息,提取带有年龄标签的85 742 个个体,共5 774 205 张人脸图像,将年龄信息分为八组:0~12,>12~18,>18~25,>25~35,>35~45,>45~55,>55~65,>65。
模型预训练时,硬件为单卡NVIDIA GeForce RTX 3090,Pytorch1.8.1 版本上搭建模型训练。批尺寸大小设置为512,迭代轮数为25,随机梯度下降法SGD 优化模型参数,初始学习率为0.01,迭代轮数为14、18、22 时,学习率衰减为上一轮的0.1,动量因子为0.9,公式(7)超参数s设置为64,m为0.5,通过反复实验对比,公式(12)中平衡系数λ1和λ2设置为0.1、0.01 时识别性能最优,MI 估计器的学习率最初被设置为1×10-5,在训练时期,编码器前向传播一次,MI 估计器优化5 次。
3.2 实验结果分析
3.2.1 FG-NET 数据集实验结果分析 FG-NET 是跨年龄人脸识别中最受欢迎的人脸老化数据集,包含82 个个体的1 002 张彩色和灰度混合的面部图像,通过扫描0~69 岁个体照片收集。遵循文献[6,11]的设置协议,采用留一法进行交叉验证。具体来说,选择一张图像作为测试数据,剩下的1 001 张人脸图像上微调模型,重复该过程1 002 次,并报告平均等级1 识别率。考虑到数据集中的每个受试者都有多个不同年龄的人脸图像,该评估策略可以很好地反映识别模型的性能。
本文方法在FG-NET 数据集上与现有的跨年龄人脸识别方法的比较如表1 所示,从表1 可知,本文方法相比其他方法具有更高的准确率,识别准确率达到了94.97%,比当前最优方法提高了0.19%。图5 可视化了检索失败的人脸图像。检索失败的图像主要位于0~12 岁的婴儿和儿童,在预训练数据集faces emore 中未成年人脸图像占比较少,甚至用于微调模型的CACD 数据集中都不包含0~12 岁之间的人脸图像,对于试图通过数据驱动方法学该特定年龄组的潜在分布来说,存在一定局限性。
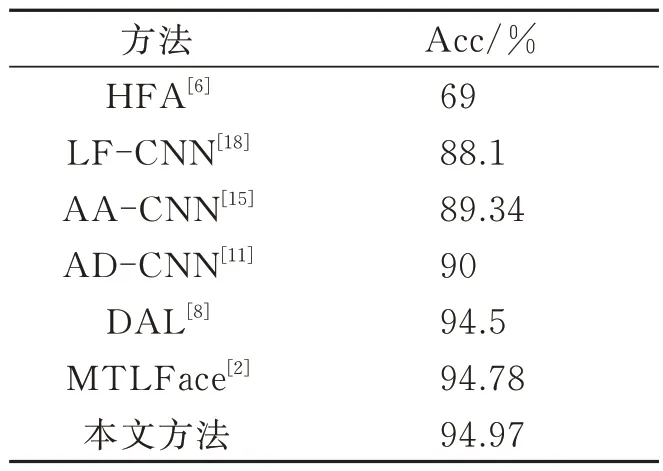
表1 不同方法在FG-NET 数据集上对比结果Tab.1 Comparison results of different methods on FGNET dataset

图5 错误检索的人脸图像Fig.5 Incorrectly retrieved face images
3.2.2 CACD-VS 数据集实验结果分析 CACD-VS 由年龄在16 至62 岁之间、2 000 位明星的163 446 张人脸图像组成,来源于互联网上各种光照条件、不同姿势和化妆效果下的人脸图像,能够有效反映跨年龄人脸识别算法的鲁棒性。CACD-VS 是CACD 的一个子集,包含了4 000 对用于人脸验证的人脸图像,其中包括2 000 对正样本图像和2 000 对负样本图像。本文严格遵循文献[18]实验设置,在CACD-VS 进行实验评估。考虑到公式(12)中超参数λ1和λ2会影响模型性能,分别设置λ1,λ2为{1,0.1,0.01,0.001},在CACD-VS 数据集进行验证,以探索其合理的取值。图6 为不同取值时人脸验证的准确率,表明了当λ1=0.1 和λ2=0.01 时模型获得了最佳性能。本文方法与现有方法的Acc 和AUC 的对比见表2,从表2可知,在两种评价指标中本文方法均不小于现有的模型,精确度达到了99.51%,超过现有最高模型0.16%,表明了本方法在稳健性方面的优越性。

表2 不同方法在CACD-VS 数据集上对比结果Tab.2 Comparison results of different methods on CACD-VS dataset
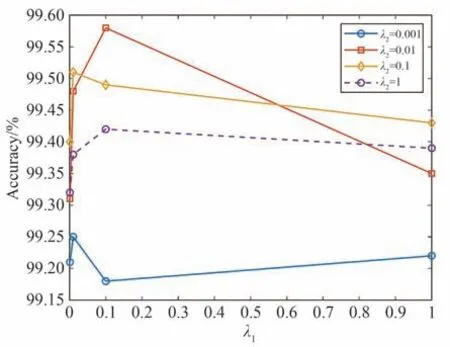
图6 不同λ1、λ2 值的人脸验证准确率曲线图Fig.6 The accuracy curve of face verification with different λ1 and λ2 values
3.2.3 CALFW 数据集实验结果分析 CALFW 数据集专为具有显著年龄差异的无约束人脸验证设计,包含了4 025 个个体的12 176 张人脸图像,每个个体至少2 张图片,挑选了600 对年龄差距相同的正样本图像和600对性别相同且种族不用的负样本图像,使用Acc 和EER指标评估本文方法的性能。如表3 所示,本文的方法在CALFW 数据集上识别准确率达到了95.81%,创造了CALFW 数据集上的最新记录。由于该数据集中缺少年龄信息,模型的训练和微调过程均无其参数,故在该数据进行实验评估,充分验证了本文方法在泛化能力方面的优越性。
3.2.4 消融实验结果分析 为了展示所提模块的有效性,遵循前文的参数设置,在FG-NET、CACD-VS 和CALFW数据集上设计了4 组对比模型。
(1)Baseline1:直接采用T2T-ViT 网络提取初始人脸特征,ArcFace 函数作为身份判别器监督训练。
(2)Bseline2:将DSC 引入T2T-ViT 网络中提取特征。
(3)Baseline3:改进的T2T-ViT 网络中增添了MSADM,在高级语义空间中非线性分解初始人脸特征,年龄特征通过交叉熵损失函数约束学习。
(4)Our:本文提出的模型,在Baseline3基础上,添加了MI 正则化算法去除身份、年龄之间的相关性,MI 估计器与身份、年龄判别器同时监督训练。如表4 所示,Baseline1 简单地使用传统的T2T-ViT 网络提取身份特征进行识别,在三个数据集上的识别效果差,将DSC 模块嵌入到T2T-ViT 网络,三个数据集识别准确度分别提升0.65%,0.49%,0.71%,表明了DSC 可以弥补Transformer 模型对底层局部特征表达不足缺陷。Baseline3 中添加了特征分解模块和年龄损失函数约束,识别性能得到了一定的提升,验证了MSADM 模块能够突出年龄相关的信息,有效地降低年龄因素对身份识别的干扰。本文方案在Baseline3 基础上又添加了MI 判别器约束身份、年龄特征分解,模型性能都得到极大提升,说明了本文方法对年龄变化具有较强鲁棒性。
4 总结
本文基于多任务学习的方法,提出使用DST2T-ViT 网络提取人脸面部特征,该网络将DSC 模块嵌入T2T-ViT 网络,获取更多局部底层特征信息。为了捕获完整的身份信息,设计了MSADM 在高级语义空间中非线性地解耦面部特征,MI 最小化算法对年龄特征和身份特征进行相关系约束,以实现高效、精准的特征分解。3 个基准数据集取得良好的实验结果,证明模型在识别性能上的先进性。同时,经过实验发现,由于公开的基准数据集存在未成年人脸图像的缺乏问题,模型无法充分学习和表示未成年人脸的独特特征,导致涉及未成年人脸识别时,准确率下降,未成年人脸特征学习将是下一步研究重点。
