校园安防巡视车载可视与智能化系统方案研究
2024-01-26李鹏赵天垚
李鹏 赵天垚









摘要:文章采用车辆全景视图拼接技术与3D车道线检测技术来实现车辆行驶过程中,对车道线进行识别,并判断车辆是否在车道线范围内行驶(是否压线),同时结合车载雷达自动规避障碍物的需求。利用车辆全景视图拼接技术,将车辆上所有摄像头的图像进行拼接与变换,最终转换到全景的鸟瞰图下进行显示。利用车道线检测技术可以识别车身周围的车道线,并判断车辆的行驶状况和是否压线。最终可以满足车辆全景可视与智能化的需求。
关键词:校园安防;全景视图;车载可视化
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2023)35-0113-05
开放科学(资源服务)标识码(OSID)
1 研究现状
1.1 车载环视图拼接
车载环视图拼接技术是一种车载多摄像头系统,它可以将车辆周围的多个摄像头的视频流拼接成一个全景图像,以提供更好的驾驶体验和安全性。目前,车载环视图拼接技术已经得到了广泛应用,例如在无人驾驶、智能交通、智能网联汽车等领域。目前,车载环视图拼接技术的研究主要集中在算法优化、硬件设计、标定方法等方面。
根据车辆的大小设计4个鱼眼摄像头。在获得每个摄像机的图像后,需要通过特定的算法来处理图像,将每个通道的图像合成在一个坐标系中。同时每个图像通过车载雷达来避开障碍物识别路上的标线[1]。
日本一家公司早年研发了一个名为Around View Monitor(AVM) 的全景影像系统。这套系统采用的是 4 个普通的摄像头来获取图像,但是此系统并没有对图像合成建立细致的模型,只是将图像拼接后改为俯视效果,再按照摄像机的位置对应展现,如图1所示,存在的问题都是每个摄像头结合处都有一条明显的缝隙。
后期日本丰田汽车公司研发了名为 PVM的全景视频系统,系统在调整摄像机安装位置时,摄像机之间有重叠部分,最终全景效果要比AVM系统更好,同时消除了摄像机之间的接缝。
随后,相关领域的工程师设计了基于DSP技术、鱼眼摄像头的拼接系统。经过不断的技术革新,对多摄像头的图像拼接正确率进行了优化改进,但是大多数全景图像效果仍然差强人意。
1.2 车道线检测
车道线检测技术是自动驾驶技术中的一个重要模块,它可以通过摄像头获取道路上的车道线信息,以帮助车辆实现自动驾驶。通过建立一定的数学模型便可以让安防小车准确识别标志线,并实现车道保持行驶。
2D车道线检测检测图像平面中的车道线,并用相机位姿将它们投影到3D空间。一般来说,先进的单目车道线检测器可以分为分割方法和回归方法。
SCNN将传统的深层逐层卷积推广到特征图中的切片逐层卷积,实现一层中跨行和列的像素之间的消息传递。LaneNet介绍了一种用于目标检测的实例分割方法,该方法结合了二进制分割分支和嵌入分支。SAD 允许目标检测网络加强本身的表示学习,无需额外的标签和外部监督。RESA通过反复移动切片的特征图来聚合垂直和水平方向上的信息。
车道回归算法可以分为关键点估计、基于锚点的回归和逐行回归。PINet结合了关键点估计和实例分割,GANet将车道表示为一组只与起点相关的关键点。PointLaneNet和CurveLaneNAS将图像分成不重叠的网格,并根据垂直锚点回归车道。Line-CNN和LaneATT在预定义的射线锚上回归车道,而CLRNet通过金字塔特征动态细化射线锚的起点和角度。UltraFast引入了一种新的行分类方法,具有显著的速度。Laneformer应用行列自注意力来适应传统的Transformer来捕获车道的形状特征和語义上下文。
除了点回归外,多项式回归也是2D车道检测任务的一种方法。PolyLaneNet 使用全连接层直接预测图像平面中车道的多项式系数。PRNet将车道检测分解为多项式回归、初始分类和高度回归三部分。LSTR引入了一种基于Transformer 的网络来预测反映道路结构和相机姿势的路参数。
3D车道线检测最近引起了比2D车道线检测更多的关注,原因是后者缺乏深度信息和空间变换的结果存在错误传播问题。3DLaneNet是一种基于网络内逆透视映射和基于锚的视觉表示的双路径架构。3D-LaneNet+将Bev特征划分为不重叠的单元,并通过回归相对于单元中心、线角和高度偏移的横向偏移距离来检测通道。Gen-LaneNet首先在虚拟顶部视图坐标帧而不是自我车辆坐标帧中引入新的数学几何引导的车道锚点,同时引用既定的数值几何转换直接计算网络输出的 3D 车道线点。CLGo用Transformer替换CNN主干来预测相机姿势和多项式参数。Persformer构建了一个具有已知相机姿势的密集Bev查询,并在一个框架下统一了2D和3D边缘检测。
2 实现过程
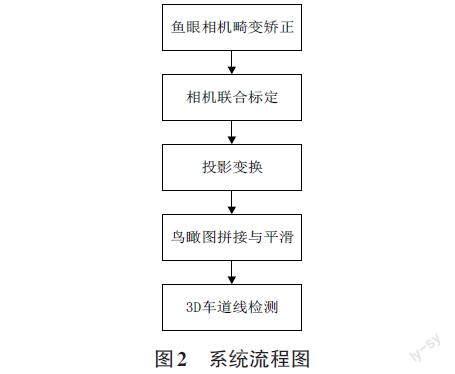
首先需要在车身周围安装足够数量的鱼眼相机(以8个为例),使得每相邻两个相机之间具有重合区域。具体的系统处理流程图如图2所示:
2.1 鱼眼相机畸变矫正
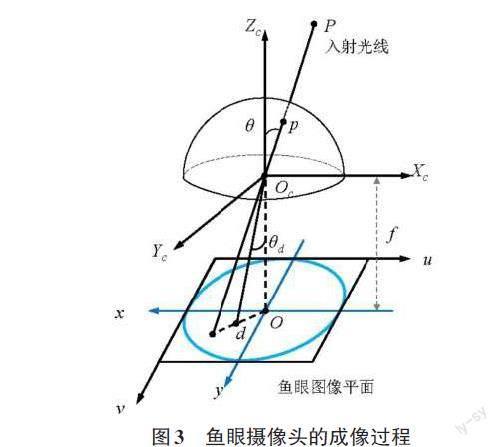
鱼眼摄像头的成像模型可转化为单位球面投影模型。一般将鱼眼摄像头成像过程分解成2步:先将立体空间的坐标点线性的投影到虚拟球面上;再将虚拟球面上的点非线性地投影到水平图像层[2]。
鱼眼摄像头合成图像存在畸变,而且畸变主要为径向畸变。
鱼眼摄像头的成像过程如图3所示。实验过程中发现,鱼眼摄像头生产过程中不能精确地设计投影模型,为了解决鱼眼相机的标定难题,Kannala-Brandt提出了一般多项式近似模型。[θd]是[θ]的奇函数,将这些式子按泰勒级数展开,[θd]用[θ]的奇次多项式表示,即:
[θd=k0θ+k1θ3+k2θ5+...]
取前5项,给出了足够的自由度来很好的近似各种投影模型:
[θd=k0θ+k1θ3+k2θ5+k3θ7+k4θ9]
下面给出空间点到图像的投影过程。假设[P=(X, Y, Z)]为世界坐标系下一个三维坐标点,变换到相机坐标系下为[(XC, YC, ZC)]:
[XCYCZC=RXYZ+T]
转换到相机坐标系下归一化坐标点:
[x=XCZCy=YCZC]
计算[θ]角:
[r=x2+y2θ=atan(r,)]
根据直角三角形的正切计算公式可以推断。r为物体通过鱼眼镜头投放在虚拟平面的像高,即物体中像素点到主点的距离。
利用KB畸变模型进行加畸变优化处理:
[θd=θ(k0+k1θ2+k2θ4+k3θ6+k4θ8)]
计算该点在图像物理坐标系中的坐标:
[x'=(θd/r)xx'=(θd/r)y]
最终得到图像像素坐标:
[u=fx(x'+αy')+cxv=fyy'+cy]
[α]是扭曲系数,[fx]、[fy]、[cx]、[cy]是鱼眼镜头的内参矩阵。
接下来介绍去畸变的过程。首先获取每个相机的内参矩阵与畸变系数。在地面上铺上一张标定布,并获取各路视频的图像,利用标定物来手动选择对应点获得投影矩阵,如图4所示。
鱼眼相机去畸变问题一般使用张正友棋盘格标定法,首先通过矩阵推导获得一个初始值,最后通过非线性优化获取最优解,包括鱼眼相机的内外参数、畸变系数,然后针对图像做去畸变处理。
优化后的图像可以发现图像较为自然,畸变优化明显。噪点较少、4个摄像头成像后的边界交汇点无黑线,如图5所示。
2.2 多路摄像头联合标定
至此需要获取每个相机到地面的投影矩阵,此模型会把摄像机校正后的画面转换为对投影图上某个矩形区域的俯视图。然后通过联合标定的形式在巡逻车四周的摄像头下摆放标定物,截取图像手动获得标定点,计算投影矩阵。
2.3 多摄像机投影变换
相机从2个不同的角度拍摄同一个平面,两个相机拍摄到的图像之间投影变换矩阵H(单应矩阵)为:
[H=K(R+T1dNT)K-1]
其中,K为相机内参矩阵,R、T为两个相机之间的外参。
2.4 鸟瞰图的拼接与平滑
将各路鱼眼相机拍摄到的图像,投影到汽车正上方平行于地面拍摄的相机平面上,从而得到鸟瞰图。
然而,由于相机之间有重叠的区域,通过简单的加权平均会导致拼接结果出现乱码和重影,如图6所示。
需要进行平滑处理。先取出投影重叠部分,进行灰度化和二值化处理,利用形态学方法去掉噪点,得到重叠区域的mask。最后将mask加入拼接当中[3-6]。
2.5 3D车道线检测
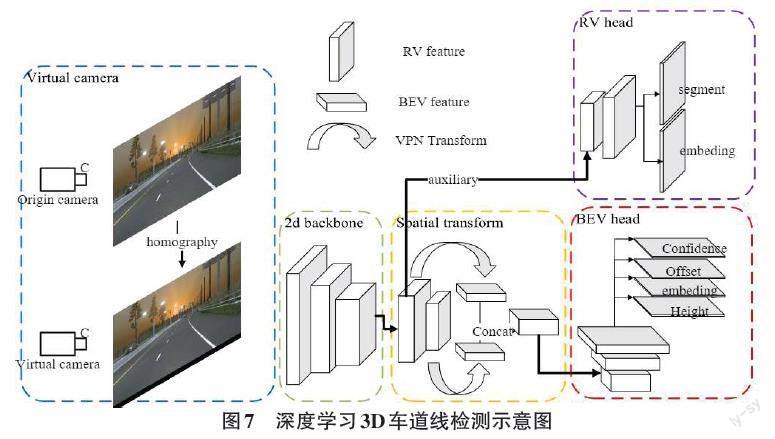
对于车道线检测,考虑采用基于深度学习的检测方法。首先采集数据,获取各路视频的图像数据,并进行标注,得到训练数据集。在数据集上训练深度学习模型,该模型可以端到端地输出检测到的车道线信息,如图7所示。
3 程序实现部分
通过Python实现环视系统中相机的安装位置标定、透视变换,同时使用OpenCV技术在AGX Xavier的无线控制车上实现。
小车上搭载了4个 USB 环视鱼眼摄像头,相机传回的画面分辨率为 640×480,图像首先经过畸变校正,然后在射影变换下转换为对地面的鸟瞰图,最后拼接起来,经过平滑处理后得到了图8的效果。全部过程在 CPU中进行处理,整体運行流畅。
系统的若干约定。为了方便起见,笔者对4个摄像机分别用front、back、left、right来代表,并假定其对应的设备号是整数,例如0、1、2、3相机的内参矩阵记做camera_matrix,这是一个3×3的矩阵。畸变系数记做dist_coeffs,这是一个1×4的向量。相机的投影矩阵记作project_matrix,这是一个3×3的射影矩阵。
获得原始图像与相机的内参步骤。首先需要获取每个相机的内参矩阵与畸变系数。通过运行脚本run_calibrate_camera.py,告诉它相机设备号,是否鱼眼相机,以及标定板的网格大小,然后手举标定板在相机面前摆几个姿势即可。以下是视频中4个相机分别拍摄的原始画面,顺序依次为前、后、左、右,并命名为front.png、back.png、left.png、right.png保存在项目的images/ 目录下。
4 个相机的内参文件分别为ront.yaml、back.yaml、left.yaml、right.yaml,这些内参文件都存放在项目的yaml子目录下。可以看到,图中地面上铺了一张标定布,这个布的尺寸是 6m×10m,每个黑白方格的尺寸为40cm×40cm,每个圆形图案所在的方格是80cm×80cm。将利用这个标定物来手动选择对应点获得投影矩阵。
设置投影范围和参数。接下来需要获取每个相机到地面的投影矩阵,这个投影矩阵会把相机校正后的画面转换为对地面上某个矩形区域的鸟瞰图。这4个相机的投影矩阵不是独立的,它们必须保证投影后的区域能够正好拼起来。这一步是通过联合标定实现的,即在车的四周地面上摆放标定物,拍摄图像,手动选取对应点,然后获取投影矩阵。如图9所示,首先在车身的4角摆放4个标定板,标定板的图案大小并无特殊要求,只要尺寸一致,能在图像中清晰看到即可。每个标定板应当恰好位于相邻的两个相机视野的重合区域中。
在上面拍摄的相机画面中,车的四周铺了一张标定布,这个具体是标定板还是标定布不重要,只要能清楚地看到特征点即可。
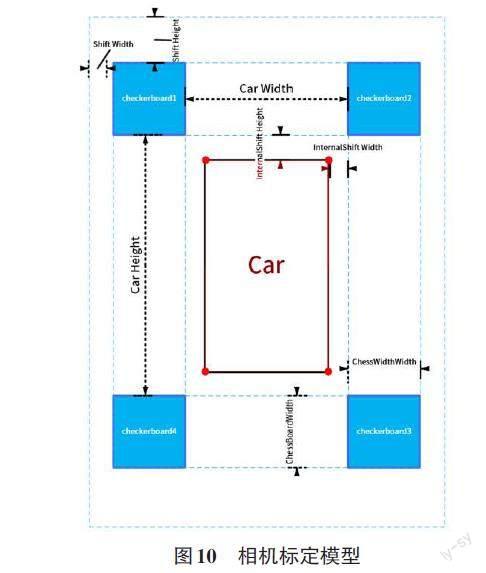
然后需要设置几个参数(如图10所示):
innerShiftWidth , innerShiftHeight :标定板内侧边缘与车辆左右两侧的距离,标定板内侧边缘与车辆前后方的距离。
shiftWidth , shiftHeight :这两个参数决定了在鸟瞰图中向标定板的外侧能看多远。这2个值越大,鸟瞰图的范围就越大,相应的,远处的物体被投影后的形变也越严重,所以应酌情选择。
totalWidth , totalHeight :这2个参数代表鸟瞰图的总宽高,在这个项目中,标定布宽 6m,高10m,于是鸟瞰图中地面的范围为 (600 + 2 * shiftWidth, 1000 + 2 * shiftHeight) 。为方便计算,让每个像素对应1cm,于是鸟瞰图的总宽高为:
totalWidth = 600 + 2 * shiftWidth
totalHeight = 1000 + 2 * shiftHeight
车辆所在矩形区域的四角 (图中标注的红色圆点),这4个角点的坐标分别为 (xl, yt) , (xr, yt) ,(xl, yb) , (xr, yb) ( l表示 left, r表示right,t表示top,b表示 bottom)。这个矩形区域相机是看不到的,用一张车辆的图标来覆盖此处。
注意这个车辆区域四边的延长线将整个鸟瞰图分为前左 (FL)、前中 (F)、前右 (FR)、左 (L)、右 (R)、后左(BL)、后中 (B)、后右 (BR) 8个部分,其中 FL (区域 I)、FR (区域 II)、BL (区域 III)、BR (区域 IV) 是相邻相机视野的重合区域,也是重点需要进行融合处理的部分。**F、R、L、R** 4个区域属于每个相机单独的视野,不需要进行融合处理。以上参数存放在 param_settings.py 中。
设置好参数以后,每个相机的投影区域也就确定了,比如前方相机对应的投影区域如图11所示,接下来需要通过手动选取标志点来获取地面的投影矩阵。
随之需要确定以下参数:
-camera : 指定是哪个相机。
-scale : 校正后画面的横向和纵向放縮比。
-shift : 校正后画面中心的横向和纵向平移距离。
因为默认的 OpenCV 的校正方式是在鱼眼相机校正后的,图像裁剪出一个 OpenCV “认为”合适的区域并将其返回,这必然会丢失一部分像素,可能会把希望选择的特征点裁掉。新的内参矩阵,对校正后但是裁剪前的画面作一次放缩和平移。可以尝试调整并选择合适的横向、纵向压缩比和图像中心的位置,使得地面上的标志点出现在画面中舒服的位置上,以方便进行标定。标定完成后图像如图12所示。
然后依次点击事先确定好的4个标志点,如图13所示。
这4个点是可以自由设置的,但是需要在程序中手动修改它们在鸟瞰图中的像素坐标。当在校正图中点击这4个点时,OpenCV 会根据它们在校正图中的像素坐标和在鸟瞰图中的像素坐标的对应关系计算一个射影矩阵。这里用到的原理就是4点对应确定一个射影变换 (4点对应可以给出8个方程,从而求解出射影矩阵的8个未知量。注意射影矩阵的最后一个分量总是固定为 1) 。显示投影后的效果图14所示。
标定最后的实现效果如图15所示。
4 总结
本项目设计了一个校园安防检测智能车全景可视与智能化系统,包括车辆全景视图拼接与3D车道线检测。首先需要在车辆四周安装足够的鱼眼相机,保证范围的全覆盖以及相邻相机之间存在重合区域;对于每个相机,进行相机内参标定以完成去畸变过程,并依次进行相机联合标定、投影变换、鸟瞰图拼接与平滑,得到车辆全景的鸟瞰图。最后采集数据训练端到端的3D车道线检测模型,实现对车道线的检测。
参考文献:
[1] 赵小松.全景泊车辅助系统的算法研究[D].西安:西安电子科技大学,2015.
[2] 杨前华,李尤,赵力.基于改进球面投影模型的鱼眼图像校正算法的研究[J].电子器件,2019,42(2):449-452.
[3] 张东,余朝刚.基于特征点的图像拼接方法[J].计算机系统应用,2016,25(3):107-112.
[4] 刘敏,周聪,汤靖博.基于SIFT图像配准算法优化研究[J].湖北工业大学学报,2020,35(2):32-36.
[5] 吴乐富,丁广太.基于区域的图像拼接算法[J].计算机工程与设计,2010,31(18):4044-4046,4050.
[6] 何惠洋.车载全景环视系统中的图像拼接技术研究[D].西安:西安工业大学,2020.
【通联编辑:唐一东】
