基于深度学习的变电设备铭牌文本提取算法
2024-01-23卫良润杨柳林
卫良润,杨柳林
(广西大学 电气工程学院,广西 南宁 530004)
0 引 言
随着中国电网的不断扩建与更新,变电站中电力设备的种类和数量越来越多,电力设备铭牌记录了该设备以及台账的主要信息内容,包括制造商名称和基本电气参数等[1]。根据供电局生产部门的需求,对电力设备铭牌信息进行采集,可以有效解决项目资料收集校准、智能运维等需求。而现阶段的采集方法(人工、智能)都不同程度地存在效率不高、精度不够等问题。对变电设备铭牌通常使用硬件设备采集得到大量的图片,因此本文拟将智能的图像文本提取技术应用于铭牌信息提取任务,将该技术应用到数据采集的设备中,以改善变电设备数据收集效率低的现状,提高电力系统数据管理水平。
变电设备铭牌文本提取任务源于自然场景文本提取,通常分为文本检测和文本识别两个阶段进行。文本检测定位提取出图像中是文本的区域;文本识别则是将文本区域中含有的文本信息“翻译”成字符输出。将文本检测和文本识别任务独立进行的方法称之为两阶段方法,而合并在一起同时运作的方法称之为端到端的方法。
传统方法中常使用边缘检测[2]、连通域计算[3]、预设模板[4]实现铭牌文本检测任务,对于文本识别任务常用基于字符分割[5-6]的识别方法。文献[2]提出一种基于“霍夫变换”的图形角度纠正预处理方法,以提高后续任务准确率。文献[3]使用Retinex 算法提高图像质量,利用MSER 和Graham 算法进行文本位置定位。文献[4]提出一种基于模板的电气铭牌识别方法。文献[5]提出一种I_CNN 的单字符识别方法。文献[6]提出一种传统的字符分割的文本识别方法。总体来说,传统方法仅适用于理想化、固定且相对简单的场景,在稍微复杂的场景中鲁棒性较差。
文献[7-8,11,13]以YOLOv3 算法为基础框架实现文本检测任务。文献[9,12,15]改进CTPN 算法提高了在倾斜文本上的检测效果。文献[10,19]在文本检测任务中使用EAST 方法改进非极大抑制后处理方法,提高了长文本检测效果。文献[14]提出基于MobileNet v3 骨架搭建移动端文本检测算法,构建了一套发动机铭牌数据集,该数据集并未公开。文献[18]提出一种端到端的文本提取方法—TDRN,文本检测分支使用CTPN 网络,文本识别分支引入BLSTM和注意力机制。
上述深度学习方法中,多数文本检测使用CTPN,少数使用EAST,但存在长文本检测不全、倾斜文本检测效果不佳、对图片背景要求简单等问题。以往文本提取研究使用的是两阶段方法,不如端到端方法简洁,还有训练流程复杂、文本提取时间长等缺点。此外,目前缺少可靠的电气设备铭牌公开数据集。针对上述问题,本文提出了一种端到端的图像文本提取算法,使用RoIRotate 模块将文本检测和文本识别合并为一个任务。
1 方法框架
传统的文本检测和识别方法以及一些深度学习的文本提取方法包含多个独立步骤,处理过程复杂且耗时。这些方法中因文本检测和识别过程是分开进行的,训练过程无法相互监督,也会导致偏差积累。本文基于FOTS 算法[20]提出一个端到端的单阶段变电设备铭牌文本提取方法。本文方法创新性地将文本检测和文本识别任务合并为单个任务,同时也避免了多阶段方法训练步骤繁琐的问题。文中算法主要分为四个部分:共享特征提取模块、文本检测分支、RoIRotate 操作和文本识别分支。方法的总体架构如图1 所示。首先对铭牌图像进行特征提取,利用该特征进行文本位置定位;再通过RoIRotate 操作将图像中定位得到的文本区域特征转换为文本识别分支所需输入格式,文本识别分支输出最终铭牌文本信息。
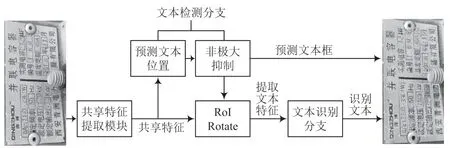
图1 文本提取方法整体框架
1.1 共享特征提取模块
为确保电力设备铭牌图像中的文本检测和文本识别准确性,需要提取足够的深层语义信息和浅层表征信息。为此,使用了ResNet-50 作为共享特征提取模块,其多层残差设计和U 型网络结构借鉴了特征金字塔(FPN)的设计,能够提取多尺度的图像特征,并避免了梯度爆炸的问题。最终得到的特征尺度分别是原图尺寸下采样4 倍、8 倍、16 倍和32 倍。
1.2 文本检测分支
特征提取模块的输出数据通过1×1 卷积层进行逐像素预测文本位置,输出六个通道数据,其中第一个通道为文本概率分类,剩下四个通道预测每个正样本像素的文本边框距离,第六个通道预测文本边框的倾斜角度。使用位置感知非最大抑制(LNMS)操作去除重复文本框,最终得到文本概率和位置信息。
居民在人生的不同阶段对于理财的要求具有很大差异,不同的人群风险偏好也有所不同,所以投资者需要的理财产品存在较大的差异,但是我国目前的理财产品却存在较大的同质性问题。要想开发更为广阔的市场为更多的投资者服务,就应当促进理财产品的创新,吸引不同的投资者。在理财产品创新方面,应当根据不同的风险偏好、不同的个人财务状况、不同的生命周期,对客户需求进行多种产品设计。
1.3 RoIRotate 操作
文本识别分支需要将横向序列特征作为输入,但变电设备铭牌图片中的文本通常是不定向、矩形的,而检测分支输出的文本框也是如此。为此,使用RoIRotate 操作将检测分支输出的尺寸不固定且方向不定的文本区域转换为高度固定、水平展开的特征区域,同时具有旋转不变性,保留了文本区域原有的细节特征。该过程包括两个主要步骤:提取仿射变换参数和通过双线性插值对每个区域进行仿射变换。
1.4 文本识别分支
通过RoIRotate 操作转换检测分支预测的文本区域,使用文本识别分支提取共享特征信息进行文本序列预测。文本识别分支包括VGG-like 序列卷积、仅沿高度轴缩放的池化、双向LSTM、全连接层和CTC 解码器,如图2 所示。利用CNN 和LSTM 对序列信息进行编码,然后使用CTC 解码器预测区域信息。
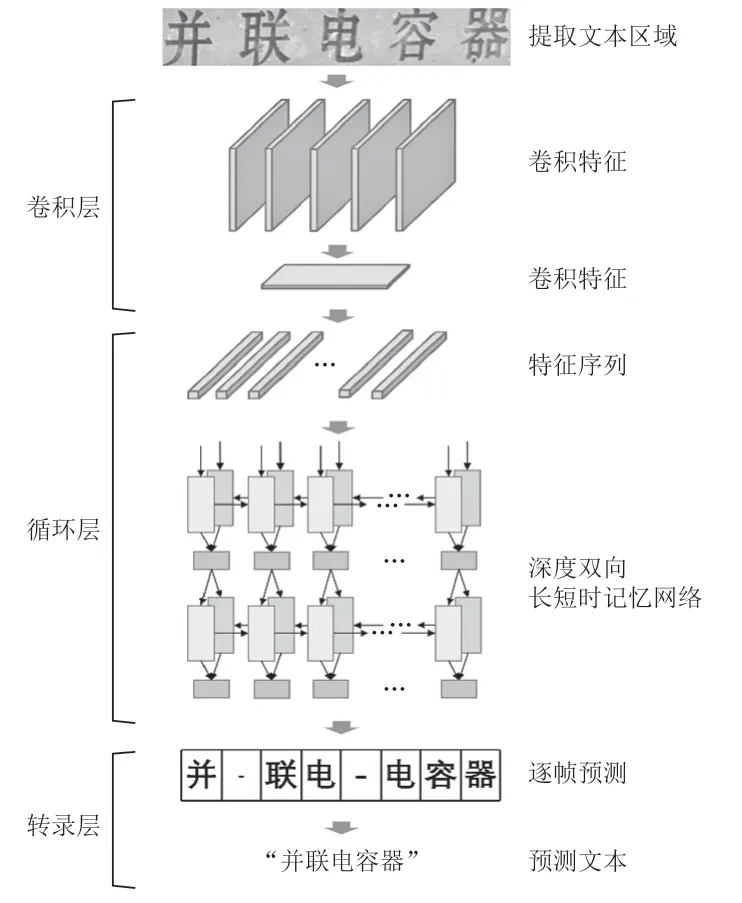
图2 基于CRNN 结构的文本识别分支
2 损失函数
本文方法总训练损失为:
式中:LD为检测分支的损失;LR为识别分支的损失;λ为平衡参数,在预训练阶段λ被设置为0.01,在微调阶段λ被设置为0.1。
2.1 文本检测分支损失函数
文本检测分支损失函数表示为:
式中:Lcls为分类损耗,使用Dice 损失函数计算;λd为平衡参数,在实验过程中设置为1;|·|为内部像素个数;和G*分别表示网络的预测矩阵和文本标签值矩阵;为两个矩阵之间重叠的像素个数;LRT为矩形框损失,通过交并比IoU 损耗进行计算;为预测的文本矩形框面积;Q*为标签框面积;Lα为旋转角度损失;λg为平衡参数,在实验过程中设置为20;α*为标签框的角度;为预测文本矩形的角度。
2.2 文本识别分支损失函数
识别分支损失LR通过CTC loss 进行计算,公式为:
式中:LR为识别损失函数,由p(y*|x)的负对数似然函数构成;N为文本预测区域的个数;x为标签序列;y*为目标标签序列;p(y*|x)为预测标签序列x为y*的条件概率。
3 数据集
本文针对变电设备铭牌的特点,在训练的不同阶段选择了对应的训练数据集。
360 万中文数据集:包含5 990 个字符,使用新闻和文学文本生成364 407 张280×32 的随机图像。本文将字符库数量扩展到6 007 个,旨在预训练文本识别模型,示例如图3(a)所示。

图3 训练数据集
ICDAR2017-RCTW-17[21]:ICDAR 是国际文本识别和识字竞赛的简称。RCTW-17 是一个真实世界中文文本检测和识别数据集,包含1.2 万张带有中文文本的图像,涵盖手写、印刷、混合和变形文本,训练集8 034 张,测试集4 229 张。该数据集用于端到端的预训练模型,示例如图3(b)所示。
合成铭牌数据集(SN):主要分为文字和背景两个部分。文字部分采集电力铭牌上的真实标签构成基础语料库,并进行随机组合扩充,再进行字体、大小随机变化。随机位置写入背景图像后,对合并后文本进行噪音、模糊、透视、拉伸等随机变化,共合成104 890张图像。该数据集为端到端标注,标签文件同时包含了文本坐标和文本内容。该数据集被用于端到端的预训练模型,示例如图3(c)所示。
真实变电设备铭牌数据集(RSEN):包括786 张图像,标注格式与合成数据集相同;为避免过拟合,进行了随机图像处理(噪声、模糊、色调、旋转、裁剪),并得到15 720张图像。数据集按9 ∶1 分为训练集和测试集。该数据集被用于模型端到端的微调训练,示例如图3(d)所示。
4 实验与分析
4.1 训练方案
4.1.1 数据预处理
为了提高模型鲁棒性,需要对电力设备铭牌图像进行预处理,这包括读取标签和图像数据、随机增强(添加噪声、模糊和颜色调整)以及随机缩放、旋转和裁剪等技术。具体而言,将原始铭牌图像按比例(0.8、0.85、0.9、0.95、1.0、1.1、1.2)随机缩放并旋转,最后裁剪尺寸为512×512,并缩放到所需大小。
4.1.2 训练细节
首先在360 万中文数据集上预训练5 个epoch 的模型,再使用RCTW-17 中文场景数据集进行7 个epoch 的端到端训练,然后使用合成铭牌数据集进行5 个epoch 的最后预训练得到最终的预训练模型,最后在真实变电设备铭牌数据集上进行微调直至收敛。训练过程中忽略一些模糊的文本区域和非重要的文本区域,将其标记为“DO NOT CARE”,避免影响参数训练。预训练过程中360 万中文数据集仅训练识别分支,而其余数据集训练过程中同时训练检测和识别分支,即端到端训练。
本文预训练和微调阶段实验的训练平台操作系统为Ubuntu 20.04 LTS,采用Tensorflow 1.15.1版本的深度学习框架,CPU 为Intel(R) Xeon(R) Gold 6330 CPU @ 2.00 GHz,GPU 为NVIDIA GeForce RTX 3090。在该模型的训练过程中,使用Adam 优化器进行损失优化,初始学习率设置为0.001,迭代中学习率呈指数下降,衰减指数设置为0.997。
4.2 消融实验
4.2.1 评估指标
在实验之前,需要引入一些指标。检测精度和查全率是衡量文本检测算法性能的两个标准指标,分别表示为:
式中:Precision 为检测精度;Recall 为查全率;G为图中实际有多少文本目标;P为模型检测出多少文本目标;T为正确检测的文本目标个数。
此外,通过F-measure 评价检测精度和查全率的贡献,F-measure 是这两个指标的总和平均值,表示为:
在文本识别任务中,评价对象为:整个图片上所有被正确检测到的文本区域。如果一个文本区域中的所有文本都被正确识别,则记录阳性样本;否则,记录阴性样品。指标为
式中:R-Precision 为识别精度;K为阳性样本总数;F为阴性样本总数。
4.2.2 实验分析
针对真实变电设备铭牌数据集的测试集中的测试结果表明,本文端到端的方法在变电设备铭牌的场景文本提取中性能获得明显提升。识别结果见表1 所列。

表1 真实铭牌数据集上不同方法的测试效果
本文端到端方法将文本检测和文本识别合并为一个任务,相比取消RoIRotate 操作的两阶段方法,F-measure 值提高了0.059 2,文本识别准确率提高了1.09个百分点。文献[10]的方法本质上与两阶段方法相同,仅改进了非极大抑制模块,提高了长文本的检测精度。与文献[7]的方法相比,本文端到端方法的检测精度更高,且联合训练的文本识别分支的识别精度也更高。原因在于本文方法检测文本更加精确,且使用多重中文场景预训练方案和大量真实铭牌数据进行微调,提高了模型鲁棒性。
4.3 文本提取结果
图4 展示了本文方法的文本检测结果,表2 展示了部分文本识别的结果。可以看出,本文方法不仅检测到了图中绝大部分的关键文本信息,检测文本区域包含短文本、长文本和倾斜文本,保证了检测结果的精度,也使文本具有语义连续性。表2 中的识别结果,不仅包含中文、英文和特殊符号,还包含了设备台账所需的型号、电压等级、设备容量、生产日期等关键信息。

表2 铭牌文本识别结果

图4 文本检测结果
5 结 语
本文设计了一种应用于变电站巡检设备的端到端的变电设备铭牌文本提取方法,将文本检测和文本识别合并为一个单阶段任务,提高了训练效率和文本提取精度。本文通过使用合成铭牌数据集和真实变电设备铭牌数据集,设计了一套中文场景训练流程方案,为该领域提供了训练数据和对比参数。未来的研究将继续扩展数据集,增加钢印文本标注数据,并改进骨架网络以缩减模型规模。
