基于区域注意力机制的有噪样本下中医舌色分类算法研究*
2024-01-22李艳萍李晓光
卓 力,李艳萍,张 辉,李晓光,杨 洋,魏 玮
(1.北京工业大学信息学部 北京 100124;2.北京工业大学计算智能与智能系统北京重点实验室 北京 100124;3.中国中医科学院望京医院功能性胃肠病中医诊治北京市重点实验室 北京 100102)
舌诊是中医区别于其他医疗体系的最具特色的一种诊法。医生通过观察舌质和舌苔等的各种表现,如舌色、苔色、厚度、质地、湿度、舌形、舌态等来诊察病症[1]。舌色是其中最为直观且最重要的一种诊察特征,常见的舌色可以分为淡红、红、暗红、紫等4类。因此,在中医客观化研究中,中医舌色分析可以看作是一个分类问题,利用机器学习的方法来解决。
近年来,以卷积神经网络(Convolutional Neural Network,CNN)为代表的深度学习发展迅猛,研究者们开展了基于深度学习的中医舌色分类研究,利用CNN强大的特征提取和语义表达能力,取得了远超过传统方法的分类性能[2]。Hou 等[3]构建了舌图像数据库,使用修改后的CaffeNet 网络对舌色进行分类。徐雍钦等[4]采用深度学习方法,提取舌象深层特征并融合舌象边缘特征、纹理特征等进行综合分析人体脏器病理变化。Lu 等[5]从颜色校正的角度出发,提出了一个深度色彩校正网络,消除因光照条件导致的颜色失真。Qu 等[6]对舌体区域进行分割,分离舌质区域和舌苔区域,用稀疏编码表示舌图像的特征向量,通过计算重建特征向量时的残差来确定舌色类别。
总的来看,与传统“人工特征+分类器”的分类方法相比,基于深度学习的中医舌色分类方法采用端到端的框架,可以获得性能上的极大提升。但是现有的这些研究工作还无法获得令人满意的分类结果,主要原因在于:
①中医医生在判断舌色时,往往以观察舌尖和舌两侧为主。然而,现有的方法往往是将整幅舌图像作为网络的输入,忽略了医生的诊断习惯,导致网络无法很好地关注舌色区域,对分类结果造成不利影响。如何有针对性地设计深度网络模型,提升舌色分类的准确性,还需要进行深入的研究。
②CNN 需要以高质量、大规模的标注数据作为支撑,才能获得理想的训练性能。但是受医生的知识水平、思维方式及诊断经验的限制,也因为光线、环境等外界因素的影响,以及部分舌象样本颜色类别的视觉界限不明显等原因,导致医生标注的舌象样本中经常会出现错误的标签,形成噪声样本。噪声样本的存在会导致网络在训练过程中难以收敛,分类模型的泛化能力差。针对有噪声标注样本情况下的分类问题,研究者们提出了各种不同的方法,用来提升有噪声样本情况下的网络训练性能,已经成为目前机器学习领域的研究热点。这些方法大致可以分为3 类:噪声样本筛选和标签校正;基于损失函数的噪声样本抑制;精细化的训练策略。
噪声样本筛选和标签校正的目的是为了筛选出有噪样本,并对错误的标签进行校正,提高标注样本的质量。一种简单的思路就是利用一个训练好的网络模型进行推理,挑选出预测结果与标签不一致的噪声样本,并对其原有的标签进行校正[7]。Veit 等[8]提出了一个新的网络框架,通过引入有噪标签的残差,学习精确标签与有噪标签之间的差别,而不是拟合精确标签,使得模型更容易学习。PENCIL框架[9]采用梯度下降和反向传播对标签进行更新和校正。Northcutt 等[10]提出置信学习,通过计算噪声联合概率转移矩阵来估计噪声标签。但是这类方法往往需要一个复杂的推理步骤来将错误的标签纠正,这个推理过程的建立依赖于一个复杂的噪声模型,而噪声模型的建立往往代价较高,或者需要一个精确的无噪声数据集。
基于损失函数的噪声样本抑制方法是通过设计损失函数,在网络训练过程中对噪声样本进行有效抑制。Label Smoothing 方法以soft-one-hot代替one-hot,避免过拟合的同时,也缓解了错误标签带来的影响[11]。Bootstrapping 把模型的预测加入到真实标签中,从而降低模型对噪声样本的关注度[12]。GCE(Generalized Cross Entropy)[13]将Box-Cox 变换引入到概率中,结合CE(Cross Entropy)和MAE(Mean Absolute Error)[14],达到了噪声抑制的效果。SCE(Symmetric Cross Entropy)[15]则是将RCE(Reverse Cross Entropy)与CE 结合,构成了对称的噪声鲁棒损失函数,也可以对噪声样本进行有效抑制。
精细化训练策略依赖于对训练过程的高度干预或者对训练过程中超参数的精确控制,为标签噪声设计全新的学习模式。Decoupling 训练策略[16]同时训练两个网络,当预测结果不一致时,则更新参数。Coteaching 方法采用双网络协同学习的思想,抑制噪声样本的影响[17]。联合优化框架通过交替更新DNN 参数和标签,来提升噪声样本下的网络训练性能[18]。除此之外,教师-学生网络[19-20]、迭代学习框架[21-22]等也是有效的噪声样本训练策略。这类方法由于对训练过程高度依赖,往往具有很强的局限性。
以上研究结果表明,噪声样本学习方法有助于提升分类性能,噪声鲁棒的损失函数不仅在抗噪声方面拥有显著的效果,而且应用方便。但是目前针对有噪样本下的舌色分类工作很少,当前舌色分类的准确性还难以满足临床需求,这严重阻碍了舌诊客观化研究的进展。
针对上述问题,本文从中医舌色分类的特点出发,提出了一种基于区域注意力机制的有噪样本下中医舌色分类方法,以提高舌色分类的鲁棒性和准确性。主要的创新点包括:①提出了一种舌色区域注意力机制(Tongue Regional Attention Mechanism,TRAM),将其嵌入到ResNet18[23]中,构建了TRAM-ResNet18 网络。该网络可以更好地提取、表达舌色区域的特征,提升舌色分类性能;②设计了一种对称修正的交叉熵(Symmetric Modified Cross-Entropy,SMCE)损失函数,用于对网络进行优化训练,可以在网络训练过程对噪声样本起到很好的抑制作用,提升分类的鲁棒性。
在自建的3个中医舌色分类数据集上的实验结果表明,本文提出的舌色分类方法能以较低的模型复杂度,显著提升分类性能,准确率分别达到了94.96%、93.36%和93.92%,mAP 分别达到了94.53%、93.05%和93.38%,Macro-F1 分别达到了94.67%、93.16%和92.43%。
1 提出的有噪样本下中医舌色分类方法
本文提出的有噪样本下中医舌色分类方法整体框架如图1 所示。该方法采用ResNet18 作为骨干网络。首先,根据中医医生主要通过观察舌尖和舌两侧的颜色进行诊断的习惯,提出了区域注意力机制TRAM,对舌色区域的特征进行增强,抑制非舌色区域的特征,提升特征的表达能力;接下来,设计了一种对称修正的交叉熵损失函数SMCE,用于在网络训练过程中对噪声样本进行抑制,提升舌色分类性能。
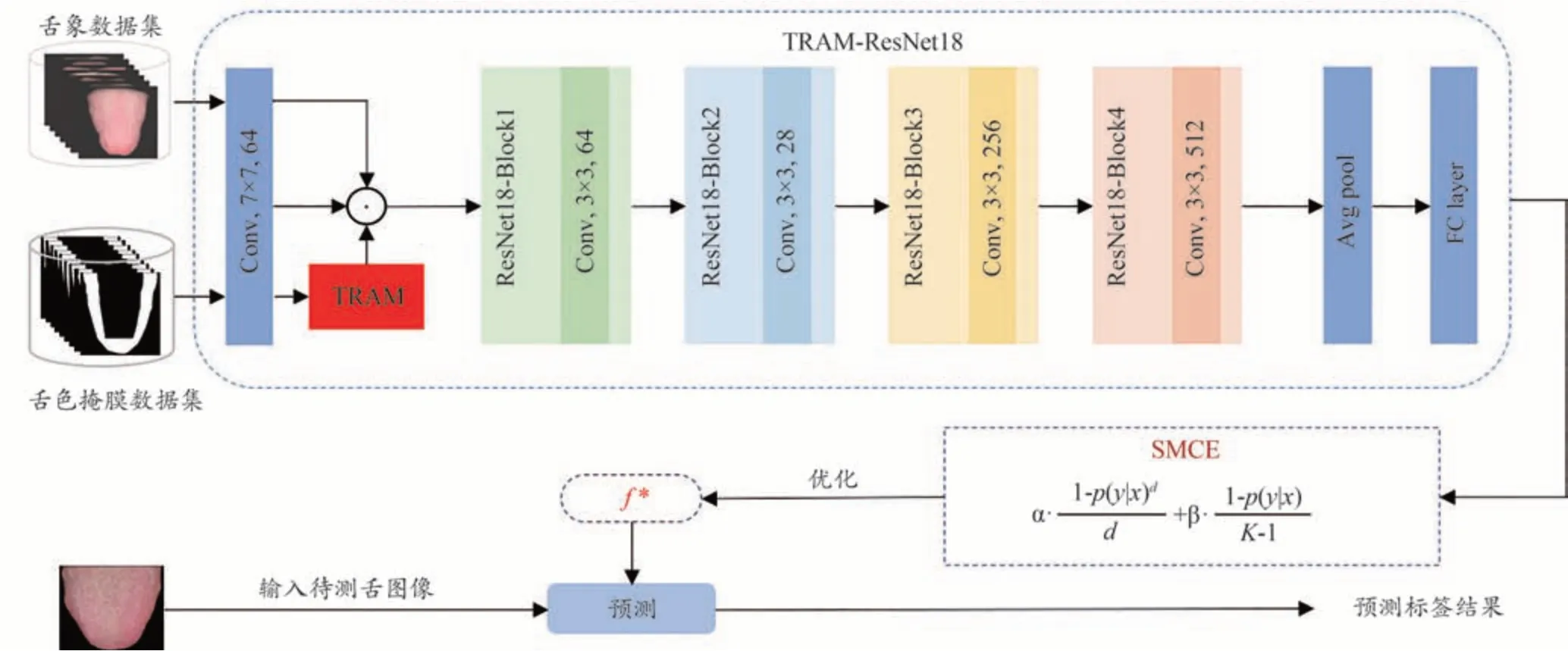
图1 本文提出的中医舌色分类整体框图
1.1 舌色区域注意力机制
舌色区域注意力机制的网络结构如图2所示。
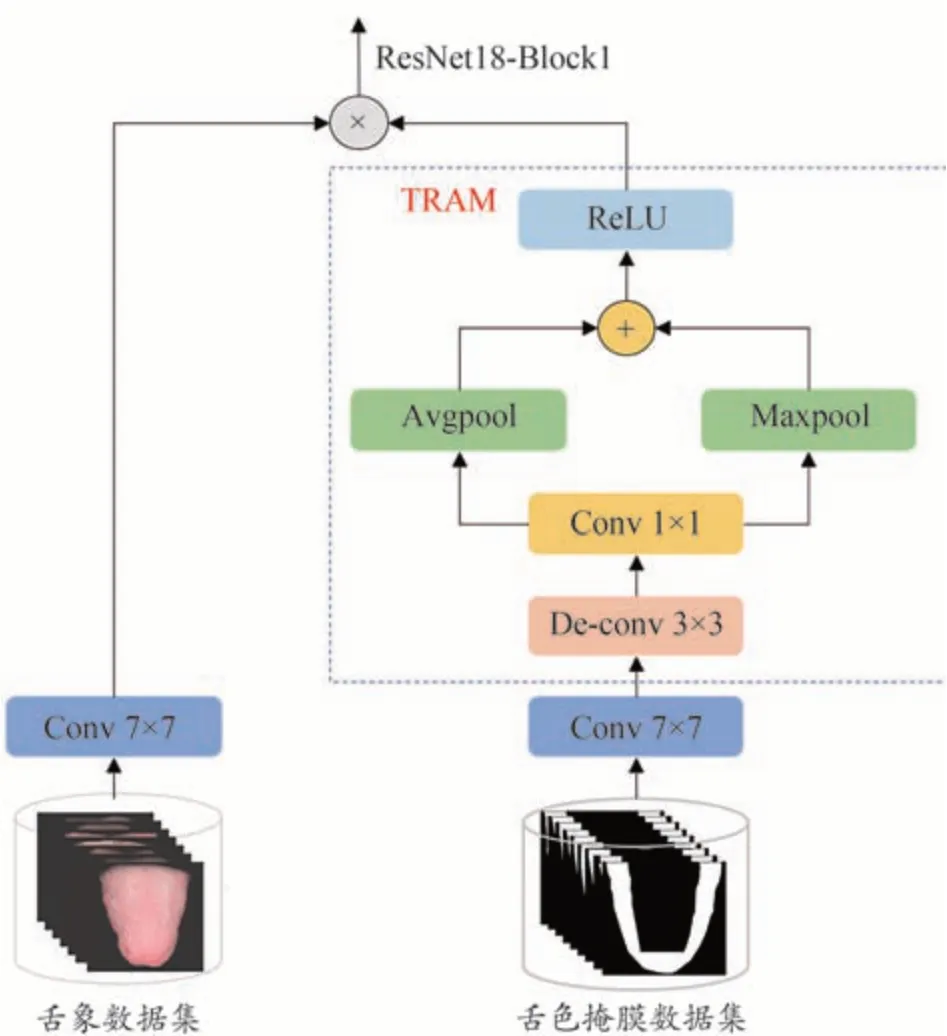
图2 舌色区域注意力机制
根据舌色区域主要位于舌尖及舌两侧部位的特点,生成舌色区域的掩膜图。假设输入为舌图像TONin,相应的舌色区域掩膜图为TONmask∈R224×224×3,对TONin和TONmask1进行卷积变换(64@conv7×7),得到特征图TONin1和TONmask1∈R112×112×64。接着对舌色区域掩膜图做以下处理:
首 先,对TONmask1做 反 卷 积,生 成TONmask2∈R224×224×64。然后对其进行1×1 卷积,生成TONmask3,目的是在不改变特征图大小以及特征图维度的情况下,实现跨通道的线性组合。接着,对TONmask3进行平均池化与最大池化操作,将输出结果相融合,此时的特征图大小恢复到112×112。最后采用ReLU 非线性激活函数,得到舌色区域注意力图TONam。整个过程可以用公式表达如下:
最后,利用舌色区域注意力图TONam对特征通道逐一进行加权,得到增强后的特征通道TONout,可以用公式表示为:
1.2 对称修正的交叉熵损失函数
1.2.1 定义
对于一个K类别的分类问题,假设有N个样本量的训练数据集D={xi,yi}N i=1,xi表示数据集中第i个训练样本,yi∈{1,...,K}表示对应的第i个样本的标签。q(k|x)表示样本x的真实标签分布,并且q(k|x) =1。本文研究的是每个样本对应一个标签的常见分类问题,假设一个样本x的真实标签为y,那么q(y|x) = 1,并且在所有其他标签的条件下,即k≠y时,q(k|x) = 0。分类问题就是学习映射函数f:X→Y,将输入空间映射到标签空间。针对每个样本x,分类器f(x)会计算它在每个标签下的概率,即k∈{1,..,K}:p(k|x)=ezk/,其中zk指类别为k时的网络logits层的输出,p(k|x)表示分类器预测的标签概率分布。训练分类器f是为了找到一组最佳参数θ满足最小化经验风险,定义为:
其中L(f(x),y)是分类器f在标签为y时的损失。
本文针对有噪样本情况下的舌色分类问题,设计了一个噪声鲁棒的损失函数,即对称修正的交叉熵损失函数,对于一个样本x,其计算公式如下:
其中p(y|x)代表预测正确时的概率分布,d是GCE 中的动态调节参数,K代表类别数,α和β分别是可调参数,通过调节α和β来搭配,以达到模型性能最好时的损失函数。本文设置α= 1,β= 0.1。
下面对SMCE进行理论分析和说明。
1.2.2 理论分析
2017 年,微软提出了一个重要的研究发现[24],即,对称性损失函数具有一定的抗噪能力。通过推导和进一步实验,证明了MAE就是一种典型的拥有对称性的损失函数,具体公式为:
而平时最常用的CE 损失函数则是非对称的,它的公式为:
此外,结合患者的病因构成,对其一般资料与病因构成关联分析显示,40岁以下患者13例,约为21.7%;40至60岁患者27例,约为45.0%;60岁以上患者20例,约为33.3%,并且年龄在50岁及以上的中老年患者数量比率达到58.3%,数量比率最多。此外,不同病因患者其年龄分布上也存在一定的差异,P<0.05,具有统计学意义。
因此,MAE 是一种噪声鲁棒的损失函数,而CE 则不是。但由于梯度饱和等原因,使用MAE训练网络的速度比较缓慢。基于此,Zhang Z 等[13]利用CE 的快速收敛性,将其与MAE 相结合,提出了一个噪声鲁棒的损失函数GCE。GCE 将Box-Cox 变换应用于概率,可以看作是MAE和CE的广义混合,具体公式为:
其中d是动态调节参数。当d= 1 时,GCE 相当于MAE;当d= 0 时,GCE 相当于CE,因此GCE 是一种可以动态调节的损失函数。但是,GCE只能保证在部分情况下是噪声鲁棒的,即当d= 1,GCE则变形为MAE。
基于此,本文提出了一种对称修正的交叉熵损失函数SMCE,使得无论d取何值、GCE 此时是何种变换形式,都有一个对称的损失函数在发挥着噪声抑制的作用。SMCE损失函数的公式为:
可以看出,SMCE 包括LGCE和LADD两个损失函数,通过α和β权重系数来调节两个损失函数的作用。LADD表达式为:
为了证明LADD是对称的,将其化简,可以得到:
可见,LADD是一个对称的损失函数。这使得SMCE始终具有一定的抗噪能力。
2 实验结果与分析
2.1 数据和参数设置
2.1.1 数据集
目前,还没有公开的中医舌色分类数据集。课题组与国内3 家中医医院合作,使用自行研发的中医舌象分析仪[25]临床采集舌图像,通过前期对仪器各项参数的调整和测试,尽可能还原真实舌象,建立了3个舌色分类数据集。本文所用的3 个数据集SIPL-A、SIPL-B 和SIPL-C 是分别与北京市宣武中医医院、中国中医科学院广安门医院和南昌市洪都中医院合作建立的。每幅舌图像都由经验丰富的中医专家手工标注。根据中医理论和临床实践,每个数据集都包括舌色的4个主要类别,即淡红色、红色、暗红色和紫色。每个数据集中的类别和数量如表1所示,3个数据集的部分示例样本如图3所示。
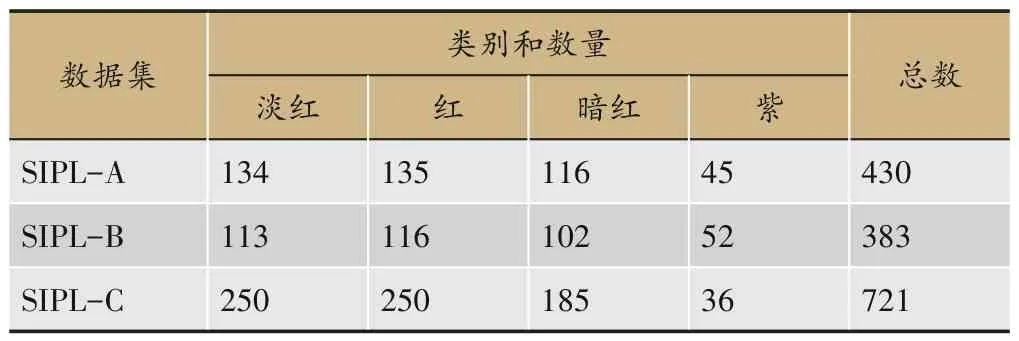
表1 三个数据集的类别和数量

图3 三个数据集的部分示例舌图像
2.1.2 数据扩充
在实验中,按照8∶2 的比例对每个数据集进行划分,其中80%作为训练数据,其余20%作为测试数据。此外,由多名中医专家对测试数据进行重新标注,综合专家的标注结果作为样本标签,以确保测试数据尽可能干净。为了提高网络的训练性能并避免过拟合,进行了数据扩充,包括水平翻转、随机旋转15°和其他几何变换方式。
2.1.3 参数设置
为了公平比较,将提出的舌色分类网络结构TRAM-ResNet18在PyTorch 平台上进行了搭建和训练测试,硬件配置为NVIDIA GeForce TX 1080 Ti GPU。模型训练时,采用Adam 梯度下降算法,学习率设为0.001,Batch Size 设置为32,epoch 为200。对输入的舌图像进行分割,只保留舌体区域,去除背景干扰,然后将舌体大小统一调整为224×224。
2.2 评价准则
本文采用准确率、mAP(mean Average Precision)和Macro-F1 这3 个指标来评价舌色分类模型性能的好坏。3 个评价指标的取值范围均为0-1,值越高,表明舌色分类性能越好。
准确率Acc表示所有测试样本中被正确预测的样本数量,定义为:
其中NC表示测试集中所有被正确预测分类的样本数量,N表示测试集中样本的总数量。
mAP是对所有类别的AP取平均值求得,即:
其中,n表示每一类的样本个数,m表示类别数。
Macro-F1 是F1 得分在多分类问题的推广,F1 的核心思想在于,它同时兼顾了精确率和召回率,用于测量不均衡数据的模型精度。Macro-F1 认定每个类别的权重都相同,不受数据不平衡的影响。Macro-F1的计算方式如下所示:
第i类的精确率和召回率分别表示为:
Macro-F1 的计算方式是先对各类别的精确率和召回率分别求平均:
然后根据下式计算得到Macro-F1:
2.3 不同注意力机制对分类结果的影响
为了验证本文提出的舌色区域注意力机制对舌色分类性能的影响,将其与SENets(Squeeze-andexcitation networks)[26]、CBAM (Convolutional block attention module)[27]、ECA(Efficient channel attention)[28]等代表性的注意力机制进行了比较。所有实验均以ResNet18 作为骨干网络,加入各种注意力机制后,采用相同的配置对网络进行训练。在3个数据集上的对比结果如表2所示,其中基线表示仅采用ResNet18,未添加任何注意力机制。可以看出,与其他的注意力机制相比,本文针对舌色分类的具体特点设计的区域注意力机制,在准确率、mAP和Macro-F1上均有所提升,在三个数据集上,准确率分别提高了0.82%、0.14%和0.56%以上,mAP 分别提高了0.94%、1.08%和1.25%以上,Macro-F1 分别提高了0.83%、0.7%和0.89%以上,充分证明了舌色区域注意力机制的有效性。

表2 不同注意力机制的分类结果对比
2.4 不同分类网络的对比结果
为了验证TRAM-ResNet18网络的分类性能,本文在SIPL-A 数 据 集 上,将 其 与LeNet[29]、AlexNet[30]、Vgg16[31]、ResNet18 和MobileNetV2[32]等代 表性 的 轻 型CNN 网络结构进行了性能上的比较。所有网络均在相同的配置下采用交叉熵损失函数进行训练。实验共重复了10次,计算其平均值和标准偏差作为实验结果,如表3 所示。表中同时列出了每个网络模型的参数量、准确率、mAP、Macro-F1 和标准偏差。可以看出,与其他轻型CNN 网络结构相比,TRAM-ResNet18能获得最高的准确率、mAP、Macro-F1 和最小的标准差。具体来说,与ResNet18 相比,网络模型参数量仅增加了0.21 M,准确率提升了4.72%,mAP 提升了4.19%,Macro-F1 提升了6.2%。与MobileNet V2 网络相比,虽然TRAM-ResNet18在模型参数量方面不占优势,但是mAP 提高了4.74%,标准差也更小。综合起来看,TRAM-ResNet18 可以在模型复杂度、分类准确性、稳定性和可靠性之间达到很好的折中。

表3 不同轻型网络的分类精度和参数量的比较结果
2.5 不同损失函数在噪声样本下的分类结果对比
为了验证SMCE的抗噪声性能,本文在3个数据集上,将其分别与6 种代表性的损失函数进行了性能对比,具体包括CE、Label Smoothing、Bootstrapping-hard、Bootstrapping-soft、GCE、SCE 等。对 比 方 法 均 采 用ResNet18作为骨干网络,训练参数和设置均按2.1所述。表4列出了使用不同的损失函数得到的分类结果。
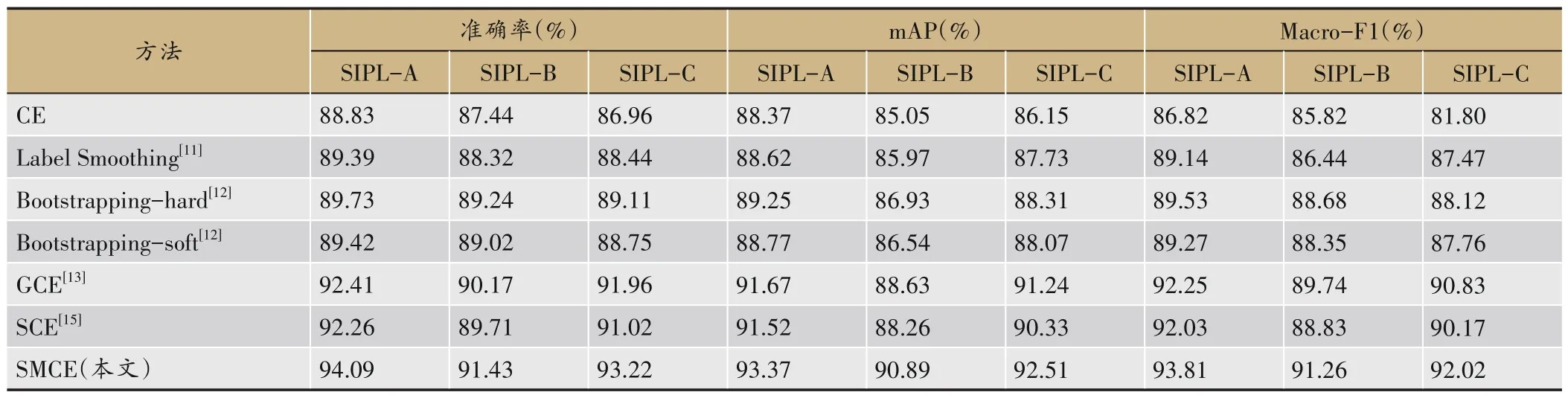
表4 不同损失函数在噪声样本下的的分类结果对比
从实验结果中可以看出,采用本文提出的SMCE损失函数在3 个数据集上均取得了最优的分类性能。相比于其他的噪声鲁棒损失函数,本文提出的SMCE损失函数可以将准确率分别提高1.68%、1.26%和1.26以上,达到了94.09%、91.43%和93.22%;将mAP分别提高1.7%、2.26%和1.27%以上,达到了93.37%、90.89%和92.51%;将Macro-F1分别提高1.56%、1.52%和1.19%以上,达到了93.81%、91.26%和92.02%。尤其是与CE 损失函数相比,Macro-F1 指标分别提高了6.99%、5.44%和10.22%。这说明本文设计的SMCE 损失函数可以更有效地对噪声样本进行抑制,显著提升了有噪样本下的分类性能。
2.6 与其他噪声样本学习方法的分类结果对比
为了验证本文方法在有噪样本情况下的分类性能,在3 个数据集上,将其分别与4 种代表性的噪声样本学习方法进行了对比,包括PENCIL、AFM(Attentive Feature Mixup)[33]、Co-teaching、Co-teaching+等。对比方法的训练设置均按2.1所述,表5列出了使用不同方法得到的分类结果。

表5 与不同有噪样本下分类方法的对比
从实验结果中可以看出,采用本文提出的方法在3 个数据集上均取得了最优的分类性能,与其他方法相比,本文方法可以将准确率分别提高2.59%、2.53%和1.06%以上,达到了94.96%、93.36%和93.92%;将mAP 分别提高2.58%、2.56%和1.54%以上,达到了94.53%、93.05% 和93.38%;将Macro-F1 分 别 提 高2.83%、2.49%和0.89%以上,达到了94.67%、93.16%和92.43%。这是因为本文方法不仅可以对噪声样本进行有效抑制,还结合舌色分类任务本身的特点,加强了对舌色区域特征的提取,从而提升了舌色分类性能。
2.7 消融实验
为了验证提出方法中各个部分的作用,本文在SIPL-A 数据集上进行消融实验。基线方法以ResNet18 作为骨干网络,使用CE 损失函数进行网络的优化训练。实验中将加入TRAM 和SMCE 前后的分类性能做了对比。实验结果如表6所示。
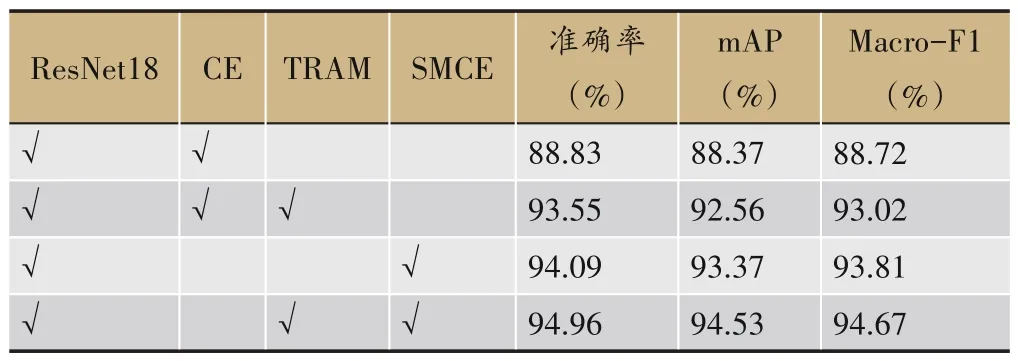
表6 消融实验
从实验结果中可以看出,采用基线方法,准确率、mAP 和Macro-F1分别仅为88.83%、88.37%和88.72%。采用TRAM 后,3 个指标分别提升了4.72%、4.19%和4.3%,达到了93.55%、92.56%和93.02%。这说明了针对舌色分类任务的具体特点设计注意力机制,可以显著提升舌色分类的性能。而使用噪声鲁棒的损失函数SMCE 代替CE 后,3 个指标比基线分别提升了5.26%、5%和5.09%。而TRAM和SMCE同时使用,3个指标进一步提升了0.87%、1.16%和0.86%,达到了94.96%、94.53%和94.67%。这说明本文提出的舌色区域注意力机制和对称修正交叉熵损失函数,均可以有效提升舌色分类的性能。
2.8 TRAM区域注意力的可视化结果
为了更直观地展示TRAM 的有效性,本文采用Grad-CAM++类激活图方法[34]分别对ResNet18 和TRAM-ResNet18网络提取的特征进行了可视化处理,如图4 所示。图中给出了原始的舌图像,以及分别采用ResNet18 和TRAM-ResNet18 网络提取的特征可视化结果。从图4 可以看出,ResNet18 网络无法有效提取舌色区域的特征,网络关注点往往集中在非舌色区域。很显然,这样的特征会导致舌色分类不够准确。而TRAM-ResNet18 网络则可以准确地对舌体区域的特征进行增强,对非舌体区域进行抑制,更符合医生判定舌色时的诊断习惯,从而可以有效提升舌色分类性能。
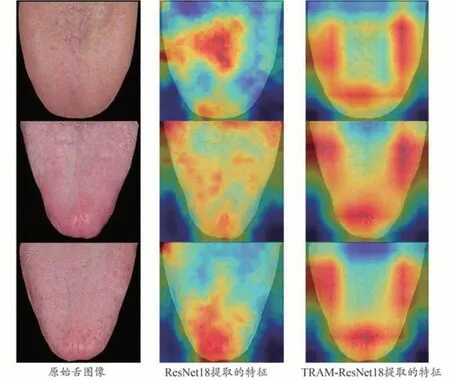
图4 TRAM-ResNet18网络特征可视化结果
3 结论
本文针对中医舌色分类的特点,提出了一种基于区域注意力机制的有噪样本下中医舌色分类方法,以提高舌色分类的鲁棒性和准确性。通过一系列实验,可以得到如下结论:①针对舌色分类的具体特点,本文设计了TRAM,可以加强网络对于舌色区域特征的提取与表达能力,从而有效提升了舌色分类性能;②针对舌色人工标注数据中存在的噪声问题,本文设计了SMCE 损失函数,可以在网络训练过程对噪声样本起到很好的抑制作用,提升分类的鲁棒性。
在自建的3个中医舌色分类数据集上的实验结果表明,本文提出的舌色分类方法能以较低的计算复杂度,显著提升分类性能,准确率分别达到了94.96%、93.36%和93.92%,mAP 分别达到了94.53%、93.05%和93.38%,Macro-F1 分别达到了94.67%、93.16%和92.43%,可以满足实际应用的需求。在未来的工作中,将增大数据集的规模,进一步提升分类准确率和模型的泛化能力,真正应用到实际临床舌诊中。
