考虑综合性能最优的非短视快速天基雷达多目标跟踪资源调度算法
2024-01-21王增福杨广宇金术玲
王增福 杨广宇 金术玲
①(西北工业大学自动化学院 西安 710072)
②(中国电子科技集团公司第三十八研究所 合肥 230088)
1 引言
天基雷达具有全天时、全天候的陆、海、空、天目标探测能力,可有效弥补现有预警系统的不足。但对于目标搜索、跟踪等复杂多任务需求,天基雷达系统资源十分有限。合理高效的资源调度是提升天基雷达性能的关键技术之一,面临着任务复杂、资源约束复杂、目标不确定等问题。如何统筹分配天基雷达系统资源,如辐射功率、驻留时间等,以最大限度满足系统任务需求,成为目前亟需解决的问题。
雷达资源调度问题是系统资源配置约束下的优化问题。其中,目标函数的构建至关重要。根据不同应用场景选择合理的目标函数可以保证资源调度的充分性,其通常考虑两方面准则:跟踪性能最大化准则和低截获概率(Low Probability of Intercept,LPI)性能最大化准则。文献[1]以预测条件克拉默-拉奥下界(Predicted Conditional-Cramér-Rao Lower Bound,PC-CRLB)为优化性能指标,基于两步半正定规划方法,提出了一种联合节点选择和功率分配策略。文献[2]面向相控阵雷达组网多目标跟踪问题,为最小化雷达资源消耗,采用后验克拉默-拉奥下界(Posterior Cramér-Rao Lower Bound,PCRLB)量化跟踪性能,提出了一种优化的资源分配策略。与统一分配资源方法相比,所提策略可以利用更少的资源实现预期性能。文献[3]将PCRLB作为目标跟踪性能指标,利用两步法求解建立的非凸优化问题,提出了一种在非理想检测环境下用于多基地雷达系统多目标跟踪的联合节点选择和功率分配策略。文献[4]针对共址多输入多输出(Multiple Input Multiple Output,MIMO)雷达中的机动目标跟踪任务,以PC-CRLB为优化性能指标,提出了一种功率分配策略,以提高机动目标跟踪性能。文献[5]以多目标跟踪误差效用函数为优化目标,利用基于分区的三阶段法和梯度投影法,提出了一种联合在线航路规划和资源优化策略,以提高多目标跟踪能力。文献[6]针对雷达组网目标跟踪,以LPI为优化准则,通过优化雷达网络中的重访间隔、驻留时间和发射功率,提出了一种自适应资源管理方法。文献[7]为解决分布式相控阵雷达网络目标跟踪问题,分别采用PC-CRLB和拦截概率作为目标跟踪精度和LPI性能指标,利用优化技术协同各雷达节点的发射功率、驻留时间、波形带宽和脉冲宽度,提出了一种联合发射资源管理和波形选择策略,以提高雷达网络的目标跟踪精度和LPI性能。
在面向动态系统的优化控制中,通过仅考虑一个预测步骤优化目标函数的方法称为短视或贪婪策略,而考虑未来多步的方法称为非短视策略[8,9]。文献[1-7]的调度策略均为短视策略。考虑到雷达多目标跟踪中大部分目标为非合作目标,量测不确定,以及当前决策对更长远未来的影响,可引入有限长时折扣的序贯决策模型框架,将雷达资源调度问题建模为部分可观测的马尔可夫决策过程(Partially Observable Markov Decision Process,POMDP),实现非短视雷达资源分配。与短视策略相同,非短视策略通过计算动作对目标函数的影响来评估每个可用动作;不同的是,其目标函数综合了未来一系列动作,具有提高资源分配效能的优势[10]。
文献[11]考虑单平台多传感器目标感知,采用POMDP对问题建模,通过序贯贝叶斯推理计算目标信念状态,使用贪心算法优化雷达资源配置。文献[12]将多模式传感器管理问题转换为多变量POMDP的雷达调度问题,提出了用于估计最佳多线性阈值策略的随机近似算法,计算出调度策略以确定被选目标以及持续时间使得代价函数最小化。文献[13]考虑了存在干扰机时跟踪多目标的认知雷达资源管理问题,将其表述为基于混合POMDP的博弈模型,提出了一种低复杂度的联合优化算法计算雷达最优抗干扰策略。
实际问题中,资源分配可能会受到多种约束限制,其中约束代表所有任务的可用资源限度,需要采用受约束的POMDP对资源调度问题进行建模。文献[14]提出了一种在跟踪精度约束下最小化辐射代价的非短视调度,其采用POMDP建模资源调度问题,通过PCRLB和隐马尔可夫模型滤波器分别预测未来有限时间范围内的跟踪精度和辐射代价,最后利用分支定界剪枝算法实现资源调度优化。在基于POMDP的多目标跟踪的资源调度问题中,通常面临着维数爆炸问题[15]。利用拉格朗日松弛法(Lagrangian Relaxation,LR)可将此类问题解耦为更易解决的子问题[16,17]。例如,文献[18]使用LR将整数规划形式的多目标跟踪调度问题解耦为多个可以快速求解的单目标POMDP问题,提出了基于拉格朗日对偶问题的可行解构造方法。
鉴于POMDP的广泛应用,其求解方法得到广泛关注。中小规模POMDP问题可通过众多离线算法求解[19]。对于大规模POMDP问题,目前已提出基于离线和在线采样的方法。文献[20]提出的基于点的值迭代(Point-Based Value Iteration,PBVI)算法在具有数百个状态的问题上表现出良好性能。后续的Perseus、启发式搜索值迭代(Heuristic Search Value Iteration,HSVI)、SARSOP (Successive Approximations of the Reachable Space under Optimal Policies)等离线策略在速度以及最优性上逐步提升[19,21,22]。在线方法通常由前向搜索组成,以找到各时间步内可执行的最佳动作,通过计算较好的局部策略来减轻计算复杂度,主要方法为分支定界剪枝,蒙特卡罗采样以及启发式搜索算法等[23]。其中,POMCP (Partially Observable Monte Carlo Planning)[24]是一种基于蒙特卡罗采样的在线算法,使用广泛,其基本框架为蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS)。MCTS依赖于信念的粒子表示,采用粒子滤波来更新信念,可使POMCP类算法应用于具有非常大甚至连续状态空间的POMDP问题。虽然已提出DESPOT(DEterminized Sparse Partially Observable Tree)[25],ABT (Adaptive Belief Tree)[26]等算法,但仍然需要通用的在线POMDP求解算法来解决连续空间,尤其是连续观测空间下的POMDP问题。对此,带有观测加宽的部分可观测的蒙特卡罗规划(Partially Observable Monte Carlo Planning with Observation Widening,POMCPOW)算法[27]使用双渐进加宽(Double Progressive Widening,DPW)来逐步增加需要考虑的观测集合,本质上利用观测采样逐步离散化观测空间,是一种有效的求解算法。
上述研究成果为解决天基雷达资源调度问题奠定了良好基础。然而,现有研究主要考虑地基、空基雷达,面向天基雷达的资源调度问题鲜有研究;同时,建立POMDP框架后的解决方法多以离线算法为主,计算量大,难以适应当下和未来的资源调度问题;鉴于天基雷达系统存在约束复杂、状态与动作、观测空间连续等特性,需研究更合理的求解方法。如图1所示,本文面向天基雷达多目标跟踪任务,基于POMDP,综合考虑目标威胁度、跟踪精度、LPI性能指标,以平均辐射功率、相参积累时间为待优化变量,建立合理准确的雷达资源调度模型;在此基础上,通过LR将带有约束的多目标POMDP问题分解为多个单目标的POMDP问题;针对连续的状态、动作以及观测空间,基于MCTS,采用POMCPOW算法近似求解,最终提出了基于LR-POMCPOW的天基雷达多目标跟踪资源调度方法,并通过仿真验证了所提方法的有效性。
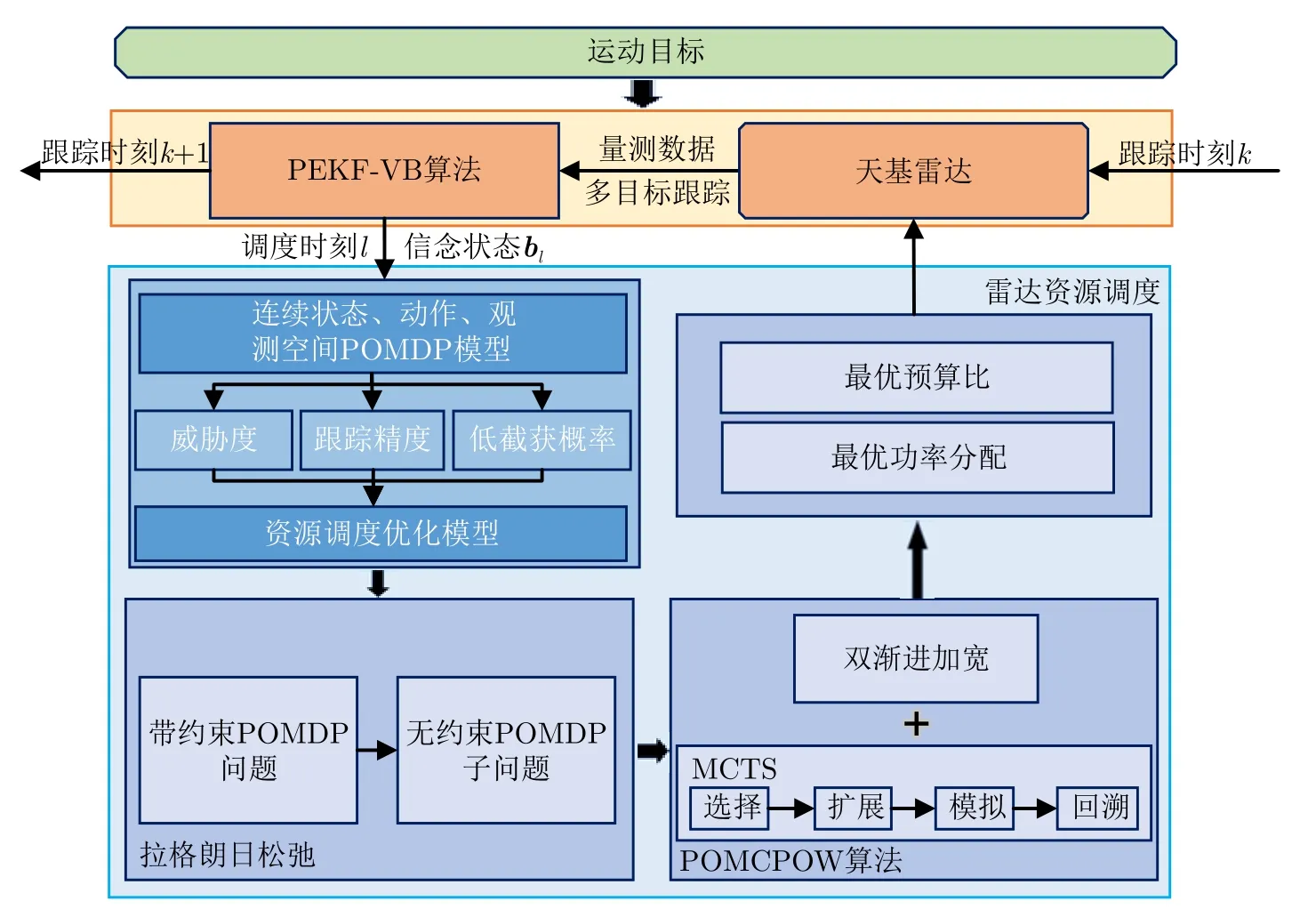
图1 基于LR-POMCPOW的天基雷达多目标跟踪资源调度方法框图Fig.1 Schematic diagram of the proposed LR-POMCPOW for resource scheduling of space-based radar multi-target tracking
2 建模与问题描述
2.1 目标运动模型
考虑单基地天基雷达多目标跟踪应用场景。设定雷达可视区域内共有I个运动目标。记离散时刻为k(k=1,2,...,U),跟踪采样间隔为T。记k时刻目标i在地心地固(Earth-Centered,Earth-Fixed,ECEF)坐标系下的运动状态向量为不失一般性,假设目标 做匀速直线(Constant Velocity,CV)运动。目标i的运动模型为
其中,状态转移矩阵Fi,k为
式(1)中,w i,k为零均值高斯白噪声,其协方差矩阵为
2.2 雷达量测模型
考虑天基雷达采用共址MIMO体制,执行多目标跟踪任务时可利用同时多波束机制,使不同发射波束指向不同目标,实现同一区域内多目标同时跟踪。雷达量测包括径向距、方位角与俯仰角。记k+1时刻关于目标i的量测向量为yi,k+1=[ri,k+1θi,k+1φi,k+1]T。量测方程为
其中,h(·)的具体形式涉及多次坐标转换,可参见GB/T 32296-2015;vi,k+1为零均值高斯白噪声,其协方差矩阵为Ri,k+1,可表示为[28,29]
其中,c1为电磁波传播速度,υk+1为k+1时刻的脉冲宽度,c2为给定常数值,一般可取为1.57[30],ρθ,ρφ分别表示方位向、俯仰向的往返波束宽度,SNRi,k+1为k+1时刻目标i的信噪比,建模方法如下。
相参体制下,单基地雷达方程为
其中,Rmax为雷达最大作用距离,pav为平均辐射功率,G为天线增益,为雷达工作波长,σ为雷达目标横截面积(Radar Cross Section,RCS),LΣ为雷达系统总损耗,主要包括发射支路损耗、大气损耗、电离层损耗、天线防护损耗、波束形状损耗、处理损耗等,k为玻尔兹曼常数,T0为标准温度(290 K),kT0=4×10-21W/Hz,Fn为接收机噪声系数,τ为相参积累时间,(SNR)min为多普勒滤波器输出的最小可检测信噪比。
由式(5)可看到,信噪比与雷达平均辐射功率、目标RCS、相参积累时间成正相关。由文献[31]可得,k+1时刻目标i的期望信噪比SNRi,k+1与雷达、目标参数的关系式为
其中,SNR0,pav,0,σ0,τ0,r0分别为参考目标的信噪比、发射机平均辐射功率、RCS、相参积累时间、雷达与参考目标的相对距离,分别为k+1时刻目标i的预测方位角和俯仰角。
2.3 POMDP模型构建
受目标运动系统噪声、雷达量测噪声等多种随机噪声以及量测方程式(4)的非线性等因素的影响,天基雷达多目标跟踪过程是典型的部分可观的随机动态系统,其资源调度是一类典型的非完美状态信息下的动态规划问题。POMDP为该类问题提供了强有力的建模框架。为此,本节采用POMDP框架,对天基雷达多目标跟踪资源调度进行建模。
本文考虑在两个不同时间尺度上完成天基雷达的资源调度。在微观尺度上(即一段调度间隔内)进行雷达对多目标的跟踪,在宏观尺度上完成雷达在有限时长上的资源调度。具体的,离散跟踪时刻为k,调度间隔为u(T≤u≤U),其为跟踪采样间隔T的整数倍,每经过一次调度间隔u,系统进行雷达资源的调度。在执行第l(l=1,2,...,L)次调度时,经调度算法求取的动作在接下来的微观尺度内保持不变,用于此调度间隔内的目标跟踪,直到下一次调度时刻到来时进行更新。从而,天基雷达多目标跟踪资源调度的POMDP模型可表示为7元组<X,A,Z,Y,W,c,γ>,具体含义如下:
(1)X:状态空间,系统所有的可能状态集合。在执行第l次调度时,目标运动状态为xl。基于目标运动状态和雷达量测,信念状态定义了目标运动状态的概率分布,表示为bl。
(2)A:动作空间,对系统可以实施的动作集合。在执行第l次调度时,选取连续动作向量为al=[τl pav,l]T,其中,τl为雷达波束在目标处的相参积累时间,考虑到天基平台能量受限,pav,l为单位时间内雷达用于目标跟踪的平均辐射功率。
(3)Z:X×A ∈Π(χ),状态转移函数,即给定系统状态和动作后关于系统状态转移的概率分布函数。在执行第l次调度时,当系统状态处于xl时采取动作al后转移到状态xl+1的概率为Pr(xl+1|xl,al),其中xl,xl+1∈X。假设状态具有马尔可夫性。
(4)Y:观测空间,系统量测值的集合。在执行第l次调度时,获取的量测值定义为yl。
(5)W:X×A ∈Π(Y),量测分布函数,采取动作al后状态转移至xl+1后的量测值为yl+1,其分布函数记为Pr(yl+1|xl+1,al)。
(6)c:X×A →R,代价函数,状态xl下选择动作al后的代价函数值为c(xl,al),xl ∈X,al ∈A。
(7)γ:折扣因子。
在执行第l(l=1,2,...,L)次调度后,需要对目标信念状态bl进行更新。当执行动作al,并得到量测yl+1时,采用贝叶斯准则更新信念状态,更新后的信念状态为
其中,Pr(yl+1|bl(xl),al)为归一化因子。
2.4 约束条件
根据天基雷达工作特性,考虑如下约束:
(1) 由于卫星平台的定轨和高速运动特性,天基雷达需运行在目标附近的星下点轨迹段以开展目标跟踪任务。从而,对一定区域内的目标,只在固定时段存在可见关系。由此,可设定可见时间窗口为[tstart,tend]。假设天基雷达运行至窗口起始时刻tstart开始工作,但跟踪任务结束时刻应不晚于tend。在可见时间窗口内,调度结束时间应早于可见时间窗口结束时间,即:
其中,tend-tstart为卫星与目标的可见时间间隔,雷达资源总调度时长为Lu。
(2) 在第l次调度时,用于不同目标跟踪的平均辐射功率pav,i,l之和不大于雷达跟踪消耗的总能量E与可见时间窗口内跟踪总时长U(U≤(tend-tstart)/T)的比值,即:
(3) 在第l次调度时,各跟踪任务的相参积累时间与采样时间间隔比值之和不大于规定的预算比,便于雷达在采样时间间隔T内可执行其他任务,即:
2.5 目标函数
在设计目标函数时考虑如下3个方面:雷达对目标进行有效的威胁度区分;最小化目标跟踪误差;雷达在可见时间窗口内用于目标跟踪的能量最小化,从而降低截获概率。为此,第l次调度时,定义目标i的综合代价函数c(xi,l,ai,l)为
其中,ω1,ω2分别是跟踪预测误差代价函数以及能量代价函数的权重。令c(bi,l,ai,l)表 示信念状态bi,l下的期望代价。接下来详细介绍式(11)的计算方法。
令φ(xi,l)表示目标i的威胁度函数,取值范围为[0,1],不失一般性,假设其与目标i在第l次调度时的状态xi,l有关,φ值越大,目标威胁度越高。对高威胁度目标,雷达可分配更多资源用于收集目标信息。本文采用目标i相对于受保护对象j时间、距离的最接近点(Closest Point of Approach,CPA)计算其威胁度[32]。目标i对受保护对象j构成的威胁取决于目标i可以多快以及多近地接近受保护对象j。受保护对象j在第l次调度时状态为相对运动状态则定义时间最接近点为[32]
距离最接近点为[32]
利用sigmoid函数,目标i对对象j的威胁度可计算为[32]
其中,t1<t0.5<t0,d1<d0.5<d0,下标表示威胁度值φ分别为1,0.5,0。令φ(xi,l)=gtimeφtime(xi,l;·)+gdistanceφdistance(xi,l;·),其中,gtime≥0,gdistance≥0,gtime+gdistance=1。
Tr(Pi,l+1(ai,l))是l+1时刻跟踪目标i的(预测的)状态误差协方差矩阵的迹,选用该指标可以衡量雷达跟踪精度性能。具体计算可参见PEKF-VB(Proximal Extended Kalman Filter-Variational Bayes)算法的相应步骤[33]。
u·pav,i,l是雷达在单次资源调度间隔u内消耗在跟踪目标i上的能量。考虑u不变,则系统消耗能量与辐射功率成正相关。本文选用系统消耗能量作为LPI性能指标[34]。一般利用截获概率表示雷达LPI性能,目标i对雷达发射信号的截获概率可表示为[6]
其中,pfa为拦截接收器的虚警概率,Gt为雷达发射天线在拦截器方向的增益,GI为拦截器天线增益,GIP为拦截器处理增益,BI表示拦截接收器的带宽,FI表示拦截接收器噪声系数,函数erfc(x)为
式(16)中,径向距离ri,l为量测分量,无需进行优化,则辐射功率pav,i,l与截获概率成正相关,从而LPI性能与功率分配密切相关。每经过一次调度间隔u,可将雷达的目标跟踪信息通过中继卫星或者直接传送至地面站中心,进行资源调度分析。
2.6 问题声明
在上述目标运动模型、雷达量测模型、POMDP模型、代价函数的基础上,保持微观尺度下的目标跟踪,则宏观尺度下的天基雷达多目标跟踪资源调度可描述为:给定系统初始状态,在满足资源约束条件的基础上,确定最优的可容许确定性策略,使得有限时间下期望的累积多目标总代价函数最小,即:
3 基于LR-POMCPOW的天基雷达多目标跟踪资源调度
针对式(17),本节采用LR方法将带有约束的动态规划问题转换为无约束的动态规划问题,然后将由I个目标构成的高维无约束动态规划问题分解为I个由单目标构成的一维无约束动态规划子问题。考虑到连续状态空间、连续动作空间及连续观测空间引起的维数灾难问题,采用基于MCTS的POMCPOW算法,最终给出了一种综合多指标性能的非短视快速天基雷达多目标跟踪资源调度算法。
3.1 拉格朗日松弛
优化问题式(17)带有多个约束,因此需要在最小化累积多目标总代价函数的同时满足约束条件。首先,引入拉格朗日乘子向量Λ=[λ1λ2...λL]T对式(17)进行拉格朗日松弛,其中,λl=[λ1,l λ2,l]≥0(注意到,式(8)并不包含动作向量a的任一分量,因此不需要对该约束构造拉格朗日乘子)。然后,构建拉格朗日对偶函数JL(B1,Λ),即:
(1) 对于任意Λ≥0,B1∈BI,JL(B1,Λ)≤V*(B1);
(2) 当Λ≥0,JL(B1,Λ)是分段线性凹的;
因此,JL(B1,Λ)可作为性能下界来评估原始优化式(17)可行策略的质量。可计算得到拉格朗日对偶函数最大值,其与V*(B1)间隙最小。即求解下列拉格朗日对偶问题,
注意到,拉格朗日对偶问题为凸优化问题。
给定拉格朗日乘子λl,结合式(11)重新定义第l次调度时目标i的综合代价函数为C(bi,l,ai,l,λl)=c(bi,l,ai,l)+λ1,lpav,i,l+λ2,lτi,l/T,则对于∀B1∈BI,JL(B1,Λ)可写成:
3.2 基于LR-POMCPOW的非短视快速天基雷达多目标跟踪资源调度算法
建立LR后,可基于次梯度法求解拉格朗日对偶问题式(19)。其中,的计算是关键。由2.3节可知,各目标的累积总代价函数优化模型表现出状态空间、动作空间、观测空间连续的特点。但即便是有限时间的POMDP问题也是PSPACEhard的,这表明离线精确算法不可用于会出现维数灾难的问题,而基于MCTS的在线近似算法已被证明可解决大规模状态空间的POMDP问题[24]。因此,接下来采用MCTS优化计算过程如图2所示。为方便起见,省略区分各目标的下标i。具体过程说明如下。

图2 蒙特卡罗树搜索算法的过程Fig.2 The process of the MCTS algorithm
首先在一次蒙特卡罗模拟中,给定初始信念状态b1作为树的根节点,往下延伸出的子节点表示可选动作a,利用UCB (Upper Confidence Bound)公式计算各动作节点的UCB值。注意到优化目标是最小化累积总代价函数,找出UCB值最小的动作节点并由此节点出发继续向下扩展。但如果信念状态节点存在未探索的动作节点,则从未探索动作节点中随机选取一个节点。在选定的动作节点下获取量测y作为分支,并根据信念状态更新式(7)得到下一时刻的信念状态节点,图中显示为节点b2。在多目标跟踪中,可通过执行b2步预测得到下一调度时刻的信念状态。此时若节点b2存在子节点,则继续重复上述过程直至树的层数达到最大深度d;若节点b2是新扩展的节点,则利用rollout算法,以默认策略向下计算d步。模拟结束后,该节点的父节点直至根节点的路径上所有节点都会根据本次模拟的结果重新计算代价估计值。当达到最大迭代次数后,选择根节点b1下最优的动作节点a*作为本次调度结果,同时求出对应量测以及更新的信念状态,并对根节点以下的其余节点及分支进行裁剪。由于优化时长为L,以本次调度的最优动作下更新的信念状态节点为新的根节点,重复L次后结束,则可行策略π*可由根节点通往路径末尾处的叶节点的最优动作集表示。
基于MCTS的常见在线近似算法虽然可行,但分析可知,如果观测空间连续且量测分布函数是给定的,则两次采样得到相同量测的概率为零,因此MCTS的蒙特卡罗模拟永远不会两次通过同一个信念状态节点,并且永远不会构建第一层信念状态节点以下的树。所以,在动作和观测空间很大或连续的情况下,基于MCTS的常见算法将生成非常浅的树,使得渐进最优性能较差。POMCPOW算法利用双渐进加宽可有效解决此问题,双渐进加宽指的是动作空间和观测空间的渐进加宽。与考虑所有动作(量测)的基于MCTS的常见算法相比,POMCPOW算法通过控制有限但逐渐增加的动作(量测)数量以更多地关注后续计算,能够更加深入地向下搜索树。
现具体介绍基于MCTS的POMCPOW算法[27],其算法结构如算法1所示。对应的 ℏ代表直至当前调度时刻l以b1为初始节点的一段历史记录(a1,y1,a2,y2,...,al,yl),即已经确定的部分搜索路径。ℏa和ℏay分别表示在末尾附加了新生成的a和(a,y)的历史。设定d≤L。C是节点的子节点集,C(ℏ)为信念状态节点的动作子节点集,C(ℏa)为动作节点的量测子节点集,N是节点访问次数的计数值,对应的N(ℏ) 为信念状态节点计数值,N(ℏa)为动作节点计数值,M是生成不同量测的计数值。与信念状态节点关联的采样状态集为X,W是对应于采样状态集X的权重集,而Q(ℏa) 是在历史 ℏ后选取动作a的代价估计值,C,N,M,X,W和Q都初始化为0或空集。其中,渐进加宽分别体现在算法1的14~17行、20~24行。在处理连续动作空间问题时,渐进加宽使用15行的 NEXTACTION(ℏ)运算进行处理。具体为,在动作空间A中采用均匀分布采样方法选择一个动作,但选择的动作不与C(ℏ)内的已采样动作重复,直至动作采样空间C(ℏ) 大小达到δaN(ℏ)αa。观测空间的渐进加宽同理。G(·)是默认的生成函数,在本文中包含目标运动模型、雷达量测模型以及综合代价函数的计算,Λ(·)单指具体的综合代价函数计算,所得的C即为综合代价值C(b,a,λ)。算法1第29行Rollout算法[24]部分如算法2所示,其中,使用默认的策略πrollout(ℏ,·) 在整个动作空间A中随机选择一个动作,递归d步后返回累积折扣代价值Ctotal。算法1第31行中m指采样状态集X包含的样本数。与常见MCTS算法不同的是,UCB为

算法 1 POMCPOW算法Alg.1 POMCPOW algorithm
在POMCPOW算法中,每一次模拟时转移采样状态x′都会被插入到代表信念状态的加权采样状态集X(ℏay)中,当动作节点的量测子节点数|C(ℏa)| 超出对应渐进加宽上限后,其选择概率取决于权重集W(ℏay)中该状态的量测分布函数之和,如算法1中第31行所示。注意到,信念状态节点包含的样本数与节点被访问的次数有关,因此,一个信念状态节点信念表示越丰富,最优策略访问经过的可能性就越大[27]。转移采样状态的加权方法被证明是合理的[35],这些采样状态集会随着树的搜索而逐渐改进。随着转移采样状态x′的不断加入,采样状态集X(ℏay)会逐渐扩展,由此改善已有在线算法的性能。
对于给定的天基雷达多目标跟踪任务,给定调度间隔u后可确定实际调度总次数为在第κ(κ=1,2,...,K)次调度时,经过LR并利用POMCPOW分别求得各目标的最优策略后,需进行拉格朗日乘子向量的更新直至迭代结束。此时选取各目标最优策略的首个动作值,构成本次调度的最优动作向量对于信念状态的更新,尽管粒子滤波算法比PEKF-VB算法更通用,但其需要更大的计算量,并可能受样本贫化等影响。本文应用PEKF-VB算法得到各目标的信念状态bi,κ+1。在经历实际K次调度后,可求得多目标跟踪的最优策略π*以及近似最优解V*(B1),因此可将最优策略的分量分别应用于持续时间为u的多目标跟踪过程中。基于LR-POMCPOW的非短视快速天基雷达多目标跟踪资源调度算法的整体流程总结如算法3所示。

算法 3 基于LR-POMCPOW的天基雷达多目标跟踪资源调度算法Alg.3 LR-POMCPOW-based resource scheduling algorithm for multi-target tracking of space-based radar
在计算复杂度方面,单独取第κ次调度进行分析,则LR-POMCPOW算法中最为耗时的部分是各子问题最优策略计算以及拉格朗日松弛。首先计算单次迭代求解单个目标的最优策略的复杂度,此处由于算法1第31行状态选取为随机采样,其复杂度为O(Γ),则各子问题最优策略计算的复杂度为O(dΓ2),从而算法3第5-7行计算复杂度为O(dILΓ2)。而LR的次梯度计算和乘子更新计算复杂度为O(L),因此在第κ次调度的计算复杂度为O(Lem+dILemΓ2)。在同样使用LR后,同属于MCTS类型的POMCP算法在求解最优策略时的复杂度为O(dIL(|A|+|Y|)),在动作空间、观测空间很大甚至连续的情况下,空间大小 |A|,|Y|使得POMCP算法计算复杂度远高于POMCPOW算法。而离线算法以PBVI为代表,其计算复杂度为O(IL|A||Y|Γ),相较在线近似算法,其在连续空间问题下需要更多计算资源[36]。
4 仿真与验证
本节通过仿真验证所提算法的有效性。首先,构建各目标威胁度区分度较高的场景,分析威胁度对天基雷达资源分配的影响,验证所构建优化函数中威胁度的有效性。然后,分析了目标与天基雷达的相对距离对资源分配的影响程度。最后,将现有适用于连续状态空间、连续动作空间、连续观测空间POMDP问题的几种算法与本文算法进行对比,验证本文所用算法的优越性。
4.1 威胁度对雷达资源分配影响分析
考虑运行于圆形轨道的天基雷达卫星,其轨道6根数包括:轨道半长轴、偏心率、轨道倾角、升交点赤经、近地点幅角以及真近点角。为保证坐标转换的准确性需给定格林尼治恒星时角(Greenwich Hour Angle,GHA),雷达天线阵面的偏航角、俯仰角、滚动角都设置为0 rad,对应参数设置如表1所示。雷达在同一时刻需跟踪I=2个飞机目标,采样间隔设为1 s,各飞机目标以及受保护飞机都处于匀速运动状态,其在STK (Satellite Tool Kit)中运动轨迹如图3所示(数据来源为AGI),图3中箭头所指为各目标运动方向以及天基雷达运动方向,雷达对目标持续跟踪的轨迹段用白色标记。各目标和受保护飞机在ECEF坐标系下的初始位置和速度,计算雷达回波信噪比SNRi,k时所需的RCS,相对距离、相参积累时间以及发射机平均辐射功率参数如表2所示,参考目标的信噪比为SNR0=15,方位角波束宽度ρθ为0.002 rad,俯仰角波束宽度ρφ为0.001 rad。

表1 仿真基本参数设置Tab.1 Basic parameter settings of simulation

表2 场景1初始时刻目标相关参数Tab.2 Parameters related to target initialization of scenario 1

图3 威胁度对雷达资源分配影响分析STK仿真图示Fig.3 STK-based demonstration for impact of distinct target threat levels on radar resource allocation
为简化调度过程,令雷达调度的连续动作量仅选取相参积累时间,其取值范围为[0.01,0.40] s,其余分量与参考目标对应值保持一致。采用LRPOMCPOW算法进行资源调度。雷达从窗口起始时刻开始跟踪,调度间隔u=70 s,至窗口结束时刻可进行 U=300次跟踪,实际调度终止时刻为K·u=280 s,从而,此仿真场景中雷达调度资源4次。
在PEKF-VB跟踪算法中,飞机目标i(i=1,2)在3个方向上的机动噪声方差都设定为6×10-5km2/s4,迭代次数为4,惩罚因子β=1。威胁度相关参数为gtime=0.3,gdistance=0.7,t0,t0.5,t1取值为60,55,50,d0,d0.5,d1取值为160,110,60,仿真中可添加0.01到威胁度评估函数的0威胁度处,避免不合理取值。另外,LR所用参数及调度算法的部分参数也如表1所示。
为验证威胁度对雷达资源调度的影响,图4给出了整个调度时期两目标的威胁度值。可以看到,与图3中受保护飞机有交叉轨迹的目标1(运动方向为红色箭头)威胁度接近1,而较远处的目标2威胁度保持在较低水平。跟踪过程中分配给两目标的相参积累时间与采样间隔比(即预算比)结果如图5所示。可以看到,目标的威胁度与雷达分配的预算比具有相关性,在满足不大于总预算比η=0.5的条件下,需要获得更多关注的目标1始终可分配到较多的相参积累时间资源。若构建优化目标函数时只考虑量测和目标运动的不确定性,会导致雷达将更多资源分配给距离受保护飞机更远的目标,而综合了威胁度的优化目标函数会更为合理地反映真实场景,当目标相对较快或较近地向受保护飞机移动时,雷达资源便会倾向于此类目标。注意到图5给出的资源分配结果呈现出阶跃式现象,这是由于每次资源优化调度计算完成后,优化参数立即输入天基雷达,应用于下一调度间隔的多目标跟踪过程中。
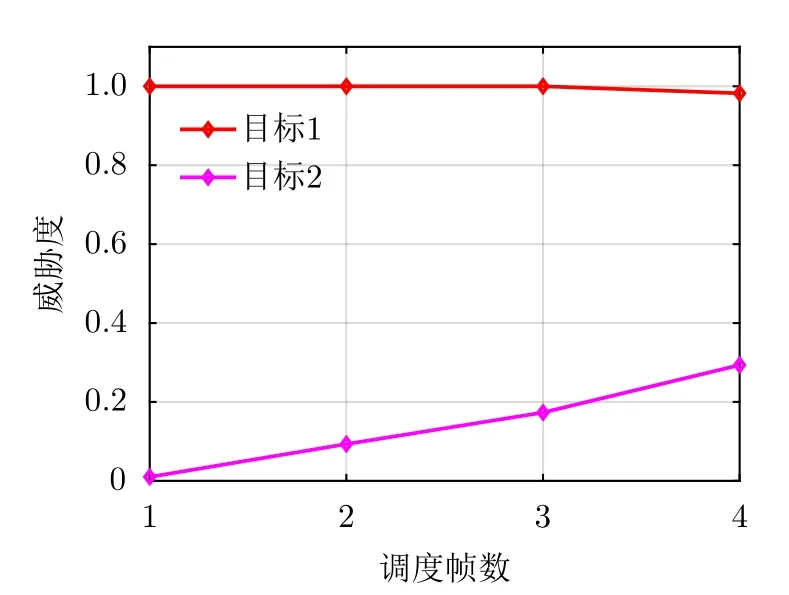
图4 目标威胁度结果Fig.4 Target threat level results
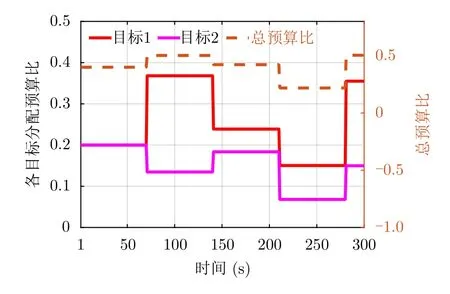
图5 各目标的预算比(τ/T)分配结果Fig.5 Budget ratio (τ/T) allocation results for each target
4.2 相对距离对雷达资源分配影响分析
在该仿真场景中,主要研究目标与雷达的相对距离大小以及其变化对雷达资源分配的影响。由于常见天基雷达多目标跟踪场景中目标与沿轨高速运行的天基雷达的相对距离变化并不明显,无法有效体现其对资源分配的影响程度,则在图6中令目标沿特殊轨迹运行。具体参数如下:调度间隔为15 s,跟踪总时长为 U=124 s,连续动作量选定为相参积累时间,其取值空间为[0.01,0.40] s,初始位置和速度如表3所示,威胁度相关参数t0,t0.5,t1取值为80,55,30;d0,d0.5,d1取值为110,75,40;窗口起始时间为4 May 2023 04:14:09.500,窗口结束时间为4 May 2023 04:16:12.000,其余参数同场景1一致。

表3 场景2初始时刻目标相关参数Tab.3 Parameters related to target initialization of scenario 2

图6 相对距离对雷达资源分配影响分析STK仿真图示Fig.6 STK-based demonstration for impact of distinct relative distances on radar resource allocation
目标径向距离变化如图7所示。可以看到,跟踪阶段初期两目标逐渐靠近雷达,两者与雷达的相对距离差别大,但变化程度较为缓慢。为突出相对距离对雷达资源分配的影响,该场景中的优化目标函数中不考虑威胁度以及能量代价,只存在量测和目标运动不确定性的作用。通过图8中分配给两目标的相参积累时间与采样间隔比可以看到,开始阶段两目标在向雷达方向运动,相对距离都在减小,但目标2比目标1更远,对应的信噪比明显小于目标1,经过算法调度可以使目标2获得持续增加的资源。但随着目标在第80~100 s时段内距雷达的相对距离大小发生转变后,可以发现资源会偏向于目标1,但变化程度较为缓慢。由于总预算比的限制,雷达会不断减少目标2的资源配置,但总体会保持分配资源多于目标1的状态。由此,可以说明目标与雷达的相对距离越大,雷达分配的资源越多,但目标与雷达的相对距离呈现增长趋势,雷达资源则会逐渐倾向于分配给此类目标。

图7 目标径向距离Fig.7 The slant range of targets
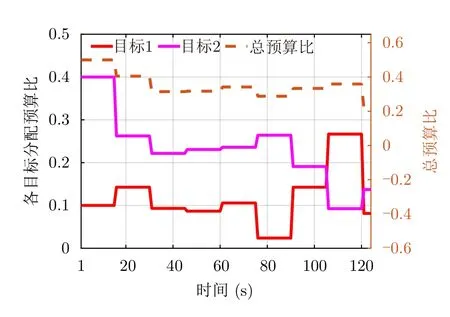
图8 相对距离影响下预算比(τ/T)分配结果Fig.8 Budget ratio (τ/T) allocation results influenced by relative distance
4.3 算法性能比较分析
为说明LR-POMCPOW算法的优越性,首先构建包括I=4个飞机目标以及受保护舰船的跟踪场景,如图9所示。在保持多数参数设置与场景1相同的条件下,其余参数设置如下:调度间隔为40 s,跟踪总时长为 U=244 s,分配至各目标的相参积累时间取值范围为[0.01,0.30] s,针对每个目标的雷达平均辐射功率取值范围为[5×103,2×104] W,最大时间预算比为η=1,最大消耗能量值为E=1.5×107J,各目标平均辐射功率之和的阈值为E/U=6.15×104W;t0,t0.5,t1取值为180,140,100;d0,d0.5,d1取值为160,130,100;GHA为4.97 rad;窗口起始时间为4 May 2023 04:12:26.000,窗口结束时间为4 May 2023 04:16:28.185,目标初始位置和速度如表4所示。综合代价函数中,ω1=0.7,ω2=0.3,避免资源分配过于倾向量级较大的能量代价。
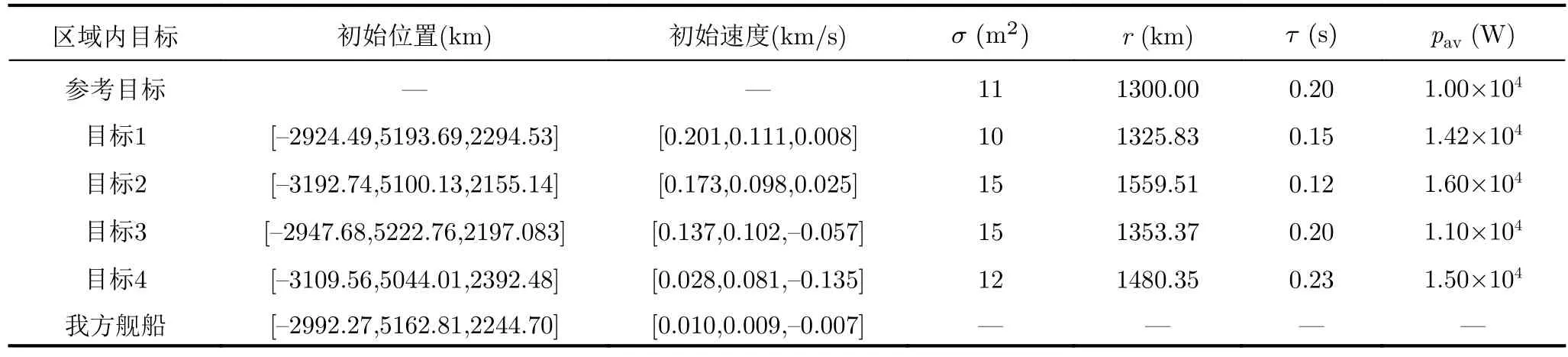
表4 场景3初始时刻目标相关参数Tab.4 Parameters related to target initialization of scenario 3

图9 多目标跟踪的STK仿真图示Fig.9 STK-based demonstration for multi-target tracking
图10给出了经过雷达资源调度的各目标跟踪轨迹对比情况,其中,各目标起始位置以空心圆标注,红色箭头所指为目标运动方向。可以看到,估计轨迹与真实轨迹经过一段时间后基本重合,经过资源分配后天基雷达能够保持良好的跟踪效果。相参积累时间(预算比)和平均辐射功率分配结果分别如图11、图12所示。可以看到,各目标的资源总量可以保持在约束值以内,总预算比在0.4~0.9,未超出最大总预算比η=1;总平均辐射功率在2×104~6×104W,小于各目标平均辐射功率之和的阈值E/U=6.15×104W。由于优化目标函数综合考虑了威胁度,而且各目标与雷达的相对距离变化较小,图中并未出现某一目标长期占据大多数资源的情况,处于合理的取值范围内。
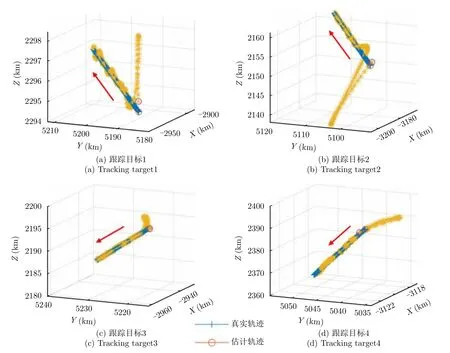
图10 目标跟踪轨迹Fig.10 Target tracking trajectory
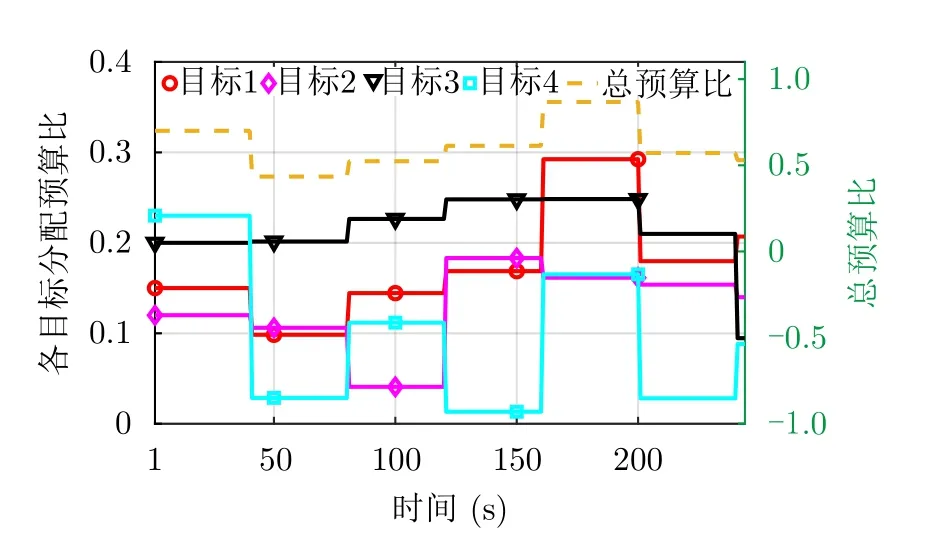
图11 多目标跟踪下各目标的预算比(τ/T)分配结果Fig.11 Budget ratio (τ/T) allocation results of each target under multi-target tracking
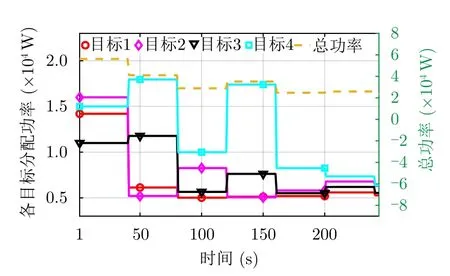
图12 各目标分配平均辐射功率Fig.12 The average radiation power allocated to each target
将LR-POMCPOW算法与其他3种结合了LR的算法进行比较。蒙特卡罗仿真次数为100次,仿真相关的超参数参见表5。

表5 各算法超参数Tab.5 Algorithm hyperparameters
(1) POMCPDPW[27]:此算法与本文所用算法类似,但区别是,对于每个生成的历史,只有一个状态插入采样状态集中。
(2) POMCP[24]:此算法不考虑连续动作以及观测值的渐进加宽,仿真中需先离散化观测空间。
(3) Rollout[37]:此算法采用预期未来的蒙特卡罗样本,随机探索可能的未来动作和相应的代价,候选动作在第1步选取,后续步的动作通过给定的基本策略选取。
现以目标1为分析对象,图13、图14给出了LR-POMCPOW与上述3种算法在跟踪目标1时的均方根误差(Root Mean Squared Error,RMSE)对比图。由于代价函数综合考虑了威胁度以及能量代价的因素,而RMSE仅为目标量测和机动性的度量指标,在此发现,RMSE并非与算法性能有直接关联性,但可以看到在应用各算法后目标跟踪的RMSE值基本保持在较低水平,相差并不明显。
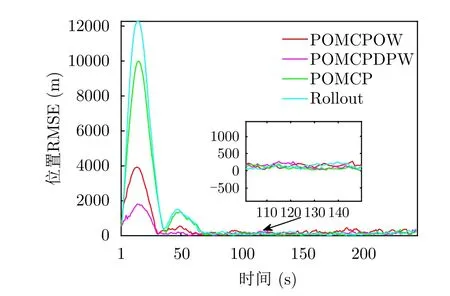
图13 目标1跟踪位置RMSEFig.13 RMSE on position of target1

图14 目标1跟踪速度RMSEFig.14 RMSE on speed of target1
图15、图16给出了不同算法的多目标总平均辐射功率和总预算比的对比结果。LR-POMCPOW算法随着资源调度的进行会不断减少平均辐射功率的消耗,POMCPDPW算法次之,POMCP,Rollout算法使消耗功率维持在较高水平。各算法得到的总预算比与RMSE结果类似,其通过影响SNR的计算进而影响状态误差协方差矩阵迹的求取,此并非代价函数的唯一考虑指标,可以看到,所提算法并非一直保持总预算比最大,各算法结果并无显著差异。各算法在资源调度期间的期望累积多目标总折扣代价如图17所示。所提算法可以得到最小期望累积多目标总折扣代价值,而其他3种算法的期望累积多目标总折扣代价值的增长趋势类似,其中Rollout算法始终保持最大总折扣代价,而POMCP与POMCPDPW算法略优于此算法,但均高出所提算法,即所提算法可达到资源调度的近似最优。综合考虑选用LR-POMCPOW算法可有效解决天基雷达资源调度问题,其性能在所比较的算法中也最为优越。
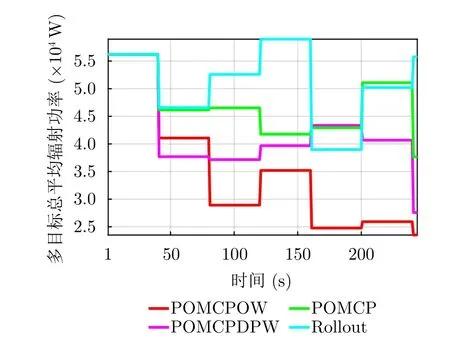
图15 总平均辐射功率对比Fig.15 Comparison of total average radiation power
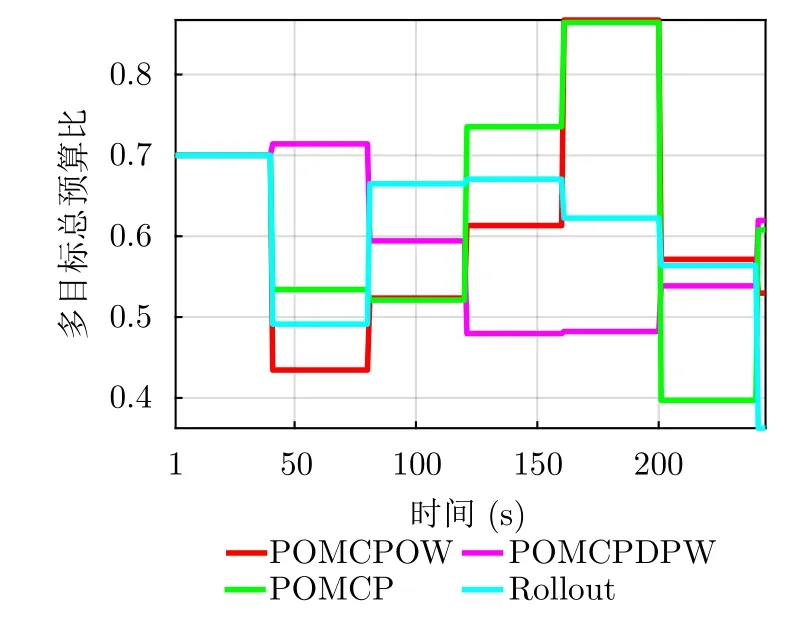
图16 总预算比对比Fig.16 Comparison of the total budget ratio (τ/T)
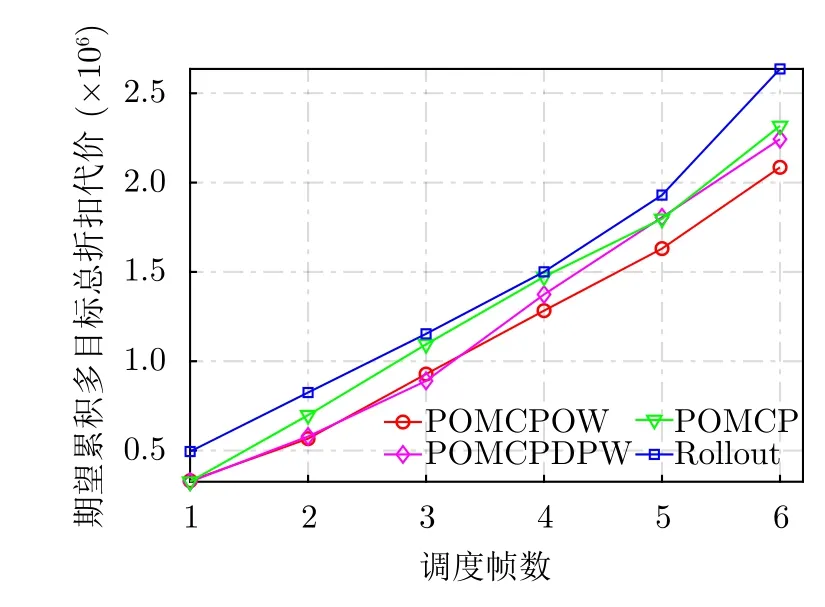
图17 各算法期望累积多目标总折扣代价对比Fig.17 Comparison of the expected cumulative multi-target discount cost
5 结语
本文考虑了天基雷达多目标跟踪过程中连续状态空间、连续动作空间以及连续观测空间下的资源调度问题,给出了基于LR-POMCPOW的综合多指标性能的非短视快速天基雷达多目标跟踪资源调度算法。针对天基雷达多目标跟踪问题,以最小化综合考虑了目标威胁度、跟踪精度与低截获概率的代价函数为优化目标,在满足雷达平台运动特性,雷达时间和能量资源的约束条件下,通过优化相参积累时间和平均辐射功率,有效保证雷达在多目标跟踪下资源分配的近似最优性。仿真结果表明,所设置的目标函数适用于天基雷达多目标跟踪场景,与已有几种调度算法相比,所提算法性能更好。
利益冲突所有作者均声明不存在利益冲突
Conflict of InterestsThe authors declare that there is no conflict of interests
