基于改进YOLOv5s的疲劳驾驶检测
2024-01-19金云峰路志展王瑞利
金云峰,路志展,王瑞利,梁 超
(北华大学土木与交通学院,吉林 吉林 132013)
目前,车辆行驶安全已成为城市道路交通安全的重中之重。研究表明,驾驶员疲劳引起的交通事故在城市交通事故中占据了相当大的比例[1]。因此,及时检测驾驶员疲劳状态(包括打哈欠、分心、闭眼等),对及时避免事故发生、降低交通事故风险、保护驾驶员和乘客生命安全至关重要。目前,国内外已有的驾驶员疲劳检测方法可以分为基于车辆行驶模式、生物信号和计算机视觉技术3类[2-3]。随着信息技术和网络技术的快速发展,深度学习算法在目标检测领域得到了广泛应用。该算法通常分为两类:两阶段算法和单阶段检测算法。其中,两阶段算法在进行目标检测时,先提出候选区域,再对这些候选区域进行目标分类和位置回归,经典代表为R-CNN[4-5]系列算法;单阶段检测无需生成候选区域,在一个阶段内直接完成目标检测,主要包括YOLO[6]系列算法、SSD[7]算法和RetinaNet[8]。
当前,疲劳检测存在以下问题:1)与普通的目标检测不同,疲劳检测的对象是车辆行驶过程中的驾驶员。由于疲劳状态通常在驾驶瞬间产生,因此,疲劳检测系统需要迅速而准确地识别驾驶员状态,以确保驾驶安全,但疲劳检测系统在检测到疲劳状态后往往存在一定的响应延迟,无法保证检测的实时性;2)在实际驾驶环境中,由于天气、光线的复杂性和多变性,常常无法精确地识别到驾驶员的面部疲劳特征,因此,导致检测精度低,无法保证检测的鲁棒性。
传统的疲劳检测方法利用驾驶员生理信号或车辆状态来检测驾驶员的疲劳状态,依赖于专业的检测设备,检测精度低、速度慢,无法实时检测驾驶员的状态变化,缺乏实用性和可扩展性,亟须找到一种高效且精确的检测方法。本文提出基于改进YOLOv5s的疲劳驾驶检测方案,以检测速度极快的单阶段目标检测算法YOLOv5s作为基础模型,改进模型的损失函数,提高模型精度与鲁棒性;引入注意力机制模块CBAM(Convolutional Block Attention Module),提高算法的特征提取能力和检测精度;开展消融试验。
1 YOLOv5s模型
YOLOv1(2015年发布)首次采用了单阶段目标检测算法,通过使用一阶网络完成分类与定位两个任务,检测速度极快。为解决定位不准确及召回率低等问题,YOLOv2采用批量归一化的方法,通过对层的输入进行重新居中和重新缩放来提高收敛速度,使用anchor boxes机制预测边界框,使卷积层输出更高的分辨率。YOLOv3(2018年发布)引入了残差模型Darknet-53,解决了梯度消失问题并加深了网络,采用FPN架构实现了多尺度检测。YOLOv4[9](2020年发布)在Darknet-53的基础上增加了backbone结构,同时增加了Droblock用来缓解过拟合现象,输入部分采用了Mosaic数据增强。不久后,GlenJocher又提出YOLOv5算法[10],相较于之前的版本,YOLOv5算法具有更高的检测精度和更快的检测速度,适用于各种目标检测场景。本文选用体积较小的YOLOv5s模型进行改进,实现对驾驶场景下驾驶员疲劳状态的精确检测。
YOLOv5s模型见图1[11],主要由Input、Backbone、Neck、Head、Prediction等5部分组成。Input包括Mosaic数据增强、自适应锚框计算、自适应图片缩放3部分[12];Backbone由Focus、CBL、CSP、SPP[13]等模块组成;Neck采用特征金字塔网络(feature pyramid networks,FPN)[14]加金字塔注意力网络(pyramid attention networks,PAN)[15]结构,有效解决了多尺度问题;Head为目标检测头,用于检测目标的位置和类别;Prediction包括Bounding box损失函数和NMS(non-maximum suppression)非极大值抑制。
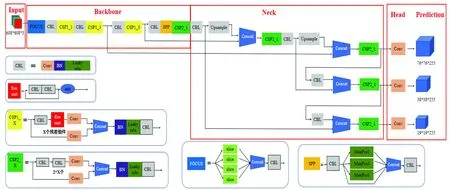
图1 YOLOv5s网络模型结构Fig.1 YOLOv5s network model structure
2 改进YOLOv5s模型
虽然YOLOv5s在各类目标检测任务中都展现出了优异的性能,但在疲劳检测这种复杂多变的驾驶环境下,原始YOLOv5s模型存在检测精度低、检测速度慢和鲁棒性较差等问题。针对这些问题,本文以原始YOLOv5s模型为基础,对其网络结构进行改进。通过改进EIoU损失函数,提高模型精度与鲁棒性,加快网络收敛速度;通过添加注意力机制模块CBAM,提高算法的特征提取能力和检测精度。
2.1 改进损失函数
在目标检测领域,模型的收敛效果与损失函数有关。损失函数在训练过程中用于衡量模型预测与实际目标之间的差异,通常由定位损失、类别损失以及置信度损失3部分组成。
原始 YOLOv5 中使用 GIoU[16]来计算定位损失:
式中的真实框GT与预测框P见图2,其中,红色矩形框是真实框,记为GT;绿色矩形框是预测框,记为P;黑色虚线的外框是一个能够同时围住红色真实框GT与绿色预测框P的最小外接框,记为C;将黑色最小外接框对角线的长度记作c;将红色真实框中心点和绿色预测框中心点用灰色线条连接,这条线的长度记作d;将真实框GT与预测框P重合的区域(图中的阴影部分)记作P∩GT;将真实框GT与预测框P共同的区域记作P∪GT。GIoU存在局限性,只能考虑到真实框与预测框之间的重合比例,所以无法很好地说明目标框的回归问题。本文选择EIoU替代原始GIoU作为目标框回归的损失函数。EIoU是基于GIoU提出的损失函数。EIoU将GIoU的宽高比损失项分解为预测框宽高与最小外接框宽高的差值,在提高回归精度的同时,大幅提高了收敛速度。同时,引入Focal Loss优化边界框回归中难易样本不平衡的问题,使回归只专注于目标框回归过程中质量高的锚框。
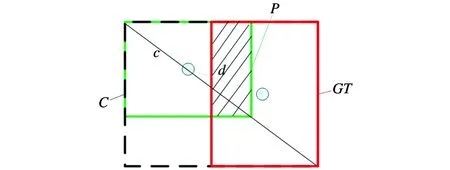
图2 真实框GT与预测框PFig.2 Prediction box P and real box GT
EIoU损失函数包括3部分:预测框与真实框的重合损失LIoU、中心差距损失Ldis、宽高损失Lasp:
式中:b和bgt分别为预测框和真实框的中心点;w和wgt分别为预测框和真实框的宽;h和hgt分别为预测框和真实框的高;ρ为预测框和真实框中心点的欧氏距离;Cw和Ch分别为覆盖预测框和真实框的最小外接框的宽和高。EIoU将真实框与预测框之间的重合面积、中心点距离和宽高比统一纳入考虑范围,在目标框回归过程中得到了更加稳定的结果,在收敛过程中得到了更高的精度。
2.2 添加注意力机制模块
注意力机制是一种用于深度学习模型的关键技术,它使得神经网络模型在处理输入数据时更加关注重要部分,过滤不重要部分,从而提高模型性能。在计算机视觉领域,注意力机制被应用于图像分类、目标检测和图像生成等任务。
2018年,HU等[17]提出了一种注意力机制结构SENet (Squeezeand-Excitation Network),通过学习,自动获取每个特征通道的重要程度,并对重要程度进行灵活分类,对识别为有用的特征进行积极提升,对识别为对当前任务无用的特征进行抑制,该方法获得了巨大成功。但SENet中的降维操作存在问题,会严重干扰通道注意力的预测,对其产生消极影响;与此同时,该方法获取依赖关系的效率也较低。虽然后续基于SENet的改进方法通过捕获更加复杂的通道依赖性提升了精度,但模型复杂度更高,计算量大幅增加。
本文在YOLOv5s 模型中引入注意力机制模块CBAM[18]。CBAM包括通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM),引入空间注意力和通道注意力两个分析维度,实现从空间到通道的顺序注意力结构变化,在足够轻量化的同时,有效提升了模型的检测效果。结构见图3。
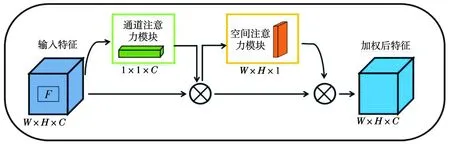
图3 CBAM结构Fig.3 CBAM structure
式中:σ为sigmoid函数;MLP为包含两个全连接层和ReLU激活函数的多层感知机;f7×7为卷积核大小为7×7的卷积运算。
笔者对自己所在的某地区片区20所学校全体英语教师(242名)、全体学生、教学管理者开展了英语教学方面的调查,并以就近5所城市实验小学全体英语教师(86名)、全体学生、教学管理者的调查作为参照,探讨了如何有效利用多媒体辅助手段,激发农村学生的学习热情,提高英语课堂教学效率。
全部注意力过程:
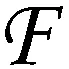
式中:⊗表示按元素级相乘。
本文在YOLOv5 模型中加入CBAM注意力机制模块,在YOLOv5的Backbone部分CSP模块中添加CBAM模块,变为CBAM-CSP,其余参数不变。
3 试验与分析
本文试验部分首先对损失函数进行改进,使用EIoU代替GIou来计算定位损失;然后在网络中插入注意力机制模块CBAM,并与其他注意力机制进行对比;最后采用交叉验证的方法进一步检测本文方法的有效性。
3.1 数据集及试验环境
本文使用的数据集为国内开源数据集fdd-dataset,该数据集主要通过车载摄像头拍摄驾驶员的不同驾驶状态,十分符合实际驾驶中的疲劳场景。数据集共有2 914张图片,其中,包括545张疲劳驾驶图像(包括闭眼和哈欠),分辨率为640×480。为训练优良的检测模型,将通过样本扩充获得的图片按3∶1∶1的比例随机划分为训练集、验证集和测试集。划分后的数据集见表1,试验环境见表2。试验基于深度学习开源框架TensorFlow,采用Python语言编程。

表1 训练、验证和测试集图像数量Tab.1 Numbers of training,verification and test sets /张

表2 试验平台Tab.2 Experimental platform
3.2 评价指标
本试验采用精确率P(Precision)、召回率R(Recall)、多个类别平均精度mAP(mean average precision)为模型性能的评价指标[19]。
式中:TP为预测为正实际为正的数量;FP为预测为负实际为正的数量;FN为预测为负实际为正的数量;Precision为预测正确的正样本比例;Recall为正确判定的正样本占总正样本的比例。

mAP为n个标签类别AP的平均值,定义为
3.3 试验结果与分析
3.3.1 消融试验
在消融试验部分,首先改进原始YOLOv5的损失函数,在保持其他条件不变的前提下,使用 EIoU代替GIoU来计算定位损失,并将此算法命名为YOLOv5-EIoU。将YOLOv5-EIoU与原始YOLOv5及采用CIoU为损失函数的YOLOv5-CIoU进行对比。3种算法的收敛结果见图4。由图4可见:相比于原始YOLOv5,采用新损失函数EIoU的YOLOv5-EIoU算法在收敛速度上更快,且损失一直小于YOLOv5算法;相比YOLOv5-CIoU,YOLOv5-EIoU收敛速度也更快,说明EIoU损失函数的性能高于GIoU损失函数和CIoU损失函数。
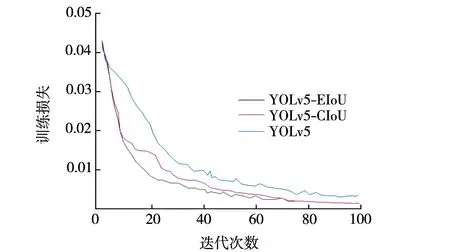
图4 收敛结果对比Fig.4 Comparison of convergence results
通过改进定位损失函数,对YOLOv5s进行初步改进后,再对网络插入注意力机制模块CBAM,将此模型称为CBAM-YOLOv5s。表3为使用注意力机制模块CBAM前后,YOLOv5s、SE-YOLOv5s与CBAM-YOLOv5s检测结果对比。

表3 3种模型试验结果Tab.3 Experiment results of three models
由表3可见:与原始YOLOv5s相比,使用注意力机制模块CBAM的CBAM-YOLOv5s在检测精度和召回率上都有提升,其中,准确率提升2.7%,召回率提升2.9%,网络精度提升3.6%,模型体积与参数量小幅上升。与SE-YOLOv5s相比,使用注意力机制模块CBAM的CBAM-YOLOv5s在准确率、召回率和mAP上都有提升,其中,准确率提升1.1%,召回率提升0.9%,网络精度提升1.1%,模型体积与参数量略微增加。对比结果表明,注意力机制模块CBAM的加入使得网络能够有效提取图像特征,提高目标检测精度,更适用于本文的疲劳驾驶检测任务。
为了进一步评估深度学习模型的性能,本试验将选用的测试集按照闭眼、哈欠细分为两个子测试集,采用交叉验证的方法来检测本文方法的有效性。为避免偶然性,分别对两种子测试集各进行两次试验,分别计算两次试验的准确率,结果见表4。由表4可见:与原始YOLOv5s相比,使用了注意力机制模块CBAM的CBAM-YOLOv5s在两种检测上的精度都有小幅度提升,其中,闭眼检测精度提高了3.6%,哈欠检测精度提高了3.8%。

表4 交叉验证检测精度Tab.4 Test accuracy of cross validation /%
3.3.2 疲劳驾驶检测
使用改进后的CBAM-YOLOv5s疲劳驾驶检测模型对测试集进行检测,结果见面图5。其中,图5 a为测试集中检测到的正常驾驶状态,图5 b为闭眼状态,图5 c为哈欠状态。由图5可见:改进后的CBAM-YOLOv5s疲劳驾驶检测模型能够有效避免背景环境的干扰,将检测集中于图片中驾驶员的眼部及嘴部,能够精确检测出驾驶员的正常驾驶、闭眼和哈欠状态。

图5 CBAM-YOLOv5s疲劳驾驶检测结果Fig.5 Test results of CBAM-YOLOv5s fatigue driving
4 结 论
本文提出了一种基于改进YOLOv5s的疲劳驾驶检测算法。通过改进EIoU损失函数,提高模型精度与鲁棒性;通过添加注意力机制模块CBAM,提高算法的特征提取能力和检测精度。试验结果表明,改进后的模型相较于原始YOLOv5s模型,准确率提高了2.7%,召回率提高了2.9%,网络精度提高了3.6%,体积与参数量小幅增加,闭眼检测精度提高了3.6%,哈欠检测精度提高了3.8%,模型收敛速度加快。该方案运用体积较小的深度学习模型,实现对眼睛睁闭和哈欠的检测,继而判断驾驶员的疲劳状态,具有一定的工程应用价值。下一步将进一步优化网络结构,研究模型实际部署于边缘端后遇到的问题及解决方案,在实际的疲劳驾驶检测中完善和改进模型。
