优化单片机性能的课程实验教学改革
2024-01-19高歌
高 歌
(济宁学院 产业学院,山东 曲阜 273155)
随着现代工业的快速发展,单片机(Micro controller Unit,简称MCU)技术迅速发展,在工业控制、智能家用电器、通讯和军事等众多领域得到了越来越广泛的应用,社会对掌握该技术的人才需求越来越大。“单片机原理及应用”课程作为自动化类专业的基础课程,要求学生不仅需要掌握单片机大量的理论知识,还要进行理论和实践相结合,才能更深入地理解单片机知识。实验教学作为课程教学的一个教学环节在整个教学中具有重要的作用,它不仅可以使学生加深对理论知识的理解,还能够培养他们的动手操作能力,开拓他们的思维[1]153-154。
单片机课程实验教学中,由于MCU资源有限,单片机的实验教学面临着很大的挑战,如何在有限的资源下提高MCU的工作效率变得十分重要。实验教学中需要在提高性能和效率的前提下尽可能降低功率,按照当前研究来看,大多数MCU实验的思路都是通过提高工作效率来尽快完成当前任务,然后使单片机进入低功率状态,这样不仅能够减少资源的浪费,还能从整体上提高效率。提高嵌入式单片机的性能是当前研究人员广泛关注的课题之一,不同的架构和系统功能的内部运行方式往往存在一些细微差别,而这些差别会影响到系统的表现。
论文以飞思卡尔Kinetis K系列MCU为例,分析影响系统性能的因素,通过在实验中提高MCU运行效率来对系统的性能进行优化,确保学生提高对MCU的认识和理解,能够获得更好的实验教学效果。Kinetis K系列芯片是2010年Freescale公司推出的基于ARM®CortexTM-M4内核的芯片,MCU的基本结构示意图[2]如图1所示。
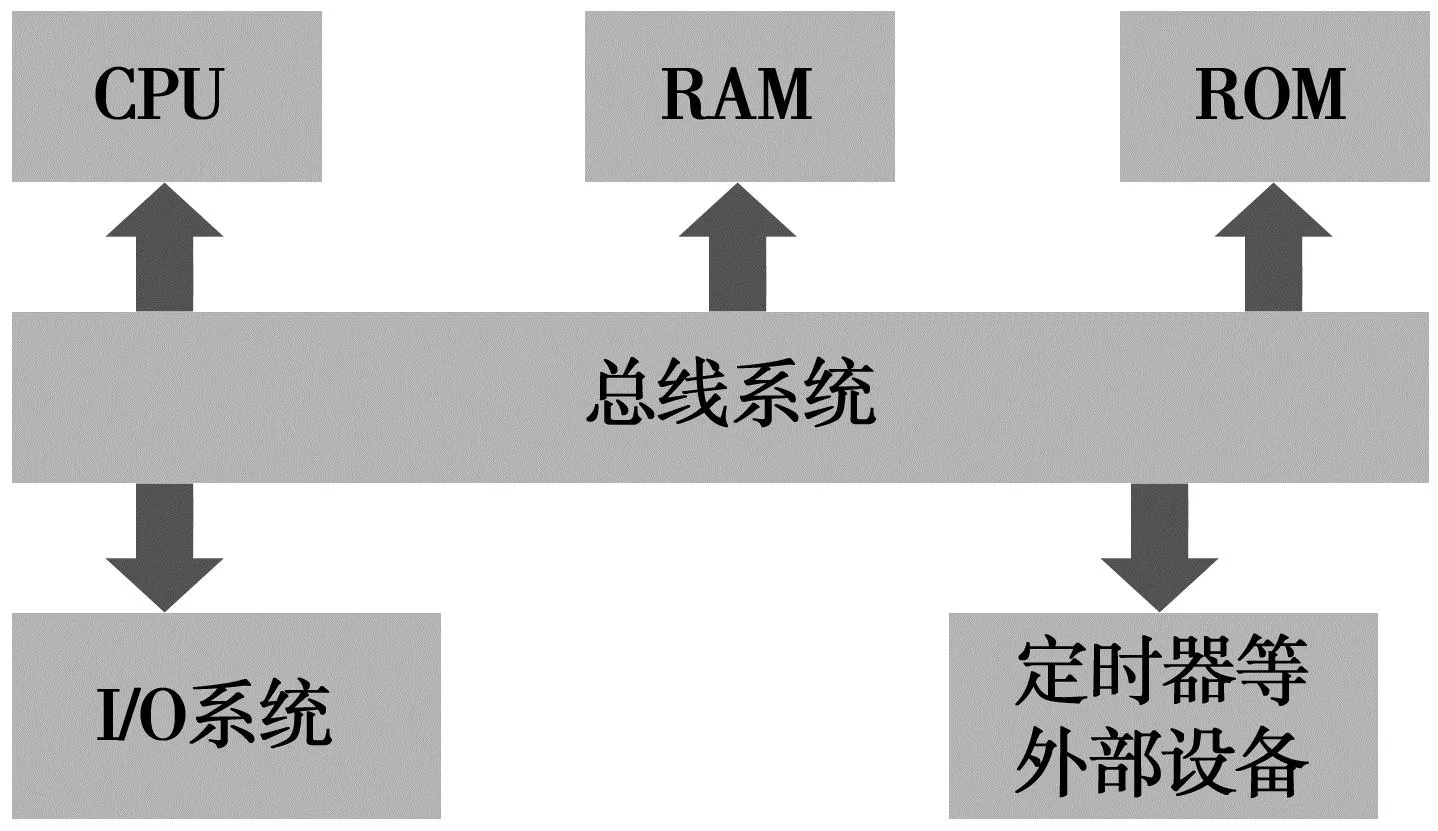
图1 MCU的基本结构图
一、Kinetis K 系列架构和主要硬件概述
Kinetis K系列的系统主要由Kinesis内核总线、SRAM静态存储器、系统缓存、闪存控制器(FMC)、交叉开关(AXBS)组成。经过多年的发展,Kinetis K系列逐渐成熟,简化结构框图[3]如图2所示。
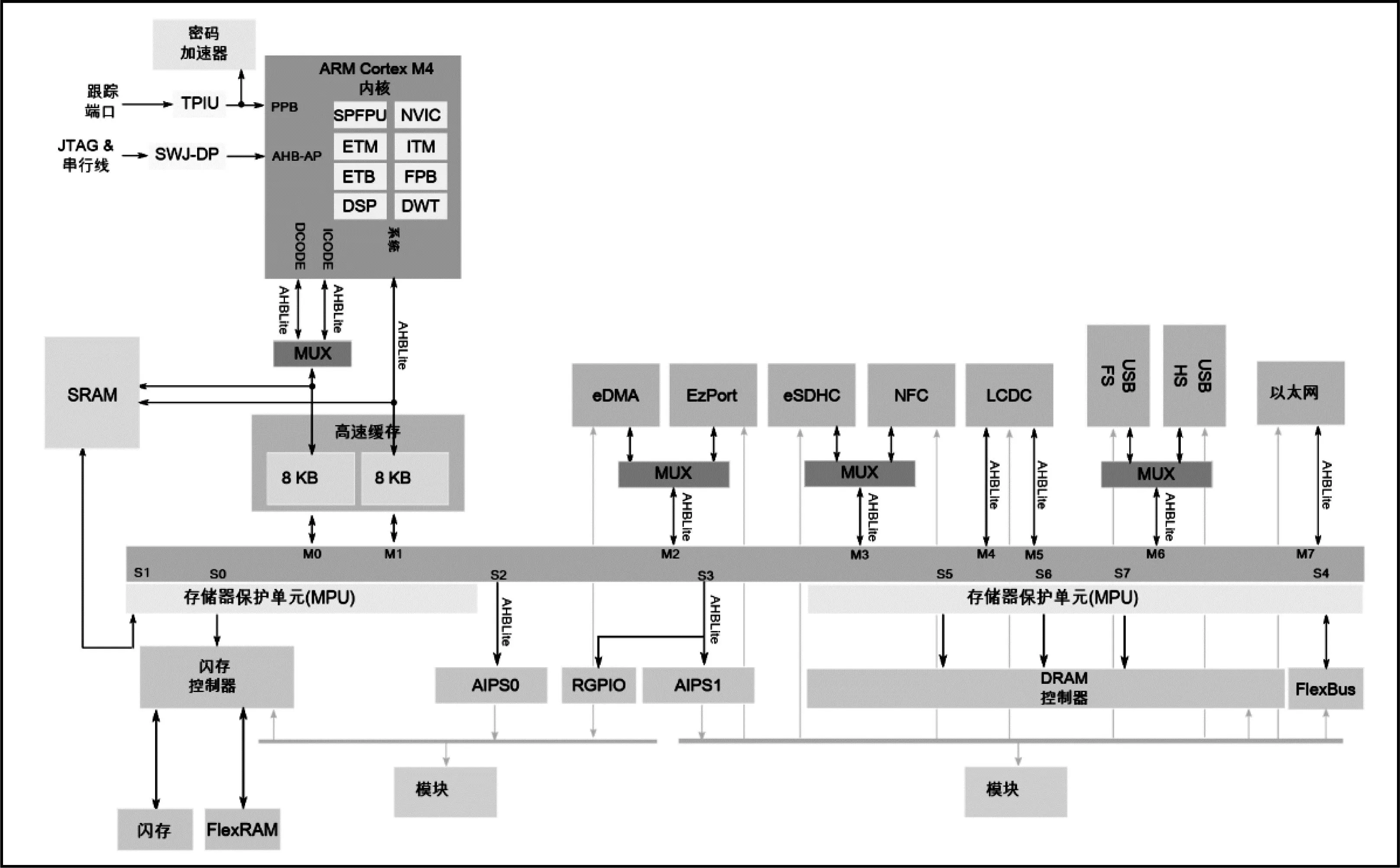
图2 Kinetis K系列的简化结构框图
Kinesis K系列的系统架构是影响单片机整体性能最重要的因素之一。内核总线中,系统总线周期的时序取决于访问类型。系统总线的数据访问在内核无附加延时,而指令访问则会在内核增加一个等待状态。Kinetis系统的存储器映像汇总了地址在0x2000_0000以下的主要存储器区域,使得从外部存储器执行代码时发挥最大性能[4]2。
SRAM静态存储器是负责存储代码和数据的区域,内核端口可通过CODE总线和系统总线访问SRMA,MCU片上的非内核主机也可通过后门端口访问SRAM,所有Kinetis K系列器件都含有两个片上SRAM块。第一个块(SRAM_L)映射于CODE总线,第二个块(SRAM_U)则映射于系统总线。由于SRAM控制器处理的访问端口比SRAM块要多,因此SRAM控制器具有内部的仲裁逻辑。仲裁过程通过MCM_CR中的字段进行控制,给每个SRAM块预留了可编程的仲裁模式。
Kinetis器件中含有可显著提高性能的系统缓存,系统缓存实际上包含两个独立的8KB高速缓存块。第一个8KB缓存用于CODE总线访问,第二个8KB缓存用于系统总线访问。高速缓存的设置通过使用预定义的地址区域进行配置。系统缓存的存在,使得在从外部存储器执行代码时,速度优势尤为明显。
闪存控制器(FMC)是闪存块和系统的接口。在典型配置中,内核总线和系统总线的时钟速度比闪存时钟的速度要快得多。FMC具有的一些特性可用来加速闪存访问,FMC缓存和预取推理缓冲器可使FMC响应闪存访问时无附加等待状态。只要请求的信息在缓存和预取缓冲器中可用,FMC的响应无附加等待状态。
交叉开关是微控制器的主要总线互连结构。交叉开关负责处理总线主控器和从端口之间的连接,当多个主控器同时尝试访问同一从端口时,还负责处理主控器之间的仲裁。
二、实验教学中存在的问题
在单片机(MCU)实验教学过程中,作为课堂教学的一个教学环节,通常是教师提供实验程序,学生在规定的时间内按照规定的步骤完成实验内容。学生在实验中很少涉及实际的电路编程内容,导致学生对设计类实验无从下手,不知道如何进行系统设计。在实验教学中,通常存在以下问题:
1.实验教学内容与最新技术的整合不足。随着技术的快速发展,实验教学需要与最新的技术和平台进行整合,以提供更全面、实用和前沿的教学内容。对于一些老旧的Kinetis单片机型号,可能无法利用最新技术进行教学和开发,因此需要合理地利用一些隐藏式的功能来提高教学效果。
2.实验教学案例相对缺乏。对于初学者来说,缺乏实际的教学案例可能导致理论知识与实际应用脱节。所以需要提供丰富的教学案例,来帮助学生更好地理解和应用Kinetis系列单片机的功能和特点。
3.教学过程中互动与实践环节相对较少。在课程实验教学中,应注重互动与实践环节的设计。缺乏互动和实践的环节可能导致学生对Kinetis系列单片机的理解和应用存在局限性,无法真正掌握相关技能。
三、实验教学性能优化方案分析
针对实验教学中存在问题,以Kinetis K系列单片机为例,通过尽可能多地使用SRAM_L块存储关键代码和数据、使用MUC系统缓存、闪存控制器(FMC)中固有的闪存加速特性、合理使用代码优化功能、采用DMA传输大块数据、采用错误检测和冗余设计等措施来优化系统,提高单片机的性能和可靠性,提高实验教学效果和实验效率。
(一)尽可能多地使用SRAM_L块存储关键代码和数据
所有Kinetis K系列单片机都设置有两个片上SRAM块。第一个块(SRAM_L)映射于CODE总线,第二个块(SRAM_U)则映射于系统总线。访问存储器本身仅需一个周期,但由于指令访问系统总线时在内核延时一个时钟周期,所以SRAM_U的指令访问至少需要两个时钟周期。SRAM_L是唯一能存放代码也能存放数据的存储器,并且始终保证内核访问仅需一个周期。因此,尽可能多地使用SRAM_L块具有很大意义,它是存放关键代码的良好区域。
SRAM_L和SRAM_U是Kinetis K系列单片机内部的两个独立的RAM区域,它们的地址空间是连续的,但是访问方式不同。SRAM_U是通过系统总线访问的,SRAM_L是通过代码总线访问的。这意味着SRAM_U可以更快地存储和读取数据,而SRAM_L可以更快地执行代码[5]5。
Kinetis K系列单片机提供了修改SRAM_L和SRAM_U配置的方法,具体可以通过采取以下步骤来实现:
1.修改链接器配置文件(ICF文件),定义SRAM_L和SRAM_U的起始和结束地址,以及相应的内存区域[6]3。如:
define symbol __ICFEDIT_region_RAM_start__ = 0x1FFFC000;
define symbol __ICFEDIT_region_RAM_end__ = 0x1FFFFFFF;
define symbol __region_RAM2_start__ = 0x20000000;
define symbol __region_RAM2_end__ = 0x20003FFF;
define region RAM_region = mem:[from __ICFEDIT_region_RAM_start__ to __ICFEDIT_region_RAM_end__];
define region RAM2_region = mem:[from __region_RAM2_start__ to __region_RAM2_end__];
place in RAM2_region {section MY_RAM2};
2.在程序文件中,使用特殊的关键字或属性来指定变量或函数的存储位置。如,在IAR编译器中,可以使用@符号来进行绝对定位[7]3。
uint8_t buffer[1024]@“MY_RAM2”;//将buffer数组放在SRAM_U中
void my_function(void)@“MY_RAM2”;//将my_function函数放在SRAM_U中
3.在对变量和函数进行定义时不要超过16KB,否则会导致编译器报错。如果需要使用大于16KB的数组或结构体,可以将它们分割成两个或多个小于16KB的部分,并分别放在SRAM_L和SRAM_U中。
因此,通过步骤1-3的自由组合,可以配置SRAM_L和SRAM_U的具体地址和内存区域,将重要的指令存储在代码执行较快的SRAM_L中,并且将超过16KB的数组或结构体分割,存储在数据访问较快的SRAM_U中,从而提高单片机程序的运行效率。
(二)尽量使用MUC系统缓存
缓存是一种高速的内存,它可以存储单片机频繁访问的代码或数据,从而减少对慢速的外部存储器(如Flash或SDRAM)的访问[8]35。Kinetis K系列单片机内部集成了一个4KB的系统缓存(System Cache),它可以用于加速对Flash和FlexRAM(可作为EEPROM使用)的访问。系统缓存可以配置为四种模式之一:禁用模式、写回模式、写通过模式、只读模式。
论文设计了一个互动和实践结合的实验,来引导学生了解如何优化系统缓存,提高访问速度。根据系统提供的现有功能,让学生在系统缓存四种模式之下分别运行同样的测试程序,并对比不同缓存模式下测试程序对Flash和FlexRAM的访问速度,自行总结出最优选择。
实验设计思路为:首先,创建一个新的工程,添加系统缓存驱动程序和头文件,编写主函数和测试函数,分别用于初始化系统缓存和测试对Flash和FlexRAM的访问速度。其次,编译并下载程序到开发板上,分别设置系统缓存为禁用模式、写回模式、写通过模式和只读模式,观察并记录串口终端上显示的结果。再次,将四种缓存模式下对Flash和FlexRAM的访问时间进行比较和分析。最后,总结出系统缓存对单片机性能的影响。
通过实验,可得到如下结果:
1.禁用模式。在这种模式下,系统缓存没有起到任何作用,所有对Flash和FlexRAM的访问都直接通过总线进行,因此访问速度最慢。根据实验代码,假设每次读取一个字(4字节),那么访问Flash和FlexRAM各需要1000次,总共需要2000次。假设总线频率为60MHz,那么每次访问需要16.67ns,那么总共需要33.34μs[9]。
相关部分代码如下:
......
cache_mode=kCacheDisableMode;//设置缓存模式为禁用模式
CACHE_DRV_Init(cache_mode);//初始化系统缓存,并设置其工作模式
print_string(“Cache mode:Disable ”);//打印缓存模式
test_flash();//测试对Flash的访问速度
test_flexram();//测试对FlexRAM的访问速度
......
2.写回模式。在这种模式下,系统缓存被启用,并且当缓存行被替换时,它会将修改过的数据写回到Flash或FlexRAM中。这种模式可以提高对Flash和FlexRAM的读取速度,但也会增加对Flash和FlexRAM的写入时间。根据实验代码,假设每次读取一个字(4字节),那么访问Flash和FlexRAM各需要1000次,总共需要2000次。假设系统缓存命中率为80%,那么缓存命中时的访问时间为0.1ns,缓存未命中时的访问时间为16.67ns,总共需要6.68μs。但是,由于系统缓存是写回模式,当缓存行被替换时,还需要将其写回到Flash或FlexRAM中。假设每次写入一个字(4字节),那么写入Flash和FlexRAM各需要250次(假设每个缓存行有4个字),总共需要500次。假设写入Flash和FlexRAM的时间分别为100μs和10μs,那么总共需要55000μs。因此,写回模式下的总时间为55006.68μs[10]13。
相关代码如下:
......
cache_mode=kCacheWriteBackMode;//设置缓存模式为写回模式
CACHE_DRV_Init(cache_mode);//初始化系统缓存,并设置其工作模式
print_string(“Cache mode:Write Back ”);//打印缓存模式
test_flash();//测试对Flash的访问速度
test_flexram();//测试对FlexRAM的访问速度
......
3.写通过模式。在这种模式下,系统缓存被启用,并且当缓存行被修改时,它会同时更新Flash或FlexRAM中的数据。这种模式可以提高对Flash和FlexRAM的读取速度,但也会增加对Flash和FlexRAM的写入时间。根据实验代码,假设每次读取一个字(4字节),那么访问Flash和FlexRAM各需要1000次,总共需要2000次。假设系统缓存命中率为80%,那么缓存命中时的访问时间为0.1ns,缓存未命中时的访问时间为16.67ns,总共需要6.68μs。但是,由于系统缓存是写通过模式,当缓存行被修改时,还需要同时更新Flash或FlexRAM中的数据。假设每次修改一个字(4字节),那么修改Flash和FlexRAM各需要1000次,总共需要2000次。假设修改Flash和FlexRAM的时间分别为100us和10us,总共需要220000μs。因此,写通过模式下的总时间为220006.68μs[11]。
相关代码如下:
......
cache_mode = kCacheWriteThroughMode;//设置缓存模式为写通过模式
CACHE_DRV_Init(cache_mode);//初始化系统缓存,并设置其工作模式
print_string(“Cache mode:Write Through ”);//打印缓存模式
test_flash();//测试对Flash的访问速度
test_flexram();//测试对FlexRAM的访问速度
......
4.只读模式。在这种模式下,系统缓存被启用,但只用于读取Flash或FlexRAM中的数据,不允许写入。这种模式可以最大程度地提高对Flash和FlexRAM的读取速度,而不会增加对Flash和FlexRAM的写入时间。根据实验代码,假设每次读取一个字(4字节),那么访问Flash和FlexRAM各需要1000次,总共需要2000次。假设系统缓存命中率为80%,那么缓存命中时的访问时间为0.1ns,缓存未命中时的访问时间为16.67ns。那么总共需要6.68μs。由于系统缓存是只读模式,不会对Flash或FlexRAM进行任何写入操作,因此不会产生额外的时间开销,只读模式下的总时间为6.68μs[12]。
相关代码如下:
......
cache_mode = kCacheReadMode;//设置缓存模式为只读模式
CACHE_DRV_Init(cache_mode);//初始化系统缓存,并设置其工作模式
print_string(“Cache mode:Read Only ”);//打印缓存模式
test_flash();//测试对Flash的访问速度
test_flexram();//测试对FlexRAM的访问速度
......
综上,四种模式下访问Flash和FlexRAM的时间如表1所示,显然当使用系统缓存时,能够减少对Flash和FlexRAM的读时间,但是由于写回模式和写通过模式下需要对Flash和FlexRAM进行写操作,反而极大的增加了操作的总时间。因此,如果需要提高系统运行效率,应当设置系统缓存为只读模式。
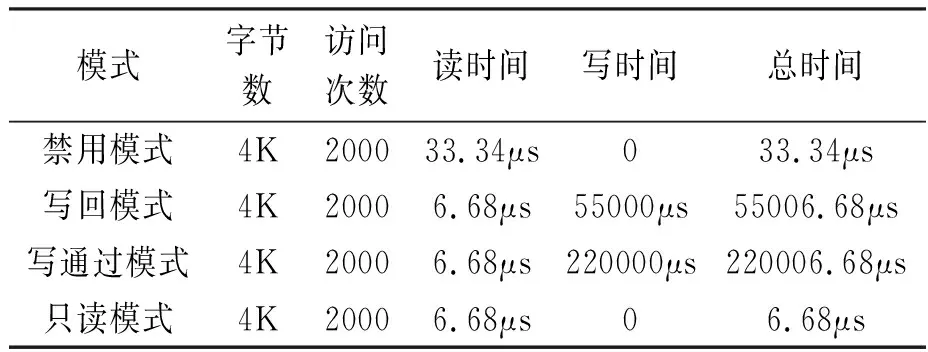
表1 四种模式下访问Flash和FlexRAM的时间
(三)其他优化方案
此外,还有一些常见的单片机性能优化方法,主要包括:
1.预先对数据传送和代码位置进行计划,选择合适的总线和外设来传输数据,以避免冲突和延迟。选择合适的存储器来存放代码,以提高执行速度和效率,选择合适的缓存模式可以优化闪存和SRAM的访问。
2.充分利用闪存控制器(FMC)中固有的闪存加速特性。利用FMC提供的FlexMemory功能,将部分闪存作为EEPROM使用。这样可以在不增加外部存储器的情况下,实现数据的非易失性存储和快速访问。FlexMemory还支持分区功能,可以根据应用需求灵活地配置EEPROM和闪存的大小。利用FMC提供的安全访问功能,保护闪存中的敏感数据或代码。FMC可以设置不同的访问权限,如只读、只写、读写或禁止访问,以及不同的访问范围,如字节、页或扇区。FMC还支持闪存保护单元(FPU),可以对闪存中的特定区域进行加密或解密。
3.合理使用代码优化功能。编译器通常为优化速度或空间提供了一个选择,表面上看来,优化速度是优化性能的最佳方案,但事实并非总是如此。如果对空间的优化可以为SRAM块中的模式代码留有余地,或者更利于在缓存中容纳函数,那么优化空间可能更利于提升系统性能。实验可以设置相应的开关选项,以确定最佳的编译器设置。如,在IAR Embedded Workbench中,可以通过Project->Options->C/C++ Compiler->Optimizations来设置优化级别和相关选项。在Keil MDK中,可以通过Project->Options for Target->C/C+±>Optimizations来设置优化级别和相关选项[13]。
4.采用DMA传输大块数据。DMA传输数据比内核的效率更高。使用DMA还可释放内核,便于内核执行其他任务(更加并行化)。在Kinetis K系列单片机中,有一个eDMA(增强型直接内存访问)模块,它可以支持多达16个DMA通道,每个通道可以配置不同的触发源、传输属性和中断选项。eDMA模块可以与I2C(串行总线)模块配合使用,实现I2C读取或写入大块数据的功能[14]60-65。
5.采用错误检测和冗余设计等措施来优化系统可靠性,如使用校验算法定期检查存储器中的数据是否错误。错误检测和冗余设计是两种常用的可靠性优化措施,它们可以提高系统的容错能力和抗干扰能力。具体来说,错误检测是指通过一定的算法或电路,检测系统中是否存在错误或异常,并及时报告或纠正。冗余设计是指在系统中增加额外的元件或功能,以备原有的元件或功能出现故障时替代使用。
以上单片机性能优化的思路,就是下一步实验教学的改进方向,希望能在以后的工作中持续深化。
结语
论文通过优化实验教学方法,整合新技术和平台,并提供实际实验案例,改进了教学环节,提高了高校实验教学的趣味性和实用性,达到了较好的教学目的。在实验案例的设计上,通过引导学生编写测试程序验证不同设置下的单片机运行效率,使学生们直观地了解了系统性能优化的方法、过程和意义,从而提升了教学效果。
