企业社会责任与股价崩盘风险:“信息桥梁”或“信息误区”?
2024-01-18李宁,尉昊
李 宁,尉 昊
(兰州财经大学 会计学院,甘肃 兰州,730020)
一、引言
资本市场中上市公司股价崩盘现象频发,如美国1929 年发生的股市大崩盘、日本1989 年股市的泡沫宣告破裂,国内昔日“股王”安硕信息、2016 年万科股份公司的股价崩盘以及2020 年瑞幸咖啡股价暴跌等事件让投资者至今谈之色变,因此股价崩盘相关研究一直以来受到业界和学术界的广泛关注。股价崩盘一方面损害投资者的利益,危害金融市场的正常运行,引发金融危机;另一方面使企业产生财务危机,不利于其稳定发展。对于股价崩盘现象的研究,不仅可以纠正投资者自身的投资决策偏误,而且对促进企业可持续发展和国家金融稳定具有重要意义。
目前,多数学者认为造成股价崩盘的主要原因是信息不对称,而社会责任报告是企业非财务信息的主要载体之一,其中必然存在着信息不对称的现象。由于我国社会责任报告披露形式的相关准则不够完善,披露质量与国际相比差距仍十分明显,使得企业管理层有机可乘,社会责任报告成为企业进行印象管理的阵地。管理层通过选择性披露操纵文本信息,主要体现在文本可读性、文本语调等方面,采用过度强调“正面信息”或者过度隐匿“负面消息”等手段,提升企业声誉以获得或维持合法性地位,进而实现企业利润最大化目标[1]。除此之外还发现上市公司社会责任报告所披露的信息几乎未作调整,出现变动的仅为某些具体事件和数字,全部套用照搬的现象被称为“克隆社会责任报告”[2],并且大部分仅是为应对证监会、国资委、上交所和深交所的规定而发布社会责任报告[3]。过度的印象管理其实质是欺诈性的[4]42,所提供的信息会误导利益相关者的评估与决策行为,最终会造成企业股价崩盘风险增加。
为了探究社会责任披露对股价崩盘的影响,本文基于LDA 主题模型提取2010—2022 年企业社会责任报告中的文本主题指标,构建股价崩盘风险模型,探讨社会责任报告文本主题指标与股价崩盘风险之间的关系,以为投资者提供更加可靠的信息,保障投资者利益;同时相比于传统模型,采用机器学习模型对股价崩盘风险进行预测分析,克服了由于变量过多导致的多重共线性、内生性的问题,增强预测的可靠性。
二、理论分析与研究假设
(一)社会责任文本主题指标与股价崩盘风险模型
在当前经济市场,有效的股价崩盘风险预测能够维护国家金融市场的稳定,减少资源错配,保持实体经济的正常运行,对于投资者自身的风险管理也具有重要的现实意义。以往研究主要使用专业机构评级数据建立股价崩盘风险模型,但评级机构是以第三方的角度对企业进行评价,可能存在个人主观评判。企业社会责任报告作为企业非财务信息披露的重要载体,相比于企业评级机构单纯的评分分值,更能具体地反映企业履行的社会责任,其披露在一定程度上能够减缓信息不对称[5]。此外,企业社会责任报告段落之间的衔接、语言的表达及语调的安排都会影响信息使用者对该报告的理解。所以直接从企业社会责任报告中提取相关文本主题指标,建立股价崩盘模型,不仅可以避免第三方角度的主观评价,弥补企业评级机构数据的缺陷,同时也能够获取更深层次的文本信息。因此,在单一企业评级机构数据指标的基础上,LDA主题模型提取的文本主题指标可以提升预测股价崩盘风险的能力。基于此,提出假设:
H1:社会责任文本主题指标能够显著提升股价崩盘风险模型的预测性能。
(二)社会责任信息披露与股价崩盘风险
现有的关于社会责任信息披露对股价崩盘风险的影响主要有两种观点:(1)企业社会责任信息披露会提升股价发生崩盘的风险;(2)企业社会责任信息披露会抑制股价发生崩盘的风险。其中,持第一种观点的学者发现当企业的经营成果不理想时,管理层出于维护自身利益的动机会操纵文本信息,进而导致投资者的决策失误,增加股价崩盘的风险。此外,管理层也会通过印象管理操纵社会责任报告信息,具体表现为隐匿坏消息,回避企业效益不佳等,通过向资本市场释放好信息,以期利用各种手段来实现自身利益最大化,但坏消息的隐匿终究是纸包不住火,一旦负面消息集中释放,最终会增大股价崩盘风险[6]。与此相反,一些学者则认为企业履行社会责任间接表明企业管理层拥有更高的伦理和道德标准,更倾向基于自身的优势去为社会谋福利,重视本身的社会价值,其社会责任报告的披露有助于真实反映企业的社会责任履行情况,从而提高企业财务报告信息的透明度,抑制股价崩盘风险[7]。
综上所述,企业基于自利性动机选择性披露企业社会责任报告,即在信息披露时,管理层可以决定如何披露社会责任信息。一般体现为凸显对自身的有利消息,而对坏消息避之不谈[8],粉饰企业社会责任报告,进而使得信息使用者进入“信息误区”。研究发现过度的印象管理,即欺诈性印象管理会增加企业额外的成本支出,降低信息的可靠性、相关性,不利于企业持久经营[4]41的同时也会导致利益相关者对企业形象识别不清,进而造成信息使用者决策偏误,损害利益相关者的利益[9]。一旦利益相关者识别出企业释放的虚假好信息,就会抛售股票,进而造成企业股价断崖式下跌。与欺骗性印象管理不同,采用适度策略性印象管理有助于获得公众的信赖,提升企业自身形象,进而吸引投资者投入更多的资源[10],降低股价崩盘风险。基于此,提出假设:
H2:社会责任披露信息与股价崩盘风险之间呈现“U”型关系。
三、研究设计
(一)样本选择与数据来源
2008 年5 月,上海证券交易所发布《关于加强上市公司社会责任承担工作的通知》,强制性要求各上市公司定期在上海证券交易所网站披露公司的社会责任报告,使得自2009 年起上市公司披露的企业社会责任报告成倍增加。所以本文选取2010—2022年上市公司公开发布的企业社会责任报告作为样本。其企业社会责任报告均从巨潮资讯网下载得到,社会责任文本主题指标通过LDA 主题模型提取整理所得,机构评级数据的选取来自和讯网。
(二)变量定义
1∙被解释变量
被解释变量为股价崩盘风险,若上市公司在经营期间发生了股价崩盘,则将上市公司当期样本的变量赋值为1,若上市公司未发生股价崩盘,则赋值为0。将股价崩盘的变量定义为Crash[11]:
其中,wi,t为第i家上市公司第t年的特定周收益率,Average(wi,t) 表示第i家公司股票第t年的特定周收益率均值,σi,t表示第i家公司股票第t年特定周收益率标准差,3∙09 个标准差对应标准正态分布下0∙1% 的概率区间。如果一年时间里第i家公司股票的特定周收益率满足上式的条件,那就意味着这家公司在该年内发生了股价崩盘事件。
2.解释变量
选取的解释变量为文本主题指标、财务变量、和讯网评级数据指标。具体变量及含义见表1。

表1 变量定义表Tab.1 Variable definition table
(1)文本主题指标变量
使用LDA 主题模型进行社会责任主题指标的构建。LDA 主题模型是一种基于概率图模型的文本主题分析方法,最早由Blei 等[12]在2003 年提出,旨在通过对文本数据进行分析,自动发现其隐藏的主题结构。与相对简单的潜在变量模型相比,LDA 的优点体现在:是全概率模型,具有清楚明晰的层次结构;引入了Dirichlet 先验参数,解决过度拟合的问题,更适合处理大批量文档。LDA 主题模型是基于这样的假设:文本是一个词的集合,忽略任何语法或者顺序关系。其由多个主题构成,而每个主题又是词集的一个概率分布,是由“词-主题-文档”三个层次构成的概率图模型,可以将文档集中每篇文档的主题以概率分布的形式给出,推测文档的主题分布,而后便可以进行主题聚类或文本分类。同时LDA 主题模型在文本分析的基础上考虑了词语在语义中的上下文关系。
困惑度(Perplexity) 是一种常用的机器学习模型评估方法,通常用于评估语言模型的性能。困惑度可以理解为预测一个测试集中每个样本发生的概率的倒数,困惑度越低,语言模型的效果越好。一致性检验则可以检验语言模型生成的每个主题所对应的高概率词语在语义上是否一致,一致性得分越高,则表示模型效果越好。在以往的研究中选择最优主题数常用的方法是最小困惑度法,但是基于最小困惑度法得到的最优主题数数量过多且相似,模型预测效果会变差[13]。基于此,本文将最小困惑度与一致性检验相结合,选择最优主题数。
(2)财务变量
参照荆思寒等[14]3093,将财务指标作为控制变量。选用5 个变量作为财务变量,分别是个股周收益率的标准差、个股收益偏度、当年股票月均换手率-去年股票月均换手率、净资产收益率、总资产对数。其中,参照荆思寒等[14]3092、尉昊等[15]的研究,预测模型中的个股收益偏度采用个股过去一整年的收益偏度。
(3)和讯网评级数据指标
参考沈红波等[16]的研究,选取和讯网评级数据指标作为控制变量。和讯网采用综合评分体系,相比于其他评级机构,该机构评分指标更全面,包含了环境、社会、治理等方面,数据来源更加可靠;其企业社会责任评分数据来源广泛,包括公司公开报告、第三方调查、媒体报道等多个渠道;评价方法更加科学,主观评价和客观评价相结合,评价结果更加客观准确;评价结果更加透明,其评价过程和评价结果都可以被公众查询。基于此,本文选取了和讯网机构的评级数据指标,分别为股东责任、社会责任、员工责任、环境责任、消费者责任、总得分。
(三)模型构建
在机器学习的有监督学习算法中,需要学习出一个能够保持稳定,各个方面表现良好的模型,但实际情况并没有理想中的那么良好,往往只能得到多个具有偏好的模型。基于此,集成学习克服了单个弱监督偏好模型的缺点,将多个弱监督模型组合起来,得到一个更好更全面的强监督模型。集成学习的基本思想是即便某一个弱分类器进行了错误的预测,其他的弱分类器也可以进行纠正错误,可能某一个弱分类器无法得出所需的最优解,但是集成学习能够得到近似解。基于集成学习的优势,本文选用集成学习模型对股价崩盘风险进行预测。以往的研究常用的是滚动时间序列求平均的方法,这种方法是基于模型数据所具有的时间序列属性,即随着时间的变动,数据目标值会发生规律的变动。而本文所选用的上市公司的时间序列属性不强,随着宏观经济的变动以及公司内部经营的改变,企业社会责任报告每年披露数量不同,甚至大相径庭,所以将所选样本总体随机打乱,以训练集: 测试集——8:2 的比例,对股价崩盘风险进行预测。
其中,Crash 表示股票发生股价崩盘,lda 表示社会责任报告文本主题特征,shareholder 表示股东责任,social 表示社会责任,employee 表示员工责任,score 表示总得分,environment 表示环境责任,consumer 表示消费者责任,ε表示回归残差,j表示第j个lda 文本主题特征,i表示第i个股票,t表示第t年,k表示lda 文本主题特征个数。
(四)评价指标
1.准确率(accuarcy)
由训练集得到样本内预测准确率Score-Train,并将训练模型在测试集上进行拟合,由此得到测试集样本内预测准确率Score-Test。具体而言,预测准确率的计算方法为:
其中TP 为真正例,即实际与预测均为正例的样本;TN 为真反例,即实际与预测均为反例的样本;FP 为假正例,是实际与预测出现相反的结果样本,即实际为反例,预测为正例的样本;FN 为假反例,是实际与预测出现相反的结果样本,即实际为正例,预测为反例的样本。TP 与TN 统称为预测正确的样本,而FP 与FN 统称为预测错误的样本,预测准确率反映的就是预测正确的样本在总样本中所占的比例。
2.F1 分数(f1-score)
F1 分数是统计学中用来衡量二分类( 或多任务二分类)模型精确度的一种指标。它兼顾了分类模型的准确率和召回率。F1 分数可以看作是模型准确率和召回率的一种加权平均,它的最大值为1,最小值为0,值越大意味着模型越好。
查准率(precision),是指预测值为1 且真实值也为1 的样本,在预测值为1 的所有样本中所占的比例。具体而言,查准率的计算公式为:
召回率(recall),是指真实值为1 且预测值也为1 的样本,在真实值为1 的所有样本中所占的比例。具体而言,召回率的计算公式为:
F1 分 数(f1-score), 又 称 为 平 衡F 分 数(Balanced-Score),其计算公式为:
3∙kappa 系数评估方法
kappa 系数是基于一致性检验的指标,也可以用于衡量分类的效果。因为对于分类问题,所谓一致性就是实际与假设的结果是否一致,也就是模型预测结果和实际分类结果是否一致。kappa 系数的计算是建立在混淆矩阵基础上的,取值为-1~1,通常大于0。
基于混淆矩阵的kappa 系数计算公式如下:
其中:
即所有类别对应的“实际与预测数量的乘积”之总和,除以“样本总数的平方”。
四、实证分析
(一)LDA 主题模型分析
1∙主题数的选择
主题的个数越多,模型的困惑度就越低,但是,当主题数很多的时候,生成的模型往往会过拟合,所以不能单纯依靠困惑度来判断一个模型的好坏。根据困惑度的实验结果,在合理的范围内进行一致性实验,最后确定效果最好的23 个主题(见图1)。
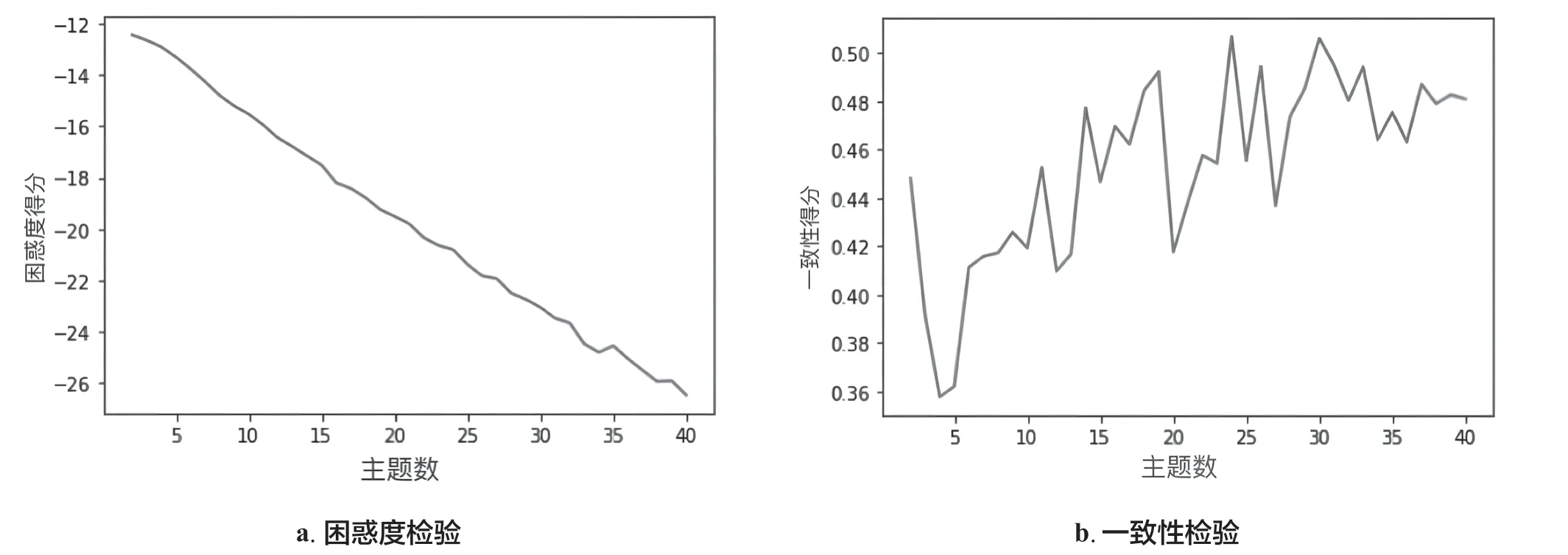
图1 LDA 主题模型的困惑度检验与一致性检验Fig.1 The perplexity test and consistency test of the LDA mode
2∙主题词可视化
对“最小困惑度”与“一致性检验”结合得出的23 个主题进行可视化,观察主题分布情况,结果如图2 所示。图中每个圆圈代表一个主题,从可视化图中可以看出每个圆圈相互独立,互不重叠,这表示23 个主题间相互独立,验证了由“最小困惑度”与“一致性检验”结合得出的主题指标是可行的。

图2 LDA 主题指标可视化结果Fig.2 LDA topic metrics visualization results
(二)模型选择
为了进一步科学地选取预测股价崩盘风险的模型,通过机器学习算法中的评价指标来评估XGBoost、Gradient Boosting、CatBoost、AdaBoost、RandomForest 这五种模型。相比于股价崩盘的企业数量来说,股价不崩盘的企业数量要更多,这就产生不平衡数据,综合准确率(accuarcy)、F1 分数(f1-score)、kappa 系数这三个指标,发现Gradient Boosting 模型在处理不平衡数据样本分类问题上明显优于其他模型,结果见图3。基于此,本文选择Gradient Boosting 模型进行股价崩盘风险的预测。
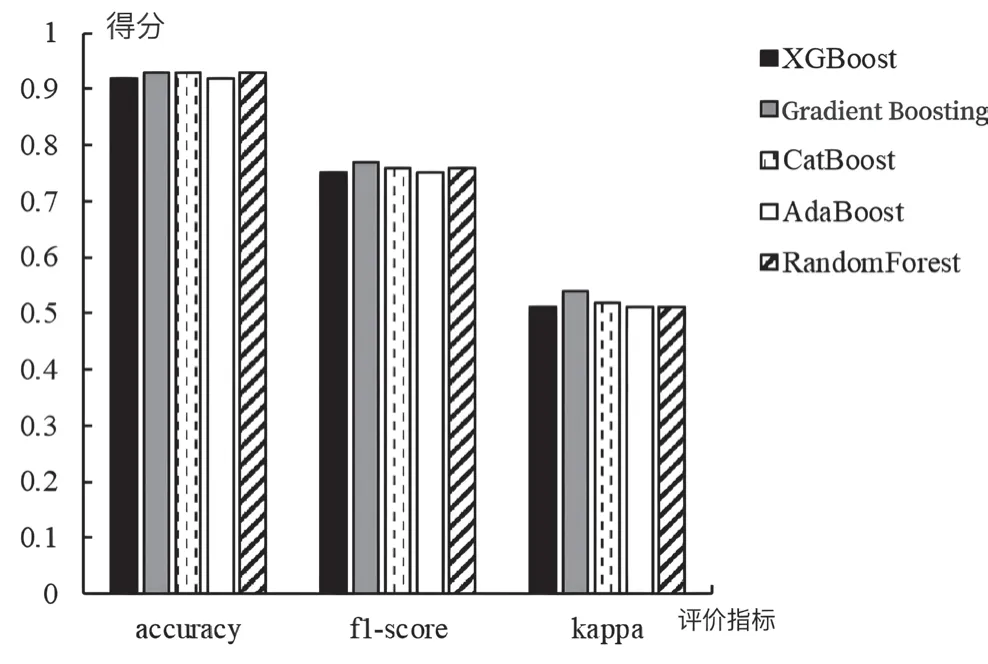
图3 各机器学习模型评价指标Fig.3 Evaluation metrics for each machine learning model
(三)预测结果分析
利用Gradient Boosting 模型分别实证检验社会责任报告信息指标、机构评级数据指标对股价崩盘风险的预测作用(见表2)。其原理是一个变量的相对重要性指的是一个变量在模型拟合过程中,相对于其他变量的重要程度。根据 Friedman[17]的思路,首先建立模型进行预测,观察其预测结果准确度,其次在模型中加入某一变量再次进行预测,观察其预测结果准确度,若后者预测准确度明显高于前者,证明该变量是重要变量。

表2 非结构化社会责任报告信息指标对股价崩盘风险的预测作用Tab.2 The predictive effect of unstructured social responsibility reporting information indicators on stock price crash risk
基于此,本文在含有财务指标的模型基础上分别加入机构评级数据指标与社会责任报告信息指标进行对比分析。在模型1 中,将机构评级数据指标放在模型中进行实证检验,其中总得分指标对股价崩盘风险的预测作用排名为第9。在模型2 中,将社会责任报告信息指标放在模型中进行实证检验,lda16 指标在社会责任报告信息指标中对股价崩盘风险的预测作用排名为第4,显然,社会责任报告信息指标相比于社会评级机构指标,有着更好的预测能力。在模型3 数据中,将社会责任报告信息指标与机构评级数据指标同时放在一个模型中进行实证检验,发现lda16对股价崩盘风险的预测作用的排名要明显高于机构评级数据指标score 的排名,而且在加入社会责任报告指标后,机构评级数据的排名也大幅下降,同时lda16 的排名较比之前也有所上升。综上所述,在初始预测模型中加入重要变量lda16 后,其预测股价崩盘风险的结果准确度明显提高。即lda16 是一个重要变量,它相对于模型中其他指标的重要程度更高,能够更好地提高股价崩盘风险模型的预测准确度,进而得出社会文本主题指标对股价崩盘风险的预测能力明显高于机构评级数据指标的结论。
上述结论出现的原因可概括为:企业评级机构数据存在个人主观评判,不够公允。企业社会责任报告披露内容中含有大量的非结构化信息,作为信息使用者了解企业非财务信息的主要载体,同财务信息一样,这些非结构化信息对于公司治理做出决策也起着非常重要的作用,但是在以往的研究中,非结构化信息未得到学者以及业界的重视,在本文所做的实证检验中,发现加入社会文本主题指标后,提高了股价崩盘风险模型的预测性能。此结果表明社会文本主题指标能够显著提升股价崩盘风险模型的预测性能,印证了假设H1。
图4 反映出总得分score 与股价崩盘风险之间的负向关系,虽然有轻微的波动,但是整体趋势是负向影响,企业总得分越高,股价崩盘风险就越低,即企业社会责任报告披露能够降低股价崩盘风险。这说明企业社会责任评级数据未考虑管理层会采用过度的印象管理手段,进而得出过于片面的结论。
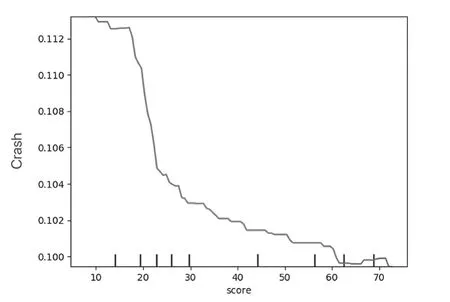
图4 专业机构评级数据对股价崩盘风险的预测机制Fig.4 The predicting mechanism for the risk of stock price crash by professional institutional rating data
图5 表现出LDA 主题模型提取的重要变量lda16 与股价崩盘风险之间非线性的预测关系,即随着lda16 文本特征数量增加到一定水平,股价崩盘风险先降低后增加,表现出“U”型关系。其理由是:在时间推进中,企业以持续经营为目标,在企业社会责任报告披露前期,适度印象管理能够提升企业自身形象,成为企业与信息使用者的“信息桥梁”,得到投资者的信任,提升企业的市值,进而降低股价崩盘风险;随着时间的推移,管理层印象管理行为不断的累积,达到某一水平之上时,从而形成欺诈性印象管理。管理层通过操纵其文本主题特征,对好消息进行过度渲染,对坏消息避之不谈,就会形成“信息误区”,此时信息使用者若不能有效地避开,就会影响其做出决策,损害信息使用者的利益,进而增加股价崩盘风险。综上印证了社会责任信息指标对股价崩盘风险之间的“U”型关系,与假设H2 相符。

图5 社会责任主题指标对股价崩盘风险预测机制Fig.5 Social responsibility theme indicators on stock price crash risk predicting mechanism
五、结论与启示
利用LDA 主题模型提取企业责任报告中的文本信息,构建社会责任主题指标,使用Gradient Boosting 模型进行股价崩盘风险的预测。研究发现:(1)相比于XGBoost、CatBoost、AdaBoost、RandomForest 这四种模型,Gradient Boosting 模型在处理样本不平衡数据时优于其他模型,对股价崩盘预测效果最优。(2)相较于社会责任专业机构评级数据的评分,非结构化社会责任报告信息指标对股价崩盘的作用更显著;在专业评级数据指标中加入社会责任报告信息指标后,股价崩盘模型预测能力显著提高。(3)社会责任报告信息披露与股价崩盘风险之间呈现“U”型关系。
从债权人、投资者等利益相关者视角来看,由于信息的不对称,利益相关者作为企业信息的接收方,被动接受企业披露的信息,处在信息获取的劣势地位。股价崩盘风险预测模型为利益相关者提供一种新型且有效的判别方式,改变了以往单纯分析企业财务指标这一途径,使其能够通过社会责任报告文本主题指标提前预知企业发生股价崩盘的风险,在一定程度上减少信息不对称带来的风险,避免非必要的损失。从监管视角来看,监管机构应尽快出台企业社会责任报告披露的相关规章制度,使企业责任报告的披露形式趋于结构化,更好地保障企业社会责任报告披露的作用。
目前来说,仅从社会责任报告中提取信息,来源比较单一,随着机器学习方法的应用逐步走向成熟,在未来的研究中,可以为大数据挖掘提供更多获取信息的渠道及更为有效的工具。学者可以利用机器学习技术对会计欺诈、股票市场风险溢价等进行更有效的预测。
