融合分类校正与样本扩增的小样本目标检测
2024-01-18黄友文肖贵光
黄友文,豆 恒,肖贵光
江西理工大学 信息工程学院,江西 赣州 341000
近几年,卷积神经网络(convolutional neural network,CNN)[1-2]的发展提高了深度学习的特征提取能力,使通用目标检测器性能得到很大的提升[3-5]。深度检测器通常需要大量带标注的训练数据才能让其性能达到最优[6],然而这些训练样本数据在很多现实场景中都难以获取。相比而言,人类只要给出极少数的样本就可以迅速理解这些新的对象,并且可以识别新类中的物体,模仿人类的学习特性实现小样本目标检测已成为当前学术研究的热点。与一般学习任务需要大量样本的情况不同,小样本学习任务需要在样本不足的情况下完成深度网络模型的有效训练。在小样本学习任务下,深度检测器有严重的过拟合问题,小样本检测任务与通用检测任务的差距大于小样本检测任务和小样本分类之间的差距[7]。这就导致在样本数据稀缺的情况下,深度检测器提取新类信息的能力与人类相差甚远。
小样本目标检测(few-shot object detection,FSOD)相对于小样本分类和通用目标检测难度更高。从算法上看,FSOD有两个分支,一个是以元学习任务为主导,目的是找到对所有任务都通用的最优参数,文献[8]在元学习注意层重新构建检测器的RoI头部,对其产生的特征图进一步处理。文献[9]在重新平衡处理后的数据集上进行特征聚合和元训练,使一个框架同时适用于小样本目标检测和小样本视点估计任务。另一个分支以微调为主导,利用新类数据对现有模型参数进行微调,文献[10]将迁移训练的方法用在Faster R-CNN 上进行小样本目标检测,还引入广义小样本检测作为评价指标。文献[11]在尺度范围上扩增样本数据解决样本数据稀缺的问题。由于微调算法采用基类数据训练模型,冻结一部分参数后在新类数据上微调,因此会产生数据分布偏移和新类数据利用率不足的问题。
最新提出的算法中,文献[12]在所有目标类别中学习通用原型,利用通用原型的软注意来增强目标特征,提高模型的泛化能力。文献[13]通过强化前景区域,再将支持图像和查询图像结合得到带有位置信息的支持向量,增加检测器对于目标的注意力。文献[14]在基础类别与新类别之间构建两个子图,利用图卷积将区域提案特征重构之后与原类型匹配训练。文献[15]针对RoI提取的区域提案构建对比分支,将支持集和查询集数据进行更好的匹配。文献[16]利用对抗的方式干扰新类目标的特征表达,优化特征空间,使基类与新类的边界更加明显。文献[17]以平均分数从记忆增强特征中重新采样,提升头尾类的区分边界,在保持头部类性能的同时提高尾部类性能。可以看出,使用现有样本数据增强特征含有的信息是小样本目标检测算法的主流,但是这种优化没有解决新类样本数据稀缺的问题。文献[18]利用蒸馏技术将支持集和查询集的数据重新匹配,充分利用支持集数据的同时产生更多不同尺度的样本特征。文献[19]构建幻觉网络在RoI空间中生成更多的新类样本。上述算法生成样本数据利用的数据集规模都很小,生成的样本多样性并不丰富。与上述算法相比,所提方法通过限制主干网络接收的信息和附加分类网络校正分类任务让特征更符合小样本检测的需要,同时使用大规模图像分类数据集进行样本扩增,可以有效缓解上述算法存在的问题。
针对上述算法的问题,提出分类校正模块(classification calibration block,CCB),利用强分类网络对RCNN 的分类分数进行校正,缓解定位任务对于分类任务性能的影响。引入样本扩增模块(sample amplification block,SAB),用大规模图像分类数据修正新类样本分布,通过采样完成样本扩增。同时通过梯度限制层(gradient control layer,GCL)对反向传播到主干网络的梯度信息乘以一个常数,限制RPN 和R-CNN 模块传递给主干网络的信息。
所提方法可以有效解决小样本目标检测任务面临新类样本数量不足以及样本多样性不足导致的过拟合问题,在PASCAL VOC 和COCO 两个数据集上均取得了目前最好的效果。
1 问题定义
参照以往研究工作使用的设置方法[9-10,20-21],将常规目标检测数据集拆分为小样本目标检测数据集。目标类分为带有大量标注数据的基类Cbase和每类只有k个标注数据的新类Cnovel,其中Cbase来自基类数据集Dbase,Cnovel来自新类数据集Dnovel,两个类别之间没有交集,即Cbase∩Cnovel=∅。小样本目标检测任务的学习过程分为基类训练阶段和新类微调阶段。前一阶段利用含有大量带标注目标的基类Cbase训练模型,让检测器拥有可以转移到新类上的信息;后一阶段在样本数据稀缺的新类Cnovel上进行微调,让整个检测器更适应新类。输入图像(x,y)∈Dbase∪Dnovel,其中x={ti,i=1,2,…,N}表示有N个目标的图像,ti表示图像中的第i个目标,y={(ci,bi),i=1,2,…,N}表示图像的标注,ci=Cbase∪Cnovel是目标ti的类别,bi表示目标ti的边框位置。依据上述设置,算法最终目的是利用基类数据集Dbase和新类数据集Dnovel在不同的学习阶段优化检测器,然后对查询集Dquery的样本进行检测,查询集Dquery样本的目标都属于类别Cquery,其中Cquery⊆Cbase∪Cnovel。
2 模型架构
2.1 Faster R-CNN
Faster R-CNN[3]是一个经典的两阶段目标检测器,由主干网络、区域提案网络(region proposal network,RPN)和R-CNN[22]三部分组成。主干网络提取预处理图片的特征,RPN利用锚框将特征转换为一组高质量类别无关的区域提案,R-CNN利用RoI池化层[23]将区域提案映射为固定大小的特征,R-CNN 的分类器与回归器分别输出类别分数和边框坐标。三个模块通过最小化损失函数L实现共同优化,如式(1)所示:
在Faster R-CNN 的架构中,RPN 模块主要负责定位任务;R-CNN 模块同时负责定位任务和分类任务。由于分类任务需要转移不变特征,而定位任务需要转移变化特征[24]。最终会彼此影响对方性能。Faster R-CNN利用损失函数L平衡两个互相矛盾的任务,但这样会导致单个任务陷入次优解。
RPN和R-CNN根据损失函数L把对应任务的梯度信息反向传播给主干网络,优化主干网络,并且利用主干网络在两个模块之间传递信息。但是RPN和R-CNN会有前景-背景混淆和错误分类的情况,通过梯度信息会将问题传播到整个检测器。拥有大量带标注的样本数据时,少量错误对整个检测器的性能影响有限。然而对小样本目标检测而言,由于样本稀少,这个问题在微调阶段会严重损害检测器的性能。
2.2 框架
基于上面的描述,提出一种新的小样本目标检测框架,整体架构如图1所示。训练过程分为基类训练和新类微调两个阶段。在评估时引入CCB,利用一个训练好的强分类网络,将区域提案作为输入,通过强分类网络的分类分数校正R-CNN的分类分数。SAB附加在主干网络之后,只在新类微调阶段调用,利用大规模图像分类数据集修正新类的样本数据分布,再从修正后的数据分布中抽取更多的样本加入微调过程,扩增新类数据。在基类训练和新类微调两个阶段中都加入GCL,通过给两个模块的梯度数据乘上不同大小的限制因子,可以不同程度限制梯度信息的传递,从而使主干网络在保存基类信息的同时加快对新类信息的适应速度。

图1 算法的网络框架Fig.1 Network framework of algorithm
基类训练阶段采用Dbase中的数据作为输入,主干网络提取样本特征后送入RPN 和R-CNN 两个模块中,得到分类分数与边框坐标。在新类微调阶段将Dnovel中的数据送到主干网络提取新类样本的特征,然后使用SAB模块对新类样本在特征域扩增,扩增后的数据输入RPN 和R-CNN 模块进行后续预测。R-CNN 分类器输出的分数经过CCB 校正得到最终的检测器分类分数,回归器得到最终的边框坐标。在两个训练阶段反向传播时,梯度信息都经过GCL处理,再传递到主干网络。
2.3 分类校正模块
分类校正模块(CCB)利用分类性能很好的强分类网络对检测器的分类分数进行校正,有效解决了检测器中分类任务受到定位任务影响的问题。通用目标检测器一般将分类器和回归器并行部署在主干网络之后,提升全局特征的利用率。然而,定位任务需要转移变化特征,会驱使主干网络提取的全局特征拥有转移变化特征,这会影响全局特征中的转移不变特性。分类任务需要转移不变特征,因此负责定位任务的回归器会影响分类器的性能。在大量标注样本的情况下,可以利用数据集的全面性缓解这个问题,但在小样本检测中,这个问题会影响检测器的最终结果。模型在新类微调阶段时,样本数量稀缺直接导致模型的分类器性能受到很大影响。本文采用如图2 所示的分类校正模块对结果进行校正,消除分类器产生的高分假阳性(false positive)和低分假阴性(false negative)。

图2 分类校正模块Fig.2 Classification calibration block
模块利用在ImageNet 数据集训练的强分类网络作为CCB 的主干网络,将基类数据集Dbase中的基类图片输入到CCB 主干网络提取特征,根据标注中的真实边框数据与特征相结合得到输入图片中的第i个目标特征xi。将数据集转换为目标原型库,uc表示类别为c的目标特征原型,其计算方式如式(2)所示:
式中,Dc是基类数据集Dbase中所有类别为c的样本子集。
将检测图片Ii输入到微调之后的小样本检测器,得到结果,ci是预测类别,si是预测类别的分数,bi表示预测边框。对输入的检测图片Ii根据预测边框bi生成对应的目标特征xi,利用目标特征xi与目标特征原型uc计算余弦相似度,如式(3)所示:
其中,α是平衡两个分数的超参数。
分类校正模块独立于检测器之外,不共享参数可以确保分类校正模块不受检测器的影响,使其提取的特征有很强的转移不变特征,适用于分类任务。CCB使用官方训练的参数,不需要迁移训练,可以即插即用,很好地适用于提升其他类型的小样本检测器性能。
2.4 样本扩增模块
为解决小样本目标检测中微调阶段样本数据稀缺导致检测器过拟合的问题,提出样本扩增模块(SAB),在特征域对样本数据进行扩增。一般目标检测器的训练过程中,每个类别都有足够多的样本为检测器提供此类别尽可能正确的样本分布。小样本目标检测器由于其任务的特殊性,在新类微调阶段每个新类只有少量样本为检测器提供类别信息。这样检测器学习到的样本分布相对于真实的样本分布有很大的偏差,这些偏差会导致检测器出现严重的错误。在新类微调阶段,主干网络之后加入样本扩增模块,利用图片类别和数量都很多的图像分类数据集在特征域扩增新类。模型的架构如图3所示。

图3 样本扩增模块Fig.3 Sample amplification block
首先将图像分类数据集DImage中的图片输入到在基类数据集Dbase训练过的主干网络,获得整个数据集的类别原型库UImage={u1,u2,…,ui},ui表示数据集DImage中类别为i的类别原型,如式(5)所示:
其中,Ni表示数据集DImage中类别为i的图片数量,xi,j表示类别i中第j个图片经过主干网络得到的特征。得到的类别原型存储到本地,作为离线文件。然后将新类数据集Dnovel的图片Ik输入到主干网络中,得到特征fk。利用余弦相似度计算fk与类别原型ui的相似度,得到图片Ik与数据集DImage中每个类别的相似度mk={mk,1,mk,2,…,mk,i},mk,i代表图片Ik和类别i的相似度,如式(6)所示:
对于mk取Top-d进行归一化得到权重系数wk={wk,1,wk,2,…,wk,i},其中wk,i表示归一化后的图片与DImage中类别i的权重系数,如式(7)所示:
其中,d表示生成新数据集中使用到的类别数量,即Top-d中的d。
利用权重系数对类别原型加权之后可以得到新类数据集Dnovel的修正原型,如式(8)所示:
式中,ui为DImage中第i类的类别原型,wk,i为每个类别原型的权重。
最后,利用类别原型和修正原型构建一个均匀分布,从这个均匀分布中采样构建新的数据集,如式(9)所示:
式中,x*为新生成的样本,y表示新生成样本的类别标签,U表示均匀分布,fk是主干网络提取的新类样本特征,pk是前述通过加权得到的新类修正原型特征,构成均匀分布的两个边界。在生成的分布中采样一定数量的样本作为新的训练样本Dnew,扩增后的数据集D*novel如式(10)所示:
式中,Dnovel表示扩增前的新类数据集,Dnew表示修正分布之后采样生成的数据集。
样本扩增模块主干网络和检测器主干网络都使用ResNet-101,使用经过基类训练的参数。对mini-ImageNet 数据集类别原型库的构建过程位于基类训练之后,独立于小样本目标检测器的训练过程。在新类微调阶段只需要利用本地数据生成新的数据集,不会带来大量的运算成本。通过扩增样本数量解决小样本任务中最根本的数据不足问题可以很好地提高小样本检测器的性能。
2.5 梯度限制层
本节中,针对主干网络中梯度信息获取与真实样本数量不匹配的问题,引入梯度限制层(GCL)限制RPN和R-CNN两个模块在训练阶段反向传播给主干网络的梯度信息。小样本检测器的主干网络不只需要基类信息,还需要新类信息,两种类别信息都是在反向传播中直接传播到主干网络。由于新类的样本数量相比于基类相差很多,所以基类在训练过程中传递给主干网络的信息更加符合类别的真实信息,但是新类也会将梯度完全传递给主干网络,这就让主干网络会受到新类信息的误导,学到与新类真实信息有区别的干扰信息。通过限制梯度传递,可以有效控制不同训练阶段传播给主干网络的信息,让主干网络侧重于利用基类信息提取新类特征。同时,通过对RPN 和R-CNN 两个模块的反向传播过程进行不同程度的限制,可以有效地缓解定位任务与分类任务互相影响的问题。
从梯度反向传播的角度,加入一个新的网络层,称为梯度限制层。正向传播时,按照Faster R-CNN 的设置正常传播,不作任何处理。反向传播时,GCL取后一层的梯度,与限制因子λ∈[0,1]相乘,传递给前面一层,结构如图4所示。

图4 梯度限制层Fig.4 Gradient control layer
其中,η为检测器的学习率,λrpn和λrcnn分别表示RPN和R-CNN的梯度限制因子。式(11)表示主干网络参数θt的更新受到λrpn和λrcnn的影响。当λrpn=0 或λrcnn=0时,表示θt不受θrpn或θrcnn的影响,相当于主干网络只接受RPN 或R-CNN 单个模块的梯度信息;当λrpn或λrcnn∈(0,1) 时,表示θt受到θrpn或θrcnn部分影响,RPN或R-CNN 对于主干网络的更新都提供梯度信息;当λrpn=λrcnn时,代表RPN 和R-CNN 两个模块的梯度信息限制程度相同;当λrpn=λrcnn=1 时,即GCL不起作用,检测器反向传播与Faster R-CNN一样。当λ<0 时对于梯度更新没有意义。另外,限制因子λ对于RPN 和RCNN模块参数θrpn和θrcnn的更新不产生影响。
梯度限制层加入两个超参数,在两个训练阶段使用超参数可以不同程度地限制RPN和R-CNN模块传播给主干网络的梯度信息。限制不同训练阶段的梯度信息可以有效解决检测器在新类别上过拟合的问题。在SAB 扩增样本时,因为k-shot 任务下新类样本的随机性,差异化很大的样本会导致扩增样本与输入样本偏离太多,GCL通过限制梯度信息的传播可以有效纠正这个错误。
3 实验
3.1 实验设置
参照以往的研究工作使用的方法[9-10,21],利用TFA[10]的实验方案将常规目标检测数据集切割为符合小样本标准的数据集,用得到的小样本目标检测数据集对所提方法进行公平的评估比较。
PASCAL VOC 属于常规目标检测数据集,根据TFA的实验方法将其20个类别拆分为15个基础类别和5 个新类别。基类训练阶段使用15 个基础类别的所有样本进行训练,新类微调阶段在新类别所有样本中抽取k个样本进行微调。对于每个新类别抽取k个样本进行新类微调称为小样本k-shot任务,设置k=1,2,3,5,10,按照k-shot 任务分别对模型输入不同数量的k个微调样本。从而将常规目标检测数据集PASCAL VOC转换为符合小样本标准的数据集。其中,用于训练和微调的样本来自VOC-07/12 的训练集。根据TFA 的实验设置抽样出基类和新类的三种划分结果,分别为Novel Set 1,2 和3。在VOC-07 测试集使用新类预测AP50 进行评估。
对于COCO 数据集,根据TFA 实验设置将其80 个类别划分为基础类别和新类别,与VOC 数据集不相交的60 个类别设置为基础类别,剩余20 个类别设置为新类别。同VOC 数据集一样,使用60 个基础类别的所有样本参与基类训练,对于新类别按照k=1,2,3,5,10,30,设置小样本k-shot 任务,按照k-shot 任务在每个新类别中抽取k个样本作为参与微调的样本。依据上述方法将大规模目标检测数据集COCO 转换为符合小样本标准的数据集。使用验证集里的5 000 张图片遵循mAP进行评估。此外所有的结果都是十次重复运行的平均值。
本文以Faster R-CNN[3]作为基本检测框架,使用在ImageNet上预训练的ResNet-101作为检测器主干网络,采用同样在ImageNet上训练过的ConvNeXt-XL作为分类校正模块主干网络,使用大规模图像分类数据集mini-ImageNet 生成SAB 的类别原型库。采用SGD 对检测器进行端到端的优化,小批量尺寸为4,动量因子为0.9,权重衰减因子为0.000 05。学习率在基础训练时设置为0.02,在新类微调时设置为0.01。CCB中的平衡系数α设置为0.6。SAB每个类别生成的新样本数量为50。在基类训练阶段,GCL 中的λrpn与λrcnn分别设置为0.25 和0.75;新类微调阶段,将λrpn与λrcnn设置为0和0.1。
3.2 比较结果
在表1 中展示了VOC 数据集上三种不同分割方式的评估结果。可以看出所提方法在FSOD评估标准下,整体性能优于其他模型,证明所提算法的有效性。对于FSOD评估,在k-shot任务中,k值越小,其提升的性能越大,当k=1 和2 时,与其他算法相比,均取得了最好的检测效果,在Novel Set 2 的2-shot 任务中相比次优的DeFRCN算法有5.1个百分点的提升。而对于k值较大的5-shot 和10-shot,与DeFRCN 的结果相差不大,不同分组的结果互有胜负,如Novel Set 1 中5-shot结果略差于DeFRCN,但10-shot 的检测效果要好于DeFRCN。
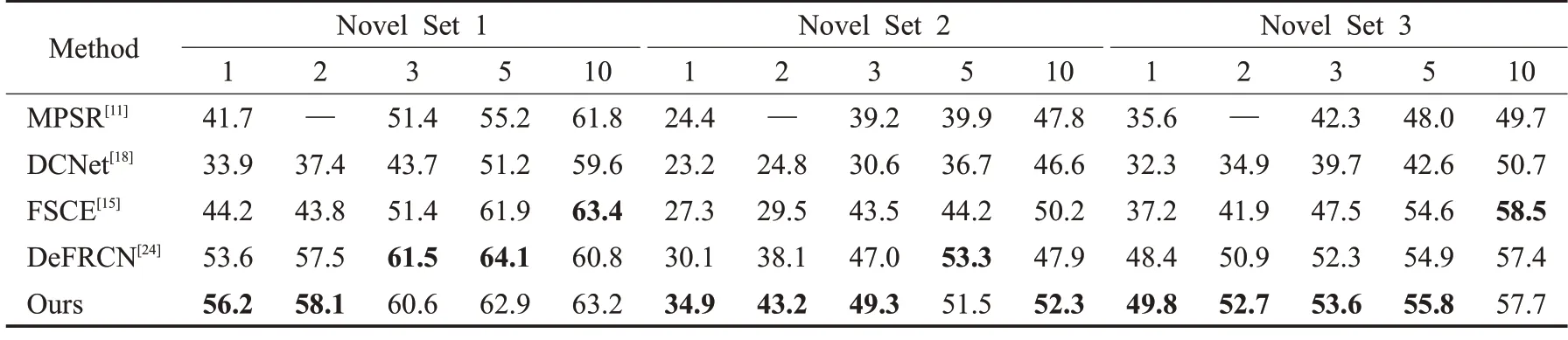
表1 不同算法在PASCAL VOC数据集下的结果对比Table 1 Comparison of different algorithms under PASCAL VOC dataset 单位:%
表2 展示了在COCO 数据集上采用mAP 评估得到的结果。在k=1 和2时,本文方法达到了最好的结果,对于次优算法DeFRCN 有1.9 和0.9 个百分点的显著提升,同时针对k=5 和10,结果也好于次优算法DeFRCN。证明所提方法在不同的数据集下都有很好的效果,在小样本检测任务下拥有很好的鲁棒性和泛化能力。
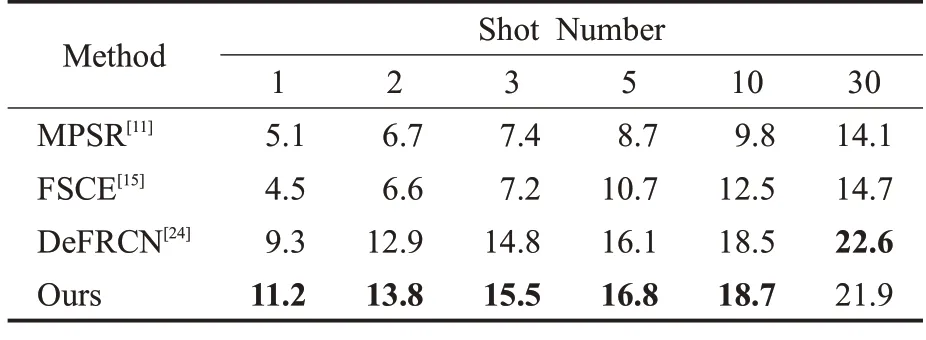
表2 不同算法在COCO数据集下的结果对比Table 2 Comparison of different algorithms under COCO dataset 单位:%
3.3 消融实验
使用不同分类模型作为CCB模块主干网络的实验结果如表3 所示。由表3 可以看出ConvNeXt-XL 作为分类器时,检测器的效果最好。主干网络采用分类性能最弱的ResNet-18 得到的最终效果也最差。表明CCB主干网络的分类能力越强,对于整个检测器分类能力的校正效果就越强。

表3 CCB不同主干网络的结果对比Table 3 Comparison of classification calibration block different backbone network results 单位:%
针对不同模块的消融实验,结果如表4 所示。第1行是基础Faster R-CNN 的检测结果,可以看到在样本稀缺的情况下,Faster R-CNN存在严重的过拟合现象,检测效果很差。第1~7行和8~14行数据显示,在基类训练阶段(base-training)使用GCL 的检测结果,基类提升2.5个百分点,新类也有提高(1.4~2.1个百分点),说明限制检测器对于基类信息的接收可以产生更适合于小样本检测的基类模型。第4行和第11行的结果说明,在新类微调阶段(novel-fine-tuing)加入GCL,对于小样本检测性能有很大的提升(3.9~16.9个百分点),GCL使用限制因子限制了检测器对于新类信息的接收,让检测器以基类信息为主导,避免过拟合风险。第2 行和第9 行展示了在评估阶段引入CCB 对性能的影响,有3.3~4.3 个百分点的性能提升。第3 行和第10 行表示在新类微调阶段加入SAB的性能提升效果(3.4~15.5个百分点),其对于k-shot任务k值越小提升效果越大,说明其很好地缓解了新类样本数据稀缺的问题。当k值较大时,提升性能较少,说明检测器不只需要大量的图片,更需要高质量的图片。第10行与第12行对比说明新类微调阶段加入GCL 对于SAB 的结果会有优化,原因是新类扩增采用差异化很大的样本数据,如果样本数据与真实分布相差很大,最终扩增的数据也有很大的误差,而GCL可以通过限制信息传递到整个检测器,缓解SAB 的缺点。第14 行显示了所有模块都加入的结果,与第一行相比提升显著(6.8~21.3个百分点)。

表4 不同模块的消融实验Table 4 Ablation experiments of different modules 单位:%
在CCB和SAB中使用不同的度量方式对于性能的影响结果如表5所示。通过表5可以看出使用余弦相似度作为度量特征之间的距离可以取得很好的结果。在CCB中使用其他度量方式,诸如欧氏距离和协方差距离对于检测器最终的结果有很大的影响,而在SAB 中使用这几种度量方式却没有如此大的差距。分析原因在于CCB利用度量方式得到的结果直接影响检测器的最终输出分类分数,而SAB 使用度量方式计算新类修正原型特征pk的权重系数来间接影响检测器的性能。
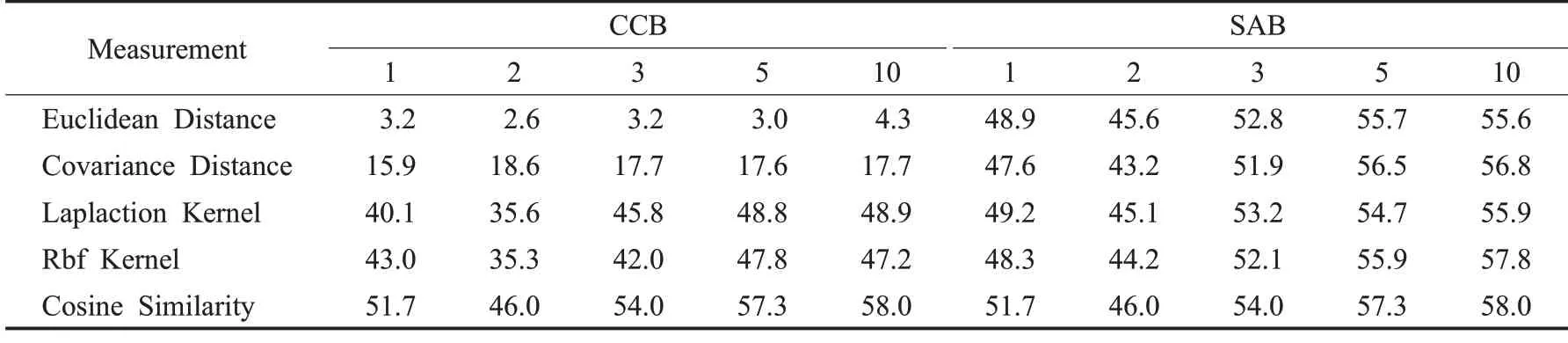
表5 CCB和SAB不同度量方式的结果比较Table 5 Comparison of classification calibration block and sample amplification block with different measurement results 单位:%
3.4 超参数选择
SAB 在扩增样本数据时,需要利用mini-ImageNet数据集中的Top-d个类别修正新类特征分布,d的不同取值对于性能结果的影响如图5 所示。可以看出取Top-300时,检测器的性能最好,取Top-100效果最差,原因在于新类的样本数据很少,使用过少的类别修正很可能因为某些非关键特征很相似其他类别,导致特征分布修正时出错。同时,实验结果表明,使用过多的类别修正分布对于性能没有很好的提升。

图5 SAB修正分布Top-dFig.5 Sample amplification block modified distribution Top-d
SAB通过在修正后的新类分布中采样N个样本作为扩增样本,采样数量N的不同对于检测器的性能影响如图6 所示。可以看出当N取50 时,检测器的性能最优。且在1/2/3-shot 时,随着N值的增大,检测器性能提升非常大,但是在5/10-shot 时,其优化提升很小。原因在于对于5/10-shot任务而言,检测器可以从未扩增数据集中获得很好的类别分布信息,因此扩增后的数据集对于检测器性能的提升效果不显著。

图6 SAB样本扩增数量NFig.6 Number of sample amplification block samples amplified N
GCL 在反向传播阶段用两个限制因子λrpn和λrcnn控制主干网络接收的信息,不同取值的λrpn和λrcnn在不同训练阶段对检测器的性能影响如表6所示。第1~5行显示新类微调阶段的两个限制因子和基类训练阶段的限制因子λrcnn固定不变,只改变基类训练阶段限制因子λrpn,当λrpn=0.25 时,检测器的检测效果最好。同理确保其他三个限制因子不变,只改变一个限制因子,第6~10行只修改基类训练阶段的限制因子λrcnn,第11~15行改变新类微调阶段的限制因子λrpn,第16~20 行改变新类微调阶段的限制因子λrcnn。通过实验结果得知,基类训练阶段限制因子设置为λrpn=0.25 和λrcnn=0.75,新类微调阶段限制因子设置为λrpn=0 和λrcnn=0.1 达到最好。另外第6~10行证明检测器不需要微调阶段的RPN提供的定位信息,即新类别所需的定位信息主要由基础类别提供。
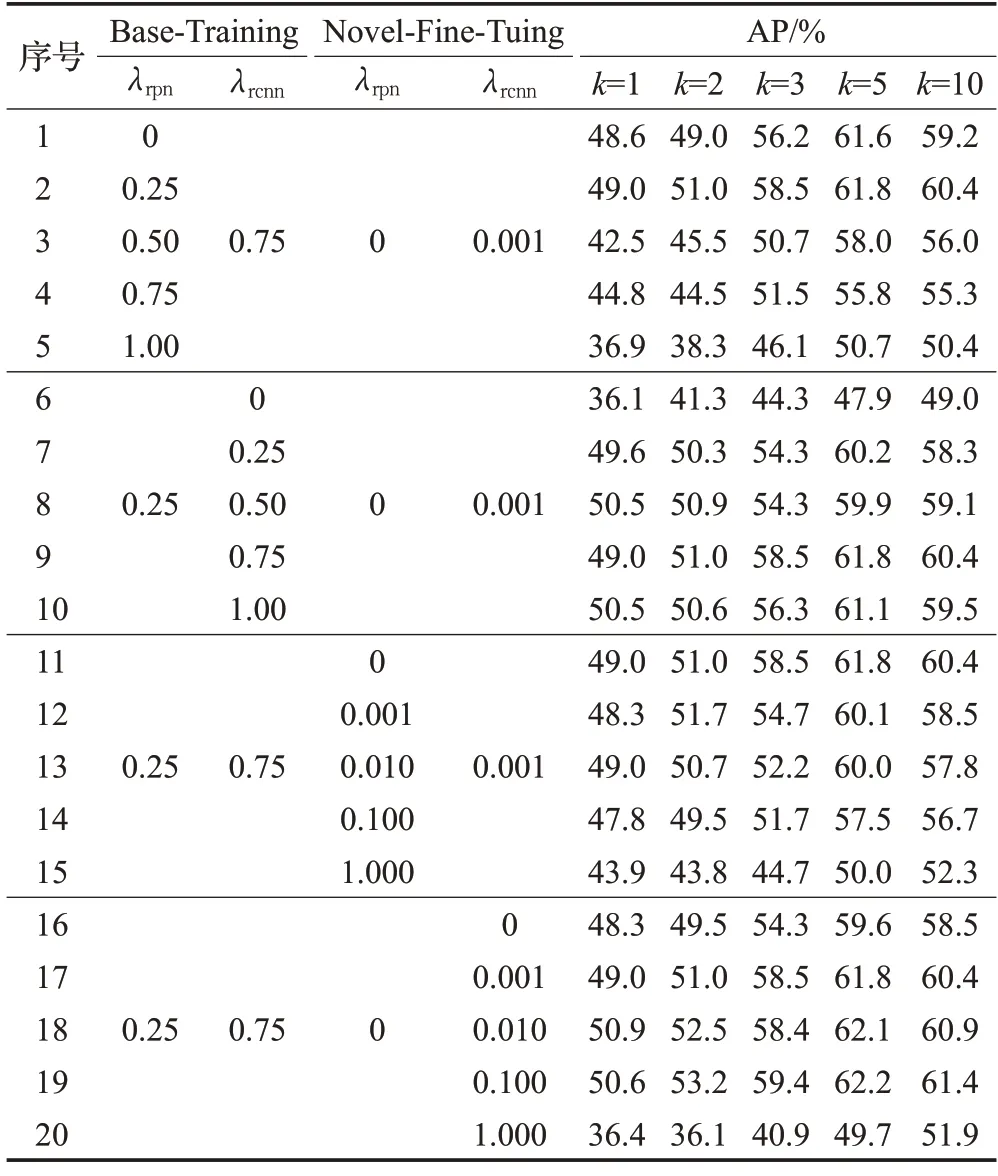
表6 GCL不同训练阶段限制因子λrpn 与λrcnnTable 6 Limiting factors of gradient control layer in different training stages λrpn and λrcnn
校正分类过程中,CCB使用平衡系数α∈[0,1]平衡强分类网络和检测器网络的检测结果,α的不同对检测器性能的影响如图7 所示,α取0.6 最为合适。由于检测器同时负责分类和定位两个任务,分类性能不可避免地受到影响,但是CCB中的强分类器不受影响,因此在最终的校正过程中强分类器的权重略大于检测器的权重。

图7 CCB平衡系数αFig.7 Classification calibration block equilibrium coefficient α
4 结束语
本文提出一种新的小样本目标检测算法,用于解决小样本目标检测扩增样本时存在的数据分布偏移问题,以及分类任务性能容易受定位任务影响的问题。现有算法对主干网络提取的特征进行融合、映射等操作以加强特征携带的信息量,所提方法通过控制主干网络接收类别信息的程度和使用强分类网络校正分类分数的方式使主干网络提取的特征更适合小样本目标检测任务;现有算法使用目标检测数据集或生成网络得到训练数据的扩增样本,所提方法使用大规模分类数据集扩增新类样本可以有效提升检测器性能。在PASCAL VOC和COCO 数据集上的实验结果表明,相比于现有的方法,所提方法实现了最佳的小样本目标检测性能,验证了算法的有效性。在未来的研究中,可以将超参数作为可学习参数,以学习到适应检测器最优值的参数配置,进一步提高小样本目标检测器的性能。
