基于迁移学习的高速公路交织区车辆轨迹预测
2024-01-17殷子健徐良杰刘伟马宇康林海
殷子健, 徐良杰, 刘伟, 马宇康, 林海
1)武汉理工大学交通与物流工程学院,湖北武汉 430063;2)武汉大学国家网络安全学院,湖北武汉 430072
交织区具有道路几何形状复杂、车流密度高及事故风险高的特点,是高速公路上交通流运行最复杂的区域之一.自动驾驶车辆通过感知周围车辆状态,预测其行驶轨迹以提高驾驶行为决策、路径规划与运动控制的准确性,确保交通安全.高速公路交织区轨迹预测的准确性对于提升道路安全、优化交通流量与自动驾驶性能至关重要.
轨迹预测旨在根据交通参与者在给定场景中的过去状态估计其未来状态.传统的轨迹预测模型包括基于物理的方法,如单轨迹法[1]、卡尔曼滤波法[2]及蒙特卡洛法[3]等,其局限性在于仅能进行不超过1 s 的短时预测,且没有考虑到相互作用等相关因素,导致预测准确率不高.另一类基于机器学习的轨迹预测方法包括支持向量机[4]、隐马尔可夫模型[5]和动态贝叶斯网络[6]等.这类模型通过挖掘数据特征来确定概率分布,其局限性在于对策略制定依赖强,以及泛化能力弱.因此,上述方法在轨迹预测中尚无法取得理想的预测性能.
基于深度学习的轨迹预测方法可以考虑物理、道路及交互相关因素,对复杂场景的适应度更高.ALAHI 等[7]首次提出利用长短时记忆(long shortterm memory, LSTM)神经网络模型学习行人一般运动,并预测其未来轨迹.受行人轨迹预测的启发,DEO 等[8]使用LSTM 编码器提取周围车辆的时间信息,并将其传入社交池化层,提出经典的卷积社交池化轨迹预测方法.随后众多学者运用社交池化层,通过改变神经网络结构或增加多模态输入数据,获得了更优秀的轨迹预测模型.GUPTA等[9]基于改进的社交池化对抗生成网络模型,提出避撞概念并提升了模型准确性.SONG 等[10]提出一种规划知情轨迹预测(planning-informed trajectory prediction, PiP)方法,将车辆轨迹规划和预测轨迹耦合,在车辆交互场景获得更优的预测效果.李立等[11]在原始社交池化模型基础上引入速度差,提高了预测精度.CHEN 等[12]提出一种新型时空动态注意网络,能够综合捕捉时间和社会交互特征,并降低误差.CHEN等[13]提出一种基于多损失函数的混合条件自动编码器生成对抗网络(convolutional autoencoder - generative adversarial network,CAE-GAN)模型,提升了预测精度.韩皓等[14]在交织区车辆轨迹预测中加入注意力机制,并引入碰撞时间和避免碰撞减速度用于预测交织区换道车辆轨迹.
尽管上述改进模型已能够取得较优性能,但随着模型的不断改进,模型复杂程度和计算量均显著增大,为智能车实时决策的计算能力带来挑战.针对交织区复杂场景,迁移学习能够快速准确预测车辆未来轨迹,大幅提高预测计算效率.因此,本研究采用经典的社交卷积池化神经网络模型验证迁移学习[15]在高速公路交织区轨迹预测中的有效性.
1 交织区交通流运行状态分析
高速公路交织区通常包括入口匝道、出口匝道、主线车道和集散车道等,车辆在此区域需要进行换道、合流、分流、加速及减速等复杂操作,以确保顺利进入或离开高速公路,如图1.其中,车道7 为进口匝道,车道8 为出口匝道.由于交织区内车流的复杂性和不确定性,分析其交通流运行状态具有重要意义.NGSIM(next generation simulation)数据集[16]是一组高度详细的交通微观数据,用于研究交通流特征和建立交通模型.本研究采用高速公路直线路段I-80 和高速公路交织区US-101 详细车辆轨迹数据集对模型进行迁移训练与验证.
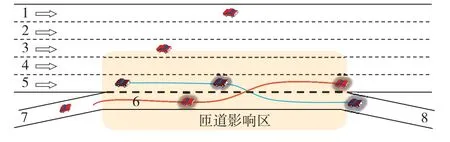
图1 交织区US-101车道示意Fig.1 Schematic diagram of weaving area US-101 lane.
1.1 交通流量及速度分析
交织区内各车道的交通流量是评估交通流运行状态的关键指标.通过统计不同时间段内的交通流量,可以获取交织区的拥堵情况、交通需求变化等信息.车辆在交织区内的速度分布与行驶安全和通行效率密切相关.由于NGSIM 数据集在采集过程中受到传感器误差与环境干扰等因素影响存在噪音,为提高数据质量,采用Savitzky-Golay滤波法对速度与坐标等关键信息进行平滑处理.基于高速公路交织区US-101 路段的45 min 数据,以5 min 为1 个时间窗口描述空间平均速度和流量关系,如图2.依据最大流量Qm和临界速度Vm将交通流状况分为拥挤或不拥挤,所研究路段从08∶00开始处于拥挤状态.

图2 空间平均速度与流率关系Fig.2 Relationship of space-mean speed and flow.
1.2 交织区车辆轨迹稳定性分析
在匝道与主线交汇的合流区和分流区,车辆需要完成合流与分流行为,这将对主线上直行的车辆产生干扰.由于合流区和分流区的交通特征复杂,因此,重点关注这些区域的车辆轨迹.由滤波处理过的车辆轨迹数据得到图3.可见,匝道影响区包括车道4~8.交织区影响区的纵坐标范围为180~400 m.在进入交织区前,车道4和车道5的车辆速度较低.在影响区的中间路段,车辆有明显减速行为,车道5受交织合流影响更为显著,车辆会加速离开交织区影响区.从车道6、7和8的时空轨迹速度图中可见,其整体速度相对于直线行驶路段更低;进入匝道的车辆在进入集散车道6后,会有更急剧的减速行为.部分车辆选择在进入集散车道6后立即换道至车道5,从而导致车道6 中的轨迹出现中断,这种行为对交织区影响区内的车辆轨迹决策造成显著影响,从而破坏了车辆轨迹稳定性.

图3 (a)车道4、 (b)车道5及(c)车道6 ~ 8的时空轨迹速度分布Fig.3 Spatio-temporal trajectory speed map for (a) lane 4, (b)lane 5, and (c) lanes 6-8 .
2 轨迹数据预处理及特征提取
2.1 轨迹数据预处理
以目标车辆为原点,行驶方向为纵向,垂直行驶方向为横向,建立平面直角坐标系,如图4中编码器部分.研究时间范围为8 s,车辆轨迹采样率为10 Hz,每帧时间为0.1 s,将车辆的前3 s 和后5 s作为纵向轨迹研究范围,前4 s和后4 s作为横向轨迹研究范围.对于纵向轨迹行为,若目标车辆在研究时间范围内减速至原车速的80%以下,则视为直行制动;否则为保持直行.横向轨迹行为包括保持车道、向左换道及向右换道.进一步将纵向行为和横向行为编码为独热张量(one-hot vector).在研究空间范围上,考虑预测车辆在纵向±27.432 m 和两个相邻车道内的所有车辆.为此,建立3 × 13的单元网格,用于描述同帧时刻研究空间范围内的所有车辆位置.在考虑邻车空间位置时,将空间划分为3 × 39的网格单元,左侧车道的车辆信息对应前13 列,当前车道的车辆信息对应中间13 列,右侧车道的车辆信息对应后13 列.每个单元格使用车辆标号进行存储,包含每个数据样本的编号,车辆身份标识(identity document, ID)及其所有帧的轨迹信息,通过这种划分方式,可以描述各车道中的车辆分布和相互关系.由于模型使用3 s 的轨迹历史进行预测,因此,每个轨迹的最初3 s 不用于训练或测试,以确保模型的准确性.将数据按照7∶1∶2划分为训练集、验证集及测试集.其中,验证集用于检验过拟合和调整超参数;测试集用于评估性能和绘制预测轨迹图.

图4 卷积社交池化LSTM轨迹预测模型Fig.4 Convolutional social pooling LSTM trajectory prediction model.
2.2 轨迹关键特征提取
对智能驾驶系统而言,周围驾驶环境中存在许多无法直接获取的信息,如其他车辆驾驶员的意图及车辆的运动特性等.为能做出有效决策,智能驾驶系统需要利用可观察变量(如位置、所在车道及邻车信息等),提取车辆运动信息时间序列,来对这些难以获取的信息进行概率推断.
目标车辆及其附近车辆在特定历史时段中的运动轨迹序列H为
其中,t为当前时刻;Th为t时刻之前的历史时段长度;hp为t时刻之前的p时刻群体中所有车辆的位置;(xi,p,yi,p)为p时刻车辆i的位置;N为群体中车辆总数.
p时刻目标车辆的位置h0,p为
目标车辆在预测长度Tf内的轨迹序列F定义为
通过监督学习得到目标车辆在未来一段时间内所有时刻的位置概率分布P( )F|H为
其中,mk为目标车辆将来采取的第k个行为类型;u为行为类型的总数;Pθ(F|mk,H)是在已知行为类型mk和已知历史信息H的条件下,目标车辆未来出现轨迹序列的概率;P(mk|H)是已知历史信息H下选择行为类型mk的概率;θ为目标车辆在未来Tf时间段内所有时刻的位置参数;θq是q时刻目标车辆的位置参数;μx,q和μy,q分别表示q时刻车辆在横向和纵向位置的期望;σx,q和σy,q是q时刻车辆在横向和纵向位置的标准差;ρq是车辆横向和纵向位置之间的相关系数.
3 轨迹预测模型建立及迁移学习
3.1 神经网络模型的搭建
图4 为卷积社交池化LSTM 轨迹预测模型,由编码器、社交卷积池化模块及解码器组成.模型采用LSTM的序列到序列(seq2seq)网络,用于预测道路上其他车辆的轨迹.为了学习道路上车辆的动态和相互作用,使用两种不同的编码策略,分别为车辆动态编码和卷积社交池化编码.网络还能选择性地对车辆的横向和纵向运动模式进行分类,以便预测基于不同运动模式的车辆轨迹.表1为预测模型的主要网络结构.

表1 神经网络模型的主要网络结构Table 1 Main network structure of neural network model
在模型前向传播过程中,首先将输入的历史轨迹和周围车辆信息分别通过输入嵌入层和编码器LSTM 进行编码;利用卷积社交池化层处理周围车辆的编码,以捕捉车辆间的相互作用;将车辆动态嵌入和社交嵌入连接在一起,并将组合后的编码传递给解码器LSTM;根据解码器LSTM 的输出预测未来轨迹,并对横向和纵向行为模式进行分类.
3.2 训练及预测指标选取
均方根误差(root mean squared error,RMSE)衡量预测值与实际值之间的偏差,用以评估预测结果的准确性.RMSE计算为
其中,Rq为q时刻的RMSE;xj,q和yj,q分别表示第j辆目标车辆在q时刻的横向和纵向实际位置;xˉj,q和yˉj,q分别表示第j辆目标车辆在q时刻横向和纵向的预测位置;n为所分析目标车辆的总数.
在车辆轨迹预测中,RMSE 是衡量模型性能的重要指标.在训练阶段,RMSE 损失用于调整模型参数,目标是缩小预测轨迹和实际轨迹之间的差距;在测试阶段,RMSE 则被用来评估模型对未见过数据的预测能力.RMSE 较低意味着模型能准确预测车辆的未来行驶路径,具有优良的泛化性能.
负对数似然(negative log-likelihood, NLL)是一种常用的损失函数,用于衡量模型预测概率分布与真实概率分布之间的差异,NLL计算为
其中,Lq为q时刻的NLL 值;mture为模型预测出现概率最高的动作类型.
在训练过程中,通过最小化预测概率分布与真实概率分布之间的负对数似然来优化模型参数,使模型预测结果更接近实际行驶轨迹的概率分布.在测试过程中,NLL可以作为评估指标,用于衡量模型在测试数据上的性能.
双变量高斯分布是高斯分布在二维空间的推广,可以表示两个随机变量之间的关联.双变量高斯分布的概率密度函数由均值向量和协方差矩阵决定,计算为
其中,x和y为随机变量;μx和μy是x和y的均值;σx和σy是x和y的标准差;ρ是x和y之间的相关系数,-1 ≤ρ≤1.Z计算为
在目标车辆行为预测中,采用双变量高斯分布概率密度函数估计不同行为组合的概率.关注2种横向行为和3 种纵向行为,即6 种不同行为组合,如图5.通过目标车辆的历史轨迹数据拟合双变量高斯分布,获取其均值向量和协方差矩阵,从而捕捉横向和纵向行为之间的相关性.利用拟合得到的双变量高斯分布计算概率密度函数,用于估计未来轨迹上各个行为组合的概率.双变量高斯分布概率密度函数提供了一种直观且易于计算的方法,以量化不同行为组合的可能性.

图5 横向与纵向行为组合Fig.5 Lateral and longitudinal maneuver combinations.
对所有可能的行为组合进行概率评估,并选取具有最大概率的组合作为预测点.能够在横向和纵向行为之间找到最有可能发生的行为组合,从而更准确预测未来轨迹.预测轨迹包含多个潜在的轨迹,每个轨迹预测对应1 个纵向和横向的行驶状态.根据横向和纵向行为的预测概率选择最可能的行为,最终从这6个行为类别的预测结果中选择最大概率的轨迹作为最终预测结果.
3.3 模型训练及迁移学习
本研究使用NGSIM 数据集中的I-80 和US-101轨迹数据进行迁移训练和轨迹预测.硬件配置包括i5-12400 CPU 和RTX 3060 GPU,利用基于Python语言的PyTorch框架构建神经网络模型.采用Adam(adaptive moment estimation)梯度下降优化算法,设置学习率为0.001,样本批量为128.训练过程选用RMSE和NLL作为损失函数,迁移学习过程采用NLL 作为损失函数.本研究设计了4组实验以验证所提出方法的有效性和可行性,包括直线路段的训练与测试、交织区路段的训练与测试、交织区的迁移学习与测试,以及改进交织区模型的迁移学习与测试.
预训练可以改进性能、加速收敛、防止过拟合,为新任务提供较优的初始参数设置.在高速公路直线路段I-80 车辆轨迹预测项目中,采用RMSE作为深度学习的预训练指标,用以衡量模型预测轨迹与实际轨迹之间的差距,为模型提供一个较好的初始状态.在正式训练阶段,使用NLL作为深度学习训练的指标,以衡量模型预测概率分布与真实概率分布之间的差异,可以进一步提升模型在预测概率分布方面的性能.
图6 为模型损失变化.可见,每100 次训练为1 个训练周期,共有8 个训练轮次,模型在I-80 高速公路直线路段有较好的训练参数.训练损失是在训练集上计算的损失,用于衡量模型在训练数据上的拟合程度.模型在正确学习过程中不断调整参数使训练损失不断减小.验证损失是在验证集上计算的损失,验证损失用于评估模型在未见过数据上的性能.在训练过程中,验证损失不断减小证明模型没有发生过拟合.

图6 直线路段训练损失及验证损失 (a)平均训练损失随训练周期变化; (b)平均验证损失随训练轮次变化Fig.6 Training and validation loss for straight-line segment.(a) Average training loss over training epochs and (b) average validation loss over training iterations.
迁移学习是一种高效的深度学习方法,适用于新的、与原任务相似但难度更高且更复杂的目标任务上.本研究预训练的模型参数(权值和偏置)从I-80 高速公路的直线路段迁移至复杂度更高的US-101高速公路交织区任务中,这种策略称为预训练策略.此外,模型在新任务上还进行了微调,以适应US-101 高速公路交织区的特性,这种策略称为微调策略.通过使用NLL指标引导微调过程,提升计算速度与效率.迁移学习提升了模型的泛化能力,使其在US-101 交织区车辆轨迹预测任务中表现优异.
将US-101高速公路交织区3个时间段共45 min的轨迹数据用于迁移学习,其中,将入口匝道、出口匝道和集散车道视为同一车道.表2为直接训练和迁移学习的指标对比.可见,在US-101 交织区数据上训练同样的神经网络模型,使用迁移学习能减少61.1%的训练时间.同时,迁移学习模型在预测横向和纵向行为的准确率上均有提升,其训练损失和验证损失也低于直接训练.随着训练次数的增加,损失逐渐减小并趋于稳定,验证损失降低了5%,预测准确率提高了0.3%,表明迁移学习能在节省计算资源的同时,提升模型的准确率和泛化能力.
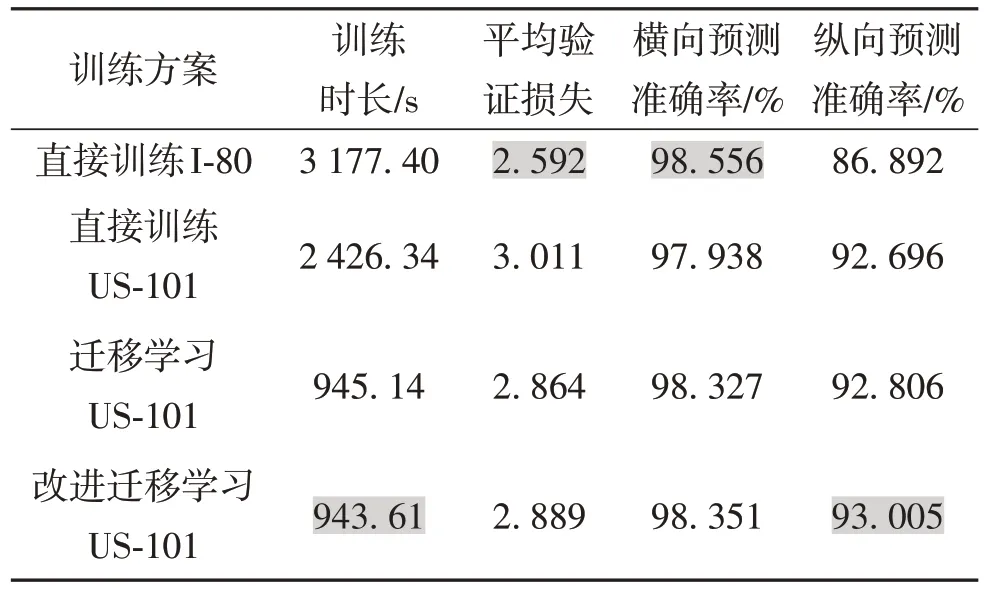
表2 直接训练和迁移学习指标对比Table 2 Comparison of direct training and transfer learning metrics
然而,在将模型从直线路段迁移到交织区路段时,未考虑入口匝道和出口匝道在跟驰换道时与直线路段的交互问题.因此,在数据处理阶段,本研究将入口匝道7 和出口匝道8 视为独立车道,提出了改进后的迁移预测模型.此模型能够正确提取交织区匝道的几何形状,其迁移训练结果如图7.可见,训练时长、平均验证损失以及预测准确率等性能指标均得到进一步提升.

图7 平均训练损失随训练周期变化Fig.7 Average training loss varies with the training period.
4 模型评估及轨迹滚动预测
根据上述4种实验方案,引入测试集来计算未来5 s 轨迹预测位置,利用RMSE 和NLL 指标评估预测偏差,结果见图8.可见,由于交织区路段相较直线路段交通流运行状态更复杂,4 s 后交织区路段直接训练方案相较于直线路段直接训练方案的预测误差更大,但短时间内基于迁移学习的交织区轨迹预测误差更小.基于迁移学习训练的交织区坐标预测误差显著降低,车辆行为预测准确率得到提升.表明迁移学习训练不仅能大幅缩短训练时间,还能提高模型预测准确率与泛化能力.

图8 采用(a)RMSE指标与(b)NLL指标对于未来5 s的轨迹预测结果对比. 插图为局部放大细节Fig.8 Comparison of future 5 s trajectory prediction results using (a) RMSE metric and (b) NLL metric across different training schemes. The figure includes a zoomed-in detail. Blue line with circle represents direct line segment I80, orange line with square represents direct training US101, green line with spindle shape represents transfer learning US101, and red line with triangle represents improved transfer learning US101.
采用图9 的滚动预测法(rolling prediction)实时更新车辆轨迹预测,以应对动态变化的交通场景,并提供较为准确的预测结果.模型根据前3 s 的历史轨迹、邻车位置信息、掩码信息、横向及纵向行为数据,预测未来5 s 内的车辆轨迹.模型选取前0.1 s 轨迹位置的最大概率点作为预测轨迹开始,以0.1 s为步长,逐步进行滚动预测.0.1 s对应于NGSIM 的数据采样率,确保预测和实际情况同步.通过这种方式,模型能够逐步绘制出车辆在一段时间内的预测轨迹,从而实现实时预测.

图9 滚动预测的原理及方法Fig.9 Principle and method of rolling prediction.
以历史轨迹最后一帧的坐标为原点,将纵向相对位置设为横坐标,横向相对位置设为纵坐标,构建车辆轨迹坐标图,可以直观对比车辆在一段时间内预测轨迹与真实轨迹之间的拟合程度.图10 为交织区换道的两条不同车辆的真实轨迹与预测轨迹,使用LSTM 神经网络迁移学习预测模型与滚动预测法,交织区换道车辆的轨迹预测值与真实值的RMSE 为2.04 cm,表明迁移学习结合滚动预测法在高速公路交织区的预测可靠性,进一步证实在复杂交织区场景下,迁移学习能够在大幅减少计算时间,并精准预测车辆轨迹.

图10 (a)交织区汇入车辆与(b)汇出车辆的真实轨迹与预测轨迹对比Fig.10 Comparison of real and predicted trajectories for (a) vehicles on-ramp and (b) off-ramp the weaving area. The blue line with circle and the red line with triangle are for the real trace and predicted trace, respectively.
5 结 论
本研究所取得的结论如下:
1)相较于直接使用交织区车辆轨迹数据进行训练,迁移学习在计算效率、稳定性等多方面展现出显著优势.首先,迁移学习能够减少61.10%的训练时间,降低计算机运算负担;其次,迁移学习有助于增强模型的泛化能力,使其在不同场景中具有更好的适应性和鲁棒性.迁移学习能够在有效降低计算成本的同时,进行更精准的轨迹预测,横向和纵向行为预测准确率可提升至98.35% 和93.00%.在未来复杂交织区场景中,采用迁移学习的方法可以显著提高智能车的决策效率.
2)滚动预测法能够实现精准的车辆轨迹预测,但由于其预测滚动步长较小,计算量随之显著增加.在实时算力有限的情况下,迁移学习能够有效降低计算成本,结合滚动预测法可以实现快速高效且精准的轨迹预测,其每个滚动步长的RMSE 为2.04 cm.迁移学习轨迹预测可为智能车在复杂交织区场景中的行为决策提供可靠依据,有助于提高智能车在复杂交织区场景中的轨迹预测效率,值得在类似场景中广泛应用.
