基于自高斯与通道注意力的重塑卷积高光谱图像分类算法
2024-01-16谭云飞李明罗勇航文贵豪石超山


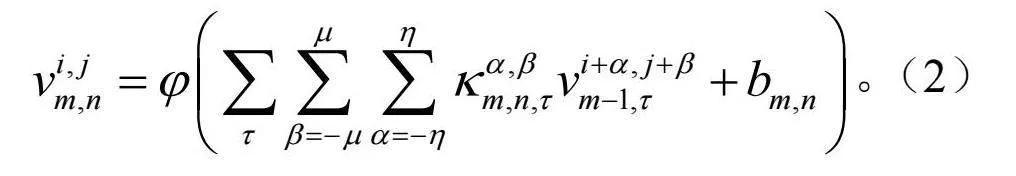






摘 "要:针对传统卷积受限固有的网络结构,缺乏建立远程依赖关系的能力和分类精度较差等问题,提出一种基于自高斯与通道注意力的重塑卷积高光谱图像分类算法(RC-LSGA)模型。RC-LSGA模型首先采用卷积层提取浅层空间信息的特征,再使用通道注意力机制增强光谱特征,然后通过LSGA Transformer模块和重塑卷积分支对全局-局部特征信息进行提取,最后将获得的特征输入分类器实现分类。RC-LSGA模型能够有效区分不同波段信息,对PU、SA和LK数据集中类别识别的平均准确率分别达到98.20%、99.33%和99.46%。实验结果表明,在训练样本数量有限的情况下,RC-LSGA模型性能优异,在分类任务中实用价值较高。
关键词:高光谱图像分类;通道注意力;LSGA"Transformer模块;重塑卷积
中图分类号:TP391 """"""""""""""""文献标志码:A """""""""""""文章编号:1008-0562(2024)06-0742-10
Hyperspectral image classification method based on"reshaped convolutional channel attention with light self-Gaussian attention
TAN Yunfei, LI Ming*, LUO Yonghang,"WEN Guihao,"SHI Chaoshan
(College of Computer and Information Science, Chongqing Normal University, Chongqing"401331, China)
Abstract:"Aiming at the problems of traditional convolution limited inherent network structure, lack of ability to establish remote dependencies and poor classification accuracy, a reshaped convolution hyperspectral image classification algorithm "model based on self-Gaussian and channel attention"(RC-LSGA) is proposed. The RC-LSGA model first uses the convolutional layer to extract the features of shallow spatial information, and then uses the channel attention mechanism to enhance the spectral features. Then, the global-local feature information is extracted by the LSGA Transformer module and the reshaping convolution branch. Finally, the obtained features are input into the classifier to achieve classification. The RC-LSGA model can effectively distinguish different band information, and the average accuracy of category recognition in PU, SA"and LK datasets is 98.20%, 99.33% and 99.46% respectively. The experimental results show that the RC-LSGA model has excellent performance and high practical value in classification tasks when the number of training samples is limited.
Key"words:"hyperspectral image classification; channel attention; LSGA"Transformer"module; reshaped convolutional
0""引言
高光谱图像(hyperspectral image,HSI)含有大量有价值的空间信息和光谱信息,因此在遥感测量[1]、农业检测[2]、城市安全监控[3]、军事国防[4]等领域得到广泛应用。为充分挖掘HSI数据在图像去噪[5]、光谱解混[6]、异常检测[7]、地物分类[8]等方面的潜力,学者们采用不同方法捕获数据特征。HSI数据规模庞大、维度高且信息冗余,增加了图像解析的难度,因此如何准确提取和有效利用空间光谱信息来进行分类是当前研究的一个主要挑战[9-10]。
早期的HSI分类方法有支持向量机(SVM)[11]、基于协作表示的分类器(CRC)[12]和主成分分析(PCA)[13]等。这些方法在分类性能中表现良好,但在处理高维度非线性特征方面存在局限性。随着深度学习在视觉任务中不断发展,学者们将神经网络扩展到HSI分类领域。LIU等[14]设计了浅层卷积神经网络,但该方法只关注了光谱的相关性,忽略了空间信息,导致性能不佳。随着网络深度增加和模型复杂度变大,运行效率受到影响。ROY等[15]使用2D-3D混合卷积神经网络降低模型复杂度,提升分类精度。SONG等[16]通过加深2DCNN,在卷积层之间引入残差学习,缓解梯度消失和爆炸的问题,由此提出深度特征融合网络(DFFN)。为充分重用前几层的特征信息,PAOLETTI等[17]使用密集连接卷积网络,ZHONG等[18]建立3D空谱残差网络(SSRN),WANG等[19]提出基于密集连接模块的快速密集连接空谱卷积网络(FDSSC)。然而,受卷积核尺寸的影响,较深层的网络会出现捕捉非局部区域长程交互信息效率低的问题。
注意力机制被设计成关注信息相关区域,减少对非必要区域的关注,在Transformer架构中引入了自注意力机制,并应用在计算机视觉领域,取得较好效果。QING等[20]提出一种端到端的Transformer网络,通过光谱注意力机制和自注意力机制提取光谱和空间特征。HONG等[21]提出频谱转换器网络(SF),该网络通过Transformer从HSI的相邻波段中学习每个波段的局部序列信息,但在捕捉全局信息方面仍有提升的空间。MA等[22]提出双分支多注意力机制网络(DBMA),但将注意力机制置于网络的后端,且在初始阶段不发生作用。LI等[23]提出结合光谱注意力机制和空间注意力机制的双分支双注意力网络(DBDA),但该方法在计算过程中存在参数量过大的问题。SUN等[24]提出的光谱空间特征标记的Transformer网络(SSFTT)在一定程度上提升了分类精度,但总体性能仍不理想,主要原因是Transformer在提取局部和全局信息方面存在局限性。ZHU等[25]提出一种带有光谱注意力和空间注意力的残差光谱-空间注意网络(RSSAN),该方法能更好地关注丰富的光谱波段和空间位置。MA等[26]提出一种自高斯注意力的网络,采用高斯绝对位置偏差模拟HSI数据分布,能够显著提升全局特征信息的获取效果,但存在局部信息缺失的情况。虽然以上方法在引入注意力机制后性能增强,但在捕捉空间和光谱之间的长程依赖关系方面,仍未能达到最优效果。
针对上述问题,笔者提出一种基于自高斯与通道注意力的重塑卷积高光谱图像分类算法 (reshaped convolutional"channel attention with light self-Gaussian attention,RC-LSGA)模型。RC-LSGA模型首先通过卷积层获取局部特征关系,然后引入通道注意力机制,更好地保留图像块完整性,最后将得到的特征传入两个分支。一个分支将LSGA与Transformer结合建模,通过感知位置的方式建模远程关系,实现全局特征提取;另一分支引入重塑卷积分支,高效利用局部特征信息。这种全局和局部结合的方式,提高了高光谱图像特征的表达性,使整体分类精度表现优异。
1 "RC-LSGA模型整体框架
RC-LSGA模型框架见图1。首先,通过主成分分析对HSI数据降维,再将图像块输入混合谱空特征提取器提取浅层特征信息。然后,使用通道注意力增强光谱特征信息的表达,再将特征信息传入LSGA Transformer和重塑卷积分支中,实现深层特征提取。最后,融合提取的特征,并经由线性分类器分类。
RC-LSGA程序如下。
Input:"The HSI dataset X0∈RH×W×S.
1: Obtain XPCA∈RH×W×S"by performing PCA to reduce the dimensionality of the original HSI.
2: Divide"XPCA"into blocks, obtain n"samples, each samples size is X1∈Rh×w×s.
3: for" =1 to
=1 to  "do
"do
4:""Use the hybrid spectral-spatial feature extractor to extract shallow local features"A.
5: "Enhance the spectral feature representation of"A"using channel attention to obtain"E.
6:""""for" =1 to
=1 to  "do
"do
7:""""""Feature"Zlsga"with local and global information is generated by the LSGA transformer.
8:""""""Feature Zr-conv"with the detailed feature information by the reshaped convolutional branch.
9:""""""Feature information Fusion"Zout=Zlsga+Zr-conv
10: ""end for
11:""Perform average pooling on the feature
U=AvgPooling(Zout).
12:""Perform linear classification on the feature
N=LinearClassifier(U).
13: end for
Output:"Predicted the labels of pixels via N.
2 "算法描述
2.1""混合谱空特征提取器
设输入的高光谱数据为X0∈RH×W×S,其中H和W分别为HSI的高度和宽度,S为光谱带数。通过PCA对原始数据进行降维,既保留大部分关键信息,又减少参数数量和模型计算量。经过PCA降维后,HSI可表示为XPCA∈RH×W×s, 为PCA处理后的光谱带数。然后将降维后的数据,以中心像素为基准,逐像素取周边邻域像素构成像素特征块X1∈Rh×w×s,其类别Y=(y1,y2,…,yk)为中心像素对应的标签,其中
为PCA处理后的光谱带数。然后将降维后的数据,以中心像素为基准,逐像素取周边邻域像素构成像素特征块X1∈Rh×w×s,其类别Y=(y1,y2,…,yk)为中心像素对应的标签,其中 为HSI类别数量。
为HSI类别数量。
混合谱空特征提取器先将X1重塑为X2∈Rs×h×w,再利用3D卷积层提取特征信息。第m卷积层第n个特征图在像素位置(i,j,k)处的输出值为
 ,(1)
,(1)
式中:φ(·)为激活函数;bm,n为偏置参数;2λ+1,2μ+1和2η+1分别为卷积核的通道数、高度和宽度; 为卷积核;
为卷积核; 为输入三维数据块的数量,取1。
为输入三维数据块的数量,取1。
将输出特征进一步传入到2D卷积层,第 卷积层第
卷积层第 个特征图在像素位置(i,j)处的输出值为
个特征图在像素位置(i,j)处的输出值为
 。(2)
。(2)
最后得到所有特征,输出为A。
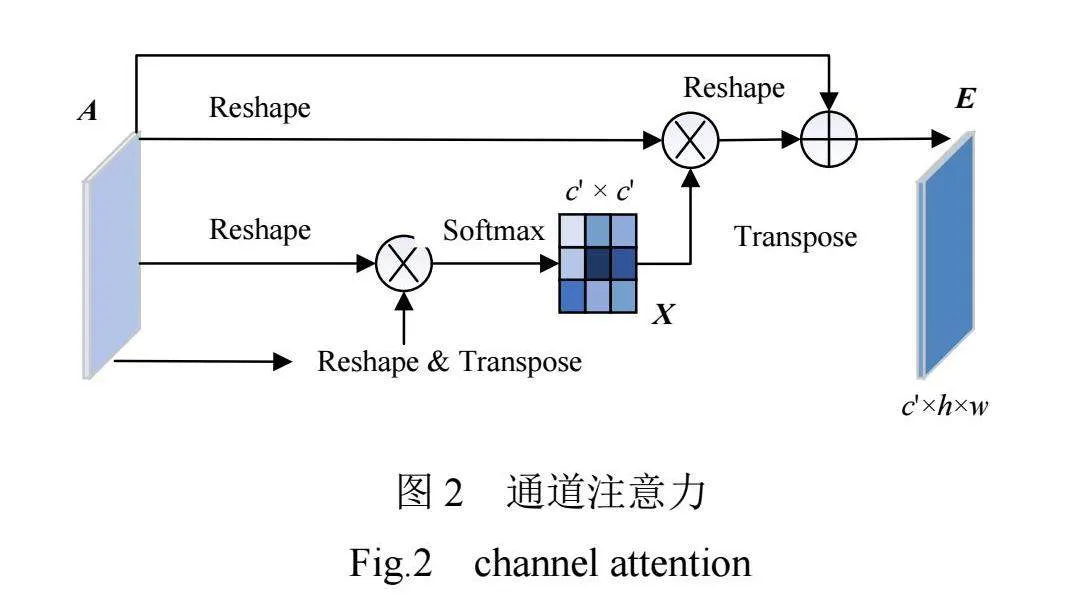
2.2 "通道注意力
为细化光谱特征,在卷积层后添加通道注意力,如图2所示,图中c'表示通道的个数,h×w表示输入的尺寸大小。
将A与AT矩阵相乘,经过Softmax激活函数层获得通道注意力特征图 。
。
第 个通道对第
个通道对第 个通道的影响力可表示为
个通道的影响力可表示为
 , (3)
, (3)
式中,Ai、Aj分别为输出特征A在 通道和
通道和 通道上的特征值。
通道上的特征值。
将XT与A矩阵相乘的结果变换为 。通过尺寸参数
。通过尺寸参数 对结果进行加权并添加输入A,得到最终光谱注意力图
对结果进行加权并添加输入A,得到最终光谱注意力图 ,其中E是所有通道Ej的加权和。
,其中E是所有通道Ej的加权和。
 。 (4)
。 (4)
通道注意力机制会削弱信息缺失通道,增加像素的权重,得到输出大小为c'×h×w的特征图。
2.3 "LSGA Transformer网络
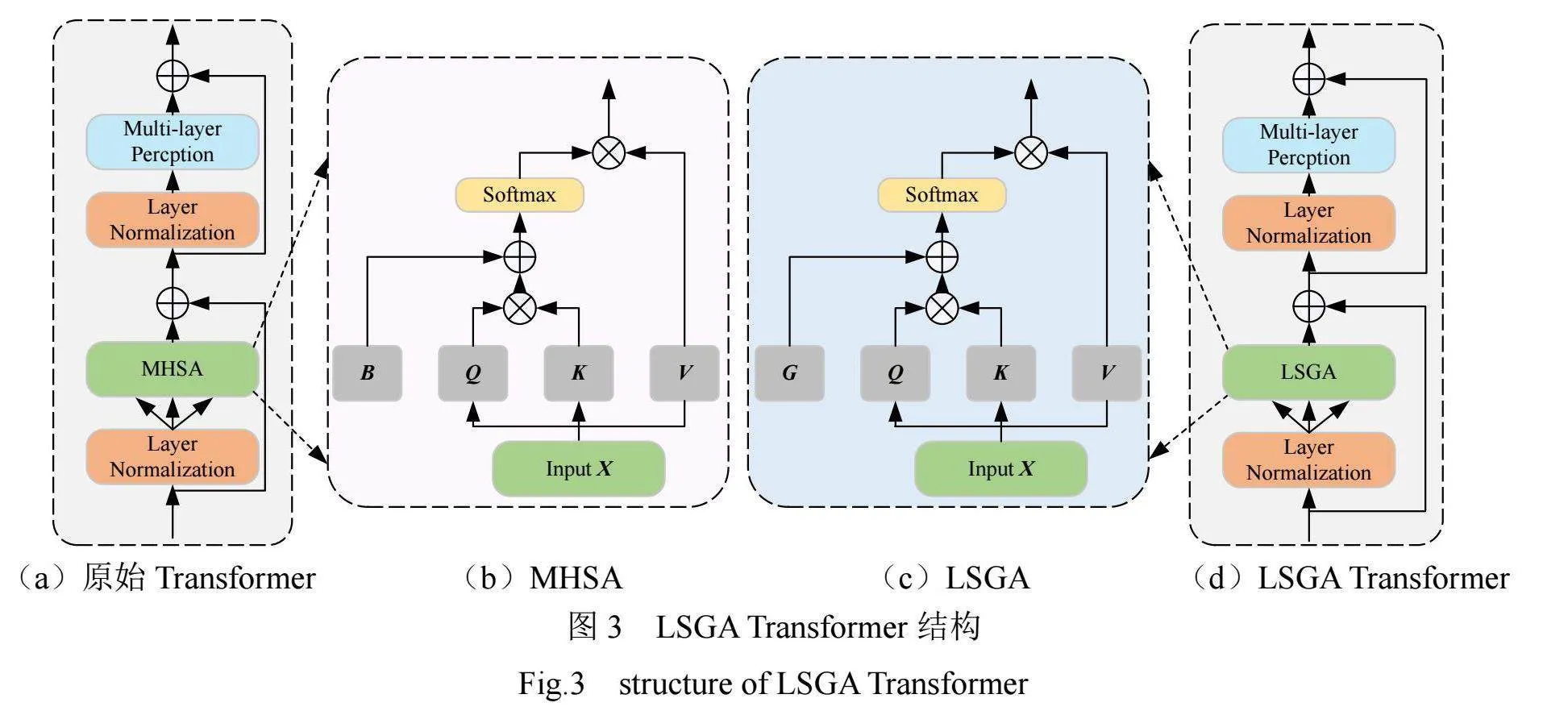
Transformer主要用于学习全局特征信息。原始的Transformer结构见图3(a),分别由两个归一化(LN)层,一个多层感知机(MLP)和多头自注意力(MHSA)组成,其中MHSA是Transformer中最重要的部分,其结构见图3(b)。
引入多头自注意力机制可以同时关注多个重点区域,提升模型效率,还可以为注意力层提供多个表示子空间,使模型有更大容量。原始注意力可表示为
 ,(5)
,(5)
式中,Q、K和V分别为查询矩阵、键矩阵和值矩阵。
Transform无法捕获位置信息,因此在多头自注意力机制中,对每个头中引入相对位置偏差参数 ,即
,即
 , (6)
, (6)
式中,d为多头注意力机制中每个头的维度。
对于每个输入HSI块,中心像素光谱信息比周围像素更关键。通常距离相近的像素更相似,因此使用二维高斯函数来表示HSI的空间关系为
 ,(7)
,(7)
式中: 为标准差;(x,y)为空间位置坐标;t为输入HSI块的大小。
为标准差;(x,y)为空间位置坐标;t为输入HSI块的大小。
将多头注意力中的相对位置偏差用高斯绝对位置替代偏差,提升细节特征信息获取能力,如图3(c)所示,完整的LSGA"Transformer如图3(d)所示,其表达式为
 。 (8)
。 (8)
将LSGA的计算结果再传入多层感知机进行处理,整个LSGA Transformer处理的特征表示为Zlsga。
2.4 "重塑卷积分支
卷积神经网络具有强大的局部特征提取能力,因此为充分重用特征信息,使用二维卷积组来捕获HSI的局部特征信息。卷积组主要包含3个二维卷积层,同时为使模型更快收敛,在每个卷积层后添加BN层和ReLU激活函数,重塑卷积分支结构见图4。
将得到的特征信息进行三维重塑,然后传输到二维卷积组进行操作,利用卷积参数共享的特点,更快地得到细腻的特征信息,此过程可表示为
Zr-conv=Conv2D(Conv2D(Conv2D(Reshape(E))))。(9)
最后,通过逐元素相加将LSGA Transformer和重塑卷积分支捕获的不同类型特征融合。
3 "实验
为验证提出的方法在HSI分类中的准确性和有效性,选取3个公共数据集开展实验。首先采用定量精度指标对RC-LSGA的性能进行评估。定量精度指标包括:总体准确率(overall accuracy,OA)、平均准确率(average accuracy,AA)和Kappa系数K。然后,通过调整模型的输入尺寸、学习率、PCA光谱波段和LSGA Transformer层数,取10次实验的平均值,确定模型的最优参数。最后,将RC-LSGA模型与其他模型进行对比,并进行消融实验。实验计算机配置如下:Intel Core I7-9700K CPU、RTX1080Ti和16GB RAM。选Adam优化器,设批处理大小为128,Epoch为100。
3.1 "高光谱数据集
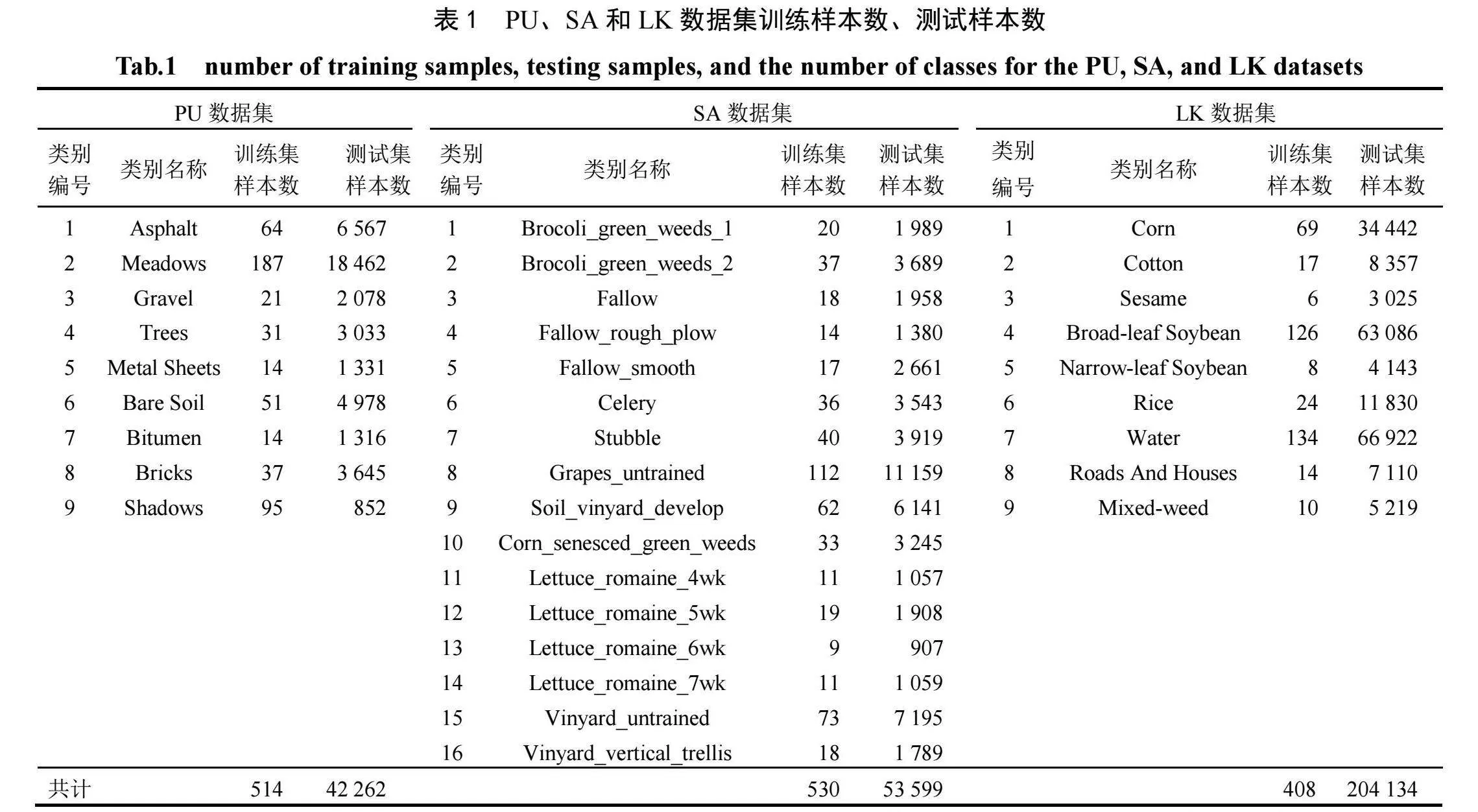
高光谱数据是含有多个光谱波段的图像,实验选取的3个公共数据集的信息见表1。PU数据集在意大利北部帕维亚大学校园内采集,包含9个不同类别,103个高光谱波段,图像分辨率为610×340。SA数据集在加利福尼亚州萨利纳斯谷的农田上采集,包含16个不同类别,204个高光谱波段,图像分辨率为512×217。LK数据集在中国湖北省龙口镇采集,包含9个不同类别,270个高光谱波段,图像分辨率为550×400。为了验证RC-LSGA模型的性能,分别将每个数据集的训练集设置为总样本数的1%、1%和0.2%。
3.2 "参数设置及调节
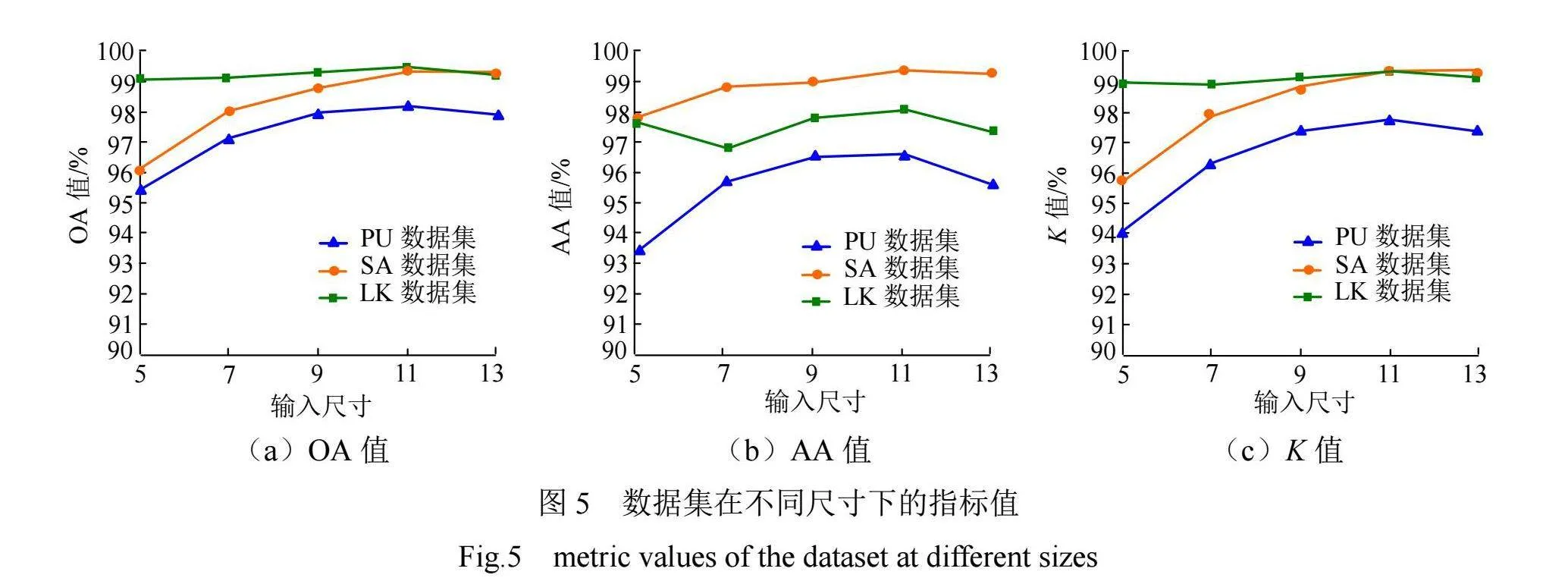
(1)输入尺寸敏感性分析
图像输入尺寸对分类的结果影响显著,因此通过对比3个数据集的定量精度指标确定最优输入尺寸,结果见图5。从图5可以看出,输入尺寸为7×7时,LK数据集的AA值明显下降;除此之外,各数据集的OA值、AA值和K值随输入尺寸增大呈缓慢增加而后缓慢下降的趋势,导致这一结果的主要原因是LK数据集中存在样本不平衡问题。然而,从总体来看,当输入图像尺寸为11×11时,在3个数据集上均分类结果表现出最佳效果。
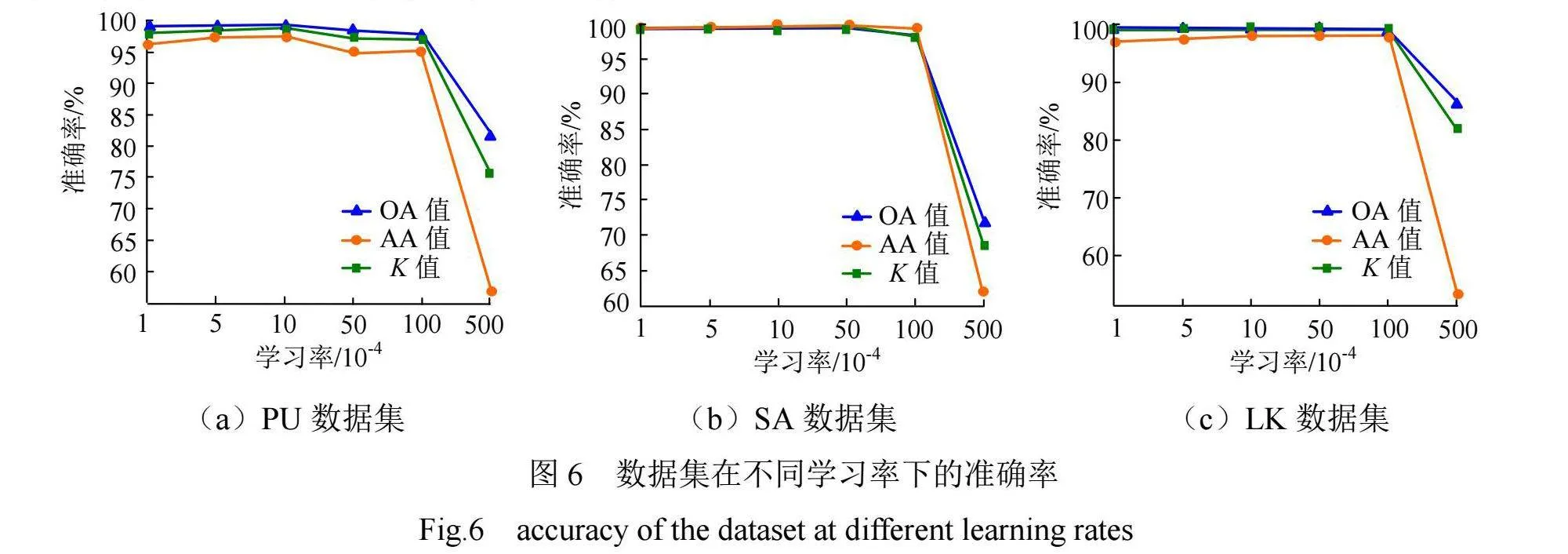
(2)学习率分析
学习率对模型的拟合效果有直接影响。不同学习率下,3个数据集的分类准确率见图6。从图6中可以看出,当学习率为0.001时,3个数据集的分类准确率均达到最高。根据图6(a),PU数据集的分类准确率随着学习率的增加先上升后下降,且在拐点处达到最佳。根据图6(b)、图6(c)可知,学习率对SA、LK数据集的分类准确率影响较小,这主要是因为SA、LK数据集具有丰富的样本和多个类别,使得RC-LSGA模型具备较强的抗过拟合能力。
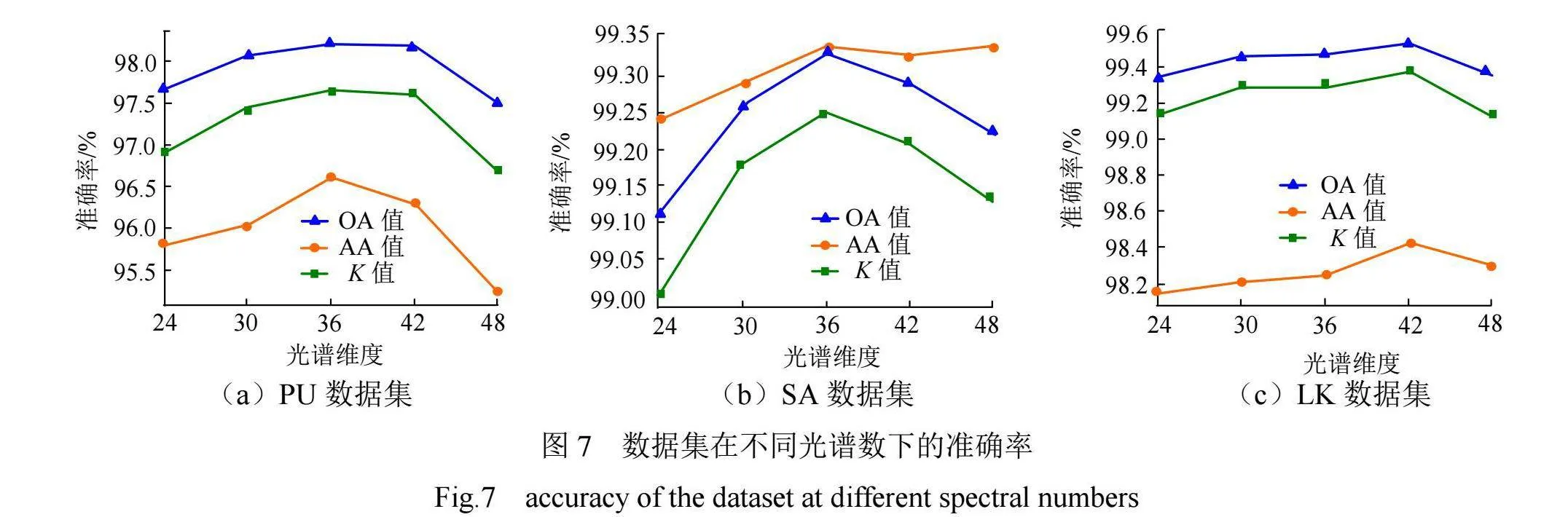
(3)PCA维度分析
光谱维度大小对分类准确率同样存在影响,3种数据集在不同光谱维度下的分类准确率见图7。由图7(a)、图7(b)可见,PU、SA数据集的3个分类准确率指标值均呈先增大后减少的趋势,光谱维度为36时,3个指标值最大。由图7(c)可见,LK数据集分类准确率的变化不太明显,光谱维度为42时表现最好。这可能是因为该数据集中包含了大量类别且光谱信息丰富。
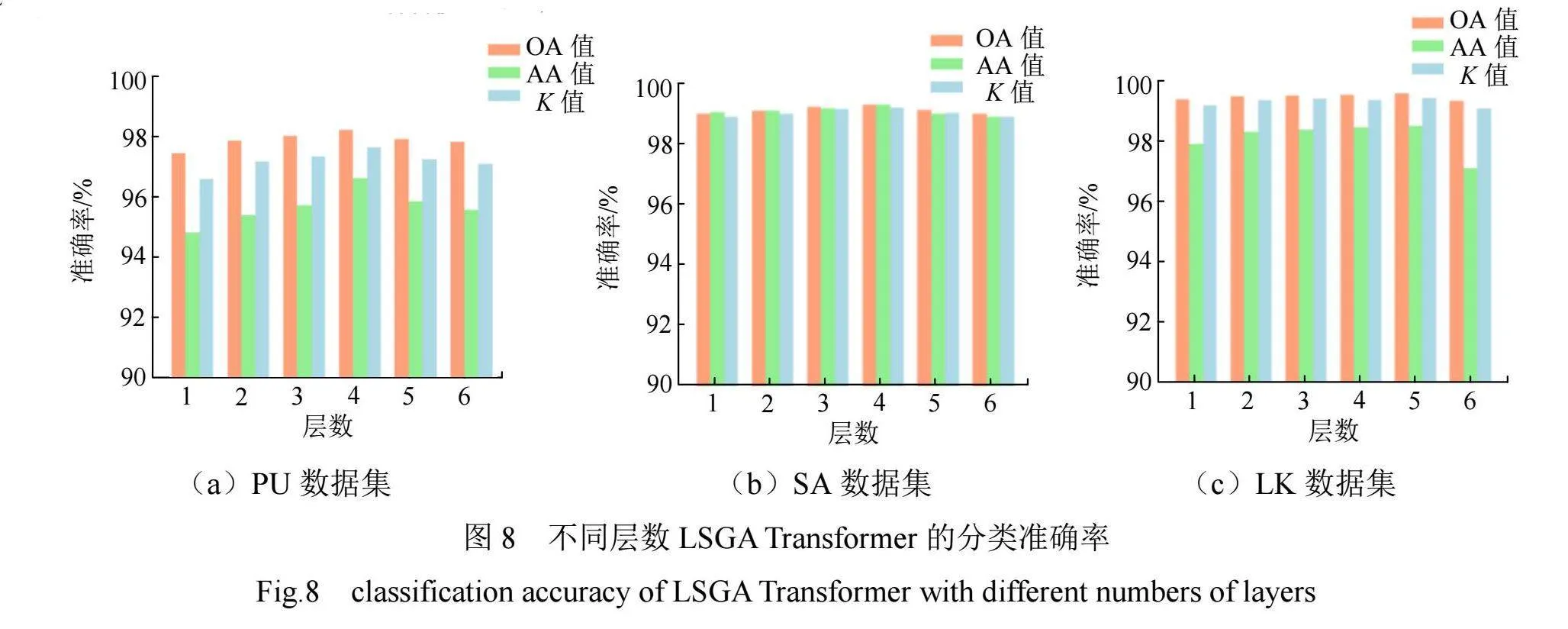
(4)LSGA Transformer层数分析
 合理选择Transformer的层数可保证RC-LSGA模型网络的鲁棒性,因此分别使用6种层数对3种数据集进行分类,验证RC-LSGA模型的性能。不同Transformer层数下3种数据集分类准确率见图8。
合理选择Transformer的层数可保证RC-LSGA模型网络的鲁棒性,因此分别使用6种层数对3种数据集进行分类,验证RC-LSGA模型的性能。不同Transformer层数下3种数据集分类准确率见图8。
从图8可以看出,层数为4时,RC-LSGA模型对3种数据集分类的OA值、AA值和K值均为最优。由图8(a)可知,PU数据集分类的3个评价指标随着层数的增加变化较为明显,这是因为PU数据集种类别较少,层数增加使训练更充分。但当层数持续增加到一定值,分类评价指标值出现下降,这是因为层数过多使RC-LSGA模型的计算量增加,导致模型整体性能下降。由图8(b)、图8(c)可知,SA、LK数据集的3个评价指标随着层数的增加变化较为平缓,这是因为样本在空间分布较为紧凑且类别数量较多,增加网络层数不利于特征的识别,反而使分类准确率降低。层数为6时,LK数据集的3个评价指标下降最明显,这是因为层数过大增加了模型的复杂性。
3.3 "对比实验结果与分析
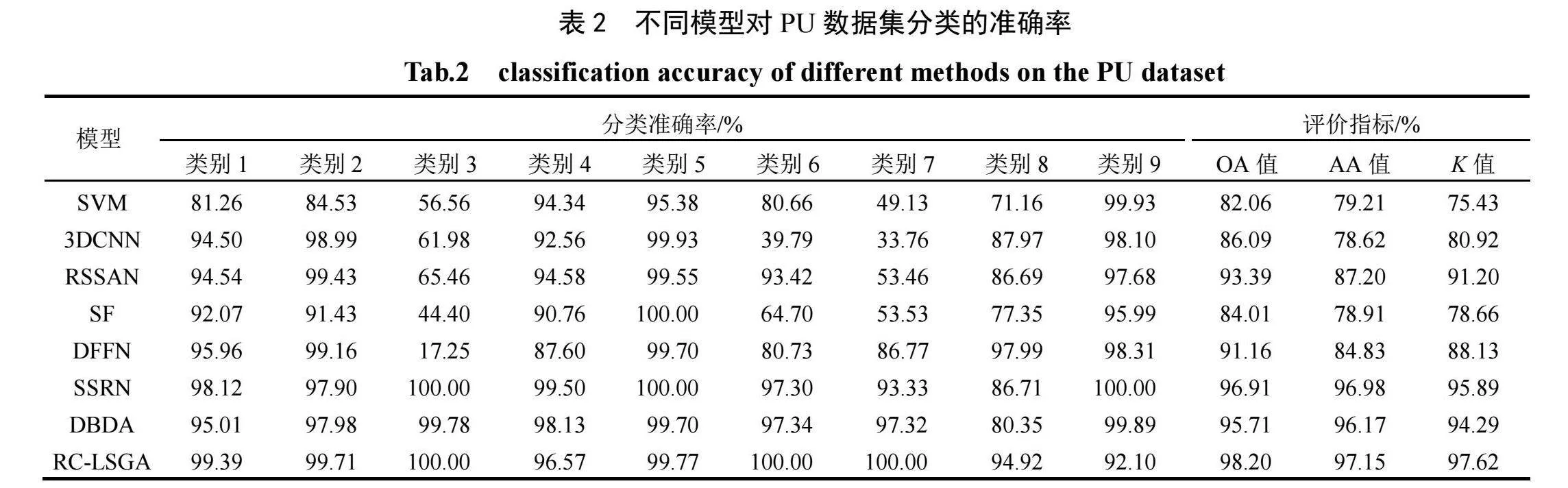
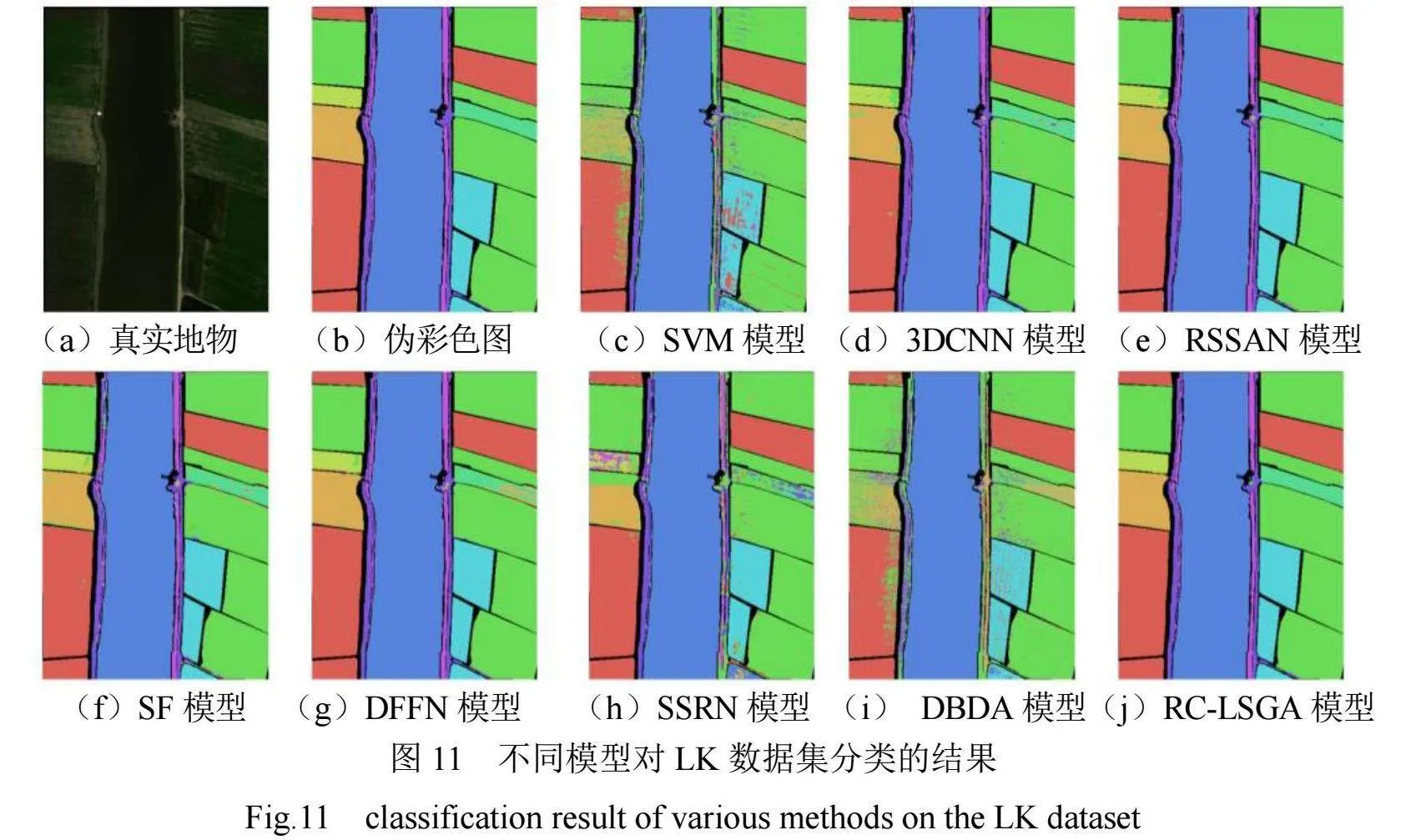
将RC-LSGA模型分别与SVM模型、3DCNN模型、RSSAN模型、SF模型、DFFN模型、SSRN模型、DBDA模型进行对比。PU、SA和LK数据集的分类准确率分别见表2~表4,分类结果分别见图9~图11。
由表2可见,RC-LSGA模型对PU数据集的分类在OA值、AA值和K值上都有一定优势。与SVM模型相比,RC-LSGA模型的OA值高16.14个百分点,这表明深度学习在HSI分类中表现更加出色。RC-LSGA模型对类别3、类别6和类别7的分类准确率达到100%,明显优于其他方法。但与SSRN模型相比,RC-LSGA模型对类别3的分类准确率低2.93个百分点;与DFFN模型相比,对类别8的分类准确率低3.07个百分点。这主要是因为两类材质较为接近,在分类的时候易出现交叉误分的情况。由图9可见,RC-LSGA模型的分类结果最为清晰,尽管在建筑物轮廓处存在细微的误分类,但与其他方法相比,其分类效果显著提升,这表明RC-LSGA模型能够充分利用HSI中的高低频信息。
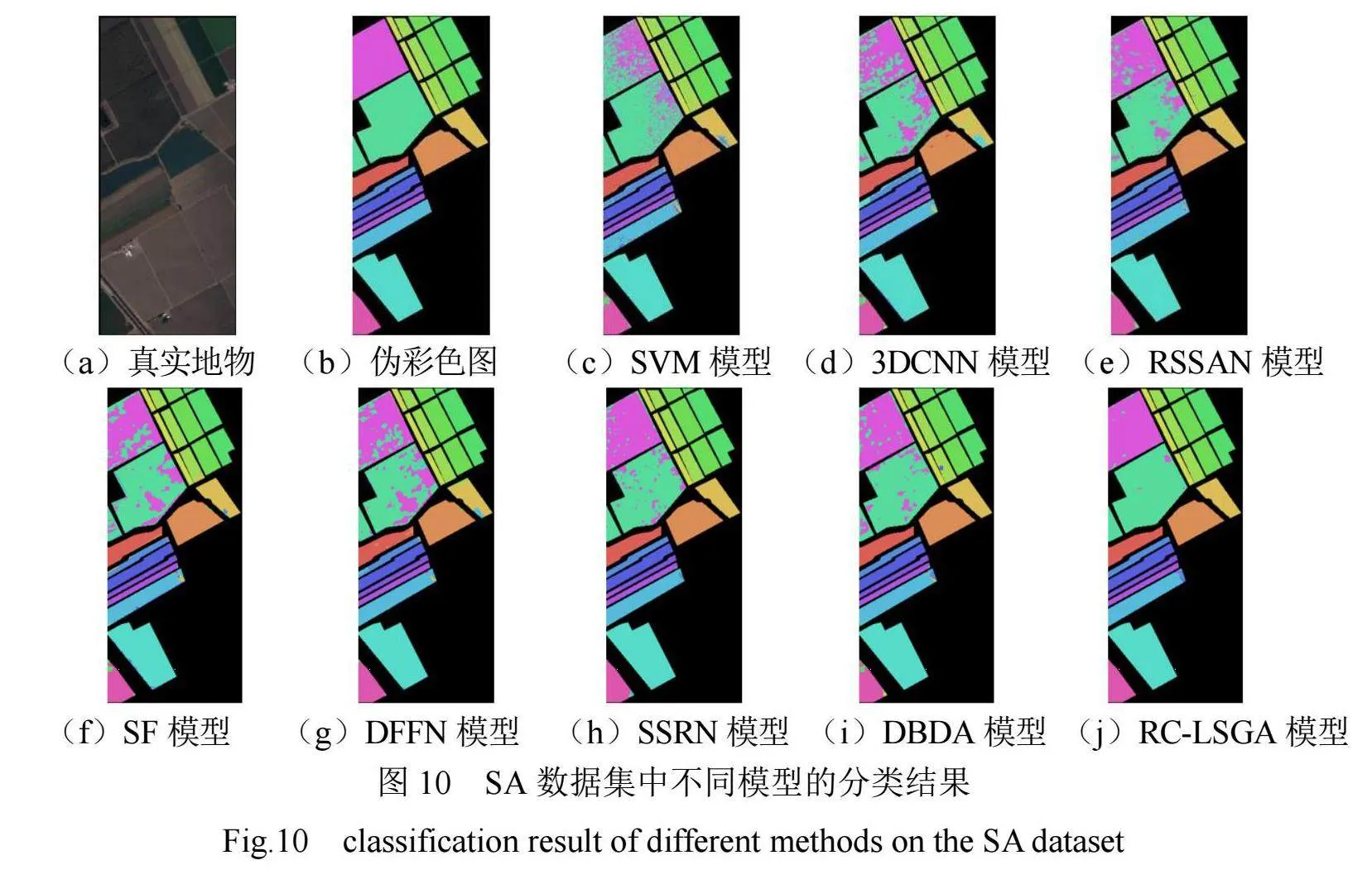
由表3可见,RC-LSGA模型对多个类别的分类准确率为100%,这是因为SA数据集样本数量充足,同时RC-LSGA模型对不同光谱波段的特征有加强作用。由图10可见,RSSAN模型提取和细化了光谱空间特征,但特征提取不足导致分类结果图中有噪声点。DBDA模型虽然引入了注意力机制,但对树木的分类准确率不理想。与其他引入注意力机制的模型相比,RC-LSGA模型对SA数据集的分类结果最优,OA值、AA值和K值分别达到了99.33%,99.34%和99.25%。
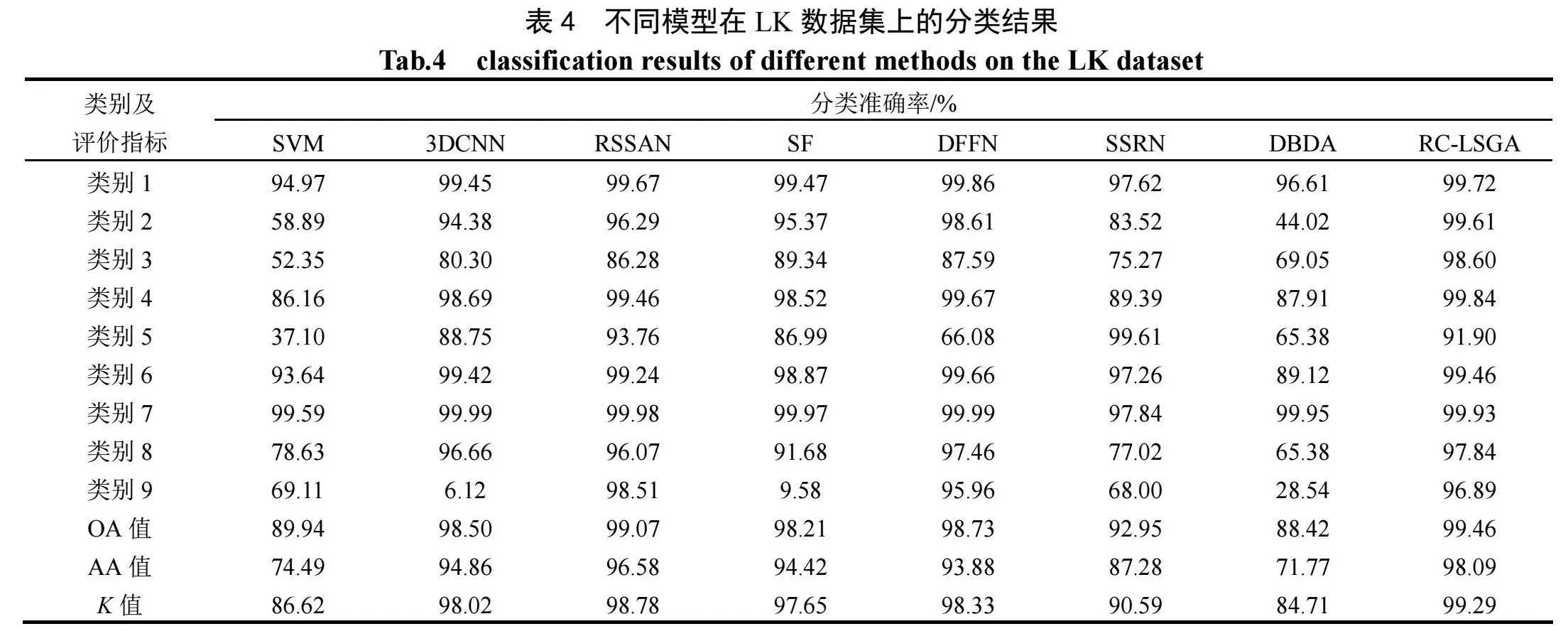
由表4可见,在LK数据集上不同模型的分类效果均较好,但RC-LSGA模型对大多数类别的分类准确率明显较高,尤其是类别2、类别4,RC-LSGA模型的分类准确率分别达到99.61%和99.84%。RC-LSGA模型在LK数据集上的OA值达到了99.46%,优于其他模型,进一步验证了该模型的有效性。由图11可见,"RC-LSGA模型在LK数据集上生成的分类图更接近实际情况,这是因为该模型能生成更多的特征图,并充分利用其中的信息来提取全局特征和局部细节。
3.4 "消融实验
为探究不同模块对RC-LSGA模型性能的影响,针对每个数据集分别进行了4组消融实验。通过分析OA值,评估了RC-LSGA模型的可行性,消融实验结果见表5。
首先在不添加任何模块的情况下分类精度最低,一定程度上说明没有充分利用全局与局部信息。其次,只添加通道注意力和只添加三维重塑卷积情况下,虽然在精度上有一定的提升,但总体效果不佳。将通道注意力和三维重塑卷积结合后,分类的准确率提升较大,在PU、SA和LK数据集上分别达到了98.20%,99.33%,99.46%,这进一步证明了RC-LSGA模型在分类性能上的优势。
3.5 "模型运行效率分析
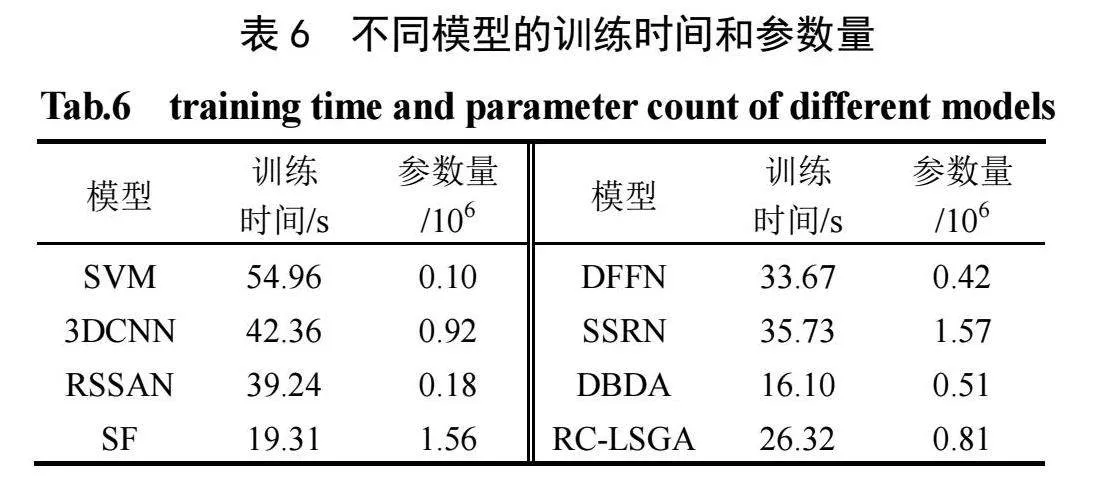
为验证RC-LSGA的执行效率,以模型的参数量和单次训练时间作为评价指标,见表6。
由表6可见,SVM模型训练的时间最长,这是因为SVM模型采用逐像素预测;与只使用卷积的3DCNN模型、DFFN模型和SSRN模型相比,引入视觉Transformer的SF模型,运行时间明显缩短;与其他模型相比,RC-LSGA模型的训练时间和参数量明显减少,只有DBDA模型的训练时间和参数量都优于RC-LSGA模型,这主要是因为RC-LSGA模型引入重塑卷积分支,导致训练成本增加。但总体看来,RC-LSGA模型仍是分类精度最高的。
4 "结论
(1)通过自高斯注意力Transformer来建立长距离依赖关系并获取全局信息,利用通道注意力和重塑卷积来获取细腻的局部特征,建立RC-LSGA模型。与其他模型的对比实验表明,该模型对3个数据集中的类别识别效果最优。
(2)RC-LSGA模型在不同类别之间仍存在误判的情况,因此模型仍需要进一步改进。在未来的研究中,将致力于提高HSI分类精度的同时,实现模型的轻量化。
参考文献(References):
[1] TU B,ZHOU C"L,KUANG W"L,et al.Multiattribute sample learning for hyperspectral image classification using hierarchical peak attribute propagation[J].IEEE Transactions on Instrumentation and Measurement,"2022,71:6502617.
[2] GEVAERT C M,SUOMALAINEN J,TANG J,et al.Generation of spectral-temporal response surfaces by combining multispectral satellite and hyperspectral UAV imagery for precision agriculture applications[J]."IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2015,8(6):3140-3146.
[3] XUE Z"H,ZHOU Y"Y,DU P"J.S3Net:spectral–spatial Siamese network for few-shot hyperspectral image classification[J].IEEE Transactions on Geoscience and Remote Sensing,2022,60:1-19.
[4] ARDOUIN J P,LÉVESQUE J,REA T A.A demonstration of hyperspectral image exploitation for military applications[C]//2007 10th International Conference on Information Fusion.July 9-12,2007,Quebec, QC,Canada. IEEE,2007:1-8.
[5] HE C"X,SUN L,HUANG W,et al.TSLRLN:tensor subspace low-rank learning with non-local prior for hyperspectral image mixed denoising[J].Signal Processing,2021,184:108060.
[6] SUN L,WU F"Y,ZHAN T"M,et al.Weighted nonlocal low-rank tensor decomposition method for sparse unmixing of hyperspectral images[J]."IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2020,13:1174-1188.
[7] NASRABADI N M.Hyperspectral target detection:an overview of current and future challenges[J].IEEE Signal Processing Magazine, 2014,31(1):34-44.
[8] TU B,REN Q,ZHOU C"L,et al.Feature extraction using multidimensional spectral regression whitening for hyperspectral image classification[J].IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2021,14:8326-8340.
[9] MA Y,LIU Z,CHEN CHEN C L P.Hybrid spatial-spectral feature in broad learning system for Hyperspectral image classification[J].Applied Intelligence,2022,52(3):2801-2812.
[10] AUDEBERT N,LE SAUX B,LEFÈVRE S.Deep learning for classification of hyperspectral data:a comparative review[J].IEEE Geoscience and Remote Sensing Magazine,2019,7(2):159-173.
[11] ARCHIBALD R,FANN G.Feature selection and classification of hyperspectral images with support vector machines[J].IEEE Geoscience and Remote Sensing Letters,2007,4(4):674-677.
[12] SHEN X"F,BAO W"X,LIANG H"B,et al.Grouped collaborative representation for hyperspectral image classification using a two-phase strategy[J].IEEE Geoscience and Remote Sensing Letters,2022,19:"5505305.
[13] BANDOS T V,BRUZZONE L,CAMPS-VALLS G.Classification of hyperspectral images with regularized linear discriminant analysis[J]. IEEE Transactions on Geoscience and Remote Sensing,2009,47(3): 862-873.
[14] LIU B,YU X"C,ZHANG P"Q,et al.A semi-supervised convolutional neural network for hyperspectral image classification[J].Remote Sensing Letters,2017,8(9):839-848.
[15] ROY S K,KRISHNA G,DUBEY S R,et al.HybridSN:exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification[J].IEEE Geoscience and Remote Sensing Letters,2020, 17(2):277-281.
[16] SONG W"W,LI S"T,FANG L"Y,et al.Hyperspectral image classification with deep feature fusion network[J].IEEE Transactions on Geoscience and Remote Sensing,2018,56(6):3173-3184.
[17] PAOLETTI M E,HAUT J M,PLAZA J,et al.Deep"amp;"dense convolutional neural network for hyperspectral image classification[J].Remote Sensing,2018,10(9):1454.
[18] ZHONG Z"L,LI J,LUO Z"M,et al.Spectral-spatial residual network for hyperspectral image classification:a 3-D deep learning framework[J]. IEEE Transactions on Geoscience and Remote Sensing,2018,56(2): 847-858.
[19] WANG W"J,DOU S"G,JIANG Z"M,et al.A fast dense spectral–spatial convolution network framework for hyperspectral images classification[J]."Remote Sensing,2018,10(7):1068.
[20] QING Y"H,LIU W"Y,FENG L"Y,et al.Improved transformer net for hyperspectral image classification[J].Remote Sensing,2021,13"(11):2216.
[21]"HONG D"F,HAN Z,YAO J,et al."Spectral"former:"rethinking hyperspectral image classification with transformers[J].IEEE Transactions on Geoscience and Remote Sensing,2022,60:5518615.
[22] MA W"P,YANG Q"F,WU Y,et al.Double-branch multi-attention mechanism network for hyperspectral image classification[J]. Remote Sensing,2019,11(11):1307.
[23] LI R,ZHENG S"Y,DUAN C"X,et al.Classification of hyperspectral image based on double-branch dual-attention mechanism network[J]. Remote Sensing,2020,12(3):582.
[24] SUN L,ZHAO G"R,ZHENG Y"H,et al.Spectral-spatial feature tokenization transformer for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing,2022,60:5522214.
[25] ZHU M"H,JIAO L"C,LIU F,et al.Residual spectral–spatial attention network for hyperspectral image classification[J].IEEE Transactions on Geoscience and Remote Sensing,2021,59(1):449-462.
[26] MA C,WAN M"J,WU J,et al.Light self-Gaussian-attention vision transformer for hyperspectral image classification[J].IEEE Transactions on Instrumentation and Measurement,2023,72:5015712.
