基于N-gram模型的多层融合气象灾害预警文本检验方法
2024-01-15兰海波宋瑛瑛曹之玉朱小祥沈晨笛
兰海波,宋瑛瑛,曹之玉,朱小祥,沈晨笛,王 然
(中国气象局公共气象服务中心,北京 100081)
气象灾害是自然灾害中最为常见且影响十分严重的灾害。我国气象灾害造成的损失已占自然灾害造成损失的70%以上。为防御和减轻气象灾害带来的危害,保护国家和人员生命财产安全,气象部门所属气象台向政府部门和社会公众发布气象灾害预警信息[1]。气象灾害预警信息在农牧业[2]、海洋[3]、地质灾害[4]等都发挥了重要的作用,传播效能在一定程度上决定了气象灾害防御水平[5]。
气象灾害预警信息,通过计算机系统实现了信息的制作、录入、审核、发布等环节,制定了23类质量控制策略,采用自动化规则性对照检查和人工复核的方式,保障了对公众发布预警的准确性[6]。自动化规则性对照检查并不能有效地核验识别预警文本存在的错别字、冗余字、缺失字、字序颠倒等文本错误,而人工检查存在审核效率低下的问题。预警信息正文包含大概100多字,仔细完整检查需要1分钟的时间,严重影响了预警信息发布的时效性。2018年唐山市气象台发布雷电黄色预警信号,预警描述文本中错将“强降水”拼写为“强僵尸”,引发众多媒体热议。
文本质量控制检测模型,一般是先对文本进行分词,再用语言模型对分割的部分进行错误检测,主要的不足之处在于没有考虑气象灾害文本的专业特性。笔者在统计了2017—2020年全国气象历史灾害预警信息的基础上,对预警信息的特征进行分析,基于多模式融合分词方法,建立了一种以预警专业语料库为基础的气象预警文本分词方法。利用该方法研发了预警信息文本质量控制检测模型,识别预警文本中存在的文本错误,辅助提高人工预警审核效率。
1 气象预警信息和分词方法
1.1 气象预警信息特征分析
气象预警信息是按照国际通用警报协议CAP (common alerting protocol)进行数据格式编码[7]。其中,预警描述文本是直接对政府部门和公众进行发布的内容,包含了发布单位、发布时间、预警信息类型、预警信息等级、灾害因素、影响时间、影响区域、灾害影响、防御指南等内容的描述信息。基本格式为“X气象台X年X月X时X分发布X类型X级别预警信号:预计,X日X时至X日X时,将会对A地区、B地区、C地区等造成XXX影响,请注意防范”。预警文本示例为“北京市气象台2021年10月29日16时45分发布大雾黄色预警信号:预计,29日20时至30日09时,本市通州、大兴、平谷、顺义、朝阳、丰台、东城、西城、石景山、密云大部、海淀大部、怀柔东南部、房山东部、门头沟东部和昌平东部有雾,能见度小于1 000 m,部分地区小于500 m,请注意防范。”
通过文本示例和格式要求,可以看出气象预警信息文本有一定的领域专业特性,以地名、组织机构名称、时间、灾害类型、灾害级别、影响描述、防御常见措施、计量单位和专有名词等为主要文本构成,而且具有特定的格式框架。这些专业特性成为气象预警信息文本质量检测的关键点。
文本质量检测主要是精准确定出文本中出现的错误类型和错误位置,及时发现得到预防性处理。气象预警信息文本质量检测的关键和难点,是对专业特性名词的准确分词。统计总结2017—2020年全国气象历史灾害预警信息发现,预警描述文本中的错误类型涉及错别字、冗余字、缺失字、多词四大类。
1.2 多模式融合分词方法
近年来,随着互联网和高性能计算机的发展,自然语言处理领域在情感分析[8]、信息抽取[9]、机器翻译[10]等文本处理方面有了新的进展和应用。汉语与英语不同,不是以词出现,而是通过字与字的组合呈现出不同的含义。中文分词是进行自然语言处理的基础。
目前中文分词算法和工具应用都比较成熟,这些自然语言处理工具为预警描述文本检查提供了技术基础。场景不同,目标不同[11],工具的选择也不同。根据气象预警信息文本特征和质量检测应用场景,综合考虑处理速度、准确率、社区活跃度、适应范围、更新频率和语料结果,JIEBA、北京大学PKUSEG分词可供选择使用[12]。JIEBA分词处理速度最快,应用最广泛。在预警文本分词领域,北京大学PKUSEG分词在准确率、召回率、F评分测试指标上评价最高,笔者使用单一分词工具PKUSEG分词作为多模式融合分词方法的参照对象。气象预警信息文本的中文分词,直接应用单一通用分词工具存在两方面的问题:①由于气象预警信息文本的专业特性及分词工具对地名、组织机构名称、时间、灾害类型、灾害级别、影响描述、防御常见措施、计量单位和专有名词等新词识别的准确率、召回率和F评分会降低,对整体句子的语义理解将产生负贡献。在预警文本特征分析中,地名是用来描述预警影响范围的重要实体。使用单一分词工具对31个省名称、3 185个市县名称、40 446个乡镇名称进行切分,得到的地名识别准确率、召回率、F评分指标的平均评分,如表1所示。从表1可以看出,地名随行政级别的降低,分词的评价指标得分下降得很明显。②分词工具在解决歧义问题的方案中,索引时使用细粒度的分词以保证召回,查询时使用粗粒度的分词以保证精度。分词结果的多个短词对整体句子的语义理解比一个长词的贡献低。例如,使用分词工具切分词“森林火险气象等级”,会被切分为“森林/火险/气象/等级”。一个长词对整体句子理解的贡献比多个短词的贡献要高[13]。因此,我们期望“森林火险气象等级”是作为一个词被切分出来。
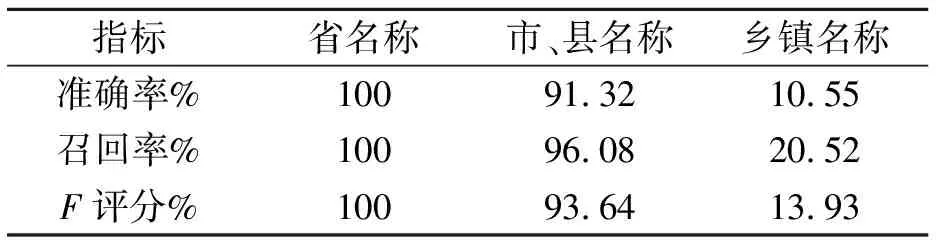
表1 利用单一分词工具拆分地名的准确率、召回率、F评分
为了解决上述问题,笔者设计了一种多模式融合分词方法。首先通过双向最大匹配[14]的方法,根据自建命名实体库将命名实体切分出来,只有正向最大匹配和逆向最大匹配切分出来的实体一致时才进行切分。命名实体库主要包括地名、组织机构名称、时间、计量单位、专业名称,如表2所示。其次,同时使用JIEBA分词和PKUSEG分词两种分词工具将句子进行切分,并将分词结果进行对比,如果两个分词结果相同,则返回;否则判定为较少单字或较多长字的分词结果。

表2 命名实体库示例
分词的准确率Pre、召回率Recall、F评分是评价分词方法的几种检验方法,如式(1)~式(3)所示。
(1)
(2)
(3)
式中:Nr为提取出的正确信息条数;NS为提取出的信息条数;Np为样本中的信息条数。
以某省2020年发布预警信息中随机采样50条省级预警、50条市级预警、50条县级预警作为中文分词性能测试数据来源,选择PKUSEG分词作为单一分词工具为对比对象,分别计算分词的准确率、召回率、F评分。对比测试结果显示,使用多模式分词方法的准确率、召回率和F评分在省级发布单位的预警文本、市级发布单位的预警文本、县级发布单位的预警文本中均有提升。省级预警文本的分词准确率由80.66%提升至94.94%,市级预警文本的分词准确率由82.08%提升至95.41%,县级文本的分词准确率由82.77%提升至95.14%,平均准确率提升了13.33%。同样,计算分词的平均召回率和平均F评分,在省、市、县三级预警文本中也均有提升,分别为6.76%和10.24%,如图1所示。
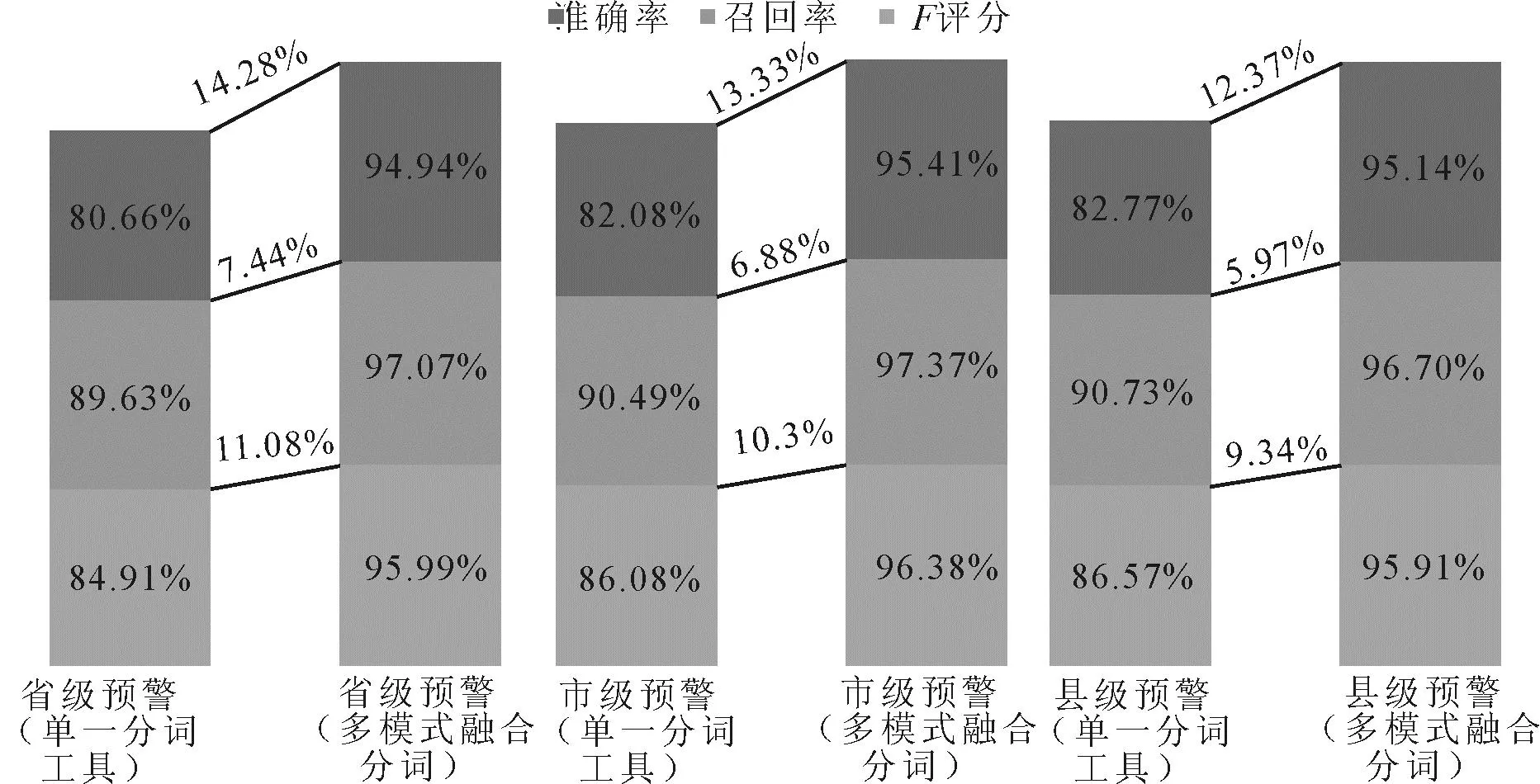
图1 多模式融合分词方法与单一分词方法评分对比
2 气象预警信息文本质量检测模型
2.1 字序列组合检验模型
气象灾害预警文本具有较高的相似度,甚至很多文本除日期、发布单位、影响范围(地名)外,其他信息是100%一致的。基于此,设计了字序列组合预警文本库,字序列组合按以下步骤对历史预警文本进行抽取、清洗:①对句子按分隔符切分成多个子句;②将每个子句中每个单字wi依次作为组合首字,向右顺序按照预设组合长度n进行切字,组合为wiwi+1wi+n-1;③组合长度依次设为n-m(m=1,n=2),重复步骤②;④单字由停顿词组成,包括物理单位(米、级),连接副词(和、将),助词(的),动词(对、有)等;⑤清洗过滤重复词。待检验预警文本按字序列组合方法切字,字序列组合预警文本库,如图2所示。按图中流程进行全匹配,考虑到模型运行性能适宜性,以及历史预警文本库中非专业特性名词大都为2个字组成,故设置n=3。
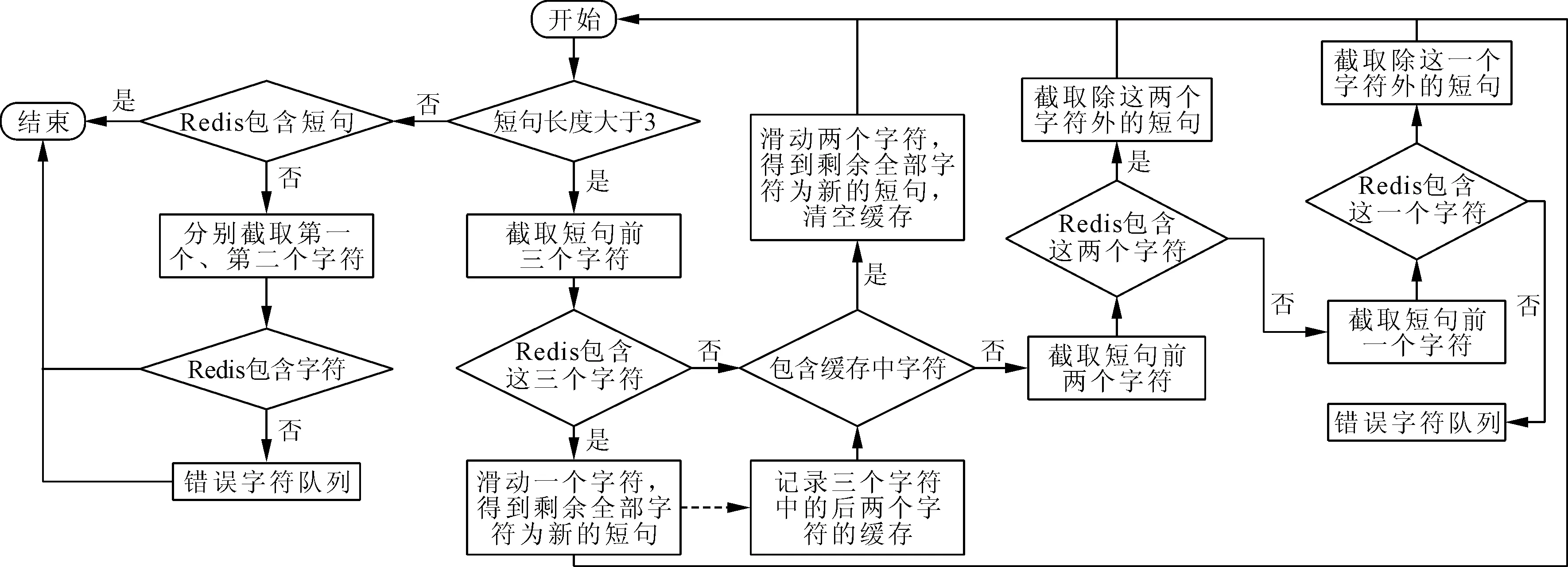
图2 字序列组合模型处理流程
以国家预警信息发布中心2021年全国预警库作为检验样本,从中随机抽取正确样本400条,人工制作错误样本400条。对字序列组合检验模型做准确性检验分析,结果如表3所示。由表3可知,正确样本判断为正确、错误样本判断为错误的准确率=(393+82)/(400+400)=59.38%。
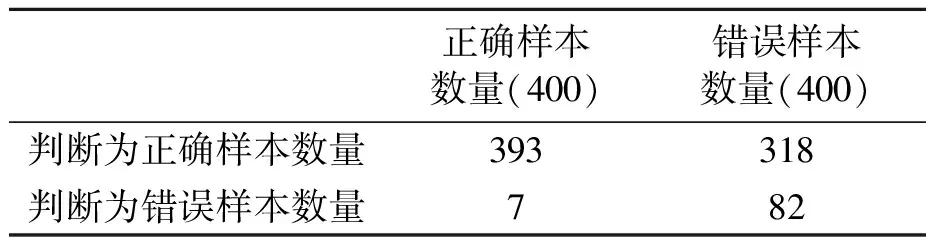
表3 字序列组合检验模型检验结果
其中,正确样本判断为正确的检验准确率=393/400=98.25%;错误样本被误判断为正确的漏警率=318/400=79.5%。尽管字序列组合模型的准确率(59.38%)并不高,但对正确样本的检验准确率却非常高,达98.25%。这主要是因为预警文本制作具有一定的模板式和规律性,大量的预警描述文本是由“制作单位+发布(解除)时间+预警类型+预警级别+影响范围+提示(指导)信息”组成,这些信息都有标准或规范可以遵循,排除日期、字符后,有大量的重复信息,通过切分排列组合达到完全一致的可能性非常高。同时,样本检验的漏警率较高,主要是因为序列组合的方法对缺失字、字序颠倒的检出率非常低。随预警文本内容的日益丰富,提示(指导)性的内容越来越多元化,字序列组合检验模型的漏警率也会越来越高。
2.2 归一化N-gram检验模型
N-gram在自然语言处理中是一种简单易理解的概率统计模型,根据前N-1个对象来预测第N个对象,即句子中的前N-1个单词和该单词之间有一个概率,可以用来判断句子是否正确。N-gram模型基于马尔可夫假设,假设每次出现的概率仅与前面的N-1个字符相关。假设一个句子s由i个词构成,则其出现的概率可表示为:
p(s)=p(w1w2…wi)=
p(w1)p(w2∣w1)p(w3∣w1,w2)…
p(wi∣w1,w2,…,wi-1)
(4)
式中:p(s)为句子s在语料库中出现的概率;p(wi|w1,w2,…,wi-1)为句子s在前i-1个词为w1,w2,…,wi-1的情况下,第i个词为wi的概率。N-gram在恶意信息检测[15]、主题识别[16]等方面有很多示范应用。N-gram语料库规模越大,做出的模型结果才更有用[17]。对于N的选择,考虑到气象预警信息文本是短文本,并且短句之间的联系并不深,因此构建Bi-gram模型足够解决需要,这意味着当前字词的条件概率取决于从前1个字词到该字词的转换概率,则式(4)可以近似表示为:
(5)
笔者依据气象预警信息文本特征分析和多模式融合分词方法,结合自建命名实体库,创建了预警专业语料库。预警专业语料库是按照N-gram模型运行默认语料库格式进行扩充增加中文分词。再利用多模式融合分词方法对检验预警描述文本分词,得到词序列,将多个连续地面标记为“AD”,将数字定义为“D”,经归一处理后得到词序列,将前文中预警描述处理得到如下词序列:“北京市气象台D年D月D日D时D分发布大雾黄色预警信号预计D日D时至D日D时AD有雾能见度小于D米AD小于D米请注意防范”。计算“AD有雾能见度小于D米”句子评分,部分选择计算过程如图3所示,句子评分结果为-21.408 8,比原值-52.861 2提升了59.5%。可见处理后的词序列对计算机来说更易理解的。
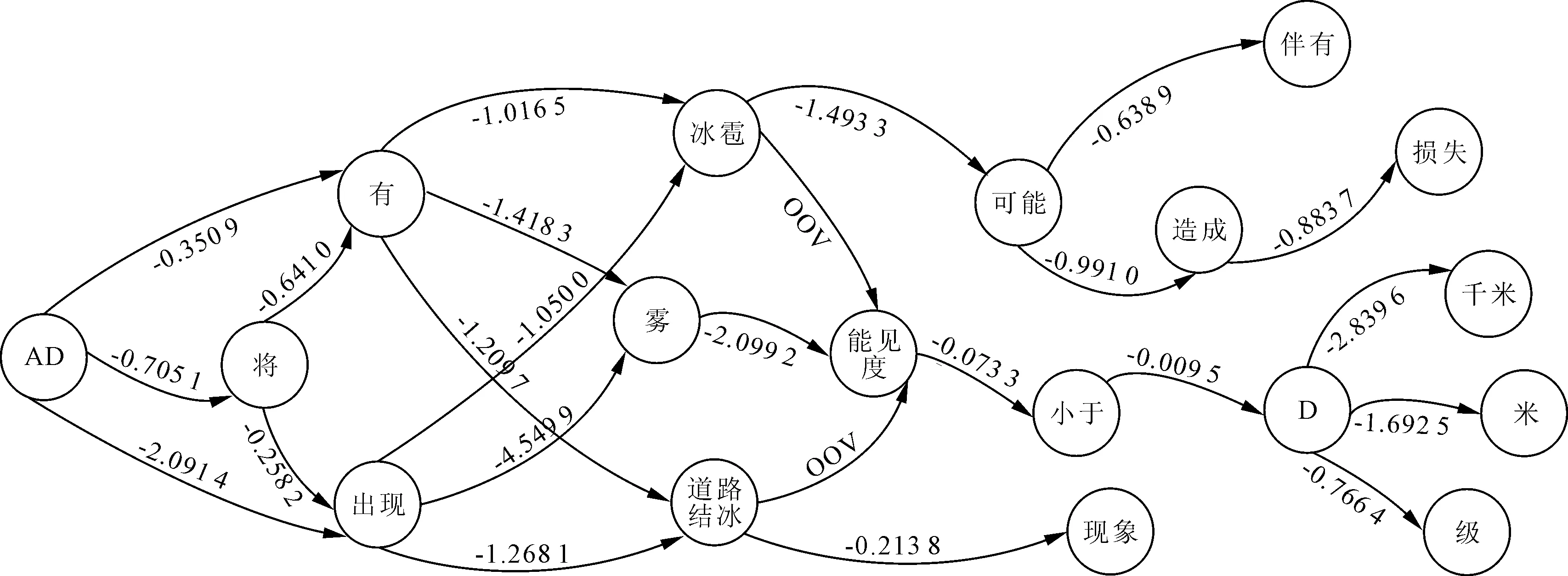
图3 Bi-gram选择计算过程
历史气象预警信息文本2个词之间的平均评分值为-4,使用并列归一方法的N-gram检验模型的检验规则为:判断每个词与词之间的评分值,如果值小于-4,则认为句子理解存疑。唐山市气象台2018年08月11日14时53分发布雷电黄色预警信号:目前我市北部地区已经出现雷电,预计未来六小时中北部大部分地区仍有雷电活动,雷雨时可能伴有短时强僵尸,大风等强对流天气,请有关单位和人员做好防范准备。使用N-gram模型对该雷电黄色预警信号文本进行检验,发现“强”和“僵尸”两个词之间的评分值为-100。
同样以2021年全国预警库为本样,对N-gram模型做准确性检验分析,检验结果如表4所示。
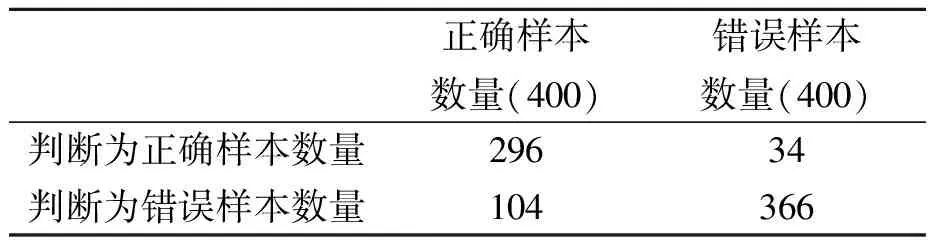
表4 N-gram检验模型检验结果
根据表4可以得到模型检验的准确率=(296+366)/(400+400)=82.75%,漏警率=34/400=8.5%。对比分析表3和表4的结果,可见N-gram模型检验错误句子的检出率更高,对词与词之间的逻辑关联关系要求更严格,在错别字词、缺失字、冗余字、词序颠倒的检出上均有较好的表现。与字序列组合模型相比,漏警率由79.5%减少至8.5%。但由于2017—2020年预警描述文本范围较小,重复词语较多,当出现未出现词时,即便是正确样本也会被认为是错误。
2.3 多级检验模型
为解决上述问题,提出了多级检验的方式,除将2017—2020年历史预警描述文本整理成预警专业语料库外,引入了人民日报语料库,扩大了词库的范围。预警信息描述文本来自国家预警信息发布中心2017—2020年历史预警库。地名信息来自民政部网“2012年中华人民共和国县以下行政区划代码及统计代码”。正确检验预警信息描述文本来自国家预警信息发布中心2021年预警库。多级检验模型以预警专业语料库为主,辅以人民日报语料库,以归一化N-gram检验模型为主,辅以字序列组合检验模型,其检验逻辑关系如图4所示。
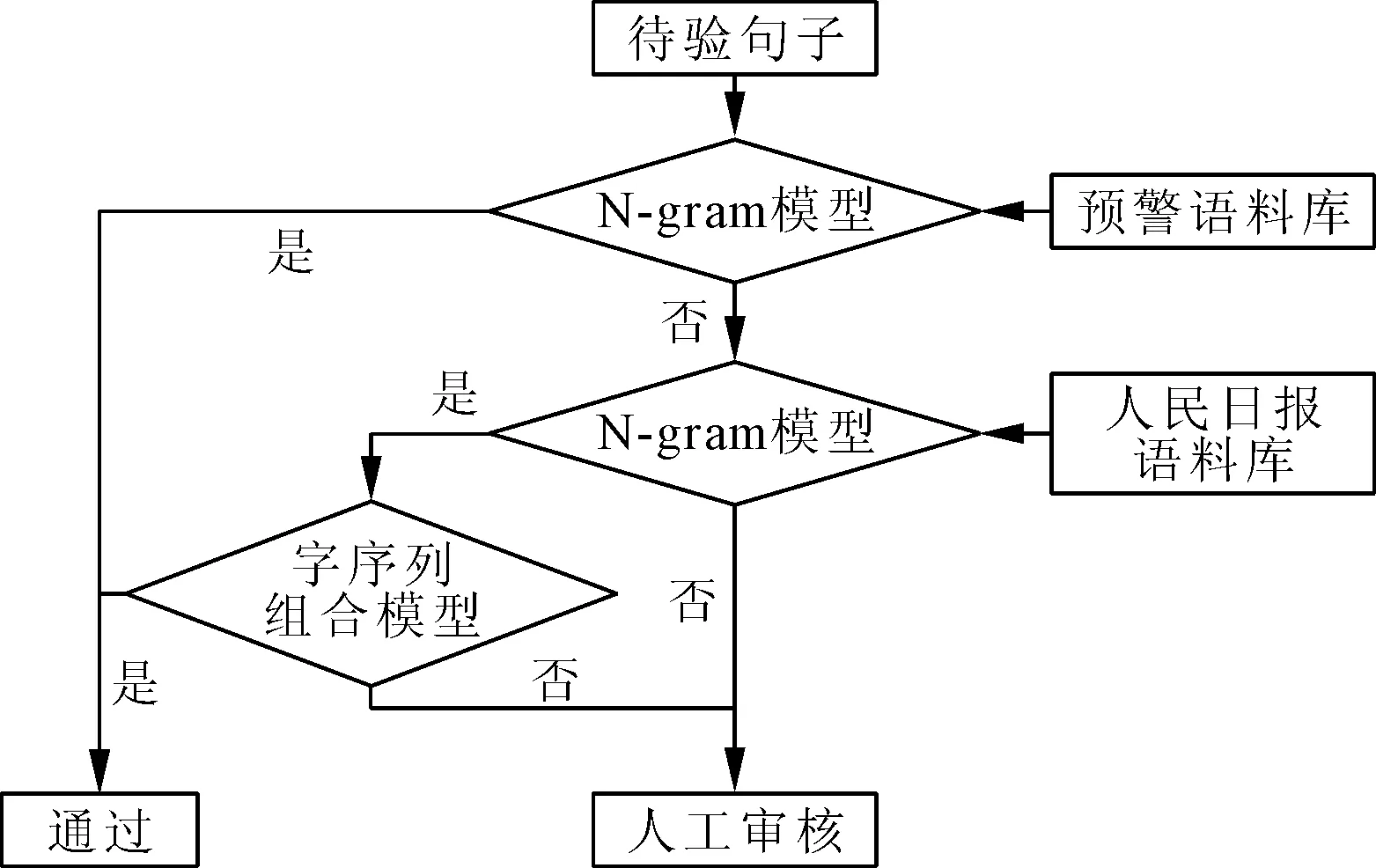
图4 多级检验模型流程图
多级检验模型检验结果如表5所示。
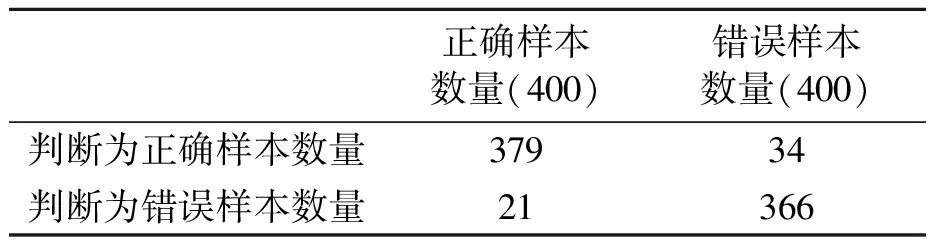
表5 多级检验模型检验结果
由表5结果可以得到模型检验的准确率=(379+366)/(400+400)=93.13%,漏警率=34/400=8.5%。多级检验模型整合了字序列组合检验模型和归一化N-gram检验模型的优势,大大提高了样本整体的准确率,降低了漏警率。
3 模型应用
使用JAVA语言将多级检验模型封装成API服务接口,嵌入国家突发事件预警信息监控系统中应用。接口示例:输入为预警描述文本;接口为http://127.0.0.1:5896/sentcheck?sentence=预警描述文本;返回值为正确(0);错误为质疑词的首字。
截止到2021年12月,共检测了34条语义错误类预警内容错误,占错误拦截总数的85.2%,大大提高了错误检出率,并减少了人为审核的工作量。当前模型所不能识别的错误类型,也在系统应用工作过程中做了积累和通过其他方式解决了业务应用中的实际问题。虽然多级检验模型的错误样本被误判断为正确的漏警率为8.5%,但在实际应用中暂未出现错误未被检测出来的情况。由于漏警率是在特定的人为制作的错误样本测试数据样本上的结果,模型应用的过程中,会进行自学习训练样本,进而改变模型精准度。多级检验模型在业务应用系统中,主要实现文本错误的定位和错误类型的提示,示例如图5所示。
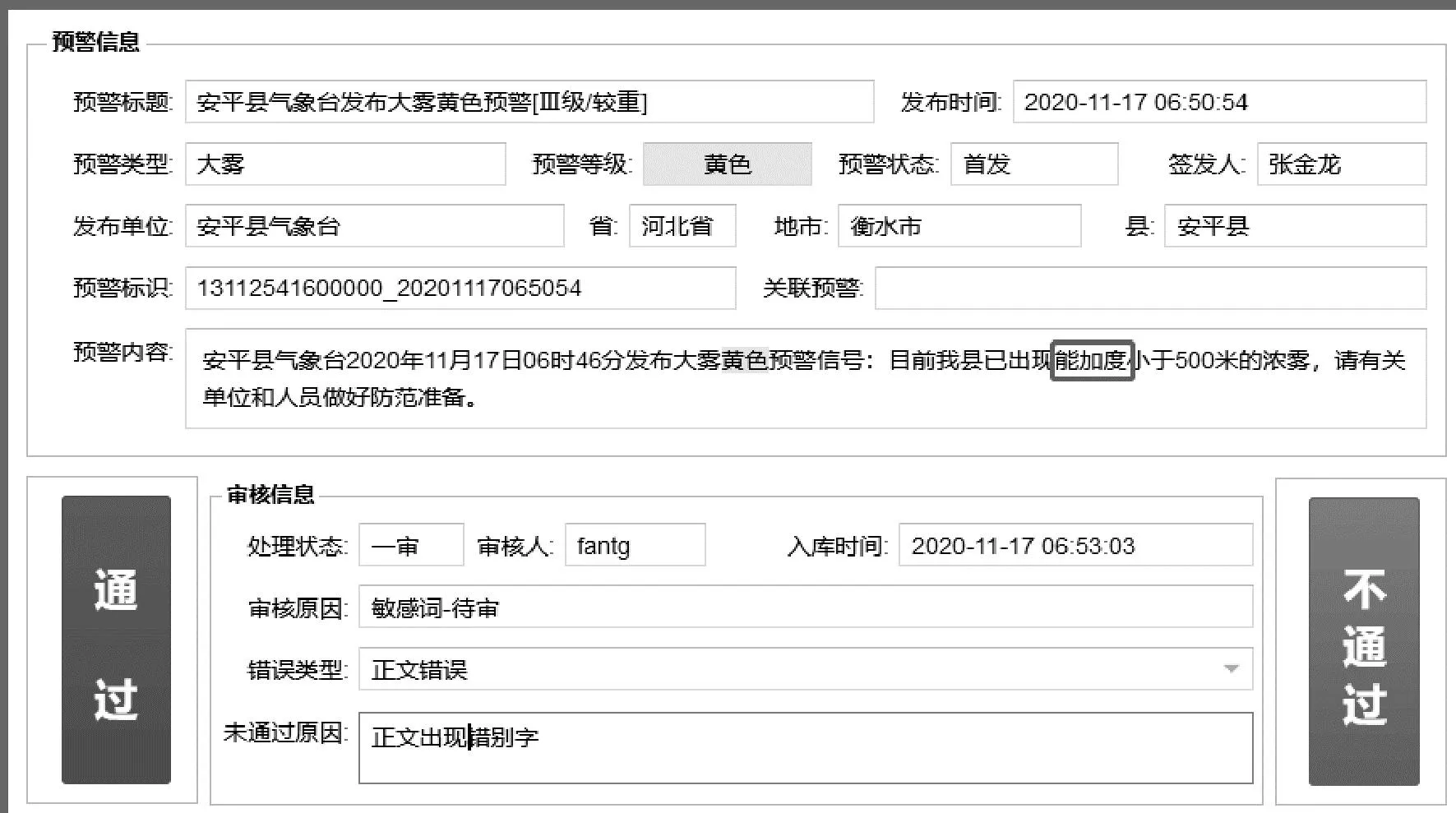
图5 国家突发事件预警信息监控系统提示错误信息
4 结论
(1)结合气象预警描述文本的特征分析,提出了一种多模式融合分词方法,并创建了预警专业语料库,建立了以归一化N-gram检验模型为主,以字序列组合检验模型为辅的多级检验模型。
(2)对比试验显示,多级检验模型的准确率有所提升,漏警率有所下降,在实际应用中取得了较好的效果。
(3)在应用中发现分词对预警专有语料库的依赖性高,当地名不在语料词库表中,如缩写词、分词会产生错误,从而导致检验失败。针对这个问题,未来将通过建立地名和缩写词之间的标签关系图谱的方式,继续优化分词方法的研究。
