基于GA-ANFIS-FCM算法的电力能源预测
2024-01-14朱元凯李长英谢清强
陈 亮 朱元凯 李长英 谢清强
(泰山职业技术学院,山东 泰安 271000)
1 引言
电力公司负责电力分配,提供不间断的电力供应,以满足企业、居民的需求。为实现该目标,需要准确地预测电力能源需求情况,以及预测需求波动幅度,并及时调整能源的生产和分配。精确的能源预测有助于电力供应者降低运营成本,维持经济高效的电力系统,从而提高经济效益。因此,预测能源使用量对提高供电系统的可靠性和效率至关重要。
2 文献综述
有关电力能耗预测的研究有很多。Jang Roger 于1993年开发了自适应神经模糊推理系统(ANFIS),并应用于风力发电方面[1]。ANFIS 融合了模糊逻辑和神经网络的优势,能够以更高的精度对复杂系统进行建模,但是ANFIS的预测精度时高时低[2]。沈兆轩等使用卷积神经网络对区域电力能耗进行预测,预测精度有所提高,但效率降低了[3]。王艳松等使用遗传算法GA对海上油田长期电力能耗进行了预测,精度达到了较高水平[4]。李玲玲等使用ISHO-ELM混合模型预测短期电力能耗,执行效率较高,但在长期预测上精度不足,也不太稳定[5]。Yodav 将ANFIS 与遗传算法(GA)相结合构建了具有长期性的混合电力预测模型,该模型虽然改进了预测的不稳定问题,但其精度没得到广泛认可[6]。
本文在Yodav 工作的基础上加入模糊C-均值聚类(FCM)算法,构造GA-ANFIS-FCM混合模型,并应用到电力能源预测上,同时与ANFIS模型进行比较。
3 数据收集
实验数据来自泰山区2022年1-12月的实际用电量数据集(数据非公开)。每个月份的数据由31条记录组成,每条记录有30天。数据集也包含了最高温度、最低温度、湿度、风速和露点等气候信息。耗电量是模型的最终输出,以MWh 为单位。数据的统计特性如表1 所示。数据集划分为训练集(70%)、测试集(15%)和验证集(15%)。

表1 输入数据的统计特性
4 提出算法
4.1 自适应神经模糊推理系统(ANFIS)
自适应神经模糊推理系统(ANFIS)是具有神经网络特性和模糊逻辑特性的神经网络,或者说它是自适应混合多层前馈神经网络[7]。ANFIS执行过程就是利用ANN和FIS的双重学习能力来模拟人类做出智能决策的过程。
4.2 模糊C-均值(FCM)聚类技术
使用FCM 进行聚类时,数据点可以属于具有不同隶属度的多个聚类,并非严格地分配给单个聚类。FCM根据数据点的相似性将数据点划分为聚类。每个对象在其所属聚类的隶属度值在0 至1 之间。FCM 聚类过程分3 步,首先随机设置聚类的中心,然后根据每个聚类中对象的成员关系反复调整,在所有对象成员关系值稳定之后,就得到了完整的聚类。FCM具有处理重叠和模糊数据的能力,因此在多个领域得到了广泛应用。将FCM 与ANFIS 结合有3 个优点:(1)FCM可用于确定ANFIS模型的初始参数;(2)FCM能为ANFIS 的模糊集分配初始隶属度和聚类中心,提高了学习过程的准确性和速度;(3)FCM具有澄清输入和输出变量之间联系的能力,增强了ANFIS模型的可解释性。通过将输入空间划分为模糊区域,FCM简化了与模型预测的输出结果最相关的输入变量的识别。
设X为数据集,X=(x1,x2,…,xn),xi=(xi1,xi2,…,xi6),xi1至xi6分别为最高温度、最低温度、湿度、风速、露点和耗电量,U为隶属度矩阵,Uij为第i个数据点属于第j个聚类的隶属度。公式1是用于计算数据点到第j个聚类中心的距离公式。
其中,m为加权指数且m≥1,为权重为m时的隶属度且∈(0,1),V=(v1,v2,…,vc)是聚类中心,c为聚类个数。公式2用于计算Uij。
4.3 遗传算法
遗传算法(GA)是一种基于搜索的算法,能够解决机器学习中出现的优化问题。遗传算法有选择、交叉和变异等算子,该算子有效解决遗传算法陷于部分最优问题[8]。GA有一个关键优势,不需要误差函数,因此,GA 适用于连续和离散优化问题。将GA与ANFIS结合,能够改进基于Sugeno模型的FIS隶属度函数的优化问题,提高预测精度,降低错误率。
将遗传算法、模糊C-均值聚类和自适应神经模糊推理系统结合在一起,形成GA-ANFIS-FCM混合算法。算法过程分为4步:(1)初始化和生成初始种群;(2)对每个种群成员的适应度进行评估,从种群中选择一对成员进行繁殖,并根据适应度进行排序;(3)将分离的种群个体和当前种群的子集整合到现有种群中,形成新的整体;(4)停止算法,调整ANFIS 参数。这个过程反复执行,直持续到达到预定的终点。图1是电力预测算法流程。

图1 电力预测算法流程
4.4 评估
性能指标用于评估模型预测的精度和准确性。通过将模型的输出与实际数据进行对比,可以评估ANFIS模型是否有效地反映输入和输出之间的潜在联系。通过使用统计性能指标,对多个模型进行比较,以确定哪一个模型在准确性和精确度方面表现更好。本文采用了部分常见的性能指标:平均绝对百分比误差(MAPE)、平均绝对误差(MAE)、均方根系数(CVRMSE)和均方根误差(RMSE)等。各指标描述如下:
其中,Y=(y1,y2,…,yN) 为实际用电量,为预测用电量,k是样本索引,是实际用电量的平均值。
5 实验分析
实现环境为Windows 10,inter(R)CPU@3.20 GHz,16 GB RAM。聚类算法采用的是FCM。实验过程分三步:(1)使用不同的聚类规模对每个模型进行试验,目的是评估不同聚类规模下模型的准确性,并确定产生最佳结果的聚类规模,试验的结果是适用不同聚类规模的不同子模型。(2)使用相同的框架评估子模型的性能,比较其准确性。(3)识别出精度最高的子模型,为每个模型选择最佳聚类数量。表3~5中的粗体表示最佳结果。表2是实验模型设置的参数。

表2 实验模型参数设置

表3 ANFIS-FCM子模型的结果
通过改变模型中聚类的数量来检验独立ANFIS-FCM模型的性能。ANFIS-FCM模型使用4个子模型进行评估,采用不同数量的聚类进行训练和测试。结果如表3所示。从表中发现,使用2 个聚类的ANFIS-FCM1 是测试阶段的最佳模型。统计指标MAPE、MAE、CVRMSE 和RMSE 的值分别为8.2698、754.4429、10.5766和1.0147e+03。最佳模型的准确率为91.7%(MAPE=8.2698),这表明观测到的用电量与预期用电量之间有很好的匹配。从表3中可看出,随着聚类数量从3 个增加到4 个,模型的准确性降低了。这表明,在ANFISFCM模型中使用更多的聚类并不一定会带来更好的准确性,而较小数量的聚类可能会产生更好的结果。
GA对ANFIS具有调整作用,如表4所示。在测试阶段,GA-ANFIS-FCM3 是最佳的子模型,统计指标MAPE、CVRMSE、RMSE 的值分别为7.6345、9.4913、918.6518,预测准确率为92.4%。这表明观测到的能源使用和预期能源消耗之间具有合理的可比性。从表4还可得到,具有5个簇的GA-ANFIS-FCM4具有更好的MAE值,即具有最好的总体最佳性能。
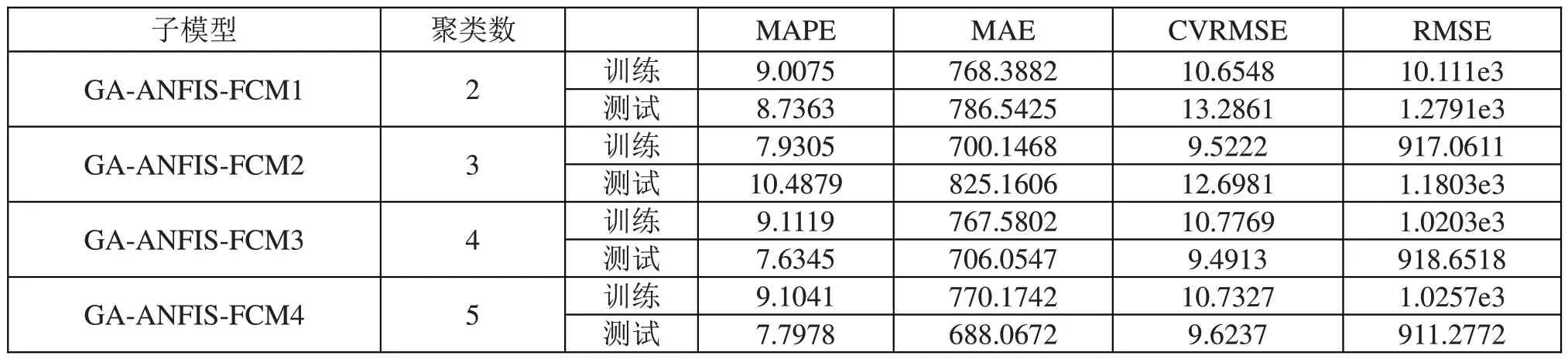
表4 GA-ANFIS-FCM子模型的结果
将最优ANFIS-FCM1 子模型和最优GA-ANFIS-FCM3子模型进行对比,如表5所示。GA-ANFIS-FCM3的性能在4 个统计指标的得分超过了ANFIS-FCM1,进一步说明了混合模型比独立预测模型有优势。

表5 两个最佳模型的比较
6 结语
电力能耗预测是电力系统有效管理的重要任务。准确的电力耗能预测有助于优化电力使用,降低成本,提高能源效率。本文将遗传算法(GA)、聚类算法(FCM)与自适应神经模糊推理系统(ANFIS)相结合,构建了混合模型(GAANFIS-FCM),将该模型应用到了电力能耗预测方面,并与独立的ANFIS-FCM模型进行了比较。实验结果表明,子模型GA-ANFIS-FCM3 为最佳的电力能耗预测模型。本文为GA-ANFIS-FCM混合模型在电力耗能方面的预测提供了有价值的参考,对加强能源管理和提高能源效率具有重要意义。
