基于MobileNetV2特征提取的自修复表情识别算法
2024-01-14刘忠旭
于 延 刘忠旭
(哈尔滨师范大学计算机科学与信息工程学院,黑龙江 哈尔滨 150025)
1 引言
人脸表情识别是计算机视觉技术中的热点问题,在众多领域得到广泛关注。对人脸图片的特征提取是表情识别技术中的关键,基于卷积神经网络的深度学习技术通过反向传播与误差优化对权值进行迭代优化,可以提取出人类预想不到的关键点和特征[1,2],是目前表情识别任务的主要研究方向。本研究在SCN[3]算法的基础上针对其特征提取,提出了一种改进的轻量级人脸表情识别算法MSCN,降低了模型的参数量和计算量,并且模型具有轻量级特征。
2 理论基础
2.1 SCN表情识别算法
实际中采集的大量人脸表情图片存在模糊、低质量和标注者主观性等因素的干扰,对大规模人脸表情数据集进行标注是相当困难的。为了克服这一困难Wang K.等人提出了一个简便且可行的算法即SCN,以抑制大规模人脸表情识别的不确定性。具体来说SCN由自注意重要性加权、排序正则化、噪声重标记3个模块组成。
(1)自注意重要性加权模块在给定一批图像的基础上,首先利用ReNet18[4]提取人脸特征。然后通过全连接层和sigmoid激活函数为每个图像分配一个重要性权重。这些权重乘以样本重加权方案的对数。捕捉样本对训练过程的重要贡献,对于确定性样本可以产生很大的重要性权重,但不确定性样本的重要性则较少。
(2)排序正则化模块首先对学习到的每张图片的重要性权重进行降序排序,然后按照β比例将图片分成两组,确保高重要性组的平均权重高于低重要性组的平均权重,同时定义了秩正则化损失函数。
(3)噪声重标记模块针对低重要性组中的样本,将最大预测概率与给定标签的概率进行大小比较。假设最大预测概率大于给定标签的预测概率,那么就为样本分配一个新的标签,否则不变。
2.2 MobileNetV2 卷积神经网络
MobileNetV2是由谷歌公司所开发的轻量级神经网络,它相较于MobileNetV1[5]版本,模型的参数量减少了20%,然而精度却超越了MobileNetV1,其主要创新包括:
(1)采用了深度可分离卷积取代普通卷积,减少了模型的计算量和参数量。
(2)提出利用反向残差结构增强网络层数加深和对特征的表达能力。
(3)通过线性瓶颈结构以减少对低维特征信息的损失。
2.3 CA注意力机制
注意力机制可以用来加强模型注意重点信息和位置,现已经被普遍应用于深度神经网络中以提高模型的性能。但是在网络大小被严格控制的轻量级网络中,对注意力机制的使用还是滞后的,因为大多数注意力机制的计算量开销是轻量级网络所承受不起的。考虑到轻量级神经网络有限的计算能力,Qibin Hou 等人提供了一个专门针对轻量级网络而开发的注意力机制CA(coordinate attention,CA),该机制将位置信息内嵌入到了通道注意力中,能够通过将其嵌入到卷积神经网络模块中实现端到端的训练,并且只需要少许的计算量。其基本功能设计如图3 中展示,每一个CA 模块都可被认为是一个计算模块,用以提升模型对信息的表达能力。CA利用精确的位置信息对通道关系的长期依赖性进行了编码,具体操作包括协调信息嵌入和协调注意生成2个阶段。深度可分离卷积其原理如图1所示。

图1 深度可分离卷积原理图
3 MSCN算法设计
本研究以搭建低消耗、高精度同时具有大规模数据集中人脸表情识别不确定性抑制的表情识别算法为目标,提出了一种轻量级的MSCN 人脸表情识别算法。以MobileNetV2为基础进行特征提取网络的改进。调整原始MobileNetV2网络层结构,在模型中嵌入CA 注意力机制来增强模型对重要特征的学习;通过增大深度可分离卷积中深度卷积(DW)卷积核为5×5 的方式增大卷积特征感受野;采用一个14×14的全局逐深度卷积(GDConv)代替MobileNetV2中的全局平均池化层,减少特征信息丢失;通过调整MobileNetV2 的通道因子α,在准确率可承受的范围内,进一步减小模型的参数量和计算量;改进后的网络结构如表1以及图2所示。

表1 改进后的特征提取网络结构表

图2 改进后的特征提取网络结构图
表1 中,t、c、n 和s 分别是MobileNetV2 中瓶颈结构进行升维的通道扩增系数、输出特征矩阵深度、bottleneck的循环次数和卷积核的步距。表中每个bottleneck模块如图3所示。
余三进野村谷是重阳节前后,气候已值深秋,白龙山万山红遍,层林皆染。而山谷与山上唱反调,满谷尽带黄金甲。密匝匝的银杏树林荫道上,飘落的银杏叶铺成一条黄金地毯,铺向山谷纵深地带。明黄的、暗黄的、深黄的、浅黄的,细辨又有金黄、谷黄、橙黄、鹅黄……之不同。黄得恣意放肆的银杏叶,在穿林阳光照射下,折射出精灵古怪的色泽,炫耀成令人迷醉的黄金世界幻象。
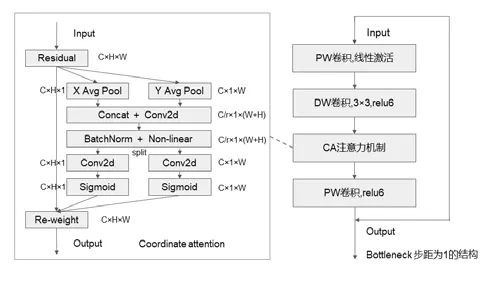
图3 改进后的网络bottleneck模块图
在人脸图片的特征提取中,一张图片不同像素点所提取的表情特征对表情分类的贡献是不同的,图像中眼睛或嘴角处的权重自然要比边缘出的作用大,使用全局平均池化将权重平均会降低模型性能,所以采用一个14×14的全局逐深度卷(GDConv)积代替全局平均池化层以实现提取特征图中不同位置具有不同重要程度的特征,使网络提取到的特征具有高度泛化性和全局性。全局逐深度卷积由MobileFaceNet[6]所提出,一个GDConv 层就是一个逐深度卷积。其kernel 大小等于输入的size,pad=0,stride=1。全局逐深度卷积层的输出如式1:
这里F是输入的特征矩阵,其大小为W×H×M;K是逐深度卷积核,其大小为W×H×M;G 是输出,其大小为1×1×M。其中在G的第m个通道上只有一个元素Gm。(i,j)表示F和K中的空间位置,m表示通道的索引。整个MSCN表情识别算法结构如图4所示。

图4 MSCN表情识别算法结构

图5 数据集实例图片

图6 ResNet18特征可视化
4 实验与结果
4.1 实验环境和数据集
本研究所作实验在一台中央处理器为11th Gen Intel(R)Core(TM)i5-11400H@2.70GHz 2.69 GHz,内存16GB,GPU为RTX3050 的计算机,操作系统为64 位Windows 11 家庭中文版,编程环境为Python3.10 深度学习框架为Pytorch。编译器为Pycharm 通过python 编程语言实现。训练总轮数epoch 设置为30,训练中的bitch size 设置为24。学习率设置为0.1。
RAF-DB为真实场景的人脸表情标准数据集,该数据集包含7 类基本情绪(惊讶、恐惧、厌恶、快乐、悲伤、愤怒、中立);在本实验中使用了这7 类基本情绪共15339 张图像,包括训练集12271张图像和测试集3068张图像。
FERPlus是从FER2013中拓展而来的人脸表情标准数据集,它由3589 张验证图片,3589 张测试图片和28709 张训练图片组成,它增加了轻蔑表情,因此该数据集有8个类别。图4 为数据集样本图像展示,第一行是RAF-DB 数据集样本图像,第二行为FERPlus数据集样本图像。
4.2 消融实验
为了研究各项改进对模型性能提升的帮助以及计算量和参数量的变化,将改进后的算法在RAF-DB数据集上进行消融实验。在不加预训练的情况下记录模型在测试集top1准确率。消融实验包括改变MobileNetV2的宽度因子模块、是否嵌入CA 注意力机制的瓶颈模块、是否用全局逐深度卷积(GDConv)代替全局平均池化层模块和是否改变DW卷积核的大小为5×5模块。消融实验结果如表2所示。

表2 消融实验结果
实验分别以宽度因子为0.5的情况下对3种因素进行消融对比实验。由表中结果可以看出宽度因子为0.5的本研究算法的精度、参数量和计算量分别为79.46%、177904 和90.18MFlops。相较于宽度因子为1 时,精度降低了1.19%,参数量减少了302308,计算量减少了134.98MFlops。表明本研究算法对降低模型的参数量计算量效果明显。
4.3 对比实验
4.3.1 与SCN对比实验
为了研究本文所提出的MSCN 算法在参数量、计算量和精度上的优势,将MSCN 与SCN 在数据集RAF-DB 和FERPlus 上进行对比实验,模型在没有预训练的情况下实验结果如表3所示。

表3 改进后的算法与SCN对比实验表
相较于SCN,改进后的算法在RAF-DB 和FERPlus 精度分别提高了7.81%和5.37%,参数量和计算量分别减少了11511608 和1731.21 MFlops,分别是原模型的1.52%和4.95%,参数量计算量得到了大幅缩减。
4.3.2 不确定性抑制评估
为了验证改进后的MSCN仍具有表情标签不确定性抑制的特点,对RAF-DB和FERPLus数据集各个类别的标签随机选取10%、20%和30%比例将其随机更改为其他类别,将改进后的算法与原SCN进行对比实验,结果如表4所示。

表4 不确定性对比实验表
由表4 改进后的MSCN 算法较原SCN 算法在带有10%、20%和30%不同比例的噪声标签下,在RADF-DB上精度分别提升了8.05%、6.11%、7.12%,在FERPlus 上精度分别提升了4.27%、3.9%、3.13%。证明MSCN表情识别算法具备对人脸表情数据集大规模不确定性的抑制效果及鲁棒性。
4.3.3 特征可视化分析
为了研究本文所提出MSCN算法对图像特征提取的程度和关键信息捕捉的能力,分别将改进的特诊提取模型与SCN算法中ResNet18网络模型所提取的浅层、中层、深层的特征图做特征可视化。证明改进的模型拥有更好的表征能力。如图所示,图中用于测试的人脸图像来自数据集RAF-DB。
图中第一列是测试原图,第一行是来自模型浅层的特征提取可视化,结果表明改进后的模型提取的表情纹理特征更加细致清晰,第二行是来自模型中层的特征提取可视化,结果表明CA注意力机制对表情眼关键位置的着重定位。第三行是来自模型深层的特征提取可视化,改进后的模型对图片语义信息的把控更加注重。
4.3.4 计算量参数量对比实验
为了证明该研究算法在保证高识别准确率的同时模型轻量化的优势,与经典网络模型AlexNet[7]、VGG16[8]以及其他轻量级网络Shufflenet[9]、EfficientNet[10]、MobileFaceNet 在RAF-DB数据集上进行对比实验结果如表5中给出。可以看出,本研究算法的参数量和计算量不仅低于其他轻量级网络,精度也高于其他网络模型。
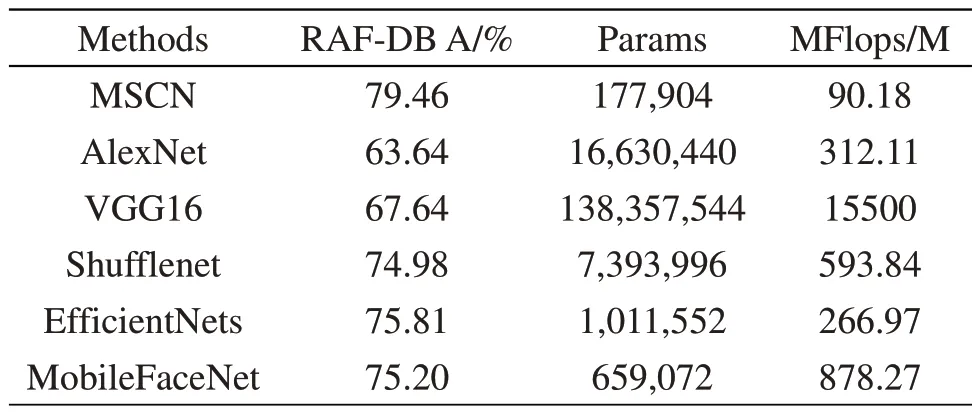
表5 不同模型在RAF-DB上的性能对比表
5 结语
本文基于MobileNetV2 中的深度可分离卷积,优化网络层结构,在瓶颈模块中引入CA混合注意力机制,并使用了全局逐深度卷积(GDConv)代替全局平均池化层,增大深度可分离卷积中深度卷积核大小,调整MobileNetV2 的宽度因子,构建出改进的MobileNetV2来做SCN表情识别的特征提取网络。RAF-DB和FERPlus数据集上的实验结果验证了所提方法的可行性和优越性。在没有预训练的前提下所提方法在识别上的正确率为79.46%和81.65%高于原SCN 算法,且参数量和计算量仅为177904 和90.18 MFlops 得到了大幅度降低,对比其他方法具有明显优势。
