基于多头注意力机制字词联合的中文命名实体识别
2024-01-13王猛旗张昕跃孙开伟朴昌浩
王 进, 王猛旗, 张昕跃, 孙开伟, 朴昌浩
(重庆邮电大学 数据工程与可视计算重点实验室, 重庆 400065)
命名实体识别(named entity recognition, NER)是自然语言处理领域的一项基础性工作,是信息检索、关系抽取、 问答系统等任务的子任务.其任务包含从非结构化文本中识别出诸如人名、地名、组织名、日期、时间、特定的数字形式等内容,并为之添加相应的标注信息.已有很多方法来解决NER问题,包括隐式马尔可夫模型、最大熵模型、支持向量机、条件随机场等等.随着深度学习的发展,由于循环神经网络(recurrent neural network, RNN)在处理序列问题上的优势,很多基于RNN以及RNN变体的模型被提出来,以解决NER问题,例如LSTM、S-LSTM[1]、ON-LSTM[2]等.
由于中文文本不具有天然词汇分割的特性,与英文NER任务相比,中文NER任务具有实体组成复杂、实体边界不确定以及实体嵌套等问题[3].因此,中文NER任务的常见做法是首先使用现有的中文分词系统(Chinese word segmentation, CWS)对文本进行分词,然后使用序列标注模型对分词结果进行标注.然而,CWS系统不可避免地会造成实体错误分割,导致实体边界检测和实体类别打标错误.为了避免实体分割错误引入误差干扰,大多数中文NER模型都是基于字符的.针对中文NER任务,研究[4-6]表明基于字符的方法要显著优于基于词汇的方法.
中文文本中的词汇可以为NER模型提供丰富的实体边界信息.尽管基于字符的方法已经取得了良好的性能,但它并没有很好地利用文本中的词汇信息.基于此,近年来一些基于字词联合的方法被提出来,例如Lattice-LSTM[7]、LR-CNN[8]、WC-LSTM[9]、SoftLexicon[10]等.相较于单纯基于字的模型,基于字词联合的方法都取得了不同程度的性能提升.这些方法的共同点是将字词匹配得到的所有词汇融入字嵌入的表征中,让模型学习所有匹配词信息.然而,这些方法都存在引入冗余词汇以及词汇信息利用不充分的问题.Lattice-LSTM[7]模型对LSTM序列建模层进行了动态修改,降低了模型的并行能力,并且词汇中间字符并不能显式的利用词汇信息.LR-CNN[8]模型受到卷积神经网络(convolutional neural network, CNN)感受野的限制,得到的特征序列可能损失长距离依赖[11].WC-LSTM[9]与SoftLexicon[10]采用不同的策略在字符表示层将全量词汇信息融入字符嵌入中,不影响模型的并行能力,但WC-LSTM模型缺少对词汇位置信息的表达,SoftLexicon字符融合方法使得模型降低了对强相关词汇的选择能力(难以区分冗余词汇).
文中拟提出一种高效的字词联合算法,在使用全量匹配词的同时,提高模型对关键词汇的选择能力.具体地,将字词匹配得到的全量词集按字在词中的位置分为B(begin)、I(inside)、E(end)共3类,然后采用注意力机制将B、I、E词集分别融入字符嵌入中,最后通过Fusion层融合3种字符嵌入,达到融合并选择词汇位置信息的目的.为了避免设计复杂的序列建模结构,文中算法的改动集中在嵌入层,方便与现有的NER模型结合.
1 相关工作
1.1 字词联合
字词联合又称词汇增强,作用是使单纯基于字的中文NER算法能够更有效地利用词汇信息,提高模型识别实体边界、解决实体嵌套问题的能力.
目前主要有基于词汇列表、基于多源分词器2种字词联合方式.前者需要额外的词汇列表以及预训练的字词嵌入,后者需要多个分词器共同协作[12].具体地,基于词汇列表的字词联合方式又分为Dynamic和Adaptive这2种框架.前者通过设计一种动态抽取框架兼容词汇输入,如文献[13-15]所述,这种方式往往需要修改模型的结构或采用新的网络结构汇聚词汇信息.后者通过构建自适应的embedding,将词汇信息在embedding阶段融入字嵌入中,与模型结构无关.
由于基于Adaptive框架模型能够达到与基于Dynamic框架模型相同的性能,并且模型结构更简单,易于和现有的NER模型相结合,成为研究热点.
1.2 多头注意力机制
通过引入注意力机制动态获取需要关注部分的信息,使得任务处理系统能够更有效地获得输入数据与当前输出数据之间的有用信息,提升模型动态结构输出质量[16].注意力机制可以看成是一个组合函数,通过计算注意力的概率分布,突出某个关键输入对输出的影响.
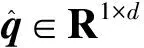
(1)
(2)
多头注意力机制首先被Transformer模型[17]使用.图1给出了多头注意力机制模型.
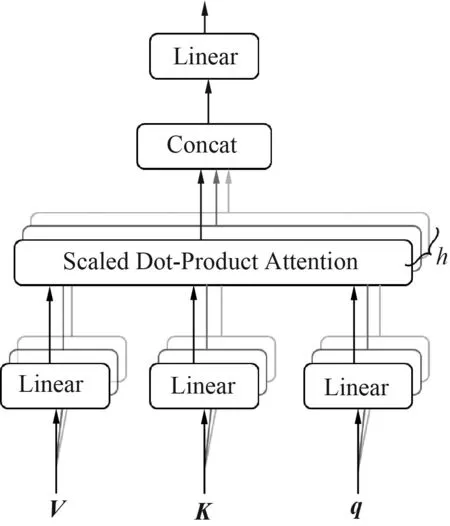
图1 多头注意力机制模型
如图1所示,首先对原始的q、K、V做多次线性映射,将映射的结果输入到缩放点积注意力中,每次得到的结果称为头.多头注意力计算式为
(3)
(4)
式中:h为头的个数.
2 多头注意力字词联合模型
2.1 整体框架
文中针对如何高效地在字嵌入表征中融入词汇信息,提出了一种基于多头注意力机制字词联合的中文命名实体识别算法,其整体框架如图2所示.相较于传统基于字的中文NER算法,如BiLSTM+CRF,文中算法的改动主要集中在嵌入层.首先,通过字词匹配得到全量匹配词集,并根据字词位置关系将词集分为B、I、E共3类.然后,采用多头注意力机制将B、I、E词汇位置信息分别融入每个字的字嵌入中,并通过Fusion层将多位置信息进行融合.最后将词汇增强后的字嵌入输入到序列建模层和CRF层,得到预测结果.图2中,输入序列为“重庆市长江大桥”,模型预测结果应包含2个位置实体,即重庆市和长江大桥.
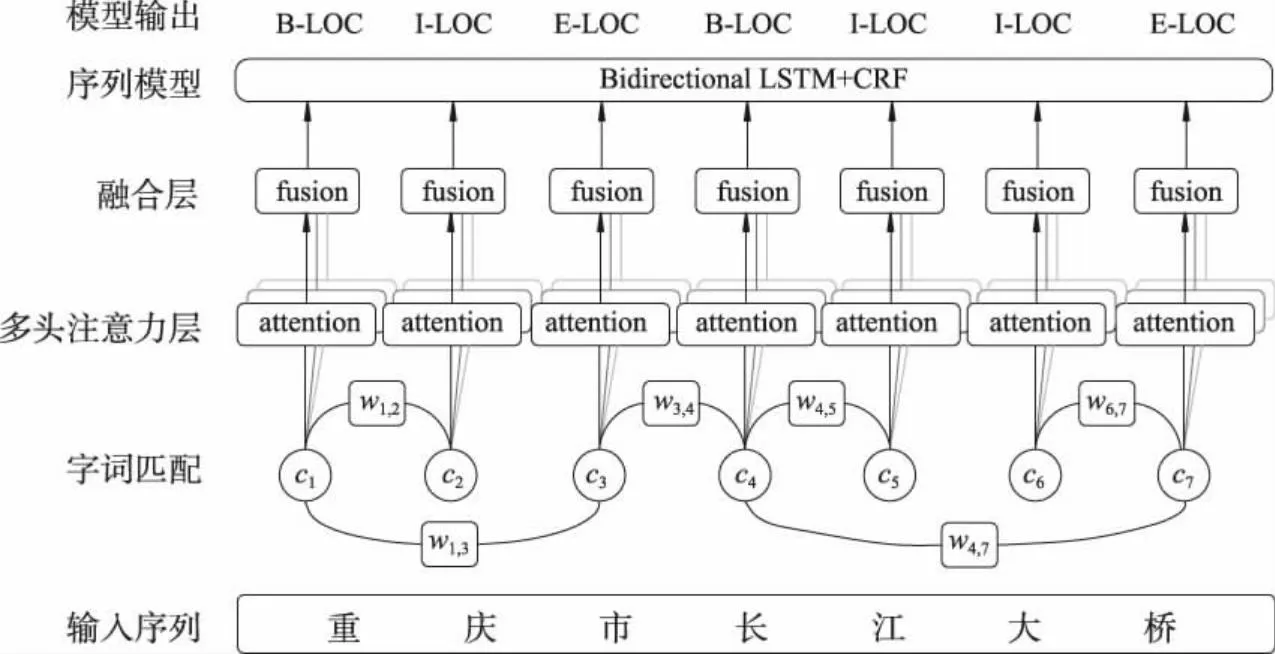
图2 多头注意力字词联合模型整体框架
2.2 原始字嵌入
在中文NER模型中,输入的文本序列可表示为
S={ci|ci∈Vc,i=1,2,…,n},
(5)
式中:Vc表示字符表.通过字符嵌入查找表ec可将字符ci映射为原始字嵌入:
(6)
另外,字+双字的嵌入结构能够为字嵌入提供方向信息,特别是对于不使用词汇信息的方法[18-19].因此,通常使用二元嵌入来增强字嵌入表征:
(7)
式中:eb为二元字符嵌入查找表.
2.3 原始词嵌入
单纯基于字的中文NER模型的问题在于无法有效利用词汇信息.特别地,对于中文NER模型,词汇的边界信息、字与词的位置关系信息尤为重要,据此,如何有效利用这些信息是文中需要解决的问题.
首先,对输入的中文文本序列S进行字词匹配,得到全量匹配词集Lw,匹配词wi,j可表示为
wi,j={ci,ci+1,…,cj}∈Lw.
(8)
通过词嵌入查找表ew可将匹配词wi,j映射为词嵌入:
(9)
其次,为了降低未登录词(out of vocabulary, OOV)的影响,文中将通过分词得到的词集Mw作为全量词集Lw的补充.通过这种方式可以缓解人名、地名等专有名词在通用语料中出现频率较低且构词方式无固定规律带来的无匹配词问题.对于词集Mw中的词汇wi,j∉Lw,采用加权融合字嵌入的方式表征原始词嵌入:
(10)
2.4 多头注意力机制模块
根据字在词中的不同位置,将序列中字的相关词集分为B、I、E共3个集合.对于序列中的字ci,其B、I、E词集可表示为
(11)
对于字ci,将其B、I、E词集分别输入多头注意力模块,得到融合后的字嵌入:
(12)
特别地,由于单个字最多只属于一个实体,采用多头注意力机制分别学习B、I、E词汇位置信息,可以提高模型选择关键词汇的能力,降低冗余词汇信息的影响.
2.5 Fusion层
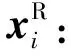
(13)
式中:W1、W2、W3、W4为参数矩阵.B、I、E可以充分表达字与词的相对位置信息,通过融合,可以在字嵌入中融合不同维度的位置信息,提高模型选择不同位置词汇的能力.
2.6 序列建模层
得到B、I、E字词联合的字嵌入表征后,将字嵌入表征输入到序列建模层学习字符之间的依赖关系.序列建模层通用的框架包括双向长短期记忆网络[20](bi-directional long short-term memory network,BiLSTM)、 卷积神经网络和Transformer[17].文中选择使用经典的BiLSTM网络作为序列建模层.BiLSTM包含前向LSTM与后向LSTM共2部分,其中前向LSTM网络定义为
(14)
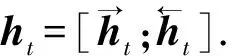
2.7 解码模块
为了捕捉连续标签之间的依赖关系,文中采用标准的CRF层对序列进行打标.给出中文文本序列S,基于输入序列Hs={h1,h2,…,hn}计算分数矩阵O:
O=WoHs+bo,
(15)
式中:Wo和bo为计算分数矩阵的参数.标注序列y={y1,y2,…,yn}的概率为
(16)
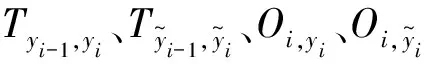
解码时,文中使用Viterbi算法找出得分最高的标签序列:
(17)
在模型训练过程中,给定N个训练数据(Sj,yj),j=1,2,…,N,文中采用最大化预测值和真实值带L2正则化的对数似然作为优化目标:
(18)
式中:λ为L2正则化的参数;Θ为参数集合.
3 试 验
本节采用4个对比算法,在3个数据集上进行对比试验来验证文中算法的有效性,并通过消融试验检验本算法融合词汇信息的能力.
3.1 数据集与对比算法
文中采用单纯基于字的中文NER算法Char-based BiLSTM以及基于字词联合的中文NER算法Lattice-LSTM[7]、LR-CNN[8]、SoftLexicon LSTM[10],在3个公开的中文序列标注数据集MSRA、Weibo[20]、Resume[7]上进行对比试验.表1中统计了数据集中的句子、字符等信息.
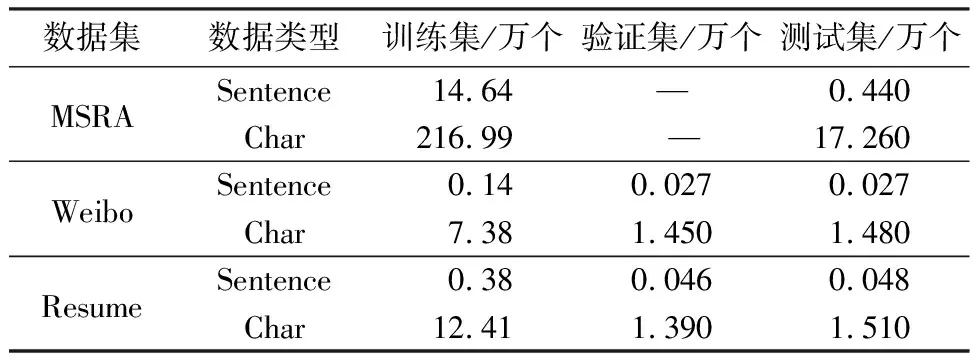
表1 数据集统计信息
MSRA数据集来自新闻领域,共包含14个实体标签,分为NR(人名)、NS(地名)、NT(团体机构实体)等3种实体类型.Weibo数据集来自社交媒体领域,共包含28个实体标签,分为PER(人名)、ORG(组织名)、LOC(地名)、GPE(地缘政治实体)等4种实体类型.Resume数据集来自新浪财经的中文简历数据,共包含28个实体标签,分为CONT(国家/地区实体)、EDU(教育机构实体)、LOC、PER、ORG、PRO(专业实体)、RACE(种族/背景实体)、TITLE(职位名称)等8种实体类型.
3.2 试验设置
文中使用与Lattice-LSTM相同的词典以及字、词嵌入列表:字典共包含0.57万个单字词汇,29.15万个双字词汇,27.81万个三字词汇和12.91万个其他长度的词汇;字、词嵌入列表由word2vec[21]算法在Chinese Giga-Word数据集上训练得到.
文中将字嵌入大小和词嵌入大小都设置为50.对于没有出现在预训练字嵌入列表中的字,文中采用均匀分布初始化,范围表示为
(19)
式中:dim表示字嵌入的维度.对于没有出现在预训练词嵌入列表中的词,采用加权融合字嵌入的方式进行初始化.
对于MSRA数据集,单向LSTM隐藏层状态维度设为200维,其他数据集设为150维.文中在嵌入层和LSTM网络中使用dropout[22]技术避免过拟合,其中dropout值设为0.5.Weibo数据集初始化学习率为0.005 0,其他数据集初始化学习率为0.001 5,采用Adamax[23]优化器优化模型参数.
文中选用召回率R、精确率P、以及F1值作为评价指标.R为被预测正确的正例占实际总正例样本的比例:
(20)
P为预测结果中为正例的样本占预测为正例的比例:
(21)
式中:TP表示预测为正例且实际为正例的样本个数;FP表示预测为正例且实际为负例的样本个数;FN表示预测为负例且实际为正例的样本个数.F1值为精确率和召回率的调和均值,用来衡量分类的精确度:
(22)
3.3 试验结果与分析
文中采用单层BiLSTM 模型作为序列编码层.表2-4展示了本算法与对比算法的试验结果,并使用粗体表示最优结果,其中+bichar表示采用字+双字嵌入结构表征原始字嵌入.表3中,指标F1NE、F1NM、F1Overall分别表示命名实体、名义实体和两者合并后的F1值.
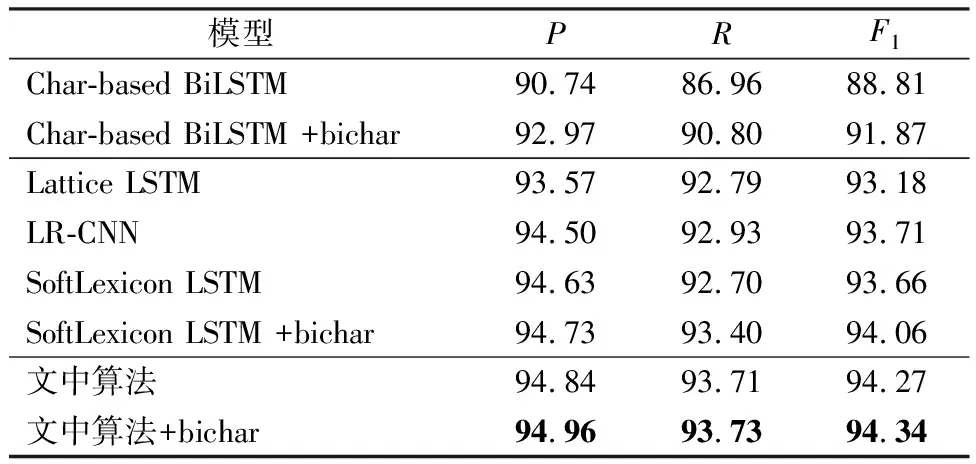
表2 不同模型在MSRA数据集上的性能指标
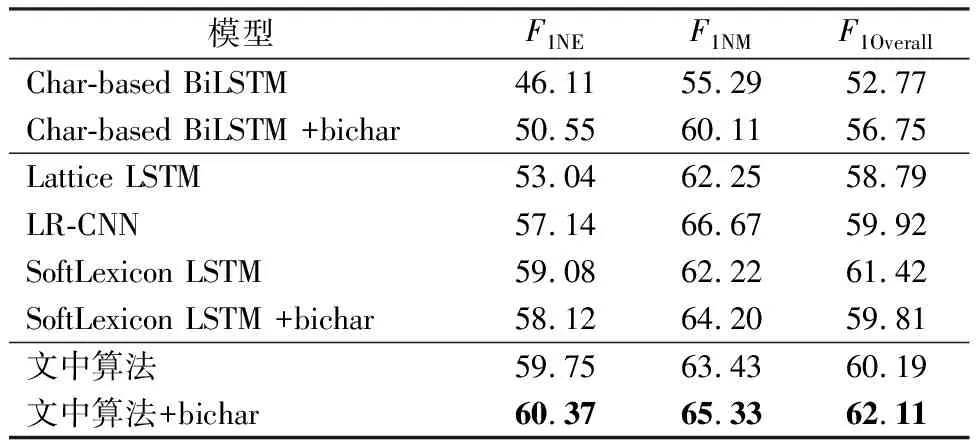
表3 不同模型在Weibo数据集上的性能指标
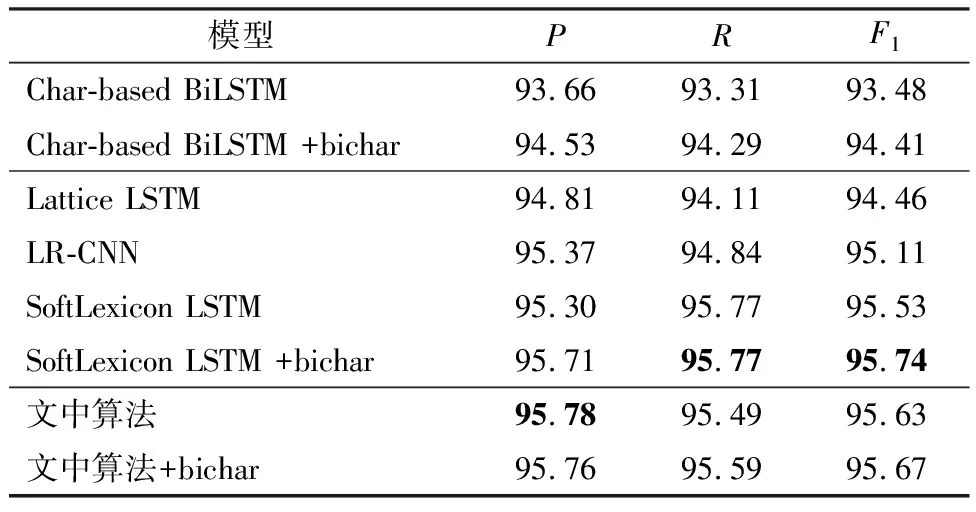
表4 不同模型在Resume数据集上的性能指标
从表2-4可见,在所有数据集上,文中算法的性能指标明显优于Char-based BiLSTM算法、Lattice LSTM算法和LR-CNN算法.由表2-3可见,文中算法在MSRA和Weibo数据集上F1值分别提升0.28、0.69;由表4可见,文中算法在Resume数据集上精确率提升0.07.
对于所有对比算法,在MSRA、Weibo数据集上,本算法取得了最优的性能.在Resume数据集上,本算法性能稍次于最优的SoftLexicon LSTM算法,F1值仅相差0.07.说明文中算法能够较为有效地利用词汇信息.
为了验证本模型各个部分的贡献,文中在上述3个数据集上进行了消融试验.试验结果见图3.
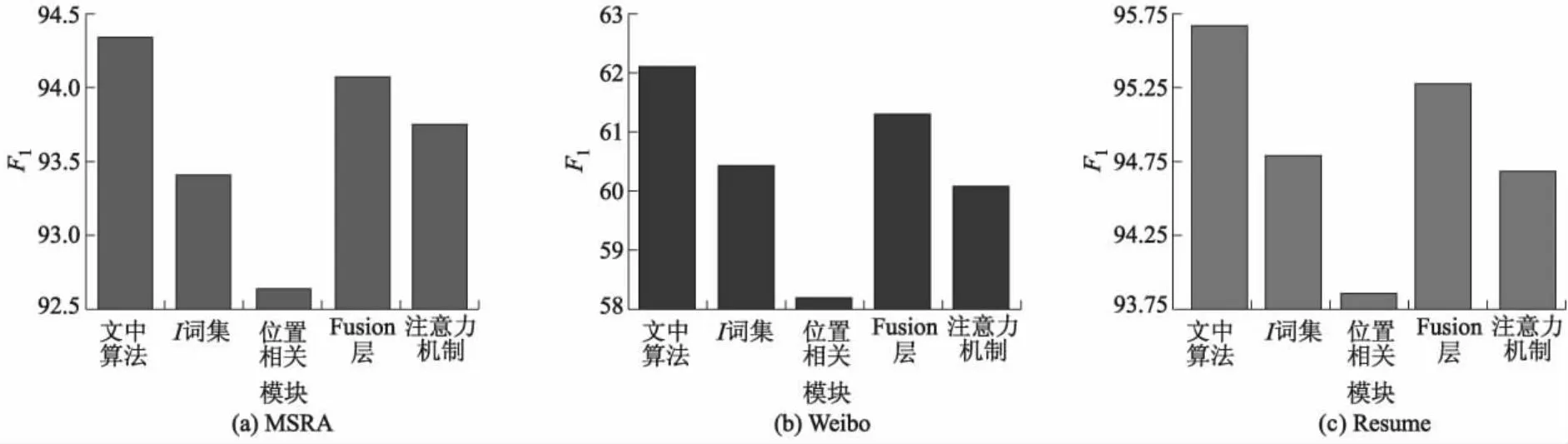
图3 模型不同部分对3个数据集F1值影响对比
在Lattice LSTM模型中,词汇信息只会显式地融入以词汇开头和结尾的字符中,位于词汇中间的字符并不能显式地利用到词汇信息.为了验证词集I的作用,文中只保留词集B、E,并进行试验.从图3中可看出,向词汇中间的字符融入词汇信息能够提高模型性能.并且通过分析预测结果发现,向词汇中间字符融入词汇信息能够提升模型处理实体嵌套问题的能力.
在文中的模型中根据字与词的位置关系,将字相关词集分为B、I、E共3种,为了研究此设计的贡献,本节不区分位置关系,将B、I、E词集合并,并进行试验.如图3所示,性能的大幅下降证明了字词相对位置信息的重要性,也说明文中算法能够有效地融合词汇位置信息.
与直接采用字嵌入加权融合不同,文中采用Fusion层融合原始字嵌入与B、I、E位置字嵌入.本节通过采用加权融合的方式进行消融试验,结果表明Fusion层能够有效地融合不同类型的字嵌入表征.
为了验证多头注意力机制的贡献,采用Softword融合方式替换注意力模块.Softword融合公式如下:
(23)
若单个词集中有多个词汇,采用将词嵌入加权融合后与原始字嵌入拼接.并且本节也验证了不同注意力头数对性能的影响,结果见图4,其中横轴0表示不使用注意力机制.
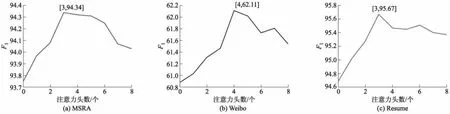
图4 不同注意力头数在3个数据集上的F1值对比
从图4可见,注意力机制能够有效地获得输入数据与当前的输出数据之间的有用信息,提高字词联合的性能.
4 结 论
文中基于在字嵌入中融入词汇信息的思路,提出了一种基于多头注意力机制字词联合的中文命名实体识别算法.在3个不同领域的中文数据集上的试验结果表明,文中算法能够高效地融合词汇信息,尤其是词汇位置信息,提高中文命名实体识别的性能.文中算法在MSRA和Weibo数据集上F1值分别提升0.28、0.69,在Resume数据集上精确率提升0.07.
