基于多任务学习与层叠 Transformer 的多模态情感分析模型
2024-01-13陈巧红孙佳锦漏杨波方志坚
陈巧红,孙佳锦,漏杨波,方志坚
(浙江理工大学 计算机科学与技术学院,浙江 杭州 310018)
多模态情感分析是新兴的深度学习技术,不仅应用于视频的情感极性识别,也是用户行为分析、对话生成的基础.作为文本情感分析的延伸,数据源不仅有文本模态,还包含音频与视觉模态,同一数据段中的不同模态往往相互补充,为语义和情感消歧提供额外的线索[1].任何话语的每个模态都包含着独特的信息[2],这些独特的信息可能与其他模态信息相互冲突,并被认为是噪声,但它们在预测情感极性方面可能是有用的.多模态情感分析现存两大挑战:1)如何模拟人类接受多模态信息的过程,对模态内特征进行有效建模,以便保留模态的异质性,并尽可能筛除噪声;2)在跨模态建模时,能够有效地集成异构数据,提取并整合有意义的信息.
多模态融合方式主要分为3 种:早期融合[3]、后期融合[4]与中期融合[5].早期融合是在模型的初期通过特征拼接融合不同模态的特征.后期融合为每个模态建立单独的模型,再使用多数投票或加权平均方法将输出集成.中期融合将不同模态的数据先转化为高维特征表达,再于模型的中间层进行融合.根据输入模态的特征是否按时间步对齐,多模态融合又分为时序融合与非时序融合.时序融合模型根据时间对不同模态进行连续建模,须先将不同模态特征对齐,再按时序依次融合每个时间步的特征.Wang 等[6]通过时序融合,将每个时间步的文本特征作为主模态,将音频和视觉特征作为辅助模态对词表征进行动态调整,再将调整后的特征序列输入长短时记忆(LSTM)网络.在非时序融合研究方面,Zadeh 等[7]提出基于张量融合的方法,将经过时序网络提取的单模态特征,使用笛卡尔积进行融合.Yu 等[8]通过创建多标签数据集SIMS,并在情感分析中利用多任务学习来指导单模态特征提取,后续Yu 等[9]又提出SELF-MM,通过自监督学习策略生成伪单模态标签来适应传统单标签数据集.Tsai 等[10]分别将不同模态特征输入Transformer 的编码器结构,实现非对齐特征的注意力交互.其他方法(如图胶囊网络)也被提出并取得了良好的效果[11-13].
上述模型只利用多模态整体情感标签,且整体采用三元对称结构[14],轮流对3 个模态中的每对模态进行建模,平等的计算每个模态对最终情感的贡献.在情感交流的过程中,不同模态所携带的信息量不同,文本模态是多模态情感的主要载体,音频和视觉信息起辅助作用.本研究提出层叠跨模态Transformer 结构,将文本模态作为目标模态,并将音频模态与视觉模态依次与文本模态融合,通过模拟人类接受多模态信息的过程来平衡不同模态的情感贡献;引入多任务学习与门控机制,根据模态异质性调整跨模态特征融合,更有效地集成异构数据,提取并整合有意义的信息;通过Gradnorm 与子任务动态权重衰减来调优多任务损失,指导单模态异质性特征提取.
1 基于多任务学习和层叠Transformer的多模态情感分析模型
1.1 算法架构
本研究算法架构如图1 所示,该框架共分为4 个步骤:单模态特征提取、跨模态特征融合、情感预测和多任务损失调优.1)将给定视频片段作为输入,分别使用 BERT[15]、LibROSA[16]、openface2.0[17]提取文本特征XT、音频特征XA与视觉特征XV.2)采用LSTM[18]网络作为单模态特征提取的基础框架,对于不同模态的初始特征,分别通过对应模态的单向LSTM 网络,将特征映射到同一维度,令每一时间步特征能感知当前特征的上下文.通过将最终时间步特征输入前馈层得到单模态预测,并在训练阶段与真实标签计算分类损失,引导时序特征的提取,以保证输出的特征能在过滤噪声的同时最大程度保存模态异质性.3)通过跨模态特征融合模块,将3 个模态的特征依次输入层叠的跨模态Transformer 网络得到融合特征,并将对应模态的高级语义特征间的相似度作为Transformer 残差连接的门控,指导模态间的注意力交互.4)将融合特征通过特征补充后输入前馈层,得到情感预测.
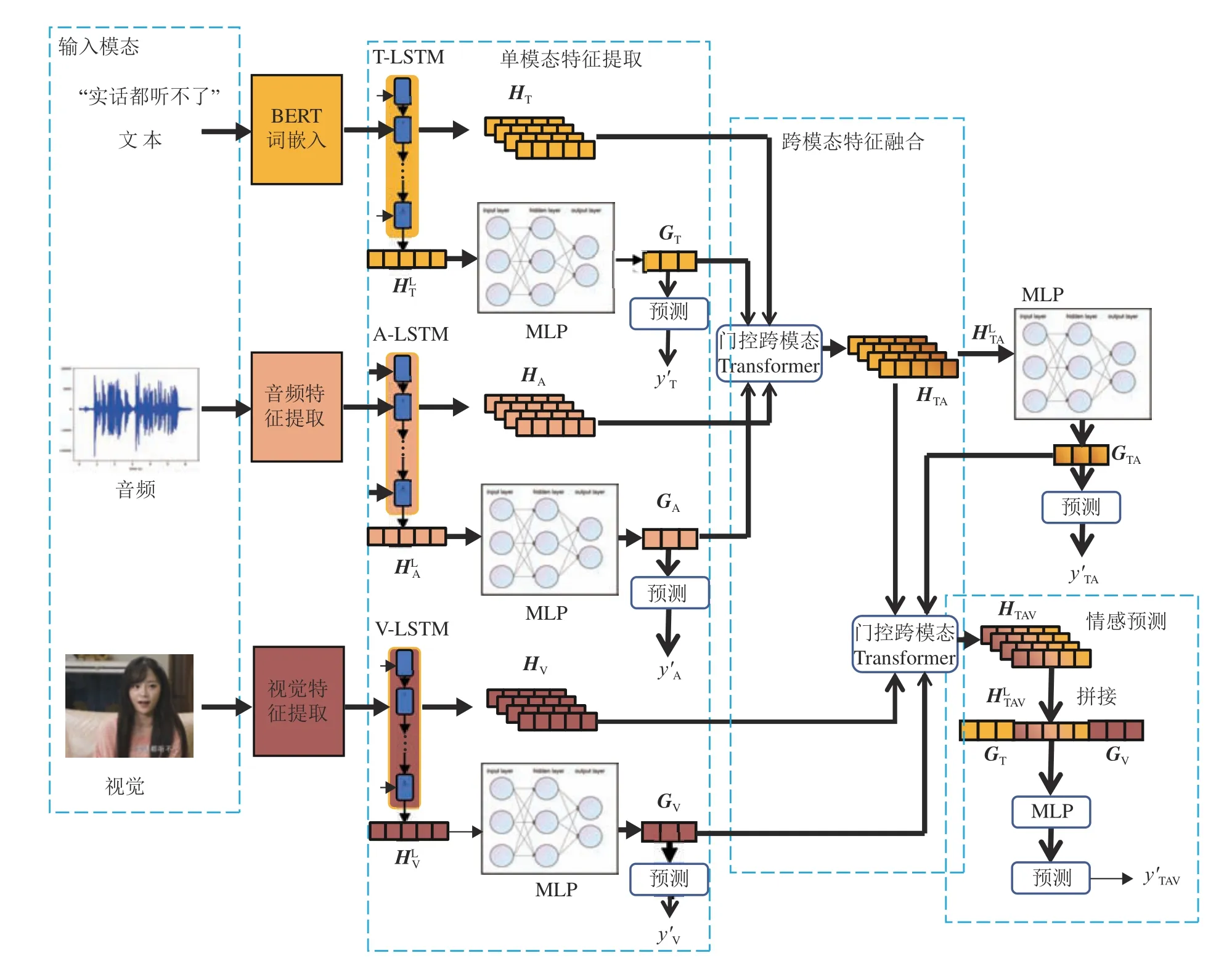
图1 基于多任务学习和层叠Transformer 的多模态情感分析模型结构图Fig.1 Structure of multimodal sentiment analysis model based on multi-task learning and stacked cross-modal Transformer
1.2 单模态特征提取模块
单模态特征提取模块旨在从初始特征序列中学习模态内表示.本研究使用LSTM 网络对原始输入特征进行提取,即
式中:Xm∈Rlm×dm为 模态m的原始输入特征,l表示特征序列的长度,d表示特征维度,模态分别标记为文本T、音频A、视觉V;Hm∈Rlm×dh为模态m经过LSTM 网络提取后的隐藏层特征,LTSMm为使用单向LSTM 网络对模态m进行特征提取.不同模态的LSTM 特征提取网络的输入维度不同,因此本研究将各个LSTM 网络的隐藏层维度统一为dh,以适应之后的跨模态特征融合.Hm被用作跨模态特征融合模块的输入,将Hm的末尾时间序列特征HmL通过多层感知机(MLP)得到高级语义特征Gm,作为跨模态特征融合模块的门控输入来指导跨模态特征融合,即
以往的模型采用CNN、GRU 或者LSTM 提取不同子模态内部特征,由于这类模型只以多模态整体情感标签为训练目标,在训练过程中,为了筛除原始特征中的噪声,模型会将对跨模态特征融合至关重要的单模态异质性特征一并筛除,只保留模态中的共性特征.受Yu 等[8]启发,本研究引入多任务学习机制,以保留单模态特征的异质性,通过将Gm输入至前馈层得到单模态分类结果,并在训练时结合真实标签计算交叉熵损失,以指导LSTM 网络提取单模态特征,使模型在有效表征单模态情感的基础上进行特征融合,进而识别多模态整体情感,计算式为
式中:f()为前馈层,D为图文评论样本总数,N为情感类别数,ym,i为第i个视频片段对m模态的真实情感分值,为预测情感分值,为第i个视频片段对模态m预测为第k类情感的概率.ym,i,k为指示变量,若与真实样本类别相同,则ym,i,k为1,不同则为0.式(3)表示将高级语义特征Gm通过前馈层得到情感预测,式(4)用于分类任务计算损失值,式(5)用于回归任务计算损失值.
1.3 跨模态特征融合模块
在大脑识别多模态信息的过程中,听觉器官反馈给大脑的是经过融合后的文本与音频特征,之后该特征再与视觉器官接收的特征进行交互[19].基于这点启发,本研究提出层叠Transformer结构,将文本特征与音频特征先进行跨模态Transformer 融合,得到语言特征后,再将语言特征与视觉特征进行融合.
跨模态特征融合模块由跨模态Transformer 堆叠组成,跨模态Transformer 的原理是利用多头自注意力机制[20],通过将目标模态的查询值与辅助模态的键值进行相似度对比,在低层特征级别增强目标模态特征.此前的MULT 模型[10]通过跨模态Transformer 将文本、音频和视觉特征进行两两组合后,再将得到的6 组经过注意力机制增强的融合特征进行拼接,作为3 个模态的融合特征,如图2 所示.这种融合方式,本质上只是对2 个模态进行注意力增强,融合程度不足,且当模态扩充到更高维数时,该融合方式的参数量与训练时间都会呈指数级上升.本研究所提模块通过堆叠跨模态Transformer,将文本特征依次与音频、视觉特征融合,可以有效解决上述缺陷.此外,本研究在跨模态Transformer 中加入各模态的高级语义特征Gm,通过比较2 个模态高级语义特征的余弦相似度sα,β,作为Transformer 残差连接的门控,以指导目标模态接受或拒绝辅助模态的引导.

图2 2 种融合结构的对比Fig.2 Comparison of two fusion architecture
对于从单模态特征提取子网中得到的序列特征HT、HA、HV与 高 级 语 义 特 征GT、GA、GV,先 将HT、HA、GT、GA输 入至 跨 模态Transformer 网络,得到经过音频特征加强的文本特征HTA,融合了音频特征的模式更接近语言.将HTA的尾部特征输入前馈层,得到高级语义特征GTA,作为下一次跨模态Transformer 的门控输入.为了能让模型保留语言特征的异质性,将GTA通过前馈层,得到语言情感分类结果,并在训练阶段计算与真实标签的交叉熵损失,指导本层的跨模态融合.将HTA、HV、GTA、GV输 入 跨 模 态 门 控Transformer网络,得到多模态情感特征HTAV.跨模态门控Transformer 如图3 所示.对于 主 模 态 α 与辅助模态β , T ransformerβ→α表 示 将 模 态 β 对 模 态 α 做 引 导 注意 力, T ransformerβ→α中 包 含n层 跨 模 态 注 意 力块,向每层跨模态注意力块输入目标模态、Hβ,经过层归一化和映射后得到Query、Key 和Value,表达式分别为


图3 跨模态门控Transformer 结构图Fig.3 Structure of cross-modal gated Transformer
Transformer 为了强化目标模态的特征信息,通过残差连接的方式使原目标模态Hα得到辅助模态的补充.传统的Transformer 是针对单模态与自注意力机制设计的,其目标模态与辅助模态的来源相同.跨模态Transformer 与传统Transformer不同,当目标模态与辅助模态的差异性过大,导致难以有效融合时,应该降低辅助模态对目标模态的影响与干扰;当目标模态与辅助模态的差异性较小时,应该增强跨模态融合的强度.本研究在跨模态Transformer 的残差连接中加入门控机制,通过将目标模态与辅助模态对应的高层特征进行余弦相似度对比,得到相似度sα,β作为残差连接的门控,指导跨模态Transformer融合,得到本层跨模态融合特征,作为下一Transformer层的目标模态输入,计算式为

1.4 情感预测
在情感预测前,再将不同模态的高层特征整合,以提高模型的稳健性.取出经过音频、视觉特征引导的文本特征HTAV的尾部特征,将文本高层特征GT、视觉高层特征GV,与拼接,再输入前馈层得到分类结果,计算过程式为
特征整合时没有拼接音频高层特征与语言高层特征,原因是音频伪标签与真实标签存在差异,虽然能指导音频特征的提取,但音频特征高层特征的可信度不高,经过实验证明,将音频特征加入拼接会降低多模态情感预测的性能.此外,语言高层特征与文本高层特征GT、经过引导的文本尾部特征存在较多冗余,将它们补充至整合特征的意义不大.
1.5 多任务损失调优
在训练阶段,将不同模态的损失值加权求和,得到损失函数,即
式中:wm为不同模态m损失占总体损失的权重,模态分别标记为文本T、音频A、视觉V、文本融合音频TA 和多模态M.在训练过程中发现,不同子任务的收敛速度与损失值体量不同,这将导致任务的不平衡进而阻碍模型的训练.这种阻碍体现在反向传播时参数的梯度不平衡,为此基于Gradnorm[21]自适应平衡多个任务之间的损失权重,计算过程式为

子任务对总体情感的训练起辅助作用,随着训练的推进,子任务在多任务损失函数中的占比应该逐渐降低,因此每经过一轮训练,计算所有子任务的学习完成率并衰减它的权值,新增权值cm调整子任务权重,计算过程式为
式中:cm为任务m的完成度系数;pm为任务m在该轮测试集中的准确率,pm越大,训练完成度越高,对应的完成度系数越小.式(24)表示总损失值由每个子任务的损失与cm、wm相乘得到,式(25)表示cm与pm间的数量关系.
2 实验及结果分析
2.1 数据集与评价指标介绍
数据集CMU-MOSEI[22]的23 000 多段对话提取自某视频网站的1 000 多条视频,标记每段对话的情感极性值范围为[-3, 3].SIMS[8]是针对中文多模态情感分析的数据集,相比如MOSI[23]与MOSEI 的单标签数据集,SIMS 额外提供文本、音频与视觉单模态标签,本研究的完整模型依赖于该数据集提供的细粒度单模态标签.该数据集为从60 个原始视频中提取的2 281 个视频片段,令标记者在仅接受单一模态输入的情况下给出该模态的情感得分.实验过程中数据集分别按60%、20%和20%的比例划分为训练集、测试集和验证集.
为了公平地评估模型性能,在2 个数据集上分别执行回归和分类任务.回归任务的指标包括平均绝对误差MAE 和皮尔逊相关系数Corr,分类任务将二分类准确率A c c 2,三分类准确率Acc3 和F1 值作为评价指标.
2.2 实验细节与参数设置
本研究模型在Nvidia 3090GPU 上进行进行训练,操作系统为Windows 10,使用python3.8 为编程语言,深度学习框架为pytorch1.2.0,完整实验参数设置如表1 所示.

表1 所提模型在2 个数据集上的实验参数设置Tab.1 Experimental parameter settings of proposed model in two datasets
2.3 基准模型
为了验证所提出的模型,选择性能优异、代码开源且复现后性能与原文接近的6 个模型进行对比.1)TFN[7]:张量融合网络通过对提取的单模态特征进行交替的笛卡儿积,得到多维张量,以对模态内与模态间动态进行建模,M_TFN[8]:TFN 的多任务版本.2)LMF[24]:TFN 的改进版本,通过使用特定模态因子进行低秩多模态融合来产生多模态输出表示,使用多模态表示来生成预测任务,M_LMF[8]为LMF 的多任务版本.3)MFN[25]:通过提取不同子模态的相邻时序特征,实现特点视图与跨视图的交互,通过特殊的注意力机制构造多视图门控记忆模块,以增加模型的可解释性.4)MISA[26]:结合包括分布相似性、正交损失、重构损失和任务预测损失在内的损失组合来学习模态不变和模态特定表示,通过将每个模态投射到模态共性(modality-invariant)与模态特性(modalityspecific)2 个不同的子空间,以保存模态特征的异质性与统一性.5)MULT[10]:利用跨模态Transformer,将辅助模态融入目标模态,得到多组跨模态融合特征后,再通过特征拼接进行整合.6)CMFIB[27]:从信息瓶颈理论出发,通过互信息估计器的互信息估计模块,优化多模态表示向量与真实标签之间的互信息下界,获得具有较好预测能力的多模态表示向量.
2.4 结果对比分析
本研究所提模型和基准模型在2 个数据集上的实验结果如表2、3 所示, 其中,T为训练时间,N为参数量.在MOSEI 与SIMS 数据集上的结果显示,MTSA 在去除多任务标签的辅助后,性能依然能高于传统模型TFN、MFN,且与MULT 这类基于跨模态Transformer 结构的模型相比,性能仍有提升.虽然MTSA 在MOSEI 数据集上略低于MISA 与CMFIB,但在SIMS 数据集上,MTSA通过多任务机制利用数据集中额外的单模态精细标签,相比CMFIB、MISA 有了较大的性能提升,说明MTSA 对不同数据集的泛化能力更强;此外,MTSA 对比多任务框架M_TFN 与M_LMF也有明显的提升,这些结果初步证明了MTSA 在多模态情感分析中的有效性.在模型参数量、训练时间与计算速度方面,MTSA 的指标明显低于MFN、MISA 与CMFIB 这些性能较优但构造比较复杂的模型.与MULT 相比,层叠的跨模态融合结构相比三元对称的跨模态融合结构能够显著减少参数冗余并加快模型的训练与运算速度.
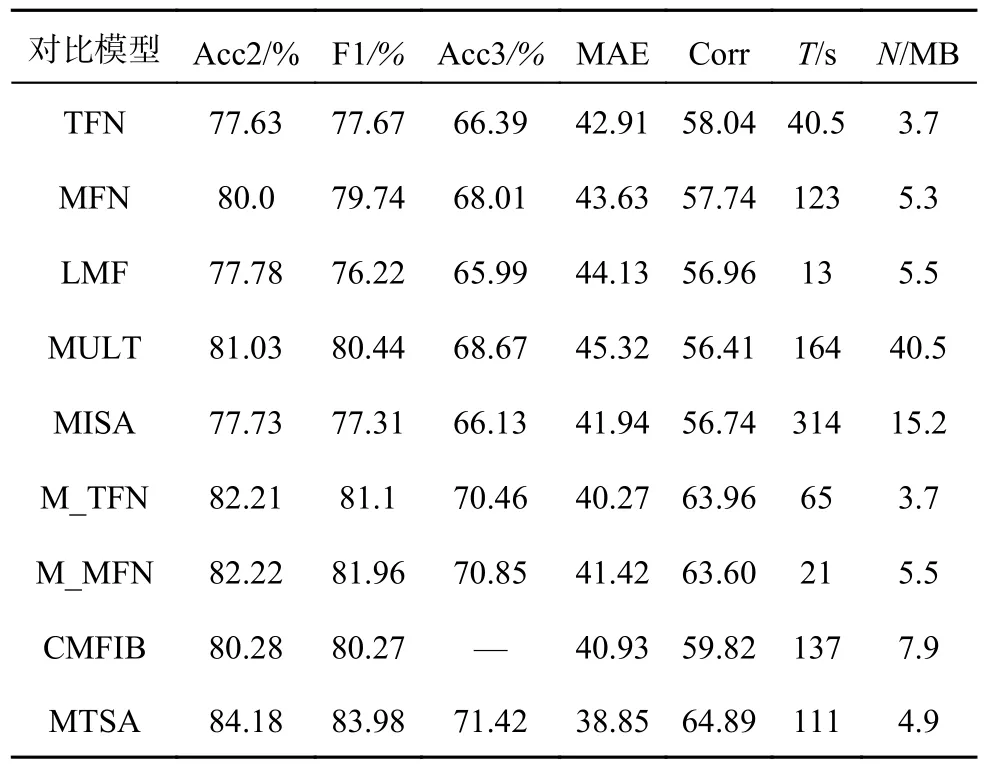
表2 SIMS 数据集上不同模型的性能对比结果Tab.2 Performance comparison of results with different models in SIMS dataset

表3 MOSEI 数据集上不同模型的性能对比结果Tab.3 Performance comparison of results with different models in MOSEI dataset
2.5 消融实验
将MTSA 与4 种模型变体进行消融实验.1)MTSA+WA:在MTSA 模型的基础上,添加自适应权重调整,通过Gradnorm 实现多任务损失调优,并根据子任务的学习完成率衰减该任务的权值.2)MTSA-G:在MTSA 模型的基础上,删去跨模态门控模块,不再根据2 个模态高层特征的相似度改变跨模态Transformer 残差连接系数.3) MTSAGMT:在MTSA-G 的基础上,仅使用整体任务标签进行训练,不再将单任务损失值加入总损失值.4) MTSA-SMT:在MTSA-GMT 的基础上,将层叠Transformer 结构修改为三元对称的并行Transformer结构,再将融合后的6 组Transformer 头部特征进行拼接后输入多层感知机,得到情感分类.
消融实验在SIMS 数据集上进行,采用准确率、F1 值、MAE 与Corr 作为评估指标,实验结果如表4 所示.实验结果显示,MTSA+WA 的实验效果最好,缺少不同模块会对实验结果造成不同影响.MTSA-G 相比MTSA 省去了跨模态相似度门控模块,其总体性能略低于MTSA-G,这是由于通过将2 个模态高层特征的余弦相似度作为跨模态融合时残差连接的门控,可以更好地融合不同模态的特征.MTSA+WA 与MTSA 的消融实验结果表明,对多任务损失函数进行动态调优能有效提高模型的性能.此外,MTSA-SMT 未采用层叠的Transformer 结构,而是将3 个输入模态两两组合,进行跨模态Transformer,并将得到的6 组双模态融合特征拼接,因此MTSA-SMT 的参数量与运算时间都远高于MTSA-SMT 的,在SIMS 数据集上,MTSA-GMT 的性能明显高于MTSA-SMT,进一步说明层叠Transformer 结构的优越性.MTSA-G 与MTSA-GMT 的实验结果表明,通过利用单模态特征标签指导多任务学习,能够有效提升模型对单模态异质性的保留能力,进而提高多模态情感分析性能.

表4 所提模型在SIMS 数据集上的消融实验结果Tab.4 Results of ablation experiments of proposed model in SIMS dataset
为了进一步探讨不同层叠顺序与主辅模态的选择对多模态情感分析的影响,分别以文本、音频、视觉作为主模态,并按不同的层叠顺序依次将剩余模态作为辅助模态进行跨模态融合,消融实验结果如表5 所示.可以看出,以文本为主模态进行跨模态融合的模型比以音频或视觉为主模态的模型在实验中取得的效果好,证明文字在多模态情感分析中是作为支点的.此外,文本模态先与音频模态进行融合,再与视觉模态融合的顺序,其性能优于其他层叠融合顺序的性能,这可能是这种融合方式与人脑识别多模态情感的过程更接近导致的.

表5 SIMS 数据集上的模态融合顺序实验结果Tab.5 Results of mode fusion sequence in SIMS dataset
2.6 样例分析
如表6 所示,为了体现MTSA 的泛化性能与其对单模态情感预测的准确率,从SIMS 数据集中选取典型样例进行模型测试.表中分别列出每个实例的文本、音频、视觉信息,原视频编号,MTSA 对不同模态的情感预测结果以及不同模态的真实情感标签.可以看出,本研究所提模型能够有效提取文本、音频和视觉等单模态信息,在能够识别单模态情感的基础上,进一步实施跨模态融合,识别多模态整体情感.

表6 所提模型在SIMS 数据集的样例分析Tab.6 Sample analysis of proposed model in SIMS dataset
3 结 语
本研究提出的MTSA 在多模态情感分析任务中有较好的性能.MTSA 利用LSTM 与多任务学习在一定程度上解决单模态特征异质性难以提取的问题,通过累加辅助模态任务损失避免了模型在训练过程中单模态特征坍缩;将各模态的高级语义特征的相似度计算,作为门控指导跨模态特征融合;通过层叠Transformer 结构进行特征融合,提升融合深度并避免融合特征冗余.MTSA在2 个数据集上的对比实验结果显示了模型的有效性;消融实验和定性分析证明了MTSA 的性能.由于SIMS 数据集中受试者提供的音频标签并不准确,通过计算偏移量的方式模拟纯音频标签不足.在之后的工作中将继续研究如何更好地提取各模态的特征,尤其是音频和视觉模态,更有效地融合模态信息.
