基于单阶段生成对抗网络的文本生成图像方法
2024-01-13杨冰那巍向学勤
杨冰,那巍,向学勤
(1.杭州电子科技大学 计算机学院,浙江 杭州 310018;2.杭州电子科技大学 浙江省脑机协同智能重点实验室,浙江 杭州 310018;3.杭州灵伴科技有限公司,浙江 杭州 311121)
文本生成图像是根据给定英文句子生成符合句子语义的图像.文本生成图像的方法大多基于生成对抗网络(generative adversarial networks,GAN)[1].生成对抗网络也用于图像恢复[2]、图像增强和图像补全等领域.
文本生成图像任务需要先对文本进行编码,再根据编码生成图像.如果仅使用单个句子提取的文本编码,可能会遗漏一些关键的细节描述,无法提供足够的语义信息来帮助生成对抗网络生成细节丰富的图像.在AttnGAN[3]中,引入单词信息来帮助生成器生成图像的不同子区域,通过使用更多的文本信息来更好地表示文本语义,帮助生成器生成高质量图像.ManiGAN[4]的网络结构与AttnGAN 类似,该模型能够挖掘单词信息实现图像编辑功能.DF-GAN[5]通过串联多个文本图像融合块,将句子信息有效地融入图像特征.DF-GAN在只使用句子信息的情况下,生成图像的质量远远超过AttnGAN 生成图像的质量,证明AttnGAN使用直接拼接的方式融合图像特征和单词信息并不能实现文本信息和视觉特征的深度融合.在生成图像的过程中,合理地利用文本信息,使得文本信息能够更充分有效地融合进图像特征之中,是决定生成图像视觉真实性并且符合文本语义的关键因素.因此,尽可能提供更多文本信息表示文本语义和把文本信息有效融入图像特征,是文本生成图像任务的2 个关键因素.本研究提出在DF-GAN 中的文本图像融合块中合理的添加单词信息,在充分挖掘文本语义的同时,使单词信息能够有效地融入图像特征.对比学习已经在计算机视觉许多领域得到广泛应用,例如图像转换[6].为了进一步促使生成图像和文本在潜在语义上保持一致,本研究将对比损失应用在真实图像与生成图像之间,减小相同语义图像对之间的距离,增大不同语义图像对之间的距离.通过使生成图像更“像”真实图像的方式,促进生成图像符合文本语义.为了更好使生成器根据给定文本动态地生成图像,本研究引入动态卷积.由于不同语义文本对应的图像有很大差异,有必要根据输入文本动态生成图像.动态卷积可以根据融入语义后的图像特征动态地调整多个卷积核的权重,使生成器间接的根据输入的文本信息动态地生成图像,进而提高生成图像的质量.
本研究在DF-GAN 基础上提出3 点改进,总结如下:1)引入单词信息,使生成器能够根据单词信息生成图像的子区域,使生成图像具有更丰富的细节.2)加入对比损失,使给定文本和生成图像在潜在语义上更加一致.3)生成器采用动态卷积,在只增加少量的计算成本的情况下,强化生成器的表达能力,使生成对抗网络更快收敛.
1 相关工作
1.1 基于生成对抗网络的文本生成图像
Reed 等[7]以GAN 为基础框架,将字符信息转换为像素信息,根据字符文本生成合理的图像.为了获得更高分辨率的图像,Zhang 等[8]提出StackGAN,使用堆叠结构把直接生成高分辨率图像的复杂过程进行分解.第1 阶段生成64×64 低分辨率图像,第2 阶段在第1 阶段生成图像的基础上添加细节,生成具有视觉真实性的256×256高分辨率图像.在AttnGAN 中单词信息用来帮助生成器生成合理的图像,注意力机制关注与子区域最相关的单词来帮助生成器生成图像的不同子区域,实现了图像的细粒度生成.相比于AttnGAN平等地“看待”句子中所有单词,SE-GAN[9]抑制了视觉影响较小的单词(例如the、is),只关注对视觉影响较大的关键词,提高了生成器的训练效率.后续基于GAN 的文本生成图像模型很多都延续了这种堆叠结构,即包含多个生成器和多个判别器.
在DF-GAN 提出之前,文本生成图像的网络结构大多采用类似StackGAN 堆叠式结构.Tao 等[5]指出,堆叠式结构存在多个生成器,导致生成器之间存在纠缠,使得堆叠式架构为主干的网络生成的图像像是不同图像区域的简单组合.DF-GAN以简单的单阶段文本生成图像主干,可以直接生成高分辨率图像,解决了生成器之间的纠缠问题,使得生成图像更加自然.SSA-GAN[10]在DF-GAN的基础上通过弱监督的方式使文本信息只影响生成图像中与文本相关的区域.RAT-GAN[11]使用递归神经网络连接DF-GAN 所有的融合块,降低了网络训练的难度.以上基于单阶段主干的文本生成图像方法都只使用句子信息,没有在图像生成的过程中融入细粒度的单词信息.
基于DF-GAN 和AttnGAN 的优点,本研究使用单阶段文本生成图像主干,合理地融入单词信息,进一步提高生成图像质量.将扩散模型 (diffusion model)[12]应用于文本生成图像任务,取得了一系列显著的效果,但扩散模型存在如训练时间长、训练代价高昂的问题.因此,研究如何利用生成对抗网络实现文本生成图像,具有十分重要的现实意义.
1.2 跨模态训练优化
文本生成图像任务是跨模态任务,并且文本信息和图像信息存在巨大差异,生成的图像既要保证视觉真实性,还要确保文本和图像在潜在语义上一致是困难的.之前的工作通过一系列措施对文本生成图像这个跨模态任务进行优化,如MirrorGAN[13]将生成图像重新编码为文本描述,文本语义重建损失被用来约束生成图像符合文本语义.S D-G A N[14]通过暹罗结构(S i a m e s e structure)生成同语义对应2 个不同文本表达的图像,并在2 个批量的生成图像之间添加对比损失,使生成图像更加符合文本语义.Ye 等[15]使用相同结构,并将更有效的NT-Xent[16]作为对比损失加入AttnGAN 和DMGAN[17]中,获得了更符合文本语义的图像.Zhang 等[18]利用对比损失捕获模态间和模态内的对应关系,效果显著.本研究将对比损失应用在所提网络结构中,并测试将对比损失应用在不同的对象上带来的效果,合理的选择作用对象来促进文本和生成图像在潜在语义上一致.
相比于普通的卷积操作,动态卷积[19]非线性地聚合不同卷积核,使得动态卷积具有比普通卷积更强的表现能力.由于动态卷积在分类任务中的应用效果较好,本研究尝试将它应用到生成模型中,优化跨模态训练.
2 基于单阶段生成对抗网络的文本生成图像方法
本研究提出方法的模型框架如图1 所示.模型整体遵循DF-GAN 单阶段结构并进行以下改进.1)在前3 个上采样文本融合块的第2 个融合块中改进仿射变换,使它具有融入单词信息的能力,使图像特征的子区域融入与当前子区域最相关的单词信息;2)添加对比损失,通过减小对应图像对之间的距离,增大不同图像对之间的距离,提高文本与生成图像之间的语义一致性;3)将生成器中的普通卷积替换为动态卷积,根据输入图像特征动态地聚合多个卷积核.
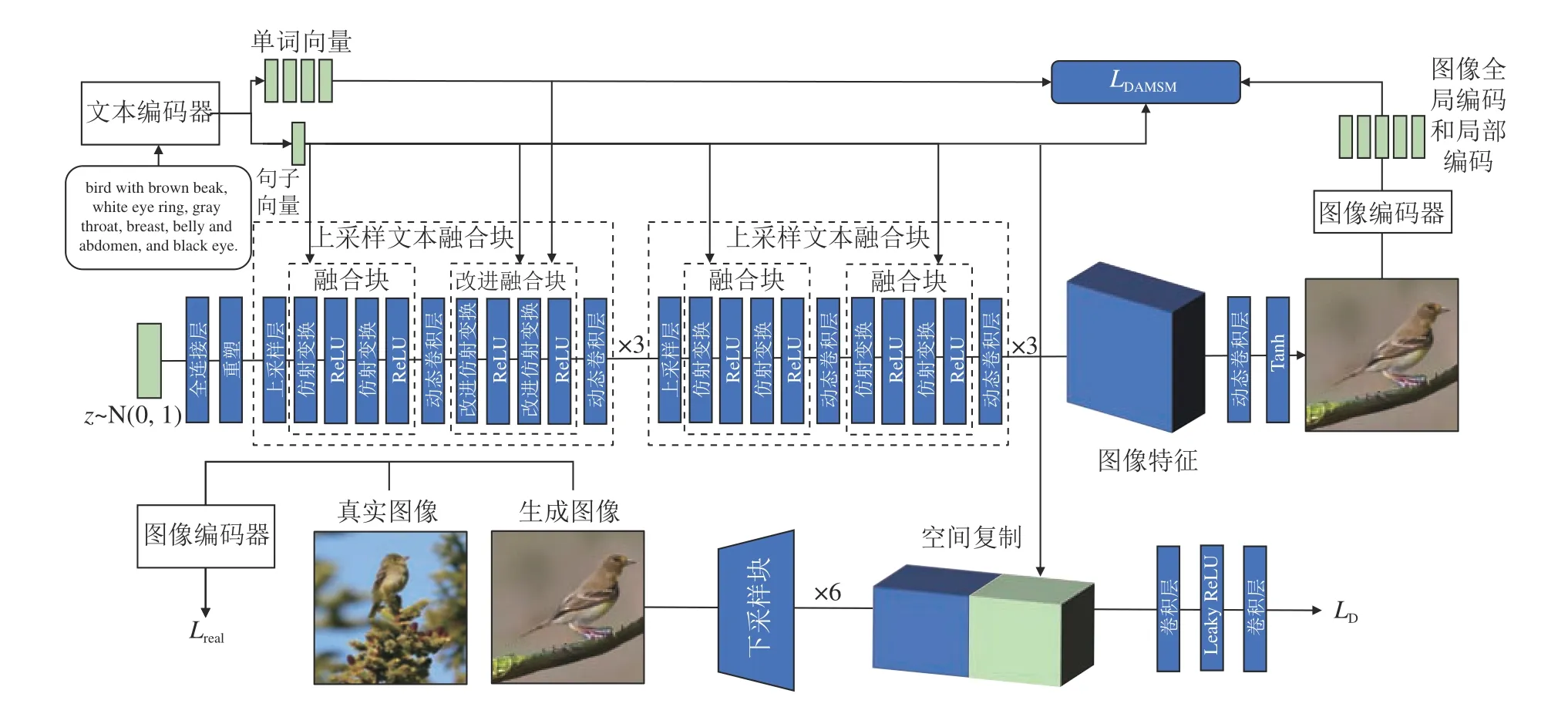
图1 基于单阶段生成对抗网络的文本生成图像方法的框架图Fig.1 Framework illustration of text-to-image generation method based on single stage generative adversarial network
2.1 文本编码
文本生成图像任务中的文本编码是将文本字符编码为具有视觉区分能力的向量,为接下来生成符合文本语义的图像提供条件.文本编码器采用双向长短期记忆网络(LSTM)[20],一个隐藏层2 个方向的连接作为1 个单词的编码,最后一个隐藏层2 个方向的连接作为当前句子的编码.单句中所有单词编码为e∈RD×T,句子编码为s∈RD,其中T为句子中单词的个数,D为单词或句子向量的维度.图像编码器建立在ImageNet[21]数据集预训练的Inception-V3[22]基础上.真实图像缩放为固定尺寸输入图像编码器,在最后一个平均池化层得到真实图像的编码f¯ ∈R2048,在mixed_6e 层得到图像子区域的编码f∈R768×289.一幅图像的子区域数量为289,子区域的维度为768.通过最小化DAMSM 损失[3]对图像编码器和文本编码器进行训练.这样文本编码器生成的文本编码具有视觉区分能力,即能够区分具体颜色.在生成对抗网络训练时,文本编码器和图像编码器参数固定,减小了生成对抗网络模型的参数量,降低了训练难度.
2.2 模型结构
将噪声向量z输入全连接层并重塑为4×4×256大小的图像特征.此图像特征经过6 个上采样文本融合块的信息融合得到256×256×32 大小的图像特征,再经过动态卷积层生成256×256 大小的图像.将生成图像、真实图像和句子向量输入鉴别器中进行鉴别.
如图1 所示,1 个上采样文本融合块由1 个上采样层、2 个融合块和2 个动态卷积层组成.1 个融合块中包含2 个ReLU 激活层和2 个仿射变换层.为了实现细粒度生成图像,使用注意力机制得到每个子区域最相关单词的动态表示,在前3 个上采样文本融合块的第2 个融合块中加入单词信息,在原有仿射变换只融入句子信息的基础上又融入单词信息.
添加单词信息的改进仿射变换的结构如图2所示.使用1×1 卷积把单词编码e∈RD×T的维度转化为与当前图像特征的维度相同:

图2 改进仿射变换结构图Fig.2 Structure diagram of modified affine
把e′和当前图像特征h∈RN×Dˆ相乘归一化后得到αji.由于每次输入仿射变换的图像特征大小不同,N为当前图像特征的子区域个数,Dˆ 为当前子区域维度.αji为当前图像特征第j个区域对第i个单词的权重,
通过 αji与单词相乘得到与当前图像子区域相关所有单词的动态表示:
将句子向量s,单词上下文向量cj和噪声向量z进行拼接并作为当前子区域的文本条件.通过多层感知机从文本条件中得到当前子区域的缩放参数和移位参数,实现每个子区域都有自己的缩放参数 γj和 移 位 参 数 θj,
输入的图像特征经过仿射变换,使图像子区域不但会融合句子信息,还会使图像子区域能够融入与当前子区域最相关的单词信息,弥补原始框架只使用句子信息可能忽略单词信息的问题,使生成器实现细粒度生成图像.
2.3 对比学习
使用NT-Xent 作为对比学习损失.对比学习可以使网络学习同类实例之间的共同特征,非同类实例之间的不同之处.通过最小化相关文本图像之间的距离,最大化不相关文本图像之间的距离,使同一语义下图像更加接近,不同语义图像更加疏远的方式,保证图像和文本的语义一致.定义余弦相似性作为2 个向量是否相似的评价标准:
当i≠j时,真实图像和生成图像对比损失Lreal的计算式为
当i≠k时,生成图像和生成图像对比损失Lfake的计算式为
式中:fimg为训练好的图像编码器,用于把生成图像或真实图像编码成向量;η 为温度超参数;N为批处理(batch)的大小.在Lreal中,相关图像指的是同一文本对应的真实图像和生成图像,对应xi和x˜i,不相关图像指的是真实图像和当前batch 中其他生 成 图 像,对 应xi和x˜j.在Lfake中,x˜i和x˜j代 表 同 一语义2 个不同文本表达所生成的图像,它们是相关 图 像,x˜i和x˜k是 同 一batch 不 相 关 文 本 生 成 的 图像.在计算生成图像之间的对比损失时,由于是在生成图像和生成图像之间计算对比损失,在batch 大小不变的情况下,须生成图像的数量是原来的2 倍.
2.4 动态卷积
传统的卷积操作中,所有输入共享统一的卷积核参数,动态卷积则可以根据输入的不同,动态地聚合多个卷积核.由于文本生成图像的数据集中有多种不同类型的图像,比如在数据集COCO[23]中,有人物、风景和汽车等多种类型,不同类型图像之间差异很大,在进行卷积操作的时候,应根据融入文本信息后的图像特征的不同,动态地生成图像.融入图像特征的文本信息不同,各个卷积核的权重也不同.不同文本信息会得到不同的卷积核权重,实现在图像生成过程中根据文本信息动态生成图像,提高网络动态生成的能力.在生成器中,本研究使用动态卷积代替传统的卷积操作.
动态卷积的结构如图3 所示.在动态卷积中,输入的图像特征h先通过全局平均池化,将图像特征的长和宽变为1;再经过第1 个全连接层将通道大小变为原来的25%,经过第2 个全连接层把通道大小变为K;最后归一化得到每个卷积核对 应 的 注 意 力 πk(h) ,

图3 动态卷积的结构图Fig.3 Structure diagram of dynamic convolution
聚合K个卷积核和偏差,使用聚合后的卷积核和偏差对输入图像特征进行卷积操作.
使用动态卷积后,生成器可以更快地生成质量较好的图像.计算每个卷积核对应的注意力成本较低,而且每个卷积核的大小相对输入的图像特征来说较小,相应卷积核的聚合计算量也较小,因此使用动态卷积替代卷积增加的计算量也不大.
2.5 目标函数
定义生成器网络的目标函数为
式中: λ1为DAMSM 损失的权重, λ2为生成图像之间的对比损失的权重, λ3为生成图像和真实图像之间对比损失的权重.只使用Lreal时 , λ3=0.本研究引入单词级信息,为此使用DAMSM 损失LDAMSM.DAMSM 计算单词和生成图像区域的损失,从单词水平上度量生成图像和文本的匹配程度.
定义鉴别器网络的目标函数为
使用和DF-GAN 相同的铰链损失来稳定对抗训练的过程,使用匹配感知梯度惩罚(MA-GP)和单向输出促使生成器生成与文本语义一致性更高的图像.
3 实 验
3.1 数据集
采用Caltech-UCSD Birds 200-2011[24](CUB)和2014 版COCO 来训练和测试提出的模型.CUB 是只有鸟类图片的数据集.数据集中共有200 种鸟类的图像,其中训练集中包含150 种8 855 幅图像,测试集中包含50 种2 933 幅图像.每幅图像对应10 种语义相同但表达方式不同的英文句子.COCO 中的图像具有更丰富的种类和更复杂的场景,共有171 种图像类别,其中训练集包含8 万幅图像,测试集包含4 万幅图像.每幅图像对应5 种语义相同但表达方式不同的英文句子.
3.2 评估指标
使用FID[25]对生成图像的质量进行量化分析.生成图像和真实图像可以分别看作2 个分布,FID 计算生成图像分布和真实图像分布之间的距离,更低的FID 分数代表生成图像更加接近真实图像,即视觉真实并且符合文本语义.
式中:r、g分别为真实图像编码和生成图像编码,µr、 µg分别为真实图像编码均值和生成图像编码均 值, Σr、 Σg分 别 为 真 实 图 像 编 码 协 方 差 和 生 成图像编码协方差.
3.3 训练细节
所提模型在pytorch 上实现,文本编码器和图像编码器参数来自文献[3].模型在CUB 和COCO的训练和测试都在单个NVIDIA V100 32G GPU上进行.训练中使用 β1=0.0, β2=0.9 的Adam 优化器[26].设置式(8)中的η=0.1,式(9)中的η=0.5,式(10)中的K=8,batch=32.在使用生成图像和生成图像的对比损失时,设置式(14)中系数权重为λ1=0.1,λ2=0.1,λ3=0.2.CUB 的 最 终 模 型 是 在600~700 次迭代时取得最小的FID 数值的对应模型.COCO 的最终模型是取第1 次FID 数值小于13 的模型,迭代次数为219.
3.4 定量评价
使用和DF-GAN 相同的测试方法对生成图像进行测试.在CUB 上测试时,测试集中每个语义文本生成10 幅对应图像,共生成29 330 幅图像计算FID 分数.在COCO 数据集上测试时,每个语义文本生成1 幅图像,共生成4 万幅图像计算FID分数.与DM-GAN、KD-GAN 和DF-GAN 等模型进行比较,定量对比实验的结果如表1 所示.相比DF-GAN,在CUB 上,所提模型将FID 从12.10 降到10.36,在COCO 上,将FID 从15.41 降到12.74.从定量分析的角度来看,所提方法相比其他方法生成的图像更加接近真实图像,文本和生成图像的潜在语义一致性更好,图像质量得到较大地提升.

表1 CUB 和COCO 数据集上各个模型FID 得分比较Tab.1 Performance of FID scores compared with different models in CUB and COCO datasets
参考Tao 等[5]在GitHub 上公布的模型,实验得到训练DF-GAN 需要的epoch 数量.如表2 所示为在CUB 和COCO 训练的epoch 数量n和训练单个epoch 的时间t.相比DF-GAN,所提模型在单个epoch 的训练时间有所增加,但从2 个数据集训练的总时间来看,达到较高水平所需的总时间基本相同,训练时间没有明显增加.在CUB 上,所提方法需要的训练时间约为69.56 h,DF-GAN 需要的训练时间约为96.24 h.在COCO 上,所提方法需要的训练时间约为226.30 h,DF-GAN 需要的训练时间约为211.70 h.当进行模型推理时,所提方法生成1 幅图像的时间约为2 ms,与DF-GAN 模型生成1 幅图像的时间相当.

表2 CUB 和COCO 数据集上与DF-GAN 训练时间比较Tab.2 Training time compared with DF-GAN in CUB and COCO datasets
3.5 定性评价
将真实图像、所提方法生成的图像和DF-GAN模型生成的图像进行可视化对比.如图4 所示为在CUB 上的生成图像对比示例.在第1 幅图像中,所提模型的生成图像很好地体现了白色的鸟和灰色的翅膀,DF-GAN 生成的图像没有体现出文本语义,和真实图像相似度不如本文模型生成的图像.在第2 幅图像中,所提方法的生成图像很好地体现了红色的眼睛和白色的腹部.在第5 幅图像中,白色的眼睛环明显展现出来.可以看出,所提方法可以更好地利用单词信息实现细粒度图像生成,生成图像在单词细节上更加符合文本信息的描述.在其他几组生成图像对比中,2 个模型生成的图像都体现了文本所表达的语义,但所提方法生成的图像更加自然,并且和真实图像相似度更高.如图5 所示为在COCO 上的生成图像对比示例.由于COCO 中的图像种类丰富并且场景复杂,生成图像只能尽量保证图像的真实性.在第1 幅图像中,所提方法刻画了滑雪队员的大致轮廓.在第5 幅图像中,所提方法较好地还原了建筑中有带有钟的高塔.总体来看,与DF-GAN的生成图像相比,所提方法生成的图像轮廓更加清晰,较好地捕捉了文本描述中提到的图像细节特征,图像的清晰度有了较好地改善,生成的图像更加符合人眼观察预期.通过文本再次对生成图像进行评估,可以看出所提方法生成的图像更加匹配文本语义.

图4 在CUB 数据集上2 种模型文本生成图像的定性比较Fig.4 Qualitative comparisons of text-to-image generation by two models in CUB dataset

图5 在COCO 数据集上2 种模型文本生成图像的定性比较Fig.5 Qualitative comparisons of text-to-image generation by two models in COCO dataset
3.6 消融研究
在CUB 上进行消融实验来验证每个针对DF-GAN改进的有效性.基线的FID 来源于DF-GAN 提供模型的运行结果.这些改进包括在生成图像的过程中融入单词信息、添加真实图像和生成图像的对比损失、在生成器中引入动态卷积.通过评估FID 证明不同改进的有效性,结果如表3 所示.在基线模型中引入细颗粒度的单词信息,FID 从12.10 降到10.98.进一步增加真实图像和生成图像之间的对比损失,FID 从10.98 降到10.83.进一步将生成器中的卷积层换成动态卷积层,FID 从10.83 降到10.36.可以看出,相比于加入对比损失(FID 降至11.89) 或者引入动态卷积(FID 降至11.76),融入单词信息(FID 降至10.98)更能有效地提升所提方法的性能.

表3 在CUB 数据集上改进模块的消融研究Tab.3 Ablation study of improvement modules in CUB dataset
为了验证在生成图像的过程中融入单词信息的位置对FID 数值的影响.间隔地融入单词信息,在第1、3、5 个上采样文本融合块中的第1 个融合块中加入单词信息.在较前位置融入单词信息,在第1、2、3 个上采样文本融合块中的第2 个融合块中加入单词信息.在较后位置融入单词信息,第4、5 个上采样文本融合块中的第2 个融合块中加入单词信息.通过FID 分数评估在不同位置融入单词信息的有效性,结果如表4 所示.实验发现在较后位置融入单词信息会降低生成图像的质量.在较前位置融入单词信息,生成图像的质量有较好的提升.

表4 在CUB 数据集上融入单词信息位置差异性的消融研究Tab.4 Ablation study on different positions for incorporatingword information in CUB dataset
在基线模型融入单词信息的前提下,尝试在生成图像和生成图像之间应用对比损失代替生成图像和真实图像之间的对比损失,使用文献[15]提供的文本编码器和图像编码器参数,结果如表5所示.可以看出,在没有使用动态卷积的情况下达到了最好的FID 最好,FID 从10.98 降到10.32.在生成图像和生成图像之间添加对比损失要生成原来2 倍的图像来计算对比损失,使得模型参数剧增并且训练时长加大,由表5 可知,此时模型性能提升有限,因此最终的模型中没有使用这种对比损失.

表5 在CUB 数据集上添加对比损失的消融研究Tab.5 Ablation study on adding contrastive loss in CUB dataset
4 结 语
针对DF-GAN 生成器的网络结构和损失函数进行改进.在生成器生成阶段,通过在合理的位置引入单词信息生成器实现了细粒度图像生成.引入对比损失,进一步增强文本-生成图像之间语义一致性.将生成器中的卷积层换成动态卷积层,增强了模型表达能力并使得模型更快地收敛.在性能提高的同时,增加改进后的模型仍然可以在显存为24G 的GPU 上进行训练,并且训练时间没有明显增加,方便后序进一步改进.通过量化指标和消融实验,证明针对DF-GAN 的各种改进有明显的成效,能够有效地提高生成图像质量.
