基于改进YOLOv5s网络模型的火灾图像识别方法*
2024-01-12梁金幸赵鉴福周亚同史宝军
梁金幸,赵鉴福,周亚同,史宝军
(1.河北工业大学 省部共建电工装备可靠性与智能化国家重点实验室,天津 300401;2.河北工业大学 机械工程学院 河北省机器人感知与人机融合重点实验室,天津 300401;3.河北工业大学 电子信息工程学院,天津 300401)
0 引 言
随着社会发展水平的不断提升,产生较大损失火灾的可能性也逐渐增大。早期的火灾识别方法主要是通过探测器对特定区域的温度、光谱和烟雾等进行采样分析,但由于探测器检测范围与灵敏度的限制,在开阔空间以及环境恶劣的情况下,难以实现较为及时的检测[1]。此外,探测器难以确定火灾位置、火焰大小和火灾发展趋势,不利于后续火灾的处置。
近年来,使用图像处理技术进行火灾识别,引起了许多研究人员的关注。传统的火灾图像识别方法主要通过图像分割[2]、运动目标检测[3]来确定疑似火焰区域,然后设计并提取火焰的多种特征,使用支持向量机(support vector machine,SVM)[4]等机器学习分类器进行特征融合,从而实现火灾识别。此外,火焰的颜色和运动特征受到了广泛关注。Khalil A等人[5]使用颜色特征分割出火焰区域,然后利用动态特征来确定该区域是否包含火焰,该方法可在一定程度上降低火灾检测系统的误报率。得益于计算机性能的提升,深度学习网络模型在图像识别领域得以发展和应用。常用的深度学习网络模型主要有YOLO(you only look once)模型[6]、单次多框检测(single shot multibox detector,SSD)模型[7]以及快速区域卷积神经网络(faster regionbased convolutional neural network,Faster R-CNN)模型[8]。在对火灾图像识别的研究中,Li P和Zhao W[9]对比分析了基于Faster R-CNN,R-FCN,SSD 和YOLOv3 等深度神经网络的火灾识别方法,实验结果表明YOLOv3 网络模型的性能优于其他网络模型;张海波等人[10]提出了一种三通道拟合的卷积神经网络(convolutional neural network,CNN)火灾探测算法,该算法可有效提高火灾识别率。
上述研究工作丰富和发展了火灾图像识别方法,但仍然存在一些问题:颜色和运动特征识别方法难以排除颜色类似于火焰的动态干扰物;传统的火灾图像识别方法依赖于人工设计特征,导致算法泛化能力不足;深度学习方法通过神经网络模型自动学习特征,但模型对有效信息的提取能力和对小目标的检测能力有待进一步提升。
针对当前火灾图像识别方法存在的问题,本文提出一种基于改进的YOLOv5s 网络模型的火灾图像识别方法。首先,通过在特征提取网络中添加注意力机制模块,增强模型对图像特征的学习能力;然后,在YOLOv5s 多尺度检测的基础上添加大尺度检测层,提升模型对小目标的识别能力,并且使用K-Means算法对火灾数据集的标注框进行聚类,获得先验框的尺寸;最后,在实验数据集上验证了本文火灾图像识别方法的有效性。
1 YOLOv5s网络模型
YOLO网络模型由Redmon J 等人[6]于2016 年提出,利用回归的思想来解决目标检测问题,能够同时输出物体的边界和类别概率。2020 年,Ultralytics 公司公布了YOLOv5s网络模型。图1为YOLOv5s网络模型的结构。

图1 YOLOv5s网络模型结构
如图1 所示,YOLOv5s 网络模型包括输入(input)层、主干(backbone)部分、颈(neck)部和输出(output)层4个部分。输入图片经过特征提取后,得到3 种不同尺寸的特征图(feature map),这些不同尺寸的特征图用于检测不同大小的目标。Backbone 和Neck 由Focus,CBL(convolutional,batch normalization,leaky)ReLU,CSP(cross stage partial)以及SPP(space pyramid pooling)模块组成。Focus 模块包含切片层(slice layer)、卷积层(convolutional layer)和激活函数(activation function),用于对特征图进行切片操作。CBL模块包含卷积层,批量标准化(batch normalization,BN)层和激活函数。CSP模块有CSP1_X和CSP2_X两种类型,使用跨层连接的方式来融合不同层间的特征信息。CSP1_X包含CBL模块、X个残差单元(ResUnit)、卷积层、批量标准化层和激活函数。与CSP1_X不同,CSP2_X用CBL模块代替了残差单元。SPP模块包含CBL 模块和池化层(pooling layer),采用最大池化操作对不同尺度的特征图进行张量拼接,实现多重感受野的融合。此外,YOLOv5s网络模型采用GIOU_Loss损失函数[11]来估算边界框的位置损失。
由于火灾识别任务具有实时性的需求,YOLO 系列模型以检测速度快的优点引起了研究人员的关注。相比于之前的YOLO系列模型,YOLOv5s网络模型体积轻便且检测速度快,适合部署到嵌入式设备。因此,本文使用YOLOv5s网络模型进行火灾图像识别并对模型进行改进,进一步提升模型的性能。
2 模型改进方法
2.1 特征提取网络改进
Backbone,即为特征提取网络,采用Focus,CBL,CSP以及SPP等模块来提取图像的特征。这些模块的使用可以在一定程度上改善特征提取过程中的特征信息损失问题,但不同通道(channel)间特征的重要程度并没有得到关注。为了解决这个问题,研究人员通过使用注意力机制(attention mechanism)对输入图像的特征加以选择,使模型更加关注不同特征的重要性[12]。
为了提升模型对特征的学习能力,本文将挤压-激励(squeeze and excitation,SE)模块加入到YOLOv5s网络模型的特征提取网络中,为模型添加注意力机制。SE模块源自SE网络(SE network,SENet)[13]。具体来说,SE 模块通过调整各通道的权重,使模型关注信息量大的特征,抑制无效或效果作用小的特征,从而实现注意力的集中,提高网络模型的学习能力。图2为SE模块的计算流程,W×H×C代表特征图的尺寸,输入特征图经过Squeeze操作得到1 ×1 ×C的向量;然后,通过Excitation操作学习到各通道的权重;最后,将各通道的权重赋予输入特征图。

图2 SE模块计算流程
YOLOv5s网络模型借鉴特征金字塔网络(feature pyramid network,FPN)的多尺度检测思想,使用80 ×80,40 ×40和20 ×20这3种尺寸的特征图来实现目标识别。图3 为引入SE模块后的特征提取网络及参数,相比于原始模型的特征提取网络,改进后的特征提取网络在第2个CSP1模块、第3 个CSP1 模块以及SPP 模块后分别添加了SE 模块,用于获得80 ×80,40 ×40 和20 ×20 这3 种带有注意力机制的特征图。

图3 改进后的特征提取网络和参数
2.2 多尺度检测改进
火灾发生初期是火灾识别的关键时期,此时的火焰形态多为小型火焰,所以,火灾识别网络模型应当对小目标具备较好的识别能力。在YOLOv5s 网络模型特征提取过程中,图像经过多次卷积、池化等操作后会丢失部分信息,导致模型对小目标的检测效果不佳。因此,本文在YOLOv5s多尺度检测的基础上添加大尺度检测层,提高模型对小目标的识别能力。
值得注意的是,检测层层数的增多会增加网络模型的参数量,导致检测速度降低。为了满足火灾识别网络模型的精度和实时性要求,本文在YOLOv5s网络模型的输出部分添加1个160 ×160的检测层,利用4种不同尺寸的特征图对图片中的大、中、小和较小目标进行识别。改进后的多尺度检测层如图4 所示,新增加的检测层4 会对检测层3中80 ×80 的特征图进行一次上采样,获得160 ×160 的特征图,然后再与主干网络中160 ×160的特征图相连接。
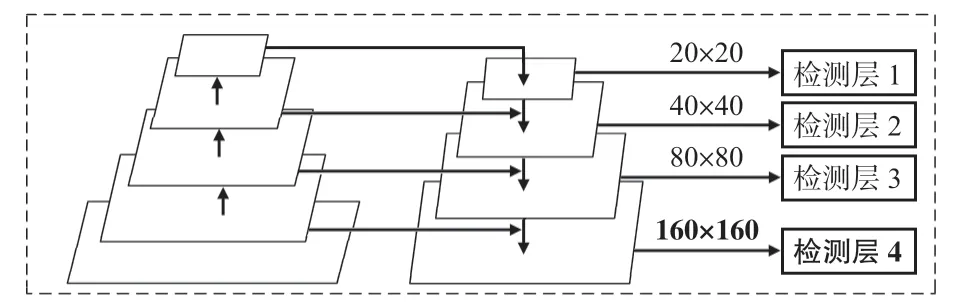
图4 改进后的多尺度检测层
2.3 先验框改进
先验框是从训练集中真实标注框中统计或聚类得到的一组固定尺寸和宽高比的初始区域,在网络模型训练中,初始先验框参数越接近真实边界框,模型将会越容易收敛,其预测边界框也会更加符合真实边界框。
K-Means是一种常用的聚类算法,主要思想是根据欧氏距离将样本点聚集到指定的K 个类别中。YOLOv5s 网络模型设定的初始先验框如表1 所示,每个尺度的特征图匹配3个先验框。由于检测层层数的增加,先验框的个数也要相应增加。此外,数据集中火灾图像的火焰区域大小各异。为了使先验框能够与检测层相匹配,并且符合数据集的真实情况,使用K-Means算法对火灾数据集中的标注框进行聚类,将聚类得到的一组先验框代替YOLOv5s设定的初始先验框。

表1 YOLOv5s网络模型先验框
依据每个尺度的特征图匹配3 个先验框的原则,改进后的检测层所匹配的先验框总数为12,即聚类个数K =12。添加大尺度检测层后,网络模型能够输出4 种不同尺寸的特征图。尺寸较大的特征图包含图像的低层信息,具有较小的感受野,故匹配较小的先验框;相反,尺寸较小的特征图匹配较大的先验框。改进后的先验框与特征图的匹配情况如表2所示。

表2 改进后的先验框
3 实验与结果分析
3.1 实验环境
实验环境为:Intel®CoreTMi9-10900KF @ 3.70 GHz,32 GB内存,Nvidia GeForce RTX 2080 Ti,Windows10 64位操作系统。使用Python开发语言,CUDA10.0 GPU 加速库以及Pytorch1.8.1深度学习框架。
3.2 模型训练
由于目前火灾防治领域没有公开的标准数据库,本文主要使用互联网上搜集的火灾图片,以及文献[14 ~16]中提出的一系列典型火灾数据库来构建火灾数据集。所构建的火灾数据集共计2 730 张图片,主要包括室内、公路和森林等场景中不同大小和形状的火焰,部分火灾数据集图片如图5所示。使用Labelimg软件完成火灾数据集的标注,标注好的数据集将用于模型的训练和测试。训练集和测试集分别按照70%和30%的典型比例进行划分,即训练集包含1 911张图片,测试集包含819张图片。

图5 火灾数据集部分图片
依据YOLOv5s网络模型设定的训练参数,在网络模型训练阶段,初始学习率设置为0.01,迭代批量尺寸(batch size)设置为16,动量(momentum)因子设置为0.937,权值衰减(weight decay)系数设置为0.000 5,轮次(epoch)设置为300,使用随机梯度下降(stochastic gradient descent,SGD)法进行优化。此外,为了增加火灾数据集中样本的多样性,本文对输入网络模型的图片进行数据增强处理。增强方法包括图像平移(translate),尺度(scale)变化、左右翻转(flip left-right)、马赛克(mosaic)数据增强以及HSV颜色空间中色调(hue)、饱和度(saturation)及明度(value)的变化。
3.3 结果分析
本文以YOLOv5s网络模型为基础,对特征提取网络,多尺度检测层以及先验框尺寸进行了改进。采用精确率(precision,P)、召回率(recall,R)、置信度0.5 下的平均精度均值(mean average precision,mAP)和帧率(frames per second,FPS)来评价模型的性能[17,18]。mAP 为Precision 和Recall曲线下的面积,用来表示模型的整体性能,P =TP/(TP +FP),R =TP/(TP +FN)。其中,TP 为正样本被正确分类的数量,FP为负样本被错误分类的数量,FN为正样本被错误分类的数量。
改进YOLOv5s 网络模型的训练情况如图6 所示。图6(a)为损失函数随训练轮次的变化曲线,模型训练300轮次,损失函数数值收敛在0.05 ~0.1。图6(b)为mAP随训练轮次的变化曲线,模型训练150轮次左右,mAP波动较小,然后趋于稳定。
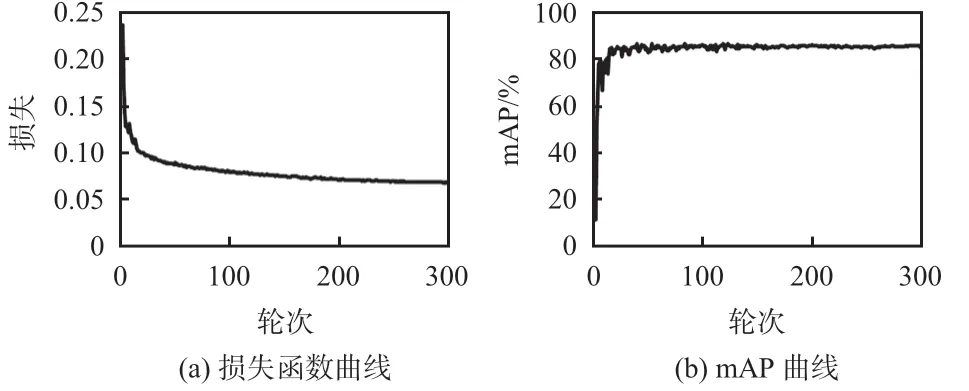
图6 改进YOLOv5s网络模型的训练表现
为探究所使用的改进方法对模型性能的影响,将改进特征提取网络的模型记为YOLOv5s-A,由于先验框个数需要与检测层层数相匹配,故将同时改进特征提取网络,多尺度检测层以及先验框的模型记为YOLOv5s-AB,并将改进的2种网络模型与YOLOv3 和YOLOv5s 进行对比。各网络模型的性能评价结果如表3所示。
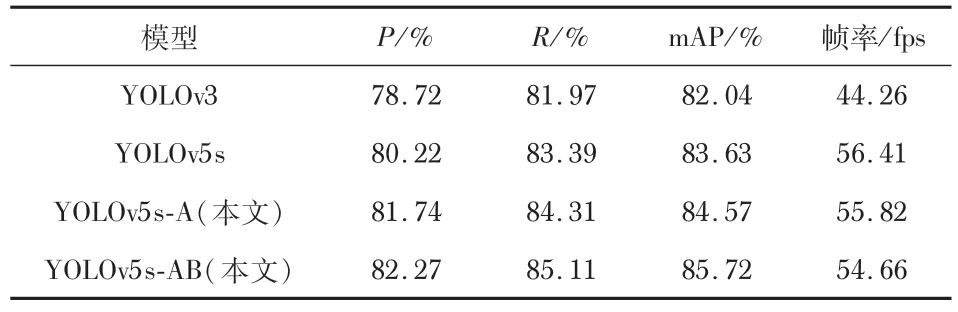
表3 各网络模型性能评价结果
由表3 可知,YOLOv5s-A、YOLOv5s-AB 相比YOLOv3和YOLOv5s,P、R和mAP指标均有提升;YOLOv5s-AB相比YOLOv3,P、R 和mAP 指标分别提高了3.55%、3.14%和3.68%,帧率提高了10.40 fps;YOLOv5s-AB相比YOLOv5s,P、R和mAP指标分别提高了2.05%、1.72%和2.09%,帧率可达54.66 fps。由于在YOLOv5s 中添加了SE 模块和160 ×160的检测层,导致YOLOv5s-A、YOLOv5s-AB的检测速度略低于YOLOv5s。
为了进一步测试YOLOv5s-AB 网络模型的性能,使用文献[19]中构建的火灾数据集进行实验,图7 为YOLOv5s与YOLOv5s-AB网络模型对火灾图像和干扰图像的识别效果。

图7 火灾识别实验结果
本文在原始YOLOv5s 网络模型中,同时添加了SE 模块和大尺度检测层,并使用K-Means聚类算法得到先验框的尺寸。由图7所示的火灾识别实验结果可以看出,改进的YOLOv5s-AB网络模型相比于原始模型,在置信度上有了明显提升,对多目标和小目标的识别效果更好,并且可以在一定程度上排除夕阳、灯光等干扰物。
4 结 论
本文通过研究YOLOv5s网络模型的特征提取网络,多尺度检测层以及先验框机制,提出一种改进YOLOv5s网络模型的火灾图像识别方法。在原始YOLOv5s 网络模型中同时添加SE注意力机制和大尺度检测层,并使用K-Means聚类算法得到先验框尺寸。实验结果表明:改进的YOLOv5s网络模型(YOLOv5s-AB)在实验数据集上的P为82.27 %,R 为85.11 %,mAP 为85.72 %,检测帧率达54.66 fps,以较低的时间代价提升了模型性能;尤其在置信度上有明显提升,对多目标和小目标的识别效果更好;并可较好地排除夕阳、灯光等干扰物,提高了对火灾图像的识别效果。下一步将考虑对现有火灾数据集进行扩充,使网络模型学习到的图像信息更加全面。
