基于深度学习的网络Web异常流量检测方法
2024-01-12徐丞
徐丞
(成都鸿安华宇科技有限公司, 四川, 成都 610000)
0 引言
Web服务凭借便捷性强、可靠性高等优势逐渐成为用户获取信息的主要方式。随着Web应用规模的不断扩大,越来越多的不法分子开始盗取信息,网络面临更多攻击威胁。为了提高用户隐私数据安全性,向用户提供可靠的服务,Web异常流量检测成为主要防护手段。流量中包含海量有用信息,是数据传播的载体,利用有效的方式分析流量特征,就可敏锐感知网络态势,及时检测出异常流量,并采取有针对性的措施,抵御非法攻击,维护网络安全。国外的一些检测方法主要结合已有的攻击类型特征,实现异常行为与正常行为的划分。但此种措施对于新增攻击类型而言漏报率较高,且特征提取过程中人为干扰因素较大。
为提高检测效果,国内学者也纷纷展开研究。杜军龙等[1]提出基于云计算和机器学习的新型入侵检测系统,利用神经网络和贝叶斯滤波器,构建海量流量数据集预测模型,获取数据可视化信息组织映射,对计算机网络实现可视化监控和监督。虽然该方法检测率能够满足实际需求,但是容易出现虚报情况,虚警率较高。王琦等[2]提出基于大数据分析技术的网络入侵检测方法,采用神经网络构建网络入侵检测的分类器,通过蚁群算法选择最优的神经网络连接值和连接权值,实现网络入侵检测,但是该方法的检测正确率还有上升的空间。
为了解决上述问题,同时满足高检测率与低虚警率的要求,本文提出基于深度学习的异常流量检测方法。深度学习也可称为特征学习[3],此种学习方法不需要人工参与,减少主观干扰,同时具有自组织学习能力,可最大程度在找出异常流量的同时,降低虚警发生几率。
1 流量数据采集与预处理
1.1 基于DPDK的数据采集
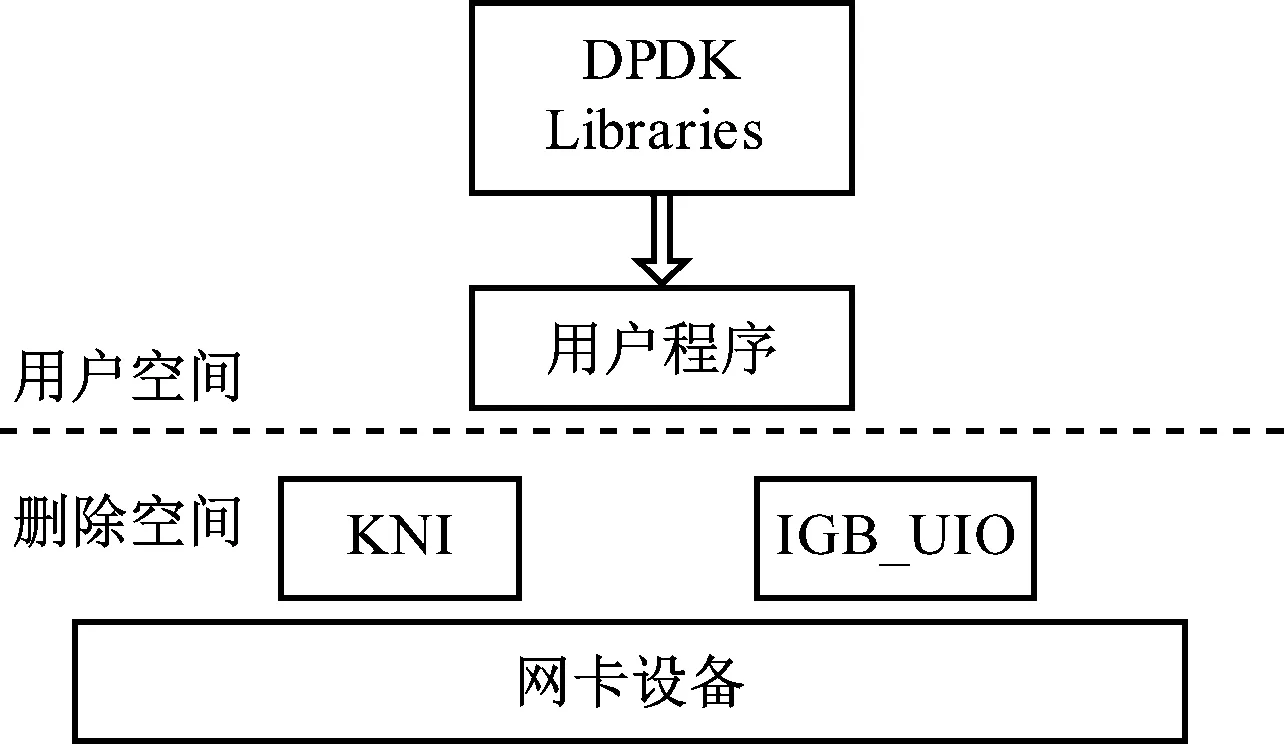
在Web网络环境下,如何高效、全面地采集流量数据是异常流量检测的关键问题。为保证数据采集的实时性,设计基于DPDK(数据平面开发工具包)的流量采集架构[4],如图1所示。
(a) DPDK整体架构
如图(2)所示,采集架构共分为6个核心组件,具体功能如下:
环境抽象层能够为用户提供API接口,是DPDK架构中最为关键的组件,利用DPDK自身提供的数据平面库进行数据包的处理,绕过了Linux的内核协议[5],可屏蔽网络环境中的细节差异,加载并初始化操作接口,并进行接口调试,实现最底层资源的访问;
堆内存管理组件在程序正常运行期间提供内存管理接口,避免系统内存过多,提高访问速度;
缓冲区管理组件提供单个或多个的无锁处理接口,建立MBUF对象,封装实际数据帧,并且可实现在多进程间的相互通信,在通信过程中,还能降低系统开销;
内存池管理组件提供储存接口;
调试组件可以调整其他组件状态功能,缓存报文和普通数据;
定时器组件为执行单元提供定时器服务。
利用图1所示的流量采集架构,通过端口镜像设备采集Web网络流量,并将采集到的全部流量备份到检测模型中。端口镜像不会对数据交换造成影响,实时捕获流量包。
1.2 数据预处理
数据预处理的主要目的是确保所有采集到的数据格式统一,便于异常特征提取。
(1) 数值化处理
流量集合中的特征属性主要包括匹配和附加特征,其中前者表示采集到的综合数据,也是数值化处理的主要目标,主要从如下方面进行数值化处理:
基本特征包括IP地址、字节数量、目标生存时间、丢包数量、网络服务类型、数据传输速度等;
内容特征包括通告窗口大小、序列编码、流量包大小平均值、响应速度、未压缩数据大小;
(2) 归一化处理
将上述特征赋予具体数值后,还需将这些数据归一化,提高特征提取速度。利用离差标准化的方法[6]将初始数据映射在[0,1]之间,归一化具体公式如下:
(1)
式(1)中,xmax与xmin分别代表属性极大与极小值,x表示当前属性值,f(x)表示经过映射后的属性值。
2 基于小波分解的流量特征提取
小波分解的实质是利用平移等运算过程多尺度分析信号,提取其中的主要信息。其中,小波函数是决定小波分解效果的关键因素。综合分析各函数差异,最终选用Daubechiesl小波函数实现信号的离散小波变换,获取信号中的有用信息。特征提取流程如图2所示。
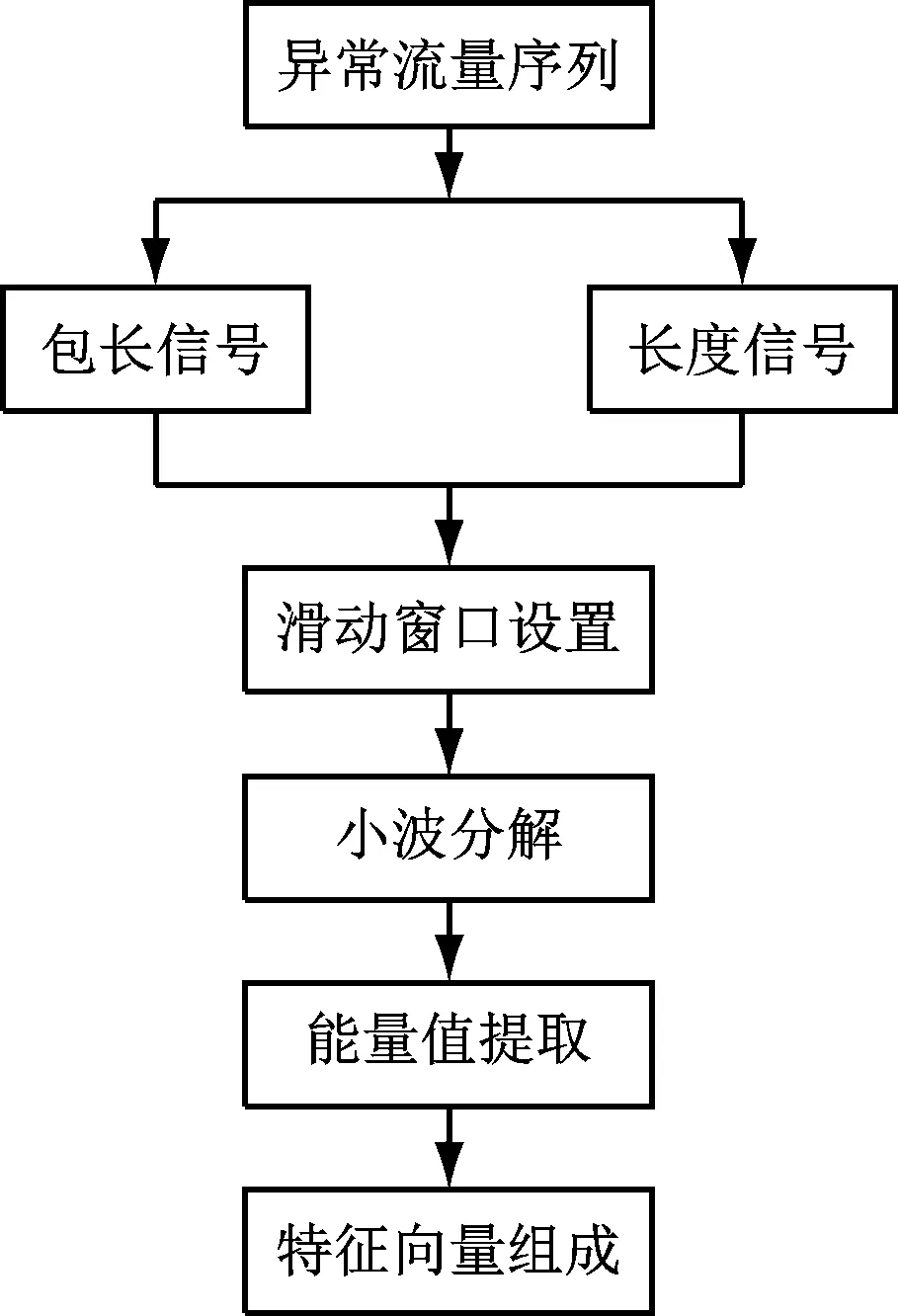
图2 基于小波分解的信号特征提取流程图
Daubechiesl函数属于一个正交小波函数[7],其支撑域范围为t∈[0,1],具体定义表示为
(2)
Daubechiesl函数是不连续的,但是计算简单,且ψ(t)不与ψ(2t)正交。
为保证特征组长度合理,设定滑动窗口提取子序列,并对序列进行初步分析,了解序列大概周期;在窗口内获取某组特征,根据周期情况设置窗口大小,并将滑动步长设置为1;确定特征参数,确定过程中,需保证类别差异明显且不冗余,最大程度保证最低维数。
综合平均值、标准差和能量占比情况确定最终异常特征向量组。
(1) 平均值
反映数值序列的理想值,体现出信号的波动状况,平均值μ在异常流量检测中表示信号能量,其计算公式如下:
(3)
式(3)中,Xi表示点i处信号取值,N表示信号长度。
(2) 标准差
标准差σ体现数据的分散程度,计算公式如下:

(4)
(3) 能量占比
能量占比指低频信号a5与每个高频信号d1,d2,…,d5总能量的比值。低频信号能量aj和高频信号能量dj的计算公式如下:
(5)
(6)
低频能量占比Ea5与高频能量占比计算公式分别如下:
(7)
(8)
综合上述平均值、标准差和能量占比3个指标可从长度序列中提取特征向量组。
3 基于深度学习的Web异常流量检测
通过构建混合神经网络模型实现深度学习,首先利用长短时记忆网络(LSTM)[8]对获取的流量特征进行学习建模,挖掘其内在时序特点;引入注意力机制对检测贡献较大的特征赋权;最后利用多层神经网络[9](MLP)输出检测结果。此种混合深度学习网络可以提高检测精度,保证异常检测的各指标均有所提高。
3.1 长短时记忆网络建立
LSTM能够处理时序特征较强的数据,元素输出不但和现阶段输入相关,还和历史状态相关。该网络会记忆历史信息并用在当前运算中。由于每条流量数据均具有时序性,某两台主机经过多次交流生成的数据包具也有时序性,因此异常检测过程中还需获取流量数据的时序相关特性,为深度挖掘时序关系,本文利用LSTM处理已经提取到的特征向量。
LSTM在每个时段的输出均取决于遗忘门fa、输入门ia以及输出门oa。在a时间点中,h为单元编码的输出,任意一个门都和上个模块的输出ha-1、现阶段输入pa相关,这些因素决定了记忆细胞的状态与异常状态。
将经过池化的特征序列P看作时间序列,同时将其输入到LSTM网络中。针对正向LSTM网络,分别输入pn1,pn2,…,pN;针对反向网络,则输入pN,pN-1,…,pn1,由n个神经元得到1×n维的特征向量。经过LSTM处理后,LSTM中隐含层单元数量为n,而隐含层输出n×m维的特征向量[10]。输出每个特征的状态,将正向与反向的最后一个输出级联,获取流量数据时间特征向量。输入门ia、遗忘门fa和输出门oa的表达式如下:
ia=α(Wi[ha-1,pa]+bi)
(9)
fa=α(Wf[ha-1,pa]+bf)
(10)
oa=tanh(Wo[ha-1,pa]+bo)
(11)
式(9)~式(11)中,α表示sigmoid函数,tanh属于双曲正切函数,Wi、Wf和Wo均代表权重矩阵,bi、bf和bo均属于偏置项;在得到初始样本在LSTM中的特征表达后,根据输入输出可以计算其对应的重构误差。非异常的特征数据在经过LSTM处理后的重构误差较小,相反,异常的特征数据在经过LSTM处理后的重构误差较大。可以通过计算正常流量的训练数据输入进模型后重构误差的分布来确定异常流量检测的阈值τ。如果输入的流量数据的重构误差大于之前计算出的异常流量检测阈值,即可判定该数据为异常流量数据[11]。设数据序列表示为x(τ)=[xi1,xi2,…,xin],n为序列长度。重构误差计算如下:
(12)
计算重构误差后,特征序列经过LSTM网络处理可获得流量数据的时间特征向量T:
T=E(τ)[a1,a2,…,an]
(13)
3.2 基于注意力机制的特征向量赋权
异常检测过程中,不同特征的贡献度不同,因此利用注意力机制对特征赋权,再利用特征加权求和的方式获取新的特征表示。
针对LSTM处理后得到的时序特征ai,利用式(14)中的tanh激活函数作非线性变换生成ui,再采用式(15)中的softmax函数获取所有分量ui的权重Wβ=[β1,β2,…,βn],使用式(16)对输出向量加权求和,获得Web流量特征的整体表示形式S。具体公式如下:
(14)
βi=softmax(Wui)
(15)
(16)
3.3 检测结果输出
多层感知机属于前馈式神经网络,结构简单,泛化能力强。利用该网络对S进行处理,通过分类器输出最后检测结果,MLP网络的运算过程如下:
y=fdense(WdenseS-bdense)
(17)
(18)
式(17)~式(18)中,Wdense表示全连接层的权重矩阵,bdense表示偏置项,fdense表示激活函数,yc表示第c维特征,ρ(yc)表示检测出的特征类别概率。
4 实验数据分析与研究
实验数据集选用公开数据集HTTPCSIC2020,此集合中包括海量Web请求信息。其中异常流量类型和特征如表1所示。
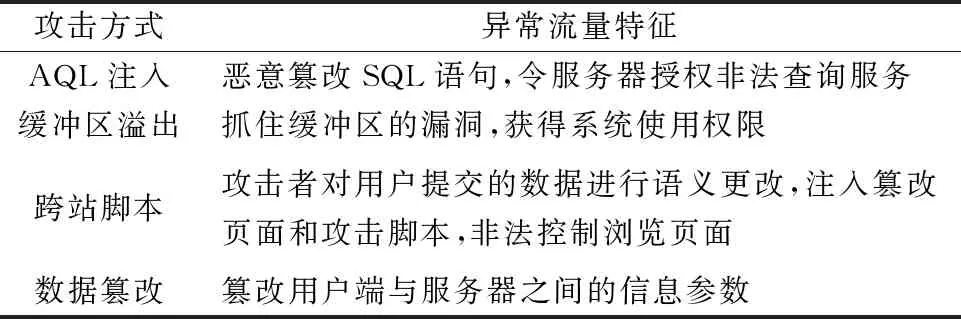
表1 异常流量攻击类型和特征表
特征提取效果影响着最终检测精度,在上述4种攻击类型中选取相同数量样本,利用本文方法、基于云计算机器学习方法和大数据分析方法,分别对这些样本进行特征提取。在空间坐标系中表示提取的结果,不同流量数据的中心坐标如下:正常流量(0,0)、AQL注入流量(-15,-5)、缓冲区溢出(-15,10)、跨站脚本(20,15)、数据篡改(20,0)。3种方法的特征提取聚类结果分别如图3~图5所示。
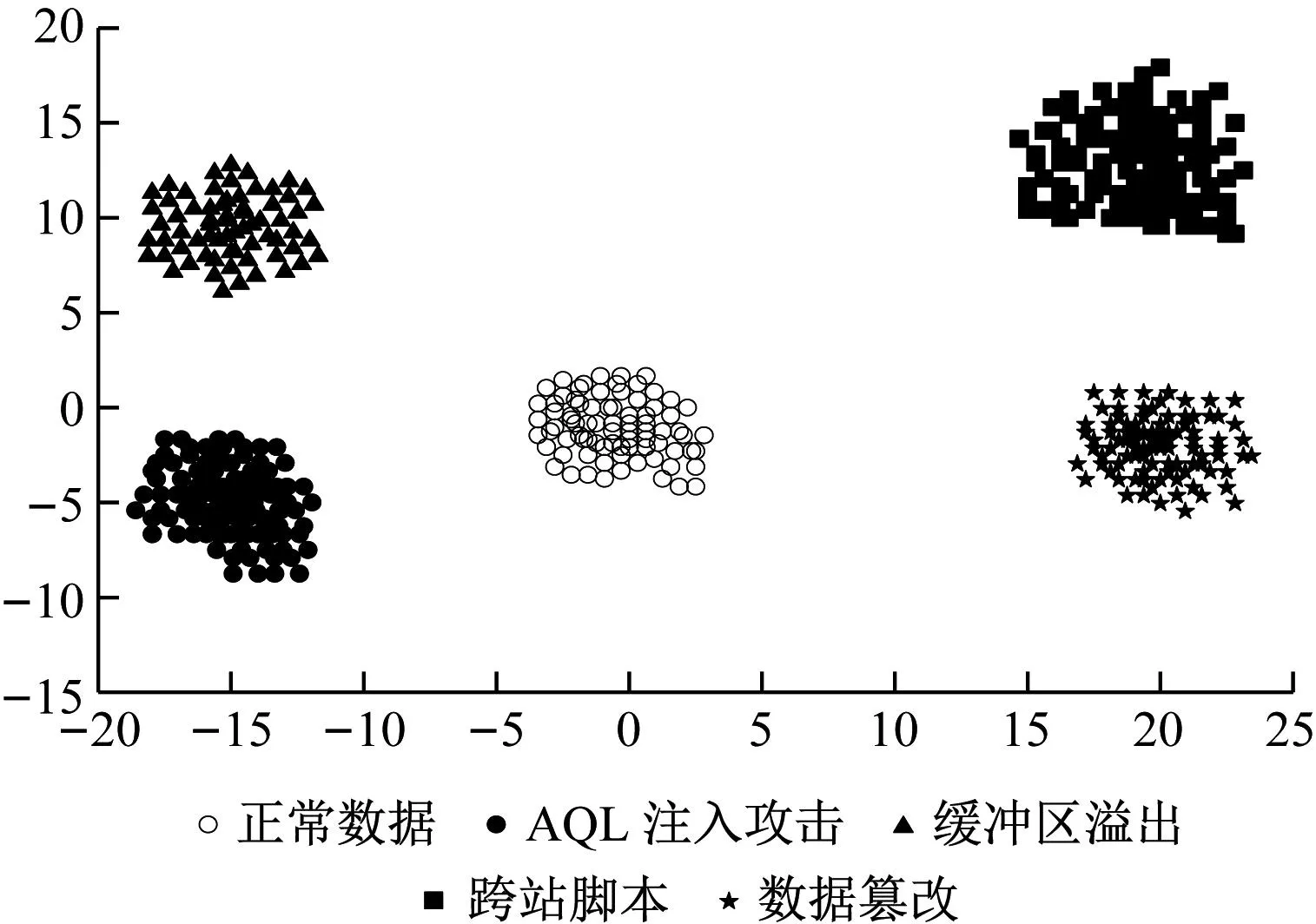
图3 本文方法特征提取结果
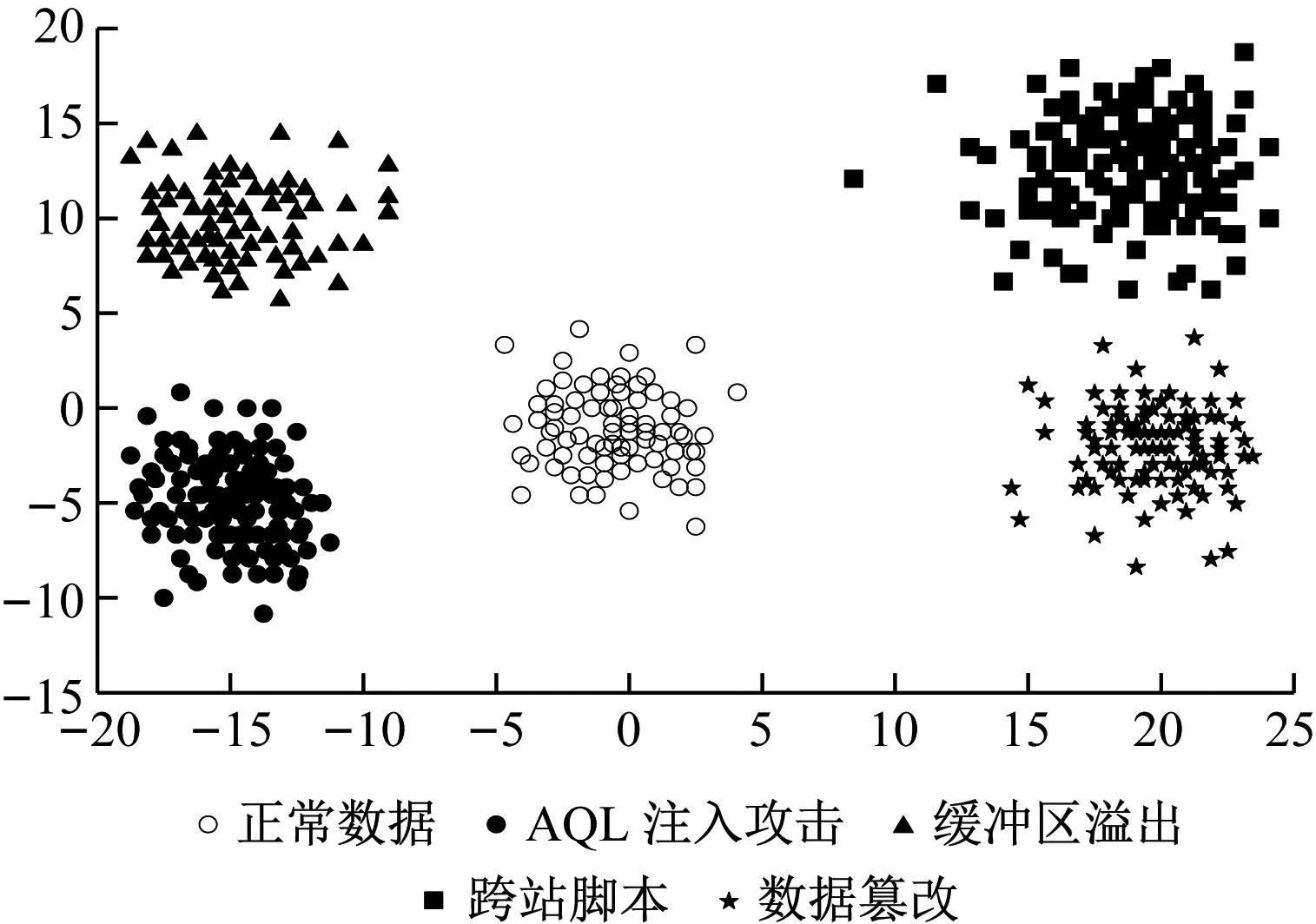
图4 基于云计算机器学习方法特征提取结果
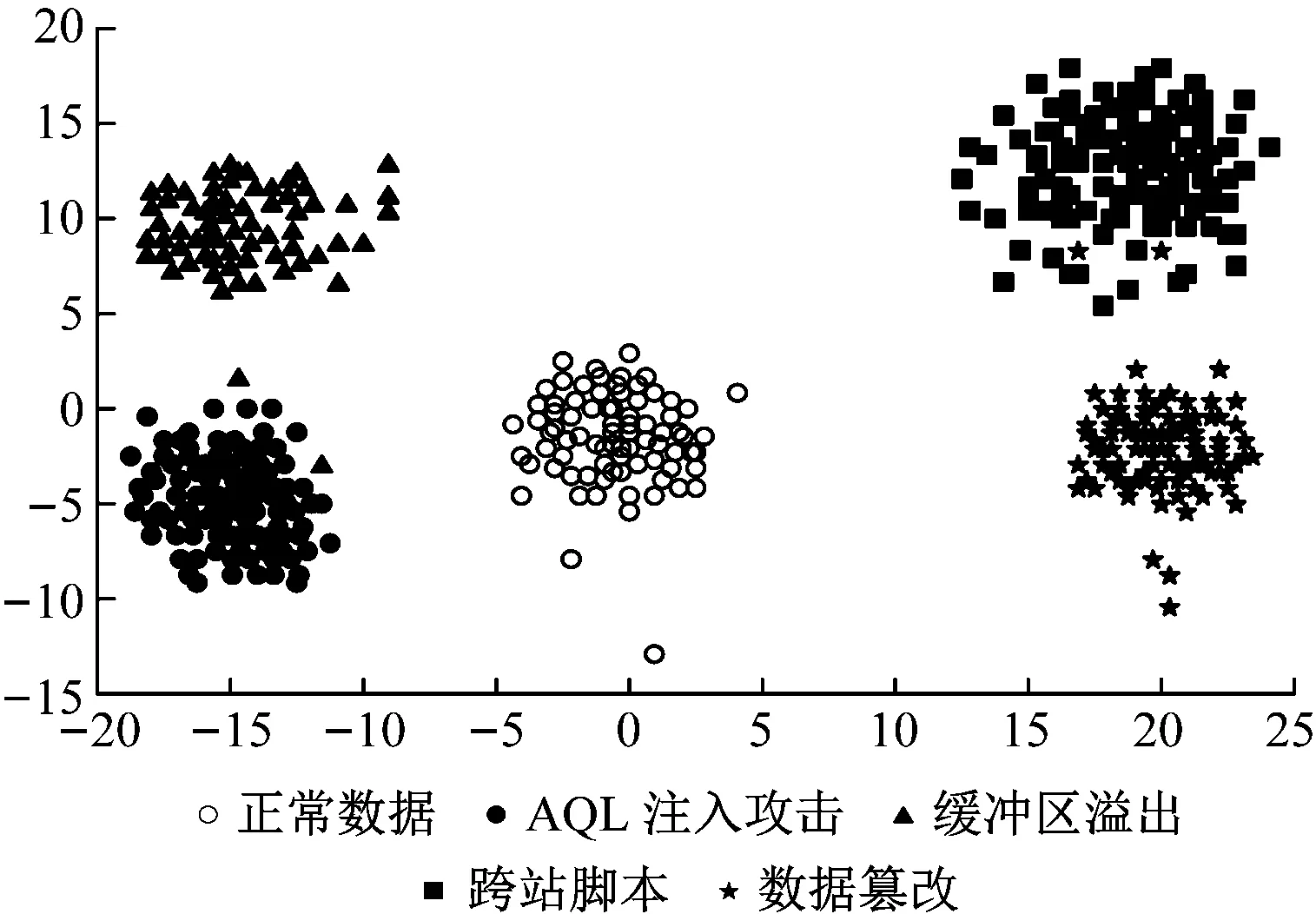
图5 大数据分析方法特征提取结果
由图3~图5可知,本文方法对不同类型流量的聚类效果非常明显,在类间距离最大情况下确保类内距离最小;而基于云计算机器学习方法虽然没有出现错误聚类的现象,但是类间距离较小,分类特征不够明显,一旦流量样本增加,则容易聚类错误;大数据分析方法出现错误聚类现象,类内距离较大。这是因为本文使用的特征提取算法选择了适合的小波函数,提高特征提取能力,因此能够取得较好的聚类效果。
为验证不同方法的检测效果,考虑检测率与误警率双重指标,设计了Effectiveness Measure(EM)指标,假设C′代表所有流量类型,i=1描述仅取异常流量。则该指标可通过下述公式描述:
(19)
式中,DR和FAR分别代表检出率和虚警率,计算公式分别如下:
(20)
(21)
式中,TP与TN分别代表被正确检测为正常与异常流量的数量,FP与FN分别为被错误检测为正常和异常流量的数量。
经过计算,上述3种算法的EM指标测试情况如图6所示,EM指标值越高表明检测算法同时满足高检测率与低误警率的要求。
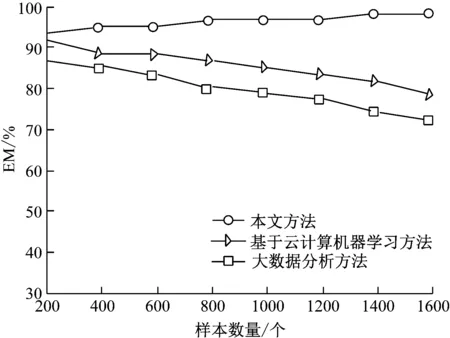
图6 不同算法EM指标测试结果图
由图6能够看出,本文方法随着检测样本的增加,EM值没有表现出下降趋势,其他两种方法均有不同程度的下降表现。因此,本文方法不仅表现出较高的检测率还能降低误警率,算法的整体性能较好。主要因为本文构建的混合神经网络检测模型具有较强的学习能力,能够通过提取的特征经过不断学习,判断出流量是否存在异常,实现流量异常检测。
5 总结
Web网络异常流量检测是维护网络整体安全的重要保障。因此本文建立了混合神经网络模型,通过深度学习过程学习异常流量特征,精准输出检测结果。仿真实验证明,本文方法能够同时满足高检出率和低虚警率两个指标要求,解决了异常流量和正常流量的分类问题。
但由于时间的限制,本文只进行了初步探索,在实际应用中可能会出现一些问题,因此还需针对更多的数据样本进行训练,同时提高检测设备的硬件配置。从不同方面共同提高算法的应用效果,进一步保障Web网络安全。
